pandas on Snowflake¶
Pandas on Snowpark vous permet d’exécuter votre code pandas directement sur vos données dans Snowflake. En modifiant simplement l’instruction d’importation et quelques lignes de code, vous pouvez profiter de l’expérience habituelle de Pandas pour développer des pipelines robustes, tout en bénéficiant de manière transparente des performances et de l’évolutivité de Snowflake à mesure que vos pipelines évoluent.
Pandas on Snowflake détermine intelligemment s’il faut exécuter le code pandas localement ou utiliser le moteur Snowflake pour se mettre à l’échelle et améliorer les performances grâce à l’exécution hybride. Lorsque vous travaillez avec des ensembles de données volumineux dans Snowflake, les charges de travail sont exécutées en mode natif dans Snowflake via une transpilation vers SQL, ce qui permet de tirer parti de la parallélisation et des avantages de Snowflake en matière de gouvernance et de sécurité des données.
Pandas on Snowflake est livré via l’API Pandas Snowpark dans le cadre de la bibliothèque Snowpark Python, qui permet un traitement évolutif des données du code Python au sein de la plateforme Snowflake.
Avantages de l’utilisation de pandas on Snowflake¶
Rencontrer les développeurs Python là où ils se trouvent : pandas on Snowflake offre une interface familière aux développeurs Python en fournissant une couche compatible avec pandas qui peut fonctionner nativement dans Snowflake.
pandas distribués évolutifs : pandas on Snowflake allie la commodité de pandas à l’évolutivité de Snowflake en exploitant les techniques d’optimisation des requêtes existantes dans Snowflake. Des réécritures de code minimales sont requises, ce qui simplifie le parcours de migration et vous permet de passer en toute transparence du prototype à la production.
Aucune infrastructure de calcul supplémentaire à gérer et à ajuster : pandas on Snowflake exploite le moteur de calcul puissant de Snowflake, de sorte que vous n’avez pas besoin de configurer ou de gérer une infrastructure de calcul supplémentaire.
Premiers pas avec pandas on Snowflake¶
Note
Pour un exemple pratique de la façon d’utiliser Pandas on Snowflake, consultez ce notebook et regardez cette vidéo.
Pour installer pandas on Snowflake, vous pouvez utiliser conda ou pip pour installer le paquet. Pour des instructions détaillées, voir Installation.
Une fois pandas on Snowflake installé, au lieu d’importer pandas en tant que import pandas as pd, utilisez les deux lignes suivantes :
Voici un exemple de la façon dont vous pouvez commencer à utiliser pandas on Snowflake via les pandas de la bibliothèque Snowpark Python avec Modin :
read_snowflake prend en charge la lecture à partir de vues Snowflake, de tables dynamiques, de tables Iceberg, etc. Vous pouvez également transmettre directement une requête SQL et obtenir un DataFrame Pandas on Snowflake, ce qui permet de passer facilement de SQL à Pandas on Snowflake.
Comment fonctionne l’exécution hybride¶
Note
À partir de la version 1.40.0 de Snowpark Python, l’exécution hybride est activée par défaut lors de l’utilisation de Pandas on Snowflake.
Pandas on Snowflake utilise l’exécution hybride pour déterminer s’il faut exécuter le code pandas localement ou utiliser le moteur Snowflake pour se mettre à l’échelle et améliorer les performances. Cela vous permet de continuer à écrire du code pandas habituel pour développer des pipelines robustes, sans avoir à réfléchir au moyen le plus optimal et le plus efficace d’exécuter votre code, tout en bénéficiant des performances et de l’évolutivité de Snowflake à mesure que leurs pipelines évoluent.
Exemple 1 : Créer un petit DataFrame de 11 lignes en ligne. Avec l’exécution hybride, Snowflake sélectionne un backend pandas local, en mémoire, pour exécuter l’opération :
Exemple 2 : Initialiser une table contenant 10 millions de lignes de transactions
Vous pouvez voir que la table exploite Snowflake comme backend, car il s’agit d’une grande table qui réside dans Snowflake.
Exemple 3 : Filtrer les données et effectuer une agrégation groupby résultant en 7 lignes de données.
Lorsque les données sont filtrées, Snowflake reconnaît implicitement le choix du backend de changements de moteur de Snowflake vers Pandas, puisque la sortie n’est que de 7 lignes de données.
