Tutorial: Snowflake Native SDK for Connectors example Java connector¶
Introduction¶
Welcome to our tutorial on an example connector built using Snowflake Native SDK for Connectors. This guide will show you how to build, deploy, install, and configure an example connector.
Provided example application ingests GitHub issues data, by connecting to the GitHub API to pull information about issues from the specified repositories.
In this tutorial you will learn how to:
- Build an example connector from sources
- Deploy a new application package and version
- Install a new application instance
- Configure the connector instance to ingest data
Prerequisites¶
Before getting started please make sure that you meet the following requirements:
- Basic knowledge of Java
- Basic knowledge of Snowflake Native Apps
- Basic knowledge of Streamlit UI
- Access to a Snowflake account with an
ACCOUNTADMINrole - GitHub account, which can create GitHub apps
- MacOS or Linux machine to build the project and run deployment scripts
Prepare your local environment¶
Before proceeding you need to make sure all necessary software is installed on your machine and clone the example connector repository.
Java installation¶
Snowflake Native SDK for Connectors requires Java LTS (Long-Term Support) version 11 or higher. If the minimum required version of Java is not installed on your machine, you must install either Oracle Java or OpenJDK.
Oracle Java¶
The latest LTS release of the JDK is free to download and use, at no cost, under the Oracle NFTC. For download and installation instructions go to the Oracle page.
OpenJDK¶
OpenJDK is an open-source implementation of Java. For download and installation instructions go to openjdk.org and jdk.java.net.
You may also use a 3rd party OpenJDK version, such as Eclipse Temurin or Amazon Corretto.
Repository cloning¶
Clone the connectors-native-sdk repository to your machine.
Snowflake CLI configuration¶
The Snowflake CLI tool is required to build, deploy, and install the connector. If you do not have Snowflake CLI on your machine, install it as per instructions available in Installing Snowflake CLI.
After the tool is installed, you need to configure a connection to Snowflake in your configuration file.
If you do not have any connections configured, create a new one named native_sdk_connection. You
can find an example connection in the deployment/snowflake.toml file.
If you already have a connection configured and would like to use it with the connector, use its
name instead of native_sdk_connection whenever this connection is used in this tutorial.
Project structure¶
The Snowflake Native SDK for Connectors project consists of a couple main elements.
Connectors Native SDK Java¶
The connectors-native-sdk-java directory contains all the Snowflake Native SDK for Connectors Java code, with unit
and integration tests for the SDK components. Because of the nature of Native Apps inside Snowflake,
this means not only Java code, but also SQL code, which is necessary to create a working application.
The definitions of the database objects can be found inside src/main/resources directory. Those
files are used while creating an application to customize which objects will be available inside the
application. In the example connector we use the all.sql file, which creates objects for all
available features. This file will be executed during the installation process of the application
instance.
Connectors Native SDK Test Java¶
The connectors-native-sdk-test-java directory contains source code of a helper library used in
unit tests, e.g. objects used to mock particular components, custom assertions etc. Those files are
not a part of the connector application.
Example Java GitHub connector¶
The actual example connector is located inside examples/connectors-native-sdk-example-java-github-connector
directory. The app/ directory contains all the files needed to run the Native App:
- The
app/streamlit/directory contains source files necessary to run the Streamlit UI of the connector. - The
setup.sqlfile is run during the application installation and is responsible for creating the necessary database objects. This file will execute theall.sqlfile mentioned before, as well as some custom sql code. - The
manifest.ymlfile is the manifest of the Native App. It is required to create an application package and then the application instance itself. This file specifies application properties, as well as permissions needed by the application.
Additionally the examples/connectors-native-sdk-example-java-github-connector directory contains
the src/ subdirectory, which contains custom connector logic, such as implementation of the
required classes and customizations of the default SDK components.
Connectors Native SDK Template¶
A template Gradle Java project which uses Snowflake Native SDK for Connectors as a dependency to help you quickly build a new connector. You can read more about in Tutorial: Snowflake Native SDK for Connectors Java connector template.
Build, deployment, and installation¶
The following sections will show you how to build, deploy, and install the example connector.
Build the connector¶
Building a connector created using Snowflake Native SDK for Connectors is a bit different from building a typical Java application. There are some things which must be done besides just building the .jar archives from the sources. Building the application consists of the following steps:
- Copying custom internal components to the build directory
- Copying SDK components to the build directory
Copy internal components¶
This step builds the connector .jar file and then copies it (along with the UI, manifest and setup files)
to the sf_build directory.
To run this step execute the command: ./gradlew copyInternalComponents.
Copy SDK components¶
This step copies the SDK .jar file (added as a dependency to the connector Gradle module) to the
sf_build directory and extracts bundled .sql files from the .jar archive.
Those .sql files allow the customization of which provided objects will be created during the
application installation. For the first time users customization is not recommended, because omitting
objects may cause some features to fail if done incorrectly. The example connector application uses
the all.sql file, which creates all recommended SDK objects.
To run this step execute the command: ./gradlew copySdkComponents.
Deploy the connector¶
To deploy a Native App an application package needs to be created inside Snowflake. After that all
the files from the sf_build directory need to be uploaded to Snowflake.
Please note that for development purposes, version creation is optional, an application instance can be created directly from staged files. This approach allows you to see changes in most of the connector files without recreating the version and application instance.
The following operations will be performed:
- Create a new application package, if it does not already exist
- Create a schema and file stage inside the package
- Upload files from the
sf_builddirectory to the stage (this step may take some time)
To deploy the connector execute the command: snow app deploy --connection=native_sdk_connection.
For more information about the snow app deploy command see snow app deploy.
The created application package will now be visible in the App packages tab, in the
Data products category, in the Snowflake UI of your account.
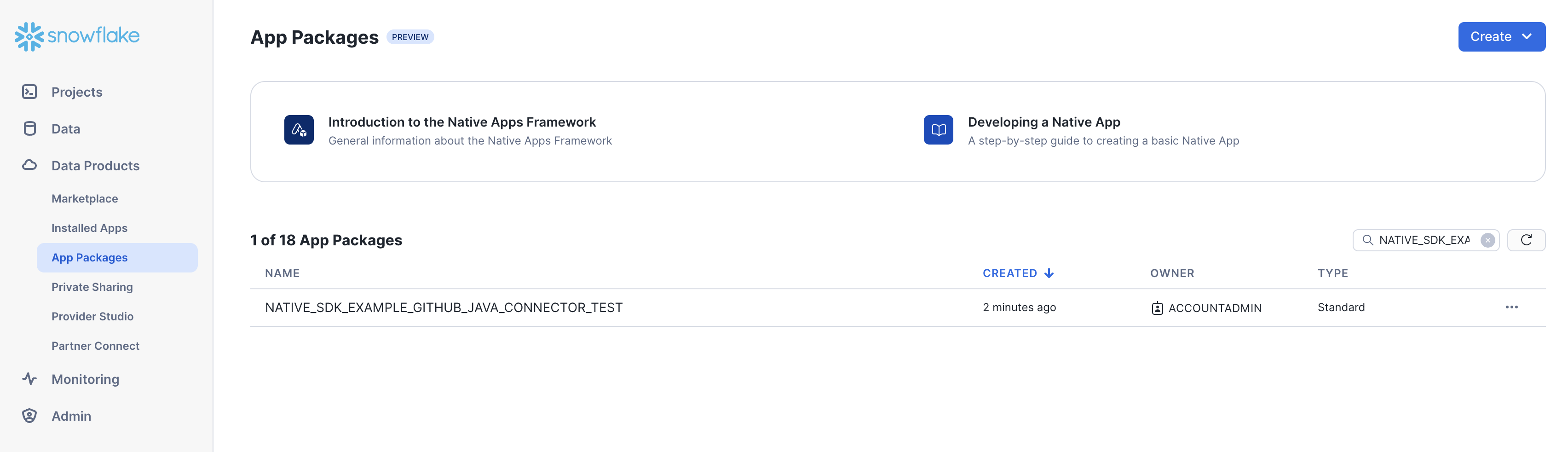
Install the connector¶
Installation of the application is the last step of the process. It creates an application from the application package created previously.
To install the connector execute the command: snow app run --connection=native_sdk_connection.
For more information about the snow app run command see snow app run.
The installed application will now be visible in the Installed apps tab, in the
Data products category, in the Snowflake UI of your account.
