Snowflake ML:エンドツーエンドの機械学習¶
Snowflake MLは、お客様の管理データの上に、単一のプラットフォームでエンドツーエンドの機械学習を行うための統合機能セットです。これは、 ML の開発および生産化のための統合環境であり、 CPU および GPU のコンピュート上で、手動でのチューニングや構成なしに、大規模な分散機能エンジニアリング、モデルトレーニング、推論を行うために最適化されています。
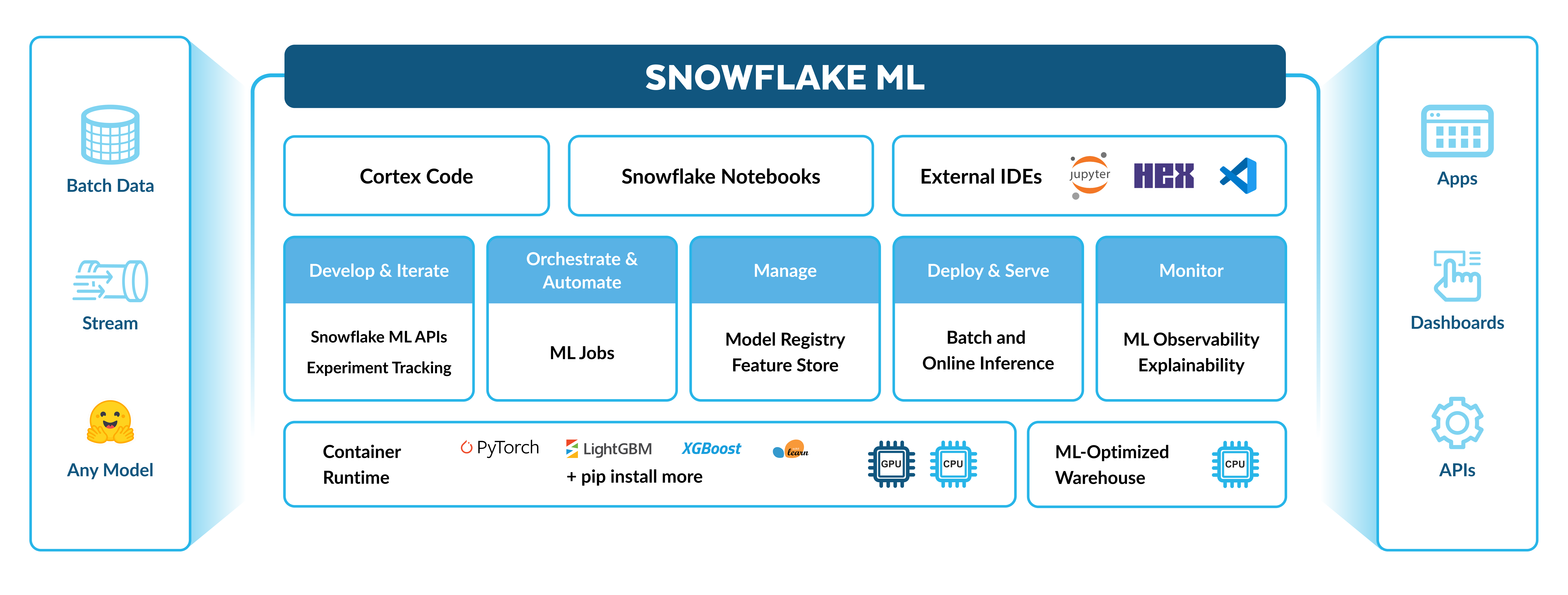
Snowflakeのエンドツーエンド ML ワークフローのスケーリングはシームレスです。以下のことができます。
データの準備
Snowflake Feature Storeを使用した機能の作成と使用
Container RuntimeでSnowflake Notebooksのオープンソースパッケージを使用して CPUs または GPUs を持つモデルをトレーニングする
設定メトリックに対してトレーニング済みモデルを評価する実験を作成する
Snowflake ML ジョブを使用してパイプラインを操作可能にする
Snowflake Model Registryを使用して、スケールの大きな推論のためにモデルをデプロイします。
ML 可観測性と説明可能性を使用した実稼働モデルを監視する
ML 系統を使用して、 ML パイプライン全体の機能、データセット、モデルのソースデータを追跡する
Snowflake ML はまた、柔軟でモジュール化されています。Snowflakeで開発したモデルをSnowflakeの外部にデプロイし、外部でトレーニングしたモデルをSnowflakeに簡単に導入して推論を行うことができます。
データサイエンティストと ML エンジニアのための機能¶
Container RuntimeのSnowflake Notebooks¶
Container RuntimeのSnowflake Notebooks は、インフラ管理なしに、Snowflakeで大規模モデルのトレーニングや微調整を行うためのJupyterライクな環境を提供します。PyTorch、 XGBoost、Scikit-learnなどのプリインストールパッケージを使用してトレーニングを開始するか、 HuggingFace や PyPI などのオープンソースリポジトリから任意のパッケージをインストールしてください。Container Runtimeは、Snowflakeのインフラストラクチャ上で動作するように最適化されており、非常に効率的なデータのロード、分散モデルのトレーニング、ハイパーパラメーターのチューニングを提供します。
Snowflake特徴ストア¶
Snowflake特徴ストア は、データから ML 機能を定義、管理、保存、発見するための統合ソリューションです。Snowflake Feature Storeは、バッチおよびストリーミングデータソースからの自動的な増分リフレッシュをサポートしているため、機能パイプラインを1回定義するだけで、新しいデータで継続的にリフレッシュすることができます。
MLジョブ¶
Snowflake MLのジョブ を使用して、 ML パイプラインを開発し、自動化します。ML ジョブを使用すると、外部 IDE (VS コード、 PyCharm、 SageMaker Notebooks)からの作業を好むチームが、関数、ファイル、またはモジュールをSnowflakeのコンテナランタイムにディスパッチすることもできます。
実験¶
実験 を使用して、モデルのトレーニング結果を記録し、モデルのコレクションを体系的に評価します。実験は、ユースケースに最適なモデルを選択し、本番環境に導入するのに役立ちます。トレーニングは、Snowflake上でのモデルトレーニング中に実験で記録することも、以前のトレーニングから独自のメタデータとアーティファクトをアップロードすることもできます。トレーニングを終了した後、 Snowsight ですべての結果を表示し、ニーズに合わせて適切なモデルを選択します。
Snowflake Model RegistryとModel Serving¶
Snowflakeモデルレジストリ では、Snowflakeや他のプラットフォームでトレーニングされたモデルに関係なく、すべての ML モデルのログと管理を行うことができます。モデルレジストリのモデルを使用して、スケール推論を実行することができます。Modeling Servingを使用すると、推論のためにモデルをSnowpark Container Serviceにデプロイすることができます。
ML 可観測性¶
ML Observability は、Snowflakeのモデルパフォーマンスメトリックをモニターするツールを提供します。実稼働中のモデルを追跡し、パフォーマンスとドリフトのメトリックをモニターし、パフォーマンスしきい値のアラートをセットできます。さらに、 ML Explainability関数を使用して、Snowflake Model Registryのモデルについて、どこでトレーニングされたかに関係なく、Shapley値を計算します。
ML 系統¶
ML Lineage は、ソースデータから機能、データセット、モデルまで、 ML アーティファクトのエンドツーエンドの系譜をトレースする機能です。これにより、 ML アセットのライフサイクル全体にわたって、再現性、コンプライアンス、およびデバッグが可能になります。
Snowflake Datasets¶
Snowflake Datasets は、機械学習モデルによる取り込みに適した、バージョン管理された不変のデータスナップショットを提供します。
ビジネスアナリストのための機能¶
ビジネスアナリストは、 ML 関数 を使用して、 SQL を使用した組織全体の予測や異常検知などの一般的なシナリオの開発時間を短縮できます。
追加のリソース¶
Snowflake ML を使い始めるには、以下のリソースをご覧ください。
Snowflakeの担当者にお問い合わせいただくと、現在開発中の他の特徴量に関するドキュメントをいち早く入手できます。