Analysieren von Abfragen und Problembehandlung mit Snowpark Scala¶
Unter diesem Thema werden einige Richtlinien zur Analyse von Abfragen und zur Behandlung von Problemen bei Verwendung der Snowpark-Bibliothek bereitgestellt.
Unter diesem Thema:
Anzeigen des Ausführungsplans von Abfragen in Snowpark¶
Um den Evaluierungsplan eines DataFrame zu prüfen, rufen Sie die explain-Methode des DataFrame auf. Dadurch werden die SQL-Anweisungen ausgegeben, die zur Evaluierung des DataFrame verwendet werden. Wenn es nur eine SQL-Anweisung gibt, gibt die Methode auch den logischen Plan für die Anweisung aus.
----------DATAFRAME EXECUTION PLAN----------
Query List:
0.
SELECT
"_1" AS "col %",
"_2" AS "col *"
FROM
(
SELECT
*
FROM
(
VALUES
(1 :: int, 2 :: int),
(3 :: int, 4 :: int) AS SN_TEMP_OBJECT_639016133("_1", "_2")
)
)
Logical Execution Plan:
GlobalStats:
partitionsTotal=0
partitionsAssigned=0
bytesAssigned=0
Operations:
1:0 ->Result SN_TEMP_OBJECT_639016133.COLUMN1, SN_TEMP_OBJECT_639016133.COLUMN2
1:1 ->ValuesClause (1, 2), (3, 4)
--------------------------------------------
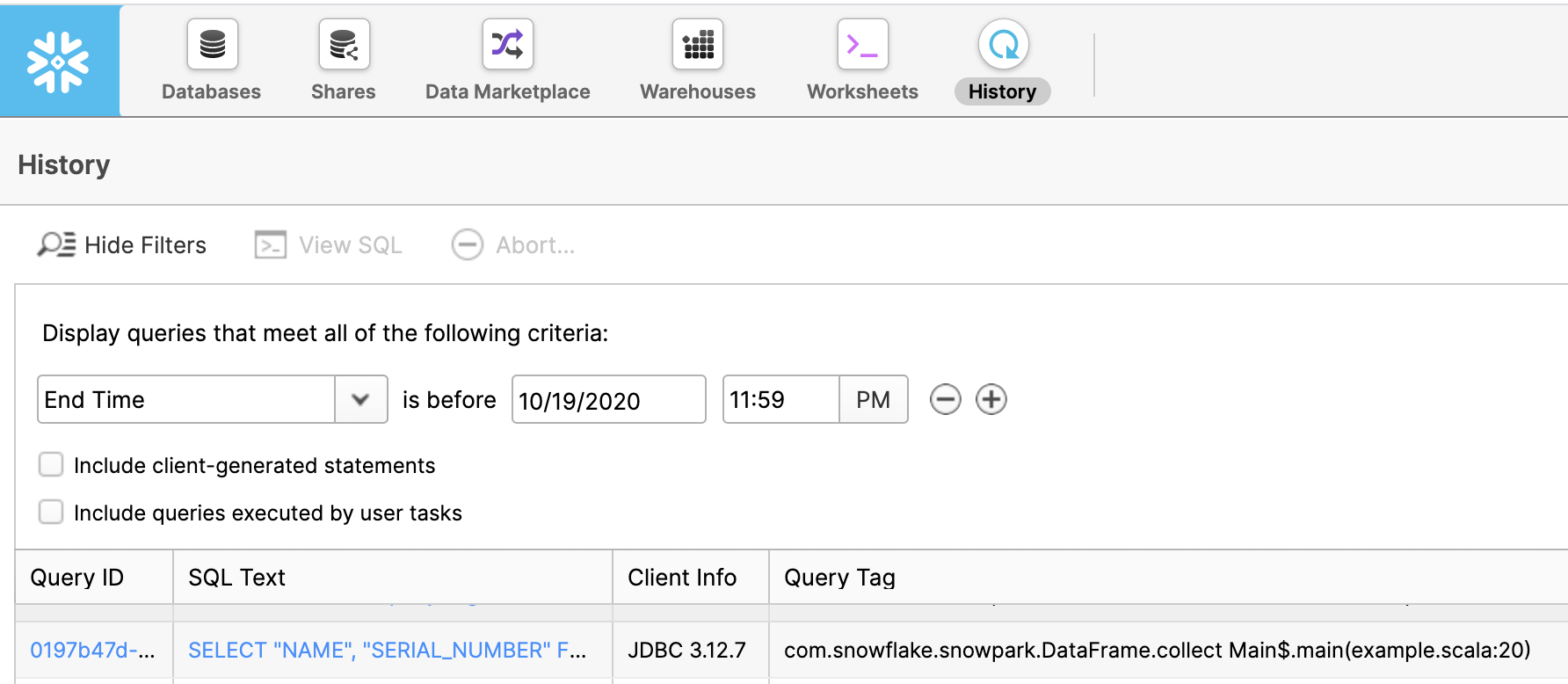
Nachdem die Ausführung eines DataFrame ausgelöst wurde, können Sie den Fortschritt der Abfrage auf der Seite History ![]() der alten Weboberfläche überprüfen.
der alten Weboberfläche überprüfen.
In der Spalte Query Tag finden Sie den Namen der Funktion und die Nummer der Codezeile, in der diese Abfrage ausgelöst wurde.
Problembehandlung¶
Ändern der Protokollierungseinstellungen¶
Standardmäßig protokolliert die Snowpark-Bibliothek Meldungen des Protokolliergrads INFO in stdout. Um die Protokollierungseinstellungen zu ändern, erstellen Sie eine simplelogger.properties-Datei, und konfigurieren Sie die Logger-Eigenschaften in dieser Datei. Setzen Sie beispielsweise die Protokollstufe wie folgt auf DEBUG:
# simplelogger.properties file (a text file)
# Set the default log level for the SimpleLogger to DEBUG.
org.slf4j.simpleLogger.defaultLogLevel=debug
Speichern Sie diese Datei in Ihren Klassenpfad. Wenn Sie eine Maven-Verzeichnisstruktur verwenden, speichern Sie die Datei im Verzeichnis src/main/resources/.
„java.lang.OutOfMemoryError“-Ausnahmen¶
Wenn eine java.lang.OutOfMemoryError-Ausnahme ausgelöst wird, erhöhen Sie die maximale Heap-Größe der JVM.
Wenn Sie die Scala-REPL verwenden und die maximale Heap-Größe erhöhen möchten, müssen Sie das Shell-Skript run.sh (ist in der Archivdatei enthalten) bearbeiten und das Flag -J-Xmxmaximum_size zum scala-Befehl hinzufügen. Im folgenden Beispiel wird die maximale Heap-Größe auf 4 GB erhöht:
scala -J-Xmx4G ...