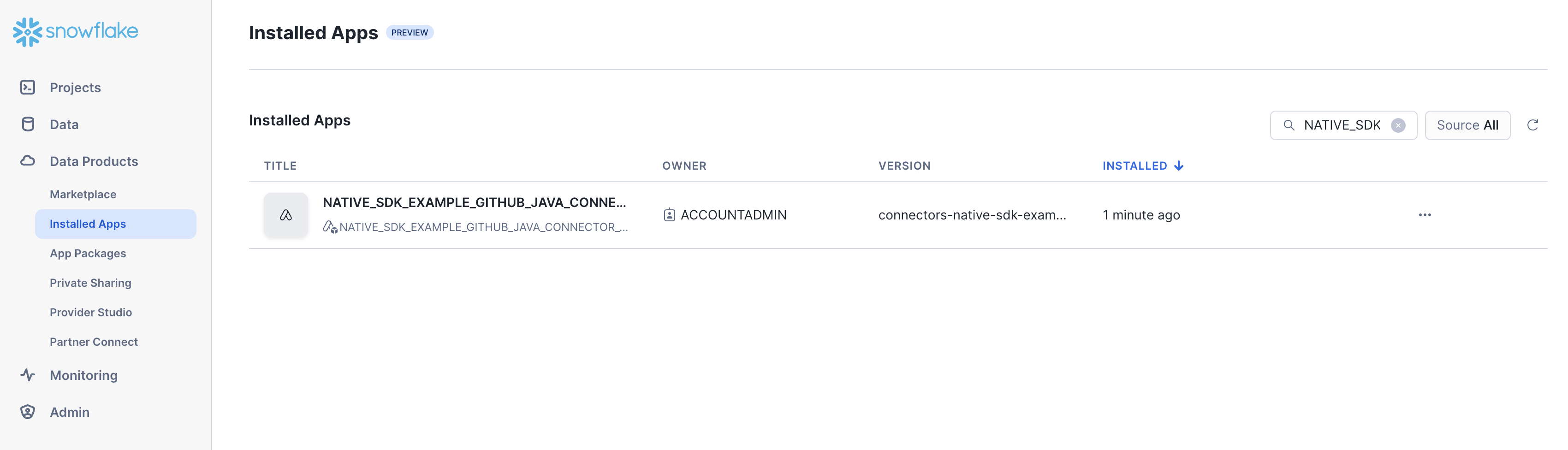
Update connector files¶
If at any point you wish to modify any of the connector files, you can easily upload the modified files into the application package stage. The upload command depends on which files were updated.
Before any of the update commands are run, you have to copy the new files of your connector to the
sf_build directory by running: ./gradlew copyInternalComponents
UI .py files or connector .java files¶
Use the snow app deploy --connection=native_sdk_connection command, the current application
instance will use the new files without reinstallation.
setup.sql or manifest.yml files¶
Use the snow app run --connection=native_sdk_connection command, the current application
instance will be reinstalled after the new files are uploaded to stage.
Connector flow¶
Before we move to configuring the connector and ingesting the data, we should have a quick look at how the connector actually works. Below you can see all the steps that will be completed in the next steps of this tutorial. The starting point will be completing the prerequisites and going through the Wizard.
The Wizard stage of the connector guides the users through all the required configurations needed by the connector. The Daily Use stage allows user to view statistics, configure repositories for ingestion and pause/resume the connector.

Configuration Wizard¶
After opening the application the Wizard UI page will be opened. The connector needs some information provided by the user before it can start ingesting data. The Wizard will guide you through all the required steps in the application itself, but also on the whole Snowflake account and sometimes even the external system that will be the source of the ingested data, in this case GitHub. After all these steps are finished, the connector will be ready to start ingesting the data.
