pandas on Snowflake¶
O pandas no Snowpark permite que você execute seu código pandas diretamente em seus dados no Snowflake. Ao simplesmente alterar a instrução de importação e algumas linhas de código, é possível obter a experiência conhecida do pandas para desenvolver pipelines robustos, enquanto se beneficia perfeitamente do desempenho e da escalabilidade do Snowflake à medida que seus pipelines são dimensionados.
O pandas on Snowflake determina de forma inteligente se o código pandas deve ser executado localmente ou se deve-se usar o mecanismo Snowflake para dimensionar e melhorar o desempenho por meio de Execução híbrida. Ao trabalhar com grandes conjuntos de dados no Snowpark, ele executa cargas de trabalho nativamente no Snowflake por meio de transpilação para SQL, permitindo o aproveitamento da paralelização e os benefícios de governança e segurança de dados do Snowflake.
O pandas on Snowflake é fornecido pela API Snowpark pandas como parte da biblioteca Snowpark Python, que permite o processamento de dados escaláveis do código Python dentro da plataforma Snowflake.
Benefícios do uso de pandas on Snowflake¶
Alinhar-se com desenvolvedores Python em seu contexto: o pandas on Snowflake oferece uma interface familiar para desenvolvedores Python, fornecendo uma camada compatível com o pandas que pode ser executada nativamente no Snowflake.
Padas distribuído escalável: o pandas on Snowflake une a conveniência do pandas com a escalabilidade do Snowflake, aproveitando as técnicas de otimização de consulta existentes no Snowflake. São necessárias poucas reescritas de código, simplificando a jornada de migração para que você possa passar facilmente do protótipo à produção.
Nenhuma infraestrutura de computação adicional para gerenciar e ajustar: o pandas on Snowflake aproveita o poderoso mecanismo de computação do Snowflake, então você não precisa definir ou gerenciar nenhuma infraestrutura de computação adicional.
Como começar com o pandas on Snowflake¶
Nota
Para um exemplo prático de como usar pandas on Snowflake, verifique este Notebook e veja isto Vídeo.
Para instalar o pandas on Snowflake, é possível usar conda ou pip para instalar o pacote. Para obter instruções detalhadas, consulte Instalação.
Depois que o pandas on Snowflake estiver instalado, em vez de importar o pandas como import pandas as pd, use as duas linhas a seguir:
Aqui está um exemplo de como é possível começar a usar o pandas on Snowflake através da biblioteca pandas no Snowpark Python com o Modin:
read_snowflake oferece suporte à leitura de exibições Snowflake, tabelas dinâmicas, tabelas Iceberg e muito mais. Você também pode passar um SQL consulte diretamente e receba de volta um pandas on Snowflake DataFrame, facilitando a movimentação contínua entre SQL e pandas on Snowflake.
Como funciona a execução híbrida¶
Nota
Começando pela versão Snowpark Python 1.40.0, a execução híbrida é habilitada por padrão ao usar pandas on Snowflake.
O pandas on Snowflake usa execução híbrida para determinar se o código pandas deve ser executado localmente ou se deve-se usar o mecanismo Snowflake para dimensionar e aprimorar o desempenho. Isso permite que você continue escrevendo código pandas familiar para desenvolver pipelines robustos, sem ter que pensar na maneira mais ideal e eficiente de executar seu código, enquanto se beneficia perfeitamente do desempenho e da escalabilidade do Snowflake à medida que seus pipelines são dimensionados.
Exemplo 1: Crie uma pequena de 11 linhas DataFrame em linha. Com a execução híbrida, o Snowflake seleciona o backend pandas local e na memória para executar a operação:
Exemplo 2: Como criar uma tabela com 10 milhões de linhas de transações
Você pode ver que a tabela usa o Snowflake como backend, pois esta é uma tabela grande que reside no Snowflake.
Exemplo 3: Filtragem de dados e execução de um groupby agregação resultando em 7 linhas de dados.
Quando os dados são filtrados, o Snowflake reconhece implicitamente a escolha de backend das alterações do mecanismo de Snowflake para pandas, já que a saída tem apenas 7 linhas de dados.
