Snowflake ML Model Development¶
注釈
Snowflake ML Modeling API は snowflake-ml-python パッケージバージョン1.1.1で一般公開されます。
Snowflake ML Modeling API は、scikit-learnや LightGBM 、 XGBoost といったおなじみのPythonフレームワークを使用して、データの前処理、特徴量エンジニアリング、Snowflake内でのモデルのトレーニングを実行します。
Snowflake ML Modelingを使用してモデルを開発するメリットには以下が含まれます。
特徴量エンジニアリングおよび前処理: 使用頻度の高いscikit-learn前処理関数の分散実行によるパフォーマンスとスケーラビリティを向上しました。
モデル学習: ストアドプロシージャやユーザー定義関数(UDFs)を手動で作成することなく、分散ハイパーパラメーター最適化を活用して、scikit-learn、 XGBoost、 LightGBM モデルのトレーニングを高速化しました。
Tip
モデリング API などを含む、Snowparkでのエンドツーエンドの ML ワークフローの例については、 Introduction to Machine Learning をご参照ください。
注釈
このトピックでは snowflake-ml-python とそのモデリングの依存関係がすでにインストールされていることを前提としています。 Snowflake ML をローカルで使用する をご参照ください。
モデルの開発¶
Notebooks on Container Runtime で利用可能な Container Runtime for ML を使用すると、Snowflake クラウド内で、1つまたは複数の GPU ノードを活用して、Snowflake データで一般的なオープンソース ML パッケージを使用することができ、 ML ワークフロー全体のセキュリティとガバナンスが確保されます。含まれるデータのロードとトレーニング APIs は、ノード上の利用可能なすべての CPUs または GPUs に自動的に分散され、大規模なデータセットでのモデル・トレーニングを高速化します。
詳細については、 Getting Started with Snowflake Notebook Container Runtime をご参照ください。 ML 用の Container Runtime の機能を活用した簡単な ML ワークフローを紹介しています。
Container Runtime for ML の柔軟性とパワーとともに、Snowflake ML Modeling API は、scikit-learn、xgboost、lightgbm ライブラリと同様の APIs を持つ推定器と変換器を提供します。これらの APIs を使用して、Snowpark Model Registry など、Snowflake ML Operationsで使用できる機械学習モデルを構築してトレーニングすることができます。
例¶
次の例を見て、Snowflake Modeling API と馴染みのある機械学習ライブラリとの類似性を理解してください。
前処理¶
この例では、Snowflake Modeling によるデータの前処理と変換機能の使用方法を説明します。この例で使用されている2つの前処理関数(MixMaxScaler と OrdinalEncoder)は、Snowflakeの分散処理エンジンを使用しているため、クライアントサイドやストアドプロシージャの実装に比べてパフォーマンスが大幅に向上しています。詳細については、 分散前処理 をご参照ください。
import numpy as np
import pandas as pd
import random
import string
from sklearn.datasets import make_regression
from snowflake.ml.modeling.preprocessing import MinMaxScaler, OrdinalEncoder
from snowflake.ml.modeling.pipeline import Pipeline
from snowflake.snowpark import Session
# Create a session with your preferred method
# session =
NUMERICAL_COLS = ["X1", "X2", "X3"]
CATEGORICAL_COLS = ["C1", "C2", "C3"]
FEATURE_COLS = NUMERICAL_COLS + CATEGORICAL_COLS
CATEGORICAL_OUTPUT_COLS = ["C1_OUT", "C2_OUT", "C3_OUT"]
FEATURE_OUTPUT_COLS = ["X1_FEAT_OUT", "X2_FEAT_OUT", "X3_FEAT_OUT", "C1_FEAT_OUT", "C2_FEAT_OUT", "C3_FEAT_OUT"]
# Create a dataset with numerical and categorical features
X, _ = make_regression(
n_samples=1000,
n_features=3,
noise=0.1,
random_state=0,
)
X = pd.DataFrame(X, columns=NUMERICAL_COLS)
def generate_random_string(length):
return "".join(random.choices(string.ascii_uppercase, k=length))
categorical_feature_length = 2
categorical_features = {}
for c in CATEGORICAL_COLS:
categorical_column = [generate_random_string(categorical_feature_length) for _ in range(X.shape[0])]
categorical_features[c] = categorical_column
X = X.assign(**categorical_features)
features_df = session.create_dataframe(X)
# Fit a pipeline with OrdinalEncoder and MinMaxScaler on Snowflake
pipeline = Pipeline(
steps=[
(
"OE",
OrdinalEncoder(
input_cols=CATEGORICAL_COLS,
output_cols=CATEGORICAL_OUTPUT_COLS,
)
),
(
"MMS",
MinMaxScaler(
input_cols=NUMERICAL_COLS + CATEGORICAL_OUTPUT_COLS,
output_cols=FEATURE_OUTPUT_COLS,
)
),
]
)
pipeline.fit(features_df)
# Use the pipeline to transform a dataset.
result = pipeline.transform(features_df)
データのロード¶
![]() プレビュー機能 --- オープン
プレビュー機能 --- オープン
すべてのアカウントで利用可能です。
この例では、 DataConnector API を使用して、Snowflake テーブルから pandas DataFrame または pytorch Dataset にデータをロードする方法を示します。データの取り込みを複数のコアまたは GPUs に分散してロードが高速化されます。
注釈
DataConnector API は Container Runtime for ML で利用でき、Snowpark Container Services (SPCS) 上で動作する Snowsight ノートブックから使用できます。
from snowflake.ml.data.data_connector import DataConnector
# Retrieve data from a snowflake table
table_name = 'LARGE_TABLE_MULTIPLE_GBs'
snowpark_df = session.table(table_name)
# Materialize it into a pandas dataframe using DataConnector
pandas_df = DataConnector.from_dataframe(snowpark_df).to_pandas()
# Materialize it into a pytroch dataset using DataConnector
torch_dataset = data.to_torch_dataset(batch_size=1024)
トレーニング¶
この例では、Snowflake ML Modelingを使用して単純なxgboost分類モデルのトレーニングを行い、予測を実行する方法を示します。ここでの API は、列の指定方法が少し違うだけで、xgboostと類似しています。これらの相違については、 一般的な API の違い をご参照ください。
import pandas as pd
from sklearn.datasets import make_classification
from snowflake.ml.modeling.xgboost import XGBClassifier
from snowflake.ml.utils.connection_params import SnowflakeLoginOptions
from snowflake.snowpark import Session
# Create a session with your preferred method
# session =
FEATURE_COLS = ["X1", "X2", "X3", "X4", "X5", "X6"]
LABEL_COLS = ["Y"]
OUTPUT_COLS = ["PREDICTIONS"]