Prerequisites¶
The first step of the Wizard are the prerequisites. This step will provide you a list of things which should be prepared before configuring the connector. Completing the prerequisites is not required, but it is recommended to ensure smoother configuration process later.
In the case of the example GitHub connector there are two things that need to be taken care of before going further:
- Preparing a GitHub account
- Confirming access to the GitHub repositories you want to ingest
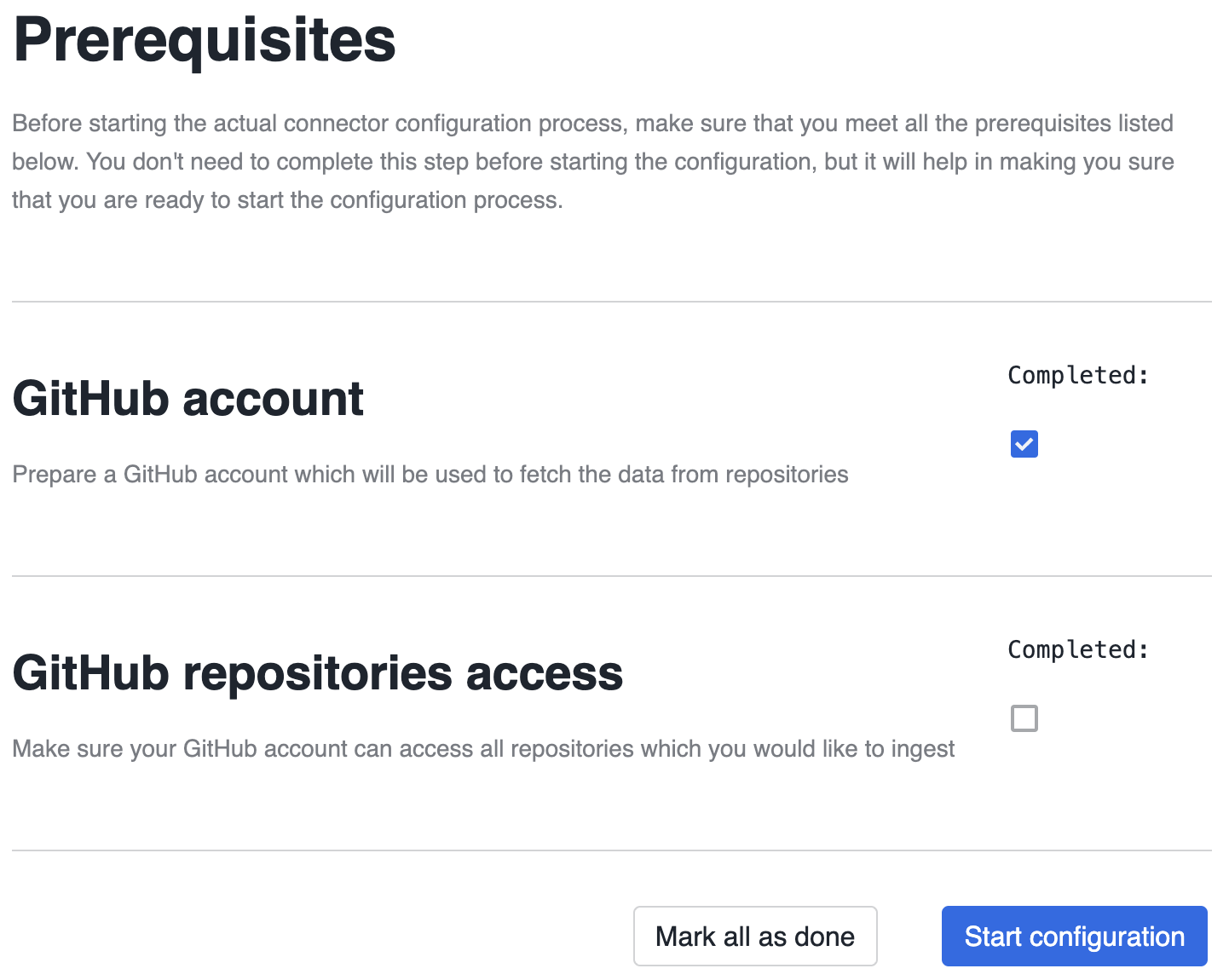
Connector Configuration¶
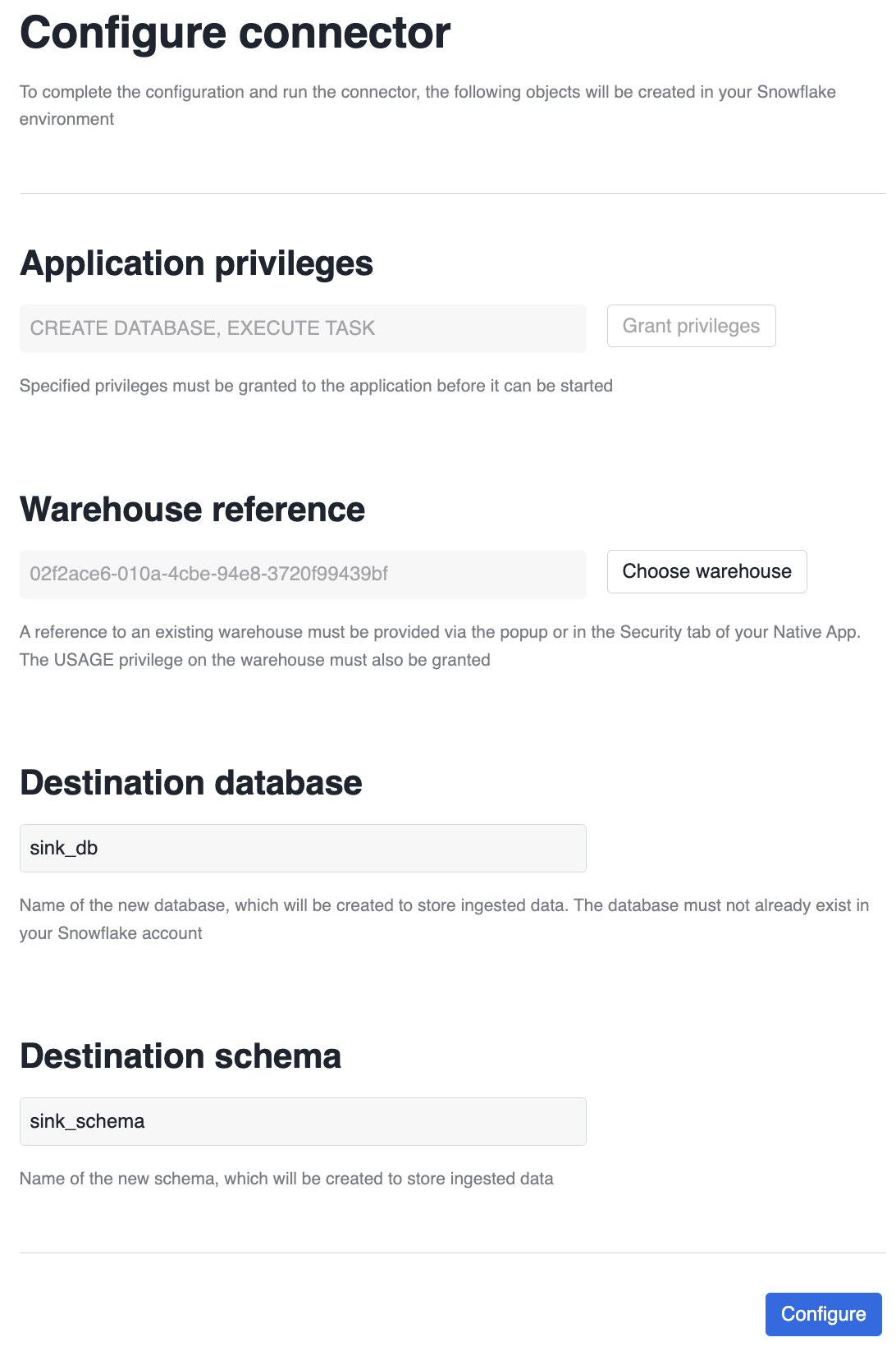
Next step of the Wizard is connector configuration. This step allows the user to:
- Grant application privileges, which are requested using the Native Apps Permission SDK
- Choose a warehouse which will be referenced when scheduling ingestion tasks
- Choose destination database and schema for the data that will be ingested
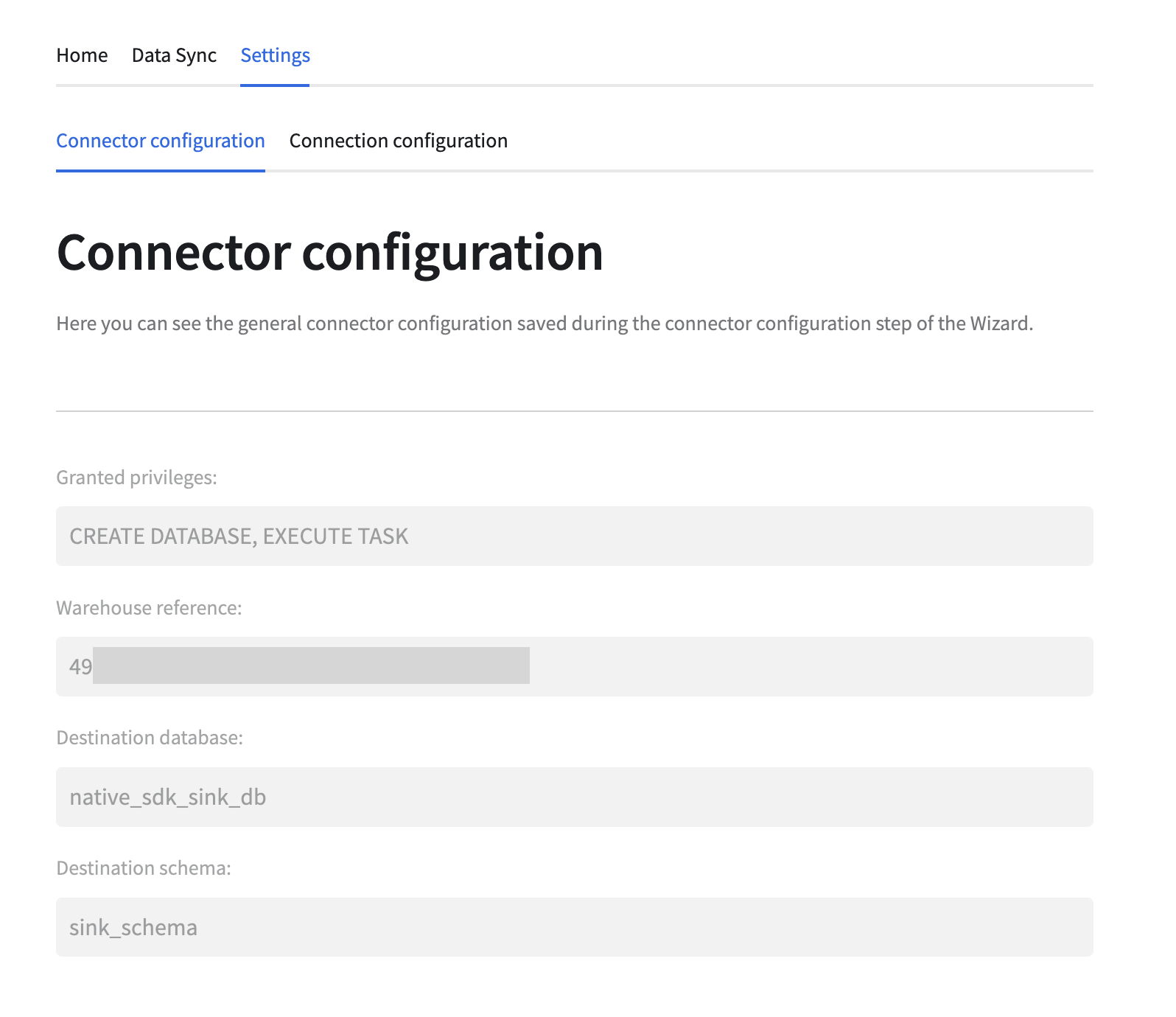
Privileges¶
Application requires two account level permissions to operate: CREATE DATABASE and EXECUTE TASK.
The first privilege is needed to create a destination database for the ingested data. This database should be created outside the application, so that the ingested data can be left intact if the application is uninstalled. However, this example does not support this feature, a new database is always created.
The second privilege is needed to schedule periodic tasks that will fetch the data from GitHub and save it in the destination database.
Granting those privileges can be done using the security tab or by pressing the Grant privileges
button in the connector configuration screen. The latter one will result in a popup appearing on the
screen.
