Exemple de service à distance asynchrone pour AWS¶
Cette rubrique contient un exemple de fonction AWS Lambda asynchrone (service distant). Vous pouvez créer cet exemple de fonction en suivant les mêmes étapes que celles décrites dans Étape 1 : Créer le service distant (fonctionAWS Lambda) dans la console de gestion.
Aperçu du code¶
Cette section de la documentation fournit des informations sur la création d’une fonction externe asynchrone sur AWS. (Avant de mettre en œuvre votre première fonction externe asynchrone, vous pouvez lire l” aperçu conceptuel des fonctions externes asynchrones).
Sur AWS, les services à distance asynchrones doivent surmonter les restrictions suivantes :
Comme les requêtes HTTP POST et GET sont des requêtes distinctes, le service distant doit conserver des informations sur le workflow lancé par la requête POST afin que l’état puisse être interrogé ultérieurement par la requête GET.
En général, chaque requête HTTP POST et HTTP GET appelle une instance distincte de la ou des fonctions de gestionnaire dans un processus ou un chemin distinct. Les différentes instances ne partagent pas leur mémoire. Pour que le gestionnaire GET puisse lire le statut ou les données traitées, le gestionnaire GET doit accéder à une ressource de stockage partagée qui est disponible sur AWS.
La seule façon pour le gestionnaire POST d’envoyer le code de réponse initial HTTP 202 est d’utiliser une instruction
return(ou un équivalent), qui met fin à l’exécution du gestionnaire. Par conséquent, avant de renvoyer HTTP 202, le gestionnaire POST doit lancer un processus indépendant (ou thread) pour effectuer le travail de traitement des données du service à distance. Ce processus indépendant nécessite généralement un accès au stockage qui est visible pour le gestionnaire GET.
Un moyen pour un service distant asynchrone de surmonter ces restrictions est d’utiliser 3 processus (ou chemins) et un stockage partagé :
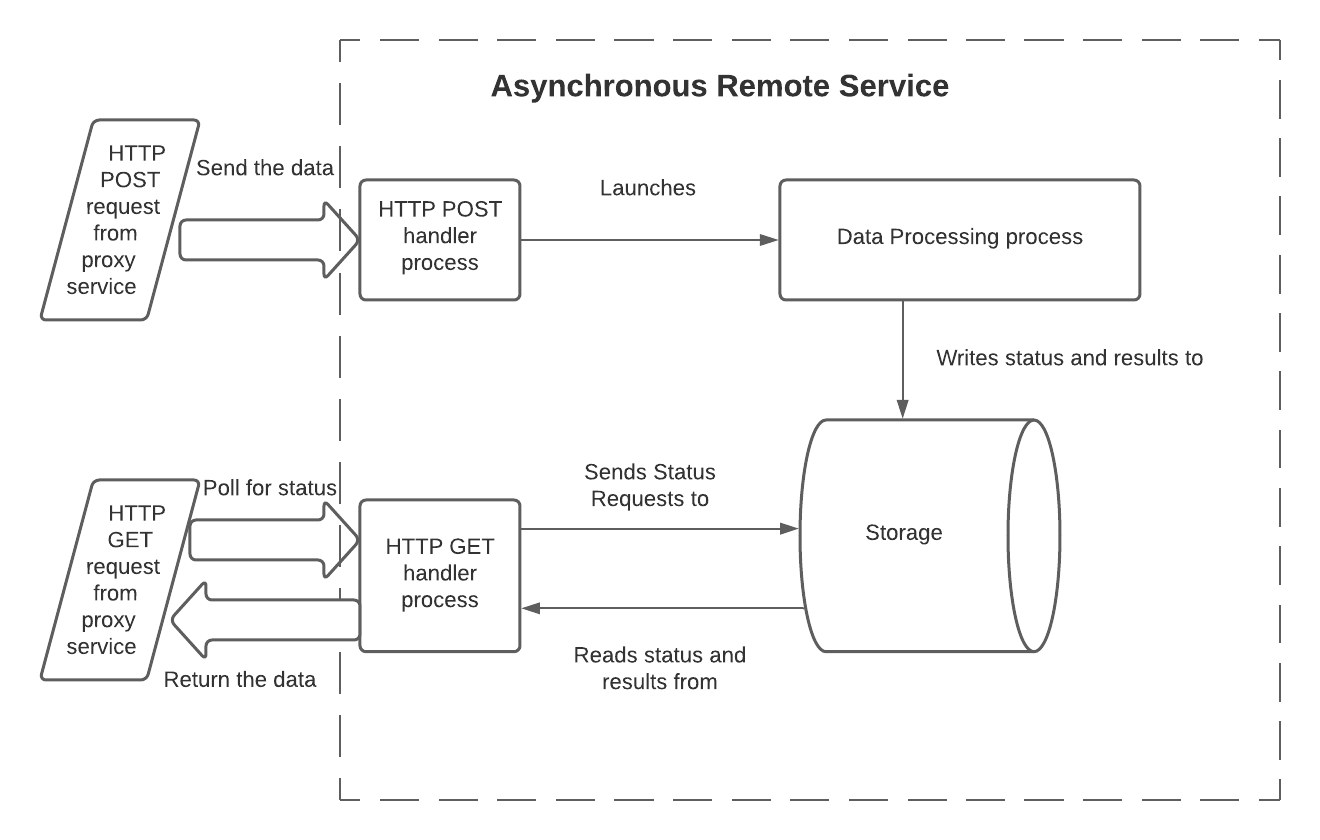
Dans ce modèle, les processus ont les responsabilités suivantes :
Le gestionnaire HTTP POST :
Lit les données d’entrée. Dans une fonction Lambda, elle est lue à partir du corps du paramètre d’entrée
eventde la fonction de gestionnaire.Lit l’ID de lot. Dans une fonction Lambda, ceci est lu à partir de l’en-tête du paramètre d’entrée
event.Lance le processus de traitement des données, et lui transmet les données et l’ID de lot. Les données sont généralement transmises pendant l’appel, mais elles peuvent être transmises en les écrivant sur un stockage externe.
