Développement de modèles de ML Snowflake¶
Note
L’API Snowflake ML Modeling est généralement disponible à partir du paquet snowflake-ml-python version 1.1.1.
L’API Snowflake ML Modeling utilise des frameworks Python familiers tels que scikit-learn, LightGBM et XGBoost pour le prétraitement des données, l’ingénierie des fonctions et l’entraînement des modèles à l’intérieur de Snowflake.
Les avantages du développement de modèles avec Snowflake ML Modeling incluent :
Ingénierie des fonctions et prétraitement : Améliorer les performances et l’évolutivité avec une exécution distribuée pour les fonctions de prétraitement scikit-learn fréquemment utilisées.
Entraînement des modèles : Accélérer l’entraînement pour les modèles scikit-learn, XGBoost et LightGBM sans avoir à créer manuellement des procédures stockées ou des fonctions définies par l’utilisateur (UDFs), en tirant parti de l’optimisation distribuée des hyperparamètres.
Astuce
Voir Introduction au machine learning pour un exemple de workflow de ML de bout en bout, y compris l’API de modélisation.
Note
Cette rubrique suppose que snowflake-ml-python et ses dépendances de modélisation sont déjà installés. Voir Utilisation de Snowflake ML en local.
Développement de modèles¶
Avec Container Runtime pour ML, disponible dans Notebooks sur Container Runtime, vous pouvez utiliser des paquets ML open source populaires avec vos données Snowflake, en exploitant un ou plusieurs nœuds GPU, au sein du Cloud Snowflake, garantissant la sécurité et la gouvernance de l’ensemble du flux de travail de ML. Le chargement des données et l’entraînement d’APIs inclus sont automatiquement distribués sur tous les CPUs ou GPUs sur un nœud, accélérant l’entraînement du modèle avec de grands ensembles de données.
Pour plus d’informations, voir Prise en main de Snowflake Notebook Container Runtime, qui présente une simple flux de travail de ML exploitant les capacités de Container Runtime pour ML.
Outre la flexibilité et la puissance de Container Runtime pour ML, l’API Snowflake ML Modeling fournit des estimateurs et des transformateurs qui ont des APIs similaires à celles des bibliothèques scikit-learn, xgboost et lightgbm. Vous pouvez utiliser ces APIs pour construire et entraîner des modèles de machine learning qui peuvent être utilisés avec Snowflake ML Operations, comme le registre des modèles de Snowpark.
Exemples¶
Examinez les exemples suivants pour vous faire une idée des similitudes entre l’API Snowflake Modeling et les bibliothèques de machine learning que vous connaissez peut-être.
Prétraitement¶
Cet exemple illustre l’utilisation des fonctions de prétraitement et de transformation des données de Snowflake Modeling. Les deux fonctions de prétraitement utilisées dans l’exemple (MixMaxScaler et OrdinalEncoder) utilisent le moteur de traitement distribué de Snowflake pour améliorer considérablement les performances par rapport aux implémentations côté client ou des procédures stockées. Pour plus de détails, voir Prétraitement distribué.
import numpy as np
import pandas as pd
import random
import string
from sklearn.datasets import make_regression
from snowflake.ml.modeling.preprocessing import MinMaxScaler, OrdinalEncoder
from snowflake.ml.modeling.pipeline import Pipeline
from snowflake.snowpark import Session
# Create a session with your preferred method
# session =
NUMERICAL_COLS = ["X1", "X2", "X3"]
CATEGORICAL_COLS = ["C1", "C2", "C3"]
FEATURE_COLS = NUMERICAL_COLS + CATEGORICAL_COLS
CATEGORICAL_OUTPUT_COLS = ["C1_OUT", "C2_OUT", "C3_OUT"]
FEATURE_OUTPUT_COLS = ["X1_FEAT_OUT", "X2_FEAT_OUT", "X3_FEAT_OUT", "C1_FEAT_OUT", "C2_FEAT_OUT", "C3_FEAT_OUT"]
# Create a dataset with numerical and categorical features
X, _ = make_regression(
n_samples=1000,
n_features=3,
noise=0.1,
random_state=0,
)
X = pd.DataFrame(X, columns=NUMERICAL_COLS)
def generate_random_string(length):
return "".join(random.choices(string.ascii_uppercase, k=length))
categorical_feature_length = 2
categorical_features = {}
for c in CATEGORICAL_COLS:
categorical_column = [generate_random_string(categorical_feature_length) for _ in range(X.shape[0])]
categorical_features[c] = categorical_column
X = X.assign(**categorical_features)
features_df = session.create_dataframe(X)
# Fit a pipeline with OrdinalEncoder and MinMaxScaler on Snowflake
pipeline = Pipeline(
steps=[
(
"OE",
OrdinalEncoder(
input_cols=CATEGORICAL_COLS,
output_cols=CATEGORICAL_OUTPUT_COLS,
)
),
(
"MMS",
MinMaxScaler(
input_cols=NUMERICAL_COLS + CATEGORICAL_OUTPUT_COLS,
output_cols=FEATURE_OUTPUT_COLS,
)
),
]
)
pipeline.fit(features_df)
# Use the pipeline to transform a dataset.
result = pipeline.transform(features_df)
Chargement des données¶
![]() Fonctionnalité en avant-première — Ouvrir
Fonctionnalité en avant-première — Ouvrir
Disponible pour tous les comptes.
Cet exemple montre comment charger des données d’une table Snowflake vers un pandas DataFrame ou un ensemble de données pytorch utilisant l’API DataConnector , qui répartit l’ingestion de données sur plusieurs cœurs ou GPUs pour accélérer le chargement.
Note
L’API DataConnector est disponible dans Container Runtime pour ML et peut être utilisée à partir des Notebooks Snowsight exécutés sur Snowpark Container Services (SPCS).
from snowflake.ml.data.data_connector import DataConnector
# Retrieve data from a snowflake table
table_name = 'LARGE_TABLE_MULTIPLE_GBs'
snowpark_df = session.table(table_name)
# Materialize it into a pandas dataframe using DataConnector
pandas_df = DataConnector.from_dataframe(snowpark_df).to_pandas()
# Materialize it into a pytroch dataset using DataConnector
torch_dataset = data.to_torch_dataset(batch_size=1024)
Formation¶
Cet exemple montre comment entraîner un modèle de classificateur xgboost simple en utilisant Snowflake ML Modeling, puis comment exécuter des prédictions. Ici, l’API est similaire à xgboost, avec seulement quelques différences près dans la façon dont les colonnes sont spécifiées. Pour plus de détails sur ces différences, voir Différences générales entre les API.