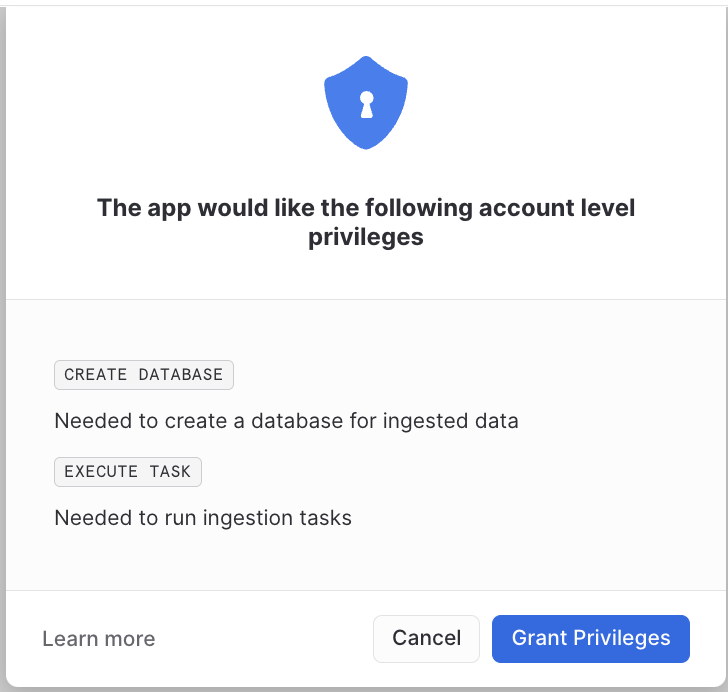
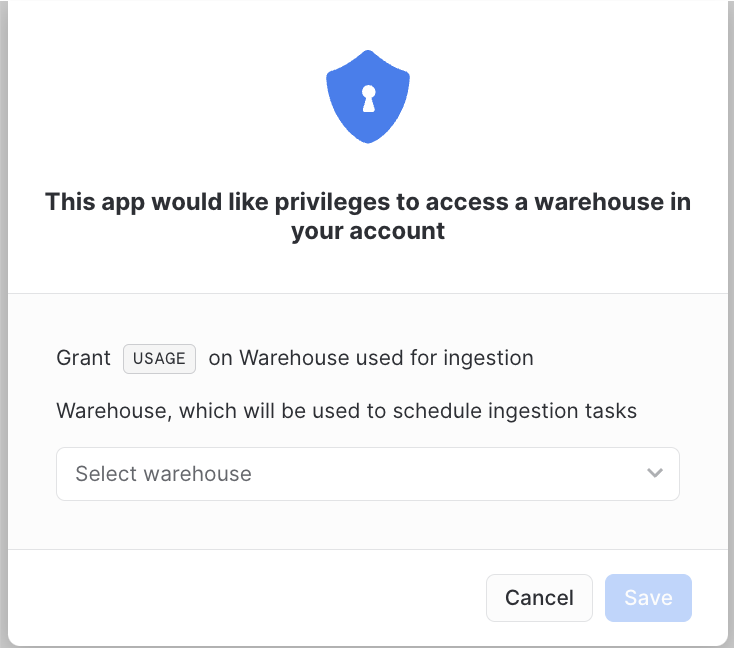
Warehouse reference¶
The connector requires a warehouse to run and schedule ingestion tasks. Application will use the
warehouse through a reference.
Warehouse reference is defined in the manifest.yml file:
The reference can set using the security tab, the same as the privileges above, or by pressing the
Choose warehouse button.
Destination database and schema¶
As mentioned before, the connector requires a database to store the ingested data. This database will be created, during a later step, with the schema specified by the user. Name of the database is up to the user, as long as the provided database does not already exist.
The completed connector configuration screen will look similar to this one:
Connection Configuration¶
Next step of the Wizard is connection configuration. This step allows user to set up the connection to an external data source. We recommend using OAuth2 authentication whenever possible, instead of using user/password or plaintext tokens.
GitHub currently supports two ways of OAuth2 authentication: OAuth apps and GitHub apps. OAuth apps are a bit easier to set up and use, however they do not provide the same level of permission control granularity. We recommend using a GitHub app for this example; however if you wish to use an OAuth app, the connector will still work as intended.
Permission SDK setup¶
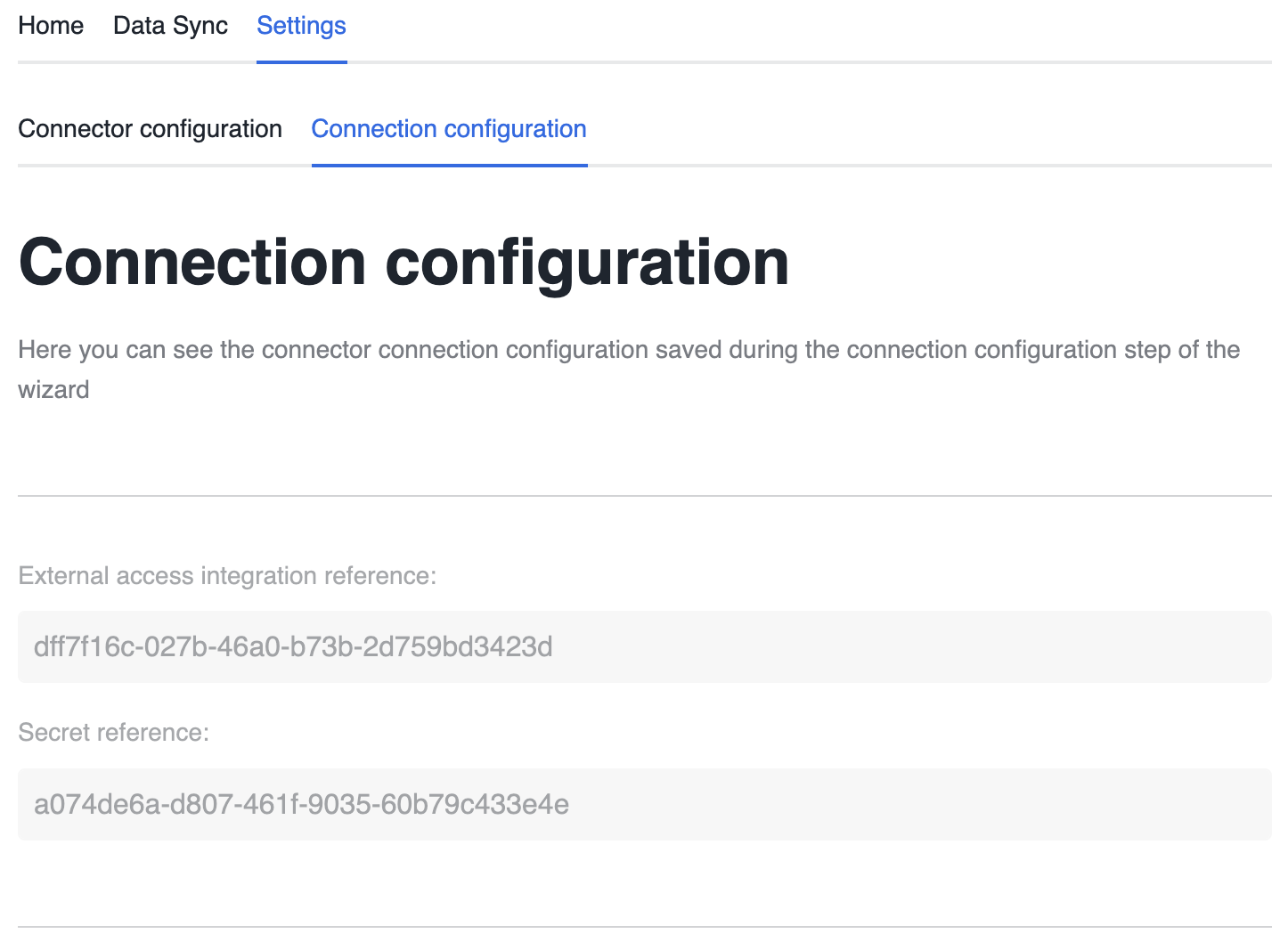
OAuth2 authentication requires a security integration, secret and external access integration to be created in the user’s account. Our connector uses the Native Apps Permission SDK to request the creation of those objects.
References for the external access integration and secret, which are needed by the connector, are
defined in the manifest.yml file:
In addition, a special procedure needs to be added in the setup.sql file. It is referenced in the
configuration_callback property for each of the references presented above:
For the external access integration reference the procedure provides:
host_ports- hostnames of the external data source, which will be accessed during ingestionsecret_references- array of names of references to OAuth secretsallowed_secrets-LIST, telling the Permission SDK to use secrets specified in thesecret_referencesfield
For the secret reference the procedure provides:
type-OAUTH2in case of our secretsecurity_integration- properties of the created security integration:oauth_scopes- a list of OAuth scopes requested by the connector (if using a GitHub app - this field is optional)oauth_token_endpoint- endpoint from which the refresh and access token will be acquiredoauth_authorization_endpoint- endpoint to which the authorization request will be sent
GitHub app setup¶
The next step is the setup of a GitHub app in the user’s account. This app will be used to grant limited access to the account, so that data can be ingested.
The first step is to press the Request access button in the connector UI.
The first screen allows you to review the endpoints, for which external connectivity will be allowed.
