Introduction aux UDFs Java¶
Vous pouvez écrire le gestionnaire d’une fonction définie par l’utilisateur (UDF) en Java. Les rubriques de cette section décrivent comment concevoir et écrire un gestionnaire Java. Vous trouverez également des exemples.
Pour une introduction aux UDFs, y compris une liste de langages dans lesquels vous pouvez écrire un gestionnaire d’UDF, reportez-vous à Vue d’ensemble des fonctions définies par l’utilisateur.
Une fois que vous avez un gestionnaire, vous créez l’UDF avec SQL. Pour plus d’informations sur l’utilisation de SQL pour créer ou appeler une UDF, reportez-vous à Créer une fonction définie par l’utilisateur ou Exécutez une UDF.
Snowflake prend actuellement en charge l’écriture d’UDFs dans les versions suivantes de Java :
11.x
17.x
Note
Pour les limitations liées aux gestionnaires d’UDF Java, reportez-vous à Limitations liées aux UDF Java.
Dans ce chapitre :
Fonctionnement d’un gestionnaire Java¶
Lorsqu’un utilisateur appelle une UDF, il transmet le nom et les arguments de l’UDF à Snowflake. Snowflake appelle le code du gestionnaire associé (avec des arguments, le cas échéant) pour exécuter la logique de l’UDF. La méthode de gestion renvoie ensuite la sortie à Snowflake, qui la renvoie au client.
Pour chaque ligne transmise à une UDF, l’UDF renvoie soit une valeur scalaire (c’est-à-dire unique), soit, si elle est définie comme une fonction de table, un ensemble de lignes.
Les UDFs Java peuvent contenir à la fois du nouveau code et des appels vers des bibliothèques existantes, ce qui vous offre à la fois flexibilité et réutilisation du code. Par exemple, si vous disposez déjà d’un code d’analyse de données en Java, vous pouvez probablement l’intégrer dans une UDF Java.
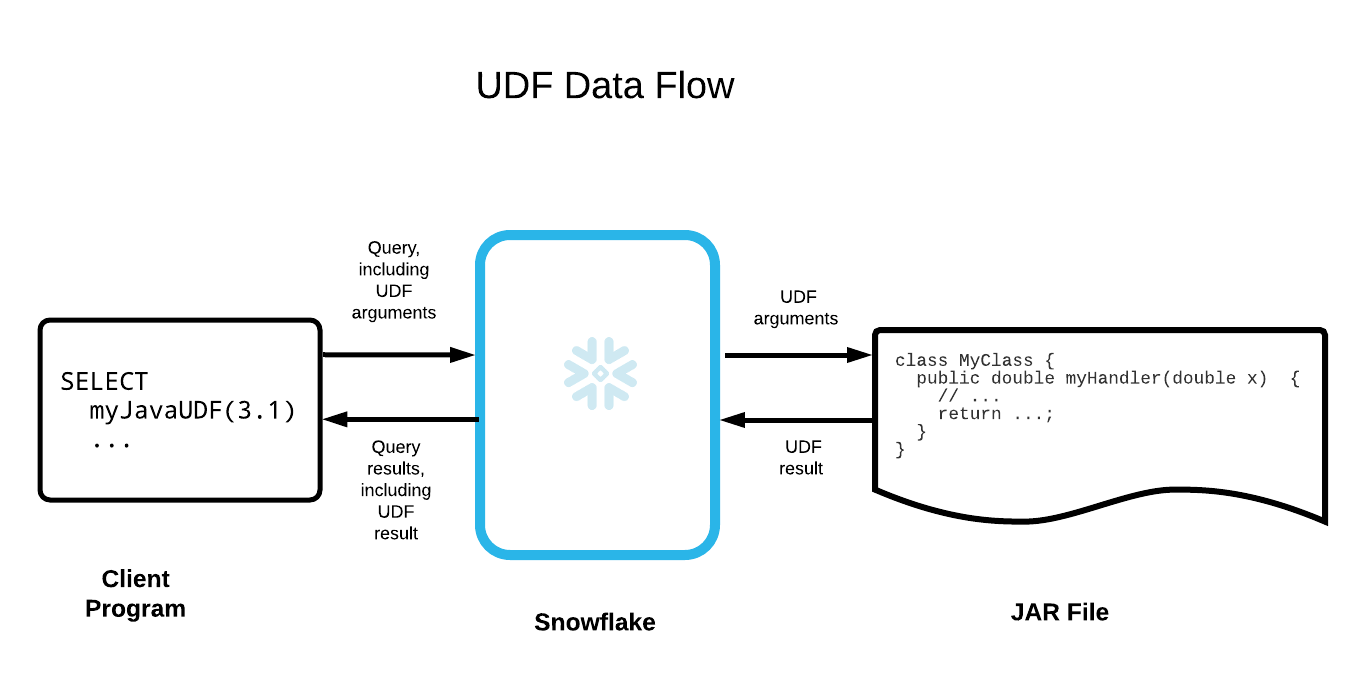
Vous trouverez ci-dessous une illustration simplifiée du flux de données :
Exemple¶
Le code de l’exemple suivant crée une UDF appelée echo_varchar avec une méthode de gestionnaire TestFunc.echoVarchar. Les types d’arguments et de retours Java sont convertis de et vers SQL par Snowflake selon les mappings décrits dans Mappages de type de données SQL-Java.