Remarques et limites¶
Le type de DataFrame sera toujours
modin.pandas.DataFrame/Series/etcmême lorsque le backend change, pour assurer l’interopérabilité/compatibilité avec le code en aval.Pour déterminer le backend à utiliser, Snowflake utilise parfois une estimation de la taille des lignes au lieu de calculer la longueur exacte du DataFrame à chaque étape. Cela signifie que Snowflake peut ne pas toujours basculer vers le backend optimal immédiatement après une opération lorsque l’ensemble de données devient plus grand/plus petit (par exemple, filtre, agrégation).
Lorsqu’une opération combine deux ou plusieurs DataFrames sur les différents backends, Snowflake détermine où déplacer les données en fonction du coût de transfert des données le plus faible.
Les opérations de filtrage peuvent ne pas entraîner de mouvement de données, car Snowflake peut ne pas être en mesure d’estimer la taille des données filtrées sous-jacentes.
Tout DataFrames composé de données Python en mémoire utilisera le backend pandas, comme ce qui suit :
Les DataFrames passeront automatiquement du moteur Snowflake au moteur Pandas sur un ensemble limité d’opérations. Ces opérations comprennent
df.apply,df.plot,df.iterrows,df.itertuples,series.items, ainsi que les opérations de réduction où la taille des données est garantie plus petite. Toutes les opérations ne sont pas prises en charge aux points où la migration des données peut avoir lieu.L’exécution hybride ne déplace pas automatiquement un DataFrame du moteur Pandas vers Snowflake, sauf dans les cas où une opération comme
pd.concatagit sur plusieurs DataFrames.Snowflake ne déplace pas automatiquement un DataFrame du moteur pandas vers Snowflake, à moins qu’une opération comme
pd.concatagit sur plusieurs DataFrames.
Quand utiliser pandas on Snowflake¶
Vous devez utiliser pandas on Snowflake si l’une des conditions suivantes est remplie :
Vous connaissez l’API pandas et l’écosystème plus large PyData.
Vous travaillez en équipe avec d’autres personnes qui connaissent pandas et qui souhaitent collaborer sur la même base de code.
Vous avez du code existant écrit en pandas.
Vous préférez une complétion de code plus précise à partir d’outils de copilote basés sur l’AI.
Pour plus d’informations, voir DataFrames Snowpark contre DataFrame pandas Snowpark : lequel dois-je choisir ?
Utilisation de pandas on Snowflake avec des DataFrames Snowpark¶
L’API pandas on Snowflake et l’API DataFrame sont hautement interopérables, vous pouvez donc créer un pipeline qui exploite ces deux APIs. Pour plus d’informations, voir DataFrames Snowpark contre DataFrame pandas Snowpark : lequel dois-je choisir ?
Vous pouvez utiliser les opérations suivantes pour effectuer des conversions entre des DataFrames Snowpark et des DataFrames Snowpark pandas :
Fonctionnement |
Entrée |
Sortie |
|---|---|---|
DataFrame Snowpark |
DataFrame Snowpark Pandas |
|
DataFrame Snowpark pandas ou Snowpark pandas Series |
DataFrame Snowpark |
Comparaison de pandas on Snowflake et de pandas natif¶
Pandas on Snowflake et pandas natif ont des APIs DataFrame similaires avec des signatures correspondantes et une sémantique similaire. Pandas on Snowflake fournit la même signature d’API que pandas natif et fournit un calcul évolutif avec Snowflake. Pandas on Snowflake respecte autant que possible la sémantique décrite dans la documentation native de pandas, mais il utilise le système de calcul et de type Snowflake. Cependant, lorsque pandas natif s’exécute sur une machine cliente, il utilise le système de calcul et de type de Python. Pour obtenir des informations sur le mappage des types entre pandas on Snowflake et Snowflake, consultez Types de données.
À partir de Snowpark Python 1.40.0, pandas on Snowflake est plus efficace avec des données déjà présentes dans Snowflake. Pour effectuer la conversion entre pandas natif et pandas on Snowflake, utilisez les opérations suivantes :
Fonctionnement |
Entrée |
Sortie |
|---|---|---|
DataFrame Snowpark Pandas |
DataFrame pandas natif - Matérialisez toutes les données dans l’environnement local. Si l’ensemble de données est volumineux, il peut en résulter une erreur de mémoire insuffisante. |
|
DataFrame pandas natif, données brutes, objet pandas Snowpark |
DataFrame Snowpark Pandas |
Environnement d’exécution¶
pandas: fonctionne sur une seule machine et traite les données en mémoire.pandas on Snowflake: S’intègre à Snowflake, qui permet un calcul distribué sur un cluster de machines pour de grands ensembles de données, tout en exploitant les pandas en mémoire pour le traitement de petits ensembles de données. Cette intégration permet de traiter des ensembles de données beaucoup plus importants qui dépassent la capacité de mémoire d’une seule machine. Notez que l’utilisation d’API pandas Snowpark nécessite une connexion à Snowflake.
