Desenvolvimento do modelo Snowflake ML¶
Nota
A Snowflake ML Modeling API está disponível ao público em geral a partir da versão 1.1.1 do pacote snowflake-ml-python.
A Snowflake ML Modeling API usa estruturas Python familiares, como scikit-learn, LightGBM e XGBoost para pré-processamento de dados, engenharia de recurso e modelos de treinamento dentro do Snowflake.
Os benefícios do desenvolvimento de modelos com a Snowflake ML Modeling incluem:
Engenharia de recursos e pré-processamento: melhore o desempenho e a escalabilidade com execução distribuída para funções de pré-processamento do scikit-learn usadas com frequência.
Treinamento de modelo: acelere o treinamento para modelos scikit-learn, XGBoost e LightGBM sem a necessidade de criar manualmente procedimentos armazenados ou funções definidas pelo usuário (UDFs), aproveitando a otimização de hiperparâmetros distribuídos.
Dica
Consulte Introdução ao aprendizado de máquina para um exemplo de um fluxo de trabalho de ML de ponta a ponta, incluindo a API de modelagem.
Nota
Este tópico pressupõe que snowflake-ml-python e suas dependências de modelagem já estejam instaladas. Consulte Como usar o Snowflake ML localmente.
Desenvolvimento de modelos¶
Com o Container Runtime para ML, disponível nos Notebooks no Container Runtime, é possível usar pacotes de ML populares de código aberto com seus dados Snowflake, aproveitando um ou mais nós de GPU, dentro da nuvem do Snowflake, garantindo segurança e governança para todo o fluxo de trabalho do ML. As APIs de carregamento de dados e treinamento inclusas são distribuídas automaticamente por todas as CPUs ou GPUs disponíveis em um nó, acelerando o treinamento do modelo com grandes conjuntos de dados.
Para obter mais informações, consulte Introdução ao Container Runtime dos notebooks Snowflake, que apresenta um fluxo de trabalho de ML simples aproveitando os recursos do Container Runtime para ML.
Junto com a flexibilidade e o poder do Container Runtime para ML, a Snowflake ML Modeling API fornece estimadores e transformadores que têm APIs semelhantes aos das bibliotecas scikit-learn, xgboost e lightgbm. É possível usar essas APIs para criar e treinar modelos de aprendizado de máquina que podem ser usados com o Snowflake ML Operations, como o Snowpark Model Registry.
Exemplos¶
Revise os exemplos a seguir para ter uma ideia das semelhanças da Snowflake Modeling API com as bibliotecas de aprendizado de máquina com as quais você pode estar familiarizado.
Pré-processamento¶
Este exemplo ilustra o uso das funções de pré-processamento e transformação de dados da Snowflake Modeling. As duas funções de pré-processamento usadas no exemplo (MixMaxScaler e OrdinalEncoder) usam o mecanismo de processamento distribuído do Snowflake para fornecer melhorias significativas de desempenho em relação às implementações do lado do cliente ou de procedimentos armazenados. Para obter mais detalhes, consulte Pré-processamento distribuído.
import numpy as np
import pandas as pd
import random
import string
from sklearn.datasets import make_regression
from snowflake.ml.modeling.preprocessing import MinMaxScaler, OrdinalEncoder
from snowflake.ml.modeling.pipeline import Pipeline
from snowflake.snowpark import Session
# Create a session with your preferred method
# session =
NUMERICAL_COLS = ["X1", "X2", "X3"]
CATEGORICAL_COLS = ["C1", "C2", "C3"]
FEATURE_COLS = NUMERICAL_COLS + CATEGORICAL_COLS
CATEGORICAL_OUTPUT_COLS = ["C1_OUT", "C2_OUT", "C3_OUT"]
FEATURE_OUTPUT_COLS = ["X1_FEAT_OUT", "X2_FEAT_OUT", "X3_FEAT_OUT", "C1_FEAT_OUT", "C2_FEAT_OUT", "C3_FEAT_OUT"]
# Create a dataset with numerical and categorical features
X, _ = make_regression(
n_samples=1000,
n_features=3,
noise=0.1,
random_state=0,
)
X = pd.DataFrame(X, columns=NUMERICAL_COLS)
def generate_random_string(length):
return "".join(random.choices(string.ascii_uppercase, k=length))
categorical_feature_length = 2
categorical_features = {}
for c in CATEGORICAL_COLS:
categorical_column = [generate_random_string(categorical_feature_length) for _ in range(X.shape[0])]
categorical_features[c] = categorical_column
X = X.assign(**categorical_features)
features_df = session.create_dataframe(X)
# Fit a pipeline with OrdinalEncoder and MinMaxScaler on Snowflake
pipeline = Pipeline(
steps=[
(
"OE",
OrdinalEncoder(
input_cols=CATEGORICAL_COLS,
output_cols=CATEGORICAL_OUTPUT_COLS,
)
),
(
"MMS",
MinMaxScaler(
input_cols=NUMERICAL_COLS + CATEGORICAL_OUTPUT_COLS,
output_cols=FEATURE_OUTPUT_COLS,
)
),
]
)
pipeline.fit(features_df)
# Use the pipeline to transform a dataset.
result = pipeline.transform(features_df)
Carregamento de dados¶
![]() Recurso em versão preliminar — Aberto
Recurso em versão preliminar — Aberto
Disponível para todas as contas.
Este exemplo mostra como carregar dados de uma tabela Snowflake para um DataFrame pandas ou conjunto de dados pytorch usando a API DataConnector, que distribui a ingestão de dados em vários núcleos ou GPUs para acelerar o carregamento.
Nota
A API DataConnector está disponível no Container Runtime para ML e pode ser usada em notebooks Snowsight em execução no Snowpark Container Services (SPCS).
from snowflake.ml.data.data_connector import DataConnector
# Retrieve data from a snowflake table
table_name = 'LARGE_TABLE_MULTIPLE_GBs'
snowpark_df = session.table(table_name)
# Materialize it into a pandas dataframe using DataConnector
pandas_df = DataConnector.from_dataframe(snowpark_df).to_pandas()
# Materialize it into a pytroch dataset using DataConnector
torch_dataset = data.to_torch_dataset(batch_size=1024)
Treinamento¶
Este exemplo mostra como treinar um modelo simples de classificador xgboost usando a Snowflake ML Modeling e, em seguida, executar previsões. A API é semelhante ao xgboost aqui, com apenas algumas diferenças em como as colunas são especificadas. Para obter detalhes sobre essas diferenças, consulte Diferenças gerais da API.
