Notebooks sur Container Runtime pour ML¶
Vue d’ensemble¶
Vous pouvez exécuter Snowflake Notebooks. sur Container Runtime pour ML. Container Runtime pour ML est optimisé par Snowpark Container Services, vous offrant une infrastructure de conteneur flexible qui prend en charge la création et l’opérationnalisation d’une grande variété de flux de travail entièrement dans Snowflake. Container Runtime pour ML fournit des options logicielles et matérielles pour prendre en charge les charges de travail avancées de science des données et de machine learning. Par rapport aux entrepôts virtuels, Container Runtime pour ML fournit un environnement de calcul plus flexible dans lequel vous pouvez installer des paquets à partir de plusieurs sources et sélectionner des ressources de calcul, notamment des types de poste GPU, tout en continuant à exécuter des requêtes SQL sur les entrepôts pour des performances optimales.
Ce document aborde quelques considérations relatives à l’utilisation de notebooks sur Container Runtime pour ML. Vous pouvez également consulter le guide de démarrage rapide Prise en main de Snowflake Notebook Container Runtime pour en savoir plus sur l’utilisation de Container Runtime pour ML dans votre développement.
Conditions préalables¶
Avant de commencer à utiliser Snowflake Notebooks sur Container Runtime pour ML, le rôle ACCOUNTADMIN doit compléter les étapes de configuration de notebook pour créer les ressources nécessaires et accorder des privilèges à ces ressources. Pour les étapes détaillées, voir Configurer l’administrateur.
Créer un notebook sur Container Runtime pour ML¶
Lorsque vous créez un notebook sur Container Runtime pour ML, vous sélectionnez un entrepôt, un runtime et un pool de calcul pour fournir les ressources nécessaires à l’exécution de votre notebook. Le runtime que vous sélectionnez vous donne accès à des paquets Python différents suivant votre cas d’utilisation. Des tailles d’entrepôt ou pools de calcul différents ont des implications différentes en termes de coûts et de performances. Tous ces paramètres peuvent être modifiés ultérieurement, si nécessaire.
Note
Un utilisateur titulaire du rôle ACCOUNTADMIN, ORGADMIN ou SECURITYADMIN ne peut pas créer ou posséder directement un notebook sur Container Runtime pour ML. Les éléments Notebooks créés par ou appartenant directement à ces rôles ne pourront pas s’exécuter. Cependant, si un notebook appartient à un rôle et que le rôle ACCOUNTADMIN, ORGADMIN ou SECURITYADMIN hérite de ses privilèges, comme le rôle PUBLIC, vous pouvez ensuite utiliser ce rôle pour exécuter ce notebook.
Pour créer un notebook Snowflake à exécuter sur Container Runtime pour ML, procédez comme suit :
Connectez-vous à Snowsight.
Sélectionnez Notebooks.
Sélectionnez + Notebook.
Saisissez un nom pour votre notebook.
Sélectionnez une base de données et un schéma dans lesquels stocker votre notebook. Ce paramètre ne peut pas être modifié après la création du notebook.
Note
La base de données et le schéma ne sont nécessaires que pour stocker vos notebooks. Vous pouvez interroger n’importe quelle base de données et n’importe quel schéma auxquels votre rôle a accès depuis votre notebook.
Sélectionnez Run on container comme environnement Python.
Sélectionnez le type de Runtime : CPU ou GPU.
Sélectionnez un Compute pool.
Modifiez l’entrepôt sélectionné à utiliser pour exécuter des requêtes SQL et Snowpark.
Pour créer et ouvrir votre notebook, sélectionnez Create.
Runtime :
Cette avant-première fournit deux types de runtime : CPU et GPU. Chaque image de runtime contient un ensemble de base de paquets et de versions Python de base vérifiés et intégrés par Snowflake. Toutes les images de runtime prennent en charge l’analyse, la modélisation et l’apprentissage des données avec Snowpark Python, Snowflake ML et Streamlit.