# Set up data.
X, y = make_classification(
n_samples=40000,
n_features=6,
n_informative=4,
n_redundant=1,
random_state=0,
shuffle=True,
)
X = pd.DataFrame(X, columns=FEATURE_COLS)
y = pd.DataFrame(y, columns=LABEL_COLS)
features_pandas = pd.concat([X, y], axis=1)
features_df = session.create_dataframe(features_pandas)
# Train an XGBoost model on snowflake.
xgboost_model = XGBClassifier(
input_cols=FEATURE_COLS,
label_cols=LABEL_COLS,
output_cols=OUTPUT_COLS
)
xgboost_model.fit(features_df)
# Use the model to make predictions.
predictions = xgboost_model.predict(features_df)
predictions[OUTPUT_COLS].show()
非合成データの特徴量の前処理とトレーニング¶
この例では、地上に設置された大気チェレンコフ望遠鏡からの高エネルギーガンマ粒子データを使用します。この望遠鏡は、ガンマ線によって引き起こされる電磁シャワーの中で生成される荷電粒子から放出される放射線を利用して、高エネルギーのガンマ粒子を観測します。検出器は、大気を透過して漏れるチェレンコフ放射(可視から紫外線の波長)を記録し、ガンマ線シャワーのパラメーターを再構成することができます。この望遠鏡は、宇宙線シャワーに多く含まれ、ガンマ線に似た信号を出すハドロン線も検出します。
目標は、ガンマ線とハドロン線を区別するための分類モデルを開発することです。このモデルによって、科学者はバックグラウンドのノイズをフィルタリングし、本物のガンマ線信号に焦点を当てることができます。ガンマ線により、科学者は星の誕生と死、宇宙爆発、極限状態における物質の挙動といった宇宙現象を観測することができます。
粒子データは MAGIC ガンマ望遠鏡 からダウンロードできます。データをダウンロードして解凍し、 DATA_FILE_PATH 変数にデータファイルを指すように設定し、以下のコードを実行してSnowflakeに読み込みます。
DATA_FILE_PATH = "~/Downloads/magic+gamma+telescope/magic04.data"
# Setup
from snowflake.ml.utils.connection_params import SnowflakeLoginOptions
from snowflake.snowpark import Session
import posixpath
import os
##
# Note: Create session https://docs.snowflake.com/en/developer-guide/snowpark/reference/python/latest/api/snowflake.snowpark.Session
##
session = Session.builder.configs(SnowflakeLoginOptions()).create()
session.sql("""
CREATE OR REPLACE TABLE Gamma_Telescope_Data(
F_LENGTH FLOAT,
F_WIDTH FLOAT,
F_SIZE FLOAT,
F_CONC FLOAT,
F_CONC1 FLOAT,
F_ASYM FLOAT,
F_M3_LONG FLOAT,
F_M3_TRANS FLOAT,
F_ALPHA FLOAT,
F_DIST FLOAT,
CLASS VARCHAR(10))
""").collect()
session.sql("CREATE OR REPLACE STAGE SNOWPARK_ML_TEST_DATA_STAGE").collect()
session.file.put(
DATA_FILE_PATH,
"SNOWPARK_ML_TEST_DATA_STAGE/magic04.data",
auto_compress=False,
overwrite=True,
)
session.sql("""
COPY INTO Gamma_Telescope_Data FROM @SNOWPARK_ML_TEST_DATA_STAGE/magic04.data
FILE_FORMAT = (TYPE = 'CSV' field_optionally_enclosed_by='"',SKIP_HEADER = 0);
""").collect()
session.sql("select * from Gamma_Telescope_Data limit 5").collect()
データを読み込んだら、次のコードを使って、以下のステップでトレーニングと予測を行います。
データを前処理する:
欠損値を平均値で置き換える。
標準的なスケーラーを使用してデータを中央に配置する。
xgboost分類器でイベントのタイプを決定できるようにトレーニングする。
トレーニングデータセットとテストデータセットの両方でモデルの精度をテストする。
from snowflake.ml.utils.connection_params import SnowflakeLoginOptions
from snowflake.snowpark import Session, DataFrame
from snowflake.ml.modeling.preprocessing import StandardScaler
from snowflake.ml.modeling.impute import SimpleImputer
from snowflake.ml.modeling.pipeline import Pipeline
from snowflake.ml.modeling.xgboost import XGBClassifier
from snowflake.ml.modeling.metrics import accuracy_score
##
# Note: Create session https://docs.snowflake.com/en/developer-guide/snowpark/reference/python/latest/api/snowflake.snowpark.Session
##
session = Session.builder.configs(SnowflakeLoginOptions()).create()
# Step 1: Create train and test dataframes
all_data = session.sql("select *, IFF(CLASS = 'g', 1.0, 0.0) as LABEL from Gamma_Telescope_Data").drop("CLASS")
train_data, test_data = all_data.random_split(weights=[0.9, 0.1], seed=0)
# Step 2: Construct training pipeline with preprocessing and modeling steps
FEATURE_COLS = [c for c in train_data.columns if c != "LABEL"]
LABEL_COLS = ["LABEL"]
pipeline = Pipeline(steps = [
("impute", SimpleImputer(input_cols=FEATURE_COLS, output_cols=FEATURE_COLS)),
("scaler", StandardScaler(input_cols=FEATURE_COLS, output_cols=FEATURE_COLS)),
("model", XGBClassifier(input_cols=FEATURE_COLS, label_cols=LABEL_COLS))
])
# Step 3: Train
pipeline.fit(train_data)
# Step 4: Eval
predict_on_training_data = pipeline.predict(train_data)
training_accuracy = accuracy_score(df=predict_on_training_data, y_true_col_names=["LABEL"], y_pred_col_names=["OUTPUT_LABEL"])
predict_on_test_data = pipeline.predict(test_data)
eval_accuracy = accuracy_score(df=predict_on_test_data, y_true_col_names=["LABEL"], y_pred_col_names=["OUTPUT_LABEL"])
print(f"Training accuracy: {training_accuracy} \nEval accuracy: {eval_accuracy}")
分散ハイパーパラメーターの最適化¶
この例では、Snowflake のscikit-learnの GridSearchCV の実装を使用して、分散ハイパーパラメーターの最適化を実行する方法を示します。個々の実行は、分散ウェアハウスのコンピューティングリソースを使用して並列実行されます。分散ハイパーパラメーターの最適化の詳細については、 分散ハイパーパラメーターの最適化 をご参照ください。
from snowflake.snowpark import Session, DataFrame
from snowflake.ml.utils.connection_params import SnowflakeLoginOptions
from sklearn.datasets import make_classification
from snowflake.snowpark import Session, DataFrame
from snowflake.ml.modeling.xgboost import XGBClassifier
from snowflake.ml.modeling.model_selection.grid_search_cv import GridSearchCV
FEATURE_COLS = ["X1", "X2", "X3", "X4", "X5", "X6"]
LABEL_COLS = ["Y"]
OUTPUT_COLS = ["PREDICTIONS"]