Enregistre l’ID de lot dans un stockage partagé auquel peuvent accéder à la fois le processus de traitement des données et le processus du gestionnaire HTTP GET.
Si nécessaire, enregistre que le traitement de ce lot n’est pas encore terminé.
Retourne HTTP 202 si aucune erreur n’a été détectée.
Le code de traitement des données :
Lit les données d’entrée.
Traite les données.
Met le résultat à la disposition du gestionnaire GET (soit en écrivant les données de résultat sur un stockage partagé, soit en fournissant une API permettant d’interroger les résultats).
Généralement, il met à jour le statut de ce lot (par exemple de
IN_PROGRESSàSUCCESS) pour indiquer que les résultats sont prêts à être lus.Quitte. En option, ce processus peut renvoyer un indicateur d’erreur. Snowflake ne le voit pas directement (Snowflake ne voit que les codes de retour HTTP du gestionnaire POST et du gestionnaire GET), mais le renvoi d’un indicateur d’erreur du processus de traitement des données pourrait aider au débogage.
Le gestionnaire GET :
Lit l’ID de lot. Dans une fonction Lambda, ceci est lu à partir de l’en-tête du paramètre d’entrée
event.Lit le stockage pour obtenir le statut actuel de ce lot (par exemple
IN_PROGRESSouSUCCESS).Si le traitement est toujours en cours, alors retournez 202.
Si le traitement s’est terminé avec succès, alors :
Lisez les résultats.
Nettoyez le stockage.
Renvoyez les résultats avec le code HTTP 200.
Si le statut stocké indique une erreur, alors :
Nettoyez le stockage.
Renvoyez un code d’erreur.
Notez que le gestionnaire GET peut être appelé plusieurs fois pour un lot si le traitement prend suffisamment de temps pour que plusieurs requêtes HTTP GET soient envoyées.
Il existe de nombreuses variations possibles sur ce modèle. Par exemple :
L’ID de lot et le statut pourraient être écrits au début du processus de traitement des données plutôt qu’à la fin du processus POST.
Le traitement des données pourrait être effectué dans une fonction distincte (par exemple, une fonction Lambda distincte) ou même comme un service complètement distinct.
Le code de traitement des données ne doit pas nécessairement être écrit sur un stockage partagé. Au lieu de cela, les données traitées pourraient être mises à disposition d’une autre manière. Par exemple, une API pourrait accepter l’ID de lot comme paramètre et renvoyer les données.
Le code de mise en œuvre doit tenir compte de la possibilité que le traitement prenne trop de temps ou échoue, et tout résultat partiel doit donc être nettoyé pour éviter de gaspiller de l’espace de stockage.
Le mécanisme de stockage doit pouvoir être partagé entre plusieurs processus (ou chemins). Parmi les mécanismes de stockage possibles, on peut citer :
Les mécanismes de stockage fournis par AWS, tels que :
Espace disque (par exemple Système de fichiers élastiques d’Amazon (EFS) ).
Un serveur de base de données local disponible via AWS (par exemple Amazon DynamoDB ).
Stockage qui est à l’extérieur de AWS mais accessible depuis AWS.
Le code de chacun des 3 processus ci-dessus peut être écrit comme 3 fonctions Lambda séparées (une pour le gestionnaire POST, une pour la fonction de traitement des données et une pour le gestionnaire GET), ou comme une fonction unique qui peut être appelée de différentes manières.
L’exemple de code Python ci-dessous est une fonction Lambda unique qui peut être appelée séparément pour les processus POST, le traitement des données et GET.
Exemple de code¶
Ce code montre un exemple de requête avec sortie. Dans cet exemple, l’accent est mis sur les trois processus et leur interaction, et non sur le mécanisme de stockage partagé (DynamoDB) ou la transformation des données (analyse des sentiments). Le code est structuré de manière à faciliter le remplacement du mécanisme de stockage et de transformation des données par d’autres.
Par souci de simplicité, voici un exemple :
Code en dur certaines valeurs importantes (par exemple, la région AWS).
Suppose l’existence de certaines ressources (par exemple, la table Jobs dans Dynamo).
Exemple d’appel et de sortie¶
Voici un exemple d’appel à la fonction externe asynchrone, ainsi qu’un exemple de sortie, avec les résultats de l’analyse des sentiments :
Notes sur l’exemple de code¶
La fonction de traitement des données est appelée par un appel :
Le InvocationType doit être un « événement », comme indiqué ci-dessus, car le 2e processus (ou chemin) doit être asynchrone et
Eventest le seul type d’appel non bloquant disponible par la méthodeinvoke().La fonction de traitement des données renvoie un code HTTP 200. Toutefois, ce code HTTP 200 n’est pas renvoyé directement à Snowflake. Snowflake ne voit aucun HTTP 200 jusqu’à ce qu’un GET interroge le statut et constate que la fonction de traitement des données a terminé le traitement de ce lot avec succès.