Pour installer des paquets supplémentaires à partir d’un référentiel public, vous pouvez utiliser pip. Une intégration d’accès externe (EAI) est requise pour que Snowflake Notebooks puisse installer des paquets à partir de points de terminaison externes. Pour configurer des EAIs, voir Configurer l’accès externe pour Snowflake Notebooks. Cependant, si un paquet fait déjà partie de l’image de base, vous ne pouvez pas modifier la version du paquet en installant une version différente via pip install. Pour une liste des paquets préinstallés, voir Container Runtime pour ML.
Compute pool :
Un pool de calcul fournit les ressources de calcul pour le noyau de votre notebook et le code Python. Utilisez des pools de calcul basés sur CPU plus petits pour commencer, et sélectionnez des pools de calcul basés sur GPU de mémoire supérieure pour optimiser les scénarios d’utilisation de GPU intensive tels que la vision par ordinateur ou les LLMs/VLMs.
Notez que chaque nœud de calcul est limité à l’exécution d’un seul notebook par utilisateur à la fois. Vous devez définir le paramètre MAX_NODES sur une valeur supérieure à celle utilisée lors de la création de pools de calcul pour notebooks. Pour un exemple, voir Ressources de calcul. Pour plus de détails sur les pools de calcul Snowpark Container Services, voir Snowpark Container Services : utilisation des pools de calcul.
Lorsqu’un notebook n’est pas utilisé, pensez à l’arrêter pour libérer les ressources de nœud. Vous pouvez fermer un notebook en sélectionnant End session dans le bouton de connexion déroulant.
Exécuter un notebook sur Container Runtime pour ML¶
Après avoir créé votre notebook, vous pouvez immédiatement commencer à exécuter du code en ajoutant et en exécutant des cellules. Pour obtenir des informations sur l’ajout de cellules, consultez Développez et exécutez du code dans des Snowflake Notebooks.
Importation de davantage de paquets¶
Outre les paquets préinstallés pour que votre notebook soit opérationnel, vous pouvez installer des paquets provenant de sources publiques pour lesquelles vous avez configuré un accès externe. Vous pouvez également utiliser des paquets stockés dans une zone de préparation ou un référentiel privé. Vous devez utiliser le rôle ACCOUNTADMIN ou un rôle capable de créer des intégrations d’accès externes (EAIs) pour pouvoir effectuer la configuration et vous accorder l’accès vous permettant de consulter des points de terminaison externes spécifiques. Utilisez la commande ALTER NOTEBOOK pour activer l’accès externe sur votre notebook. Une fois l’accès accordé, vous verrez apparaître les EAIs dans Notebook settings. Activez les EAIs avant de démarrer l’installation à partir de canaux externes. Pour obtenir des instructions, voir Créer des intégrations d’accès externes (EAI).
L’exemple suivant installe un paquet externe à l’aide de pip install dans une cellule de code :
!pip install transformers scipy ftfy accelerate
Mettre à jour les paramètres de notebook¶
Vous pouvez à tout moment mettre à jour les paramètres tels que les pools de calcul ou l’entrepôt à utiliser dans Notebook settings, accessible via le menu Actions de notebook  dans le coin supérieur droit.
dans le coin supérieur droit.
L’un des paramètres que vous pouvez mettre à jour dans Notebook settings est le paramètre de délai d’inactivité. Le délai d’inactivité par défaut est d’1 heure et vous pouvez le définir sur un maximum de 72 heures. Pour définir cette valeur dans SQL, utilisez la commande CREATE NOTEBOOK ou ALTER NOTEBOOK pour définir la propriété IDLE_AUTO_SHUTDOWN_TIME_SECONDS propriété du notebook.
Installation de paquets privés¶
Pip prend en charge l’installation de paquets provenant de sources privées avec authentification de base, telles que JFrog Artifactory. Configurez le notebook pour l’intégration de l’accès externe (EAI) afin qu’il puisse accéder au dépôt.