Évaluation paresseuse versus exigeante¶
pandas: Exécute les opérations immédiatement et matérialise les résultats intégralement dans la mémoire après chaque opération. Cette évaluation exigeante des opérations peut entraîner une pression accrue sur la mémoire, car les données doivent être déplacées de manière intensive au sein d’une machine.pandas on Snowflake: fournit la même expérience d’API que pandas. Cela imite le modèle d’évaluation exigeante de pandas, mais construit en interne un graphe de requête à évaluation paresseuse pour permettre l’optimisation entre les opérations.La fusion et la transposition des opérations dans un graphe de requêtes offrent des possibilités d’optimisation supplémentaires pour le moteur de calcul distribué Snowflake sous-jacent, ce qui réduit à la fois le coût et la durée d’exécution du pipeline de bout en bout par rapport à l’exécution de pandas directement dans Snowflake.
Note
Les APIs liées aux E/S et les APIs dont la valeur de retour n’est pas un objet pandas Snowpark (c’est-à-dire
DataFrame,SeriesouIndex) s’évaluent toujours avec exigence. Par exemple :read_snowflaketo_snowflaketo_pandasto_dictto_list__repr__La méthode dunder,
__array__qui peut être appelée automatiquement par certaines bibliothèques tierces telles que scikit-learn. Les appels à cette méthode matérialiseront les résultats sur la machine locale.
Source et stockage des données¶
pandas: prend en charge les différents lecteurs et rédacteurs listés dans la documentation de pandas dans les outils IO (texte, CSV, HDF5, …).pandas on Snowflake: Peut lire et écrire à partir de tables Snowflake et lire des fichiers CSV, JSON ou Parquet locaux ou mis en zone de préparation. Pour plus d’informations, consultez IO (lecture et écriture).
Types de données¶
pandas: possède un riche ensemble de types de données, tels que les entiers, les flottants, les chaînes, les typesdatetimeet les types catégoriels. Prend également en charge les types de données définis par l’utilisateur. Les types de données dans pandas sont généralement dérivés des données sous-jacentes et sont appliqués de manière stricte.pandas on Snowflake: est limité par le système de types Snowflake, qui mappe les objets pandas à SQL en traduisant les types de données pandas en types SQL dans Snowflake. Une majorité de types pandas ont un équivalent naturel dans Snowflake, mais le mappage n’est pas toujours univoque. Dans certains cas, plusieurs types pandas sont mappés vers le même type SQL.
Le tableau suivant liste les mappages de types entre pandas et Snowflake SQL :
type pandas |
Type Snowflake |
|---|---|
Tous les types d’entiers signés/non signés, y compris les types d’entiers étendus pandas |
NUMBER(38, 0) |
Tous les types de flottants, y compris les types de données flottants étendus de pandas |
FLOAT |
|
BOOLEAN |
|
STRING |
|
TIME |
|
DATE |
Tous les types de |
TIMESTAMP_NTZ |
Tous les types de |
TIMESTAMP_TZ |
|
ARRAY |
|
MAP |
Colonne d’objets avec des types de données mixtes |
VARIANT |
Timedelta64[ns] |
NUMBER(38, 0) |
Note
Les types de données suivants ne sont pas pris en charge : données catégorielles, données de période, données d’intervalle, données éparses et données définies par l’utilisateur. Timedelta n’est actuellement pris en charge que sur le client pandas de Snowpark. Lors de la réécriture de Timedelta dans Snowflake, il sera stocké sous forme de type Nombre.
Le tableau suivant fournit le mappage des types SQL de Snowflake vers les types de pandas on Snowflake à l’aide de df.dtypes :
Type Snowflake |
type pandas on Snowflake ( |
|---|---|
NUMBER ( |
|
NUMBER ( |
|
BOOLEAN |
|
STRING, TEXT |
|
VARIANT, BINARY, GEOMETRY, GEOGRAPHY |
|
ARRAY |
|
OBJECT |
|
TIME |
|
TIMESTAMP, TIMESTAMP_NTZ, TIMESTAMP_LTZ, TIMESTAMP_TZ |
|
DATE |
|
Lors de la conversion du DataFrame pandas Snowpark en DataFrame pandas natif avec to_pandas(), le DataFrame pandas natif aura des types de données affinés par rapport aux types de pandas on Snowflake, qui sont compatibles avec Mappages des types de données SQL-Python pour les fonctions et les procédures.
