AWS용 샘플 비동기 원격 서비스¶
이 항목에는 샘플 비동기 AWS Lambda Function(원격 서비스)이 포함됩니다. 1단계: Management Console에서 원격 서비스(AWS Lambda Function) 만들기 에 설명된 것과 같은 단계에 따라 이 샘플 함수를 만들 수 있습니다.
코드 개요¶
본 설명서의 이 섹션에서는 AWS에서 비동기 외부 함수를 만드는 방법에 대한 정보를 제공합니다. (첫 번째 비동기 외부 함수를 구현하기 전에 비동기 외부 함수의 개념적 개요 를 읽어볼 수 있습니다.)
AWS에서 비동기 원격 서비스는 다음 제한 사항을 극복해야 합니다.
HTTP POST와 GET은 별개의 요청이므로, 원격 서비스가 POST에 의해 실행된 워크플로에 대한 정보를 보관하여 나중에 GET 요청으로 상태를 쿼리할 수 있도록 해야 합니다.
일반적으로, 각각의 HTTP POST와 HTTP GET은 별개의 프로세스 또는 스레드에서 별개의 처리기 함수 인스턴스를 호출합니다. 별개의 인스턴스는 메모리를 공유하지 않습니다. GET 처리기가 상태 또는 처리된 데이터를 읽기 위해, GET 처리기는 AWS에서 사용할 수 있는 공유 저장소 리소스에 액세스해야 합니다.
POST 처리기가 초기 HTTP 202 응답 코드를 보내는 유일한 방법은 처리기의 실행을 종료하는
return문(또는 이와 동등한 문)을 통해 보내는 것입니다. 따라서 HTTP 202를 반환하기 전에 POST 처리기는 원격 서비스의 실제 데이터 처리 작업을 수행하기 위해 독립 프로세스(또는 스레드)를 시작해야 합니다. 이 독립적인 프로세스는 일반적으로 GET 처리기에 표시되는 저장소에 액세스해야 합니다.
비동기 원격 서비스가 이러한 제한을 극복하는 한 가지 방법은 3개의 프로세스(또는 스레드)와 공유 저장소를 사용하는 것입니다.
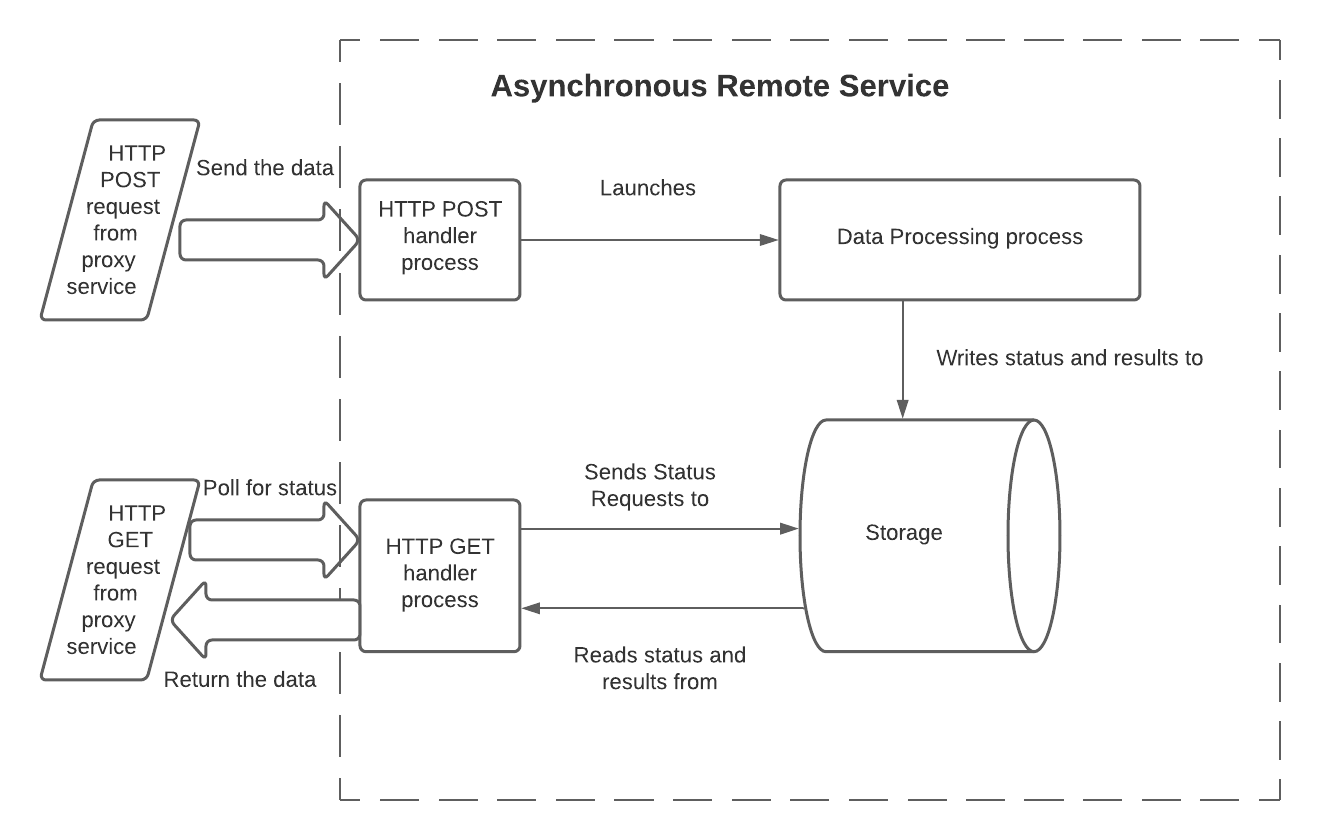
