Introdução a UDFs de Java¶
Você pode escrever o manipulador para uma função definida pelo usuário (UDF) em Java. Os tópicos desta seção descrevem como projetar e escrever um manipulador Java. Você também encontrará exemplos.
Para uma introdução às UDFs, incluindo uma lista de linguagens na qual você pode escrever um manipulador de UDF, consulte Visão geral das funções definidas pelo usuário.
Quando você tiver um manipulador, você criará a UDF com SQL. Para obter mais informações sobre como usar SQL para criar ou chamar uma UDF, consulte Criação de uma função definida pelo usuário ou Execução de uma UDF.
O Snowflake atualmente oferece suporte à escrita de UDFs nas seguintes versões de Java:
11.x
17.x
Nota
Para limitações relacionadas aos manipuladores da UDF de Java, consulte Limitações da UDF Java.
Como funciona um manipulador de Java¶
Quando um usuário chama uma UDF, o usuário passa o nome e os argumentos da UDF para o Snowflake. Snowflake chama o código do manipulador associado (com argumentos, se houver) para executar a lógica da UDF. O método do manipulador então retorna a saída para o Snowflake, que a passa de volta para o cliente.
Para cada linha passada para uma UDF, a UDF retorna um valor escalar (ou seja, único) ou, se definida como uma função de tabela, um conjunto de linhas.
UDFs de Java podem conter tanto código novo como chamadas para bibliotecas existentes, permitindo flexibilidade e reutilização do código. Por exemplo, se você já tem um código de análise de dados em Java, você provavelmente pode incorporá-lo em uma UDF de Java.
Abaixo está uma ilustração simplificada do fluxo de dados:
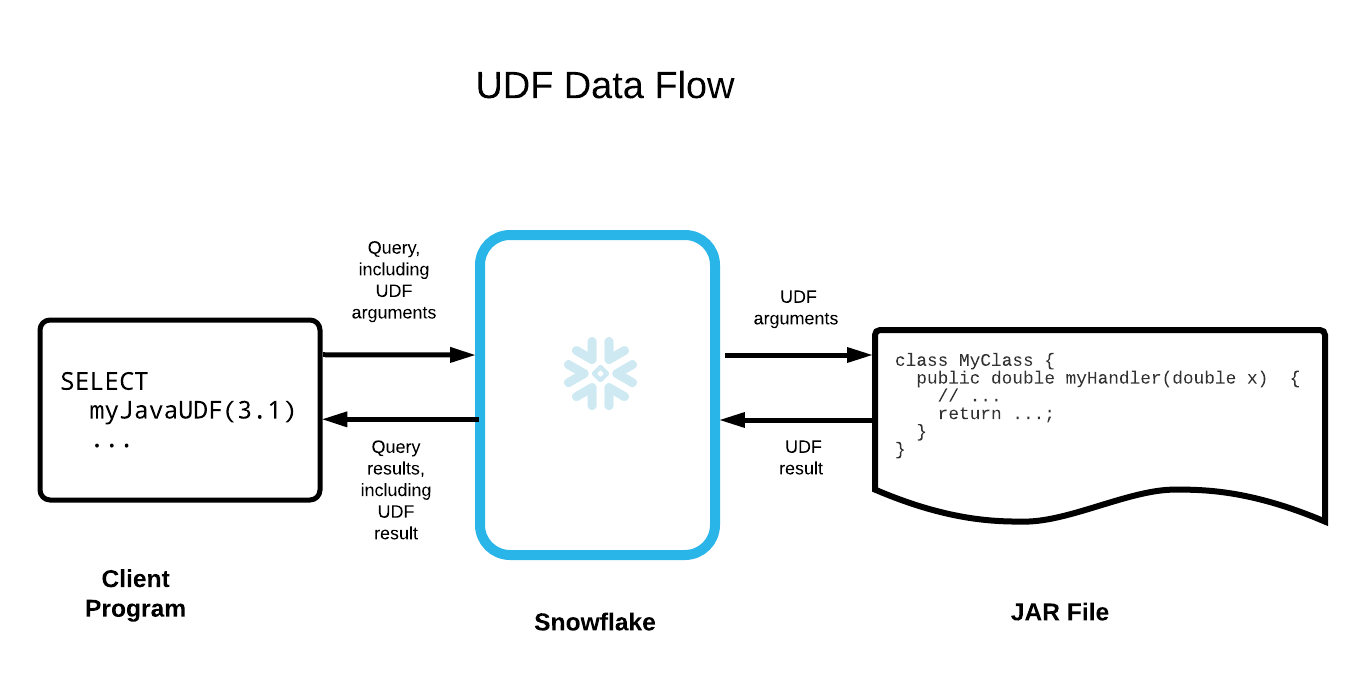
Exemplo¶
O código no exemplo a seguir cria uma UDF chamada echo_varchar com um método do manipulador TestFunc.echoVarchar. O argumento Java e os tipos de retorno são convertidos de e para SQL pelo Snowflake de acordo com os mapeamentos descritos em Mapeamentos de tipos de dados SQL-Java.
Considerações sobre o projeto¶
Tenha em mente o seguinte ao projetar um manipulador útil.
Considerações gerais. Para considerações comuns a UDFs e procedimentos, consulte Diretrizes de projeto e restrições para funções e procedimentos.
Mapeamento de tipo Java-SQL. Ao trocar argumentos e retornar valores com uma UDF, Snowflake converte entre a linguagem do manipulador e SQL. Para obter mais informações sobre a escolha dos tipos de dados para seu código de manipulador, consulte Como escolher seus tipos de dados.
Empacotamento de código. Você pode disponibilizar seu código de manipulador em linha com a instrução CREATE FUNCTION ou em um estágio como código compilado em um JAR. Para obter mais informações sobre a diferença, consulte Como manter o código do manipulador em linha ou em um estágio.
Otimização do código. Para obter mais informações sobre a otimização do código do manipulador, como quando o código lida com estado compartilhado entre linhas, consulte Como otimizar a inicialização e controlar o estado global em UDFs escalares.
Práticas recomendadas. Para obter mais informações sobre as práticas recomendadas, consulte Práticas recomendadas e Práticas de segurança para UDFs e procedimentos.
Codificação do manipulador¶
De exemplos básicos a detalhados, os seguintes tópicos descrevem como escrever um manipulador de UDF em Java.
Definição da classe Java. Você escreve a lógica para uma UDF em uma classe Java. Para obter mais informações sobre como Snowflake interage com seu código, consulte Criação da classe.
Tratamento de erros. Para obter mais informações sobre como o Snowflake descobre os erros gerados por manipuladores, consulte Tratamento de erros.
Valores tabulares de retorno. Você pode retornar valores tabulares assim como valores escalares (únicos) a partir de uma UDF. Para obter mais informações sobre como escrever um manipulador que retorna valores tabulares, consulte UDFs tabulares (UDTFs) de Java.
Registro em log e rastreamento de eventos. Para obter mais informações sobre a captura de dados de registro e rastreamento à medida que o código do manipulador é executado, consulte Registro, rastreamento e métricas.
Dependências. Você pode disponibilizar dependências para seu código no tempo de execução, carregando-as em um estágio. Para obter mais informações, consulte Disponibilização das dependências para seus códigos.
Organização de arquivos do manipulador. Se você pretende empacotar o código compilado do manipulador em um arquivo JAR, organize e construa seu código usando as sugestões em Organização de arquivos.
Exemplos de códigos Para uma série de exemplos de manipuladores em Java, consulte Exemplos de manipuladores de UDF Java.