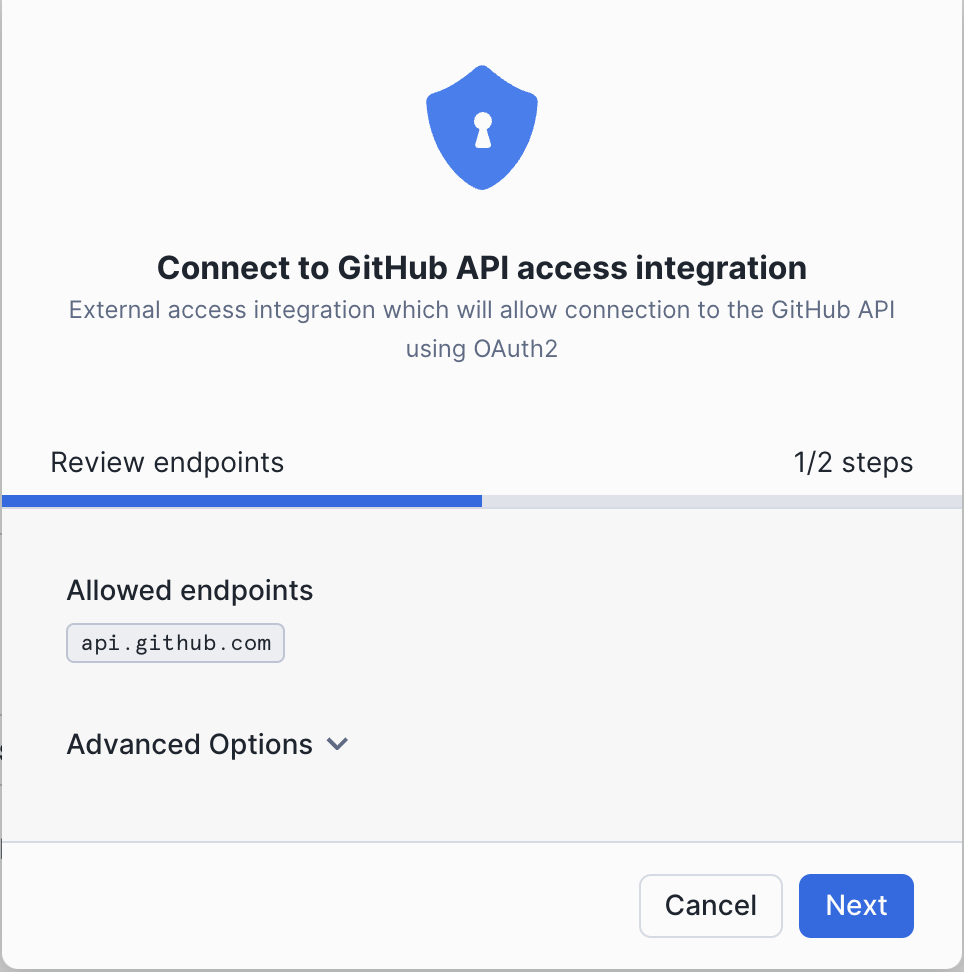
After pressing Next, you will see a second screen. Select OAuth2 to create a new integration
and secret, and copy the provided redirect URL, it will contain your organization name and the
region of your account.
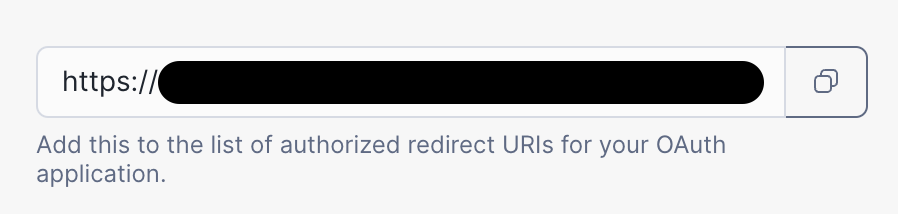
Next go to your GitHub account settings page, then into Developer settings > GitHub Apps and
press the New GitHub App button:
-
Enter the name and homepage URL of your app
-
Paste the redirect URL you copied into the
Callback URLfield -
Make sure the
Expire user authorization tokensoption is selected -
Make sure the
Request user authorization (OAuth) during installationis not selected -
If you do not need it, deselect the
Activeoption in theWebhooksection -
Select the permissions needed for the connector to work:
Repository permissions > Issueswith theRead-onlyaccessRepository permissions > Metadatawith theRead-onlyaccess
-
If the app will only be used by you, with this example connector, it is best to select
Only on this accountin the installation access section
After the app is created, press the Install app option in the left sidebar and install the
application in your account. You can choose which repositories the app (and by extension the
connector) will be able to access. Without this installation, the connector will only be able to
access public repositories.
OAuth integration setup¶
After installation return to your GitHub app and generate a new client secret. Make sure to copy it immediately, as it will not be shown again. Paste the client secret in the OAuth configuration popup of your connector. Finally, copy the client ID (not app ID) of your application and also paste it in the OAuth configuration popup of your connector.
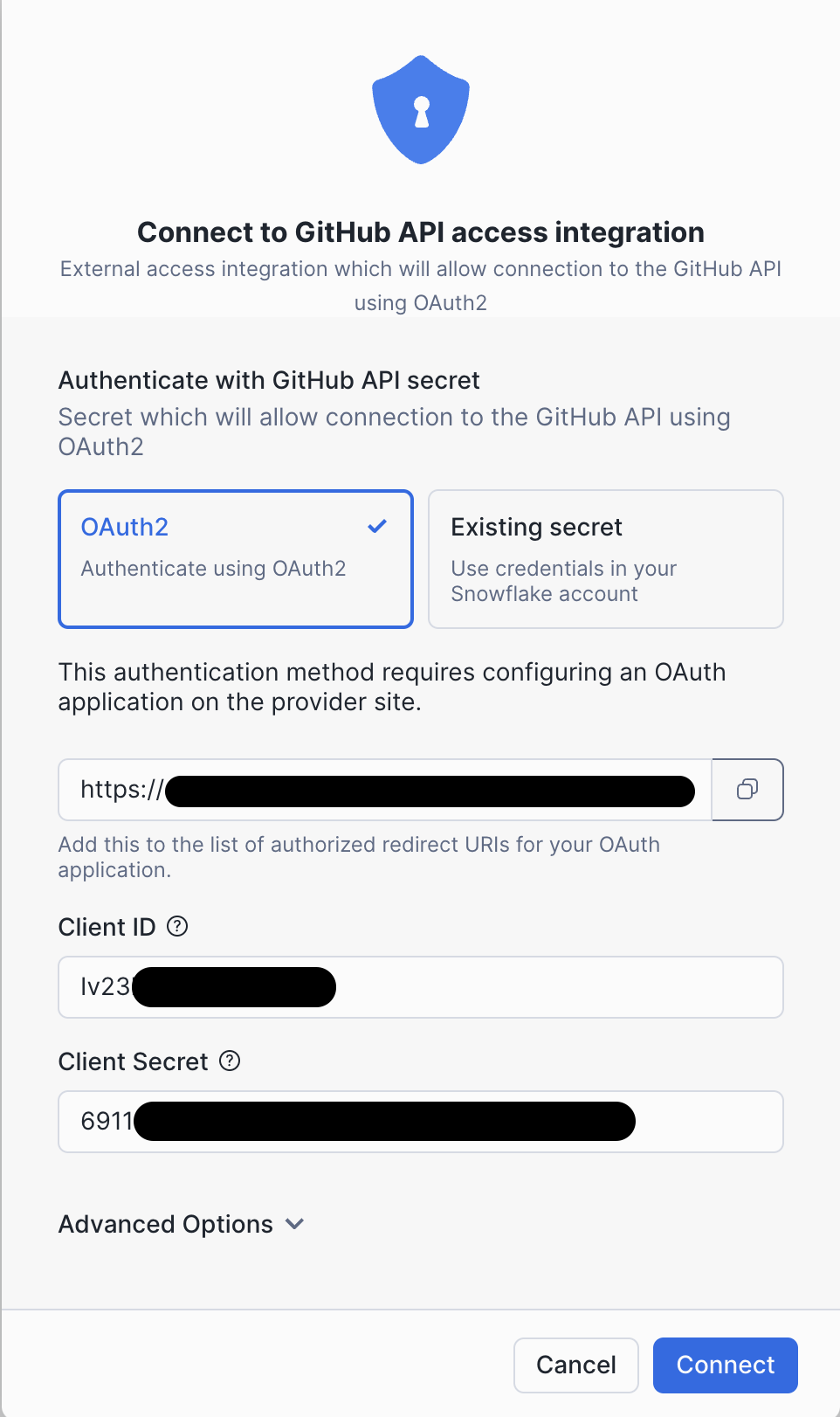
After pressing Connect a GitHub window will pop up, asking you for app authorization on your
GitHub account. After authorizing, you will be automatically redirected back to the connector UI.
After successful authorization (it may take a couple seconds to finish and close the popup) the
page will be populated with the IDs of external access integration and secret references.