Observações e limitações¶
O tipo DataFrame sempre será
modin.pandas.DataFrame/Series/etcmesmo quando o backend muda, para garantir a interoperabilidade/compatibilidade com o código downstream.Para determinar qual backend usar, o Snowflake às vezes usa uma estimativa do tamanho da linha em vez de calcular o comprimento exato do DataFrame em cada etapa. Isso significa que o Snowflake pode nem sempre mudar para o back-end ideal imediatamente após uma operação quando o conjunto de dados fica maior/menor (por exemplo, filtro, agregação).
Quando há uma operação que combina duas ou mais DataFrames em diferentes backends, o Snowflake determina para onde mover os dados com base no menor custo de transferência de dados.
As operações de filtragem podem não resultar na movimentação de dados, porque o Snowflake pode não ser capaz de estimar o tamanho dos dados filtrados subjacentes.
Qualquer DataFrames composos de dados Python na memória usará o backend pandas, como o seguinte:
DataFrames passará automaticamente do mecanismo Snowflake para o mecanismo pandas em um conjunto limitado de operações. Essas operações incluem
df.apply,df.plot,df.iterrows,df.itertuples,series.items, e em operações de redução em que o tamanho dos dados é garantido ser menor. Nem todas as operações são pontos suportados onde a migração de dados pode ocorrer.A execução híbrida não move automaticamente uma DataFrame do pandas Engine de volta para o Snowflake, exceto nos casos em que uma operação como
pd.concatatua em vários DataFrames.O Snowflake não move automaticamente um DataFrame do pandas Engine de volta para o Snowflake, a menos que uma operação como
pd.concatatua em vários DataFrames.
Quando usar o pandas on Snowflake¶
Você deve usar pandas on Snowflake se alguma das seguintes condições for verdadeira:
Você está familiarizado com a API do pandas e o ecossistema PyData mais amplo.
Você trabalha em equipe com outras pessoas que estão familiarizadas com o pandas e querem colaborar na mesma base de código.
Você tem um código existente escrito em pandas.
Você prefere uma conclusão de código mais precisa em ferramentas de copiloto baseadas em AI.
Para obter mais informações, consulte DataFrames Snowpark vs. DataFrame Snowpark pandas: Qual devo escolher?
Como usar o pandas on Snowflake com Snowpark DataFrames¶
O pandas on Snowflake e DataFrame API é altamente interoperável, então você pode construir um pipeline que aproveite ambas as APIs. Para obter mais informações, consulte DataFrames Snowpark vs. DataFrame Snowpark pandas: Qual devo escolher?
Você pode usar as seguintes operações para fazer conversões entre Snowpark DataFrames e Snowpark pandas DataFrames:
Operação |
Entrada |
Saída |
|---|---|---|
Snowpark DataFrame |
DataFrame Snowpark pandas |
|
DataFrame Snowpark pandas ou série Snowpark Pandas |
Snowpark DataFrame |
Como o pandas on Snowflake se compara ao pandas nativo¶
O pandas on Snowflake e o pandas nativo têm DataFrame APIs com assinaturas correspondentes e semânticas semelhantes. O pandas on Snowflake fornece a mesma assinatura de API que o pandas nativo e fornece computação escalável com o Snowflake. O pandas on Snowflake respeita a semântica descrita na documentação do pandas nativo o máximo possível, mas usa o sistema de computação e tipo do Snowflake. No entanto, quando o pandas nativo é executado em uma máquina cliente, ele usa o sistema de computação e tipos Python. Para obter informações sobre o mapeamento de tipos entre pandas on Snowflake e Snowflake, consulte Tipos de dados.
A partir do Snowpark Python 1.40.0, o pandas on Snowflake é melhor utilizado com dados que já estão no Snowflake. Para converter entre o tipo nativo do pandas e o pandas on Snowflake, use as seguintes operações:
Operação |
Entrada |
Saída |
|---|---|---|
DataFrame Snowpark pandas |
DataFrame pandas nativo: materialize todos os dados para o ambiente local. Se o conjunto de dados for grande, isso poderá resultar em um erro de falta de memória. |
|
pandas DataFrame nativo, dados brutos, objeto Snowpark pandas |
DataFrame Snowpark pandas |
Ambiente de execução¶
pandas: opera em uma única máquina e processa dados na memória.pandas on Snowflake: integra-se ao Snowflake, o que permite computação distribuída em um cluster de máquinas para grandes conjuntos de dados, enquanto aproveita o em memória pandas para processar pequenos conjuntos de dados. Essa integração permite o manuseio de conjuntos de dados muito maiores que excedem a capacidade de memória de uma única máquina. Observe que usar a do Snowpark pandas API requer uma conexão com o Snowflake.