이 모델에서는 프로세스에 다음과 같은 책임이 있습니다.
HTTP POST 처리기는 다음을 수행합니다.
입력 데이터를 읽습니다. Lambda Function에서는 처리기 함수의
event입력 매개 변수의 본문에서 이 데이터를 읽습니다.배치 ID를 읽습니다. Lambda Function에서는
event입력 매개 변수의 헤더에서 읽습니다.데이터 처리 프로세스를 시작하고 데이터와 배치 ID를 전달합니다. 데이터는 보통 호출 중에 전달하지만, 외부 저장소에 작성하여 전달할 수 있습니다.
데이터 처리 프로세스와 HTTP GET 처리기 프로세스가 모두 액세스할 수 있는 공유 저장소에 배치 ID를 기록합니다.
필요한 경우 이 배치의 처리가 아직 완료되지 않았음을 기록합니다.
아무런 오류도 감지되지 않으면 HTTP 202를 반환합니다.
데이터 처리 코드는 다음을 수행합니다.
입력 데이터를 읽습니다.
데이터를 처리합니다.
(결과 데이터를 공유 저장소에 쓰거나 결과를 쿼리할 경로가 되는 API를 제공하여) GET 처리기에서 처리 결과를 사용할 수 있게 합니다.
일반적으로, 이 배치의 상태를 업데이트하여(예:
IN_PROGRESS에서SUCCESS로) 결과를 읽을 준비가 되었음을 나타냅니다.종료합니다. 선택적으로, 이 프로세스는 오류 표시기를 반환할 수 있습니다. Snowflake가 이를 직접 보는 것은 아니지만(Snowflake는 POST 처리기와 GET 처리기의 HTTP 반환 코드만 봄), 데이터 처리 프로세스에서 오류 표시기를 반환하면 디버깅 중에 도움이 될 수 있습니다.
GET 처리기는 다음을 수행합니다.
배치 ID를 읽습니다. Lambda Function에서는
event입력 매개 변수의 헤더에서 읽습니다.저장소를 읽어 이 배치의 현재 상태를 가져옵니다(예:
IN_PROGRESS또는SUCCESS).처리가 아직 진행 중이면 202를 반환합니다.