import pandas as pd
from sklearn.datasets import make_classification
from snowflake.ml.modeling.xgboost import XGBClassifier
from snowflake.ml.utils.connection_params import SnowflakeLoginOptions
from snowflake.snowpark import Session
# Create a session with your preferred method
# session =
FEATURE_COLS = ["X1", "X2", "X3", "X4", "X5", "X6"]
LABEL_COLS = ["Y"]
OUTPUT_COLS = ["PREDICTIONS"]
# Set up data.
X, y = make_classification(
n_samples=40000,
n_features=6,
n_informative=4,
n_redundant=1,
random_state=0,
shuffle=True,
)
X = pd.DataFrame(X, columns=FEATURE_COLS)
y = pd.DataFrame(y, columns=LABEL_COLS)
features_pandas = pd.concat([X, y], axis=1)
features_df = session.create_dataframe(features_pandas)
# Train an XGBoost model on snowflake.
xgboost_model = XGBClassifier(
input_cols=FEATURE_COLS,
label_cols=LABEL_COLS,
output_cols=OUTPUT_COLS
)
xgboost_model.fit(features_df)
# Use the model to make predictions.
predictions = xgboost_model.predict(features_df)
predictions[OUTPUT_COLS].show()
Pré-processamento de recursos e treinamento em dados não sintéticos¶
Este exemplo usa dados de partículas gama de alta energia de um telescópio atmosférico Cherenkov baseado em terra. O telescópio observa partículas gama de alta energia, aproveitando a radiação emitida pelas partículas carregadas produzidas nas chuvas eletromagnéticas iniciadas pelos raios gama. O detector registra a radiação Cherenkov (de comprimentos de onda visíveis a ultravioleta) que vaza pela atmosfera, permitindo a reconstrução dos parâmetros da chuva gama. O telescópio também detecta raios hádrons que são abundantes em chuvas cósmicas e produzem sinais que imitam os raios gama.
O objetivo é desenvolver um modelo de classificação para distinguir entre raios gama e raios hádrons. O modelo permite que os cientistas filtrem o ruído de fundo e se concentrem nos sinais genuínos de raios gama. Os raios gama permitem aos cientistas observar eventos cósmicos como o nascimento e a morte de estrelas, explosões cósmicas e o comportamento da matéria em condições extremas.
Os dados das partículas estão disponíveis para download no MAGIC Gamma Telescope. Baixe e descompacte os dados, defina a variável DATA_FILE_PATH para apontar para o arquivo de dados e execute o código abaixo para carregá-lo no Snowflake.
DATA_FILE_PATH = "~/Downloads/magic+gamma+telescope/magic04.data"
# Setup
from snowflake.ml.utils.connection_params import SnowflakeLoginOptions
from snowflake.snowpark import Session
import posixpath
import os
##
# Note: Create session https://docs.snowflake.com/en/developer-guide/snowpark/reference/python/latest/api/snowflake.snowpark.Session
##
session = Session.builder.configs(SnowflakeLoginOptions()).create()
session.sql("""
CREATE OR REPLACE TABLE Gamma_Telescope_Data(
F_LENGTH FLOAT,
F_WIDTH FLOAT,
F_SIZE FLOAT,
F_CONC FLOAT,
F_CONC1 FLOAT,
F_ASYM FLOAT,
F_M3_LONG FLOAT,
F_M3_TRANS FLOAT,
F_ALPHA FLOAT,
F_DIST FLOAT,
CLASS VARCHAR(10))
""").collect()
session.sql("CREATE OR REPLACE STAGE SNOWPARK_ML_TEST_DATA_STAGE").collect()
session.file.put(
DATA_FILE_PATH,
"SNOWPARK_ML_TEST_DATA_STAGE/magic04.data",
auto_compress=False,
overwrite=True,
)
session.sql("""
COPY INTO Gamma_Telescope_Data FROM @SNOWPARK_ML_TEST_DATA_STAGE/magic04.data
FILE_FORMAT = (TYPE = 'CSV' field_optionally_enclosed_by='"',SKIP_HEADER = 0);
""").collect()
session.sql("select * from Gamma_Telescope_Data limit 5").collect()
Depois de carregar os dados, use o código a seguir para treinar e prever, usando as etapas a seguir.
Pré-processamento os dados:
Substitua os valores ausentes pela média.
Centralize os dados usando um escalonador padrão.
Treine um classificador xgboost para determinar o tipo de eventos.
Teste a precisão do modelo em conjuntos de dados de treinamento e teste.
from snowflake.ml.utils.connection_params import SnowflakeLoginOptions
from snowflake.snowpark import Session, DataFrame
from snowflake.ml.modeling.preprocessing import StandardScaler
from snowflake.ml.modeling.impute import SimpleImputer
from snowflake.ml.modeling.pipeline import Pipeline
from snowflake.ml.modeling.xgboost import XGBClassifier
from snowflake.ml.modeling.metrics import accuracy_score
##
# Note: Create session https://docs.snowflake.com/en/developer-guide/snowpark/reference/python/latest/api/snowflake.snowpark.Session
##
session = Session.builder.configs(SnowflakeLoginOptions()).create()
# Step 1: Create train and test dataframes
all_data = session.sql("select *, IFF(CLASS = 'g', 1.0, 0.0) as LABEL from Gamma_Telescope_Data").drop("CLASS")
train_data, test_data = all_data.random_split(weights=[0.9, 0.1], seed=0)
# Step 2: Construct training pipeline with preprocessing and modeling steps
FEATURE_COLS = [c for c in train_data.columns if c != "LABEL"]
LABEL_COLS = ["LABEL"]
pipeline = Pipeline(steps = [
("impute", SimpleImputer(input_cols=FEATURE_COLS, output_cols=FEATURE_COLS)),
("scaler", StandardScaler(input_cols=FEATURE_COLS, output_cols=FEATURE_COLS)),
("model", XGBClassifier(input_cols=FEATURE_COLS, label_cols=LABEL_COLS))
])
# Step 3: Train
pipeline.fit(train_data)
# Step 4: Eval
predict_on_training_data = pipeline.predict(train_data)
training_accuracy = accuracy_score(df=predict_on_training_data, y_true_col_names=["LABEL"], y_pred_col_names=["OUTPUT_LABEL"])
predict_on_test_data = pipeline.predict(test_data)
eval_accuracy = accuracy_score(df=predict_on_test_data, y_true_col_names=["LABEL"], y_pred_col_names=["OUTPUT_LABEL"])
print(f"Training accuracy: {training_accuracy} \nEval accuracy: {eval_accuracy}")
Otimização de hiperparâmetros distribuídos¶
Este exemplo mostra como executar a otimização de hiperparâmetros distribuídos usando a implementação do GridSearchCV do scikit-learn do Snowflake. As execuções individuais são executadas em paralelo usando recursos de computação de warehouse distribuídos. Para obter detalhes sobre otimização de hiperparâmetros distribuídos, consulte Otimização de hiperparâmetros distribuídos.