Avaliação lenta e adiantada¶
pandas: executa as operações imediatamente e materializa os resultados completamente na memória após cada operação. Essa avaliação imediata das operações pode levar a um aumento da pressão sobre a memória, pois os dados precisam ser movidos extensivamente dentro da máquina.pandas on Snowflake: fornece a mesma experiência de API que o pandas. Ele imita o modelo de avaliação adiantada do pandas, mas cria internamente um gráfico de consulta avaliado lentamente para permitir a otimização entre as operações.As operações de fusão e transpilação por meio de um gráfico de consulta permitem oportunidades adicionais de otimização para o mecanismo de computação distribuído subjacente do Snowflake, o que diminui o custo e o tempo de execução do pipeline de ponta a ponta em comparação à execução do pandas diretamente no Snowflake.
Nota
APIs e APIs relacionadas a E/S cujo valor de retorno não é um objeto Snowpark pandas (ou seja,
DataFrame,SeriesouIndex) sempre avaliam de forma adiantada. Por exemplo:read_snowflaketo_snowflaketo_pandasto_dictto_list__repr__O método dunder,
__array__, que pode ser chamado automaticamente por algumas bibliotecas de terceiros, como o scikit-learn. Chamadas para esse método materializarão resultados na máquina local.
Fonte e armazenamento de dados¶
pandas: oferece suporte a vários leitores e gravadores listados na documentação do pandas nas ferramentas IO (texto, CSV, HDF5, …).pandas on Snowflake: pode ler e escrever de tabelas Snowflake e ler arquivos locais ou preparados, CSV, JSON ou Parquet. Para obter mais informações, consulte IO (leitura e gravação).
Tipos de dados¶
pandas: possui um rico conjunto de tipos de dados, como inteiros, flutuantes, cadeias de caracteres, tiposdatetimee tipos categóricos. Também oferece suporte a tipos de dados definidos pelo usuário. Os tipos de dados no pandas geralmente são derivados dos dados subjacentes e são aplicados de forma rigorosa.pandas on Snowflake: é limitado pelo sistema do tipo Snowflake, que mapeia objetos pandas para SQL traduzindo os tipos de dados do pandas para os tipos SQL no Snowflake. A maioria dos tipos de pandas tem um equivalente natural no Snowflake, mas o mapeamento nem sempre é um para um. Em alguns casos, vários tipos de pandas são mapeados para o mesmo tipo SQL.
A tabela a seguir lista os mapeamentos de tipos entre pandas e Snowflake SQL:
Tipo pandas |
Tipo de dados Snowflake |
|---|---|
Todos os tipos inteiros assinados/não assinados, incluindo tipos inteiros estendidos do pandas |
NUMBER(38, 0) |
Todos os tipos de float, incluindo os tipos de dados float estendidos do pandas |
FLOAT |
|
BOOLEAN |
|
STRING |
|
TIME |
|
DATE |
Todos os tipos |
TIMESTAMP_NTZ |
Todos os tipos |
TIMESTAMP_TZ |
|
ARRAY |
|
MAP |
Coluna de objeto com tipos de dados mistos |
VARIANT |
Timedelta64[ns] |
NUMBER(38, 0) |
Nota
Tipos de dados categóricos, de período, de intervalo, esparsos e definidos pelo usuário não são suportados. Atualmente, o Timedelta só é compatível com o cliente pandas no Snowpark. Ao escrever Timedelta de volta no Snowflake, ele será armazenado como tipo Number.
A tabela a seguir fornece o mapeamento dos tipos SQL Snowflake de volta para os tipos pandas on Snowflake usando df.dtypes:
Tipo de dados Snowflake |
Tipo pandas on Snowflake ( |
|---|---|
NUMBER ( |
|
NUMBER ( |
|
BOOLEAN |
|
STRING, TEXT |
|
VARIANT, BINARY, GEOMETRY, GEOGRAPHY |
|
ARRAY |
|
OBJECT |
|
TIME |
|
TIMESTAMP, TIMESTAMP_NTZ, TIMESTAMP_LTZ, TIMESTAMP_TZ |
|
DATE |
|
Ao converter um DataFrame do pandas Snowpark para um DataFrame do pandas nativo com to_pandas(), o DataFrame do pandas nativo terá tipos de dados refinados em comparação com os tipos do pandas on Snowflake, que são compatíveis com os Mapeamentos de tipos de dados SQL-Python para funções e procedimentos.