# Create a session using your favorite login option.
# In this example we use a session builder with `SnowflakeLoginOptions`.
session = Session.builder.configs(SnowflakeLoginOptions()).create()
# Set up data.
def set_up_data(session: Session, n_samples: int) -> DataFrame:
X, y = make_classification(
n_samples=n_samples,
n_features=6,
n_informative=2,
n_redundant=0,
random_state=0,
shuffle=True,
)
X = pd.DataFrame(X, columns=FEATURE_COLS)
y = pd.DataFrame(y, columns=LABEL_COLS)
features_pandas = pd.concat([X, y], axis=1)
features_pandas.head()
features_df = session.create_dataframe(features_pandas)
return features_df
features_df = set_up_data(session, 10**4)
# Create a warehouse to use for the tuning job.
session.sql(
"""
CREATE or replace warehouse HYPERPARAM_WH
WITH WAREHOUSE_SIZE = 'X-SMALL'
WAREHOUSE_TYPE = 'Standard'
AUTO_SUSPEND = 60
AUTO_RESUME = TRUE
INITIALLY_SUSPENDED = FALSE;"""
).collect()
session.use_warehouse("HYPERPARAM_WH")
# Tune an XGB Classifier model using sklearn GridSearchCV.
DISTRIBUTIONS = dict(
n_estimators=[10, 50],
learning_rate=[0.01, 0.1, 0.2],
)
estimator = XGBClassifier()
grid_search_cv = GridSearchCV(estimator=estimator, param_grid=DISTRIBUTIONS, input_cols=FEATURE_COLS, label_cols=LABEL_COLS, output_cols=OUTPUT_COLS)
grid_search_cv.fit(features_df)
# Use the best model to make predictions.
predictions = grid_search_cv.predict(features_df)
predictions[OUTPUT_COLS].show()
# Retrieve sklearn model, and print the best score
sklearn_grid_search_cv = grid_search_cv.to_sklearn()
print(sklearn_grid_search_cv.best_score_)
分散最適化のパワーを実際に見るには、100万行のデータでトレーニングします。
large_features_df = set_up_data(session, 10**6)
# Scale up the warehouse for a faster fit. This takes 2m15s to run on an L warehouse versus 4m5s on a XS warehouse.
session.sql(f"ALTER WAREHOUSE {session.get_current_warehouse()} SET WAREHOUSE_SIZE='LARGE'").collect()
grid_search_cv.fit(large_features_df)
print(grid_search_cv.to_sklearn().best_score_)
Snowflake Modeling Classes¶
すべてのSnowflakeのモデリングクラスと前処理クラスは、 snowflake.ml.modeling 名前空間にあります。 snowflake-ml-python のモジュールは、 sklearn 名前空間の対応するモジュールと同じ名前です。たとえば、 sklearn.calibration に対応するモジュールは、 snowflake.ml.modeling.calibration です。 xgboost と lightgbm モジュールは、それぞれ snowflake.ml.modeling.xgboost と snowflake.ml.modeling.lightgbm に対応しています。
モデリング API は、基礎となるscikit-learn、xgboost、lightgbmクラスのラッパーを提供し、その大部分は仮想ウェアハウス内のストアドプロシージャ(単一のウェアハウスノードで実行)として実行されます。scikit-learnのすべてのクラスがサポートされているわけではありません。現在利用可能なクラスのリストについては、 Python API Reference をご参照ください。
一部のクラス(前処理やメトリクスクラスを含む)は分散実行をサポートしており、同じ操作をローカルで実行するのに比べて顕著なパフォーマンス上のメリットを提供する場合があります。詳細については、 分散前処理 および 分散ハイパーパラメーターの最適化 をご参照ください。以下のテーブルは、分散実行をサポートする特定のクラスを一覧表示したものです。
|
分散クラス |
|---|---|
|
|
|
|
|
|
|
|
一般的な API の違い¶
Tip
モデリング API の完全な詳細については、Snowpark API Reference をご参照ください。
Snowflake Modelingクラスには、scikit-learn、xgboost、lightgbmに基づくデータ前処理、変換、予測アルゴリズムが含まれています。Snowpark Pythonクラスは、オリジナルパッケージからの対応するクラスを置き換えたもので、署名も類似しています。ただし、これらの APIs は、 NumPy 配列の代わりに、Snowpark DataFrames で動作するように設計されています。