Casting et inférence de type¶
pandas: s’appuie sur NumPy et suit par défaut le système de type NumPy et Python pour le casting implicite des types et l’inférence. Par exemple, il traite les booléens comme des types entiers, de sorte que1 + Truerenvoie2.pandas on Snowflake: mappe NumPy et les types Python en types Snowflake selon le tableau précédent, et utilise le système de types Snowflake sous-jacent pour le casting implicite des types et l’inférence. Par exemple, conformément à Types de données logiques, il ne convertit pas implicitement les booléens en types entiers, de sorte que1 + Trueentraîne une erreur de conversion de type.
Traitement des valeurs nulles¶
pandas: dans les versions 1.x de pandas, pandas était flexible lorsqu’il traitait les données manquantes, il traitait donc toutes les valeurs manquantes PythonNone,np.nan,pd.NaN,pd.NA, etpd.NaTcomme des valeurs manquantes. Dans les versions ultérieures de pandas (2.2.x), ces valeurs sont traitées comme des valeurs différentes.pandas on Snowflake: adopte une approche similaire aux versions antérieures de pandas qui traite toutes les valeurs précédentes de la liste comme des valeurs manquantes. Snowpark réutiliseNaN,NA, etNaTde pandas. Mais notez que toutes ces valeurs manquantes sont traitées de manière interchangeable et stockées en tant que valeurs SQL NULL dans la table Snowflake.
Alias de décalage/fréquence¶
pandas: les décalages de date dans pandas ont été modifiés dans la version 2.2.1. Les alias à une lettre'M','Q','Y', et autres ont été abandonnés au profit de décalages à deux lettres.pandas on Snowflake: utilise exclusivement les nouveaux décalages décrits dans la documentation sur les séries temporelles pandas.
Installer la bibliothèque pandas on Snowflake¶
Conditions préalables
Les versions de paquet suivantes sont nécessaires :
Python 3.9 (obsolète), 3.10, 3.11, 3.12 ou 3.13
Version Modin 0.32.0
version pandas 2.2.*
Astuce
Pour utiliser pandas on Snowflake dans Snowflake Notebooks, voir les instructions d’installation dans Pandas on Snowflake dans des notebooks.
Pour installer Pandas on Snowflake dans votre environnement de développement, suivez ces étapes :
Allez dans le répertoire de votre projet et activez votre environnement virtuel Python.
Note
L’API étant en cours de développement, nous vous recommandons de l’installer dans un environnement virtuel Python plutôt que sur l’ensemble du système. Cette pratique permet à chaque projet que vous créez d’utiliser une version spécifique, ce qui vous protège des modifications apportées aux versions ultérieures.
Vous pouvez créer un environnement virtuel Python pour une version particulière de Python à l’aide d’outils tels que Anaconda, Miniconda ou virtualenv.
Par exemple, pour utiliser conda afin de créer un environnement virtuel Python 3.12, exécutez ces commandes :
Note
Si vous avez précédemment installé une version plus ancienne de Pandas on Snowflake en utilisant Python 3.9 et pandas 1.5.3, vous devrez mettre à niveau vos versions de Python et de pandas comme décrit ci-dessus. Suivez ces étapes pour créer un nouvel environnement avec Python 3.10 ou 3.13.
Installez la bibliothèque Snowpark Python avec Modin :
ou
Note
Assurez-vous que la version 1.17.0 ou ultérieure de
snowflake-snowpark-pythonest installée.
Authentification à Snowflake¶
Avant d’utiliser pandas on Snowflake, vous devez établir une session avec la base de données Snowflake. Vous pouvez utiliser un fichier de configuration pour choisir les paramètres de connexion de votre session ou les énumérer dans votre code. Pour plus d’informations, consultez Création d’une session pour Snowpark Python. S’il existe une session active unique de Snowpark Python, pandas on Snowflake l’utilisera automatiquement. Par exemple :
pd.session est une session de Snowpark, vous pouvez donc faire tout ce que vous pouvez faire avec n’importe quelle autre session de Snowpark. Par exemple, vous pouvez l’utiliser pour exécuter une requête SQL arbitraire, qui produit un DataFrame Snowpark conformément à l’API de session, mais notez que le résultat sera un DataFrame Snowpark, et non un DataFrame Snowpark pandas.
Vous pouvez également configurer vos paramètres de connexion Snowpark dans un fichier de configuration. Cela élimine le besoin d’énumérer les paramètres de connexion dans votre code, ce qui vous permet d’écrire votre code pandas on Snowflake presque comme vous écririez normalement du code pandas.