Conversão e inferência de tipos¶
pandas: depende de NumPy e por padrão segue o NumPy e sistema de tipos Python para conversão de tipos implícita e inferência. Por exemplo, ele trata boolianos como tipos inteiros, então1 + Trueretorna2.pandas on Snowflake: mapeia os tipos NumPy e Python para tipos Snowflake de acordo com a tabela anterior e usa o sistema de tipos Snowflake subjacente para conversão de tipos e inferência implícitos. Por exemplo, de acordo com Tipos de dados lógicos, ele não converte implicitamente boolianos em tipos inteiros, então1 + Trueresulta em um erro de conversão de tipo.
Tratamento de valor nulo¶
pandas: nas versões 1.x do pandas, o pandas era flexível ao manipular dados ausentes, então tratou todo o PythonNone,np.nan,pd.NaN,pd.NAepd.NaTcomo valores ausentes. Em versões posteriores do pandas (2.2.x), esses valores são tratados como valores diferentes.pandas on Snowflake: adota uma abordagem semelhante às versões anteriores do pandas que trata todos os valores anteriores listados como valores ausentes. O Snowpark reutilizaNaN,NAeNaTdo pandas. Mas observe que todos esses valores ausentes são tratados de forma intercambiável e armazenados como SQL NULL na tabela Snowflake.
Aliases de offset/frequência¶
pandas: os offsets de data no pandas foram alterados na versão 2.2.1. Os aliases de uma única letra'M','Q','Y'e outros foram descontinuados em favor de offsets de duas letras.pandas on Snowflake: usa exclusivamente os novos offsets descritos ao documentação da série temporal dos pandas.
Instalar a biblioteca do pandas on Snowflake¶
Pré-requisitos
As seguintes versões do pacote são necessárias:
Python 3.9 (obsoleto), 3.10, 3.11, 3.12 ou 3.13
Modin versão 0.32.0
pandas versão 2.2.*
Dica
Para usar pandas on Snowflake em Snowflake Notebooks, consulte as instruções de configuração em pandas on Snowflake no notebooks.
Para instalar o pandas on Snowflake em seu ambiente de desenvolvimento, siga estas etapas:
Mude para o diretório do seu projeto e ative seu ambiente virtual Python.
Nota
A API está em desenvolvimento ativo, então recomendamos instalá-la em um ambiente virtual Python em vez de em todo o sistema. Essa prática permite que cada projeto criado use uma versão específica, protegendo você de alterações em versões futuras.
Você pode criar um ambiente virtual Python para uma versão específica do Python usando ferramentas como Anaconda, Miniconda ou virtualenv.
Por exemplo, para usar o conda para criar um ambiente virtual Python 3.12, execute estes comandos:
Nota
Se você instalou anteriormente uma versão mais antiga do pandas on Snowflake usando o Python 3.9 e o pandas 1.5.3, será necessário atualizar suas versões do Python e do pandas conforme descrito acima. Siga as etapas para criar um ambiente com Python 3.10 ou 3.13.
Instale a biblioteca Snowpark Python com o Modin:
ou
Nota
Confirme se a versão 1.17.0 ou posterior do
snowflake-snowpark-pythonestá instalada.
Autenticação no Snowflake¶
Antes de usar o pandas on Snowflake, é necessário estabelecer uma sessão com o banco de dados Snowflake. Você pode usar um arquivo de configuração para escolher os parâmetros de conexão para sua sessão ou pode enumerá-los em seu código. Para obter mais informações, consulte Como criar uma sessão para o Snowpark Python. Se existir uma sessão Python ativa exclusiva do Snowpark, o pandas on Snowflake a utilizará automaticamente. Por exemplo:
O pd.session é uma sessão do Snowpark, então você pode fazer com ela tudo o que faria com qualquer outra sessão do Snowpark. Por exemplo, você pode usá-lo para executar uma consulta SQL arbitrária, que resulta em um DataFrame do Snowpark conforme a API da sessão, mas observe que o resultado é um DataFrame do Snowpark, não um DataFrame do Snowpark pandas.