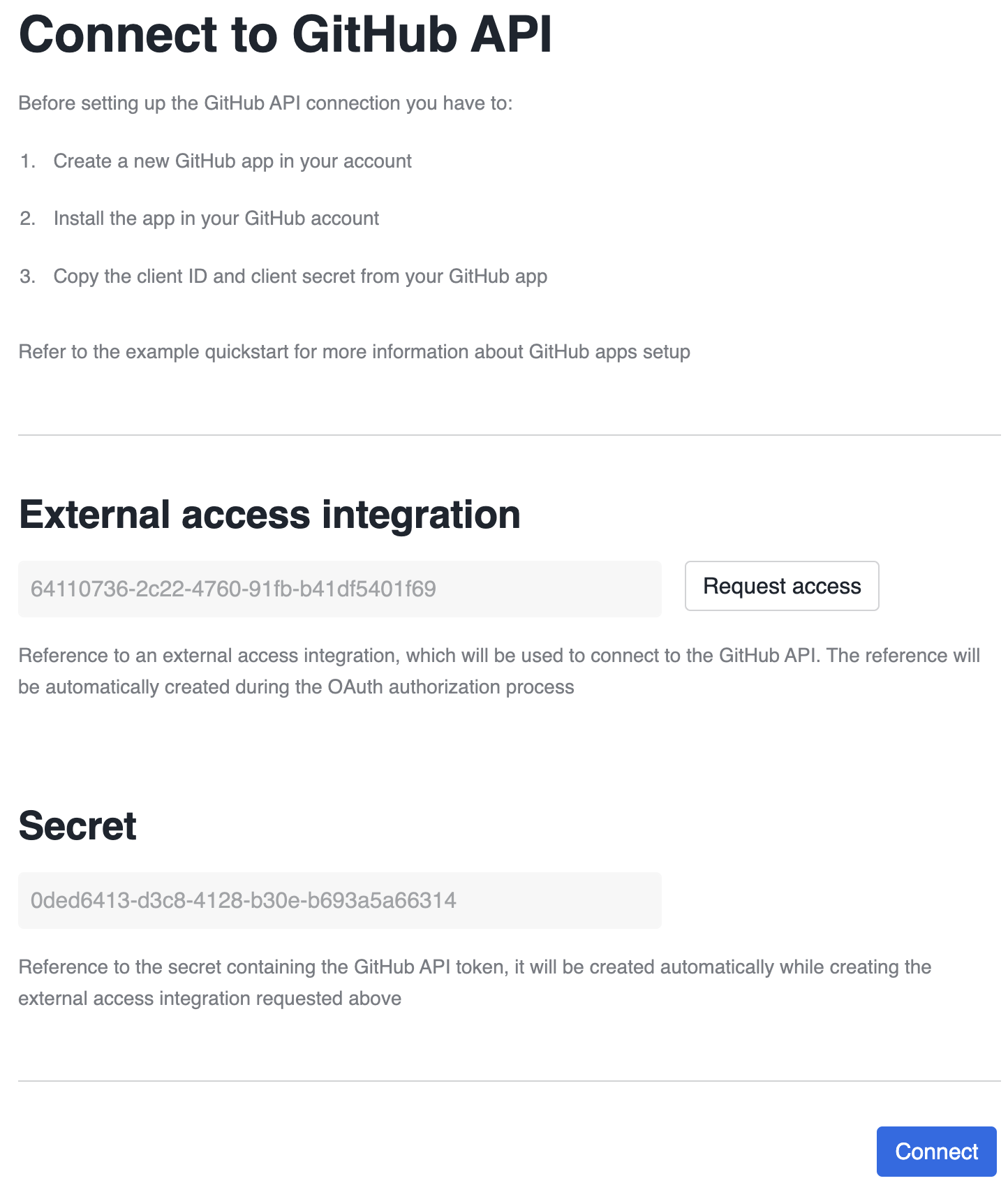
Pressing the Connect button will trigger the TEST_CONNECTION procedure inside the connector.
This procedure will try to access the GitHub API octocat endpoint,
to check if external connectivity was configured correctly, and the OAuth access token obtained
correctly.
When the test succeeds, application will proceed into the finalization step.
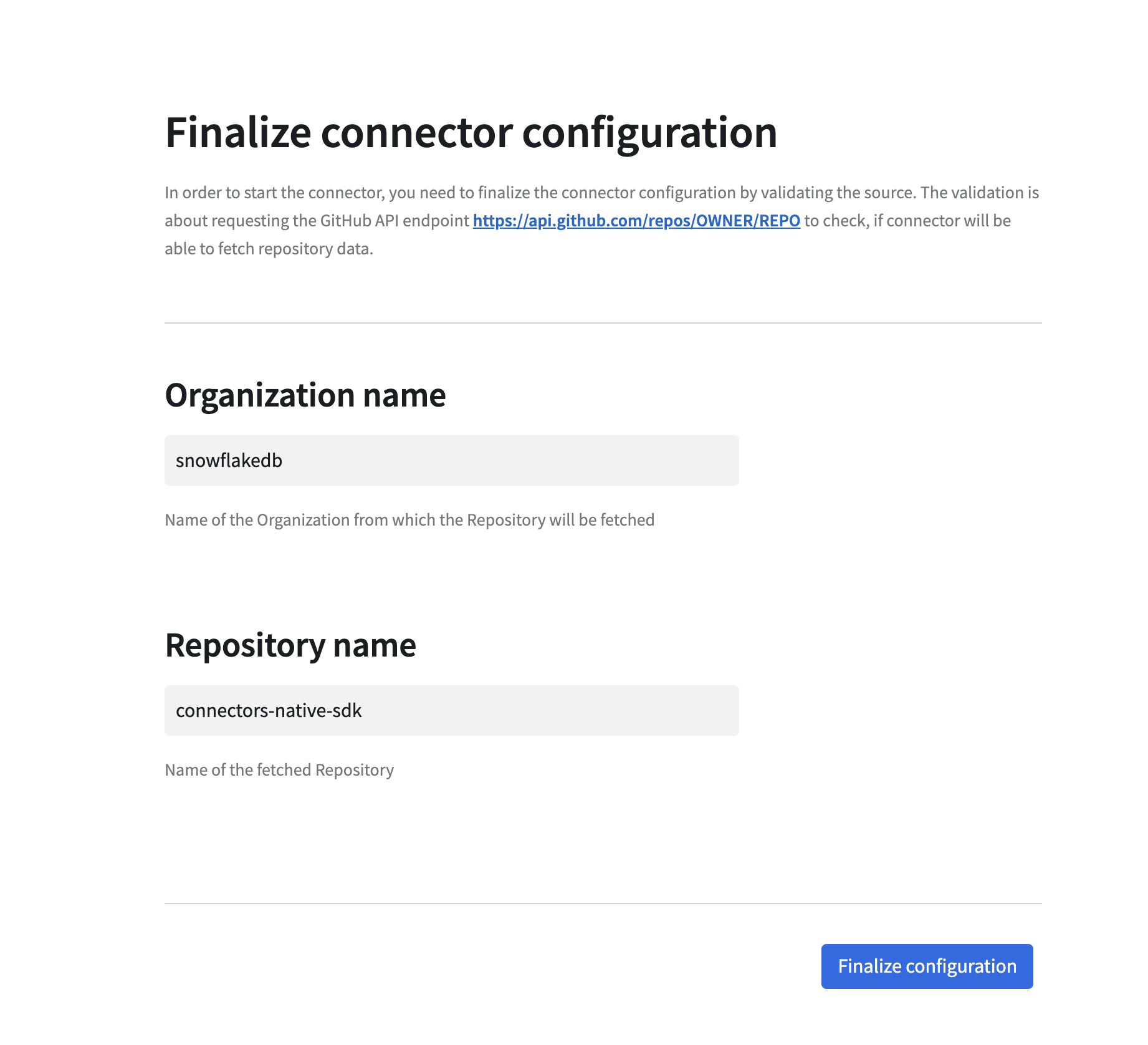
Configuration Finalization¶
Finalization is the last step of the Wizard. In this step you will be asked to provide an organisation and a repository name. This repository must be accessible with the OAuth token obtained during the connection configuration step. The provided repository will be used only for connection validation purposes.
This is a bit different from the previous step, because the TEST_CONNECTION procedure only checks
if the GitHub API is accessible and the provided token is valid.
Finalization step ensures that repository provided by user is accessible with the provided GitHub API token. It will fail if the token does not have required permissions to access the repository. If you would like to ingest data from private repositories, we recommend finalizing the configuration using a private repository, just to make sure they work correctly.
Additionally, during this step the database and schema specified in connector configuration phase will finally be created in your account.
Daily Use¶
After the Configuration Wizard is completed successfully you can now start using your example GitHub connector.
Next steps will explain:
- How to configure resources to ingest the data
- How the ingestion process works
- How to view statistics of the ingested records
- How to view ingested data
- How to pause and resume connector
Configuring resources¶
To configure resources go to the Data Sync tab. This tab displays a list of the repositories
already configured for ingestion. When opened for the first time the list will be empty.