import pandas as pd
from sklearn.datasets import make_classification
from snowflake.ml.modeling.xgboost import XGBClassifier
from snowflake.ml.utils.connection_params import SnowflakeLoginOptions
from snowflake.snowpark import Session
# Create a session with your preferred method
# session =
FEATURE_COLS = ["X1", "X2", "X3", "X4", "X5", "X6"]
LABEL_COLS = ["Y"]
OUTPUT_COLS = ["PREDICTIONS"]
# Set up data.
X, y = make_classification(
n_samples=40000,
n_features=6,
n_informative=4,
n_redundant=1,
random_state=0,
shuffle=True,
)
X = pd.DataFrame(X, columns=FEATURE_COLS)
y = pd.DataFrame(y, columns=LABEL_COLS)
features_pandas = pd.concat([X, y], axis=1)
features_df = session.create_dataframe(features_pandas)
# Train an XGBoost model on snowflake.
xgboost_model = XGBClassifier(
input_cols=FEATURE_COLS,
label_cols=LABEL_COLS,
output_cols=OUTPUT_COLS
)
xgboost_model.fit(features_df)
# Use the model to make predictions.
predictions = xgboost_model.predict(features_df)
predictions[OUTPUT_COLS].show()
Prétraitement et formation des fonctions sur des données non synthétiques¶
Cet exemple utilise les données de particules gamma haute énergie d’un télescope Cherenkov atmosphérique au sol. Le télescope observe les particules gamma haute énergie, en tirant parti du rayonnement émis par les particules chargées produites dans les gerbes électromagnétiques initiées par les rayons gamma. Le détecteur enregistre le rayonnement Cherenkov (des longueurs d’onde visibles à ultraviolettes) qui traverse l’atmosphère, ce qui permet de reconstruire les paramètres de gerbe gamma. Le télescope détecte également les rayons d’hadrons abondants dans les gerbes cosmiques et qui produisent des signaux qui imitent les rayons gamma.
L’objectif est de développer un modèle de classification permettant de distinguer les rayons gamma des rayons d’hadrons. Le modèle permet aux scientifiques de filtrer le bruit de fond et de se concentrer sur les véritables signaux de rayons gamma. Les rayons gamma permettent aux scientifiques d’observer des événements cosmiques tels que la naissance et la mort des étoiles, les explosions cosmiques et le comportement de la matière dans des conditions extrêmes.
Les données des particules peuvent être téléchargées à partir du Télescope gamma MAGIC. Téléchargez et décompressez les données, définissez la variable DATA_FILE_PATH pour qu’elle pointe vers le fichier de données, et exécutez le code ci-dessous pour le charger dans Snowflake.
DATA_FILE_PATH = "~/Downloads/magic+gamma+telescope/magic04.data"
# Setup
from snowflake.ml.utils.connection_params import SnowflakeLoginOptions
from snowflake.snowpark import Session
import posixpath
import os
##
# Note: Create session https://docs.snowflake.com/en/developer-guide/snowpark/reference/python/latest/api/snowflake.snowpark.Session
##
session = Session.builder.configs(SnowflakeLoginOptions()).create()
session.sql("""
CREATE OR REPLACE TABLE Gamma_Telescope_Data(
F_LENGTH FLOAT,
F_WIDTH FLOAT,
F_SIZE FLOAT,
F_CONC FLOAT,
F_CONC1 FLOAT,
F_ASYM FLOAT,
F_M3_LONG FLOAT,
F_M3_TRANS FLOAT,
F_ALPHA FLOAT,
F_DIST FLOAT,
CLASS VARCHAR(10))
""").collect()
session.sql("CREATE OR REPLACE STAGE SNOWPARK_ML_TEST_DATA_STAGE").collect()
session.file.put(
DATA_FILE_PATH,
"SNOWPARK_ML_TEST_DATA_STAGE/magic04.data",
auto_compress=False,
overwrite=True,
)
session.sql("""
COPY INTO Gamma_Telescope_Data FROM @SNOWPARK_ML_TEST_DATA_STAGE/magic04.data
FILE_FORMAT = (TYPE = 'CSV' field_optionally_enclosed_by='"',SKIP_HEADER = 0);
""").collect()
session.sql("select * from Gamma_Telescope_Data limit 5").collect()
Une fois les données chargées, utilisez le code suivant pour effectuer la formation et des prédictions, en procédant comme suit.
Prétraitez les données :
Remplacez les valeurs manquantes par la moyenne.
Centrez les données à l’aide d’une échelle standard.
Formez un classificateur xgboost pour déterminer le type d’événements.
Testez la précision du modèle sur les ensembles de données de formation et de test.
from snowflake.ml.utils.connection_params import SnowflakeLoginOptions
from snowflake.snowpark import Session, DataFrame
from snowflake.ml.modeling.preprocessing import StandardScaler
from snowflake.ml.modeling.impute import SimpleImputer
from snowflake.ml.modeling.pipeline import Pipeline
from snowflake.ml.modeling.xgboost import XGBClassifier
from snowflake.ml.modeling.metrics import accuracy_score
##
# Note: Create session https://docs.snowflake.com/en/developer-guide/snowpark/reference/python/latest/api/snowflake.snowpark.Session
##
session = Session.builder.configs(SnowflakeLoginOptions()).create()
# Step 1: Create train and test dataframes
all_data = session.sql("select *, IFF(CLASS = 'g', 1.0, 0.0) as LABEL from Gamma_Telescope_Data").drop("CLASS")
train_data, test_data = all_data.random_split(weights=[0.9, 0.1], seed=0)
# Step 2: Construct training pipeline with preprocessing and modeling steps
FEATURE_COLS = [c for c in train_data.columns if c != "LABEL"]
LABEL_COLS = ["LABEL"]
pipeline = Pipeline(steps = [
("impute", SimpleImputer(input_cols=FEATURE_COLS, output_cols=FEATURE_COLS)),
("scaler", StandardScaler(input_cols=FEATURE_COLS, output_cols=FEATURE_COLS)),
("model", XGBClassifier(input_cols=FEATURE_COLS, label_cols=LABEL_COLS))
])
# Step 3: Train
pipeline.fit(train_data)
# Step 4: Eval
predict_on_training_data = pipeline.predict(train_data)
training_accuracy = accuracy_score(df=predict_on_training_data, y_true_col_names=["LABEL"], y_pred_col_names=["OUTPUT_LABEL"])
predict_on_test_data = pipeline.predict(test_data)
eval_accuracy = accuracy_score(df=predict_on_test_data, y_true_col_names=["LABEL"], y_pred_col_names=["OUTPUT_LABEL"])
print(f"Training accuracy: {training_accuracy} \nEval accuracy: {eval_accuracy}")
Optimisation distribuée des hyperparamètres¶
Cet exemple montre comment exécuter l’optimisation distribuée des hyperparamètres en utilisant GridSearchCV de scikit-learn de l’implémentation de Snowflake. Les cycles individuels sont exécutés en parallèle via les ressources de calcul d’entrepôt distribué. Pour plus de détails sur l’optimisation distribuée des hyperparamètres, voir Optimisation distribuée des hyperparamètres.