Snowpark Modeling API はscikit-learnに似ていますが、いくつかの重要な違いがあります。このセクションでは、Snowflakeで提供される推定器クラスと変換器クラスの __init__ (コンストラクター)、 fit、および predict メソッドを呼び出す方法について説明します。
すべてのSnowflake モデルクラスの コンストラクター は、scikit-learn、xgboost、lightgbmの同等クラスが受け入れるパラメーターに加えて、5つの追加パラメーター(
input_cols、output_cols、sample_weight_col、label_cols、およびdrop_input_cols)を受け入れます。これらは文字列または文字列のシーケンスで、SnowparkまたはPandas DataFrameの入力列、出力列、サンプル重み列、ラベル列の名前を指定します。使用するデータセットの名前が異なる場合は、インスタンス化後にset_input_colsのようなセッターメソッドを使って名前を変更することができます。クラスをインスタンス化するときに列名を指定する(あるいはその後でセッターメソッドを使用する)ため、
fitとpredictメソッドは、入力、重み、ラベルのための別々の配列ではなく、単一の DataFrame を受け入れます。提供された列名は、fitまたはpredictの DataFrame から適切な列にアクセスするために使用されます。 fit、および predict をご参照ください。デフォルトでは、
transformとpredictメソッドは、メソッドに渡された DataFrame のすべての列を含む DataFrame を返し、予測からの出力は追加の列に格納されます。入力列名と一致する出力列名を指定して、インプレースで変換することも、drop_input_cols = Trueを渡して、入力列をドロップすることもできます。)scikit-learn、xgboost、lightgbmと同等のものは、結果のみを含む配列を返します。Snowpark Pythonの変換器には
fit_transformメソッドがありません。しかし、scikit-learnと同様に、パラメーターの検証はfitメソッドでのみ実行されます。したがって、変換器がフィッティングを実行しない場合でも、transformの前のある時点でfitを呼び出す必要があります。fitは変換器を返すため、メソッド呼び出しは、たとえばBinarizer(threshold=0.5).fit(df).transform(df)のように連鎖させることができます。Snowflake トランスフォーマーには
inverse_transformメソッドがありません。多くの使用例では、入力列はデフォルトで出力データフレームに保持されるため、この方法は不要です。
任意のSnowpark Modelingオブジェクトを、対応するscikit-learn、xgboost、またはlightgbmオブジェクトに変換して、基礎となる型のすべてのメソッドと属性を使用できます。 基礎となるモデルの取得 をご参照ください。
モデルの構築¶
個別のscikit-learnモデルクラスが受け入れるパラメーターに加えて、すべてのモデリングクラスは、インスタンス化の際に次の追加パラメーターを受け入れます。
これらのパラメーターは技術的にはすべてオプションですが、 input_cols、または output_cols、あるいはその両方を指定する場合が多くあります。 label_cols と sample_weight_col は、テーブルに示す特定の状況では必須ですが、それ以外の場合では省略できます。
Tip
すべての列名は、Snowflakeの 識別子の要件 に従う必要があります。テーブル作成時に大文字と小文字を区別したり、特殊文字(ドル記号とアンダースコア以外)を使用したりする場合は、列名を二重引用符で囲む必要があります。大文字と小文字を区別するPandas DataFrames との互換性を維持するために、可能な限りすべて大文字の列名を使用します。
from snowflake.ml.modeling.preprocessing import MinMaxScaler
from snowflake.snowpark import Session
# Snowflake identifiers are not case sensitive by default.
# These column names will be automatically updated to ["COLUMN_1", "COLUMN_2", "COLUMN_3"] by the Snowpark DataFrame.
schema = ["column_1", "column_2", "column_3"]
df = session.create_dataframe([[1, 2, 3]], schema = schema)
df.show()
--------------------------------------
|"COLUMN_1" |"COLUMN_2" |"COLUMN_3"|
--------------------------------------
|1 |2 |3 |
--------------------------------------
# Identify the column names using the Snowflake identifier.
input_cols = ["COLUMN_1", "COLUMN_2", "COLUMN_3"]
mms = MinMaxScaler(input_cols=input_cols)
mms.fit(df)
# To maintain lower case column names, include a double quote within the string.
schema = ['"column_1"', '"column_2"', '"column_3"']
df = session.create_dataframe([[1, 2, 3]], schema = schema)
df.show()
----------------------------------------
|'"column_1"'|'"column_2"'|'"column_3"'|
----------------------------------------
|1 |2 |3 |
----------------------------------------