CREATE OR REPLACE FUNCTION echo_varchar(x VARCHAR)
RETURNS VARCHAR
LANGUAGE JAVA
CALLED ON NULL INPUT
HANDLER = 'TestFunc.echoVarchar'
TARGET_PATH = '@~/testfunc.jar'
AS
'class TestFunc {
public static String echoVarchar(String x) {
return x;
}
}';
Remarques relatives à la conception¶
Gardez à l’esprit les points suivants pour concevoir un gestionnaire utile.
Considérations générales. Pour les considérations communes aux UDFs et aux procédures, reportez-vous à Directives et contraintes de conception pour les fonctions et les procédures.
Mappage de type Java SQL. Lors de l’échange d’arguments et de valeurs de retour avec une UDF, Snowflake fait la conversion entre le langage du gestionnaire et SQL. Pour plus d’informations sur le choix des types de données pour votre code de gestionnaire, reportez-vous à Choisir vos types de données.
Code empaqueté. Vous pouvez rendre le code de votre gestionnaire disponible soit en ligne avec l’instruction CREATE FUNCTION, soit sur une zone de préparation en tant que code compilé dans une instruction JAR. Pour plus d’informations sur la différence, reportez-vous à Conserver le code du gestionnaire en ligne ou dans une zone de préparation.
Optimisation de code. Pour plus d’informations sur l’optimisation du code de votre gestionnaire, par exemple lorsque le code gère des états partagés entre plusieurs lignes, reportez-vous à Optimisation de l’initialisation et contrôle de l’état global dans des UDFs scalaires.
Meilleures pratiques. Pour plus d’informations sur les meilleures pratiques, reportez-vous à Suivre les meilleures pratiques et Pratiques de sécurité pour UDFs et procédures.
Codage du gestionnaire¶
Des principes de base à des exemples détaillés, les rubriques suivantes décrivent comment écrire un gestionnaire UDF en Java.
Définition de classe Java. Vous écrivez la logique d’une UDF dans une classe Java. Pour en savoir plus sur la manière dont Snowflake interagit avec votre code, reportez-vous à Conception de la classe.
Traitement des erreurs. Pour plus d’informations sur la façon dont Snowflake traite les erreurs générées par les gestionnaires, reportez-vous à Gestion des erreurs.
Valeurs de retour tabulaires. Vous pouvez renvoyer des valeurs tabulaires ainsi que des valeurs scalaires (individuelles) à partir d’une UDF. Pour plus d’informations sur la manière d’écrire un gestionnaire qui renvoie des valeurs tabulaires, reportez-vous à UDFs Java tabulaires (UDTFs).
Journalisation et traçage d’événements. Pour plus d’informations sur la capture des données de journal et de trace lors de l’exécution du code de votre gestionnaire, reportez-vous à Journalisation, traçage et métriques.
Dépendances. Vous pouvez mettre des dépendances à la disposition de votre code au moment de l’exécution en les chargeant dans une zone de préparation. Pour plus d’informations, reportez-vous à Mettre les dépendances à la disposition de votre code.
Organisation des fichiers du gestionnaire. Si vous avez l’intention d’empaqueter le code compilé du gestionnaire dans un fichier JAR, organisez et concevez votre code en utilisant les suggestions de Organiser vos fichiers.
Exemples de code Pour une série d’exemples de gestionnaires en Java, reportez-vous à Exemples de gestionnaires d’UDF Java.