from snowflake.snowpark import Session, DataFrame
from snowflake.ml.utils.connection_params import SnowflakeLoginOptions
from sklearn.datasets import make_classification
from snowflake.snowpark import Session, DataFrame
from snowflake.ml.modeling.xgboost import XGBClassifier
from snowflake.ml.modeling.model_selection.grid_search_cv import GridSearchCV
FEATURE_COLS = ["X1", "X2", "X3", "X4", "X5", "X6"]
LABEL_COLS = ["Y"]
OUTPUT_COLS = ["PREDICTIONS"]
# Create a session using your favorite login option.
# In this example we use a session builder with `SnowflakeLoginOptions`.
session = Session.builder.configs(SnowflakeLoginOptions()).create()
# Set up data.
def set_up_data(session: Session, n_samples: int) -> DataFrame:
X, y = make_classification(
n_samples=n_samples,
n_features=6,
n_informative=2,
n_redundant=0,
random_state=0,
shuffle=True,
)
X = pd.DataFrame(X, columns=FEATURE_COLS)
y = pd.DataFrame(y, columns=LABEL_COLS)
features_pandas = pd.concat([X, y], axis=1)
features_pandas.head()
features_df = session.create_dataframe(features_pandas)
return features_df
features_df = set_up_data(session, 10**4)
# Create a warehouse to use for the tuning job.
session.sql(
"""
CREATE or replace warehouse HYPERPARAM_WH
WITH WAREHOUSE_SIZE = 'X-SMALL'
WAREHOUSE_TYPE = 'Standard'
AUTO_SUSPEND = 60
AUTO_RESUME = TRUE
INITIALLY_SUSPENDED = FALSE;"""
).collect()
session.use_warehouse("HYPERPARAM_WH")
# Tune an XGB Classifier model using sklearn GridSearchCV.
DISTRIBUTIONS = dict(
n_estimators=[10, 50],
learning_rate=[0.01, 0.1, 0.2],
)
estimator = XGBClassifier()
grid_search_cv = GridSearchCV(estimator=estimator, param_grid=DISTRIBUTIONS, input_cols=FEATURE_COLS, label_cols=LABEL_COLS, output_cols=OUTPUT_COLS)
grid_search_cv.fit(features_df)
# Use the best model to make predictions.
predictions = grid_search_cv.predict(features_df)
predictions[OUTPUT_COLS].show()
# Retrieve sklearn model, and print the best score
sklearn_grid_search_cv = grid_search_cv.to_sklearn()
print(sklearn_grid_search_cv.best_score_)
Pour bien comprendre la puissance de l’optimisation distribuée, il faut s’entraîner sur un million de lignes de données.
large_features_df = set_up_data(session, 10**6)
# Scale up the warehouse for a faster fit. This takes 2m15s to run on an L warehouse versus 4m5s on a XS warehouse.
session.sql(f"ALTER WAREHOUSE {session.get_current_warehouse()} SET WAREHOUSE_SIZE='LARGE'").collect()
grid_search_cv.fit(large_features_df)
print(grid_search_cv.to_sklearn().best_score_)
Classes Modeling de Snowflake¶
Toutes les classes de modélisation Snowflake et les classes de prétraitement se trouvent dans l’espace de noms snowflake.ml.modeling. Les modules snowflake-ml-python portent le même nom que les modules correspondants de l’espace de noms sklearn. Par exemple, le module correspondant à sklearn.calibration est snowflake.ml.modeling.calibration. Les modules xgboost et lightgbm correspondent respectivement à snowflake.ml.modeling.xgboost et snowflake.ml.modeling.lightgbm.
L’API Modeling fournit des wrappers pour les classes scikit-learn, xgboost et lightgbm sous-jacentes, la majorité d’entre elles étant exécutées sous forme de procédures stockées (sur un seul nœud d’entrepôt) dans l’entrepôt virtuel. Toutes les classes de scikit-learn ne sont pas prises en charge. Voir la Référence d’API Python pour une liste des classes actuellement disponibles.
Certaines classes (notamment les classes métriques et de prétraitement) prennent en charge l’exécution distribuée et peuvent offrir des avantages significatifs en termes de performances par rapport à l’exécution locale des mêmes opérations. Pour plus d’informations, voir Prétraitement distribué et Optimisation distribuée des hyperparamètres. Le tableau ci-dessous répertorie les classes spécifiques qui prennent en charge l’exécution distribuée.
Nom du module |
Classes distribuées |
|---|---|
|
|
|
|
|
|
|
|
Différences générales entre les API¶
Astuce
Consultez la référence d’API pour plus de détails sur l’API Modeling.
Les classes Snowflake Modeling comprennent des algorithmes de prétraitement, de transformation et de prédiction des données basés sur scikit-learn, xgboost et lightgbm. Les classes Python de Snowpark remplacent les classes correspondantes des paquets d’origine, avec des signatures similaires. Cependant, ces APIs sont conçues pour fonctionner avec des DataFrames Snowpark plutôt qu’avec des tableaux NumPy.
Bien que l’API soit similaire à celle de scikit-learn, il existe quelques différences clés. Cette section explique comment appeler les méthodes __init__ (constructeur), fit, et predict pour les classes d’estimateurs et de transformateurs Snowflake.
Le constructeur de toutes les classes du modèle Snowflake accepte cinq paramètres supplémentaires (
input_cols,output_cols,sample_weight_col,label_cols, etdrop_input_cols) en plus des paramètres acceptés par les classes équivalentes dans scikit-learn, xgboost ou lightgbm. Il s’agit de chaînes ou de séquences de chaînes qui spécifient les noms des colonnes d’entrée, des colonnes de sortie, de la colonne de poids de l’échantillon et des colonnes de balises dans un DataFrame Snowpark ou Pandas. Si certains des ensembles de données que vous utilisez portent des noms différents, vous pouvez modifier ces noms après l’instanciation en utilisant l’une des méthodes setter fournies, telles queset_input_cols.Comme vous spécifiez les noms des colonnes lors de l’instanciation de la classe (ou par la suite, à l’aide des méthodes setter), les méthodes
fitetpredictacceptent un seul DataFrame au lieu de tableaux distincts pour les entrées, les poids et les libellés. Les noms de colonne fournis sont utilisés pour accéder à la colonne appropriée à partir du DataFrame dansfitoupredict. Consultez fit et predict.Par défaut, les méthodes
transformetpredictrenvoient un DataFrame contenant toutes les colonnes du DataFrame transmis à la méthode, avec le résultat de la prédiction stocké dans des colonnes supplémentaires. Vous pouvez effectuer une transformation sur place en spécifiant les noms de colonne de sortie correspondant aux noms de colonne d’entrée, ou supprimer les colonnes d’entrée en transmettantdrop_input_cols = True.) Les équivalents scikit-learn, xgboost et lightgbm renvoient des tableaux contenant uniquement les résultats.Les transformateurs Snowpark Python n’ont pas de méthode
fit_transform. Cependant, comme avec scikit-learn, la validation des paramètres n’est effectuée que dans la méthodefit. Vous devez donc appelerfità un moment donné avanttransform, même si le transformateur n’effectue aucun ajustement.fitrenvoie le transformateur, de sorte que les appels de méthode peuvent être chaînés, par exempleBinarizer(threshold=0.5).fit(df).transform(df).Les transformateurs Snowflake n’ont actuellement pas de méthode
inverse_transform. Dans de nombreux cas d’utilisation, cette méthode n’est pas nécessaire car les colonnes d’entrée sont conservées par défaut dans le dataframe de sortie.
