Snowflake ML 모델 개발¶
참고
Snowflake ML Modeling API는 snowflake-ml-python 패키지 버전 1.1.1부터 일반 공급으로 제공됩니다.
Snowflake ML Modeling API는 Snowflake 내에서 데이터 전처리, 특성 공학, 모델 학습을 위해 scikit-learn, LightGBM 및 XGBoost와 같은 익숙한 Python 프레임워크를 사용합니다.
Snowflake ML Modeling을 사용한 모델 개발의 이점은 다음과 같습니다.
특성 공학 및 전처리: 자주 사용되는 scikit-learn 전처리 함수에 대한 분산 실행으로 성능과 확장성을 향상합니다.
모델 학습: 분산 하이퍼 매개 변수 최적화를 활용하여 저장 프로시저나 사용자 정의 함수(UDF)를 수동으로 생성할 필요 없이 scikit-learn, XGBoost 및 LightGBM 모델에 대한 학습을 가속화합니다.
팁
모델링 API를 포함한 엔드투엔드 ML 워크플로 예시는 머신 러닝 소개 섹션을 참조하십시오.
참고
이 항목에서는 snowflake-ml-python 과 해당 모델링 종속성이 이미 설치되어 있다고 가정합니다. 로컬에서 Snowflake ML 사용하기 섹션을 참조하십시오.
모델 개발하기¶
Notebooks on Container Runtime 에서 제공되는 Container Runtime for ML 을 사용하면, 하나 이상의 GPU 노드를 활용하여 Snowflake 데이터와 함께 인기 있는 오픈 소스 ML 패키지를 Snowflake 클라우드 내에서 사용할 수 있어 전체 ML 워크플로에 대한 보안과 거버넌스를 보장합니다. 포함된 데이터 로딩 및 훈련 APIs는 노드에서 사용 가능한 모든 CPUs 또는 GPUs에 자동으로 배포되므로 대규모 데이터 세트로 모델 훈련을 가속화할 수 있습니다.
자세한 내용은 Container Runtime for ML의 기능을 활용하는 간단한 ML 워크플로를 소개하는 Snowflake Notebook Container Runtime 시작하기 를 참조하십시오.
Container Runtime for ML의 유연성과 강력한 성능과 함께, Snowflake ML Modeling API는 scikit-learn, xgboost 및 lightgbm 라이브러리와 유사한 APIs가 있는 추정기와 변환기를 제공합니다. 이러한 APIs를 사용하여 Snowpark Model Registry와 같은 Snowflakek ML Operations와 함께 사용할 수 있는 머신 러닝 모델을 개발하고 훈련시킬 수 있습니다.
예¶
다음 예제를 검토하여 Snowflake Modeling API와 이미 능숙하게 활용하실 수도 있는 머신 러닝 라이브러리의 유사점을 파악해 보십시오.
전처리¶
이 예제에서는 Snowflake Modeling 데이터 전처리 및 변환 함수를 사용하는 방법을 보여줍니다. 예제에서 사용하는 두 전처리 함수(MixMaxScaler 및 OrdinalEncoder)는 Snowflake의 분산 처리 엔진을 사용하여 클라이언트 측 또는 저장 프로시저 구현에 비해 상당한 성능 향상 효과를 제공합니다. 자세한 내용은 분산 전처리 섹션을 참조하십시오.
import numpy as np
import pandas as pd
import random
import string
from sklearn.datasets import make_regression
from snowflake.ml.modeling.preprocessing import MinMaxScaler, OrdinalEncoder
from snowflake.ml.modeling.pipeline import Pipeline
from snowflake.snowpark import Session
# Create a session with your preferred method
# session =
NUMERICAL_COLS = ["X1", "X2", "X3"]
CATEGORICAL_COLS = ["C1", "C2", "C3"]
FEATURE_COLS = NUMERICAL_COLS + CATEGORICAL_COLS
CATEGORICAL_OUTPUT_COLS = ["C1_OUT", "C2_OUT", "C3_OUT"]
FEATURE_OUTPUT_COLS = ["X1_FEAT_OUT", "X2_FEAT_OUT", "X3_FEAT_OUT", "C1_FEAT_OUT", "C2_FEAT_OUT", "C3_FEAT_OUT"]
# Create a dataset with numerical and categorical features
X, _ = make_regression(
n_samples=1000,
n_features=3,
noise=0.1,
random_state=0,
)
X = pd.DataFrame(X, columns=NUMERICAL_COLS)
def generate_random_string(length):
return "".join(random.choices(string.ascii_uppercase, k=length))
categorical_feature_length = 2
categorical_features = {}
for c in CATEGORICAL_COLS:
categorical_column = [generate_random_string(categorical_feature_length) for _ in range(X.shape[0])]
categorical_features[c] = categorical_column
X = X.assign(**categorical_features)
features_df = session.create_dataframe(X)
# Fit a pipeline with OrdinalEncoder and MinMaxScaler on Snowflake
pipeline = Pipeline(
steps=[
(
"OE",
OrdinalEncoder(
input_cols=CATEGORICAL_COLS,
output_cols=CATEGORICAL_OUTPUT_COLS,
)
),
(
"MMS",
MinMaxScaler(
input_cols=NUMERICAL_COLS + CATEGORICAL_OUTPUT_COLS,
output_cols=FEATURE_OUTPUT_COLS,
)
),
]
)
pipeline.fit(features_df)
# Use the pipeline to transform a dataset.
result = pipeline.transform(features_df)
데이터 로딩¶
![]() 미리 보기 기능 — 공개
미리 보기 기능 — 공개
모든 계정에서 사용 가능합니다.
이 예제는 로딩 속도를 높이기 위해 여러 코어 또는 GPUs에 걸쳐 데이터 수집을 분산하는 DataConnector API를 사용하여 Snowflake 테이블의 데이터를 pandas DataFrame 또는 pytorch 데이터 세트로 로드하는 방법을 보여줍니다.
참고
DataConnector API 는 Container Runtime for ML 에서 사용할 수 있으며, Snowpark Container Services(SPCS)에서 실행되는 Snowsight 노트북에서 사용할 수 있습니다.
from snowflake.ml.data.data_connector import DataConnector
# Retrieve data from a snowflake table
table_name = 'LARGE_TABLE_MULTIPLE_GBs'
snowpark_df = session.table(table_name)
# Materialize it into a pandas dataframe using DataConnector
pandas_df = DataConnector.from_dataframe(snowpark_df).to_pandas()
# Materialize it into a pytroch dataset using DataConnector
torch_dataset = data.to_torch_dataset(batch_size=1024)
학습¶
이 예제에서는 Snowflake ML Modeling을 사용하여 간단한 xgboost 분류기 모델을 훈련시킨 다음 예측을 실행하는 방법을 보여줍니다. 여기서 API는 xgboost와 유사하며 열 지정 방법이 약간 다를 뿐입니다. 이러한 차이점에 대한 자세한 내용은 일반적인 API 차이점 섹션을 참조하십시오.