from snowflake.snowpark import Session, DataFrame
from snowflake.ml.utils.connection_params import SnowflakeLoginOptions
from sklearn.datasets import make_classification
from snowflake.snowpark import Session, DataFrame
from snowflake.ml.modeling.xgboost import XGBClassifier
from snowflake.ml.modeling.model_selection.grid_search_cv import GridSearchCV
FEATURE_COLS = ["X1", "X2", "X3", "X4", "X5", "X6"]
LABEL_COLS = ["Y"]
OUTPUT_COLS = ["PREDICTIONS"]
# Create a session using your favorite login option.
# In this example we use a session builder with `SnowflakeLoginOptions`.
session = Session.builder.configs(SnowflakeLoginOptions()).create()
# Set up data.
def set_up_data(session: Session, n_samples: int) -> DataFrame:
X, y = make_classification(
n_samples=n_samples,
n_features=6,
n_informative=2,
n_redundant=0,
random_state=0,
shuffle=True,
)
X = pd.DataFrame(X, columns=FEATURE_COLS)
y = pd.DataFrame(y, columns=LABEL_COLS)
features_pandas = pd.concat([X, y], axis=1)
features_pandas.head()
features_df = session.create_dataframe(features_pandas)
return features_df
features_df = set_up_data(session, 10**4)
# Create a warehouse to use for the tuning job.
session.sql(
"""
CREATE or replace warehouse HYPERPARAM_WH
WITH WAREHOUSE_SIZE = 'X-SMALL'
WAREHOUSE_TYPE = 'Standard'
AUTO_SUSPEND = 60
AUTO_RESUME = TRUE
INITIALLY_SUSPENDED = FALSE;"""
).collect()
session.use_warehouse("HYPERPARAM_WH")
# Tune an XGB Classifier model using sklearn GridSearchCV.
DISTRIBUTIONS = dict(
n_estimators=[10, 50],
learning_rate=[0.01, 0.1, 0.2],
)
estimator = XGBClassifier()
grid_search_cv = GridSearchCV(estimator=estimator, param_grid=DISTRIBUTIONS, input_cols=FEATURE_COLS, label_cols=LABEL_COLS, output_cols=OUTPUT_COLS)
grid_search_cv.fit(features_df)
# Use the best model to make predictions.
predictions = grid_search_cv.predict(features_df)
predictions[OUTPUT_COLS].show()
# Retrieve sklearn model, and print the best score
sklearn_grid_search_cv = grid_search_cv.to_sklearn()
print(sklearn_grid_search_cv.best_score_)
Para realmente ver o poder da otimização distribuída, treine em um milhão de linhas de dados.
large_features_df = set_up_data(session, 10**6)
# Scale up the warehouse for a faster fit. This takes 2m15s to run on an L warehouse versus 4m5s on a XS warehouse.
session.sql(f"ALTER WAREHOUSE {session.get_current_warehouse()} SET WAREHOUSE_SIZE='LARGE'").collect()
grid_search_cv.fit(large_features_df)
print(grid_search_cv.to_sklearn().best_score_)
Classes Snowflake Modeling¶
Todas as classes de modelagem e pré-processamento do Snowflake estão no namespace snowflake.ml.modeling. Os módulos snowflake-ml-python têm o mesmo nome que os módulos correspondentes do namespace sklearn. Por exemplo, o módulo correspondente a sklearn.calibration é snowflake.ml.modeling.calibration. O módulos xgboost e lightgbm correspondem a snowflake.ml.modeling.xgboost e snowflake.ml.modeling.lightgbm, respectivamente.
A API de modelagem fornece wrappers para classes scikit-learn, xgboost e lightgbm subjacentes, a maioria das quais são executadas como procedimentos armazenados (executados em um único nó de warehouse) no warehouse virtual. Nem todas as classes do scikit-learn são compatíveis. Consulte a Referência da API Python para obter uma lista das classes disponíveis atualmente.
Algumas classes (incluindo classes de pré-processamento e métricas) suportam a execução distribuída e podem fornecer benefícios significativos de desempenho em comparação com a execução local das mesmas operações. Para obter mais informações, consulte Pré-processamento distribuído e Otimização de hiperparâmetros distribuídos. A tabela abaixo lista as classes específicas que oferecem suporte à execução distribuída.
Nome do módulo |
Classes distribuídas |
|---|---|
|
|
|
|
|
|
|
|
Diferenças gerais da API¶
Dica
Consulte a Referência da API para obter detalhes completos da API de modelagem.
As classes de modelagem do Snowflake incluem algoritmos de pré-processamento, transformação e previsão de dados baseados em scikit-learn, xgboost e lightgbm. As classes Snowpark Python são substituições para as classes correspondentes dos pacotes originais, com assinaturas semelhantes. No entanto, estas APIs são projetadas para funcionar com o Snowpark DataFrames em vez das matrizes NumPy.
Embora a API seja semelhante ao scikit-learn, existem algumas diferenças importantes. Esta seção explica como chamar os métodos __init__ (construtor), fit e predict para as classes estimadoras e transformadoras do Snowflake.
O construtor de todas as classes do modelo Snowflake aceita cinco parâmetros adicionais (
input_cols,output_cols,sample_weight_col,label_colsedrop_input_cols) além dos parâmetros aceitos pelas classes equivalentes em scikit-learn, xgboost ou lightgbm. São cadeias de caracteres, ou sequências de cadeias de caracteres, que especificam os nomes das colunas de entrada, colunas de saída, coluna de peso de amostra e colunas de rótulo em um DataFrame do Snowpark ou Pandas. Se alguns dos conjuntos de dados que você usa tiverem nomes diferentes, você pode alterar esses nomes após a instanciação usando um dos métodos setter fornecidos, comoset_input_cols.Como você especifica nomes de colunas ao instanciar a classe (ou depois, usando métodos setter), os métodos
fitepredictaceitam um único DataFrame em vez de matrizes separadas para entradas, pesos e rótulos. Os nomes das colunas fornecidos são usados para acessar a coluna apropriada do DataFrame emfitoupredict. Consulte fit e predict.Por padrão, os métodos
transformepredictretornam um DataFrame com todas as colunas do DataFrame passado ao método, com a saída da previsão armazenada em colunas adicionais. Você pode transformar no local especificando os nomes das colunas de saída que correspondem aos nomes das colunas de entrada ou descartar as colunas de entrada passandodrop_input_cols = True.) Os equivalentes scikit-learn, xgboost e lightgbm retornam matrizes contendo apenas os resultados.Os transformadores Snowpark Python não têm um método
fit_transform. No entanto, como no scikit-learn, a validação de parâmetros é realizada apenas no métodofit, então você deve chamarfitem algum momento antes detransform, mesmo quando o transformador não tem nenhum encaixe.fitretorna o transformador, então as chamadas de método podem ser encadeadas; por exemplo,Binarizer(threshold=0.5).fit(df).transform(df).Atualmente, os transformadores Snowflake não têm um método
inverse_transform. Em muitos casos de uso, esse método é desnecessário porque as colunas de entrada são retidas no dataframe de saída por padrão.