Como alternativa, você pode configurar os parâmetros de conexão do Snowpark em um arquivo de configuração. Isso elimina a necessidade de enumerar parâmetros de conexão em seu código, o que permite que você escreva seu código pandas on Snowflake quase como normalmente escreveria o código pandas.
Crie um arquivo de configuração localizado em
~/.snowflake/connections.tomlque se pareça com isto:Para criar uma sessão usando essas credenciais, use
snowflake.snowpark.Session.builder.create():
Você também pode criar várias sessões do Snowpark e atribuir uma delas ao pandas on Snowflake. O pandas on Snowflake usa apenas uma sessão, então você precisa atribuir explicitamente uma das sessões ao pandas on Snowflake com pd.session = pandas_session:
O exemplo a seguir mostra que tentar usar o pandas on Snowflake quando não há uma sessão ativa do Snowpark resultará em um SnowparkSessionException com um erro como «pandas on Snowflake requer uma sessão ativa do Snowpark, mas não há nenhuma». Depois de criar uma sessão, você poderá usar o pandas on Snowflake. Por exemplo:
O exemplo a seguir mostra que tentar usar pandas on Snowflake quando há várias sessões ativas do Snowpark causará SnowparkSessionException com uma mensagem como: “Há várias sessões ativas do Snowpark, mas é preciso escolher uma para pandas on Snowflake.”
Nota
É necessário definir a sessão usada para uma nova pandas on Snowflake DataFrame ou série via modin.pandas.session. No entanto, os DataFrames de junção ou mesclagem criados com diferentes sessões não são compatíveis, portanto, você deve evitar configurar repetidamente diferentes sessões e criar DataFrames com diferentes sessões em um fluxo de trabalho.
Referência de API¶
Veja a referência da API pandas on Snowflake para obter a lista completa de APIs atualmente implementadas e métodos disponíveis.
Para obter uma lista completa de operações compatíveis, consulte as seguintes tabelas na referência do pandas on Snowflake:
APIs Parâmetro de configuração e para execução híbrida¶
A execução híbrida usa uma combinação da estimativa de tamanho do conjunto de dados e as operações que estão sendo aplicadas ao DataFrame para determinar a escolha do backend. Em geral, conjuntos de dados com menos de 100 mil linhas tendem a usar pandas local; aqueles com mais de 100 mil linhas tendem a usar o Snowflake, a menos que o conjunto de dados seja carregado a partir de arquivos locais.
Configuração dos custos de transferência¶
Para alterar o limite de alternância padrão para outro valor de limite de linha, você pode modificar a variável de ambiente antes de inicializar um DataFrame:
Definir este valor vinculará a transferência de linhas do Snowflake.
Configuração de limites de execução local¶
Uma vez por DataFrame é local, geralmente permanecerá local, a menos que haja necessidade de movê-lo de volta para Snowflake para uma fusão, mas há um limite superior considerado para o tamanho máximo dos dados que podem ser processados localmente. Atualmente este limite é de 10 milhões de linhas.
Verificação e configuração do back-end¶
Para verificar o back-end atual de sua escolha, você pode usar o df.getbackend() Comando, que retorna Pandas para execução local, ou Snowflake para a execução do pushdown.
Para definir o backend atual de escolha com set_backend ou seu alias move_to:
Você também pode definir o back-end no lugar:
Para inspecionar e exibir informações sobre por que os dados foram movidos:
Seleção de backend de substituição manual por meio de fixação de backend¶
Por padrão, o Snowflake escolhe automaticamente o melhor back-end para um determinado DataFrame Operações e. Se quiser substituir a seleção automática do mecanismo, é possível desativar a ativação automática de um objeto e todos os dados resultantes produzidos por ele, usando o pan_backend() Método:
Para reativar a troca automática de back-end, chame unfix_backend():
Uso de Snowpark pandas em notebooks Snowflake¶
Para usar pandas on Snowflake em notebooks Snowflake, consulte pandas on Snowflake em notebooks.
Uso de Snowpark pandas em planilhas Python¶
Para usar Snowpark pandas, você precisa instalar o Modin selecionando modin em Packages no ambiente da planilha do Python.