Créez un fichier de configuration à l’adresse
~/.snowflake/connections.tomlqui ressemble à ceci :Pour créer une session à l’aide de ces identifiants de connexion, utilisez
snowflake.snowpark.Session.builder.create():
Vous pouvez également créer plusieurs sessions Snowpark, puis en attribuer une à pandas on Snowflake. pandas on Snowflake n’utilise qu’une seule session. Vous devez donc attribuer explicitement l’une des sessions à pandas on Snowflake avec pd.session = pandas_session.
L’exemple suivant montre qu’en essayant d’utiliser pandas on Snowflake alors qu’il n’y a pas de session Snowpark active, vous obtiendrez SnowparkSessionException avec une erreur du type « pandas on Snowflake requiert une session Snowpark active, mais il n’y en a aucune. » Après avoir créé une session, vous pouvez utiliser pandas on Snowflake. Par exemple :
L’exemple suivant montre qu’en essayant d’utiliser pandas on Snowflake lorsqu’il y a plusieurs sessions Snowpark actives, vous obtiendrez SnowparkSessionException avec un message du type « Il y a plusieurs sessions snowpark actives, mais vous devez en choisir une pour pandas on Snowflake. »
Note
Vous devez définir la session utilisée pour un nouveau DataFrame Pandas on Snowflake ou Series via modin.pandas.session. Cependant, la jointure ou la fusion de DataFrames créés avec des sessions différentes n’est pas prise en charge, vous devez donc éviter de définir plusieurs fois des sessions différentes et de créer des DataFrames avec des sessions différentes dans un flux de travail.
Référence API¶
Voir la référence d’API pandas on Snowflake pour une liste complète des APIs et des méthodes mises en œuvre actuellement disponibles.
Pour une liste complète des opérations prises en charge, consultez les tableaux suivants dans la référence de pandas on Snowflake :
APIs DataFrame prises en charge
APIs GroupBy prises en charge
APIs DatetimeProperties prises en charge
APIs StringMethods prises en charge
APIs et paramètre de configuration pour l’exécution hybride¶
L’exécution hybride utilise une combinaison de l’estimation de la taille de l’ensemble de données et des opérations appliquées au DataFrame pour déterminer le choix du backend. En général, les ensembles de données de moins de 100 000 lignes auront tendance à utiliser des pandas locaux. Ceux de plus de 100 000 lignes auront tendance à utiliser Snowflake, à moins que l’ensemble de données ne soit chargé à partir de fichiers locaux.
Configuration des coûts de transfert¶
Pour remplacer le seuil de basculement par défaut par une autre valeur de limite de lignes, vous pouvez modifier la variable d’environnement avant d’initialiser un DataFrame :
La définition de cette valeur pénalisera le transfert de lignes hors de Snowflake.
Configuration des limites d’exécution locale¶
Une fois qu’un DataFrame est local, il restera généralement local à moins qu’il ne soit nécessaire de le ramener à Snowflake pour une fusion, mais il existe une limite supérieure prise en compte pour la taille maximale des données pouvant être traitées localement. Actuellement, cette limite est de 10 millions de lignes.
Vérification et définition du backend¶
Pour vérifier le backend actuel du choix, vous pouvez utiliser la commande df.getbackend(), qui renvoie Pandas pour une exécution locale, ou Snowflake pour l’exécution du pushdown.
Pour définir le backend actuel du choix avec set_backend ou son alias move_to :
Vous pouvez également définir le backend en place :
Pour inspecter et afficher des informations sur la raison pour laquelle les données ont été déplacées :
Remplacer manuellement la sélection du backend par l’épinglage du backend¶
Par défaut, Snowflake choisit automatiquement le meilleur backend pour un DataFrame et une opération donnés. Si vous souhaitez remplacer la sélection automatique des moteurs, vous pouvez désactiver le basculement automatique sur un objet et toutes les données résultantes produites par celui-ci, en utilisant la méthode pin_backend() :
Pour réactiver le basculement automatique du backend, appelez unpin_backend() :
Utilisation des pandas Snowpark dans les Notebooks Snowflake¶
Pour utiliser pandas on Snowflake dans les Notebooks Snowflake, voir pandas on Snowflake dans les Notebooks.
Utilisation des pandas Snowpark dans les feuilles de calcul Python¶
Pour utiliser les pandas Snowpark, vous devez installer Modin en sélectionnant modin à partir de Packages dans l’environnement de feuille de calcul Python.
