데이터를 로드하기 위한 Snowpipe REST 엔드포인트 개요¶
이 항목에서는 데이터를 로드하고 로드 내역 보고서를 검색하기 위해 공용 REST 엔드포인트를 호출하는 경우의 사용 세부 정보에 대한 개요를 제공합니다.
이 항목의 내용:
인증¶
수집 서비스는 클라이언트 세션을 유지하지 않으므로, 공용 Snowpipe REST 엔드포인트 호출에서는 일반적인 사용자 이름/비밀번호 인증 대신 키 기반 인증을 사용합니다.
최소 권한의 일반 원칙을 따르려면 파이프를 사용하여 파일을 수집하기 위해 사용할 별도의 사용자와 역할을 생성하는 것이 좋습니다. 사용자는 이 역할을 기본 역할로 생성해야 하며 역할에는 대상 테이블에 파일을 삽입하여 데이터를 로드하기 위해 필요한 최소한의 권한 세트가 있어야 합니다.
프로세스 흐름¶
클라이언트 애플리케이션은 데이터 파일 이름 목록과 참조된 파이프 이름을 사용하여 공용 REST 엔드포인트를 호출합니다(사용자 편의를 위해 Java 및 Python SDKs 제공됨). 목록과 일치하는 새 데이터 파일이 스테이지에서 발견되면 로드하기 위해 큐에 추가됩니다. Snowflake가 제공하는 컴퓨팅 리소스는 파이프에 정의된 매개 변수를 기반으로 큐에서 Snowflake 테이블로 데이터를 로드합니다.
다음 다이어그램은 Snowpipe REST API 프로세스 흐름을 보여줍니다.
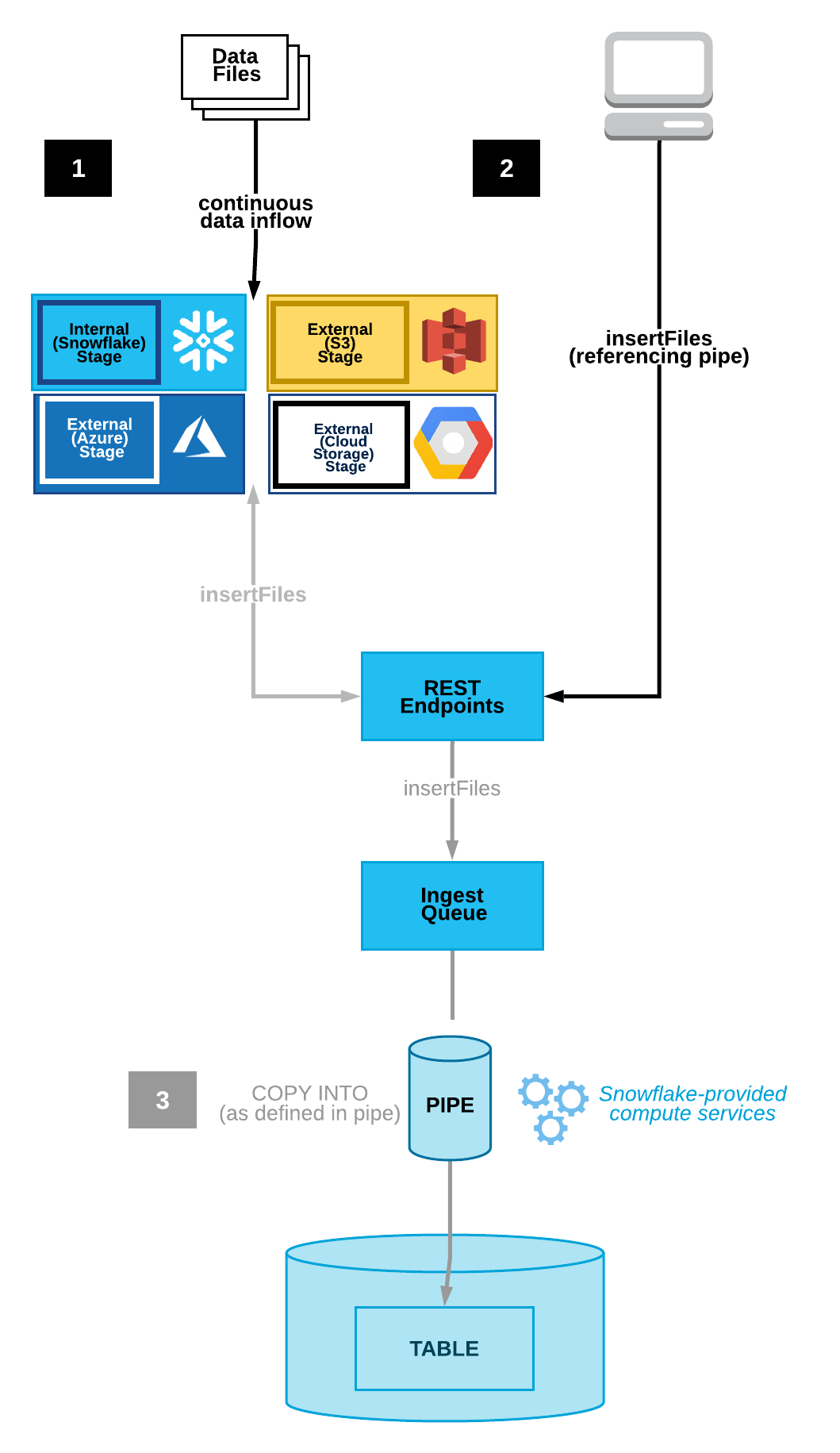
데이터 파일은 내부(Snowflake) 또는 외부(Amazon S3, Google Cloud Storage 또는 Microsoft Azure) 스테이지에 복사됩니다.
클라이언트는 수집할 파일 목록과 정의된 파이프를 사용하여
insertFiles엔드포인트를 호출합니다.엔드포인트는 이러한 파일을 수집 큐로 이동합니다.
Snowflake가 제공하는 가상 웨어하우스는 지정된 파이프에 정의된 매개 변수를 기반으로 큐에서 대기 중인 파일의 데이터를 대상 테이블로 로드합니다.
