Remarques relatives à la réplication¶
Cette rubrique décrit le comportement de certaines fonctionnalités Snowflake dans des bases de données secondaires et les objets lorsqu’ils sont répliqués avec les groupes de réplication ou de basculement ou la réplication de base de données, et fournit des conseils généraux pour utiliser des objets et des données répliqués.
Si vous avez précédemment activé la réplication de base de données pour des bases de données individuelles à l’aide de la commande ALTER DATABASE … ENABLE REPLICATION TO ACCOUNTS, voir Remarques relatives à la réplication de base de données pour des considérations supplémentaires spécifiques à la réplication de base de données.
Contraintes du groupe de réplication et du groupe de basculement¶
Les sections suivantes expliquent les contraintes liées à l’ajout d’objets de compte, de bases de données et de partages à des groupes de réplication et de basculement.
Objets de compte¶
Un compte ne peut avoir qu’un seul groupe de réplication ou de basculement qui contient des objets de compte autres que des bases de données ou des partages.
Privilèges de réplication¶
Cette section décrit les privilèges de réplication qui peuvent être accordés à des rôles pour spécifier les opérations que les utilisateurs peuvent effectuer sur des objets de groupes de réplication et de basculement dans le système. Pour la syntaxe de la commande GRANT, voir GRANT <privilèges> … TO ROLE.
Note
Pour la réplication de base de données, seul un utilisateur ayant le rôle ACCOUNTADMIN peut activer et gérer la réplication et le basculement de la base de données. Pour plus d’informations sur les privilèges requis pour la réplication de base de données, voir le tableau des privilèges requis dans Étape 6. Actualisation d’une base de données secondaire sur une planification.
Privilège |
Objet |
Utilisation |
Remarques |
|---|---|---|---|
OWNERSHIP |
Groupe de réplication Groupe de basculement |
Donne la possibilité de supprimer, de modifier, d’accorder ou de révoquer l’accès à un objet. |
Peut être accordé par :
|
CREATE REPLICATION GROUP |
Compte |
Donne la possibilité de créer un groupe de réplication. |
Doit être accordé par le rôle ACCOUNTADMIN. |
CREATE FAILOVER GROUP |
Compte |
Donne la possibilité de créer un groupe de basculement. |
Doit être accordé par le rôle ACCOUNTADMIN. |
FAILOVER |
Groupe de basculement |
Donne la possibilité de promouvoir un groupe de basculement secondaire pour servir de groupe de basculement principal. |
Peut être accordé ou révoqué par un rôle ayant le privilège OWNERSHIP sur le groupe. |
REPLICATE |
Groupe de réplication Groupe de basculement |
Donne la possibilité d’actualiser un groupe secondaire. |
Peut être accordé ou révoqué par un rôle ayant le privilège OWNERSHIP sur le groupe. |
MODIFY |
Groupe de réplication Groupe de basculement |
Permet de modifier les paramètres ou les propriétés d’un objet. |
Peut être accordé ou révoqué par un rôle ayant le privilège OWNERSHIP sur le groupe. |
MONITOR |
Groupe de réplication Groupe de basculement |
Donne la possibilité de voir les détails d’un objet. |
Peut être accordé ou révoqué par un rôle ayant le privilège OWNERSHIP sur le groupe. |
Pour obtenir des instructions sur la création d’un rôle personnalisé avec un ensemble spécifique de privilèges, voir Création de rôles personnalisés.
Pour des informations générales sur les rôles et les privilèges accordés pour effectuer des actions SQL sur des objets sécurisables, voir Aperçu du contrôle d’accès.
Réplication et références à travers les groupes de réplication¶
Les objets d’un groupe de réplication (ou de basculement) qui ont des références pendantes (c’est-à-dire des références à des objets d’un autre groupe de réplication ou de basculement) peuvent être répliqués avec succès vers un compte cible dans certaines circonstances. Si l’opération de réplication entraîne un comportement dans le compte cible cohérent avec le comportement qui peut se produire dans le compte source, la réplication réussit.
Par exemple, si une colonne d’une table du groupe de basculement fg_a fait référence à une séquence du groupe de basculement fg_b, la réplication des deux groupes réussit. Si fg_a est répliqué avant fg_b, les opérations d’insertion (après basculement) sur la table qui fait référence à la séquence échouent si fg_b n’a pas été répliqué. Ce comportement peut se produire dans un compte source. Si une séquence est détruite dans un compte source, les opérations d’insertion sur une table dont une colonne fait référence à la séquence détruite échouent.
Lorsque la référence pendante est une politique de sécurité qui protège des données, le groupe de réplication (ou de basculement) avec la politique de sécurité doit être répliqué avant que tout groupe de réplication contenant des objets qui font référence à la politique soit répliqué.
Attention
La mise à jour des politiques de sécurité qui protègent les données dans des groupes de réplication ou de basculement distincts peut entraîner des incohérences et doit être effectuée avec précaution.
Pour les objets de base de données, vous pouvez visualiser les dépendances d’objets dans la Vue OBJECT_DEPENDENCIES Account Usage.
Références pendantes et politiques réseau¶
Les références pendantes dans les politiques réseau peuvent faire échouer la réplication avec le message d’erreur suivant :
Afin d’éviter les références pendantes, spécifiez les types d’objets suivants dans la liste OBJECT_TYPES lors de l’exécution de la commande CREATE ou ALTER pour le groupe de réplication ou de basculement :
Si une politique réseau utilise une règle réseau, incluez la base de données qui contient le schéma où la règle réseau a été créée.
Si une politique de réseau est associée au compte, incluez
NETWORK POLICIESetACCOUNT PARAMETERSdans la listeOBJECT_TYPES.Si une politique réseau est associée à un utilisateur, incluez
NETWORK POLICIESetUSERSdans la listeOBJECT_TYPES.
Pour plus de détails, voir Réplication des politiques réseau.
Références pendantes et politiques de paquets¶
Si une politique de paquets est définie sur le compte, l’erreur de références pendantes suivante se produit lors de l’opération d’actualisation d’un groupe de réplication ou de basculement contenant des objets de compte :
Pour éviter les références pendantes, répliquez la base de données qui contient la politique de paquets dans le compte cible. La base de données contenant la politique peut se trouver dans le même groupe de réplication ou de basculement ou dans un groupe différent.
Références pendantes et secrets¶
Pour plus de détails, voir Réplication et secrets.
Références pendantes et flux¶
Les références pendantes pour les flux entraînent l’échec de la réplication avec le message d’erreur suivant :
Pour éviter les erreurs de référence pendante :
La base de données primaire doit inclure à la fois le flux et son objet de base ou
La base de données qui contient le flux et la base de données qui contient l’objet de base référencé par le flux doivent être incluses dans le même groupe de réplication ou de basculement.
Réplication et objets secondaires en lecture seule¶
Tous les objets secondaires d’un compte cible, y compris les bases de données et les partages, sont en lecture seule. Les modifications apportées à des objets ou à des types d’objets répliqués ne peuvent pas être effectuées localement dans un compte cible. Par exemple, si le type d’objet USERS est répliqué d’un compte source vers un compte cible, de nouveaux utilisateurs ne peuvent pas être créés ou modifiés dans le compte cible.
De nouvelles bases de données locales et des partages peuvent être créés et modifiés dans un compte cible. Si des ROLES sont également répliqués dans le compte cible, de nouveaux rôles ne peuvent pas être créés ou modifiés dans ce compte cible. C’est pourquoi des privilèges ne peuvent pas être accordés à un rôle (ni révoqués d’un rôle) sur un objet secondaire dans le compte cible. Toutefois, des privilèges peuvent être accordés à un rôle secondaire (ou révoqués) sur des objets locaux (par exemple, des bases de données, des partages ou des groupes de réplication ou de basculement) créés dans le compte cible.
Réplication et objets dans les comptes cibles¶
Si vous avez créé des objets de compte, par exemple des utilisateurs et des rôles, dans votre compte cible par un moyen autre que via la réplication (par exemple, en utilisant des scripts), ces utilisateurs et rôles n’ont pas d’identificateur global par défaut. Lorsqu’un compte cible est actualisé à partir du compte source, l’opération d’actualisation détruit tous les objets de compte des types de la liste OBJECT_TYPES du compte cible qui n’ont pas d’identificateur global.
Note
L’opération d’actualisation initiale pour répliquer USERS ou ROLES peut entraîner une erreur. Cela permet d’éviter la suppression accidentelle des données et des métadonnées associées aux utilisateurs et aux rôles. Pour plus d’informations sur les circonstances qui déterminent si ces types d’objet sont supprimés ou si l’opération d’actualisation échoue, voir Réplication initiale des utilisateurs et des rôles.