Vous pouvez sélectionner le type de retour de la fonction Python sous Settings > Return type. Par défaut, il est défini sur une table Snowpark. Pour afficher le DataFrame pandas Snowpark comme résultat, vous pouvez convertir un DataFrame pandas Snowpark en DataFrame Snowpark en appelant to_snowpark(). Aucun coût d’E/S ne sera encouru lors de cette conversion.
Voici un exemple d’utilisation des pandas Snowpark avec les feuilles de calcul Python :
Utilisation de pandas on Snowflake dans les procédures stockées¶
Vous pouvez utiliser pandas on Snowflake dans une procédure stockée pour créer un pipeline de données et planifier l’exécution de la procédure stockée avec des tâches.
Voici comment vous pouvez créer une procédure stockée à l’aide de SQL :
Voici comment vous pouvez créer une procédure stockée à l’aide de l’API Snowflake Python :
Pour appeler la procédure stockée, vous pouvez exécuter dt_pipeline_sproc() en Python ou CALL run_data_transformation_pipeline_sp() en SQL.
Utilisation de pandas on Snowflake avec des bibliothèques tierces¶
Pandas est couramment utilisé avec les APIs de la bibliothèque tierce pour les applications de visualisation et de machine learning. pandas on Snowflake est interopérable avec la plupart de ces bibliothèques, de sorte qu’elles peuvent être utilisées sans être converties explicitement en DataFrames Pandas. Notez toutefois que l’exécution distribuée n’est pas souvent prise en charge dans la plupart des bibliothèques tierces, sauf dans des cas d’utilisation limités. Par conséquent, cela peut conduire à des performances plus lentes sur les grands ensembles de données.
Bibliothèques tierces prises en charge¶
Les bibliothèques listées ci-dessous acceptent en entrée les DataFrames pandas on Snowflake, mais toutes leurs méthodes n’ont pas été testées. Pour un statut d’interopérabilité approfondi au niveau de l’API, voir Interopérabilité avec des bibliothèques tierces.
Plotly
Altair
Seaborn
Matplotlib
Numpy
Scikit-learn
XGBoost
NLTK
Streamlit
pandas on Snowflake a actuellement une compatibilité limitée pour certaines APIs NumPy et Matplotlib, comme une implémentation distribuée pour np.where et l’interopérabilité avec df.plot. En convertissant des DataFrames pandas Snowpark via to_pandas() lorsque vous travaillez avec ces bibliothèques tierces, vous éviterez plusieurs appels d’E/S.
Voici un exemple avec Altaïr pour la visualisation et scikit-learn pour le machine learning.
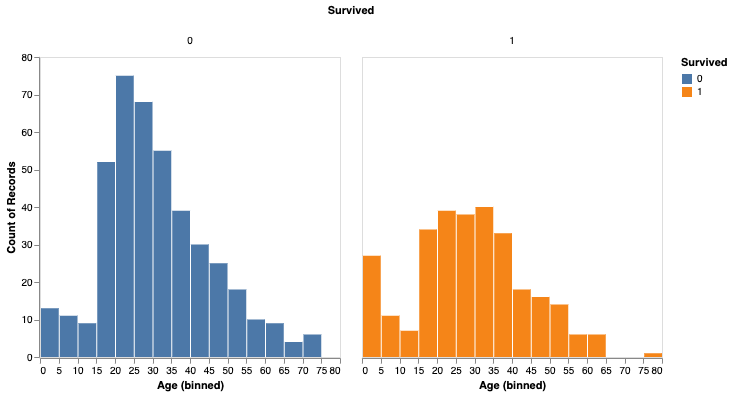
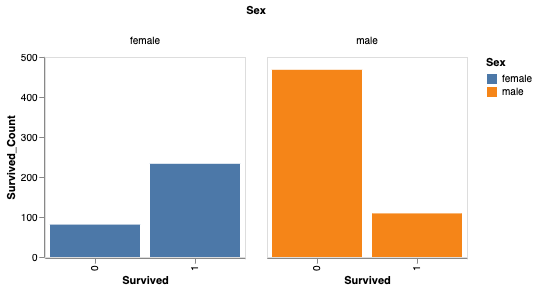
Vous pouvez également analyser le taux de survie en fonction du sexe.
Vous pouvez désormais utiliser scikit-learn pour entraîner un modèle simple.
Note
Pour plus de performance, nous vous recommandons une conversion en DataFrames pandas via to_pandas(), en particulier lorsque vous utilisez des bibliothèques de machine learning telles que scikit-learn. Cependant, la fonction to_pandas() collecte toutes les lignes. Il peut donc être préférable de réduire d’abord la taille du dataframe à l’aide de sample(frac=0.1) ou head(10).