Vous pouvez convertir n’importe quel objet de modélisation Snowflake en objet scikit-learn, xgboost ou lightgbm correspondant, ce qui vous permet d’utiliser l’ensemble des méthodes et attributs du type sous-jacent. Voir Récupération du modèle sous-jacent.
Construction d’un modèle¶
En plus des paramètres acceptés par les classes de modèles scikit-learn individuelles, toutes les classes de modélisation acceptent les paramètres supplémentaires suivants lors de l’instanciation.
Ces paramètres sont tous techniquement facultatifs, mais vous souhaiterez souvent spécifier input_cols, output_cols, ou les deux. label_cols et sample_weight_col sont nécessaires dans les situations spécifiques indiquées dans la table, mais peuvent être omis dans d’autres cas.
Astuce
Tous les noms de colonne doivent respecter les conditions d’identificateur Snowflake. Pour préserver la casse ou utiliser des caractères spéciaux (autres que le signe dollar et le trait de soulignement) lors de la création d’une table, les noms de colonnes doivent être placés entre guillemets doubles. Utilisez les noms de colonne tout en majuscules dans la mesure du possible pour maintenir la compatibilité avec la sensibilité à la casse des DataFrames Pandas.
from snowflake.ml.modeling.preprocessing import MinMaxScaler
from snowflake.snowpark import Session
# Snowflake identifiers are not case sensitive by default.
# These column names will be automatically updated to ["COLUMN_1", "COLUMN_2", "COLUMN_3"] by the Snowpark DataFrame.
schema = ["column_1", "column_2", "column_3"]
df = session.create_dataframe([[1, 2, 3]], schema = schema)
df.show()
--------------------------------------
|"COLUMN_1" |"COLUMN_2" |"COLUMN_3"|
--------------------------------------
|1 |2 |3 |
--------------------------------------
# Identify the column names using the Snowflake identifier.
input_cols = ["COLUMN_1", "COLUMN_2", "COLUMN_3"]
mms = MinMaxScaler(input_cols=input_cols)
mms.fit(df)
# To maintain lower case column names, include a double quote within the string.
schema = ['"column_1"', '"column_2"', '"column_3"']
df = session.create_dataframe([[1, 2, 3]], schema = schema)
df.show()
----------------------------------------
|'"column_1"'|'"column_2"'|'"column_3"'|
----------------------------------------
|1 |2 |3 |
----------------------------------------
# Since no conversion took place, the schema labels can be used as the column identifiers.
mms = MinMaxScaler(input_cols=schema)
mms.fit(df)
Paramètre |
Description |
|---|---|
|
Chaîne ou liste de chaînes représentant les noms des colonnes qui contiennent des fonctions. Si vous omettez ce paramètre, toutes les colonnes du DataFrame d’entrée, à l’exception des colonnes spécifiées par les paramètres |
|
Chaîne ou liste de chaînes représentant les noms des colonnes qui contiennent des balises. Vous devez spécifier des colonnes de balises pour les estimateurs supervisés, car l’inférence de ces colonnes n’est pas possible. Ces colonnes de balises sont utilisées comme cibles pour les prédictions du modèle et doivent être clairement distinguées des |
|
Chaîne ou liste de chaînes représentant les noms des colonnes qui stockeront la sortie des opérations Si vous omettez ce paramètre, les noms des colonnes de sortie sont dérivés via l’ajout d’un préfixe Pour la transformation en place, transmettez les mêmes noms pour |
|
Chaîne ou liste de chaînes indiquant les noms des colonnes à exclure de la formation, de la transformation et de l’inférence. Les colonnes intermédiaires restent intactes entre les DataFrames d’entrée et de sortie. Cette option s’avère utile lorsque vous souhaitez éviter d’utiliser des colonnes spécifiques, telles que les colonnes d’index, lors de la formation ou de l’inférence, mais que vous ne transmettez pas de |
|
Chaîne représentant le nom de la colonne contenant les poids des exemples. Cet argument est nécessaire pour les ensembles de données pondérés. |
|
Valeur booléenne indiquant si les colonnes d’entrée sont supprimées du résultat DataFrame. La valeur par défaut est |
Exemple¶
Le constructeur DecisionTreeClassifier n’a pas d’arguments obligatoires dans scikit-learn ; tous les arguments ont des valeurs par défaut. Ainsi, dans scikit-learn, vous pourriez écrire :
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
Dans la version de Snowflake de cette classe, vous devez spécifier les noms des colonnes (ou accepter les valeurs par défaut en ne les spécifiant pas). Dans cet exemple, ils sont explicitement spécifiés.
Vous pouvez initialiser un DecisionTreeClassifier en transmettant les arguments directement au constructeur ou en les définissant comme attributs du modèle après l’instanciation. (Les attributs peuvent être modifiés à tout moment.)
En tant qu’arguments du constructeur :
from snowflake.ml.modeling.tree import DecisionTreeClassifier model = DecisionTreeClassifier( input_cols=feature_column_names, label_cols=label_column_names, sample_weight_col=weight_column_name, output_cols=expected_output_column_names )
En définissant des attributs du modèle :
from snowflake.ml.modeling.tree import DecisionTreeClassifier model = DecisionTreeClassifier() model.set_input_cols(feature_column_names) model.set_label_cols(label_column_names) model.set_sample_weight_col(weight_column_name) model.set_output_cols(output_column_names)
fit¶
La méthode fit d’un classificateur Snowflake prend un seul DataFrame Snowpark ou Pandas contenant toutes les colonnes, y compris les fonctions, les balises et les poids. Cela diffère de la méthode fit de scikit-learn, qui prend des entrées séparées pour les fonctions, les balises et les poids.
Dans scikit-learn, l’appel à la méthode DecisionTreeClassifier.fit ressemble à ceci :
model.fit(
X=df[feature_column_names], y=df[label_column_names], sample_weight=df[weight_column_name]
)
Dans fit de Snowflake, il vous suffit de transmettre le DataFrame. Vous avez déjà défini les noms des colonnes d’entrée, de balise et de poids lors de l’initialisation ou à l’aide des méthodes setter, comme indiqué dans Construction d’un modèle.
model.fit(df)
predict¶
La méthode predict prend également un seul DataFrame Snowpark ou Pandas contenant toutes les colonnes de caractéristiques. Le résultat est un DataFrame qui contient toutes les colonnes du DataFrame d’entrée inchangées et les colonnes de sortie ajoutées. Vous devez extraire les colonnes de sortie de ce DataFrame. Cette méthode est différente de la méthode predict de scikit-learn, qui ne renvoie que les résultats.