Créez une règle réseau pour spécifier le dépôt auquel vous souhaitez accéder. Par exemple, cette règle réseau spécifie un dépôt JFrog :
CREATE OR REPLACE NETWORK RULE jfrog_network_rule MODE = EGRESS TYPE = HOST_PORT VALUE_LIST = ('<your-repo>.jfrog.io');
Créez une intégration d’accès externe qui permet l’accès au dépôt :
CREATE OR REPLACE EXTERNAL ACCESS INTEGRATION jfrog_integration ALLOWED_NETWORK_RULES = (jfrog_network_rule) ENABLED = TRUE; GRANT USAGE ON INTEGRATION jfrog_integration TO ROLE data_scientist;
Pour accéder à la configuration de l’accès externe, sélectionnez le menu
(Notebook actions) en haut à droite de votre notebook.Sélectionnez Notebook settings puis l’onglet External access.
Sélectionnez le EAI pour vous connecter au dépôt.
Le notebook redémarre.
Une fois que le notebook a redémarré, vous pouvez procéder à l’installation à partir du dépôt :
!pip install hello-jfrog --index-url https://<user>:<token>@<your-repo>.jfrog.io/artifactory/api/pypi/test-pypi/simple
Installer des paquets privés avec une connectivité privée¶
Si votre dépôt privé de paquets nécessite une connectivité privée, suivez les étapes suivantes pour configurer votre compte. Si vous avez besoin d’aide, vous pouvez demander à votre administrateur de compte de définir la règle réseau.
Suivez les étapes décrites dans Sortie réseau par connectivité privée pour définir la sortie du réseau à l’aide de la connectivité privée.
Créez un EAI avec la règle réseau de l’étape 1. Par exemple :
CREATE OR REPLACE EXTERNAL ACCESS INTEGRATION private_repo_integration ALLOWED_NETWORK_RULES = (PRIVATE_LINK_NETWORK_RULE) ENABLED = TRUE; GRANT USAGE ON INTEGRATION private_repo_integration TO ROLE data_scientist;
Pour accéder à la configuration de l’accès externe, sélectionnez le menu
(Notebook actions) en haut à droite de votre notebook.Sélectionnez Notebook settings puis l’onglet External access.
Sélectionnez le EAI pour vous connecter à votre dépôt privé.
Le notebook redémarre.
Après le redémarrage du notebook, vous pouvez fournir l’adresse
--index-urlde votre dépôt :!pip install my_package --index-url https://my-private-repo-url.com/simple
Exécution de charges de travail ML¶
Notebooks sur Container Runtime pour ML est bien adapté à l’exécution de charges de travail ML telles que l’apprentissage de modèles et le réglage de paramètres. Les environnements d’exécution sont préinstallés avec les paquets les plus courants de ML. Une fois l’accès à l’intégration externe défini, vous pouvez installer tous les autres paquets dont vous avez besoin à l’aide de !pip install.
Note
Le processus Python met en cache les modules chargés. Modifiez les versions des paquets installés avant d’importer les paquets dans le code. Sinon, vous devrez peut-être vous déconnecter et vous reconnecter à la session du notebook pour charger les nouvelles versions.
Les exemples suivants montrent comment utiliser certaines des bibliothèques disponibles pour votre charge de travail ML.
Utiliser de nouvelles bibliothèques optimisées pour les conteneurs¶
Container Runtime pour ML intègre de nouvelles APIs conçues spécifiquement pour le développement ML dans l’environnement conteneur. En répartissant le traitement sur plusieurs cœurs, ces APIs permettent d’optimiser le chargement et déchargement de données, l’entraînement des modèles et l’optimisation des hyperparamètres. Pour en savoir plus sur ces APIs, consultez la section Container Runtime du guide du développeur Snowflake ML.