# Since no conversion took place, the schema labels can be used as the column identifiers.
mms = MinMaxScaler(input_cols=schema)
mms.fit(df)
パラメーター |
説明 |
|---|---|
|
特徴量を含む列名を表す文字列または文字列のリスト。 このパラメーターを省略した場合は、 |
|
ラベルを含む列の名前を表す文字列または文字列のリスト。 監視型推定器のラベル列は推論できないため、必ず指定する必要があります。これらのラベル列はモデル予測のターゲットとして使用され、 |
|
このパラメーターを省略した場合、出力列名は監視型推定器ではラベル列名に インプレースで変換するには、 |
|
トレーニング、変換、推論から除外する列の名前を示す文字列または文字列のリスト。パススルー列は、入力と出力 DataFrames の間にそのまま残ります。 このオプションは、トレーニングや推論時にインデックス列などの特定の列の使用を避けたい場合に便利ですが、 |
|
例の重みを含む列名を表す文字列。 この引数は,重み付きデータセットに必要です. |
|
入力列を結果 DataFrame から削除するかどうかを示すブール値。デフォルトは |
例¶
scikit-learnには、 DecisionTreeClassifier コンストラクターに必須の引数がありません。すべての引数はデフォルト値です。そのため、scikit-learnでは次のように記述する場合があります。
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
このクラスのSnowflakeのバージョンでは、列名を指定する必要があります(または、指定せずにデフォルトを受け入れます)。この例では、明示的に指定されています。
引数をコンストラクターに直接渡すか、インスタンス化後にモデルの属性として設定して、 DecisionTreeClassifier を初期化することができます。(属性はいつでも変更可能です。)
コンストラクターの引数として、
from snowflake.ml.modeling.tree import DecisionTreeClassifier model = DecisionTreeClassifier( input_cols=feature_column_names, label_cols=label_column_names, sample_weight_col=weight_column_name, output_cols=expected_output_column_names )
モデルの属性を設定することで、
from snowflake.ml.modeling.tree import DecisionTreeClassifier model = DecisionTreeClassifier() model.set_input_cols(feature_column_names) model.set_label_cols(label_column_names) model.set_sample_weight_col(weight_column_name) model.set_output_cols(output_column_names)
fit¶
Snowflake 分類器の fit メソッドは、特徴量、ラベル、重みを含むすべての列を含む単一の SnowparkまたはPandas DataFrame を受け取ります。これはscikit-learnが特徴量、ラベル、および重みを個別の入力として受け取る fit メソッドとは異なります。
scikit-learnでは、 DecisionTreeClassifier.fit メソッド呼び出しは次のようになります。
model.fit(
X=df[feature_column_names], y=df[label_column_names], sample_weight=df[weight_column_name]
)
Snowflakeの fit では、 DataFrame を渡すだけです。 モデルの構築 に示すように、入力、ラベル、重みの列名は、初期化時、またはセッターメソッドを使用してすでに設定されています。
model.fit(df)
predict¶
predict メソッドも、すべての特徴量列を含む単一のSnowparkまたはPandas DataFrame を受け取ります。結果は、入力 DataFrame のすべての列が変更されず、出力列が追加された DataFrame になります。この DataFrame から出力列を抽出する必要があります。これは、結果のみを返すscikit-learnの predict メソッドとは異なります。
例¶
scikit-learnでは、 predict は予測結果のみを返します。
prediction_results = model.predict(X=df[feature_column_names])
Snowflake`の predict の予測結果のみを取得するには、返された DataFrame から出力列を抽出します。ここで、 output_column_names は、出力列の名前を含むリストです。
prediction_results = model.predict(df)[output_column_names]
SPCS との分散トレーニングと推論¶
![]() プレビュー機能 --- オープン
プレビュー機能 --- オープン
すべてのアカウントで利用可能です。
Snowpark Container Services (SPCS) 上のSnowflake Notebookで実行する場合、これらのモデリングクラスのモデルトレーニングと推論は、ウェアハウスではなく、基礎となるコンピュートクラスタ上で実行され、クラスタ内のすべてのノードに透過的に分散され、利用可能なすべてのコンピュート能力を使用します。
前処理とメトリクスの操作はウェアハウスにプッシュダウンされます。多くの前処理クラスは、ウェアハウス内で実行される場合、分散実行をサポートします。 分散前処理 をご参照ください。
分散前処理¶
Snowflake のデータ前処理および変換関数の多くは、Snowflakeの分散実行エンジンを使用して実装されており、シングルノード実行(つまり、ストアドプロシージャ)と比較してパフォーマンスが大幅に改善されます。どの関数が分散実行をサポートしているかは、 Snowflake Modeling Classes をご参照ください。