Exemple¶
Dans scikit-learn, predict ne renvoie que les résultats de la prédiction :
prediction_results = model.predict(X=df[feature_column_names])
Pour obtenir uniquement les résultats de la prédiction dans Snowflake predict, extrayez les colonnes de sortie du DataFrame renvoyé. Ici, output_column_names est une liste contenant les noms des colonnes de sortie :
prediction_results = model.predict(df)[output_column_names]
Entraînement et inférence distribuées avec SPCS¶
![]() Fonctionnalité en avant-première — Ouvrir
Fonctionnalité en avant-première — Ouvrir
Disponible pour tous les comptes.
Lors de l’exécution dans un Snowflake Notebook sur Snowpark Container Services (SPCS), l’entraînement et l’inférence du modèle pour ces classes de modélisation sont exécutées sur le cluster de calcul sous-jacent, et non dans un entrepôt, et sont distribuées de manière transparente sur tous les nœuds du cluster pour utiliser toutes les capacités de calcul disponibles.
Les opérations de prétraitement et de métriques sont transmises à l’entrepôt. De nombreuses classes de prétraitement prennent en charge l’exécution distribuée lorsqu’elles sont exécutées dans l’entrepôt ; voir Prétraitement distribué.
Prétraitement distribué¶
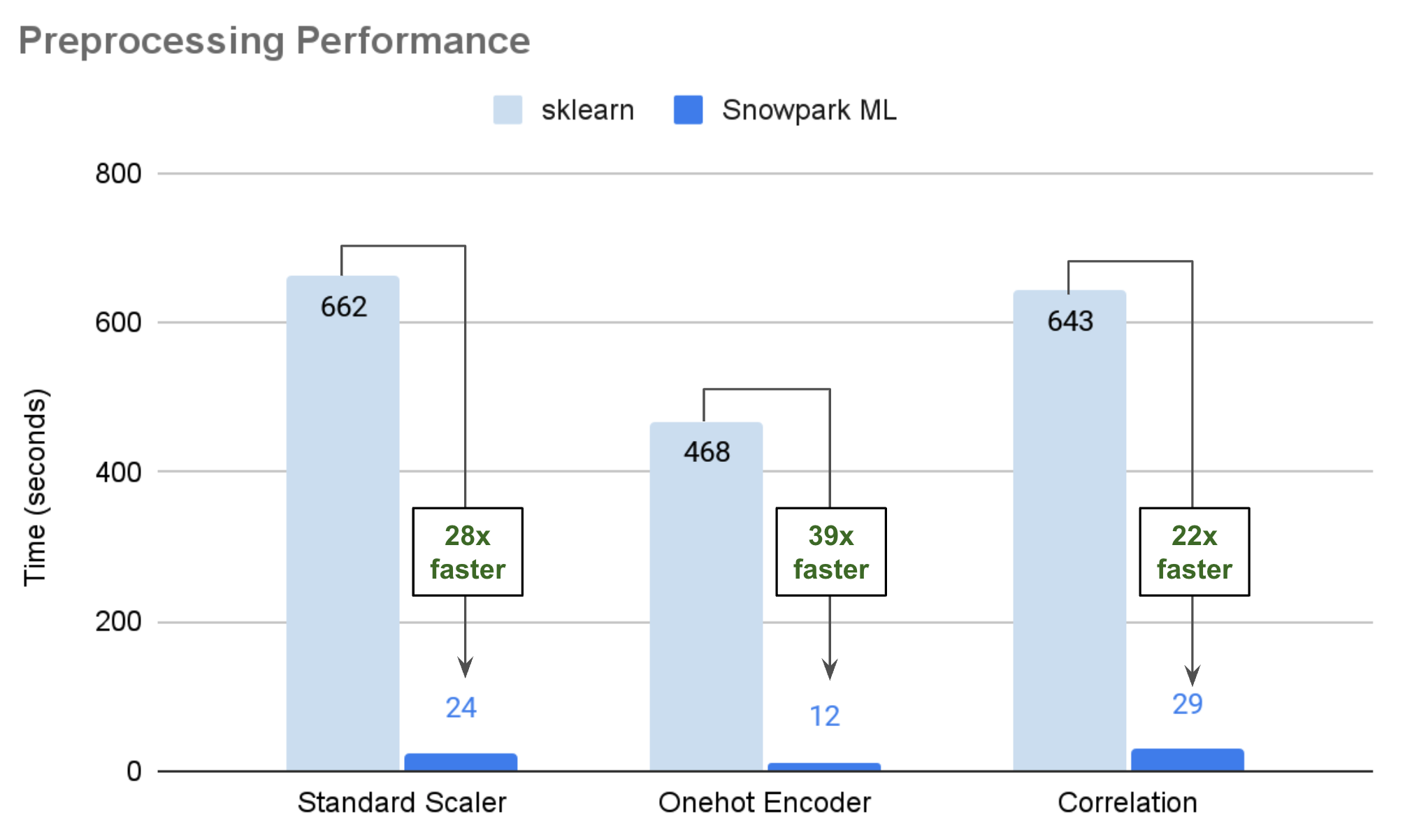
De nombreuses fonctions de prétraitement et de transformation de données Snowflake sont mises en œuvre via le moteur d’exécution distribuée de Snowflake, qui apporte des avantages significatifs en termes de performances par rapport à l’exécution sur un seul nœud (c’est-à-dire, les procédures stockées). Pour savoir quelles fonctions prennent en charge l’exécution distribuée, voir Classes Modeling de Snowflake.
Le graphique ci-dessous illustre les chiffres des performances de grands ensembles de données publics, exécutés dans un entrepôt moyen optimisé par Snowpark, en comparant scikit-learn exécuté dans des procédures stockées aux implémentations distribuées de Snowflake. Dans de nombreux scénarios, votre code peut s’exécuter 25 à 50 fois plus vite via des classes de modélisation Snowflake.
Mode de distribution des ajustements (« fits »)¶
La méthode fit d’un transformateur de prétraitement Snowflake accepte un DataFrame Snowpark ou pandas, ajuste l’ensemble de données et renvoie le transformateur ajusté.
Pour les DataFrames Snowpark, l’ajustement distribué utilise le moteur SQL. Le transformateur génère des requêtes SQL pour calculer les états nécessaires (tels que la moyenne, le maximum ou le nombre). Ces requêtes sont ensuite exécutées par Snowflake et les résultats sont matérialisés localement. Pour les états complexes qui ne peuvent être calculés dans SQL, le transformateur récupère des résultats intermédiaires auprès de Snowflake et effectue des calculs locaux sur les métadonnées.
Pour les transformateurs complexes qui nécessitent des tables d’états temporaires lors de la transformation (par exemple,
OneHotEncoderouOrdinalEncoder), ces tables sont représentées localement via des DataFrames pandas.Les DataFrames pandas sont ajustés localement, de manière similaire à l’ajustement avec scikit-learn. Le transformateur crée un transformateur scikit-learn correspondant avec les paramètres fournis. Ensuite, le transformateur scikit-learn est ajusté, et le transformateur Snowflake dérive les états nécessaires de l’objet scikit-learn.