É possível converter qualquer objeto de modelagem Snowflake no objeto scikit-learn, xgboost ou lightgbm correspondente, permitindo que você use todos os métodos e atributos do tipo subjacente. Consulte Recuperação do modelo subjacente.
Criação de um modelo¶
Além dos parâmetros aceitos por classes individuais do modelo scikit-learn, todas as classes de modelagem aceitam os seguintes parâmetros adicionais na instanciação.
Esses parâmetros são todos tecnicamente opcionais, mas muitas vezes você desejará especificar input_cols, output_cols ou ambos. label_cols e sample_weight_col são obrigatórios em situações específicas indicadas na tabela, mas podem ser omitidos em outros casos.
Dica
Todos os nomes de colunas devem seguir os requisitos de identificador do Snowflake. Para preservar maiúsculas e minúsculas ou usar caracteres especiais (além do cifrão e do sublinhado) ao criar uma tabela, os nomes das colunas devem ser colocados entre aspas duplas. Use nomes de colunas em letras maiúsculas sempre que possível para manter a compatibilidade com Pandas DataFrames que diferencia maiúsculas de minúsculas.
from snowflake.ml.modeling.preprocessing import MinMaxScaler
from snowflake.snowpark import Session
# Snowflake identifiers are not case sensitive by default.
# These column names will be automatically updated to ["COLUMN_1", "COLUMN_2", "COLUMN_3"] by the Snowpark DataFrame.
schema = ["column_1", "column_2", "column_3"]
df = session.create_dataframe([[1, 2, 3]], schema = schema)
df.show()
--------------------------------------
|"COLUMN_1" |"COLUMN_2" |"COLUMN_3"|
--------------------------------------
|1 |2 |3 |
--------------------------------------
# Identify the column names using the Snowflake identifier.
input_cols = ["COLUMN_1", "COLUMN_2", "COLUMN_3"]
mms = MinMaxScaler(input_cols=input_cols)
mms.fit(df)
# To maintain lower case column names, include a double quote within the string.
schema = ['"column_1"', '"column_2"', '"column_3"']
df = session.create_dataframe([[1, 2, 3]], schema = schema)
df.show()
----------------------------------------
|'"column_1"'|'"column_2"'|'"column_3"'|
----------------------------------------
|1 |2 |3 |
----------------------------------------
# Since no conversion took place, the schema labels can be used as the column identifiers.
mms = MinMaxScaler(input_cols=schema)
mms.fit(df)
Parâmetro |
Descrição |
|---|---|
|
Uma cadeia de caracteres ou lista de cadeias de caracteres que representam nomes de colunas que contêm recursos. Se você omitir este parâmetro, todas as colunas no DataFrame de entrada, exceto as colunas especificadas pelos parâmetros |
|
Uma cadeia de caracteres ou lista de cadeia de caracteres que representa os nomes das colunas que contêm rótulos. Você deve especificar colunas de rótulos para estimadores supervisionados porque não é possível inferir essas colunas. Essas colunas de rótulos são usadas como destinos para previsões de modelo e devem ser claramente diferenciadas de |
|
Uma cadeia de caracteres ou lista de cadeia de caracteres que representa os nomes de colunas que armazenarão a saída das operações Se você omitir esse parâmetro, os nomes das colunas de saída serão derivados adicionando um prefixo Para transformar no local, passe os mesmos nomes para |
|
Uma cadeia de caracteres ou uma lista de cadeia de caracteres indicando nomes de colunas a serem excluídas do treinamento, transformação e inferência. As colunas de passagem permanecem inalteradas entre DataFrames de entrada e saída. Esta opção é útil quando você deseja evitar o uso de colunas específicas, como colunas de índice, durante o treinamento ou inferência, mas não passa |
|
Uma cadeia de caracteres representando o nome da coluna contendo os pesos dos exemplos. Este argumento é necessário para conjuntos de dados ponderados. |
|
Um valor booleano que indica se as colunas de entrada são removidas do DataFrame de resultado. O padrão é |
Exemplo¶
O construtor DecisionTreeClassifier não possui nenhum argumento necessário no scikit-learn; todos os argumentos têm valores padrão. Portanto, no scikit-learn, você pode escrever:
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
Na versão desta classe do Snowflake, você deve especificar os nomes das colunas (ou aceitar os padrões deixando de especificá-los). Neste exemplo, eles são especificados explicitamente.
É possível inicializar um DecisionTreeClassifier passando os argumentos diretamente para o construtor ou configurando-os como atributos do modelo após a instanciação. (Os atributos podem ser alterados a qualquer momento.)
Como argumentos do construtor:
from snowflake.ml.modeling.tree import DecisionTreeClassifier model = DecisionTreeClassifier( input_cols=feature_column_names, label_cols=label_column_names, sample_weight_col=weight_column_name, output_cols=expected_output_column_names )
Definindo os atributos do modelo:
from snowflake.ml.modeling.tree import DecisionTreeClassifier model = DecisionTreeClassifier() model.set_input_cols(feature_column_names) model.set_label_cols(label_column_names) model.set_sample_weight_col(weight_column_name) model.set_output_cols(output_column_names)
fit¶
O método fit de um classificador Snowflake usa um único DataFrame Snowpark ou pandas com todas as colunas, incluindo recursos, rótulos e pesos. Isso é diferente do método fit do scikit-learn, que usa entradas separadas para recursos, rótulos e pesos.
No scikit-learn, a chamada do método DecisionTreeClassifier.fit fica assim:
model.fit(
X=df[feature_column_names], y=df[label_column_names], sample_weight=df[weight_column_name]
)
No fit do Snowflake, só é necessário passar o DataFrame. Você já definiu os nomes de coluna de entrada, rótulo e peso na inicialização ou usando métodos setter, conforme mostrado em Criação de um modelo.
model.fit(df)
predict¶
O método predict também usa um único DataFrame Snowpark ou pandas com todas as colunas de recurso. O resultado é um DataFrame que contém todas as colunas no DataFrame de entrada inalterado e as colunas de saída anexadas. Você deve extrair as colunas de saída deste DataFrame. Isso é diferente do predict no scikit-learn, que retorna apenas os resultados.
