Pythonユーザー定義集計関数¶
ユーザー定義集計関数(UDAFs)は1つ以上の行を入力として受け取り、1行の出力を生成します。複数行全体の値を操作して、合計、平均、カウント、最小値/最大値の探索、標準偏差、推定などの数学的計算に加え、一部の非数学的な演算も実行します。
Python UDAFs は、Snowflakeのシステム定義の SQL 独自の集計関数 に似たものを作成する方法を提供します。
また、 Pythonにおける DataFrames 用ユーザー定義関数(UDAFs)の作成 で説明されているように、Snowpark APIs を使用して独自の UDAFs を作成することもできます。
制限事項¶
aggregate_stateのシリアル化されたバージョンの最大サイズは64 MB であるため、集計状態のサイズを制御してみてください。UDAF を ウィンドウ関数 として呼び出すことはできません(言い換えれば、OVER 句を使用して)。
IMMUTABLE は集計関数ではサポートされていません(AGGREGATE パラメーターを使用する場合)。したがって、すべての集計関数はデフォルトで VOLATILE です。
ユーザー定義集約関数は、 WITHIN GROUP 句と共に使用することはできません。クエリの実行に失敗します。
集計関数ハンドラーのインターフェイス¶
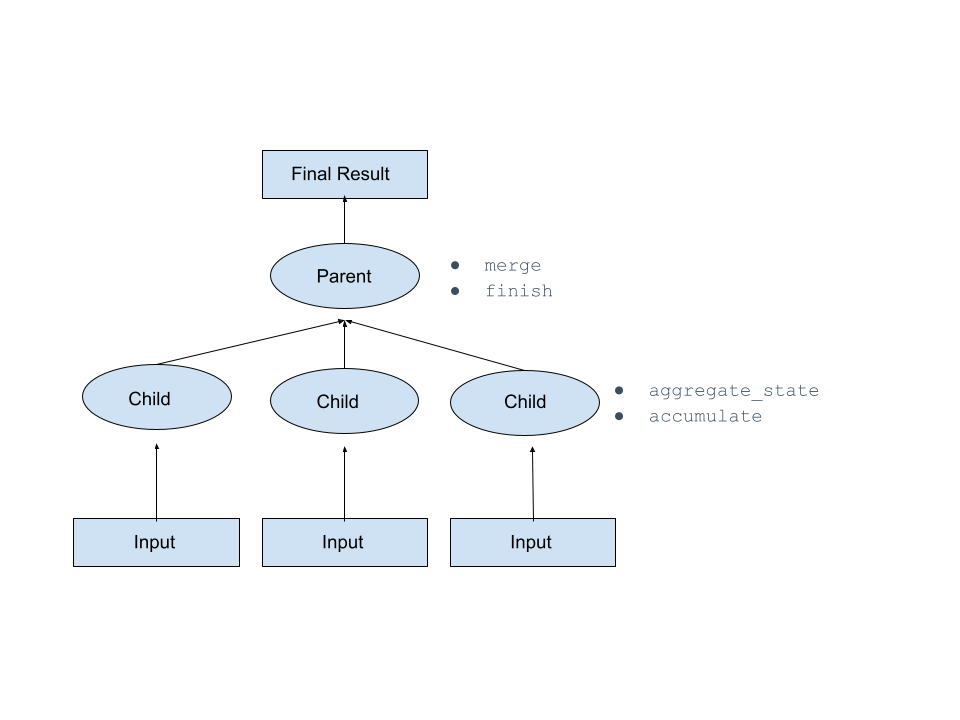
集計関数は子ノードの状態を集計し、最終的にそれらの集計された状態はシリアル化され、マージされて最終的な結果が計算される親ノードに送信されます。
集計関数を定義するには、実行時にSnowflakeが呼び出すメソッドを含むPythonクラス(関数のハンドラー)を定義する必要があります。これらのメソッドは、以下の表に説明されています。このトピックの他の例をご参照ください。
メソッド |
要件 |
説明 |
|---|---|---|
|
必須 |
集計の内部状態を初期化します。 |
|
必須 |
集計の現在の状態を返します。
|
|
必須 |
新しい入力行に基づいて集計状態を累積します。 |
|
必須 |
2つの中間集計状態を組み合わせます。 |
|
必須 |
集計状態に基づいて最終結果を生成します。 |
例: 合計の計算¶
次の例のコードでは、 python_sum ユーザー定義集計関数(UDAF)を定義し、数値の合計を返します。
UDAFを作成します。
テストデータのテーブルを作成します。
python_sumUDAF を呼び出します。Snowflakeシステム定義の SQL 関数、 SUM の出力と結果を比較し、結果が同じであることを確認します。
売上テーブルのアイテム型別の合計値でグループ化します。
例: 平均値の計算¶
次の例のコードは、数値の平均を返す python_avg ユーザー定義集計関数を定義します。
関数を作成します。
テストデータのテーブルを作成します。
python_avgユーザー定義関数を呼び出します。Snowflakeシステム定義の SQL 関数、 AVG の出力と結果を比較し、結果が同じであることを確認します。
売上テーブルのアイテム型別の平均値でグループ化します。
例: 一意な値のみを返します。¶
次の例のコードは配列を受け取り、一意な値のみを含む配列を返します。
例: 文字列の数を返します。¶
以下の例のコードは、オブジェクト内のすべての文字列インスタンスの数を返します。
例: 最大値の上位k件を返します。¶
以下の例のコードは、 k の最大値の上位リストを返します。このコードは、最小ヒープに反転させた入力値を蓄積し、上位 k 件の最大値を返します。