import pandas as pd
from sklearn.datasets import make_classification
from snowflake.ml.modeling.xgboost import XGBClassifier
from snowflake.ml.utils.connection_params import SnowflakeLoginOptions
from snowflake.snowpark import Session
# Create a session with your preferred method
# session =
FEATURE_COLS = ["X1", "X2", "X3", "X4", "X5", "X6"]
LABEL_COLS = ["Y"]
OUTPUT_COLS = ["PREDICTIONS"]
# Set up data.
X, y = make_classification(
n_samples=40000,
n_features=6,
n_informative=4,
n_redundant=1,
random_state=0,
shuffle=True,
)
X = pd.DataFrame(X, columns=FEATURE_COLS)
y = pd.DataFrame(y, columns=LABEL_COLS)
features_pandas = pd.concat([X, y], axis=1)
features_df = session.create_dataframe(features_pandas)
# Train an XGBoost model on snowflake.
xgboost_model = XGBClassifier(
input_cols=FEATURE_COLS,
label_cols=LABEL_COLS,
output_cols=OUTPUT_COLS
)
xgboost_model.fit(features_df)
# Use the model to make predictions.
predictions = xgboost_model.predict(features_df)
predictions[OUTPUT_COLS].show()
비합성 데이터에 대한 특성 전처리 및 학습¶
이 예제에서는 지상 기반 대기 관측 체렌코프 망원경의 고에너지 감마 입자 데이터를 사용합니다. 이 망원경으로는 감마선으로 시작된 전자기 샤워에서 생성되는 하전 입자가 방출하는 방사선을 이용하여 고에너지 감마 입자를 관찰할 수 있습니다. 검출기가 대기를 통해 누출되는 (가시광선부터 자외선 파장까지의) 체렌코프 방사선을 기록하여 감마 샤워 매개 변수를 재구성할 수 있습니다. 또한 이 망원경으로 우주선 샤워에 풍부한 하드론 광선을 감지하고 감마선을 모방하는 신호를 생성할 수도 있습니다.
목표는 감마선과 하드론 광선을 구별하는 분류 모델을 개발하는 것입니다. 과학자들은 이 모델을 사용해 배경 잡음을 걸러내고 순수한 감마선 신호에 집중할 수 있습니다. 그래서 감마선을 통해 별의 탄생과 죽음, 우주 폭발, 극한 조건에서의 물질 거동과 같은 우주적 사건을 관찰할 수 있습니다.
입자 데이터는 MAGIC Gamma Telescope 에서 다운로드할 수 있습니다. 데이터를 다운로드하여 압축을 풀고 DATA_FILE_PATH 변수가 데이터 파일을 가리키도록 설정한 후 아래 코드를 실행하여 Snowflake에 로드합니다.
DATA_FILE_PATH = "~/Downloads/magic+gamma+telescope/magic04.data"
# Setup
from snowflake.ml.utils.connection_params import SnowflakeLoginOptions
from snowflake.snowpark import Session
import posixpath
import os
##
# Note: Create session https://docs.snowflake.com/en/developer-guide/snowpark/reference/python/latest/api/snowflake.snowpark.Session
##
session = Session.builder.configs(SnowflakeLoginOptions()).create()
session.sql("""
CREATE OR REPLACE TABLE Gamma_Telescope_Data(
F_LENGTH FLOAT,
F_WIDTH FLOAT,
F_SIZE FLOAT,
F_CONC FLOAT,
F_CONC1 FLOAT,
F_ASYM FLOAT,
F_M3_LONG FLOAT,
F_M3_TRANS FLOAT,
F_ALPHA FLOAT,
F_DIST FLOAT,
CLASS VARCHAR(10))
""").collect()
session.sql("CREATE OR REPLACE STAGE SNOWPARK_ML_TEST_DATA_STAGE").collect()
session.file.put(
DATA_FILE_PATH,
"SNOWPARK_ML_TEST_DATA_STAGE/magic04.data",
auto_compress=False,
overwrite=True,
)
session.sql("""
COPY INTO Gamma_Telescope_Data FROM @SNOWPARK_ML_TEST_DATA_STAGE/magic04.data
FILE_FORMAT = (TYPE = 'CSV' field_optionally_enclosed_by='"',SKIP_HEADER = 0);
""").collect()
session.sql("select * from Gamma_Telescope_Data limit 5").collect()
데이터를 로드한 후 아래의 단계에 따라 다음 코드를 사용하여 학습하고 예측합니다.
데이터 전처리:
누락된 값을 평균으로 바꿉니다.
표준 스케일러를 사용하여 데이터를 중앙에 배치합니다.
이벤트 유형을 결정하도록 xgboost 분류기를 학습시킵니다.
학습 데이터 세트와 테스트 데이터 세트에서 모두 모델의 정확성을 테스트합니다.
from snowflake.ml.utils.connection_params import SnowflakeLoginOptions
from snowflake.snowpark import Session, DataFrame
from snowflake.ml.modeling.preprocessing import StandardScaler
from snowflake.ml.modeling.impute import SimpleImputer
from snowflake.ml.modeling.pipeline import Pipeline
from snowflake.ml.modeling.xgboost import XGBClassifier
from snowflake.ml.modeling.metrics import accuracy_score
##
# Note: Create session https://docs.snowflake.com/en/developer-guide/snowpark/reference/python/latest/api/snowflake.snowpark.Session
##
session = Session.builder.configs(SnowflakeLoginOptions()).create()
# Step 1: Create train and test dataframes
all_data = session.sql("select *, IFF(CLASS = 'g', 1.0, 0.0) as LABEL from Gamma_Telescope_Data").drop("CLASS")
train_data, test_data = all_data.random_split(weights=[0.9, 0.1], seed=0)
# Step 2: Construct training pipeline with preprocessing and modeling steps
FEATURE_COLS = [c for c in train_data.columns if c != "LABEL"]
LABEL_COLS = ["LABEL"]
pipeline = Pipeline(steps = [
("impute", SimpleImputer(input_cols=FEATURE_COLS, output_cols=FEATURE_COLS)),
("scaler", StandardScaler(input_cols=FEATURE_COLS, output_cols=FEATURE_COLS)),
("model", XGBClassifier(input_cols=FEATURE_COLS, label_cols=LABEL_COLS))
])
# Step 3: Train
pipeline.fit(train_data)
# Step 4: Eval
predict_on_training_data = pipeline.predict(train_data)
training_accuracy = accuracy_score(df=predict_on_training_data, y_true_col_names=["LABEL"], y_pred_col_names=["OUTPUT_LABEL"])
predict_on_test_data = pipeline.predict(test_data)
eval_accuracy = accuracy_score(df=predict_on_test_data, y_true_col_names=["LABEL"], y_pred_col_names=["OUTPUT_LABEL"])
print(f"Training accuracy: {training_accuracy} \nEval accuracy: {eval_accuracy}")
분산 하이퍼 매개 변수 최적화¶
이 예제는 scikit-learn의 GridSearchCV 를 구현한 Snowflake를 사용하여 분산 하이퍼파라미터 최적화를 실행하는 방법을 보여줍니다. 개별 실행은 분산된 웨어하우스 컴퓨팅 리소스를 사용하여 병렬로 실행됩니다. 분산 하이퍼 매개 변수 최적화에 대한 자세한 내용은 분산 하이퍼 매개 변수 최적화 섹션을 참조하십시오.
from snowflake.snowpark import Session, DataFrame
from snowflake.ml.utils.connection_params import SnowflakeLoginOptions
from sklearn.datasets import make_classification
from snowflake.snowpark import Session, DataFrame
from snowflake.ml.modeling.xgboost import XGBClassifier
from snowflake.ml.modeling.model_selection.grid_search_cv import GridSearchCV
FEATURE_COLS = ["X1", "X2", "X3", "X4", "X5", "X6"]
LABEL_COLS = ["Y"]
OUTPUT_COLS = ["PREDICTIONS"]
# Create a session using your favorite login option.
# In this example we use a session builder with `SnowflakeLoginOptions`.
session = Session.builder.configs(SnowflakeLoginOptions()).create()
# Set up data.
def set_up_data(session: Session, n_samples: int) -> DataFrame:
X, y = make_classification(
n_samples=n_samples,
n_features=6,
n_informative=2,
n_redundant=0,
random_state=0,
shuffle=True,
)
X = pd.DataFrame(X, columns=FEATURE_COLS)
y = pd.DataFrame(y, columns=LABEL_COLS)
features_pandas = pd.concat([X, y], axis=1)
features_pandas.head()
features_df = session.create_dataframe(features_pandas)
return features_df
features_df = set_up_data(session, 10**4)
# Create a warehouse to use for the tuning job.
session.sql(
"""
CREATE or replace warehouse HYPERPARAM_WH
WITH WAREHOUSE_SIZE = 'X-SMALL'
WAREHOUSE_TYPE = 'Standard'
AUTO_SUSPEND = 60
AUTO_RESUME = TRUE
INITIALLY_SUSPENDED = FALSE;"""
).collect()
session.use_warehouse("HYPERPARAM_WH")
# Tune an XGB Classifier model using sklearn GridSearchCV.
DISTRIBUTIONS = dict(
n_estimators=[10, 50],
learning_rate=[0.01, 0.1, 0.2],
)
estimator = XGBClassifier()
grid_search_cv = GridSearchCV(estimator=estimator, param_grid=DISTRIBUTIONS, input_cols=FEATURE_COLS, label_cols=LABEL_COLS, output_cols=OUTPUT_COLS)
grid_search_cv.fit(features_df)
# Use the best model to make predictions.
predictions = grid_search_cv.predict(features_df)
predictions[OUTPUT_COLS].show()
# Retrieve sklearn model, and print the best score
sklearn_grid_search_cv = grid_search_cv.to_sklearn()
print(sklearn_grid_search_cv.best_score_)
분산 최적화의 힘을 실제로 확인하려면 백만 행의 데이터를 학습하십시오.
large_features_df = set_up_data(session, 10**6)
# Scale up the warehouse for a faster fit. This takes 2m15s to run on an L warehouse versus 4m5s on a XS warehouse.
session.sql(f"ALTER WAREHOUSE {session.get_current_warehouse()} SET WAREHOUSE_SIZE='LARGE'").collect()
grid_search_cv.fit(large_features_df)
print(grid_search_cv.to_sklearn().best_score_)
Snowflake Modeling 클래스¶
모든 Snowflake 모델링 및 전처리 클래스는 snowflake.ml.modeling 네임스페이스에 있습니다. snowflake-ml-python 모듈은 sklearn 네임스페이스의 해당 모듈과 이름이 동일합니다. 예를 들어, sklearn.calibration 에 해당하는 모듈은 snowflake.ml.modeling.calibration 입니다. xgboost 및 lightgbm 모듈은 각각 snowflake.ml.modeling.xgboost 및 snowflake.ml.modeling.lightgbm 에 해당합니다.
Modeling API는 기본 scikit-learn, xgboost 및 lightgbm 클래스의 래퍼를 제공하며, 그 대부분은 가상 웨어하우스에서 (단일 웨어하우스 노드에서 작동하는) 저장 프로시저로 실행됩니다. scikit-learn의 모든 클래스가 지원되는 것은 아닙니다. 현재 사용 가능한 클래스의 목록은 Python API 참조 섹션을 참조하십시오.
일부 클래스(전처리 및 메트릭 클래스 포함)는 분산 실행을 지원하며 동일한 작업을 로컬에서 실행하는 것에 비해 상당한 성능 이점을 제공할 수 있습니다. 자세한 내용은 분산 전처리 및 분산 하이퍼 매개 변수 최적화 섹션을 참조하십시오. 아래 표에는 분산 실행을 지원하는 특정 클래스가 나열되어 있습니다.
|
분산 클래스 |
|---|---|
|
|
|
|
|
|
|
|
일반적인 API 차이점¶
팁
모델링 API에 대한 전체 세부 정보는 API 참조 섹션을 참조하십시오.
Snowflake 모델링 클래스에는 scikit-learn, xgboost 및 lightgbm 기반의 데이터 전처리, 변환 및 예측 알고리즘이 포함됩니다. Snowpark Python 클래스는 서명이 유사한 원래 패키지의 해당 클래스를 대체합니다. 하지만 이러한 API는 NumPy 배열 대신 Snowpark DataFrames와 함께 작동하도록 설계되었습니다.
API는 scikit-learn과 유사하지만, 몇 가지 주요 차이점이 있습니다. 이 섹션에서는 Snowflake 추정기 및 변환기 클래스의 __init__ (생성자), fit, predict 메서드를 호출하는 방법을 설명합니다.
모든 Snowflake 모델 클래스의 생성자 는 scikit-learn, xgboost 또는 lightgbm의 동등한 클래스에서 허용되는 매개 변수 외에 5개 추가 매개 변수(
input_cols,output_cols,sample_weight_col,label_cols,drop_input_cols)를 허용합니다. 이들은 Snowpark 또는 Pandas DataFrame에서 입력 열, 출력 열, 샘플 가중치 열, 레이블 열의 이름을 지정하는 문자열 또는 문자열 시퀀스입니다. 사용하는 데이터 세트 중 일부의 이름이 다른 경우, 인스턴스화 후set_input_cols같은 제공된 setter 메서드 중 하나를 사용하여 이름을 변경할 수 있습니다.클래스를 인스턴스화할 때(또는 이후 setter 메서드를 사용하여) 열 이름을 지정하기 때문에
fit및predict메서드는 입력, 가중치 및 레이블에 대해 별도의 배열 대신 단일 DataFrame을 허용합니다. 제공된 열 이름은fit또는predict의 DataFrame에서 해당 열에 액세스하는 데 사용됩니다. fit 및 predict 섹션을 참조하십시오.기본적으로
transform및predict메서드는 추가 열에 저장된 예측의 출력과 함께 메서드에 전달된 DataFrame의 모든 열을 포함하는 DataFrame을 반환합니다. 출력 열 이름과 일치하는 출력 열 이름을 지정하여 제자리에서 변환하거나drop_input_cols = True를 전달하여 출력 열을 삭제할 수 있습니다.) scikit-learn, xgboost 및 lightgbm와 동등한 라이브러리는 결과만 포함하는 배열을 반환합니다.Snowpark Python 변환기에는
fit_transform메서드가 없습니다. 하지만 scikit-learn과 마찬가지로, 매개 변수 유효성 검사는fit메서드에서만 수행되므로, 변환기가 피팅을 수행하지 않을 때도transform전의 어느 시점에서fit을 호출해야 합니다.fit은 변환기를 반환하므로 메서드 호출이 연결될 수 있습니다(예:Binarizer(threshold=0.5).fit(df).transform(df)).현재 Snowflake 변환기에는
inverse_transform메서드가 없습니다. 많은 사용 사례에서 입력 열은 기본적으로 출력 데이터 프레임에 유지되므로 이 메서드는 필요하지 않습니다.
Snowflake Modeling 오브젝트를 해당 scikit-learn, xgboost 또는 lightgbm 오브젝트로 변환하여 기본 유형의 모든 메서드와 속성을 사용할 수 있습니다. 기본 모델 검색하기 섹션을 참조하십시오.
모델 생성하기¶
개별 scikit-learn 모델 클래스에서 허용하는 매개 변수 외에도, 모든 모델링 클래스는 인스턴스화할 때 다음의 추가 매개 변수를 허용합니다.
이러한 매개 변수는 모두 기술적으로는 선택 사항이지만, 종종 input_cols 나 output_cols 또는 둘 다 지정하려고 합니다. label_cols 와 sample_weight_col 은 표에 명시된 특정 상황에서 필요하지만 다른 경우에는 생략할 수 있습니다.
팁
모든 열 이름은 Snowflake 식별자 요구 사항 을 따라야 합니다. 테이블 생성 시 대/소문자를 유지하거나 (달러 기호 및 밑줄 이외의) 특수 문자를 사용하려면 열 이름을 큰따옴표로 묶어야 합니다. 대/소문자를 구분하는 Pandas DataFrames와의 호환성을 유지하려면 가능하다면 항상 모두 대문자로 된 열 이름을 사용하십시오.
from snowflake.ml.modeling.preprocessing import MinMaxScaler
from snowflake.snowpark import Session
# Snowflake identifiers are not case sensitive by default.
# These column names will be automatically updated to ["COLUMN_1", "COLUMN_2", "COLUMN_3"] by the Snowpark DataFrame.
schema = ["column_1", "column_2", "column_3"]
df = session.create_dataframe([[1, 2, 3]], schema = schema)
df.show()
--------------------------------------
|"COLUMN_1" |"COLUMN_2" |"COLUMN_3"|
--------------------------------------
|1 |2 |3 |
--------------------------------------
# Identify the column names using the Snowflake identifier.
input_cols = ["COLUMN_1", "COLUMN_2", "COLUMN_3"]
mms = MinMaxScaler(input_cols=input_cols)
mms.fit(df)
# To maintain lower case column names, include a double quote within the string.
schema = ['"column_1"', '"column_2"', '"column_3"']
df = session.create_dataframe([[1, 2, 3]], schema = schema)
df.show()
----------------------------------------
|'"column_1"'|'"column_2"'|'"column_3"'|
----------------------------------------
|1 |2 |3 |
----------------------------------------
# Since no conversion took place, the schema labels can be used as the column identifiers.
mms = MinMaxScaler(input_cols=schema)
mms.fit(df)
매개 변수 |
설명 |
|---|---|
|
기능을 포함하는 열 이름을 나타내는 문자열 또는 문자열 목록입니다. 이 매개 변수를 생략하면 |
|
레이블이 포함된 열의 이름을 나타내는 문자열 또는 문자열 목록입니다. 이러한 열을 유추하는 것은 불가능하므로 감독되는 추정기에 대한 레이블 열을 지정해야 합니다. 이러한 레이블 열은 모델 예측의 대상으로 사용되며 |
|
이 매개 변수를 생략하면 출력 열 이름은 감독되는 추정기의 경우 레이블 열 이름에 제자리에서 변환하려면 |
|
학습, 변환, 추론에서 제외할 열의 이름을 나타내는 문자열 또는 문자열 목록입니다. 통과 열은 입력 및 출력 DataFrames 사이에 그대로 유지됩니다. 이 옵션은 학습 또는 추론 중에 인덱스 열과 같은 특정 열을 사용하지 않으려 하지만 |
|
예제의 가중치를 포함하는 열 이름을 나타내는 문자열입니다. 이 인자는 가중 데이터 세트에 필요합니다. |
|
입력 열이 결과 DataFrame에서 제거되었는지 여부를 나타내는 부울 값입니다. 기본값은 |
예¶
DecisionTreeClassifier 생성자는 scikit-learn에 필요한 인자가 없습니다. 모든 인자에는 기본값이 있습니다. 따라서 scikit-learn에서 다음과 같이 작성할 수 있습니다.
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
Snowflake 버전의 이 클래스에서는 열 이름을 지정해야 합니다(또는 지정하지 않고 기본값을 사용). 이 예에서는 열 이름이 명시적으로 지정됩니다.
인자를 생성자에 직접 전달하거나 인스턴스화 후 인자를 모델의 특성으로 설정하여 DecisionTreeClassifier 를 초기화할 수 있습니다. (특성은 언제든지 변경될 수 있습니다.)
생성자 인자로 전달:
from snowflake.ml.modeling.tree import DecisionTreeClassifier model = DecisionTreeClassifier( input_cols=feature_column_names, label_cols=label_column_names, sample_weight_col=weight_column_name, output_cols=expected_output_column_names )
모델 특성 설정:
from snowflake.ml.modeling.tree import DecisionTreeClassifier model = DecisionTreeClassifier() model.set_input_cols(feature_column_names) model.set_label_cols(label_column_names) model.set_sample_weight_col(weight_column_name) model.set_output_cols(output_column_names)
fit¶
Snowflake 분류자의 fit 메서드는 특징, 레이블, 가중치를 비롯한 모든 열이 포함된 단일 Snowpark 또는 Pandas DataFrame을 받습니다. 이는 특징, 레이블, 가중치에 대해 별도의 입력을 받는 scikit-learn의 fit 메서드와 다른 점입니다.
scikit-learn에서는 DecisionTreeClassifier.fit 메서드 호출이 다음과 같은 형태입니다.
model.fit(
X=df[feature_column_names], y=df[label_column_names], sample_weight=df[weight_column_name]
)
Snowflake fit 에서는 DataFrame만 전달하면 됩니다. 모델 생성하기 에 표시된 것처럼, 초기화 시 또는 setter 메서드를 사용하여 입력, 레이블 및 가중치 열 이름을 이미 설정했습니다.
model.fit(df)
predict¶
predict 메서드는 또한 모든 기능 열이 포함된 단일 Snowpark 또는 pandas DataFrame을 사용합니다. 결과는 변경되지 않은 입력 DataFrame의 모든 열과 추가된 출력 열을 포함하는 DataFrame입니다. 이 DataFrame에서 출력 열을 추출해야 합니다. 이는 결과만 반환하는 scikit-learn의 predict 메서드와 다릅니다.
예¶
scikit-learn에서 predict 는 예측 결과만 반환합니다.
prediction_results = model.predict(X=df[feature_column_names])
Snowflake의 predict 에서 예측 결과만 가져오려면 반환된 DataFrame 에서 출력 열을 추출합니다. 여기서 output_column_names 는 출력 열의 이름을 포함하는 목록입니다.
prediction_results = model.predict(df)[output_column_names]
SPCS를 사용한 분산 훈련 및 추론¶
![]() 미리 보기 기능 — 공개
미리 보기 기능 — 공개
모든 계정에서 사용 가능합니다.
Snowpark Container Services(SPCS)의 Snowflake Notebook에서 실행하는 경우, 이러한 모델링 클래스에 대한 모델 훈련과 추론은 웨어하우스가 아닌 기본 컴퓨팅 클러스터에서 실행되며, 클러스터의 모든 노드에 투명하게 분산되어 사용 가능한 모든 컴퓨팅 기능을 사용합니다.
전처리 및 메트릭 작업은 웨어하우스로 푸시됩니다. 많은 전처리 클래스는 웨어하우스에서 실행할 때 분산 실행을 지원합니다. 분산 전처리 섹션을 참조하십시오.
분산 전처리¶
많은 Snowflake의 데이터 전처리 및 변환 함수는 분산 실행 엔진을 사용하여 구현되므로 단일 노드 실행(즉, 저장 프로시저)에 비해 상당한 성능 이점을 얻을 수 있습니다. 분산 실행을 지원하는 함수를 알아보려면 Snowflake Modeling 클래스 섹션을 참조하십시오.
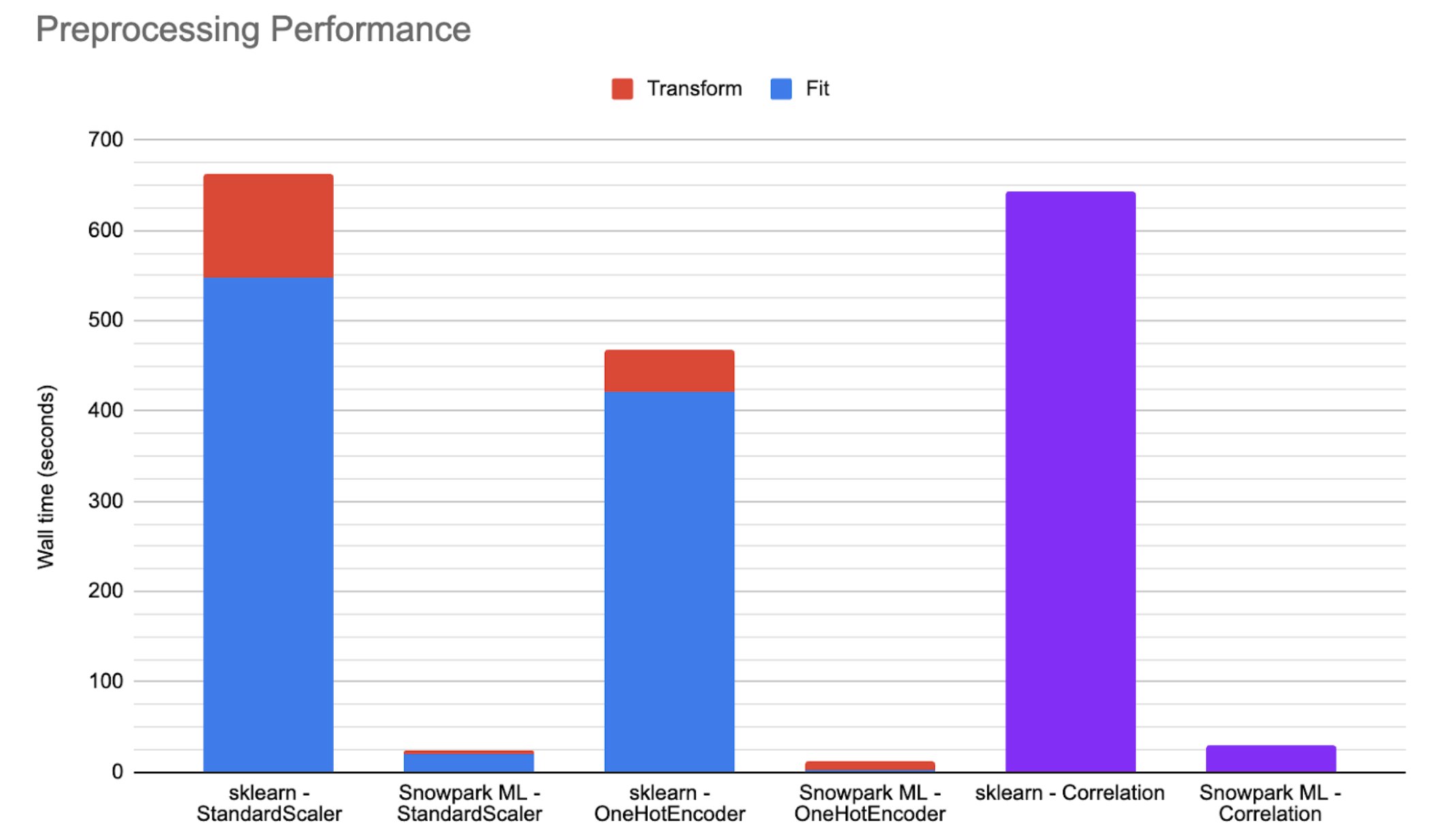
아래 차트는 Snowflake의 분산 구현과 저장 프로시저에서 실행되는 scikit-learn을 비교하여 Snowpark에 최적화된 중간 규모의 웨어하우스에서 실행되는 대규모 공개 데이터 세트의 성능 수치를 보여줍니다. Snowflake 모델링 클래스를 사용하면 코드가 25~50배 더 빠르게 실행될 수 있습니다.
피팅 배포 방식¶
Snowflake 전처리 변환기의 fit 메서드는 Snowpark 또는 pandas DataFrame을 받아들이고 데이터 세트를 피팅하고 피팅된 변환기를 반환합니다.
Snowpark DataFrames의 경우 분산 피팅은 SQL 엔진을 사용합니다. 변환기는 필요한 상태(예: 평균, 최대값 또는 개수)를 계산하는 SQL 쿼리를 생성합니다. 그런 다음 이러한 쿼리는 Snowflake에서 실행되고 결과는 로컬에서 구체화됩니다. SQL에서 계산할 수 없는 복잡한 상태의 경우 변환기는 Snowflake에서 중간 결과를 가져오고 메타데이터에 대해 로컬 계산을 수행합니다.
변환 중에 임시 상태 테이블이 필요한 복잡한 변환기(예:
OneHotEncoder또는OrdinalEncoder)의 경우 이러한 테이블은 pandas DataFrames를 사용하여 로컬에서 표시됩니다.pandas DataFrames는 scikit-learn과의 피팅과 유사하게 로컬에서 피팅됩니다. 변환기는 제공된 매개 변수를 사용하여 해당 scikit-learn 변환기를 생성합니다. 그런 다음 scikit-learn 변환기가 피팅되고 Snowflake 변환기가 scikit-learn 오브젝트에서 필요한 상태를 파생합니다.
변환 분산 방식¶
전처리 변환기의 transform 메서드는 Snowpark 또는 Pandas DataFrame을 받고, 데이터 세트를 변환하고, 변환된 데이터 세트를 반환합니다.
Snowpark DataFrames의 경우 SQL 엔진을 사용하여 분산 변환이 수행됩니다. 피팅된 변환기는 변환된 데이터 세트를 나타내는 기본 SQL 쿼리를 사용하여 Snowpark DataFrame을 생성합니다.
transform메서드는 간단한 변환(예:StandardScaler또는MinMaxScaler)에 대해 지연 평가를 수행하므로,transform메서드 실행 중에는 실제로 변환이 수행되지 않습니다.그러나 복잡한 특정 변환에는 실행이 포함됩니다. 여기에는 변환 중에 임시 상태 테이블(예:
OneHotEncoder및OrdinalEncoder)이 필요한 변환기가 포함됩니다. 이러한 변환기는 조인 및 기타 작업을 위해 (오브젝트 상태를 저장하는) Pandas DataFrame에서 임시 테이블을 생성합니다.또한, 특정 매개 변수가 설정되면, 예를 들어 변환 중에 발견된 알 수 없는 값을 오류를 발생시켜 처리하도록 변환기를 설정하면 변환기는 열, 알 수 없는 값 등을 포함한 데이터를 구체화합니다.
Pandas DataFrames는 scikit-learn을 사용한 변환과 유사하게 로컬에서 변환됩니다. 변환기는
to_sklearnAPI를 사용하여 해당 scikit-learn 변환기를 생성하고 메모리에서 변환을 수행합니다.
분산 하이퍼 매개 변수 최적화¶
하이퍼 매개 변수 조정은 데이터 과학 워크플로의 필수적인 부분입니다. Snowflake API는 scikit-learn GridSearchCV 및 RandomizedSearchCV APIs의 분산 구현을 제공하여 단일 노드 및 다중 노드 웨어하우스에서 모두 효율적인 하이퍼 매개 변수 조정을 지원합니다.
팁
Snowflake는 기본적으로 분산 하이퍼 매개 변수 최적화를 활성화합니다. 이를 비활성화하려면 다음 Python 가져오기를 사용하십시오.
import snowflake.ml.modeling.parameters.disable_distributed_hpo
가장 작은 Snowflake 가상 웨어하우스(XS) 또는 Snowpark 최적화 웨어하우스(M)에는 노드가 1개 있습니다. 연속적으로 크기가 커질 때마다 노드 수가 두 배로 늘어납니다.
단일 노드(XS) 웨어하우스의 경우 기본적으로 scikit-learn의 joblib 다중 처리 프레임워크를 사용하여 노드의 전체 용량을 활용합니다.
팁
각 맞춤 작업에는 RAM에 로드된 해당 훈련 데이터 세트의 자체 복사본이 필요합니다. 매우 큰 데이터 세트를 처리하려면 분산 하이퍼파라미터 최적화(import snowflake.ml.modeling.parameters.disable_distributed_hpo 사용)를 비활성화하고 n_jobs 매개 변수를 1로 설정하여 동시성을 최소화하십시오.
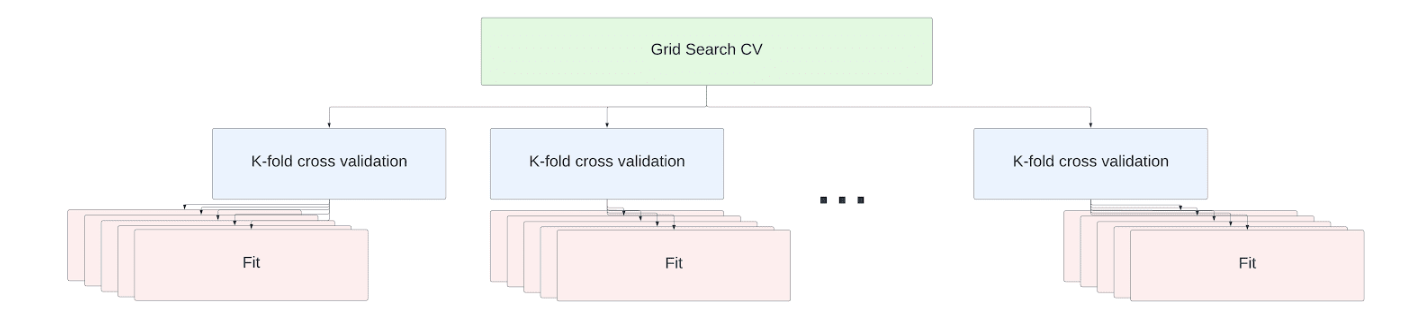
다중 노드 웨어하우스의 경우 교차 검증 조정 작업 내의 fit 작업이 노드 전체에 분산됩니다. 확장하는 데 따로 코드를 변경할 필요는 없습니다. 추정기 피팅은 웨어하우스의 모든 노드에서 사용 가능한 모든 코어에 걸쳐 병렬로 실행됩니다.
예를 들어 scikit-learn 라이브러리와 함께 제공되는 캘리포니아 주택 데이터 세트 를 생각해 보십시오. 데이터에는 다음 정보를 비롯한 20,640행의 데이터가 포함됩니다.
MedInc: 블록 그룹의 중위 소득
HouseAge: 블록 그룹의 평균 주택 연식
AveRooms: 가구당 평균 방 수
AveBedrms: 가구당 평균 침실 수
Population: 블록 그룹 인구
AveOccup: 평균 가구 구성원 수
Latitude 및 Longitude
데이터 세트의 대상은 십만 달러 단위로 표현되는 중위 소득입니다.
이 예제에서는 중위 소득 예측에 가장 적합한 하이퍼 매개 변수 조합을 찾기 위해 랜덤 포레스트 회귀 분석기에서 그리드 검색 교차 검증을 수행합니다.
from snowflake.ml.modeling.ensemble.random_forest_regressor import RandomForestRegressor
from snowflake.ml.modeling.model_selection.grid_search_cv import GridSearchCV
from sklearn import datasets
def load_housing_data() -> DataFrame:
input_df_pandas = datasets.fetch_california_housing(as_frame=True).frame
# Set the columns to be upper case for consistency with Snowflake identifiers.
input_df_pandas.columns = [c.upper() for c in input_df_pandas.columns]
input_df = session.create_dataframe(input_df_pandas)
return input_df
input_df = load_housing_data()
# Use all the columns besides the median value as the features
input_cols = [c for c in input_df.columns if not c.startswith("MEDHOUSEVAL")]
# Set the target median value as the only label columns
label_cols = [c for c in input_df.columns if c.startswith("MEDHOUSEVAL")]
DISTRIBUTIONS = dict(
max_depth=[80, 90, 100, 110],
min_samples_leaf=[1,3,10],
min_samples_split=[1.0, 3,10],
n_estimators=[100,200,400]
)
estimator = RandomForestRegressor()
n_folds = 5
clf = GridSearchCV(estimator=estimator, param_grid=DISTRIBUTIONS, cv=n_folds, input_cols=input_cols, label_cols=label_col)
clf.fit(input_df)
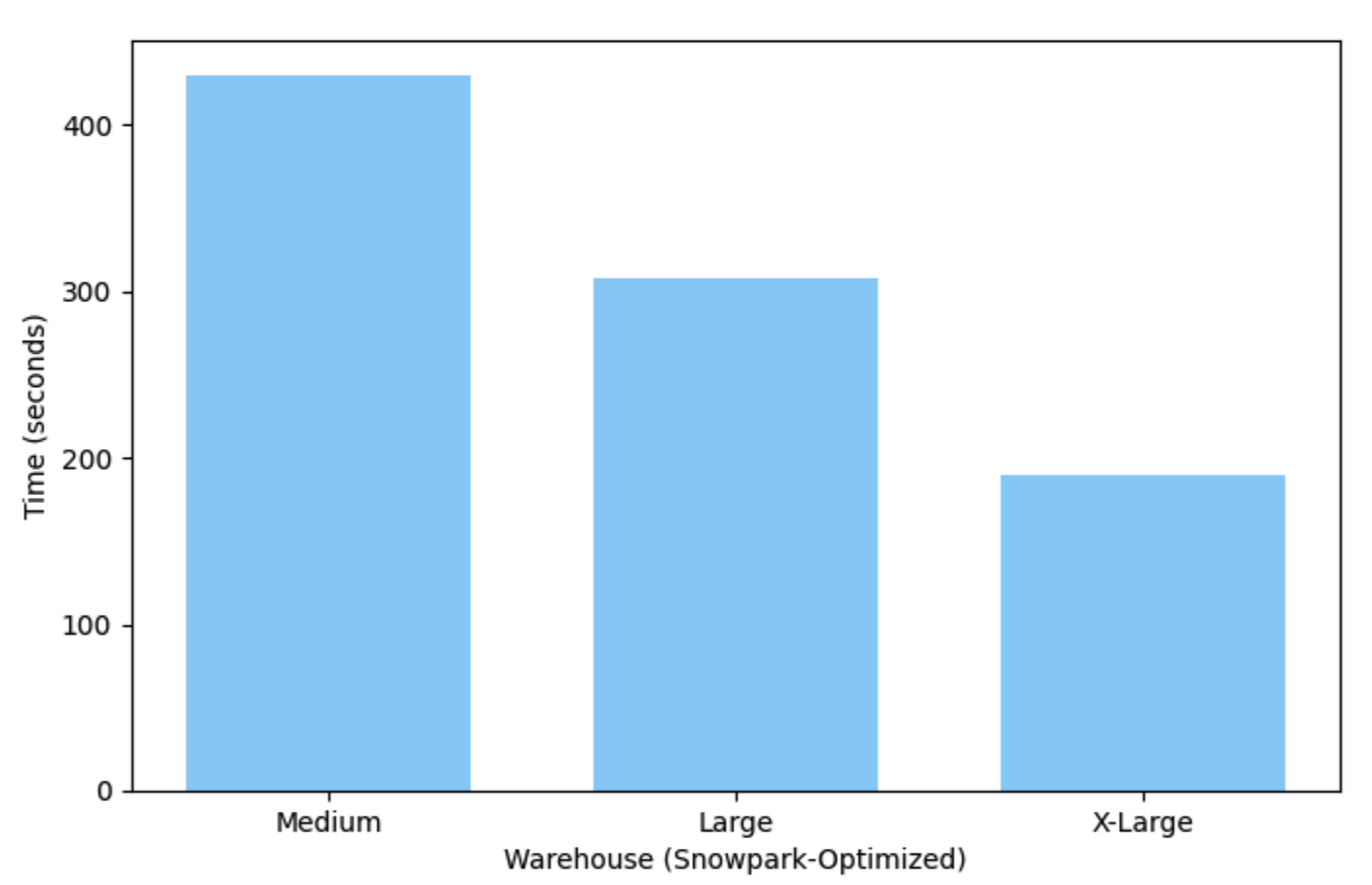
이 예는 Medium(단일 노드) Snowpark 최적화 웨어하우스에서 단 7분여 만에 실행되며 X-Large 웨어하우스에서는 실행 시간이 3분밖에 걸리지 않습니다.
모델 배포 및 실행하기¶
모델 훈련 결과는 Python 모델 오브젝트입니다. 학습된 모델을 사용하여 모델의 predict 메서드를 호출함으로써 예측을 수행할 수 있습니다. 이렇게 하면 Snowflake 가상 웨어하우스에서 모델을 실행하기 위한 임시 사용자 정의 함수가 생성됩니다. 이 함수는 Snowflake 세션이 끝날 때(예: 스크립트가 종료되거나 노트북을 닫을 때) 자동으로 삭제됩니다.
세션이 종료된 후에도 사용자 정의 함수를 유지하려면 함수를 수동으로 생성할 수 있습니다. 자세한 내용은 이 항목의 빠른 시작 을 참조하십시오.
Snowflake 모델 레지스트리도 영구 모델을 지원하고 모델을 더 쉽게 찾고 배포할 수 있게 해줍니다. Snowflake Model Registry 섹션을 참조하십시오.
분할된 사용자 지정 모델¶
모델 레지스트리는 또한 파티션 세트에 대한 적합성과 추론이 병렬로 실행되는 특수한 유형의 사용자 지정 모델을 지원합니다. 이는 1개의 데이터 세트에서 여러 모델을 동시에 생성하고 즉시 추론을 실행하는 효율적인 방법이 될 수 있습니다. 자세한 내용은 분할된 모델 사용하기 섹션을 참조하십시오.
다중 변환을 위한 파이프라인¶
scikit-learn에서는 파이프라인을 사용하여 일련의 변환을 실행하는 것이 일반적입니다. scikit-learn 파이프라인은 Snowflake 클래스에서는 작동하지 않으므로 일련의 변환을 실행하기 위해 sklearn.pipeline.Pipeline 의 Snowflake 버전이 제공됩니다. 이 클래스는 snowflake.ml.modeling.pipeline 패키지에 있으며 scikit-learn 버전과 동일하게 작동합니다.
기본 모델 검색하기¶
Snowflake ML 모델은 다음 메서드(라이브러리에 따라 다름)를 사용하여 “래핑 취소”(즉, 기본 서드 파티 모델 유형으로 변환)할 수 있습니다.
to_sklearnto_xgboostto_lightgbm
그러면 기본 모델의 모든 속성과 메서드에 액세스하고 추정기에 대해 로컬에서 이들을 실행할 수 있습니다. 예를 들어, GridSearchCV 예제 에서는 최고 점수를 검색하기 위해 그리드 검색 추정기를 scikit-learn 오브젝트로 변환합니다.
best_score = grid_search_cv.to_sklearn().best_score_
알려진 제한 사항¶
Snowflake 추정기와 변환기는 현재 희소 입력값이나 희소 응답을 지원하지 않습니다. 희소 데이터가 있는 경우 Snowflake의 추정기 또는 변환기에 전달하기 전에 조밀한 형식으로 변환하십시오.
snowflake-ml-python패키지는 현재 행렬 데이터 타입을 지원하지 않습니다. 결과적으로 행렬을 생성하는 추정기 및 변환기에 대한 모든 작업은 실패합니다.결과 데이터의 행 순서가 입력 데이터의 행 순서와 일치하리라는 보장은 없습니다.
Snowflake ML은 아직 pandas on Snowflake DataFrames 를 지원하지 않습니다. Snowflake 모델링 클래스와 함께 사용하기 위해 Pandas on Snowflake 데이터프레임을 Snowpark 데이터프레임으로 변환합니다. 다음 예제에서는 Snowflake 테이블에서 읽은 DataFrame을 변환합니다.
import modin.pandas as pd import snowflake.snowpark.modin.plugin from snowflake.ml.modeling.xgboost import XGBClassifier snowpark_pandas_df: modin.pandas.DataFrame = read_snowflake('MY_TABLE') # converting to Snowpark DataFrame adds an index column index_label_name = "_INDEX" snowpark_df = snowpark_pandas_df.to_snowpark(index=True, index_label=index_label_name) snowpark_df.show()
결과물인 Snowpark DataFrame은 다음과 같습니다.
-------------------------------------------------- |"COLUMN_1" |"COLUMN_2" |"TARGET" | "_INDEX" | -------------------------------------------------- |1 |2 |3 |1 | --------------------------------------------------
그런 다음 DataFrame을 사용하여 다음과 같이 XGBoost 분류기를 훈련시킬 수 있습니다
# Identify the column names using the Snowflake identifier input_cols = ["COLUMN_1", "COLUMN_2", "COLUMN_3"] # Pass through the _INDEX column rather than using it for training xgb_clf = XGBClassifier(input_cols=input_cols, passthrough_cols=index_label_name, label_cols="TARGET") xgb_clf.fit(snowpark_df)
문제 해결하기¶
로깅에 세부 정보 추가하기¶
Snowflake 모델링 라이브러리는 Snowpark Python의 로깅을 사용합니다. 기본적으로 snowflake-ml-python 은 INFO 수준 메시지를 표준 출력에 로그로 기록합니다. 더 자세한 로그를 얻으려면 지원되는 수준 중 하나로 수준을 변경하면 됩니다.
DEBUG는 가장 세부적인 로그를 생성합니다. 로깅 수준을 DEBUG로 설정하려면 다음을 수행하십시오.
import logging, sys
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
일반적인 문제에 대한 해결책¶
다음 표에서는 Snowflake ML Modeling과 관련하여 발생할 수 있는 문제를 해결하기 위한 몇 가지 제안 사항을 제시합니다.
문제 또는 오류 메시지 |
가능한 원인 |
해결책 |
|---|---|---|
“이름 x가 정의되지 않음”, ImportError 또는 ModuleNotFoundError와 같은 NameError |
모듈 또는 클래스 이름에 오타가 있거나 |
올바른 모듈 및 클래스 이름은 모델링 클래스 테이블을 참조하십시오. |
KeyError(“인덱스에 없음” 또는 “[인덱스[..]]가 [열]에 없음”) |
열 이름이 잘못되었습니다. |
열 이름을 확인하고 수정하십시오. |
SnowparkSQLException, “존재하지 않거나 권한이 없음” |
테이블이 없거나 테이블에 대한 충분한 권한이 없습니다. |
테이블이 존재하고 사용자의 역할에 권한이 있는지 확인하십시오. |
SnowparkSQLException, “유효하지 않은 식별자 PETALLENGTH” |
열 수가 잘못되었습니다(보통은 열 누락). |
모델 클래스를 만들 때 지정한 열 수를 확인하고 올바른 수를 전달해야 합니다. |
InvalidParameterError |
부적절한 유형 또는 값이 매개 변수로 전달되었습니다. |
대화식 Python 세션에서 |
TypeError, “예기치 않은 키워드 인자” |
명명된 인자의 인쇄상 오류. |
대화식 Python 세션에서 |
ValueError, “샘플이 0개인 배열” |
전달된 데이터 세트가 비어 있습니다. |
데이터 세트가 비어 있지 않도록 하십시오. |
SnowparkSQLException, “인증 토큰이 만료됨” |
세션이 만료되었습니다. |
Jupyter 노트북을 사용 중인 경우 커널을 다시 시작하여 새 세션을 만드십시오. |
“cannot convert string to float”와 같은 ValueError |
데이터 타입 불일치. |
대화식 Python 세션에서 |
SnowparkSQLException, “임시 테이블을 생성할 수 없음” |
호출자의 권한으로 실행되지 않는 저장 프로시저 내에서 모델 클래스가 사용되고 있습니다. |
소유자 권한 대신 호출자 권한으로 저장 프로시저를 만드십시오. |
SnowparkSQLException, “function available memory exceeded” |
데이터 세트가 표준 웨어하우스에서 5GB보다 큽니다. |
Snowpark에 최적화된 웨어하우스 로 전환하십시오. |
OSError, “디바이스에 남은 공간이 없음” |
모델이 표준 웨어하우스에서 약 500MB보다 큽니다. |
Snowpark에 최적화된 웨어하우스 로 전환하십시오. |
호환되지 않는 xgboost 버전 또는 xgboost를 가져올 때 오류 발생 |
종속성을 제대로 처리하지 못하는 |
오류 메시지의 요청에 따라 패키지를 업그레이드하거나 다운그레이드하십시오. |
|
다른 유형의 모델에서 이러한 방법 중 하나를 사용하려는 시도. |
scikit-learn 기반 모델 등에 |
Arm 기반 Mac(M1 또는 M2 칩)에서 Jupyter 노트북 커널이 충돌함: “The Kernel crashed while executing code in the current cell or a previous cell.” |
XGBoost 또는 다른 라이브러리가 잘못된 아키텍처로 설치됩니다. |
|
“lightgbm.basic.LightGBMError: (0000) 기능 이름에 특수 JSON 문자를 지원하지 않습니다.” |
LightGBM은 |
Snowpark DataFrames의 열 이름을 변경합니다. 대부분의 경우 영숫자가 아닌 문자를 밑줄로 바꾸면 충분합니다. 아래의 Python 도우미 함수가 유용할 수 있습니다. def fix_values(F, column):
return F.upper(F.regexp_replace(F.col(column), "[^a-zA-Z0-9]+", "_"))
|
추가 자료¶
해당 기능에 대한 전체 정보는 원본 라이브러리의 설명서를 참조하십시오.
감사의 말씀¶
이 문서의 일부는 BSD-3 “신규” 또는 “개정” 라이선스 및 Copyright © 2007-2023 The scikit-learn developers에 따라 라이선스가 부여된 Scikit-learn 설명서에서 파생되었습니다. All rights reserved.
이 문서의 일부는 Apache License 2.0(2004년 1월) 및 Copyright © 2019로 보호되는 XGboost 설명서에서 파생되었습니다. All rights reserved.
이 문서의 일부는 MIT 라이선스가 있고 Copyright © Microsoft Corp.로 보호되는 LightGBM 설명서에서 파생되었습니다. All rights reserved.