처리가 성공적으로 완료되면 다음을 수행합니다.
결과를 읽습니다.
저장소를 정리합니다.
HTTP 코드 200과 함께 결과를 반환합니다.
저장된 상태가 오류를 나타내는 경우에는 다음을 수행합니다.
저장소를 정리합니다.
오류 코드를 반환합니다.
여러 HTTP GET 요청이 전송될 만큼 처리 시간이 오래 걸리는 경우 한 배치에 대해 GET 처리기가 여러 번 호출될 수 있습니다.
이 모델에는 가능한 많은 변형이 있습니다. 예:
배치 ID와 상태는 POST 프로세스가 끝날 때가 아니라 데이터 처리 프로세스가 시작될 때 작성될 수 있습니다.
데이터 처리는 별개의 함수(예: 별개의 Lambda 함수) 또는 완전히 별개의 서비스에서 수행될 수 있습니다.
데이터 처리 코드는 꼭 공유 저장소에 작성할 필요는 없습니다. 대신, 처리한 데이터를 다른 방식으로 사용할 수 있습니다. 예를 들어, API는 배치 ID를 매개 변수로 받고 데이터를 반환할 수 있습니다.
구현 코드는 처리 시간이 너무 오래 걸리거나 실패할 가능성을 고려해야 하므로, 저장소 공간 낭비를 방지하기 위해 일부 결과를 정리해야 합니다.
저장소 메커니즘은 여러 프로세스(또는 스레드)에서 공유할 수 있어야 합니다. 가능한 저장소 메커니즘은 다음을 포함합니다.
다음과 같이 AWS에서 제공하는 저장소 메커니즘:
디스크 공간(예: Amazon EFS(Elastic File System)).
AWS를 통해 사용할 수 있는 로컬 데이터베이스 서버(예: Amazon DynamoDB).
AWS 외부에 있지만 AWS에서 액세스할 수 있는 저장소.
위 3개 프로세스 각각의 코드는 3개의 개별 Lambda Function(하나는 POST 처리기용, 하나는 데이터 처리 함수용, 하나는 GET 처리기용)로 작성하거나 다른 방식으로 호출할 수 있는 단일 함수로 작성할 수 있습니다.
아래 샘플 Python 코드는 POST, 데이터 처리, GET 프로세스에 대해 별도로 호출할 수 있는 단일 Lambda Function입니다.
샘플 코드¶
이 코드는 출력이 있는 샘플 쿼리를 보여줍니다. 이 예에서는 공유 저장소 메커니즘(DynamoDB) 또는 데이터 변환(감정 분석)이 아니라 세 가지 프로세스와 이들이 상호 작용하는 방식에 중점을 둡니다. 코드는 예시 저장소 메커니즘과 데이터 변환을 다른 것으로 쉽게 바꿀 수 있도록 구조화됩니다.
단순화를 위해 이 예는 다음과 같습니다.
몇 가지 중요한 값(예: AWS 리전)을 하드 코드합니다.
일부 리소스(예: Dynamo의 작업 테이블)가 있다고 가정합니다.
샘플 호출 및 출력¶
다음은 감정 분석 결과를 포함한 샘플 출력과 함께 비동기 외부 함수에 대한 샘플 호출입니다.
샘플 코드에 대한 참고 사항¶
데이터 처리 함수는 다음을 호출하여 불러옵니다.
InvocationType은 위와 같이 ‘Event’여야 하는데, 두 번째 프로세스(또는 스레드)가 비동기여야 하고
Event는invoke()메서드를 통해 사용할 수 있는 비차단 호출의 유일한 형식이기 때문입니다.데이터 처리 함수는 HTTP 200 코드를 반환합니다. 하지만 이 HTTP 200 코드는 Snowflake로 직접 반환되지 않습니다. Snowflake는 GET이 상태를 폴링하고 데이터 처리 함수가 이 배치를 성공적으로 처리 완료했음을 확인해야 HTTP 200을 봅니다.