Utiliser des bibliothèques OSS ML¶
L’exemple suivant utilise une bibliothèque OSS ML, xgboost, avec une session Snowpark active pour récupérer les données directement en mémoire pour l’apprentissage :
from snowflake.snowpark.context import get_active_session
import pandas as pd
import xgboost as xgb
from sklearn.model_selection import train_test_split
session = get_active_session()
df = session.table("my_dataset")
# Pull data into local memory
df_pd = df.to_pandas()
X = df_pd[['feature1', 'feature2']]
y = df_pd['label']
# Split data into test and train in memory
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.15, random_state=34)
# Train in memory
model = xgb.XGBClassifier()
model.fit(X_train, y_train)
# Predict
y_pred = model.predict(X_test)
Utiliser des APIs de modélisation Snowflake ML¶
Quand des APIs de modélisation Snowflake ML sont utilisées sur Container Runtime pour ML, l’intégralité de l’exécution (y compris l’apprentissage et la prédiction) se produit directement dans le runtime de conteneur et non dans l’entrepôt de requêtes. Snowflake ML sur Container Runtime peut extraire des données plus rapidement et est recommandé pour l’apprentissage à grande échelle. Avec le runtime GPU, ML Snowflake utilisera par défaut l’ensemble des GPUs pour accélérer l’apprentissage.
L’exemple de bloc de code suivant utilise XGBoost pour la modélisation :
from snowflake.snowpark.context import get_active_session
from snowflake.ml.modeling.xgboost import XGBClassifier
from snowflake.ml.modeling.metrics import accuracy_score
session = get_active_session()
df = session.table("my_dataset")
feature_cols=['FEATURE1', 'FEATURE2']
label_col = 'LABEL'
predicted_col = [PREDICTED_LABEL]
df = df[features_cols + [label_col]]
# Split is pushed down to associated warehouse
train_df, test_df = df.random_split(weights=[0.85, 0.15], seed=34)
model = XGBClassifier(
input_cols=feature_cols,
label_cols=label_col,
output_cols=predicted_col,
# This will enable leveraging all GPUs on the node
tree_method="gpu_hist",
)
# Train
model.fit(train_df)
# Predict
result = model.predict(test_df)
accuracy = accuracy_score(
df=result,
y_true_col_names=label_cols,
y_pred_col_names=predicted_col)
Voici un exemple utilisant Light Gradient Boosting Machine (LightGBM) :
from snowflake.snowpark.context import get_active_session
from snowflake.ml.modeling.lightgbm import LGBMClassifier
from snowflake.ml.modeling.metrics import accuracy_score
session = get_active_session()
df = session.table("my_dataset")
feature_cols=['FEATURE1', 'FEATURE2']
label_col = 'LABEL'
predicted_col = [PREDICTED_LABEL]
df = df[features_cols + [label_col]]
# Split is pushed down to associated warehouse
train_df, test_df = df.random_split(weights=[0.85, 0.15], seed=34)
model = LGBMClassifier(
input_cols=feature_cols,
label_cols=label_col,
ouput_cols=predicted_col,
# This will enable leveraging all GPUs on the node
device_type="gpu",
)
# Train
model.fit(train_df)
# Predict
result = model.predict(test_df)
accuracy = accuracy_score(
df=result,
y_true_col_names=label_cols,
y_pred_col_names=predicted_col)
Utiliser de nouvelles bibliothèques optimisées pour les conteneurs¶
Container Runtime pour ML préinstalle de nouvelles APIs conçues spécifiquement pour l’apprentissage ML dans l’environnement de conteneur.
APIs de connecteurs de données¶
Les APIs de connecteurs de données fournissent une interface unique pour connecter des sources de données Snowflake (notamment des tables, des DataFrames et des jeux de données) à des cadres ML populaires (tels que PyTorch et TensorFlow). Ces APIs se trouvent dans l’espace de noms snowflake.ml.data.
snowflake.ml.data.data_connector.DataConnectorConnecte les DataFrames Snowpark ou les jeux de données Snowflake ML aux DataSets TensorFlow ou PyTorch ou aux DataFrames Pandas. Instanciez un connecteur à l’aide de l’une des méthodes de classe suivantes :
DataConnector.from_dataframe:: accepte un DataFrame Snowpark.DataConnector.from_dataset: accepte un jeu de données ML Snowflake, spécifié par nom et version.DataConnector.from_sources: accepte une liste de sources, chacune pouvant être un DataFrame ou un jeu de données.