Exemplo¶
No scikit-learn, predict retorna apenas os resultados da previsão:
prediction_results = model.predict(X=df[feature_column_names])
Para obter apenas os resultados da previsão no predict Snowflake, extraia as colunas de saída do DataFrame retornado. Aqui, output_column_names é uma lista contendo os nomes das colunas de saída:
prediction_results = model.predict(df)[output_column_names]
Treinamento distribuído e inferência com SPCS¶
![]() Recurso em versão preliminar — Aberto
Recurso em versão preliminar — Aberto
Disponível para todas as contas.
Ao executar em um notebook Snowflake no Snowpark Container Services (SPCS), o treinamento e a inferência do modelo para essas classes de modelagem são executados no cluster de computação subjacente, não em um warehouse, e são distribuídos de forma transparente em todos os nós do cluster para empregar toda a capacidade de computação disponível.
As operações de pré-processamento e métricas são enviadas ao warehouse. Muitas classes de pré-processamento oferecem suporte à execução distribuída quando executadas no warehouse; consulte Pré-processamento distribuído.
Pré-processamento distribuído¶
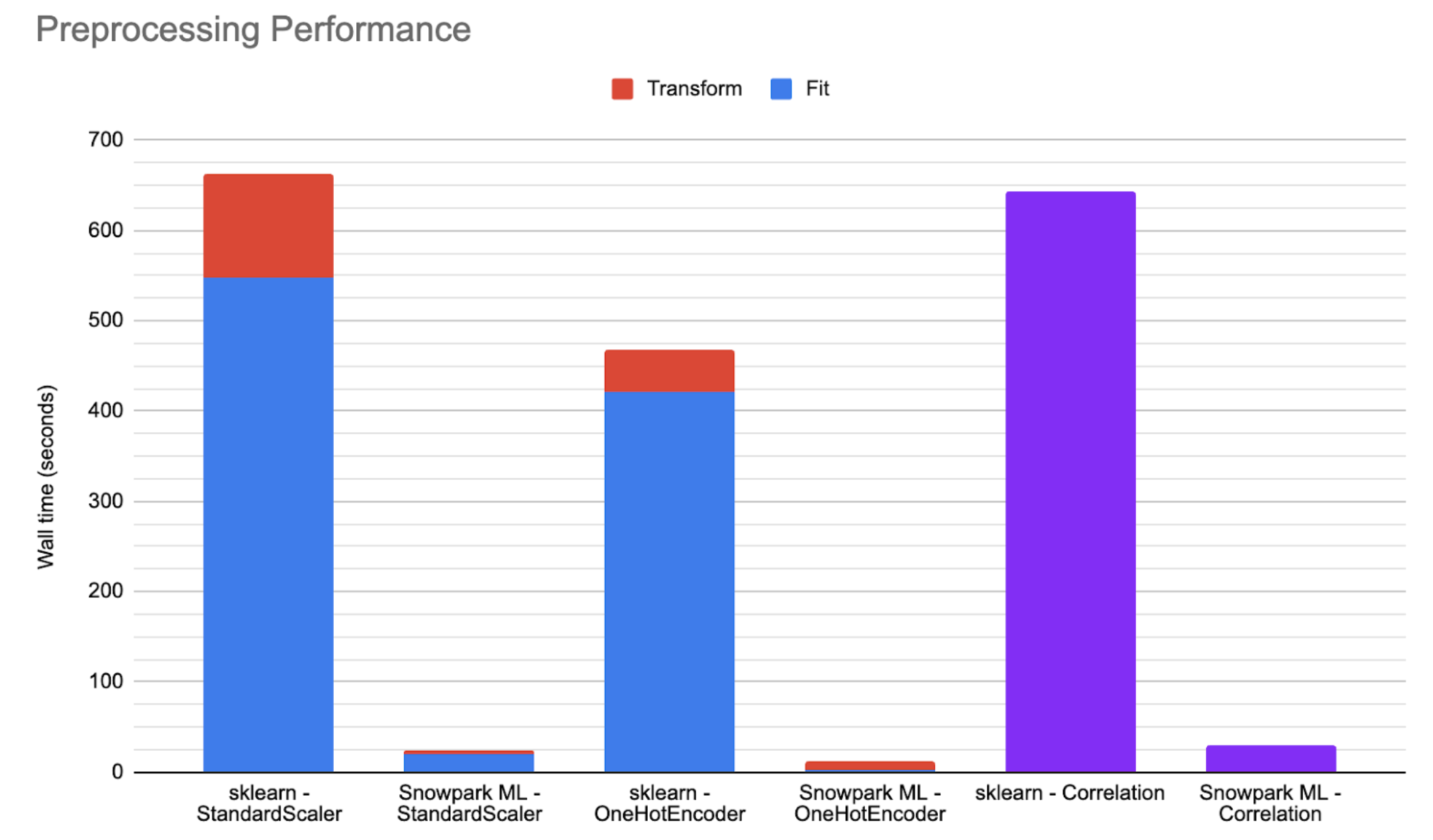
Muitas funções de pré-processamento e transformação de dados do Snowflake são implementadas usando o mecanismo de execução distribuída do Snowflake, o que gera benefícios significativos de desempenho em comparação à execução de nó único (ou seja, procedimentos armazenados). Para descobrir quais funções oferecem suporte à execução distribuída, consulte Classes Snowflake Modeling.
O gráfico abaixo mostra números ilustrativos de desempenho em grandes conjuntos de dados públicos, executados em um warehouse médio otimizado pelo Snowpark, comparando o scikit-learn executado em procedimentos armazenados com as implementações distribuídas do Snowflake. Em muitos cenários, seu código pode ser executado de 25 a 50 vezes mais rápido ao usar classes de modelagem Snowflake.
Como os ajustes são distribuídos¶
O método fit de um transformador de pré-processamento Snowflake aceita um DataFrame Snowpark ou pandas, ajusta o conjunto de dados e retorna o transformador ajustado.
Para DataFrames do Snowpark, o ajuste distribuído usa o mecanismo SQL. O transformador gera consultas SQL para calcular os estados necessários (como média, máximo ou contagem). Essas consultas são então executadas pelo Snowflake e os resultados são materializados localmente. Para estados complexos que não podem ser calculados em SQL, o transformador busca resultados intermediários do Snowflake e executa cálculos locais sobre metadados.
