Fonctions agrégées définies par l’utilisateur Python¶
Les fonctions agrégées définies par l’utilisateur (UDAFs) prennent une ou plusieurs lignes en entrée et produisent une seule ligne en sortie. Elles agissent sur les valeurs de lignes pour effectuer des calculs mathématiques tels que la somme, la moyenne, le comptage, les valeurs minimale/maximale, l’écart type et l’estimation, ainsi que d’autres opérations non mathématiques.
Les UDAFs Python vous permettent d’écrire vos propres fonctions d’agrégation qui sont similaires aux fonctions d’agrégation SQL définies par le système Snowflake.
aggregate_state a une taille maximale de 64 MB dans une version sérialisée, essayez donc de contrôler la taille de l’état agrégé.
Vous ne pouvez pas appeler une UDAF en tant que fonction de fenêtre (en d’autres termes, avec une clause OVER).
IMMUTABLE n’est pas pris en charge sur une fonction d’agrégation (lorsque vous utilisez le paramètre AGGREGATE). Par conséquent, toutes les fonctions d’agrégation sont VOLATILE par défaut.
Les fonctions d’agrégation définies par l’utilisateur ne peuvent pas être utilisées conjointement avec la clause WITHIN GROUP. Les requêtes ne pourront pas être exécutées.
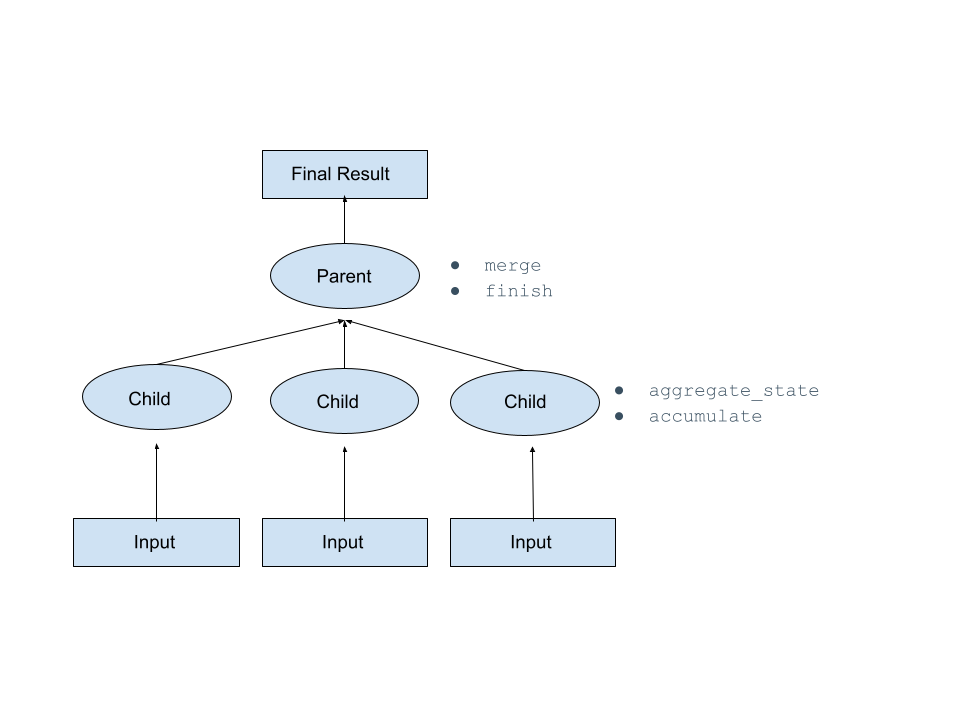
Interface pour le gestionnaire (handler) de la fonction d’agrégation¶
Une fonction d’agrégation regroupe les états des nœuds enfants, puis ces états agrégés sont sérialisés et envoyés au nœud parent où ils sont fusionnés et où le résultat final est calculé.
Pour définir une fonction agrégée, vous devez définir une classe Python (qui est le gestionnaire (handler) de la fonction) qui comprend des méthodes que Snowflake appelle au moment de l’exécution. Ces méthodes sont décrites dans le tableau ci-dessous. Voir les exemples ailleurs dans cette rubrique.
Un objet d’état agrégé peut être n’importe quel type de données Python sérialisable par la bibliothèque Python pickle.
Pour les états agrégés simples, utilisez un type de données primitif Python. Pour des états agrégés plus complexes, utilisez les classes de données Python.
accumulate
Obligatoire
Accumule l’état de l’agrégat sur la base de la nouvelle ligne d’entrée.
merge
Obligatoire
Combine deux états agrégés intermédiaires.
finish
Obligatoire
Produit le résultat final sur la base de l’état agrégé.