Une fois que vous avez instancié le connecteur (en appelant l’instance, par exemple,
data_connector), appelez les méthodes suivantes pour produire le type de sortie souhaité.data_connector.to_tf_dataset: renvoie un jeu de données TensorFlow pouvant être utilisé avec TensorFlow.data_connector.to_torch_dataset: renvoie un jeu de données PyTorch pouvant être utilisé avec PyTorch.
Pour plus d’informations sur ces APIs, voir la référence d’API Snowflake ML.
APIs de modélisation distribuée¶
Les APIs de modélisation distribuée fournissent des versions parallèles de LightGBM, PyTorch et XGBoost qui tirent pleinement parti des ressources disponibles dans l’environnement de conteneur. Vous les trouverez dans l’espace de noms snowflake.ml.modeling.distributors. Les APIs des classes distribuées sont similaires à celles des versions standards.
Pour plus d’informations sur ces APIs, voir la référence d’API.
- XGBoost
La principale classe XGBoost est
snowflake.ml.modeling.distributors.xgboost.XGBEstimator. Les classes associées comprennent :snowflake.ml.modeling.distributors.xgboost.XGBScalingConfig
Pour un exemple d’utilisation de cette API, voir l’exemple de notebook XGBoost sur GPU dans le référentiel GitHub Snowflake Container Runtime pour ML.
- LightGBM
La principale classe LightGBM est
snowflake.ml.modeling.distributors.lightgbm.LightGBMEstimator. Les classes associées comprennent :snowflake.ml.modeling.distributors.lightgbm.LightGBMScalingConfig
Pour un exemple d’utilisation de cette API, voir l’exemple de notebook LightGBM sur GPU dans le référentiel GitHub Snowflake Container Runtime pour ML.
- PyTorch
La principale classe PyTorch est
snowflake.ml.modeling.distributors.pytorch.PyTorchDistributor. Les classes associées comprennent :snowflake.ml.modeling.distributors.pytorch.WorkerResourceConfigsnowflake.ml.modeling.distributors.pytorch.PyTorchScalingConfigsnowflake.ml.modeling.distributors.pytorch.Contextsnowflake.ml.modeling.distributors.pytorch.get_context
Pour un exemple d’utilisation de cette API, voir l’exemple de notebook PyTorch sur GPU dans le référentiel GitHub Snowflake Container Runtime pour ML.
Limitations¶
L’API Modeling Snowflake ML prend en charge uniquement les méthodes d’inférence
predict,predict_proba,predict_log_probasur Container Runtime pour ML. Les autres méthodes s’exécutent dans l’entrepôt de requêtes.L’API Modeling Snowflake ML prend en charge uniquement les pipelines compatibles avec
sklearnsur Container Runtime.L’API Modeling Snowflake ML ne prend pas en charge les classes
preprocessingoumetricssur Container Runtime pour ML. Celles-ci s’exécutent dans l’entrepôt de requêtes.Les méthodes
fit,predictetscoresont exécutées sur Container Runtime pour ML. Les autres méthodes ML Snowflake s’exécutent dans l’entrepôt de requêtes.sample_weight_colsn’est pas pris en charge pour les modèles LightGBM ou XGBoost.
Remarques relatives aux coûts/à la facturation¶
Lors de l’exécution de notebooks sur Container Runtime pour ML, vous pouvez encourir des coûts de calcul d’entrepôt et des coûts de calcul SPCS.
Snowflake Notebooks nécessite un entrepôt virtuel pour l’exécution de requêtes SQL et Snowpark à des fins d’optimisation des performances. Par conséquent, vous pourriez également encourir des coûts de calcul d’entrepôt virtuel si vous utilisez SQL dans des cellules SQL et des requêtes push-down Snowpark exécutées dans des cellules Python. Le diagramme suivant montre où le calcul a lieu pour chaque type de cellule.