To configure a resource enter the organisation and repository names in the designated fields, then
press the Queue ingestion button. For example:
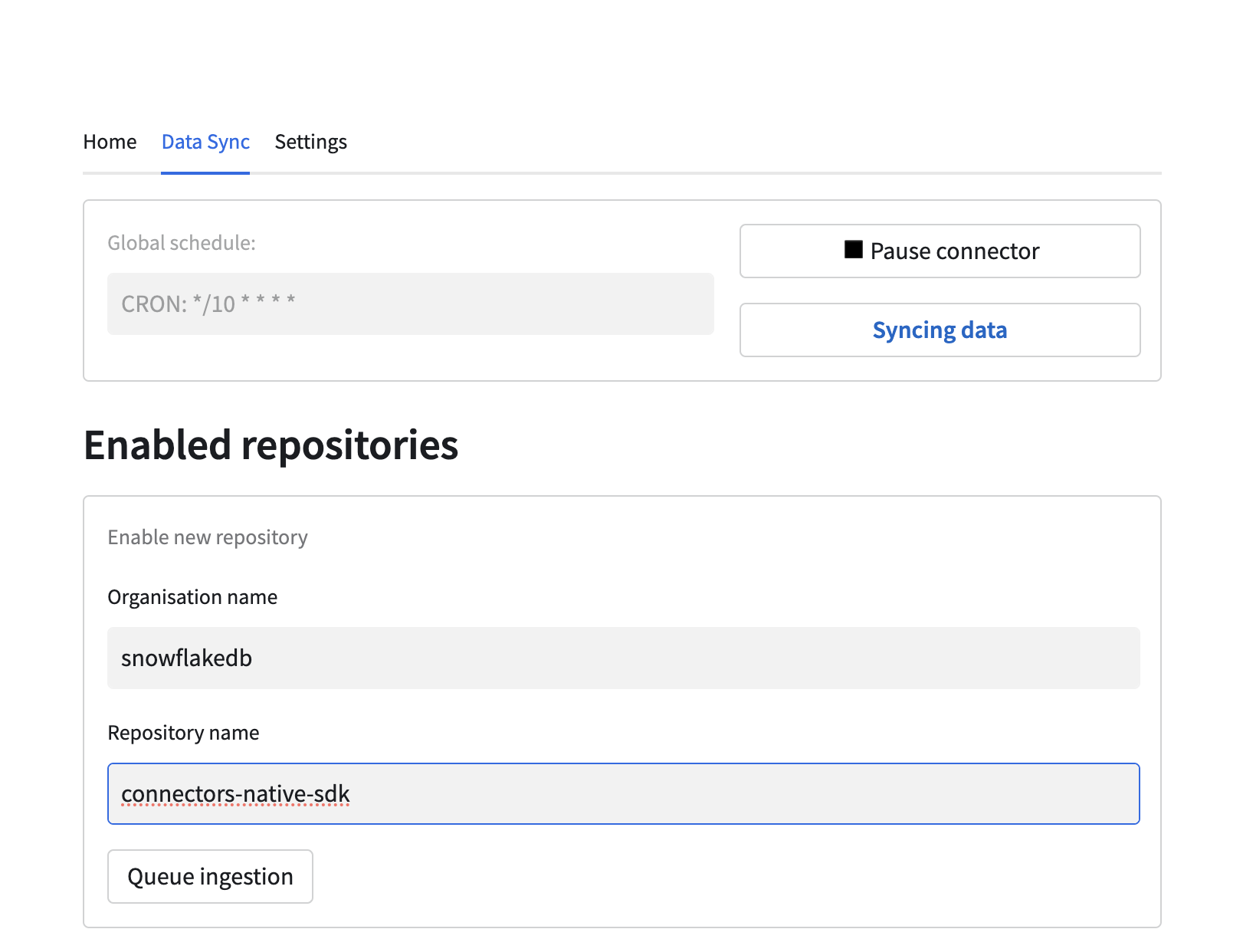
The definition for a new resource will be saved, and it will be picked up by the scheduler according to the global schedule. It will take some time before the data is ingested and visible in the sink table. It will be visible in the table below:
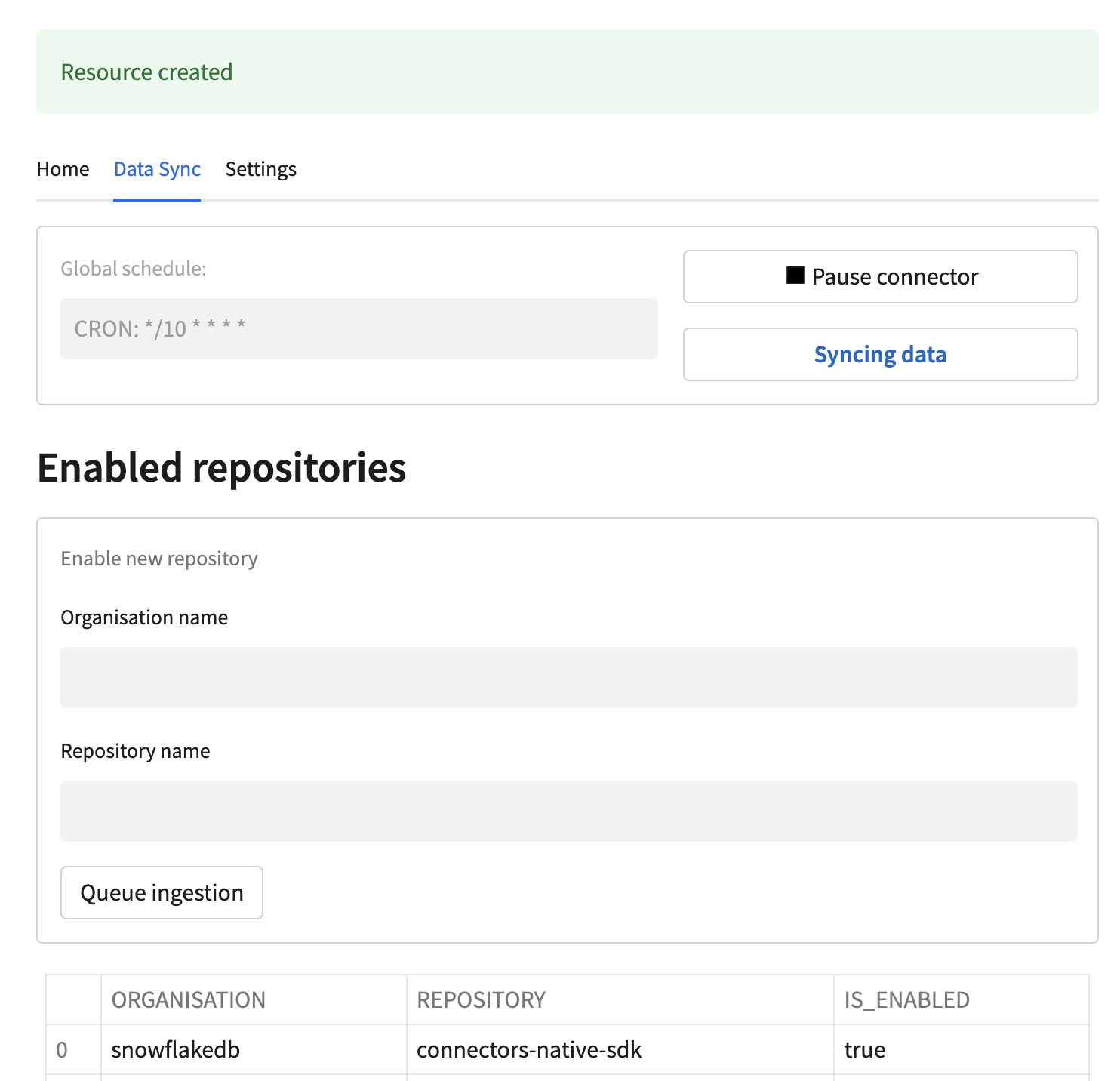
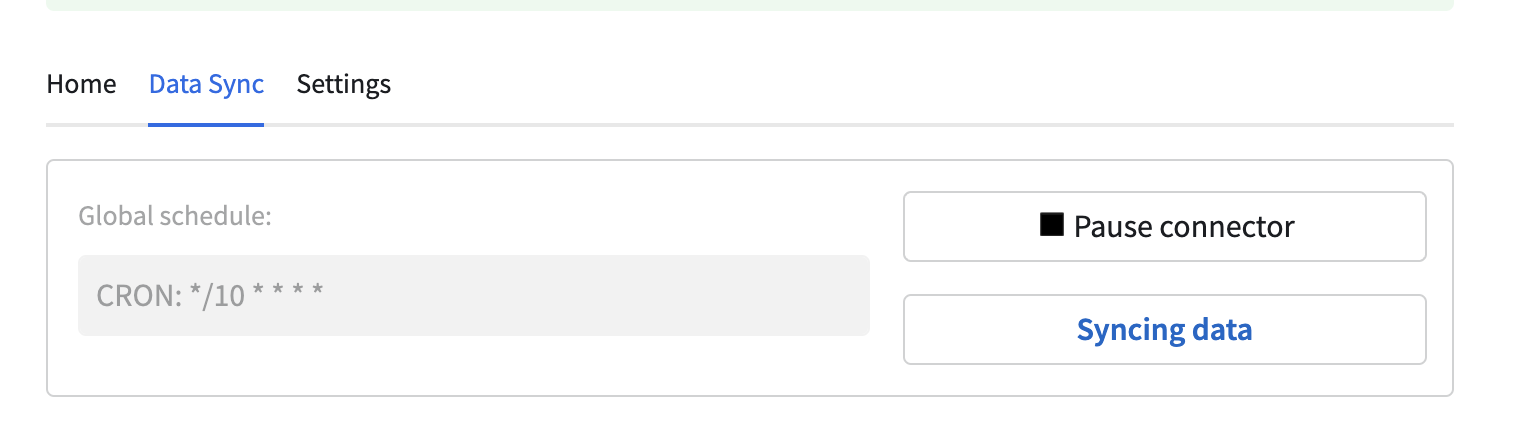
Ingestion schedule and status¶
At the top of the Data Sync tab there is a section containing general information about the
ingestion. This section allows the user to see the global schedule with which the configured resources
will be ingested. The label at the bottom right corner shows the current ingestion status. At first
it will show the NOT SYNCING state, until the first resource is defined. After that it will
transition to SYNCING, and finally when at least one resource ingestion is successfully
finished, it will show the finish date of that ingestion.