Mode de distribution des transformations¶
La méthode transform d’un transformateur de prétraitement accepte un DataFrame Snowpark ou Pandas, transforme l’ensemble de données et renvoie un ensemble de données transformé.
Pour les DataFrames Snowpark, la transformation distribuée est effectuée via le moteur SQL. Le transformateur ajusté génère un DataFrame Snowpark avec des requêtes SQL sous-jacentes représentant l’ensemble de données transformé. La méthode
transformeffectue une évaluation « paresseuse » (approximative) pour les transformations simples (par exemple,StandardScalerouMinMaxScaler), de sorte qu’aucune transformation n’est en fait effectuée via la méthodetransform.En revanche, certaines transformations complexes impliquent une exécution. Cela inclut des transformateurs qui nécessitent des tables d’états temporaires (telles que
OneHotEncoderetOrdinalEncoder) pendant la transformation. Dans ce cas, le transformateur crée une table temporaire à partir du DataFrame Pandas (qui stocke l’état de l’objet) pour les jointures et d’autres opérations.De plus, quand certains paramètres sont définis, par exemple lorsque le transformateur est défini de sorte à traiter les valeurs inconnues trouvées lors de la transformation en déclenchant des erreurs, le transformateur matérialise les données, y compris les colonnes, les valeurs inconnues, etc.
Les DataFrames Pandas sont transformés localement, de manière similaire à la transformation avec scikit-learn. Le transformateur crée un transformateur scikit-learn correspondant via l’API
to_sklearnet effectue la transformation en mémoire.
Optimisation distribuée des hyperparamètres¶
Le réglage des hyperparamètres fait partie intégrante du flux de travail de la science des données. L’API Snowflake fournit des implémentations distribuées des APIs GridSearchCV et RandomizedSearchCV scikit-learn pour permettre le réglage efficace des hyperparamètres dans des entrepôts à un ou plusieurs nœuds.
Astuce
Snowflake active par défaut l’optimisation distribuée des hyperparamètres. Pour la désactiver, utilisez l’importation Python suivante.
import snowflake.ml.modeling.parameters.disable_distributed_hpo
Le plus petit entrepôt virtuel Snowflake (XS) ou l’entrepôt optimisé par Snowpark (M) comporte un nœud. Chaque taille supérieure successive double le nombre de nœuds.
Pour les entrepôts à un seul nœud (XS), la capacité totale du nœud est utilisée par défaut à l’aide du cadre de multitraitement joblib de scikit-learn.
Astuce
Chaque opération d’ajustement nécessite sa propre copie du ensemble de données d’entraînement chargé dans RAM. Pour traiter des ensembles de données d’une telle ampleur, désactivez l’optimisation distribuée des hyperparamètres (avec import snowflake.ml.modeling.parameters.disable_distributed_hpo) et réglez le paramètre n_jobs sur 1 pour réduire la concurrence.
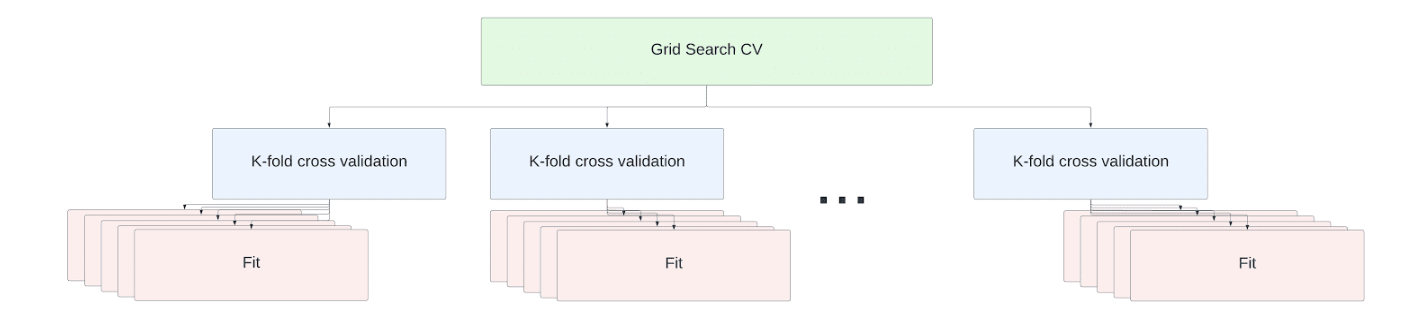
Pour les entrepôts à plusieurs nœuds, les opérations fit de votre tâche de réglage de validation croisée sont réparties entre les nœuds. Aucune modification de code n’est nécessaire pour monter en échelle. Les ajustements de l’estimateur sont exécutés en parallèle sur tous les cœurs disponibles sur tous les nœuds de l’entrepôt.
À titre d’illustration, considérons l”ensemble de données sur le logement en Californie fourni avec la bibliothèque scikit-learn. Il comprend 20 640 lignes de données fournissant les informations suivantes :
MedInc : Revenu moyen du groupe de pâtés de maisons
HouseAge : Âge moyen du foyer du groupe de pâtés de maisons
AveRooms : Nombre moyen de pièces par foyer
AveBedrms : Nombre moyen de chambres à coucher par foyer
Population : Population du groupe de pâtés de maisons
AveOccup : Nombre moyen de membres du foyer
Latitude et Longitude
La cible de l’ensemble de données est le revenu moyen, exprimé en centaines de milliers de dollars.
Dans cet exemple, nous effectuons une validation croisée via une recherche par grille sur une régression de forêt aléatoire afin de trouver la meilleure combinaison d’hyperparamètres pour prédire le revenu moyen.
from snowflake.ml.modeling.ensemble.random_forest_regressor import RandomForestRegressor
from snowflake.ml.modeling.model_selection.grid_search_cv import GridSearchCV
from sklearn import datasets
def load_housing_data() -> DataFrame:
input_df_pandas = datasets.fetch_california_housing(as_frame=True).frame
# Set the columns to be upper case for consistency with Snowflake identifiers.
input_df_pandas.columns = [c.upper() for c in input_df_pandas.columns]
input_df = session.create_dataframe(input_df_pandas)
return input_df
input_df = load_housing_data()
# Use all the columns besides the median value as the features
input_cols = [c for c in input_df.columns if not c.startswith("MEDHOUSEVAL")]
# Set the target median value as the only label columns
label_cols = [c for c in input_df.columns if c.startswith("MEDHOUSEVAL")]
DISTRIBUTIONS = dict(
max_depth=[80, 90, 100, 110],
min_samples_leaf=[1,3,10],
min_samples_split=[1.0, 3,10],
n_estimators=[100,200,400]
)
estimator = RandomForestRegressor()
n_folds = 5
clf = GridSearchCV(estimator=estimator, param_grid=DISTRIBUTIONS, cv=n_folds, input_cols=input_cols, label_cols=label_col)
clf.fit(input_df)
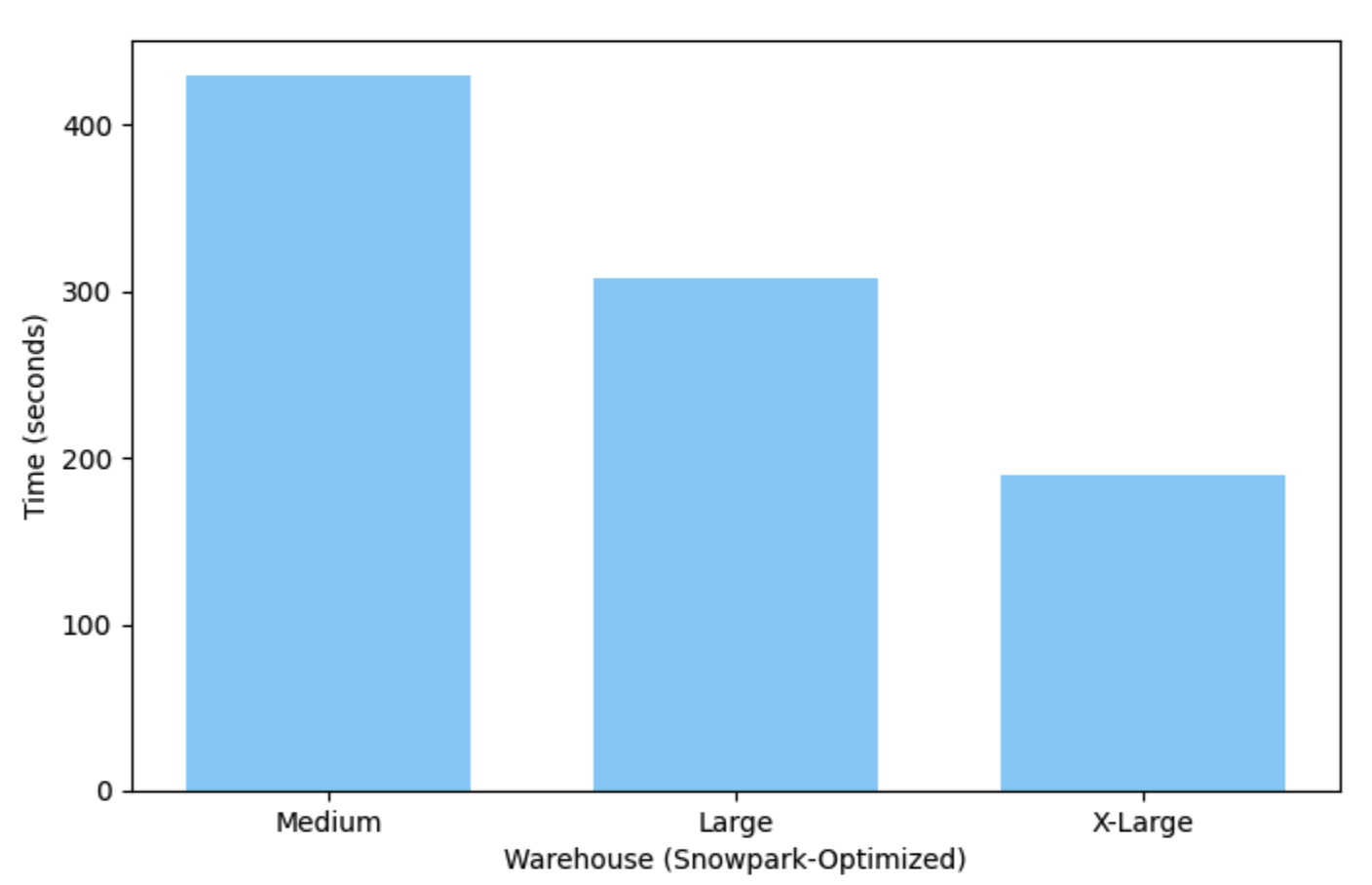
Cet exemple s’exécute en un peu plus de 7 minutes sur un entrepôt moyen (Medium) (un seul nœud) optimisé par Snowpark, et ne prend que 3 minutes pour s’exécuter sur un entrepôt X-Large.
Déploiement et exécution de votre modèle¶
Le résultat de l’entraînement d’un modèle est un objet de modèle Python. Vous pouvez utiliser le modèle entraîné pour faire des prédictions en appelant la méthode predict du modèle. Cela crée une fonction temporaire définie par l’utilisateur pour exécuter le modèle dans votre entrepôt virtuel Snowflake. Cette fonction est automatiquement supprimée à la fin de votre session Snowflake (par exemple, lorsque votre script se termine, ou lorsque vous fermez votre Notebook).
Pour conserver la fonction définie par l’utilisateur après la fin de votre session, vous pouvez la créer manuellement. Consultez les guide de démarrage rapide sur le thème pour plus d’informations.
Le registre des modèles de Snowflake prend également en charge les modèles persistants et facilite leur recherche et leur déploiement. Voir Registre des modèles de Snowflake.
Modèles personnalisés partitionnés¶
Le registre de modèles prend également en charge un type spécial de modèle personnalisé dans lequel l’ajustement et l’inférence sont exécutés en parallèle pour un ensemble de partitions. Cela peut être un moyen performant de créer plusieurs modèles à la fois à partir d’un seul ensemble de données et d’exécuter l’inférence immédiatement. Voir Snowflake Model Registry : modèles personnalisés partitionnés pour plus de détails.
Pipeline pour les transformations multiples¶
Avec scikit-learn, il est courant d’exécuter une série de transformations en utilisant un pipeline. Les pipelines scikit-learn ne fonctionnent pas avec les classes Snowflake, c’est pourquoi une version Snowflake de sklearn.pipeline.Pipeline est fournie pour exécuter une série de transformations. Cette classe se trouve dans le paquet snowflake.ml.modeling.pipeline et fonctionne de la même manière que la version scikit-learn.
Récupération du modèle sous-jacent¶
Les modèle Snowflake ML peuvent être « décapsulés » (unwrapped), c’est-à-dire convertis en modèles tiers sous-jacents, à l’aide des méthodes suivantes (selon la bibliothèque) :
to_sklearnto_xgboostto_lightgbm
L’ensemble des attributs et méthodes du modèle sous-jacent sont ensuite accessibles et peuvent être exécutés localement par rapport à l’estimateur. Par exemple, dans l”exemple GridSearchCV, nous convertissons l’estimateur de recherche par grille en un objet scikit-learn afin de récupérer le meilleur score.
best_score = grid_search_cv.to_sklearn().best_score_
Limites connues¶
Les estimateurs et transformateurs de Snowflake ne prennent actuellement pas en charge les entrées ou les réponses clairsemées. Si vous disposez de données clairsemées, convertissez-les dans un format dense avant de les transmettre aux estimateurs ou transformateurs de Snowflake.
