Remarques relatives à la réplication de base de données¶
Important
Cette section décrit une fonction de réplication de base de données limitée qui est différente de la fonction de réplication de compte. Snowflake recommande vivement d’utiliser la fonction de réplication de compte pour répliquer et basculer les bases de données.
Cette rubrique décrit le comportement de certaines fonctionnalités de Snowflake dans les bases de données secondaires lors de l’utilisation de la réplication de base de données. Pour plus d’informations sur l’utilisation des objets et des données répliqués, reportez-vous à Remarques relatives à la réplication.
Réplication de base de données et objets de sécurité¶
Cette section décrit le comportement de réplication de base de données des politiques de sécurité et des secrets.
- Politiques de masquage et d’accès aux lignes:
L’opération de réplication échoue si l’une des conditions suivantes est vraie :
La base de données principale se trouve dans un compte Enterprise (ou supérieur) et contient une politique/balise, mais au moins un des comptes approuvés pour la réplication se trouve sur des éditions inférieures.
Un objet contenu dans la base de données principale a une référence pendante à une balise dans une autre base de données.
Le comportement de la référence pendante pour la réplication des bases de données peut être évité lors de la réplication de plusieurs bases de données dans un groupe de réplication ou de basculement.
- Politiques de masquage basées sur les balises:
L’opération de réplication échoue si l’une des conditions suivantes est vraie :
La base de données principale se trouve dans un compte Enterprise (ou supérieur) et contient une politique/balise, mais au moins un des comptes approuvés pour la réplication se trouve sur des éditions inférieures.
Un objet contenu dans la base de données principale a une référence pendante à une balise dans une autre base de données.
Pour plus d’informations sur les politiques de masquage basées sur les balises, reportez-vous à Politiques de masquage basées sur les balises.
- Mot de passe, session, et politiques d’authentification:
L’opération de réplication échoue si l’une des conditions suivantes est vraie :
La base de données principale se trouve dans un compte Enterprise (ou supérieur) et contient une politique, mais au moins un des comptes approuvés pour la réplication se trouve sur des éditions inférieures.
L’un ou l’autre de ces objets contenus dans la base de données primaire est attaché à un utilisateur du même compte. Dans ce cas, Snowflake échoue l’opération de réplication.
Pour éviter l’échec de l’opération de réplication de la base de données en raison d’une référence à un utilisateur, utilisez plutôt un groupe de réplication ou de basculement.
Pour plus de détails, reportez-vous à Politiques de réplication et de sécurité.
- Secrets:
Vous ne pouvez pas répliquer un secret à l’aide de la réplication de base de données. Utilisez un groupe de réplication ou de basculement pour répliquer un secret. Pour plus de détails, voir Réplication et secrets.
Références pendantes¶
Références aux objets d’une autre base de données¶
Analysez soigneusement si les vues ou les contraintes de table dans une base de données principale font référence aux objets d’une autre base de données. Pour les objets de base de données, vous pouvez visualiser les dépendances d’objets dans la Vue OBJECT_DEPENDENCIES Account Usage.
Le tableau suivant décrit le comportement de réplication de base de données lorsqu’un objet (l’objet de référence) dans une base de données fait référence à un objet (l’objet référencé) dans une autre base de données :
Objet de référence |
Objet référencé |
Comportement de réplication |
|---|---|---|
Objet |
Réussite |
|
Objet |
Échec |
|
Vue matérialisée |
Échec |
|
Clé principale |
Échec |
|
Table |
Échec |
|
Politique de masquage, politique d’accès aux lignes ou balise |
La politique de l’objet/la balise est attribuée à |
Échec |
Objet |
Échec |
Vues non matérialisées¶
Les vues non matérialisées qui référencent n’importe quel objet d’une autre base de données (par exemple, colonnes de table, autres vues, UDFs ou zones de préparation) peuvent être répliquées, car ce type de référence est basé sur un nom. Les références basées sur des noms n’entraînent pas l’échec de la réplication. Cependant, les requêtes sur la vue dans les bases de données secondaires échoueront si les autres bases de données ne sont pas répliquées dans la même région.