Você pode selecionar o tipo de retorno da função Python em Settings > Return type. Por padrão, isso é definido como uma tabela Snowpark. Para exibir o Snowpark pandas DataFrame como resultado, você pode converter um Snowpark pandas DataFrame em um Snowpark DataFrame chamando to_snowpark(). Nenhum custo de E/S será incorrido nesta conversão.
Aqui está um exemplo de uso do Snowpark pandas com o planilhas Python:
Como usar o pandas on Snowflake em procedimentos armazenados¶
É possível usar o pandas on Snowflake em um procedimento armazenado para criar um pipeline de dados e agendar a execução do procedimento armazenado com tarefas.
Veja como você pode criar um procedimento armazenado usando o SQL:
Veja como você pode criar um procedimento armazenado usando a Snowflake Python API:
Para chamar o procedimento armazenado, é possível executar dt_pipeline_sproc() em Python ou CALL run_data_transformation_pipeline_sp() em SQL.
Como usar o pandas on Snowflake com bibliotecas de terceiros¶
O pandas é comumente usado com APIs de bibliotecas de terceiros para aplicativos de visualização e aprendizado de máquina. O pandas on Snowflake é interoperável com a maioria dessas bibliotecas, de modo que elas podem ser usadas sem a conversão explícita para o pandas DataFrames. No entanto, observe que a execução distribuída não costuma ser compatível com a maioria das bibliotecas de terceiros, exceto em casos de uso limitado. Portanto, isso pode levar a um desempenho mais lento em grandes conjuntos de dados.
Bibliotecas de terceiros compatíveis¶
As bibliotecas listadas abaixo aceitam pandas on Snowflake DataFrames como entrada, mas nem todos os seus métodos foram testados. Para obter um status detalhado da interoperabilidade em um nível de API, consulte Interoperabilidade com bibliotecas de terceiros.
Plotly
Altair
Seaborn
Matplotlib
Numpy
Scikit-learn
XGBoost
NLTK
Streamlit
O pandas on Snowflake atualmente tem compatibilidade limitada para certas APIs NumPy e Matplotlib, como implementação distribuída para np.where e interoperabilidade com df.plot. Converter o DataFrames pandas Snowpark via to_pandas() ao trabalhar com essas bibliotecas de terceiros evitará múltiplas chamadas de E/S.
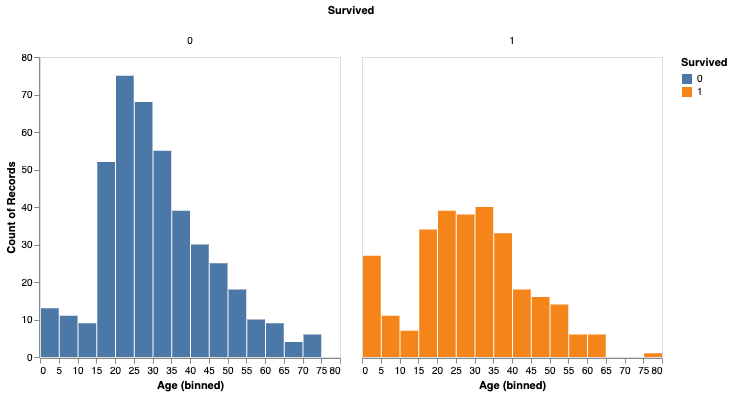
Aqui está um exemplo com Altair para visualização e scikit-learn para aprendizado de máquina.
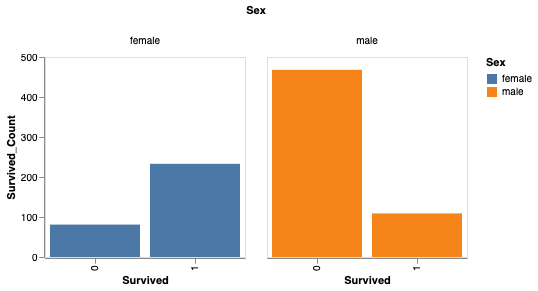
Você também pode analisar a sobrevivência com base no gênero.
Agora você pode usar o scikit-learn para treinar um modelo simples.