下のグラフは、大規模なパブリックデータセットで、中程度のSnowparkに最適化されたウェアハウスで実行され、ストアドプロシージャで実行されるscikit-learnとSnowflake の分散実装を比較した、例示的なパフォーマンス数値を示したものです。多くのシナリオでは、Snowflake Modelingを使用すると、コードの実行が25~50倍速くなります。
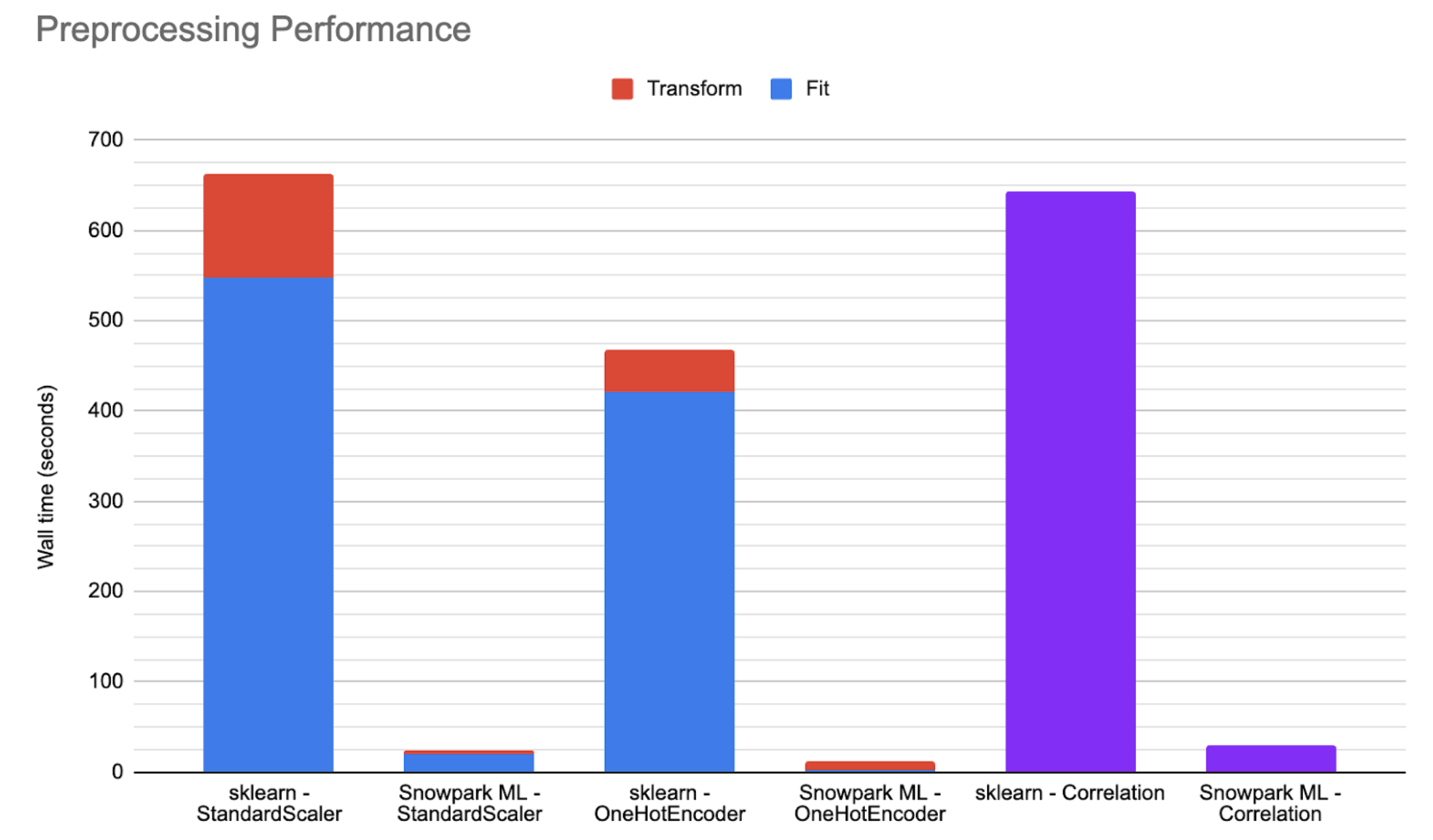
Fitの分配方法¶
Snowflake 前処理変換器の fit メソッドは、Snowparkまたはpandas DataFrame を受け取り、データセットをフィッティングし、フィッティング後の変換器を返します。
Snowpark DataFrames の場合、分散フィッティングは SQL エンジンを使用します。変換器は SQL クエリを生成して、必要な状態(平均、最大、カウントなど)を計算します。これらのクエリはSnowflakeによって実行され、結果はローカルで実体化されます。SQL で計算できない複雑な状態の場合、変換器はSnowflakeから中間結果をフェッチし、メタデータに対してローカル計算を実行します。
変換中に仮状態のテーブルを必要とする複雑な変換器(例:
OneHotEncoder、またはOrdinalEncoder)の場合、これらのテーブルはpandas DataFrames を使用してローカルに表現されます。pandas DataFrames は、scikit-learnによるフィッティングと同様に、ローカルでフィッティングされます。変換器は提供されたパラメーターを使って、対応するscikit-learn変換器を作成します。次に、scikit-learn変換器がフィッティングされ、Snowflake 変換器がscikit-learnオブジェクトから必要な状態を導出します。
Transformの分配方法¶
前処理変換器の transform メソッドは、SnowparkまたはPandas DataFrame を受け取り、データセットを変換し、変換後のデータセットを返します。
Snowpark DataFrames では、 SQL エンジンを使って分散変換が行われます。フィッティング後の変換器は、変換後のデータセットを表す基礎となる SQL クエリを持つSnowpark DataFrame を生成します。
transformメソッドは、単純な変換(StandardScalerやMinMaxScalerなど)に対して遅延評価を行うので、transformメソッドの間は実際には変換が行われません。しかし、ある種の複雑な変換には実行が伴います。これには、変換中に仮の状態テーブル(
OneHotEncoderやOrdinalEncoderなど)を必要とする変換器も含まれます。このような変換器の場合、結合やその他の操作のために、Pandas DataFrame(オブジェクトの状態を格納)から仮テーブルを作成します。さらに、特定のパラメーターが設定された時、たとえば、変換器が変換中に見つかった未知の値をエラーとして処理するように設定されている場合、列や未知の値などを含むデータを実体化します。
Pandas DataFrames は、scikit-learnによる変換と同様に、ローカルで変換されます。変換器は
to_sklearnAPI を使って、対応するscikit-learn変換器を作成し、メモリ内で変換を行います。
分散ハイパーパラメーターの最適化¶
ハイパーパラメーターチューニングは、データサイエンスのワークフローの不可欠な部分です。Snowflake API は、scikit-learn GridSearchCV と RandomizedSearchCV APIs の分散実装を提供し、シングルノードとマルチノードのウェアハウス両方で効率的なハイパーパラメーターチューニングを可能にします。
Tip
Snowflake は、デフォルトで分散ハイパーパラメーター最適化を有効にします。これを無効にするには、以下のPythonインポートを使用します。
import snowflake.ml.modeling.parameters.disable_distributed_hpo
最小のSnowflake仮想ウェアハウス(XS)またはSnowparkに最適化されたウェアハウス(M)にはノードが1つあります。サイズが大きくなる度にノード数は倍増します。
シングルノード(XS)のウェアハウスでは、scikit-learnのjoblibマルチプロセッシングフレームワークを使用して、デフォルトでノードの全容量が利用されます。
Tip
各フィット操作には、RAM に読み込まれたトレーニングデータセットのコピーが必要です。このような規模のデータセットを処理するには、分散ハイパーパラメータ最適化を無効にし(import snowflake.ml.modeling.parameters.disable_distributed_hpo)、 n_jobs パラメーターを1に設定して同時実行性を最小にします。
マルチノードのウェアハウスでは、クロスバリデーションチューニングジョブ内の fit 操作はノード間で分散されます。スケールアップのためのコード変更は必要ありません。推定器のフィッティングは、ウェアハウス内のすべてのノードの利用可能なすべてのコアで並列実行されます。
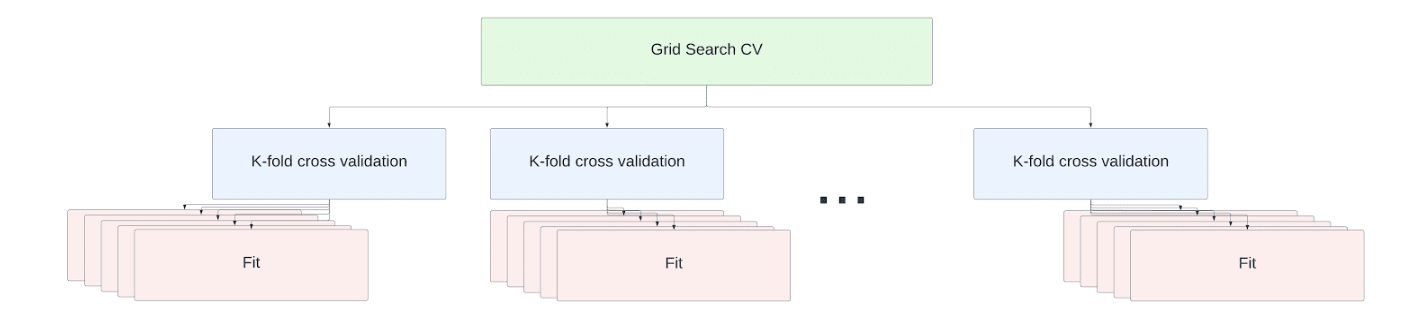
例として、scikit-learnライブラリで提供されている カリフォルニア住宅データセット を考えてみましょう。このデータには20,640行のデータがあり、以下の情報が含まれています。
MedInc: ブロックグループの所得の中央値
HouseAge: ブロックグループの住宅築年数の中央値
AveRooms: 世帯あたりの平均部屋数
AveBedrms: 世帯あたりの平均寝室数
人口: ブロックグループの人口
AveOccup: 平均世帯人数
緯度 および 経度。
データセットの対象は所得の中央値で、単位は十万ドルです。
この例では、所得中央値を予測するための最良のハイパーパラメーターの組み合わせを見つけるために、ランダムフォレスト回帰変数のグリッド探索クロスバリデーションを行います。
from snowflake.ml.modeling.ensemble.random_forest_regressor import RandomForestRegressor
from snowflake.ml.modeling.model_selection.grid_search_cv import GridSearchCV
from sklearn import datasets
def load_housing_data() -> DataFrame:
input_df_pandas = datasets.fetch_california_housing(as_frame=True).frame
# Set the columns to be upper case for consistency with Snowflake identifiers.
input_df_pandas.columns = [c.upper() for c in input_df_pandas.columns]
input_df = session.create_dataframe(input_df_pandas)
return input_df
input_df = load_housing_data()
# Use all the columns besides the median value as the features
input_cols = [c for c in input_df.columns if not c.startswith("MEDHOUSEVAL")]
# Set the target median value as the only label columns
label_cols = [c for c in input_df.columns if c.startswith("MEDHOUSEVAL")]
DISTRIBUTIONS = dict(
max_depth=[80, 90, 100, 110],
min_samples_leaf=[1,3,10],
min_samples_split=[1.0, 3,10],
n_estimators=[100,200,400]
)
estimator = RandomForestRegressor()
n_folds = 5
clf = GridSearchCV(estimator=estimator, param_grid=DISTRIBUTIONS, cv=n_folds, input_cols=input_cols, label_cols=label_col)
clf.fit(input_df)
この例は、Snowparkで最適化されたMedium(シングルノード)ウェアハウスでは7分強で実行され、X-Largeウェアハウスではわずか3分で実行されます。
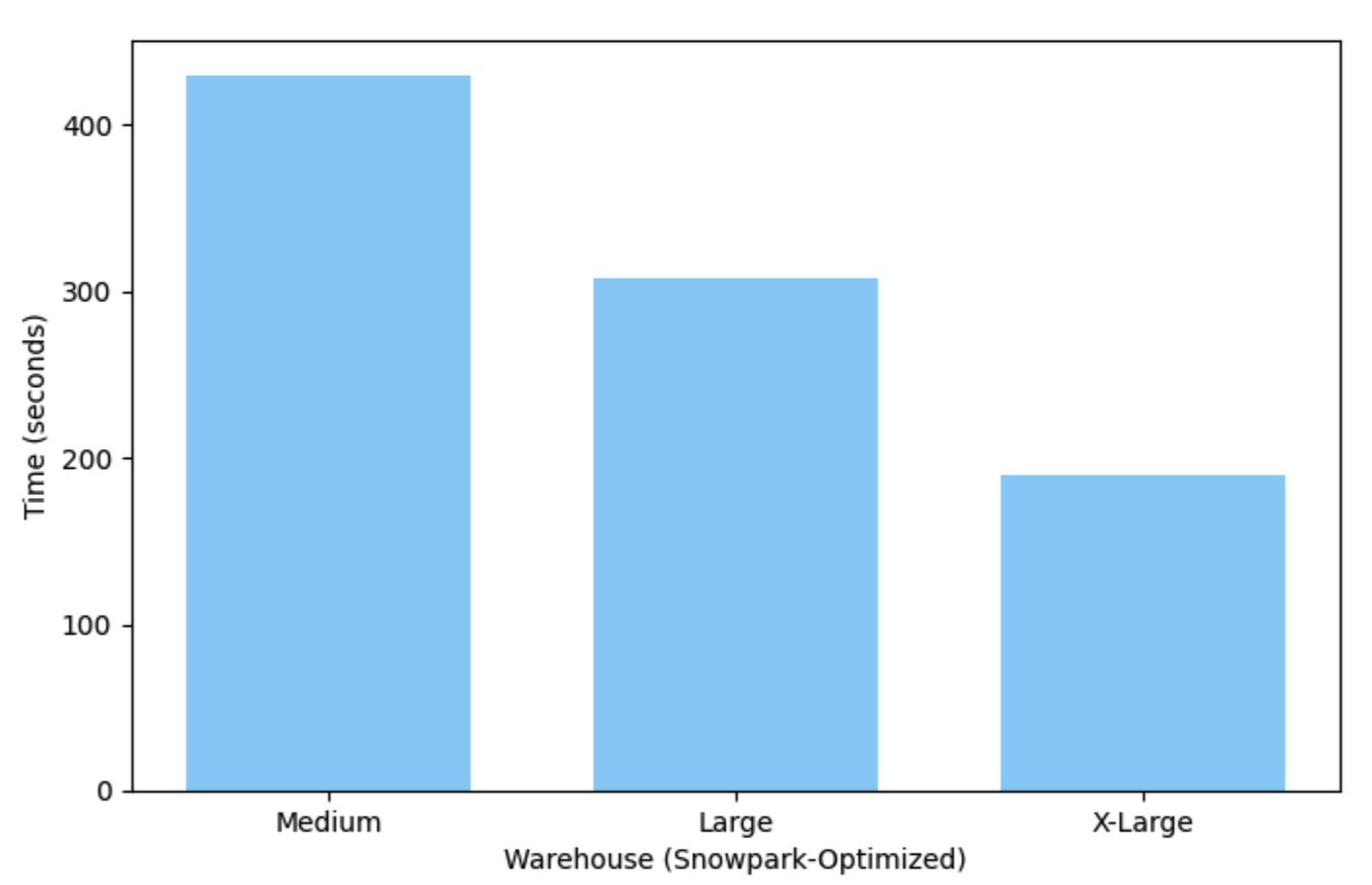
モデルの展開と実行¶
モデルをトレーニングした結果は、Python Snowparkモデルオブジェクトになります。モデルの predict メソッドを呼び出すと、トレーニング済みモデルを使用して予測できます。これにより、Snowflake仮想ウェアハウスでモデルを実行するための仮のユーザー定義関数が作成されます。この関数は、Snowflake セッションの終了時(例: スクリプトの終了時やJupyterノートブックを閉じるとき)に自動的に削除されます。
セッション終了後もユーザー定義関数を保持するには、手動で作成します。詳細については、このトピックの クイックスタート をご参照ください。
Snowflake モデルレジストリは、永続的なモデルもサポートし、モデルの検索と展開を容易にします。 Snowflakeモデルレジストリ をご参照ください。
パーティションカスタムモデル¶
モデルレジストリは、フィットと推論がパーティションの集合に対して並列に実行される特殊なカスタムモデルもサポートしています。これは、1つのデータセットから一度に多くのモデルを作成し、推論を即座に実行するパフォーマンスの高い方法です。詳細については、 Snowflake Model Registry: Partitioned Custom Models をご参照ください。
複数変換のためのパイプライン¶
scikit-learnでは、パイプラインを使用して一連の変換を実行するのが一般的です。scikit-learnパイプラインはSnowflakeクラスでは動作しないため、一連の変換を実行するために sklearn.pipeline.Pipeline のSnowflake バージョンを提供しています。このクラスは snowflake.ml.modeling.pipeline パッケージにあり、scikit-learnバージョンと同じように動作します。
基礎となるモデルの取得¶
Snowflake ML モデルは、以下の方法で「アンラップ」できます。これは、サードパーティの基礎となるモデルタイプに変換できるということです(ライブラリによって異なります)。
to_sklearnto_xgboostto_lightgbm
次に、基礎となるモデルのすべての属性とメソッドにアクセスし、推定器に対してローカルで実行することができます。たとえば、 GridSearchCV の例 では、最良のスコアを取得するために、グリッド探索推定器をscikit-learnオブジェクトに変換します。
best_score = grid_search_cv.to_sklearn().best_score_
既知の制限¶
Snowflake推定器および変換器は現在、スパース入力およびスパース応答をサポートしていません。スパースデータがある場合は、Snowflakeの推定器や変換器に渡す前に密な形式に変換します。
snowflake-ml-pythonパッケージは現在、マトリックスデータ型をサポートしていません。結果としてマトリックスを生成するような推定器や変換器に対する操作はすべて失敗します。結果データの行の順番が入力データの行の順番と一致することは保証されません。
Snowflake ML は、 pandas on Snowflake DataFrames をまだサポートしていません。Pandas on SnowflakeデータフレームをSnowparkデータフレームに変換し、Snowflakeモデリングクラスで使用します。次の例では、Snowflake テーブルから読み込んだ DataFrame を変換しています:
import modin.pandas as pd import snowflake.snowpark.modin.plugin from snowflake.ml.modeling.xgboost import XGBClassifier snowpark_pandas_df: modin.pandas.DataFrame = read_snowflake('MY_TABLE') # converting to Snowpark DataFrame adds an index column index_label_name = "_INDEX" snowpark_df = snowpark_pandas_df.to_snowpark(index=True, index_label=index_label_name) snowpark_df.show()
その結果、Snowpark DataFrame は以下のとおりです:
-------------------------------------------------- |"COLUMN_1" |"COLUMN_2" |"TARGET" | "_INDEX" | -------------------------------------------------- |1 |2 |3 |1 | --------------------------------------------------