Le code de l’exemple suivant définit une fonction d’agrégation définie par l’utilisateur python_sum (UDAF) pour renvoyer la somme des valeurs numériques.
Créez l’UDAF.
CREATEORREPLACEAGGREGATEFUNCTIONPYTHON_SUM(aINT)RETURNSINTLANGUAGEPYTHONRUNTIME_VERSION=3.12HANDLER='PythonSum'AS$$classPythonSum:def__init__(self):# This aggregate state is a primitive Python data type.self._partial_sum=0@propertydefaggregate_state(self):returnself._partial_sumdefaccumulate(self,input_value):self._partial_sum+=input_valuedefmerge(self,other_partial_sum):self._partial_sum+=other_partial_sumdeffinish(self):returnself._partial_sum$$;
Le code de l’exemple suivant définit une fonction d’agrégation définie par l’utilisateur python_avg pour renvoyer la moyenne des valeurs numériques.
Créez la fonction.
CREATEORREPLACEAGGREGATEFUNCTIONpython_avg(aINT)RETURNSFLOATLANGUAGEPYTHONRUNTIME_VERSION=3.12HANDLER='PythonAvg'AS$$fromdataclassesimportdataclass@dataclassclassAvgAggState:count:intsum:intclassPythonAvg:def__init__(self):# This aggregate state is an object data type.self._agg_state=AvgAggState(0,0)@propertydefaggregate_state(self):returnself._agg_statedefaccumulate(self,input_value):sum=self._agg_state.sumcount=self._agg_state.countself._agg_state.sum=sum+input_valueself._agg_state.count=count+1defmerge(self,other_agg_state):sum=self._agg_state.sumcount=self._agg_state.countother_sum=other_agg_state.sumother_count=other_agg_state.countself._agg_state.sum=sum+other_sumself._agg_state.count=count+other_countdeffinish(self):sum=self._agg_state.sumcount=self._agg_state.countreturnsum/count$$;
Exemple : renvoyer les k premières valeurs les plus élevées¶
Le code de l’exemple suivant renvoie une liste des plus grandes valeurs pour k. Le code accumule les valeurs d’entrée négatives sur un tas min, puis renvoie les k valeurs les plus importantes.
CREATEORREPLACEAGGREGATEFUNCTIONpythonTopK(inputINT,kINT)RETURNSARRAYLANGUAGEPYTHONRUNTIME_VERSION=3.12HANDLER='PythonTopK'AS$$importheapqfromdataclassesimportdataclassimportitertoolsfromtypingimportList@dataclassclassAggState:minheap:List[int]k:intclassPythonTopK:def__init__(self):self._agg_state=AggState([],0)@propertydefaggregate_state(self):returnself._agg_state@staticmethoddefget_top_k_items(minheap,k):# Return k smallest elements if there are more than k elements on the min heap.if(len(minheap)>k):return[heapq.heappop(minheap)foriinrange(k)]returnminheapdefaccumulate(self,input,k):self._agg_state.k=k# Store the input as negative value, as heapq is a min heap.heapq.heappush(self._agg_state.minheap,-input)# Store only top k items on the min heap.self._agg_state.minheap=self.get_top_k_items(self._agg_state.minheap,k)defmerge(self,other_agg_state):k=self._agg_state.kifself._agg_state.k>0elseother_agg_state.k# Merge two min heaps by popping off elements from one and pushing them onto another.while(len(other_agg_state.minheap)>0):heapq.heappush(self._agg_state.minheap,heapq.heappop(other_agg_state.minheap))# Store only k elements on the min heap.self._agg_state.minheap=self.get_top_k_items(self._agg_state.minheap,k)deffinish(self):return[-xforxinself._agg_state.minheap]$$;
CREATEORREPLACETABLEnumbers_table(num_columnINT);INSERTINTOnumbers_tableSELECT5FROMTABLE(GENERATOR(ROWCOUNT=>10));INSERTINTOnumbers_tableSELECT1FROMTABLE(GENERATOR(ROWCOUNT=>10));INSERTINTOnumbers_tableSELECT9FROMTABLE(GENERATOR(ROWCOUNT=>10));INSERTINTOnumbers_tableSELECT7FROMTABLE(GENERATOR(ROWCOUNT=>10));INSERTINTOnumbers_tableSELECT10FROMTABLE(GENERATOR(ROWCOUNT=>10));INSERTINTOnumbers_tableSELECT3FROMTABLE(GENERATOR(ROWCOUNT=>10));-- Return top 15 largest values from numbers_table.SELECTpythonTopK(num_column,15)FROMnumbers_table;