Bibliothèques non prises en charge¶
Lorsque vous utilisez des bibliothèques tierces non prises en charge avec un DataFrame pandas on Snowflake, nous vous recommandons de convertir le DataFrame pandas on Snowflake DataFrame pandas en appelant to_pandas() avant de transmettre le DataFrame à la méthode de la bibliothèque tierce.
Note
L’appel de to_pandas() extrait vos données de Snowflake et les place en mémoire, alors gardez cela à l’esprit pour les grands ensembles de données et les cas d’utilisation sensibles.
Utilisation des fonctions Snowflake Cortex LLM avec Snowpark pandas¶
Vous pouvez utiliser les fonctions Snowflake Cortex LLM via la fonction Snowpark pandas.
Vous appliquez la fonction avec des arguments de mot-clé spéciaux. Actuellement, les fonctions Cortex suivantes sont prises en charge :
L’exemple suivant utilise la fonction TRANSLATE sur plusieurs enregistrements dans un DataFrame Snowpark pandas :
Sortie :
L’exemple suivant utilise la fonction SENTIMENT (SNOWFLAKE.CORTEX) sur une table Snowflake nommée reviews :
L’exemple suivant utilise EXTRACT_ANSWER (SNOWFLAKE.CORTEX) pour répondre à une question :
Sortie :
Note
Le paquet snowflake-ml-python doit être installé pour utiliser les fonctions Cortex LLM.
Limitations¶
pandas on Snowflake présente les limitations suivantes :
pandas on Snowflake n’offre aucune garantie de compatibilité avec les bibliothèques tierces OSS. À partir de la version 1.14.0a1, cependant, Snowpark pandas introduit une compatibilité limitée pour NumPy, en particulier pour l’utilisation de
np.where. Pour plus d’informations, voir Intéropérabilité de NumPy.Lorsque vous appelez des APIs de la bibliothèque tierce avec un DataFrame Snowpark pandas, Snowflake vous recommande de convertir le DataFrame Snowpark pandas en DataFrame pandas en appelant
to_pandas()avant de transmettre le DataFrame vers l’appel de la bibliothèque tierce. Pour plus d’informations, voir Utilisation de pandas on Snowflake avec des bibliothèques tierces.pandas on Snowflake n’est pas intégré à Snowpark ML. Lorsque vous utilisez Snowpark ML, nous vous recommandons de convertir le DataFrame pandas de Snowpark en un DataFrame Snowpark à l’aide de `to_snowpark()<https://docs.snowflake.com/developer-guide/snowpark/reference/python/latest/modin/pandas_api/modin.pandas.to_snowpark>`_ avant d’appeler Snowpark ML.
Les objets
MultiIndexparesseux ne sont pas pris en charge. LorsqueMultiIndexest utilisé, il renvoie un objetMultiIndexpandas natif, ce qui nécessite d’extraire toutes les données du côté client.Toutes les APIs pandas n’ont pas encore d’implémentation distribuée dans pandas on Snowflake, bien que certaines soient ajoutées. Pour les APIs non prises en charge,
NotImplementedErrorest levé. Pour obtenir des informations sur les APIs prises en charge, reportez-vous à la documentation de référence des API.pandas on Snowflake assure la compatibilité avec n’importe quelle version patch de pandas 2.2.
Snowpark Pandas ne peut pas être référencé dans la fonction Snowpark Pandas
apply. Vous ne pouvez utiliser que des pandas natifs dansapply.Voici un exemple :
Résolution des problèmes¶
Cette section décrit des conseils de dépannage pour l’utilisation de pandas on Snowflake.
Lors du dépannage, essayez d’exécuter la même opération sur un DataFrame pandas natif (ou un échantillon) pour voir si la même erreur persiste. Cette approche pourrait fournir des indications sur la manière de résoudre votre requête. Par exemple :
Si vous avez un notebook ouvert depuis longtemps, notez que, par défaut, les sessions Snowflake se terminent au bout de 240 minutes (4 heures) d’inactivité. Lorsque la session expire, si vous exécutez d’autres requêtes pandas on Snowflake, le message suivant apparaît : « Le jeton d’authentification a expiré. L’utilisateur doit s’authentifier à nouveau. » À ce stade, vous devez rétablir la connexion avec Snowflake. Cela peut entraîner la perte de toute variable de session non persistante. Pour plus d’informations sur la configuration du paramètre de délai d’inactivité de la session, voir Politiques de session.