DataFrame は、次のように XGBoost 分類器を訓練するために使用することができます。
# Identify the column names using the Snowflake identifier input_cols = ["COLUMN_1", "COLUMN_2", "COLUMN_3"] # Pass through the _INDEX column rather than using it for training xgb_clf = XGBClassifier(input_cols=input_cols, passthrough_cols=index_label_name, label_cols="TARGET") xgb_clf.fit(snowpark_df)
トラブルシューティング¶
ログへの詳細の追加¶
Snowflakeモデリング・ライブラリは、Snowpark Pythonのログを使用します。デフォルトでは snowflake-ml-python は INFO レベルのメッセージを標準出力にログします。より詳細なログを取得するには、 サポートされているレベル のいずれかに変更します。
DEBUG は最も詳細なログを生成します。ログレベルを DEBUG に設定するには、
import logging, sys
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
一般的な問題の解決策¶
次のテーブルで、Snowflake ML Modelingで起こりうる問題を解決するためのいくつかの提案を示します。
問題またはエラーメッセージ |
考えられる原因 |
解決策 |
|---|---|---|
「name x is not defined」などの NameError、 ImportError、または ModuleNotFoundError |
モジュール名またはクラス名に誤字があるか、Snowpark |
正しいモジュールとクラス名については、モデリングクラスのテーブルをご参照ください。 |
KeyError (「not in index」または「none of [Index[..]] are in [列]」) |
誤った列名。 |
列名をチェックして修正します。 |
SnowparkSQLException、「does not exist or not authorize」 |
テーブルが存在しないか、テーブルに対する十分な権限がない。 |
テーブルが存在し、ユーザーロールに権限があることを確認してください。 |
SnowparkSQLException、「invalid identifier PETALLENGTH」 |
誤った列の数(通常は列が欠落)。 |
モデルクラスの作成時に指定した列の数をチェックし、正しい数を渡していることを確認してください。 |
InvalidParameterError |
不適切な型または値がパラメーターとして渡された。 |
インタラクティブPythonセッションで |
TypeError、「unexpected keyword argument」 |
名前付き引数に誤字がある。 |
インタラクティブPythonセッションで |
ValueError、「array with 0 sample(s)」 |
渡されたデータセットが空。 |
データセットが空ではないことを確認してください。 |
SnowparkSQLException、「authentication token has expired」 |
セッションの有効期限が切れた。 |
Jupyterノートブックを使用している場合は、カーネルを再起動して新しいセッションを作成します。 |
「cannot convert string to float」などの ValueError |
データ型の不一致。 |
インタラクティブPythonセッションで |
SnowparkSQLException、「cannot create temporary table」 |
モデルクラスが、呼び出し元の権限で実行されないストアドプロシージャの内部で使用されている。 |
所有者権限ではなく、呼び出し元の権限でストアドプロシージャを作成します。 |
SnowparkSQLException、「function available memory exceeded」 |
データセットが標準ウェアハウスで5 GB を超えている。 |
Snowparkに最適化されたウェアハウス に切り替えます。 |
OSError、「no space left on device」 |
モデルは標準的なウェアハウスの約500 MB よりも大きい。 |
Snowparkに最適化されたウェアハウス に切り替えます。 |
互換性のないxgboostのバージョン、またはxgboostのインポート時のエラー |
依存関係を適切に処理できない |
エラーメッセージに従って、パッケージをアップグレードまたはダウングレードします。 |
|
異なる型のモデルでこれらのメソッドのいずれかを使おうとした。 |
scikit-learn ベースのモデルなどで |
armベースのMac(M1またはM2チップ)でJupyter notebookのカーネルがクラッシュする。「The Kernel crashed while executing code in the current cell or a previous cell.」 |
XGBoost または別のライブラリが不正なアーキテクチャでインストールされている。 |
|
「lightgbm.basic.LightGBMError: (0000) 機能名の特殊文字 JSON をサポートしません。」 |
LightGBM は、 |
Snowpark DataFramesの列名を変更してください。ほとんどの場合、英数字以外の文字をアンダースコアで置き換えれば十分です。以下のPythonヘルパー関数が有用かもしれません。 def fix_values(F, column):
return F.upper(F.regexp_replace(F.col(column), "[^a-zA-Z0-9]+", "_"))
|
参考文献¶
各ライブラリの機能に関する包括的な情報については、元のライブラリのドキュメントをご参照ください。
謝辞¶
このドキュメントの一部は、 BSD-3 「新規」または「改訂」ライセンスおよびCopyright © 2007-2023 The scikit-learn developersの下でライセンスされているScikit-learnのドキュメントに由来しています。All Rights Reserved.
このドキュメントの一部は、Apache License 2.0, January 2004およびCopyright © 2019で網羅されている XGboost に由来します。All Rights Reserved.
このドキュメントの一部は、 MIT によるライセンスおよびCopyright © Microsoft Corp.の LightGBM ドキュメントに由来します。All Rights Reserved.