Le paquet
snowflake-ml-pythonne prend actuellement pas en charge les types de données matricielles. Toute opération sur les estimateurs et les transformateurs qui produirait une matrice comme résultat échoue.Il n’est pas garanti que l’ordre des lignes dans les données de résultat corresponde à l’ordre des lignes dans les données d’entrée.
Snowflake ML ne prend pas encore en charge pandas on Snowflake DataFrames. Convertissez le dataframe Pandas sur Snowflake en dataframe Snowpark pour l’utiliser avec les classes de modélisation Snowflake. L’exemple suivant convertit un DataFrame que nous avons lu dans une table Snowflake :
import modin.pandas as pd import snowflake.snowpark.modin.plugin from snowflake.ml.modeling.xgboost import XGBClassifier snowpark_pandas_df: modin.pandas.DataFrame = read_snowflake('MY_TABLE') # converting to Snowpark DataFrame adds an index column index_label_name = "_INDEX" snowpark_df = snowpark_pandas_df.to_snowpark(index=True, index_label=index_label_name) snowpark_df.show()
Le DataFrame Snowpark qui en résulte est comme suit :
-------------------------------------------------- |"COLUMN_1" |"COLUMN_2" |"TARGET" | "_INDEX" | -------------------------------------------------- |1 |2 |3 |1 | --------------------------------------------------
Le DataFrame peut ensuite être utilisé pour former un classificateur XGBoost comme suit :
# Identify the column names using the Snowflake identifier input_cols = ["COLUMN_1", "COLUMN_2", "COLUMN_3"] # Pass through the _INDEX column rather than using it for training xgb_clf = XGBClassifier(input_cols=input_cols, passthrough_cols=index_label_name, label_cols="TARGET") xgb_clf.fit(snowpark_df)
Résolution des problèmes¶
Ajout de plus de détails à l’enregistrement¶
La bibliothèque de modélisation Snowflake utilise la journalisation Snowpark Python. Par défaut, snowflake-ml-python enregistre les messages de niveau INFO sur la sortie standard. Pour obtenir des journaux plus détaillés, vous pouvez modifier le niveau en l’un des niveaux pris en charge.
DEBUG produit les journaux les plus détaillés. Pour définir le niveau de journalisation sur DEBUG :
import logging, sys
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
Solutions aux problèmes courants¶
Le tableau suivant fournit quelques fournisseurs pour résoudre les problèmes éventuels liés à Snowflake ML Modeling.
Problème ou message d’erreur |
Cause possible |
Résolution |
|---|---|---|
NameError, comme « name x is not defined », ImportError, ou ModuleNotFoundError |
Erreur typographique dans le nom du module ou de la classe, ou |
Reportez-vous au tableau des classes de modélisation pour connaître le nom correct du module et de la classe. Assurez-vous que |
KeyError (« not in index » ou « none of [Index[..]] are in the [columns] ») |
Nom de colonne incorrect. |
Vérifiez et corrigez le nom de la colonne. |
SnowparkSQLException, « does not exist or not authorize » |
La table n’existe pas ou vous ne disposez pas de privilèges suffisants sur la table. |
Assurez-vous que la table existe et que le rôle de l’utilisateur dispose des privilèges appropriés. |
SnowparkSQLException, « invalid identifier PETALLENGTH » |
Nombre de colonnes incorrect (généralement une colonne manquante). |
Vérifiez le nombre de colonnes spécifié lors de la création de la classe de modèle et assurez-vous que vous transmettez le bon nombre. |
InvalidParameterError |
Un type ou une valeur inapproprié(e) a été transmis(e) en tant que paramètre. |
Vérifiez l’aide de la classe ou de la méthode à l’aide de la fonction |
TypeError, « unexpected keyword argument » |
Erreur typographique dans l’argument nommé. |
Vérifiez l’aide de la classe ou de la méthode à l’aide de la fonction |
ValueError, « array with 0 sample(s) » |
L’ensemble de données transmis est vide. |
Assurez-vous que l’ensemble de données n’est pas vide. |
SnowparkSQLException, « authentication token has expired » |
La session a expiré. |
Si vous utilisez un Jupyter notebook, redémarrez le noyau pour créer une nouvelle session. |
ValueError comme « cannot convert string to float » |
Inadéquation du type de données. |
Vérifiez l’aide de la classe ou de la méthode à l’aide de la fonction |
SnowparkSQLException, « cannot create temporary table » |
Une classe de modèle est utilisée dans une procédure stockée qui ne s’exécute pas avec les droits de l’appelant. |
Créez la procédure stockée avec les droits de l’appelant au lieu des droits du propriétaire. |
SnowparkSQLException, « function available memory exceeded » |
Votre ensemble de données est supérieur à 5 GB dans un entrepôt standard. |
Passez à un entrepôt optimisé pour Snowpark. |
OSError, « no space left on device » |
Votre modèle est supérieur à environ 500 MB dans un entrepôt standard. |
Passez à un entrepôt optimisé pour Snowpark. |
Version incompatible de xgboost ou erreur lors de l’importation de xgboost |
Vous avez effectué l’installation en utilisant |
Mettez à jour le paquet ou revenez à une version antérieure comme le demande le message d’erreur. |
AttributeError impliquant |
Tentative d’utilisation de l’une de ces méthodes sur un modèle d’un autre type. |
Utilisez |
Le noyau du Jupyter Notebook se bloque sur un Mac basé sur arm (puce M1 ou M2) : « Le noyau s’est bloqué pendant l’exécution du code dans la cellule actuelle ou dans une cellule précédente. » |
XGBoost ou une autre bibliothèque est installée avec une architecture incorrecte. |
Recréez un nouvel environnement conda avec |
« lightgbm.basic.LightGBMError : (0000) Ne pas prendre en charge les caractères spéciaux JSON dans le nom de la fonction. » |
LightGBM ne prend pas en charge les noms de colonnes entre guillemets doubles dans |
Renommez les colonnes de vos DataFrames Snowpark. Remplacer les caractères non alphanumériques par des traits de soulignement est suffisant dans la plupart des cas. La fonction d’aide Python ci-dessous peut être utile. def fix_values(F, column):
return F.upper(F.regexp_replace(F.col(column), "[^a-zA-Z0-9]+", "_"))
|
Autres lectures¶
Consultez la documentation des bibliothèques d’origine pour obtenir des informations complètes sur leurs fonctionnalités.
Reconnaissance¶
Certaines parties de ce document sont dérivées de la documentation Scikit-learn, qui est sous licence BSD-3 « New » ou « Revised » et sous Copyright © 2007-2023 The scikit-learn developers. Tous droits réservés.
Certaines parties de ce document sont dérivées de la documentation de XGboost, qui est couverte par la licence Apache 2.0, janvier 2004 et qui est sous Copyright © 2019. Tous droits réservés.
Certaines parties de ce document sont dérivées de la documentation LightGBM, qui est sous licence MIT et sous copyright © Microsoft Corp. Tous droits réservés.