Meilleures pratiques¶
Cette section décrit les meilleures pratiques à suivre lors de l’utilisation de pandas on Snowflake.
Évitez d’utiliser des modèles de code itératifs, tels que les boucles
for,iterrowsetiteritems. Les modèles de code itératifs augmentent rapidement la complexité de la requête générée. Laissez pandas on Snowflake, et non le code client, effectuer la distribution des données et la parallélisation des calculs. En ce qui concerne les modèles de code itératifs, recherchez les opérations qui peuvent être effectuées sur l’ensemble du DataFrame, et utilisez les opérations correspondantes à la place.
Évitez d’appeler
apply,applymapettransform, qui sont finalement mis en œuvre avec des UDFs ou des UDTFs, qui peuvent ne pas être aussi performantes que les requêtes SQL habituelles. Si la fonction appliquée possède une opération équivalente sur un DataFrame ou des séries, utilisez cette opération à la place. Par exemple, au lieu dedf.groupby('col1').apply('sum'), appelez directementdf.groupby('col1').sum().Appelez
to_pandas()avant de passer le DataFrame ou une série vers un appel de bibliothèque tierce. pandas on Snowflake ne fournit pas de garantie de compatibilité avec les bibliothèques tierces.Utilisez une table Snowflake matérialisée régulière pour éviter une surcharge d’E/S supplémentaire. pandas on Snowflake fonctionne sur un instantané de données qui ne fonctionne que pour les tables régulières. Pour les autres types, y compris les tables externes, les vues et les tables Apache Iceberg™, une table temporaire est créée avant la prise de l’instantané, ce qui entraîne une surcharge supplémentaire liée à la matérialisation.
pandas on Snowflake fournit une capacité de clonage rapide et sans copie lors de la création de DataFrames à partir de tables de Snowflake avec
read_snowflake.Vérifiez deux fois le type de résultat avant de procéder à d’autres opérations, et effectuez un casting de type explicite à l’aide de
astypesi nécessaire.En raison de la capacité limitée d’inférence de type, si aucune indication de type n’est donnée,
df.applyrenverra des résultats de type objet (variante) même si le résultat contient toutes les valeurs entières. Si d’autres opérations nécessitent que la colonnedtypesoitint, vous pouvez procéder à un casting de type explicite en appelant la méthodeastypepour corriger le type de la colonne avant de continuer.Évitez d’appeler des APIs qui nécessitent une évaluation et une matérialisation si cela n’est pas nécessaire.
Les APIs qui ne renvoient pas
SeriesouDataframenécessitent une évaluation exigeante et une matérialisation pour produire le résultat dans le bon type. Il en va de même pour les méthodes de traçage. Réduisez les appels vers les APIs afin de réduire les évaluations et la matérialisation inutiles.Évitez d’appeler
np.where(<cond>, <scalar>, n)sur les grands ensembles de données.<scalar >sera diffusé à un DataFrame de la taille de<cond>, ce qui peut être lent.Lorsque vous travaillez avec des requêtes construites de manière itérative,
df.cache_resultpeut être utilisé pour matérialiser des résultats intermédiaires afin de réduire l’évaluation répétée et d’améliorer la latence et de réduire la complexité de la requête globale. Par exemple :Dans l’exemple ci-dessus, la requête permettant de produire
df2est coûteuse à calculer et est réutilisée dans la création dedf3et dedf4. La matérialisation dedf2dans une table temporaire (en faisant des opérations ultérieures impliquantdf2un balayage de table au lieu d’un pivot) peut réduire la latence globale du bloc de code :
Exemples¶
Voici un exemple de code avec des opérations pandas. Nous commençons par un DataFrame pandas Snowpark nommé pandas_test, qui contient trois colonnes : COL_STR, COL_FLOAT, et COL_INT. Pour voir le notebook associé à ces exemples, consultez les exemples de pandas on Snowflake dans le référentiel Snowflake-Labs.
Nous enregistrons le DataFrame sous la forme d’une table Snowflake nommée pandas_test, que nous utiliserons tout au long de nos exemples.
Ensuite, nous créons un DataFrame à partir de la table Snowflake. Nous supprimons la colonne COL_INT et sauvegardons le résultat dans Snowflake avec une colonne nommée row_position.
Le résultat est une nouvelle table, pandas_test2, qui ressemble à ceci :
IO (lecture et écriture)¶
Pour plus d’informations, voir Entrée/sortie.
Indexation¶
Valeurs manquantes¶
Type de conversion¶
Opérations binaires¶
Agrégation¶
Fusionner¶
Groupby¶
Pour plus d’informations, voir GroupBy.