Para transformadores complexos que exigem tabelas de estado temporárias durante a transformação (por exemplo,
OneHotEncoderouOrdinalEncoder), essas tabelas são representadas localmente usando pandas DataFrames.pandas DataFrames são ajustados localmente, semelhante ao ajuste com o scikit-learn. O transformador cria um transformador scikit-learn correspondente com os parâmetros fornecidos. Em seguida, o transformador scikit-learn é ajustado, e o transformador Snowflake deriva os estados necessários do objeto scikit-learn.
Como as transformações são distribuídas¶
O método transform de um transformador de pré-processamento aceita um DataFrame Snowpark ou pandas, transforma o conjunto de dados e retorna um conjunto de dados transformado.
Para DataFrames do Snowpark, a transformação distribuída é executada usando o mecanismo SQL. O transformador ajustado gera um DataFrame do Snowpark com consultas SQL subjacentes que representam o conjunto de dados transformado. O método
transformexecuta avaliação lenta para transformações simples (por exemplo,StandardScalerouMinMaxScaler), de modo que nenhuma transformação seja realmente executada durante o métodotransform.No entanto, certas transformações complexas envolvem execução. Isso inclui transformadores que exigem tabelas de estado temporárias (como
OneHotEncodereOrdinalEncoder) durante a transformação. Para tal transformador, o transformador cria uma tabela temporária do Pandas DataFrame (que armazena o estado do objeto) para junções e outras operações.Além disso, quando certos parâmetros são definidos – por exemplo, quando o transformador é definido para manipular valores desconhecidos encontrados durante a transformação gerando erros – o transformador materializa os dados, incluindo colunas, valores desconhecidos e assim por diante.
Pandas DataFrames são transformados localmente, semelhante à transformação com scikit-learn. O transformador cria um transformador scikit-learn correspondente usando
to_sklearnAPI e executa a transformação na memória.
Otimização de hiperparâmetros distribuídos¶
O ajuste de hiperparâmetros é parte integrante do fluxo de trabalho da ciência de dados. A API Snowflake fornece implementações distribuídas do scikit-learn GridSearchCV e APIs RandomizedSearchCV para permitir o ajuste eficiente de hiperparâmetros em warehouses de nó único e de vários nós.
Dica
O Snowflake habilita a otimização de hiperparâmetros distribuídos por padrão. Para desativá-lo, use a seguinte importação do Python.
import snowflake.ml.modeling.parameters.disable_distributed_hpo
O menor warehouse virtual Snowflake (XS) ou warehouse otimizado para Snowpark (M) tem um nó. Cada tamanho sucessivamente maior duplica o número de nós.
Para warehouses de nó único (XS), a capacidade total do nó é utilizada por padrão usando a estrutura de multiprocessamento joblib do scikit-learn.
Dica
Cada operação de ajuste requer sua própria cópia desse conjunto de dados de treinamento carregado em RAM. Para processar conjuntos de dados extremamente grandes, desabilite a otimização de hiperparâmetros distribuídos (com import snowflake.ml.modeling.parameters.disable_distributed_hpo) e defina o parâmetro n_jobs como 1 para minimizar a simultaneidade.
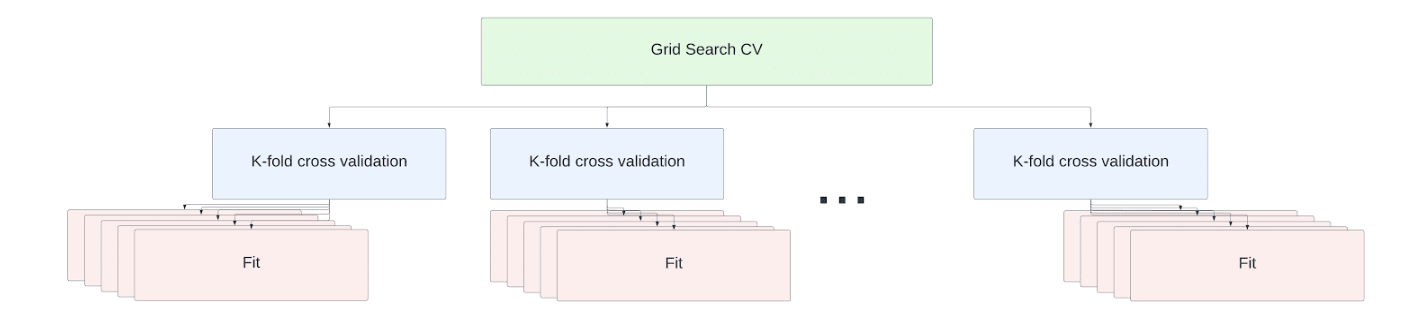
Para warehouses com vários nós, as operações fit dentro do trabalho de ajuste de validação cruzada são distribuídas entre os nós. Nenhuma alteração de código é necessária para aumentar a escala. Os ajustes do estimador são executados em paralelo em todos os núcleos disponíveis em todos os nós do warehouse.
Como ilustração, considere o conjunto de dados habitacionais da Califórnia fornecido com a biblioteca scikit-learn. Os dados incluem 20.640 linhas de dados com as seguintes informações:
MedInc: renda mediana no grupo de quarteirões
HouseAge: idade média da residência no grupo de quarteirões
AveRooms: número médio de cômodos por domicílio
AveBedrms: número médio de quartos por domicílio
População: a população do grupo de quarteirões
AveOccup: número médio de membros da família
Latitude e Longitude
O alvo do conjunto de dados é a renda média, expressa em centenas de milhares de dólares.
Neste exemplo, fazemos a validação cruzada de pesquisa em grade em um regressor aleatório para encontrar a melhor combinação de hiperparâmetros para prever a renda mediana.
from snowflake.ml.modeling.ensemble.random_forest_regressor import RandomForestRegressor
from snowflake.ml.modeling.model_selection.grid_search_cv import GridSearchCV
from sklearn import datasets
def load_housing_data() -> DataFrame:
input_df_pandas = datasets.fetch_california_housing(as_frame=True).frame
# Set the columns to be upper case for consistency with Snowflake identifiers.
input_df_pandas.columns = [c.upper() for c in input_df_pandas.columns]
input_df = session.create_dataframe(input_df_pandas)
return input_df
input_df = load_housing_data()
# Use all the columns besides the median value as the features
input_cols = [c for c in input_df.columns if not c.startswith("MEDHOUSEVAL")]
# Set the target median value as the only label columns
label_cols = [c for c in input_df.columns if c.startswith("MEDHOUSEVAL")]
DISTRIBUTIONS = dict(
max_depth=[80, 90, 100, 110],
min_samples_leaf=[1,3,10],
min_samples_split=[1.0, 3,10],
n_estimators=[100,200,400]
)
estimator = RandomForestRegressor()
n_folds = 5
clf = GridSearchCV(estimator=estimator, param_grid=DISTRIBUTIONS, cv=n_folds, input_cols=input_cols, label_cols=label_col)
clf.fit(input_df)
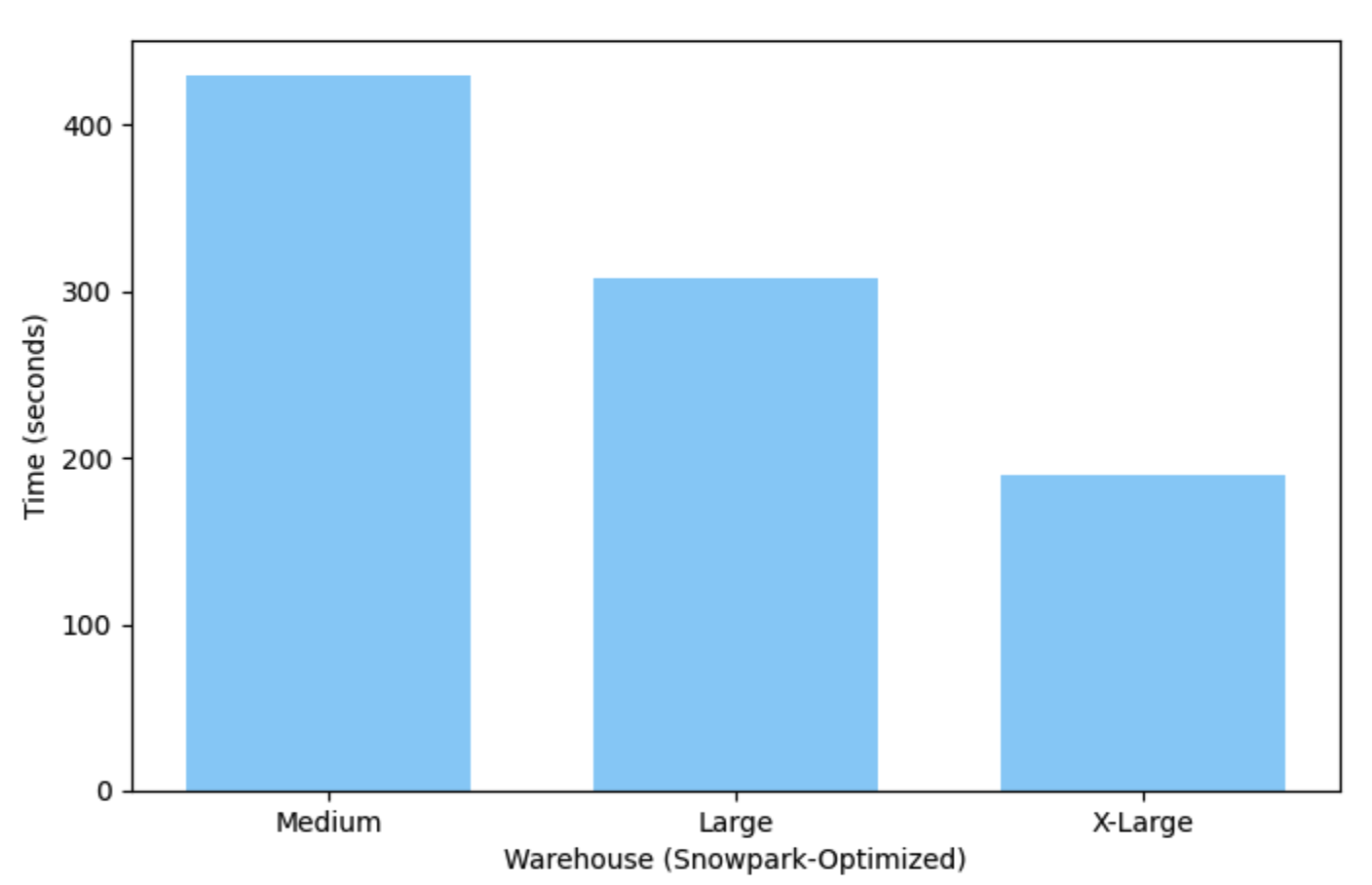
Este exemplo é executado em pouco mais de 7 minutos em um warehouse Medium (nó único) otimizado para Snowpark e leva apenas 3 minutos para ser executado em um warehouse X-Large.
Como implantar e executar seu modelo¶
O resultado do treinamento de um modelo é um objeto de modelo Python. Você pode usar o modelo treinado para fazer previsões chamando o método predict do modelo. Isso cria uma função temporária definida pelo usuário para executar o modelo em seu warehouse virtual Snowflake. Esta função é excluída automaticamente no final da sua sessão Snowflake (por exemplo, quando seu script termina ou quando você fecha seu notebook).
Para manter a função definida pelo usuário após o término da sessão, você pode criá-la manualmente. Consulte o Guia de início rápido sobre o tópico para obter mais informações.
O registro do modelo Snowflake também oferece suporte a modelos persistentes e facilita sua localização e implantação. Consulte Registro de modelo Snowflake.
Modelos personalizados particionados¶
O registro do modelo também oferece suporte a um tipo especial de modelo personalizado em que o ajuste e a inferência são executados em paralelo para um conjunto de partições. Essa pode ser uma maneira eficiente de criar muitos modelos de uma só vez a partir de um conjunto de dados e executar inferências imediatamente. Consulte Snowflake Model Registry: modelos personalizados particionados para obter mais detalhes.
Pipeline para múltiplas transformações¶
Com o scikit-learn, é comum executar uma série de transformações usando um pipeline. Os pipelines do scikit-learn não funcionam com classes Snowflake, portanto, uma versão Snowflake de sklearn.pipeline.Pipeline é fornecida para executar uma série de transformações. Esta classe está no pacote snowflake.ml.modeling.pipeline e funciona da mesma forma que a versão scikit-learn.
Recuperação do modelo subjacente¶
Os modelos de ML do Snowflake podem ser “desembrulhados”, ou seja, convertidos em tipos de modelo de terceiros subjacentes, com os seguintes métodos (dependendo da biblioteca):
to_sklearnto_xgboostto_lightgbm
Todos os atributos e métodos do modelo subjacente podem então ser acessados e executados localmente no estimador. Por exemplo, no exemplo GridSearchCV, convertemos o estimador de pesquisa em grade em um objeto scikit-learn para recuperar a melhor pontuação.
best_score = grid_search_cv.to_sklearn().best_score_
Limitações conhecidas¶
Atualmente, os estimadores e transformadores Snowflake não oferecem suporte a entradas ou respostas esparsas. Se você tiver dados esparsos, converta-os para um formato denso antes de passá-los aos estimadores ou transformadores do Snowflake.