워크플로¶
이 섹션에서는 설정 및 로드 워크플로에 대한 개략적인 개요를 제공합니다.
Snowpipe 구성하기¶
데이터 파일을 스테이징할 명명된 스테이지 오브젝트를 생성합니다. Snowpipe는 내부(Snowflake) 스테이지와 외부 스테이지(즉, S3 버킷)를 모두 지원합니다.
CREATE PIPE 를 사용하여 파이프 오브젝트를 생성합니다.
연속 데이터 로드를 실행할 사용자에 대한 보안을 구성합니다. Snowpipe 데이터 로드를 1명의 사용자로 제한하려는 경우 사용자에 대한 키 페어 인증을 한 번만 구성하면 됩니다. 이후에는 각 데이터를 로드하기 사용되는 데이터베이스 오브젝트에 대한 액세스 제어 권한만 부여하면 됩니다.
Snowpipe 공용 REST 엔드포인트를 호출하기 위한 클라이언트 SDK(Java 또는 Python)를 설치합니다.
Snowpipe REST API를 사용하여 데이터 로드하기¶
옵션 1: 클라이언트를 사용한 REST API 호출¶
클라이언트를 사용하여 REST API를 호출합니다. Java 및 Python SDK 샘플 코드가 제공됩니다. 자세한 내용은 옵션 1: Snowpipe REST API를 사용하여 데이터 로드하기 섹션을 참조하십시오.
스테이징 시에 로드할 파일 목록과 함께 REST 엔드포인트를 호출합니다.
로드 내역을 검색합니다.
옵션 2: AWS Lambda를 사용한 REST API 호출¶
REST API를 호출하기 위해 AWS Lambda 함수를 사용하여 Snowpipe를 자동화합니다. Lambda 함수는 Amazon S3에 저장된 파일에서만 REST API를 호출하여 데이터를 로드할 수 있습니다. 자세한 내용은 옵션 2: AWS Lambda를 사용한 Snowpipe 자동화 섹션을 참조하십시오.
Snowpipe REST API를 호출하여 외부(예: S3) 스테이지에서 데이터를 로드하는 AWS Lambda 함수를 생성합니다.
로드 내역을 검색합니다.