Par exemple, supposons que la vue v1 dans la base de données d1 fasse référence aux tables t1 et t2 dans les bases de données d1 et d2, respectivement. Pour interroger la vue v1 dans la base de données secondaire d1, la base de données secondaire d2 doit également exister dans le compte (par exemple, en tant qu’autre base de données secondaire). En outre, pour des résultats de requête cohérents avec les bases de données principales, les bases de données d1 et d2 secondaires doivent être actualisées simultanément.
Vues matérialisées¶
Les références pendantes dans les vues matérialisées peuvent faire échouer la réplication avec le message d’erreur suivant :
Ces références pendantes peuvent se produire si :
Une vue matérialisée fait référence à n’importe quel objet dans une autre base de données.
Les vues matérialisées font référence aux objets par ID plutôt que par nom. Un instantané de base de données ne peut pas résoudre les références basées sur ID aux objets extérieurs à la base de données.
Pour contourner cette limitation, répliquez les deux bases de données ensemble dans le même groupe de réplication ou de basculement. Vous pouvez également stocker des vues matérialisées et les objets auxquels elles font référence dans la même base de données.
Une vue matérialisée est non valide (c’est-à-dire qu’elle fait référence à un objet supprimé).
Pour éviter une erreur de référence pendante pour les vues matérialisées non valides, identifiez et corrigez le problème de la vue matérialisée. Reportez-vous à la section Résolution des problèmes dans la rubrique relative aux vues matérialisées.
Contraintes¶
Actuellement, la suspension des clés étrangères entraîne l’échec de la réplication, avec le message d’erreur suivant :
Cette situation se produit lorsqu’une clé étrangère dans la base de données principale fait référence à une clé principale dans une autre base de données, ou vice-versa. En effet, les références aux contraintes sont basées sur ID. Un instantané de base de données ne peut pas résoudre les références basées sur ID aux objets extérieurs à sa propre base de données.
Pour afficher les références de clé étrangère dans votre compte, interrogez la Vue TABLE_CONSTRAINTS Information Schema ou la Vue TABLE_CONSTRAINTS Account Usage.
Pour contourner cette limitation, répliquez les deux bases de données ensemble dans le même groupe de réplication ou de basculement. Vous pouvez également stocker des tables liées dans la même base de données.
Séquences¶
Actuellement, la suspension de séquences entraîne l’échec de la réplication, avec le message d’erreur suivant :
Cette situation se produit lorsqu’une table dans une base de données principale fait référence à une séquence dans une autre base de données. C’est parce que les références de séquence sont basées sur un ID. Un instantané de base de données ne peut pas résoudre les références basées sur ID aux objets extérieurs à sa propre base de données.
Pour contourner cette limitation, répliquez les deux bases de données ensemble dans le même groupe de réplication ou de basculement. Vous pouvez également faire référence à des séquences dans la même base de données.
Références aux objets supprimés¶
Le fait de détruire un objet auquel un autre objet fait référence dans la même base de données ou dans une autre entraîne une référence pendante. Lorsqu’un objet de la base de données principale fait référence à un objet détruit, une opération de réplication échoue avec le message d’erreur suivant :
Pour contourner cette limitation, nous vous recommandons de suivre l” une des étapes suivantes :
Rétablissez les objets référencés.
Modifiez les objets de référence (par exemple, modifiez une vue matérialisée en utilisant ALTER MATERIALIZED VIEW). Soit vous faites référence à un objet différent, soit vous supprimez la référence à l’objet détruit.
Dans la base de données principale, détruisez tous les objets qui font référence aux objets détruits.
Réplication de plusieurs bases de données¶
Lorsque plusieurs bases de données sont répliquées, la cohérence ponctuelle entre les bases de données n’est pas disponible. Un instantané de chaque base de données principale est créé indépendamment et les modifications apportées à la base de données secondaire sont validées indépendamment. Cela peut être problématique si vous avez des vues qui joignent des tables dans différentes bases de données ou qui dépendent de transactions entre bases de données. Par exemple, une transaction qui met à jour deux bases de données principales de façon atomique peut ne pas être reflétée dans les bases de données secondaires au même moment.
Pour répliquer plusieurs bases de données avec une cohérence ponctuelle, utilisez un groupe de réplication ou de basculement.