Nota
Para obter um melhor desempenho, recomendamos a conversão para pandas DataFrames via to_pandas(), principalmente quando você estiver usando bibliotecas de aprendizado de máquina, como scikit-learn. No entanto, a função to_pandas() coleta todas as linhas, portanto, talvez seja melhor reduzir o tamanho do dataframe primeiro com sample(frac=0.1) ou head(10).
Bibliotecas não compatíveis¶
Ao usar bibliotecas de terceiros não compatíveis com um pandas on Snowflake DataFrame, recomendamos converter o pandas on Snowflake DataFrame em um pandas DataFrame chamando to_pandas() antes de passar o DataFrame para o método da biblioteca de terceiros.
Nota
Chamar to_pandas() retira seus dados do Snowflake e os coloca na memória, portanto, considere isso para grandes conjuntos de dados e casos de uso confidenciais.
Usar as funções de LLM do Snowflake Cortex com o pandas Snowpark¶
Você pode usar as funções de LLM do Snowflake Cortex por meio da função de aplicação do Snowpark pandas.
Você aplica a função com argumentos de palavras-chave especiais. Atualmente, as seguintes funções do Cortex são compatíveis:
O exemplo a seguir usa a função TRANSLATE em vários registros em um pandas DataFrame do Snowpark:
Saída:
O exemplo a seguir usa a função SENTIMENT (SNOWFLAKE.CORTEX) em uma tabela Snowflake chamada reviews:
O exemplo a seguir usa o EXTRACT_ANSWER (SNOWFLAKE.CORTEX) para responder a uma pergunta:
Saída:
Nota
O pacote snowflake-ml-python deve ser instalado para usar as funções LLM do Cortex.
Limitações¶
pandas on Snowflake tem as seguintes limitações:
O pandas on Snowflake não oferece nenhuma garantia de compatibilidade com bibliotecas de terceiros OSS. A partir da versão 1.14.0a1, no entanto, o Snowpark pandas introduz compatibilidade limitada para NumPy, especificamente para o uso de
np.where. Para obter mais informações, consulte Interoperabilidade do NumPy.Ao chamar APIs da biblioteca de terceiros com um DataFrame do Snowpark pandas, a Snowflake recomenda que você converta o DataFrame do Snowpark pandas em um DataFrame do pandas chamando
to_pandas()antes de passar o DataFrame para a chamada de biblioteca de terceiros. Para obter mais informações, consulte Como usar o pandas on Snowflake com bibliotecas de terceiros.pandas on Snowflake não está integrado ao Snowpark ML. Ao usar o Snowpark ML, recomendamos que você converta o DataFrame do Snowpark pandas em um DataFrame do Snowpark usando to_snowpark() antes de chamar o Snowpark ML.
Os objetos
MultiIndexlentos não são suportados. QuandoMultiIndexé usado, ele retorna um objetoMultiIndexpandas nativo, que requer a extração de todos os dados para o lado do cliente.Nem todas as APIs do pandas têm uma implementação distribuída no pandas on Snowflake, embora algumas estejam sendo adicionadas. Para APIs não suportadas,
NotImplementedErroré lançado. Para obter informações sobre as APIs compatíveis, consulte a documentação de referência da API.O pandas on Snowflake oferece compatibilidade com qualquer versão de correção do pandas 2.2.
O Snowpark pandas não pode ser referenciado dentro da função:code:
applydo Snowpark pandas. Somente é possível usar pandas nativo dentro deapply.Veja a seguir um exemplo:
Solução de problemas¶
Esta seção descreve dicas de solução de problemas para usar o pandas on Snowflake.
Ao solucionar problemas, tente executar a mesma operação em um DataFrame do pandas nativo (ou uma amostra) para verificar se o mesmo erro persiste. Essa abordagem pode fornecer dicas sobre como corrigir sua consulta. Por exemplo:
Se você tiver um notebook de longa execução aberto, observe que, por padrão, as sessões do Snowflake atingem o tempo limite após ficarem ociosas por 240 minutos (4 horas). Quando a sessão expira, se você executar consultas adicionais do pandas on Snowflake, a seguinte mensagem será exibida: «O token de autenticação expirou. O usuário deve se autenticar novamente». Neste ponto, você deve restabelecer a conexão com o Snowflake. Isso pode causar a perda de quaisquer variáveis de sessão não persistidas. Para obter mais informações sobre como configurar o parâmetro de tempo limite de inatividade da sessão, consulte Políticas de sessão.