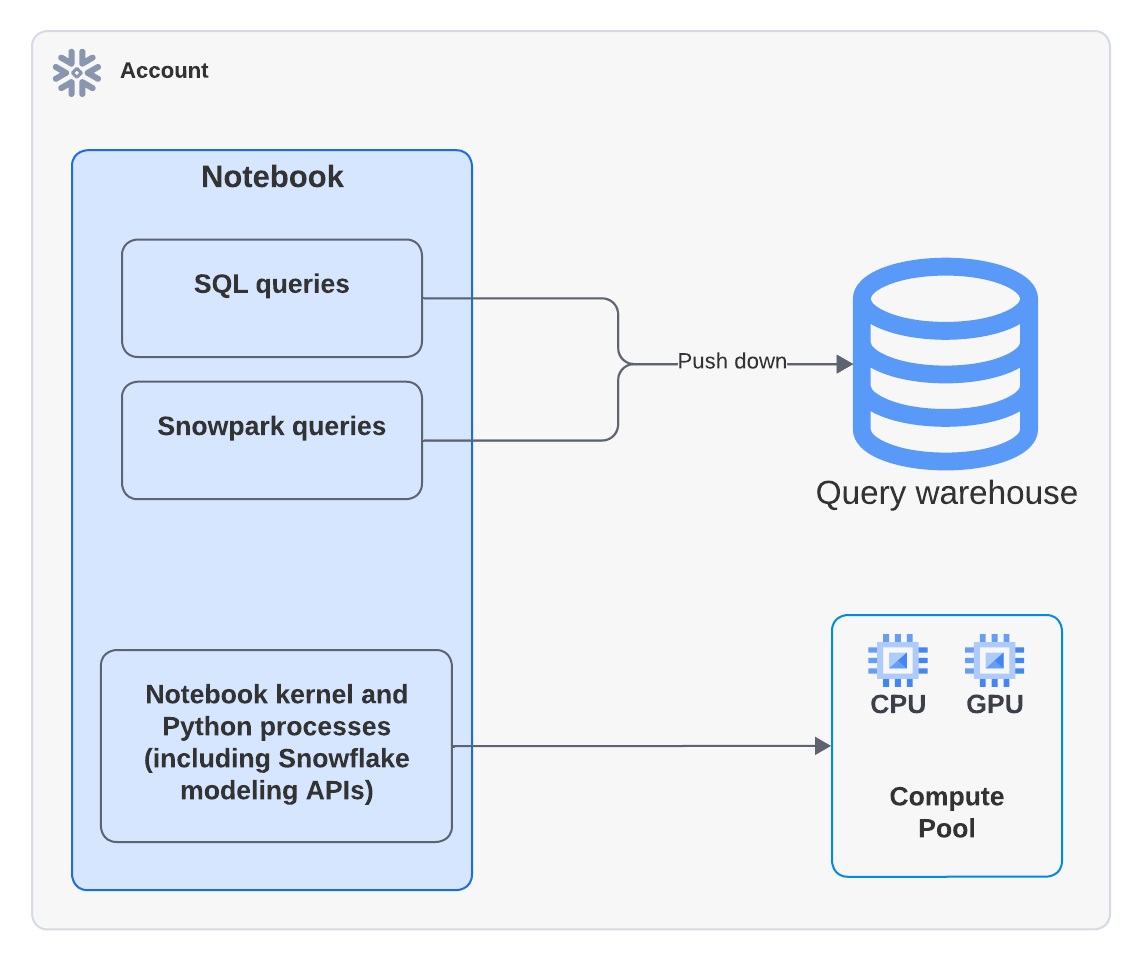
L’exemple Python suivant utilise la bibliothèque xgboost. Les données sont extraites dans le conteneur et le calcul s’effectue sur Snowpark Container Services :
from snowflake.snowpark.context import get_active_session
import pandas as pd
import xgboost as xgb
from sklearn.model_selection import train_test_split
session = get_active_session()
df = session.table("my_dataset")
# Pull data into local memory
df_pd = df.to_pandas()
X = df_pd[['feature1', 'feature2']]
y = df_pd['label']
# Split data into test and train in memory
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.15, random_state=34)
Pour en savoir plus sur les coûts des entrepôts, voir Vue d’ensemble des entrepôts.