Pour éviter la destruction de ces objets, voir Appliquer des IDs globaux à des objets créés par des scripts dans des comptes cibles.
Objets recréés dans les comptes cibles¶
Si un objet existant dans le compte source est remplacé à l’aide d’une instruction CREATE OR REPLACE, l’objet existant est supprimé, puis un nouvel objet portant le même nom est créé en une seule transaction. Par exemple, si vous exécutez une instruction CREATE OR REPLACE pour une table existante t1, la table t1 est supprimée et une nouvelle table t1 est créée. Pour plus d’informations, voir les notes sur l’utilisation de CREATE TABLE.
Lorsque des objets sont remplacés sur le compte cible, les instructions DROP et CREATE ne s’exécutent pas de manière atomique lors d’une opération d’actualisation. Cela signifie que l’objet peut disparaître brièvement du compte cible pendant qu’il est recréé sous forme de nouvel objet.
Politiques de réplication et de sécurité¶
La base de données contenant une politique de sécurité et les références (c’est-à-dire les affectations) peut être répliquée à l’aide de groupes de réplication et de basculement. Les politiques de sécurité incluent les éléments suivants :
Si vous utilisez la réplication de base de données, voir Réplication de base de données et objets de sécurité.
Politiques d’authentification, de mot de passe et de session¶
Les références aux politiques d’authentification, de mot de passe et de session des utilisateurs sont répliquées lorsque l’on spécifie la base de données contenant la politique (ALLOWED_DATABASES = policy_db) et USERS dans un groupe de réplication ou un groupe de basculement.
Si la base de données de politique ou les utilisateurs ont déjà été répliqués sur un compte cible, mettez à jour le groupe de réplication ou de basculement du compte source afin d’inclure les bases de données et les types d’objets nécessaires à la réplication réussie de la politique. Exécutez ensuite une opération d’actualisation pour mettre à jour le compte cible.
Si les politiques de niveau utilisateur ne sont pas utilisées, USERS n’a pas besoin d’être inclus dans le groupe de réplication ou de basculement.
Note
La politique doit être dans le même compte que l’affectation de politique au niveau du compte et l’affectation de politique au niveau de l’utilisateur.
Si vous avez défini une politique de sécurité sur le compte ou un utilisateur du compte et que vous ne mettez pas à jour le groupe de réplication ou de basculement pour inclure les policy_db contenant la politique et USERS, une référence pendante se produit dans le compte cible. Dans ce cas, une référence pendante signifie que Snowflake ne peut pas localiser la politique dans le compte cible, parce que le nom entièrement qualifié de la politique pointe vers la base de données dans le compte source. Par conséquent, le compte cible ou les utilisateurs du compte cible ne sont pas tenus de respecter la politique de sécurité.
Pour répliquer avec succès une politique de sécurité, vérifiez que le groupe de réplication ou de basculement comprend les types d’objets et les bases de données nécessaires pour éviter une référence pendante.
Politiques de confidentialité¶
Tenez compte des éléments suivants lors de la réplication des politiques de confidentialité et des tables et vues protégées associées à la Confidentialité différentielle :
Si une politique de confidentialité est attribuée à une table ou à une vue dans le compte source, la politique doit être répliquée dans le compte cible.
La perte cumulée de confidentialité pour un budget de confidentialité n’est pas répliquée.
Les pertes cumulées de confidentialité dans les comptes cible et source sont suivies séparément.
Les administrateurs du compte cible ne peuvent pas ajuster le budget de confidentialité répliqué. Le budget de confidentialité est synchronisé avec celui du compte source.
Si un analyste a accès à la table ou à la vue protégée à la fois dans le compte source et dans le compte cible, il peut encourir deux fois le montant de perte de confidentialité avant d’atteindre la limite du budget de confidentialité.
Les domaines de confidentialité définis dans les colonnes sont également répliqués.
Politiques de session avec rôles secondaires¶
Si vous utilisez des politiques de session avec des rôles secondaires, vous devez spécifier la base de données de politiques dans le même groupe de réplication qui contient les rôles. Par exemple :
Si vous spécifiez la base de données de politique de session qui référence les rôles secondaires dans un autre groupe de réplication ou de basculement (rg2) que le groupe de réplication ou de basculement qui contient des objets au niveau du compte (myrg) et que vous répliquez ou basculez rg2 en premier, une référence pendante s’affiche. Un message d’erreur indique de placer la base de données de politique de session dans le groupe de réplication ou de basculement qui contient les rôles. Ce comportement se produit lorsque la politique de session est définie sur le compte ou les utilisateurs.
Si la politique de session ou les objets au niveau du compte se trouvent dans des groupes de réplication différents et que la politique de session n’est pas définie sur le compte ou les utilisateurs, vous pouvez répliquer et actualiser le compte cible. Assurez-vous d’actualiser d’abord le groupe de réplication qui contient les objets au niveau du compte.
Si vous actualisez le compte cible après avoir répliqué ou basculé la politique de session avec des rôles secondaires et des objets de rôle, le compte cible reflète la politique de session et le comportement des rôles secondaires dans le compte source.
De plus, lorsque vous actualisez la base de données dans le compte cible et que la base de données contient une politique de session qui fait référence à des rôles secondaires, ALLOWED_SECONDARY_ROLES correspond toujours à [ALL].
Réplication et secrets¶
Vous pouvez uniquement répliquer le secret à l’aide d’un groupe de réplication ou de basculement. Spécifiez la base de données qui contient le secret, la base de données qui contient UDFs ou les procédures qui font référence au secret, et les intégrations qui font référence au secret dans un seul groupe de réplication ou de basculement.
Si la base de données qui contient le secret se trouve dans un groupe de réplication ou de basculement et que l’intégration qui fait référence au secret se trouve dans un autre groupe de réplication ou de basculement, alors :
Si vous répliquez d’abord l’intégration, puis le secret, l’opération est réussie : tous les objets sont répliqués et il n’y a pas de références pendantes.
Si vous répliquez le secret avant l’intégration et que le secret n’existe pas encore dans le compte cible, un « secret de remplacement » est ajouté dans le compte cible afin d’éviter une référence pendante. Snowflake mappe le secret de remplacement à l’intégration.
Après avoir répliqué le groupe qui contient l’intégration, lors de la prochaine opération d’actualisation du groupe qui contient le secret, Snowflake met à jour le compte cible pour remplacer le secret de remplacement par le secret référencé dans l’intégration.
Si vous répliquez le secret et ne répliquez pas l’intégration de
account1àaccount2, l’intégration ne fonctionne pas dans le compte cible (account2) parce qu’il n’y a pas d’intégration pour utiliser le secret. En outre, si vous effectuez le basculement et que le compte cible est promu en compte source, l’intégration ne fonctionnera pas.Lorsque vous décidez d’effectuer le basculement pour faire de
account1le compte source, les références de secret et d’intégration correspondent et le secret de remplacement n’est pas utilisé. Cela vous permet d’utiliser l’intégration de sécurité et le secret qui contient les identifiants, car les objets peuvent se référencer l’un l’autre.
Réplication et clonage¶
Historiquement, les objets clonés étaient répliqués physiquement plutôt que logiquement dans les bases de données secondaires. En d’autres termes, les tables clonées dans une base de données standard ne contribuent pas au stockage global des données tant que les opérations DML sur le clone n’ajoutent pas ou ne modifient pas les données existantes. Cependant, lorsqu’une table clonée est répliquée dans une base de données secondaire, les données physiques le sont également, ce qui augmente l’utilisation du stockage de données pour votre compte.
Une table clonée répliquée logiquement partage les micropartitions de la table originale à partir de laquelle elle a été clonée, ce qui réduit le stockage physique de la table secondaire dans le compte cible.
Si la table d’origine et la table clonée sont incluses dans le même groupe de basculement ou de réplication, la table clonée peut être répliquée logiquement sur le compte cible.
Réplication logique des clones¶
Si la table originale et la table clonée sont incluses dans le même groupe de basculement ou de réplication, la table clonée peut être répliquée logiquement sur le compte cible.
Par exemple, si la table t2 de la base de données db2 est un clone de la table t1 de la base de données db1, et que les deux bases de données sont incluses dans le groupe de réplication rg1, la table t2 est créée en tant que clone logique dans le compte cible.
Un objet cloné peut être cloné pour créer d’autres clones de l’objet d’origine. L’objet original et les objets clonés font partie du même groupe de clones. Par exemple, si la table t3 de la base de données db3 est créée en tant que clone de t2, elle fait partie du même groupe de clonage que la table d’origine t1 et la table clonée t2.
Si la base de données db3 est ajoutée ultérieurement au groupe de réplication rg1, la table t3 est créée dans le compte cible en tant que clone logique de la table t1.
Considérations¶
Les tables qui se trouvent dans le même groupe de clonage dans le compte source peuvent ne pas se trouver dans le même groupe de clonage dans le compte cible.
La table d’origine et sa table clonée doivent se trouver dans le même groupe de basculement ou de réplication.
Dans certains cas, toutes les micropartitions du groupe de clonage ne peuvent pas être partagées avec la table clonée. Cela peut entraîner une utilisation supplémentaire du stockage pour la table clonée dans le compte cible.
Exemple¶
La table t2 de la base de données db2 est un clone de la table t1 de la base de données db1. Incluez les deux bases de données dans le groupe de réplication myrg pour répliquer logiquement t2 sur le compte cible :
Réplication et clustering automatique¶
Dans une base de données principale, Snowflake surveille les tables en cluster à l’aide de Clustering automatique et effectue un reclustering au besoin. Dans le cadre d’une opération d’actualisation, les tables en cluster sont répliquées dans une base de données secondaire avec le tri en cours des micro-partitions de table. En tant que tel, le reclustering n’est pas exécuté à nouveau sur les tables en cluster de la base de données secondaire, ce qui serait redondant.
Si une base de données secondaire contient des tables en cluster et si la base de données devient la base de données principale, Snowflake démarre le clustering automatique des tables de cette base de données tout en suspendant simultanément la surveillance des tables en cluster de la base de données principale précédente.
Voir Réplication et vues matérialisées (dans cette rubrique) pour obtenir des informations sur le clustering automatique des vues matérialisées.
Réplication et tables de grande taille et à roulement élevé¶
Lorsqu’une ou plusieurs lignes d’une table sont mises à jour ou supprimées, toutes les micro-partitions touchées qui stockent ces données dans une base de données principale sont recréées et doivent être synchronisées avec les bases de données secondaires. Pour les tables de grande taille et à roulement élevé, les coûts de réplication peuvent être importants.
Pour les tables de grande taille et à roulement élevé qui entraînent des coûts de réplication importants, les mesures d’atténuation suivantes sont disponibles :
Répliquez moins fréquemment les bases de données principales qui stockent ces tables.
Modifiez votre modèle de données pour réduire le roulement.
Pour plus d’informations, voir Gestion des coûts pour les tables de grande taille et à roulement élevé.
Réplication et Time Travel¶
Les données Time Travel et Fail-safe sont maintenues indépendamment pour une base de données secondaire et ne sont pas répliquées à partir d’une base de données principale. L’interrogation de tables et de vues dans une base de données secondaire à l’aide de Time Travel peut produire des résultats différents de ceux obtenus lors de l’exécution de la même requête dans la base de données principale.
- Données historiques:
Les données historiques disponibles pour une requête dans une base de données principale à l’aide de Time Travel ne sont pas répliquées vers des bases de données secondaires.
Par exemple, supposons que les données soient chargées en permanence dans une table toutes les 10 minutes à l’aide de Snowpipe, et qu’une base de données secondaire soit actualisée toutes les heures. L’opération d’actualisation ne réplique que la dernière version de la table. Bien que chaque version horaire de la table dans la fenêtre de conservation soit disponible pour une requête utilisant Time Travel, aucune des versions itératives de chaque heure (les charges Snowpipe individuelles) n’est disponible.
- Période de conservation des données:
La période de conservation des données pour les tables d’une base de données secondaire commence lorsque la base de données secondaire est actualisée avec les opérations DML (c.-à-d. modification ou suppression de données) écrites dans les tables de la base de données principale.
Note
Le paramètre de période de conservation des données, DATA_RETENTION_TIME_IN_DAYS, n’est répliqué que sur les objets de la base de données secondaire, et non sur la base de données elle-même. Pour plus de détails sur la réplication des paramètres, voir Paramètres.
Réplication et vues matérialisées¶
Dans une base de données principale, Snowflake effectue une maintenance automatique en arrière-plan des vues matérialisées. Lorsqu’une table de base est modifiée, toutes les vues matérialisées définies sur la table sont mises à jour par un service d’arrière-plan utilisant les ressources de calcul fournies par Snowflake. En outre, si le clustering automatique est activé pour une vue matérialisée, alors celle-ci est surveillée et fait l’objet d’un reclustering selon les besoins dans une base de données principale.
Une opération d’actualisation réplique les définitions de la vue matérialisée dans une base de données secondaire ; les données de la vue matérialisée ne sont pas répliquées. La maintenance en arrière-plan automatique des vues matérialisées dans une base de données secondaire est activée par défaut. Si le clustering automatique est activé pour une vue matérialisée dans une base de données principale, la surveillance et le reclustering automatiques de la vue matérialisée dans la base de données secondaire sont également activés.
Note
Les frais de synchronisation automatisée en arrière-plan des vues matérialisées sont facturés à chaque compte qui contient une base de données secondaire.
Réplication et tables Apache Iceberg™¶
Tenez compte des points suivants lorsque vous utilisez la réplication pour les tables Iceberg :
Snowflake currently supports replication of Snowflake-managed tables only.
La réplication des tables Iceberg converties n’est pas prise en charge. Snowflake ignore les tables converties pendant les opérations d’actualisation.
Pour les tables répliquées, vous devez configurer l’accès à un emplacement de stockage dans la même région que le compte cible.
Si vous supprimez ou modifiez un emplacement de stockage utilisé pour la réplication sur le volume externe principal, les opérations d’actualisation peuvent échouer.
Les tables secondaires dans le compte cible sont en lecture seule jusqu’à ce que vous définissiez le compte cible en tant que compte source.
Snowflake conserve la Hiérarchie des répertoires de la table Iceberg principale pour la table secondaire.
Les coûts de réplication s’appliquent à cette fonctionnalité. Pour plus d’informations, voir Compréhension du coût de réplication.
Pour les considérations relatives aux objets de compte pour les groupes de réplication et de basculement, voir Objets de compte.
Replicating dynamic Iceberg tables isn’t supported. Snowflake skips converted tables during refresh operations.
Réplication et tables dynamiques¶
Le comportement de la réplication des tables dynamiques varie selon que la base de données principale contenant la table dynamique fait partie d’un groupe de réplication ou d’un groupe de basculement.
Tables dynamiques et groupes de réplication¶
Une base de données contenant une table dynamique peut être répliquée à l’aide d’un groupe de réplication. Le ou les objets sources dont elle dépend n’ont pas l’exigence d’être dans le même groupe de réplication.
Les objets répliqués dans chaque compte cible sont appelés objets secondaires et sont des réplications des objets primaires du compte source. Les objets secondaires sont en lecture seule dans le compte cible. Si un groupe de réplication secondaire est abandonné dans un compte cible, les bases de données qui étaient incluses dans le groupe deviennent en lecture/écriture. Cependant, toutes les tables dynamiques incluses dans un groupe de réplication restent en lecture seule même après la suppression du groupe secondaire dans le compte cible. Aucune actualisation DML ou de table dynamique ne peut avoir lieu sur ces tables dynamiques en lecture seule.
Tables dynamiques et groupes de basculement¶
Une base de données contenant une table dynamique peut être répliquée à l’aide d’un groupe de basculement. Si une table dynamique fait référence à des objets sources situés en dehors du groupe de basculement ou de la réplication de base de données, elle peut toujours être répliquée. Après un basculement, la table dynamique résout les objets sources à l’aide de la résolution de noms lors de l’actualisation. L’actualisation peut réussir ou échouer, en fonction de l’état des objets sources. En cas de succès, la table dynamique est réinitialisée avec les données les plus récentes des objets sources.
Les tableaux dynamiques secondaires sont en lecture seule et ne sont pas actualisés. Après un basculement et la promotion d’une table dynamique secondaire en table dynamique principale, la première actualisation est une réinitialisation suivie d’actualisations incrémentielles si la table dynamique est configurée pour une actualisation incrémentielle des données.
Note
La table dynamique réinitialisée peut différer de la réplique d’origine, car il n’est pas garanti que les objets sources et la table dynamique partagent le même instantané de réplication.
Exemple : Échec de l’actualisation en raison d’objets sources manquants
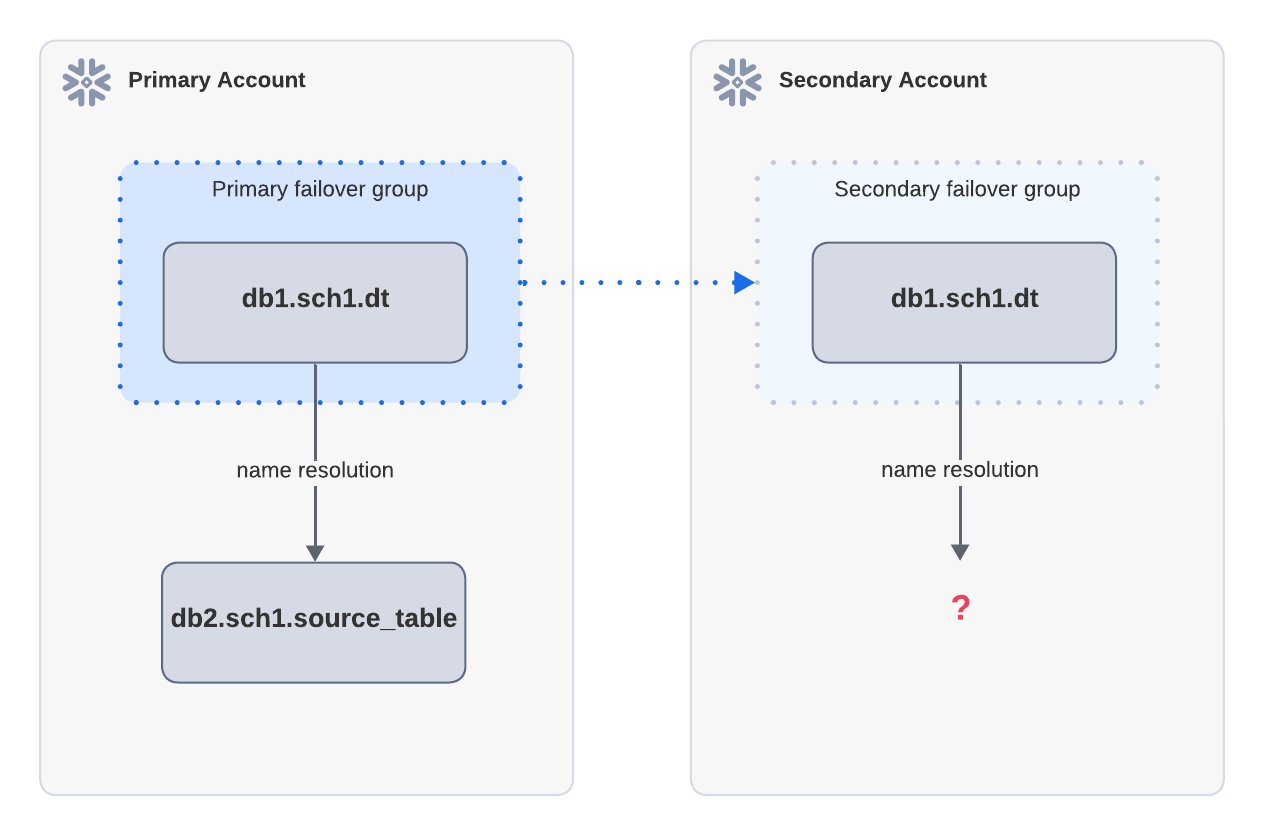
Si une table dynamique dépend d’une table source située en dehors du groupe de basculement, elle ne peut pas être actualisée après un basculement. Dans le diagramme ci-dessus, la table dynamique dt du compte principal est répliquée sur le compte secondaire. dt dépend de source_table, qui ne fait pas partie du même groupe de basculement que le compte principal. Après le basculement, l’actualisation du compte secondaire échoue car source_table ne peut pas être résolu.
Exemple : Rafraîchissement réussi lorsque les objets sources existent dans le compte secondaire via une réplication séparée
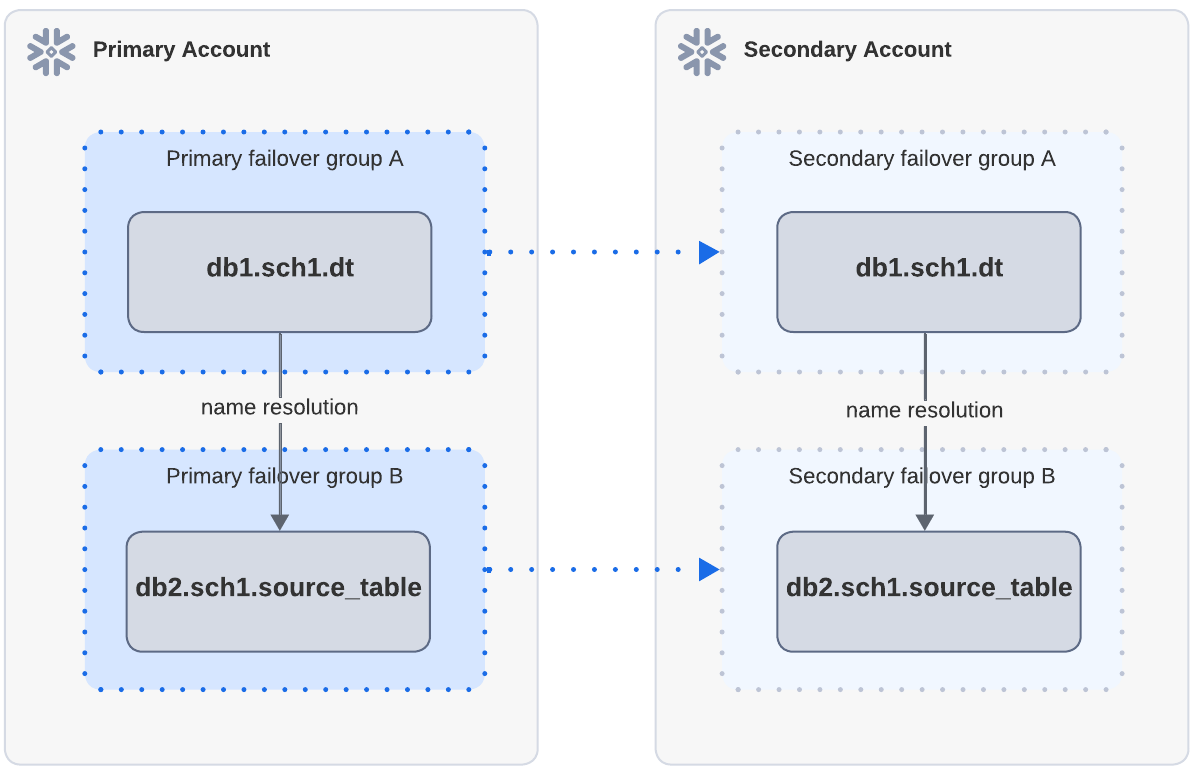
Dans le diagramme ci-dessus, la table dynamique dt dépend de source_table. dt et source_table dans le compte principal sont répliquées sur le compte secondaire par l’intermédiaire de groupes de basculement indépendants. Après la réplication et le basculement, lorsque dt est actualisé dans le compte secondaire, l’actualisation réussit car source_table peut être trouvé par la résolution de noms.
Exemple : Actualisation réussie lorsque les objets sources existent localement dans le compte secondaire
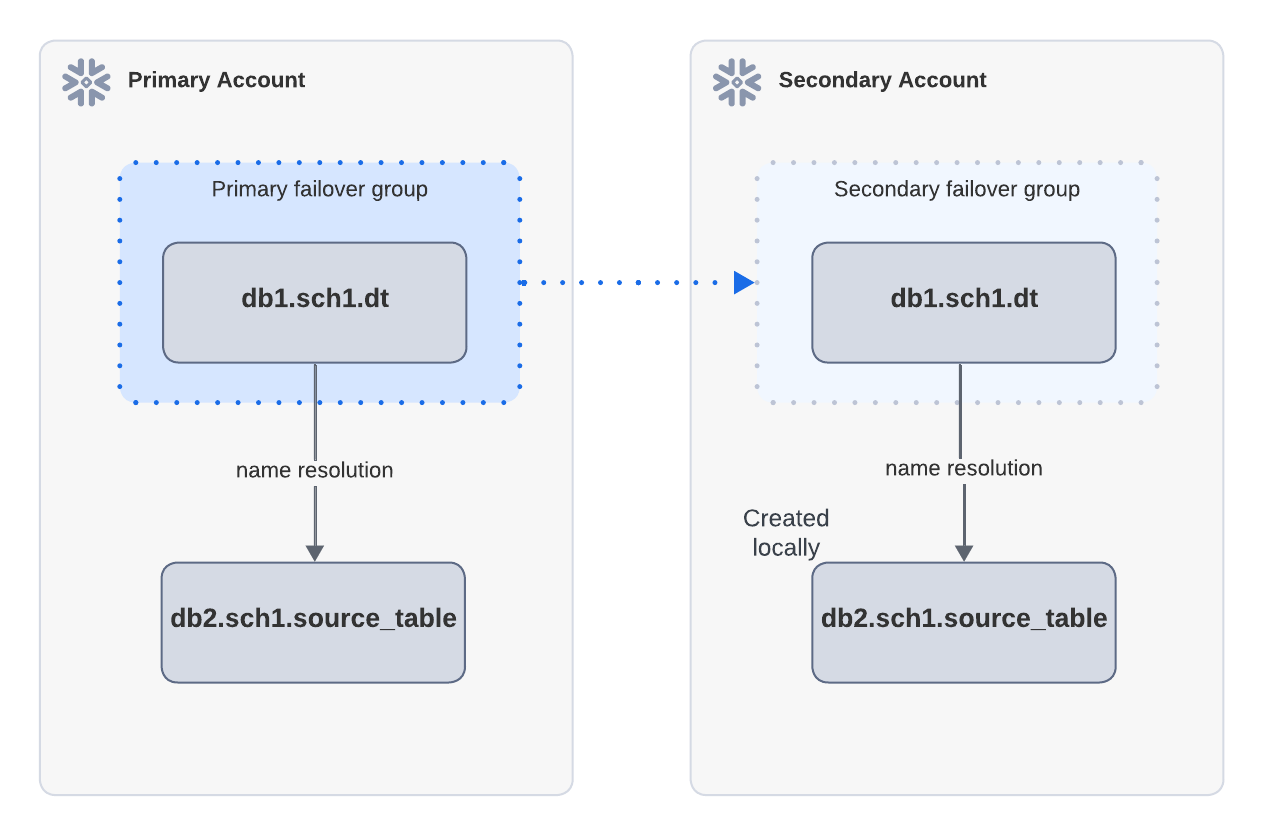
Dans le schéma ci-dessus, la table dynamique dt dépend de source_table et est répliquée par un groupe de basculement du compte principal vers le compte secondaire. Un site source_table est créé localement dans le compte secondaire. Après le basculement, lorsque dt1 est actualisé dans le compte secondaire, l’actualisation peut réussir parce que source_table peut être trouvé par la résolution de noms.
Réplication et Streaming Snowpipe¶
Une table alimentée par Snowpipe Streaming dans une base de données primaire est répliquée dans la base de données secondaire d’un compte cible.
Dans la base de données primaire, les tables sont créées et les lignes sont insérées par l’intermédiaire de canaux. Des jetons de décalage permettent de suivre la progression de l’ingestion. Une opération d’actualisation réplique l’objet de table, les données de table et les décalages de canaux associés à la table de la base de données primaire vers la base de données secondaire.
Architectures Snowpipe Streaming¶
Snowflake prend en charge deux architectures sous-jacentes pour Snowpipe Streaming, qui déterminent les APIs client disponibles et les caractéristiques de performance.
Snowpipe Streaming avec architecture classique¶
Opérations en lecture seule (disponibles dans les comptes source et cible) :
Le canal :code:`getLatestCommittedOffsetToken`API
Commande
SHOW CHANNELS
Opérations d’écriture (uniquement disponibles dans le compte source) :
Le client openChannel API
Le canal insertRow API
Le canal insertRows API
Snowpipe Streaming avec architecture hautes performances¶
Cette architecture offre des fonctionnalités optimisées, notamment des opérations en masse et des contrôles de statut améliorés, essentielles pour la gestion des environnements répliqués à grands volumes.
Toutes les fonctions décrites ci-dessous sont accessibles via les SDKs Snowpipe Streaming et l’API REST Snowpipe Streaming, ce qui permet une intégration flexible en fonction des besoins de votre infrastructure.
Opérations d’écriture et de gestion (disponibles uniquement dans le compte source) :
Gestion du cycle de vie du canal : Ouvrez et gérez les canaux d’ingestion nécessaires à l’établissement d’un flux de données. Par exemple, la méthode openChannel dans le SDK Java.
Ingestion cohérente sur le plan transactionnel : La fonction principale pour l’ajout de lignes. Les données insérées ici sont garanties d’être incluses dans l’instantané de réplication une fois validées. Par exemple, la méthode appendRows dans le SDK Java.
Suivi des jetons de décalage : Récupérez les derniers jetons de décalage engagé pour garantir l’intégrité des données et éviter les duplications lors de l’ingestion. Par exemple, la méthode getLatestCommittedOffsetToken dans le SDK Java.
Surveillance de l’état en masse : Surveillez efficacement les métriques de santé et de décalage sur plusieurs canaux. Ceci est essentiel pour vérifier que la latence des données est acceptable avant que la réplication n’ait lieu. Par exemple, la méthode getChannelStatus dans le SDK Java.
Opérations en lecture seule (disponibles dans les comptes source et cible) :
Inspection du canal : Utilisez des commandes de métadonnées, par exemple
SHOW CHANNELS, pour afficher les détails de la configuration, l’état et les propriétés des canaux d’ingestion existants dans l’environnement répliqué.
Prévention de la perte de données¶
Pour éviter toute perte de données en cas de basculement, la durée de conservation des données pour les lignes insérées avec succès dans votre source de données en amont doit être supérieure à la planification de réplication. Si des données sont insérées dans une table d’une base de données primaire et que le basculement se produit avant que les données puissent être répliquées dans la base de données secondaire, les mêmes données devront être insérées dans la table de la base de données primaire qui vient d’être promue. L’exemple suivant illustre un scénario de basculement :
La table
t1dans la base de données primairerepl_dbest alimentée en données par Snowpipe Streaming et le connecteur Kafka.Le
offsetTokenest 100 pour le canal 1 et 100 pour le canal 2 pourt1dans la base de données primaire.Une opération d’actualisation se termine avec succès dans le compte cible.
Le
offsetTokenest 100 pour le canal 1 et 100 pour le canal 2 pour let1dans la base de données secondaire.D’autres lignes sont insérées dans
t1dans la base de données primaire.Le
offsetTokenest maintenant 200 pour le canal 1 et 200 pour le canal 2 pour let1dans la base de données primaire.Un basculement se produit avant que les lignes supplémentaires et les nouveaux décalages de canaux puissent être répliqués dans la base de données secondaire.
Dans ce cas, il manque 100 décalages dans chaque canal pour la table t1 dans la base de données primaire venant d’être promue. Pour insérer les données manquantes, voir Rouvrir des canaux actifs pour Snowpipe Streaming dans le nouveau compte source promu.
Exigences en matière de prise en charge de la réplication¶
Snowpipe Streaming avec architecture classique¶
La prise en charge de la réplication Snowpipe Streaming pour l’architecture classique nécessite les versions minimales suivantes :
SDK Snowflake Ingest version 1.1.1 ou ultérieure
Si vous utilisez le connecteur Kafka : version du connecteur Kafka 1.9.3 ou ultérieure.
Snowpipe Streaming avec architecture hautes performances¶
La prise en charge de la réplication Snowpipe Streaming pour l’architecture hautes performances nécessite les versions minimales suivantes :
SDK Snowpipe Streaming version 1.1.0 ou ultérieure.
Exigence de conservation des données pour les deux architectures¶
La durée de conservation des données pour les lignes insérées avec succès dans votre source de données en amont doit être supérieure à la fréquence de réplication. Si vous utilisez le connecteur Kafka, assurez-vous que votre configuration log.retention est définie avec un tampon suffisant.
Réplication et zones de préparation¶
Les contraintes suivantes s’appliquent aux objets de zone de préparation :
Snowflake prend actuellement en charge la réplication de zone de préparation dans le cadre de la réplication par groupe (groupes de réplication et de basculement). La réplication de zones de préparation n’est pas prise en charge pour la réplication des bases de données.
Vous pouvez reproduire une zone de préparation externe. Cependant, les fichiers d’une zone de préparation externe ne sont pas répliqués.
Vous pouvez répliquer une zone de préparation interne. Pour répliquer les fichiers d’une zone de préparation interne, vous devez activer une table de répertoire sur la zone de préparation. Snowflake ne réplique que les fichiers qui sont mappés par la table de répertoire.
Lorsque vous répliquez une zone de préparation interne avec une table de répertoire, vous ne pouvez pas désactiver la table de répertoire sur la zone de préparation primaire ou secondaire. La table des répertoires contient des informations essentielles sur les fichiers répliqués et les fichiers chargés à l’aide d’une instruction COPY.
Une opération d’actualisation échoue si la table des répertoires d’une zone de préparation interne contient un fichier dont la taille est supérieure à 5GB. Pour contourner cette limitation, déplacez tous les fichiers d’une taille supérieure à 5GB vers une autre zone de préparation.
Vous ne pouvez pas désactiver la table de répertoire sur une zone de préparation principale ou secondaire, ou sur une zone de préparation qui a déjà été répliquée. Suivez ces étapes avant d’ajouter la base de données qui contient la zone de préparation à un groupe de réplication ou de basculement.
Désactivez la table de répertoire sur la zone de préparation principale.
Déplacez les fichiers dont la taille est supérieure à 5GB vers une autre zone de préparation où la table des répertoires n’est pas activée.
Après avoir déplacé les fichiers vers une autre zone de préparation, réactivez la table des répertoires sur la zone de préparation principale.
Les fichiers sur les zones de préparation d’utilisateur et de table ne sont pas répliqués.
Pour les zones de préparation externes nommées qui utilisent une intégration de stockage, vous devez configurer la relation de confiance pour les intégrations de stockage secondaires dans vos comptes cibles avant le basculement. Pour plus d’informations, consultez Configurer l’accès au stockage Cloud pour les intégrations de stockage secondaire.
Si vous répliquez une zone de préparation externe avec une table de répertoire et que vous avez configuré l’actualisation automatique pour la table de répertoire source, vous devez configurer l’actualisation automatique pour la table de répertoire secondaire avant le basculement. Pour plus d’informations, consultez Configuration de l’actualisation automatique des tables de répertoire dans les zones de préparation secondaires.
Une commande de copie peut prendre plus de temps que prévu si la table des répertoires d’une zone de préparation répliquée n’est pas cohérente avec les fichiers répliqués de cette zone de préparation. Pour rendre une table de répertoire cohérente, rafraîchissez-la à l’aide d’une instruction ALTER STAGE… REFRESH. Pour vérifier le statut de cohérence d’une table de répertoire, utilisez la fonction SYSTEM$GET_DIRECTORY_TABLE_STATUS.
Réplication et canaux¶
Les contraintes suivantes s’appliquent aux objets de canaux :
Snowflake prend actuellement en charge la réplication de canaux dans le cadre de la réplication par groupe (groupes de réplication et de basculement). La réplication de canal n’est pas prise en charge pour la réplication de bases de données.
Snowflake réplique l’historique des copies d’un canal uniquement lorsque le canal appartient au même groupe de réplication que sa table cible.
La réplication des intégrations de notification n’est pas prise en charge.
Snowflake ne réplique l’historique des chargements qu’après la dernière troncature de table.
Pour recevoir des notifications, vous devez configurer un canal d’intégration automatique secondaire dans un compte cible avant le basculement. Pour plus d’informations, consultez Configurer les notifications pour les canaux secondaires d’intégration automatique.
Utilisez la fonction SYSTEM$PIPE_STATUS pour résoudre tous les canaux qui ne sont pas dans leur état d’exécution prévu après le basculement.
Snowflake ne prend pas en charge la réplication et le basculement pour Snowpipe avec le connecteur Kafka, mais Snowflake supporte la réplication et le basculement pour Snowpipe Streaming avec le connecteur Kafka. Pour plus d’informations, voir Snowpipe Streaming et le connecteur Kafka.
Réplication des fonctions de métrique des données (DMFs)¶
Les comportements suivants s’appliquent à la réplication DMF :
- Tables d’événements
La table d’événements qui stocke les résultats de l’appel manuel ou de la planification de l’exécution de DMF n’est pas répliquée parce que la table d’événements est locale à votre compte Snowflake et que Snowflake ne prend pas en charge la réplication des tables d’événements.
- Groupes de réplication
Lorsque vous ajoutez la ou les bases de données qui contiennent vos DMFs à un groupe de réplication, le phénomène suivant se produit dans le compte cible :
Les DMFs sont répliquées à partir du compte source.
Les tables ou les vues que la définition de DMF spécifie, par exemple avec une référence de clé étrangère sont répliquées à partir du compte source, sauf si la table ou la vue est associée à l” exécution automatique inter-Cloud.
Les DMFs planifiés dans le compte cible sont suspendus. Les DMFs secondaires reprennent leur planification lorsque vous promouvez le compte cible en compte source et que les DMFs secondaires deviennent des DMFs principaux.
- Groupes de basculement
Lorsque vous répliquez la ou les bases de données qui contiennent vos DMFs à l’aide d’un groupe de basculement, ce qui suit se produit en cas de basculement :
Reprise de la planification des DMFs suspendues lorsque vous promouvez le compte cible en compte source.
Suspension des DMFs planifiées dans le compte cible après avoir promu un autre compte en tant que compte source.
Si vous ne répliquez pas la base de données qui contient la DMF vers un compte cible, les associations DMF à une table ou à une vue sont supprimées lorsque le compte cible est promu en compte source parce qu’elles ne sont pas disponibles dans le compte source nouvellement promu.
Astuce
Avant le transfert de votre compte, vérifiez les références de la DMF en appelant la fonction de table Information Schema DATA_METRIC_FUNCTION_REFERENCES pour déterminer les objets de table qui sont associés à une DMF avant les opérations de promotion et d’actualisation.
Réplication de procédures stockées et de fonctions définies par l’utilisateur (UDFs)¶
Les procédures stockées et les UDFs sont répliquées d’une base de données primaire vers des bases de données secondaires.
Procédures stockées, UDFs et zones de préparation¶
Si une procédure stockée ou une UDF dépend de fichiers dans une zone de préparation (par exemple, si la procédure stockée est définie dans un code Python qui est chargé à partir d’une zone de préparation), vous devez répliquer la zone de préparation et ses fichiers vers la base de données secondaire. Pour plus d’informations sur la réplication des zones de préparation, voir Réplication des zones de préparation, des canaux et de l’historique des chargements.
Par exemple, si une base de données principale possède une UDF Python en ligne qui importe tout code stocké dans une zone de préparation, l’UDF ne fonctionne pas tant que la zone de préparation et le code importé ne sont pas répliqués dans la base de données secondaire.
Procédures stockées, UDFs et accès réseau externe¶
Si une procédure stockée ou une UDF dépend de l’accès à un emplacement réseau externe, vous devez répliquer les objets suivants :
Les EXTERNALACCESSINTEGRATIONS doivent être incluses dans la liste
allowed_integration_typespour le groupe de réplication ou de basculement.La base de données qui contient la règle réseau.
La base de données qui contient le secret qui stocke les identifiants de connexion permettant l’authentification auprès de l’emplacement réseau externe.
Si l’objet secret fait référence à une intégration de sécurité, vous devez inclure SECURITY INTEGRATIONS dans la liste
allowed_integration_typespour le groupe de réplication ou de basculement.
Politiques de cycle de vie de la réplication et du stockage¶
Snowflake réplique les politiques de cycle de vie du stockage et leurs associations avec les tables vers les comptes cibles, mais n’exécute pas les politiques. Snowflake ne réplique pas les données archivées dans les niveaux COOL ou COLD. Les données archivées dans votre compte source ne sont pas disponibles dans le compte cible.
Après le basculement vers un compte cible, Snowflake suspend l’exécution des politiques de cycle de vie du stockage dans le compte source d’origine. Après une restauration vers le compte source, Snowflake reprend l’exécution des politiques.
Snowflake n’exécute jamais automatiquement les politiques de cycle de vie du stockage secondaires sur les tables secondaires, même après le basculement. Cependant, vous pouvez utiliser des politiques secondaires dans un compte cible en les attachant à de nouvelles tables. Pour ces nouvelles tables, Snowflake exécute les politiques.
Réplication et flux¶
Cette section décrit les pratiques recommandées et les domaines de préoccupation potentiels lors de la réplication de flux dans Réplication de bases de données sur plusieurs comptes ou Réplication de compte et basculement/restauration.
Objets sources pris en charge pour les flux¶
Les flux répliqués peuvent suivre avec succès les données de modification pour les tables et les vues dans la même base de données.
Actuellement, les types d’objets sources suivants ne sont pas pris en charge :
Tables externes
Tables ou vues dans des bases de données distinctes des bases de données de flux, sauf si la base de données de flux et la base de données qui stocke l’objet source sont incluses dans le même groupe de réplication ou de basculement.
Tables ou vues dans des bases de données partagées (c’est-à-dire des bases de données partagées entre des comptes de fournisseurs et votre compte).
La réplication de flux sur les tables de répertoire est prise en charge lorsque vous activez Réplication des zones de préparation, des canaux et de l’historique des chargements.
Une opération de réplication ou d’actualisation de la base de données échoue si la base de données principale inclut un flux avec un objet source non pris en charge. L’opération échoue également si l’objet source d’un flux a été détruit.
Les flux d’ajout uniquement ne sont pas pris en charge sur les objets sources répliqués.
Éviter la duplication des données¶
Note
Outre le scénario décrit dans cette section, les flux d’une base de données secondaire pourraient renvoyer des lignes en double la première fois qu’ils sont inclus dans une opération d’actualisation. Dans ce cas, lignes dupliquées fait référence à une seule ligne avec plusieurs valeurs de colonnes METADATA$ACTION.
Après l’opération initiale d’actualisation, vous ne devriez pas rencontrer ce problème spécifique dans une base de données secondaire.
La duplication des données se produit lorsque les opérations DML écrivent plusieurs fois les mêmes données de modification d’un flux sans contrôle d’unicité. Cela peut se produire si un flux et une table de destination pour les données de modification de flux sont stockés dans des bases de données distinctes, et que ces bases de données ne sont pas répliquées et basculées dans le même groupe.
Par exemple, supposons que vous insérez régulièrement des données de modification provenant du flux s dans la table dt. (Pour cet exemple, l’objet source du flux n’a pas d’importance). Des bases de données distinctes stockent le flux et la table de destination.
À l’horodatage
t1, une ligne est insérée dans la table source pour le fluxs, créant ainsi une nouvelle version de la table. Le flux stocke le décalage pour cette version de la table.À l’horodatage
t2, la base de données secondaire qui stocke le flux est actualisée. Le flux répliquésstocke maintenant le décalage.À l’horodatage
t3, les données de modification du fluxssont insérées dans la tabledt.À l’horodatage
t4, la base de données secondaire qui stocke le fluxsest basculée.À l’horodatage
t5, les données de modification du fluxssont à nouveau insérées dans la tabledt.
Pour éviter cette situation, répliquez et basculez ensemble les bases de données qui stockent les flux et leurs tables de destination.
Références de flux dans la tâche WHEN Clause¶
Pour éviter tout comportement inattendu lors de l’exécution de tâches répliquées qui font référence à des flux dans la clause WHEN boolean_expr nous vous recommandons soit de :
créer les tâches et les flux dans la même base de données, ou
Si les flux sont stockés dans une base de données différente de celle des tâches qui les référencent, incluez les deux bases de données dans le même groupe de basculement.
Si une tâche fait référence à un flux dans une base de données distincte, et que les deux bases de données ne sont pas incluses dans le même groupe de basculement, la base de données qui contient la tâche peut être basculée sans la base de données qui contient le flux. Dans ce scénario, lorsque la tâche est reprise dans la base de données basculée, elle enregistre une erreur lorsqu’elle tente de s’exécuter et ne trouve pas le flux référencé. Ce problème peut être résolu soit en basculant la base de données qui contient le flux, soit en recréant la base de données et le flux dans le même compte que la base de données basculée qui contient la tâche.
Obsolescence des flux¶
Si un flux dans la base de données principale est devenu obsolète, le flux répliqué dans une base de données secondaire est également obsolète et ne peut pas être interrogé ou ses données de modification consommées. Pour résoudre ce problème, recréez le flux dans la base de données principale (en utilisant CREATE OR REPLACE STREAM). Lorsque la base de données secondaire est actualisée, le flux répliqué est à nouveau lisible.
Notez que le décalage pour un flux recréé est la version actuelle de la table par défaut. Vous pouvez recréer un flux qui pointe vers une version antérieure de la table en utilisant Time Travel ; cependant, le flux répliqué resterait illisible. Pour plus d’informations, voir Réplication de flux et Time Travel (dans cette rubrique).
Réplication de flux et Time Travel¶
Après le basculement d’une base de données principale, si un flux de la base de données utilise Time Travel pour lire une version de la table pour l’objet source à partir d’un moment antérieur au dernier horodatage d’actualisation, le flux répliqué ne peut pas être interrogé ou les données de modification consommées. De même, l’interrogation des données de modification d’un objet source à partir d’un moment antérieur au dernier horodatage d’actualisation à l’aide de la clause CHANGES pour les instructions SELECT échoue avec une erreur.
En effet, une opération d’actualisation réduit l’historique de la table à une seule version de la table. Les versions de tables itératives créées avant l’horodatage de l’opération d’actualisation ne sont pas conservées dans l’historique des tables pour les objets sources répliqués.
Prenons l’exemple suivant :
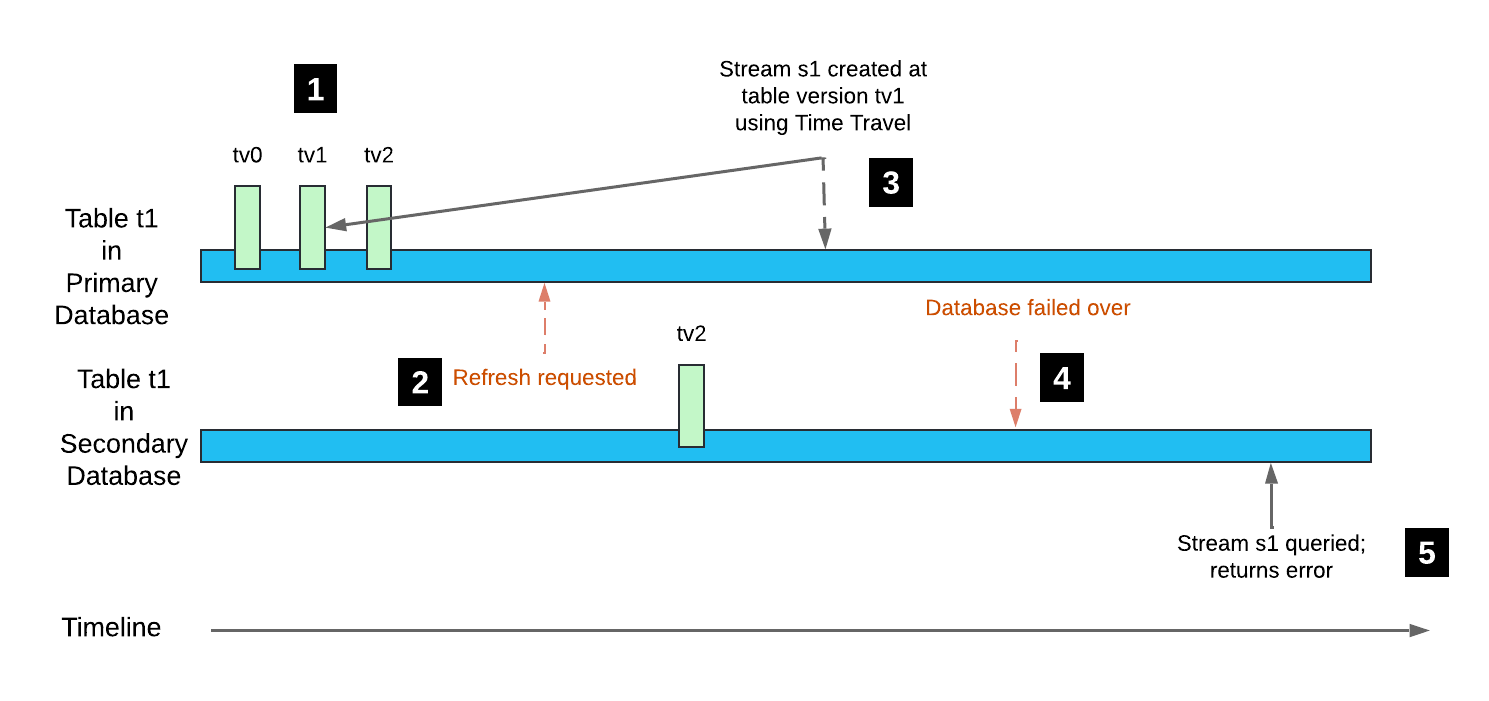
La table
t1est créée dans la base de données principale avec le suivi des modifications activé (version de la tabletv0). Les transactions DML suivantes créent des versions de tabletv1ettv2.Une base de données secondaire qui contient la table
t1est actualisée. La version de la table pour cette table répliquée esttv2; cependant, l’historique de la table n’est pas répliqué.Un flux est créé dans la base de données principale avec son décalage défini sur la version de table
tv1en utilisant Time Travel.La base de données secondaire est basculée et devient la base de données principale.
L’interrogation du flux
s1renvoie une erreur, car la version de la tabletv1ne figure pas dans l’historique de la table.
Notez que lorsqu’une transaction DML ultérieure sur la table t1 itère la version de la table vers tv3, le décalage pour le flux s1 est avancé. Le flux est à nouveau lisible.
Éviter la perte de données¶
Une perte de données peut se produire lorsque l’opération d’actualisation la plus récente d’une base de données secondaire n’est pas terminée avant l’opération de basculement. Nous vous recommandons d’actualiser fréquemment vos bases de données secondaires pour réduire le risque.
Réplication et tâches¶
Cette section décrit la réplication des tâches dans Réplication de bases de données sur plusieurs comptes ou la réplication des comptes et le basculement/la récupération.
Note
La réplication de base de données ne fonctionne pas pour les graphiques de tâches si le graphique appartient à un rôle différent de celui qui effectue la réplication.
Scénarios de réplication¶
Le tableau suivant décrit différents scénarios de tâches et précise si les tâches sont répliquées ou non. Sauf indication contraire, les scénarios concernent à la fois les tâches autonomes et les tâches dans un graphique des tâches :
Scénario |
Répliqué |
Remarques |
|---|---|---|
La tâche a été créée et reprise ou exécutée manuellement (en utilisant EXECUTE TASK). La reprise ou l’exécution d’une tâche crée une version initiale de la tâche. |
✔ |
|
La tâche a été créée mais n’a jamais été reprise ou exécutée. |
❌ |
|
La tâche a été recréée (en utilisant CREATE OR REPLACE TASK), mais n’a jamais été reprise ou exécutée. |
✔ |
La dernière version avant que la tâche a été recréée est répliquée. La reprise ou l’exécution manuelle de la tâche valide une nouvelle version. Lorsque la base de données est à nouveau répliquée, la nouvelle, ou dernière version est répliquée dans la base de données secondaire. |
La tâche a été créée et reprise ou exécutée, mais elle a été abandonnée par la suite. |
❌ |
|
Le graphique des tâches a été créé et repris ou exécuté. Par la suite, une tâche du graphe des tâches a été modifiée, mais la tâche racine du graphe des tâches n’a pas été reprise ou exécutée à nouveau. Voici quelques exemples de modifications :
|
✔ |
La dernière version du graphique de la tâche avant la tâche a été modifiée est répliquée. La reprise ou l’exécution manuelle d’une tâche entraîne la validation d’une nouvelle version qui inclut toutes les modifications apportées aux paramètres des tâches dans le graphique des tâches. Comme les nouvelles modifications n’ont jamais été validées, seule la version précédente du graphique de la tâche est répliquée. Notez que si le graphique de la tâche modifiée n’est pas repris au cours d’une période de conservation (actuellement 30 jours), la dernière version de la tâche est abandonnée. Après cette période, la tâche n’est pas répliquée dans une base de données secondaire, à moins qu’elle ne soit reprise à nouveau. |
La tâche racine d’un graphique de tâches a été créée et reprise ou exécutée, mais a ensuite été suspendue et détruite. |
❌ |
La totalité du graphique de tâches n’est pas répliquée dans une base de données secondaire. |
Une tâche enfant dans un graphique de tâches est créée et reprise ou exécutée, mais est ensuite suspendue et détruite. |
✔ |
La dernière version du graphique de tâches (avant que la tâche ne soit suspendue et détruite) est répliquée dans une base de données secondaire. |
État repris ou suspendu des tâches répliquées¶
Si toutes les conditions suivantes sont réunies, une tâche est répliquée vers une base de données secondaire dans un état repris :
Une tâche autonome ou racine est dans un état repris dans la base de données principale lorsque l’opération de réplication ou d’actualisation commence jusqu’à ce que l’opération soit terminée. Si une tâche est dans un état repris pendant une partie seulement de cette période, elle peut encore être répliquée dans un état repris.
Une tâche enfant est dans un état repris dans la dernière version de la tâche.
La base de données parent a été répliquée sur le compte cible avec des objets de rôle dans le même groupe de réplication ou de basculement , ou dans un groupe différent.
Une fois les rôles et la base de données répliqués, vous devez actualiser les objets du compte cible en exécutant soit ALTER REPLICATION GROUP … REFRESH ou ALTER FAILOVER GROUP … REFRESH, respectivement. Si vous actualisez la base de données en exécutant ALTER DATABASE … REFRESH, l’état des tâches dans la base de données devient suspendu.
Une opération de réplication ou d’actualisation inclut les attributions de privilèges pour une tâche qui étaient en cours lorsque la dernière version de la table a été validée. Pour plus d’informations, voir Tâches répliquées et attributions de privilèges (dans cette rubrique).
Si ces conditions ne sont pas remplies, la tâche est répliquée dans une base de données secondaire dans un état suspendu.
Note
Les tâches secondaires ne sont planifiées qu’après un basculement, indépendamment de leur state. Pour plus de détails, consultez le document Exécution des tâches après un basculement.
Tâches répliquées et attributions de privilèges¶
Si la base de données parent est répliquée sur un compte cible avec des objets de rôle dans le même groupe de réplication ou de basculement, ou dans un groupe différent, les privilèges accordés aux tâches de la base de données sont également répliqués.
La logique suivante détermine quels privilèges de tâche sont répliqués lors d’une opération de réplication ou d’actualisation :
Si le propriétaire actuel de la tâche (c’est-à-dire le rôle qui dispose du privilège OWNERSHIP sur une tâche) est le même rôle que lors de la dernière reprise de la tâche, tous les privilèges actuels de la tâche sont répliqués dans la base de données secondaire.
Si le propriétaire actuel de la tâche n’est pas le même rôle que lors de la dernière reprise de la tâche, alors seul le privilège OWNERSHIP accordé au rôle de propriétaire dans la version de la tâche est répliqué dans la base de données secondaire.
Si le rôle actuel de propriétaire de tâche n’est pas disponible (par exemple, une tâche enfant est détruite, mais une nouvelle version du graphique de tâches n’est pas encore validée), seul le privilège OWNERSHIP accordé au rôle de propriétaire dans la version de tâche est répliqué dans la base de données secondaire.
Exécution des tâches après un basculement¶
Après qu’un groupe de basculement secondaire a été promu pour servir de groupe principal, toutes les tâches reprises dans les bases de données du groupe de basculement sont programmées progressivement. Le temps nécessaire pour rétablir la programmation normale de l’ensemble des tâches autonomes et graphiques de tâches repris dépend du nombre de tâches reprises dans une base de données.
Réplication et projets dbt¶
Les objets de projet dbt sont répliqués d’une base de données principale vers des bases de données secondaires.
Tous les objets secondaires d’un compte cible, y compris les bases de données secondaires, sont en lecture seule. Un projet dbt secondaire ne peut pas être exécuté.
Tous les objets référencés par un projet dbt, tels que les tables sources et les vues, doivent être répliqués avec le projet dbt afin que les exécutions de ce projet dbt puissent aboutir après un basculement.
Projets dbt et accès au réseau externe¶
Si un projet dbt dépend de l’accès à un emplacement réseau externe, vous devez répliquer les objets suivants :
Les EXTERNALACCESSINTEGRATIONS doivent être incluses dans la liste
allowed_integration_typespour le groupe de réplication ou de basculement.La base de données qui contient la règle réseau.
La base de données qui contient le secret qui stocke les identifiants de connexion permettant l’authentification auprès de l’emplacement réseau externe.
Si l’objet secret fait référence à une intégration de sécurité, vous devez inclure SECURITY INTEGRATIONS dans la liste
allowed_integration_typespour le groupe de réplication ou de basculement.
Un projet dbt ne stocke pas les intégrations d’accès réseau externes auxquelles il est associé. Les intégrations d’accès au réseau externe sont spécifiées lorsque l’utilisateur exécute la commande EXECUTE DBT PROJECT. Cela met davantage en évidence la nécessité de répliquer séparément les intégrations d’accès externes.
Réplication et instances des classes Snowflake¶
Une instance de la classe CUSTOM_CLASSIFIER est répliquée lorsque la base de données qui contient l’instance est répliquée. La réplication d’instances d’autres classes Snowflake n’est pas prise en charge.
Données d’utilisation historiques¶
Les données d’utilisation historiques pour l’activité dans une base de données principale ne sont pas répliquées dans des bases de données secondaires. Chaque compte a son propre historique de requêtes, d’historique de connexion, etc.
Les données d’utilisation historiques incluent les données de requêtes renvoyées par les Schéma d’information de Snowflake fonctions de table ou Account Usage les vues suivantes :
COPY_HISTORY
LOGIN_HISTORY
QUERY_HISTORY
etc.