Práticas recomendadas¶
Esta seção descreve as melhores práticas a serem seguidas ao usar o pandas on Snowflake.
Evite usar padrões de código iterativos, como loops
for,iterrowseiteritems. Padrões de código iterativos aumentam rapidamente a complexidade da consulta gerada. Deixe que o pandas on Snowflake, e não o código do cliente, realize a distribuição de dados e a paralelização de computação. Com relação a padrões de código iterativos, procure operações que possam ser realizadas em todo o DataFrame e use as operações correspondentes.
Evite chamar
apply,applymapetransform, que acabam sendo implementadas com UDFs ou UDTFs, que podem não ser tão eficientes quanto consultas SQL regulares. Se a função aplicada tiver uma operação equivalente em DataFrame ou série, use essa operação. Por exemplo, em vez dedf.groupby('col1').apply('sum'), chame diretamentedf.groupby('col1').sum().Chame
to_pandas()antes de passar o DataFrame ou série para uma biblioteca de terceiros. O pandas on Snowflake não fornece garantia de compatibilidade com bibliotecas de terceiros.Use uma tabela Snowflake regular materializada para evitar sobrecarga extra de E/S. O pandas on Snowflake funciona sobre um instantâneo de dados que funciona apenas para tabelas regulares. Para outros tipos, incluindo tabelas externas, exibições e tabelas Apache Iceberg™, uma tabela temporária é criada antes da captura do instantâneo, o que introduz uma sobrecarga extra de materialização.
O pandas on Snowflake fornece capacidade de clonagem rápida e zero-copy ao criar DataFrames de tabelas Snowflake usando
read_snowflake.Verifique novamente o tipo de resultado antes de prosseguir com outras operações e faça a conversão de tipo explícita com
astype, se necessário.Devido à capacidade limitada de inferência de tipo, se nenhuma dica de tipo for fornecida,
df.applyretornará resultados do tipo objeto (variante) mesmo que o resultado contenha todos os valores inteiros. Se outras operações exigirem que odtypesejaint, você pode fazer uma conversão de tipo explícita chamando o métodoastypepara corrigir o tipo de coluna antes de continuar.Evite chamar APIs que exijam avaliação e materialização, a menos que seja necessário.
APIs que não retornam
SeriesouDataframeexigem avaliação e materialização adiantadas para produzir o resultado no tipo correto. O mesmo vale para métodos de plotagem. Reduza as chamadas para aquelas APIs para minimizar avaliações e materializações desnecessárias.Evite chamar
np.where(<cond>, <escalar>, n)em grandes conjuntos de dados. O<escalar>será transmitido para um DataFrame do tamanho de<cond>, o que pode ser lento.Ao trabalhar com consultas construídas iterativamente,
df.cache_resultpode ser usado para materializar resultados intermediários e reduzir a avaliação repetida, melhorar a latência e reduzir a complexidade da consulta geral. Por exemplo:No exemplo acima, a consulta para produzir
df2é cara para computar e é reutilizada na criação dedf3edf4. Materializandodf2em uma tabela temporária (fazendo operações subsequentes envolvendo uma varredura de tabeladf2em vez de um pivô) pode reduzir a latência geral do bloco de código:
Exemplos¶
Aqui está um exemplo de código com operações do pandas. Começamos com um DataFrame Snowpark pandas chamado pandas_test, que contém três colunas: COL_STR, COL_FLOAT e COL_INT. Para exibir o notebook associado a esses exemplos, consulte os exemplos do pandas on Snowflake no repositório Snowflake-Labs.
Salvamos o DataFrame como uma tabela do Snowflake chamada pandas_test, que usaremos em todos os nossos exemplos.
Em seguida, criamos um DataFrame a partir da tabela Snowflake. Nós descartamos a coluna COL_INT e então salvamos o resultado de volta no Snowflake com uma coluna chamada row_position.
O resultado é uma nova tabela, pandas_test2, que se parece com isto:
IO (leitura e gravação)¶
Para obter mais informações, consulte Entrada/Saída.
Indexação¶
Valores ausentes¶
Conversão de tipo¶
Operações binárias¶
Agregação¶
Merge¶
Groupby¶
Para obter mais informações, consulte GroupBy.