Tables dynamiques et réplication des données¶
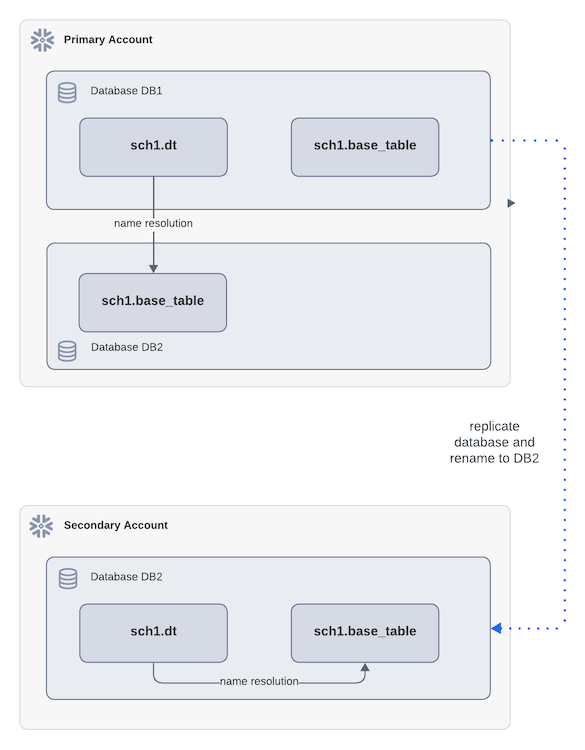
Si une table dynamique fait référence à des objets sources en dehors de la réplication de base de données, elle peut toujours être répliquée. Cependant, la résolution des noms peut devenir complexe si la base de données secondaire porte un nom différent de celui de la base principale. Après le basculement, cela peut entraîner des résultats d’actualisation inattendus en fonction de la manière dont l’objet source est référencé. Pour éviter ce problème, évitez de renommer la base de données pendant la définition de la réplication ou utilisez plutôt la réplication par groupe de basculement.
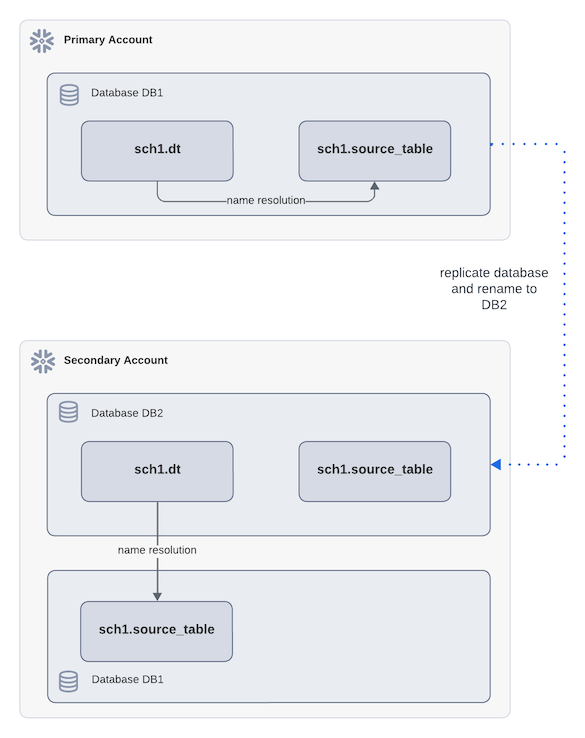
Dans le diagramme suivant, la table dynamique dt fait référence à un objet source source_table à l’aide d’un nom entièrement qualifié. Par exemple :
Pendant la réplication, DB1 est renommé en DB2 dans le compte secondaire. Après le basculement, l’actualisation de la table dynamique dt dans DB2 dans le compte secondaire résout la table source dans la même base de données, et non dans la base de données principale d’origine. Bien que ce comportement soit conforme aux règles de résolution des noms, il peut conduire à des résultats inattendus.
Dans le diagramme suivant, dt fait référence à source_table à l’aide d’un nom complet et la réplication renomme DB1 en DB2 dans le compte secondaire. dt dans le compte secondaire fait maintenant référence à une table source qui se trouve en dehors de la base de données conteneurisée.