Ingestion process¶
Ingestion process is handled using a Scheduler Task and Task Reactor components. The scheduler
picks up the defined resources according to the global schedule and submits them as Work Items to
a queue. Then task reactor component called a Dispatcher picks them up and splits between the
defined number of workers. Each worker performs the actual ingestion for every item from the queue
that it picks up.
Singular ingestion of a resource consists of fetching the data from the endpoints in the GitHub API
and then saving them in the designated tables in the sink database. For this example purposes all
the data is fetched in every run, which results in new records being added to the table and old records
being updated. Additionally, execution of each Work Item includes logging data like the start and
end date, number of ingested rows, status etc. to internal connector tables, which are then used for
statistics purposes.
Viewing statistics¶
The Home screen contains statistics from the past ingestion runs. The data is based on the
PUBLIC.AGGREGATED_CONNECTOR_STATS view. The view aggregates the number of ingested rows based
on the hour of the day when it was ingested. The data from this view can be retrieved using SELECT
queries run in a worksheet, that way it can also be aggregated by a time window bigger than an hour.
There is another view named PUBLIC.CONNECTOR_STATS that is available through the worksheet. Using this
data, you can see the status, start and end date, average rows ingested per seconds and some other
information regarding data ingestion.
Example ingestion statistics chart:
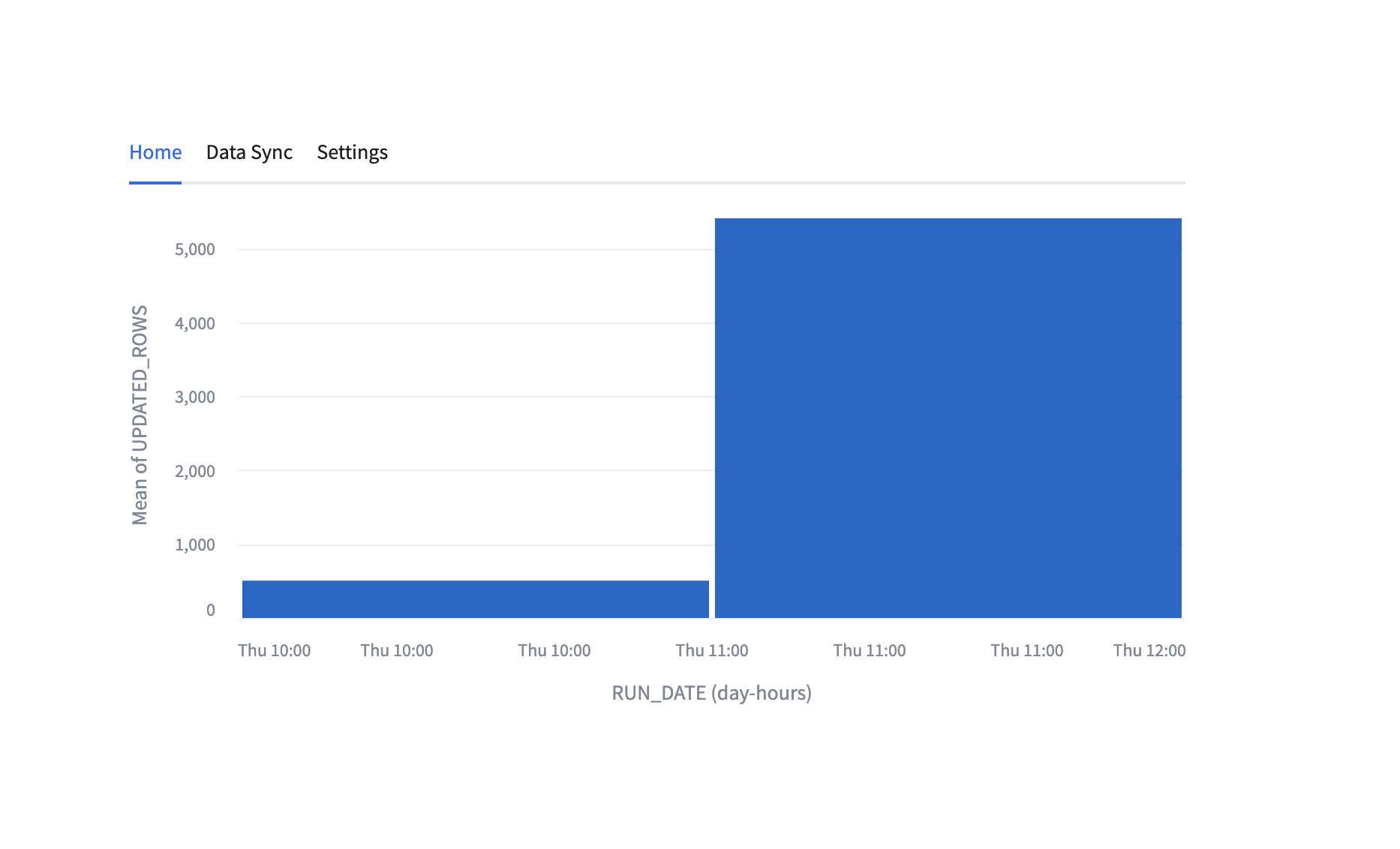
Viewing ingested data¶
Ingested data is not visible in the UI, but can be viewed by querying data from specific tables, by
users with ADMIN or DATA_READER roles. To view the data you must to go to a SQL worksheet and just
select the destination database. The destination database uses name and schema defined during the
connector configuration step. You can SELECT data from:
-
The
ISSUEStable, it contains the following columns:- ORGANIZATION
- REPOSITORY
- RAW_DATA
-
The
ISSUES_VIEWview, it contains the following columns:- ID
- ORGANIZATION
- REPOSITORY
- STATE
- TITLE
- CREATED_AT
- UPDATED_AT
- ASSIGNEE
Data visible in the ISSUES_VIEW view is extracted from the raw_data column found in the
ISSUES table. To see the data you can use one of the following queries:
Pausing and resuming¶
The connector can be paused and resumed, whenever desired. To do so just press the Pause button
in the Data Sync tab. When pausing is triggered the underlying scheduling and work execution mechanism
is disabled. However, any active ingestion work will finish before the connector actually goes into
the PAUSED state. Because of that, it can take up to a couple minutes for the connector to
fully pause.
To resume the connector, just have to press Resume button, which will be displayed in place of
the Pause button. This will resume the scheduling task which will start queueing new Work Items.
Connector settings¶
After configuration is finished one more tab called Settings becomes available. This tab allows
the user to see current connector and connection configurations. The data from this tab is extracted
from the underlying APP_CONFIG configuration table and is read only.
Troubleshooting¶
If the connector encounters any problems, they will be visible in the event table logs, if the
table is created and set in the account.
More on the enabling and using the event table, event logging, and event sharing in Native Apps
can be found in the documentation:
Cleanup¶
After the tutorial is completed you can either pause the connector as explained in the Daily Use section or completely remove it from your account using the command:
snow app teardown --connection=native_sdk_connection --cascade --force
The --cascade option is needed to remove the destination database without transferring the ownership
to the account admin. In real connectors the database should not be removed to preserve the ingested
data, it should be either owned by the account admin or ownership should be transferred before
uninstallation.
If the cleanup part is skipped, the example connector will consume credits until it is paused or removed, even if no repositories were configured for ingestion!
Customization¶
This tutorial has shown you an example connector built using Snowflake Native SDK for Connectors. To learn more about how to customize the connector, or build your own from scratch, see: