Snowpark Scala로 쿼리를 분석하고 문제를 해결하기¶
이 항목에서는 Snowpark 라이브러리로 작업할 때의 쿼리 분석 및 문제 해결에 대한 몇 가지 지침을 제공합니다.
Snowpark에서 쿼리 실행 계획 보기¶
DataFrame의 평가 계획을 검사하려면 DataFrame의 explain 메서드를 호출하십시오. 이 작업은 DataFrame을 평가하는 데 사용되는 SQL 문을 출력합니다. SQL 문이 하나만 있는 경우, 이 메서드는 이 문에 대한 논리적 계획도 출력합니다.
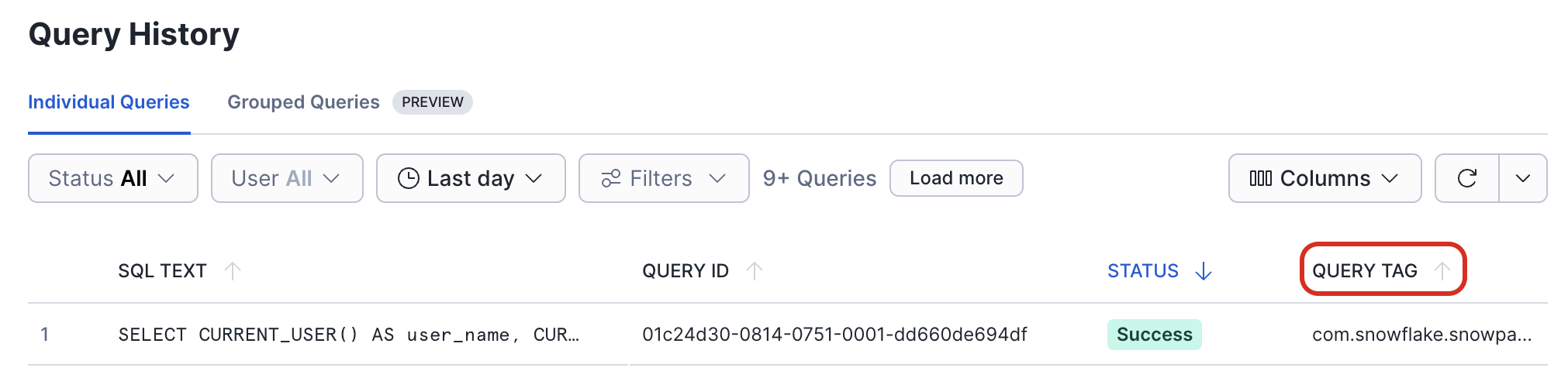
After the execution of a DataFrame has been triggered, you can check on the progress of the query in the Query History page in Snowsight.
Query Tag 열에서는 이 쿼리를 트리거한 코드의 함수 이름과 줄 번호를 찾을 수 있습니다.
문제 해결하기¶
로깅 설정 변경¶
기본적으로 Snowpark 라이브러리는 INFO 수준 메시지를 stdout에 로그합니다. 로깅 설정을 변경하려면 simplelogger.properties 파일을 만들고 해당 파일에서 로거 속성을 구성합니다. 예를 들어, 로그 수준을 DEBUG 로 설정하려면:
이 파일을 클래스 경로에 넣으십시오. Maven 디렉터리 레이아웃을 사용하는 경우, 파일을 src/main/resources/ 디렉터리에 넣으십시오.
java.lang.OutOfMemoryError 예외¶
java.lang.OutOfMemoryError 예외가 발생하면 JVM의 최대 힙 크기를 늘리십시오.
Scala REPL을 사용 중이고 최대 힙 크기를 늘려야 하는 경우, run.sh 셸 스크립트(아카이브 파일에 제공됨)를 편집하고 -J-Xmxmaximum_size 플래그를 scala 명령에 추가하십시오. 다음 예에서는 최대 힙 크기를 4GB로 늘립니다.