Atualmente, o pacote
snowflake-ml-pythonnão oferece suporte a tipos de dados de matriz. Qualquer operação em estimadores e transformadores que produzam uma matriz como resultado falha.Não há garantia de que a ordem das linhas nos dados de resultado corresponda à ordem das linhas nos dados de entrada.
O ML do Snowflake ainda não oferece suporte ao DataFrames pandas on Snowflake. Converta o DataFrame pandas on Snowflake em um DataFrame Snowpark para usá-lo com as classes de modelagem Snowflake. O exemplo a seguir converte um DataFrame cuja leitura foi realizada a partir de uma tabela Snowflake:
import modin.pandas as pd import snowflake.snowpark.modin.plugin from snowflake.ml.modeling.xgboost import XGBClassifier snowpark_pandas_df: modin.pandas.DataFrame = read_snowflake('MY_TABLE') # converting to Snowpark DataFrame adds an index column index_label_name = "_INDEX" snowpark_df = snowpark_pandas_df.to_snowpark(index=True, index_label=index_label_name) snowpark_df.show()
O DataFrame Snowpark resultante é o seguinte:
-------------------------------------------------- |"COLUMN_1" |"COLUMN_2" |"TARGET" | "_INDEX" | -------------------------------------------------- |1 |2 |3 |1 | --------------------------------------------------
O DataFrame pode então ser usado para treinar um classificador XGBoost da seguinte forma:
# Identify the column names using the Snowflake identifier input_cols = ["COLUMN_1", "COLUMN_2", "COLUMN_3"] # Pass through the _INDEX column rather than using it for training xgb_clf = XGBClassifier(input_cols=input_cols, passthrough_cols=index_label_name, label_cols="TARGET") xgb_clf.fit(snowpark_df)
Solução de problemas¶
Adição de mais detalhes ao registro¶
A biblioteca de modelagem Snowflake usa o registro em log do Snowpark Python. Por padrão, snowflake-ml-python registra mensagens de nível INFO na saída padrão. Para obter logs mais detalhados, é possível alterar o nível para um dos níveis compatíveis.
DEBUG produz logs com mais detalhes. Para definir o nível de registro em log como DEBUG:
import logging, sys
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
Soluções para problemas comuns¶
A tabela a seguir fornece algumas sugestões para resolver possíveis problemas com o Snowflake ML Modeling.
Problema ou mensagem de erro |
Possível causa |
Resolução |
|---|---|---|
NameError, como «nome x não está definido», ImportError ou ModuleNotFoundError |
Erro tipográfico no nome do módulo ou da classe, ou |
Consulte a tabela de classes de modelagem para obter o nome correto do módulo e da classe. Certifique-se de que |
KeyError («não está no índice» ou «nenhum dos [Índice[..]] está em [colunas]») |
Nome de coluna incorreto. |
Verifique e corrija o nome da coluna. |
SnowparkSQLException, «não existe ou não está autorizado» |
A tabela não existe ou você não tem privilégios suficientes na tabela. |
Certifique-se de que a tabela exista e que a função do usuário tenha os privilégios. |
SnowparkSQLException, «identificador inválido PETALLENGTH» |
Número incorreto de colunas (geralmente uma coluna ausente). |
Verifique o número de colunas especificado quando você criou a classe de modelo e certifique-se de passar o número correto. |
InvalidParameterError |
Um tipo ou valor inadequado foi passado como parâmetro. |
Verifique a ajuda da classe ou método usando a função |
TypeError, «unexpected keyword argument» |
Erro tipográfico no argumento nomeado. |
Verifique a ajuda da classe ou método usando a função |
ValueError, «array with 0 sample(s)» |
O conjunto de dados passado está vazio. |
Certifique-se de que o conjunto de dados não esteja vazio. |
SnowparkSQLException, «authentication token has expired» |
A sessão expirou. |
Se você estiver usando um Jupyter Notebook, reinicie o kernel para criar uma nova sessão. |
ValueError, como «cannot convert string to float» |
Incompatibilidade de tipo de dados. |
Verifique a ajuda da classe ou método usando a função |
SnowparkSQLException, «cannot create temporary table» |
Uma classe de modelo está sendo usada dentro de um procedimento armazenado que não é executado com os direitos do chamador. |
Crie o procedimento armazenado com os direitos do chamador em vez dos direitos do proprietário. |
SnowparkSQLException, «function available memory exceeded» |
Seu conjunto de dados é maior que 5 GB em um warehouse padrão. |
Mude para um warehouse otimizado para Snowpark. |
OSError, «no space left on device» |
Seu modelo é maior que cerca de 500 MB em um warehouse padrão. |
Mude para um warehouse otimizado para Snowpark. |
Versão xgboost incompatível ou erro ao importar xgboost |
Você instalou usando |
Atualize ou faça downgrade do pacote conforme solicitado pela mensagem de erro. |
AttributeError envolvendo |
Uma tentativa de usar um desses métodos em um modelo de um tipo diferente. |
Use |
O kernel do notebook Jupyter trava em um Mac baseado em ARM (chip M1 ou M2): “O kernel travou ao executar o código na célula atual ou em uma célula anterior.” |
XGBoost ou outra biblioteca está instalada com a arquitetura incorreta. |
Recrie o novo ambiente com |
«lightgbm.basic.LightGBMError: (0000) não oferece suporte a caracteres especiais JSON no nome do recurso.» |
LightGBM não oferece suporte a nomes de colunas com aspas duplas em |
Renomeie as colunas em seus DataFrames Snowpark. Substituir caracteres não alfanuméricos por sublinhados é suficiente na maioria dos casos. A função auxiliar Python abaixo pode ser útil. def fix_values(F, column):
return F.upper(F.regexp_replace(F.col(column), "[^a-zA-Z0-9]+", "_"))
|
Leitura adicional¶
Consulte a documentação das bibliotecas originais para obter informações completas sobre sua funcionalidade.
Aviso¶
Algumas partes deste documento são derivadas da documentação do Scikit-learn, que é licenciada sob a licença BSD-3 «Nova» ou «Revisada» e Copyright © 2007-2023 The scikit-learn developers. Todos os direitos reservados.
Algumas partes deste documento são derivadas da documentação XGboost, que é coberta pela licença Apache 2.0, janeiro de 2004 e Copyright © 2019. Todos os direitos reservados.
Algumas partes deste documento são derivadas da documentação LightGBM, que é licenciado para MIT e Copyright © Microsoft Corp. Todos os direitos reservados.