트랜잭션¶
트랜잭션은 한 단위로 커밋되거나 롤백되는 SQL 문으로 구성된 시퀀스입니다.
소개¶
트랜잭션이란?¶
트랜잭션은 원자 단위로 처리되는 SQL 문으로 구성된 시퀀스입니다. 트랜잭션의 모든 문은 함께 적용(커밋)되거나 실행 취소(롤백)됩니다. Snowflake 트랜잭션은 ACID 속성 을 보장합니다.
트랜잭션은 읽기와 쓰기를 둘 다 포함할 수 있습니다.
트랜잭션은 다음 규칙을 따릅니다.
트랜잭션은 결코 중첩 되지 않습니다. 예를 들어, 커밋된 내부 트랜잭션을 롤백하는 외부 트랜잭션을 만들거나 롤백된 내부 트랜잭션을 커밋하는 외부 트랜잭션을 만들 수 없습니다.
트랜잭션은 단일 세션과 연결됩니다. 여러 세션이 같은 트랜잭션을 공유할 수 없습니다. 같은 세션에 스레드가 겹치는 트랜잭션을 처리하는 방법에 대한 자세한 내용은 트랜잭션과 다중 스레딩 을 참조하십시오.
용어¶
이 항목에서 사용되는 주요 용어는 다음과 같습니다.
DDL 이라는 용어에는 CTAS 문(CREATE TABLE AS SELECT)은 물론이고 데이터베이스 오브젝트를 정의하는 다른 DDL 문도 포함됩니다.
DML 이라는 용어는 INSERT, UPDATE, DELETE, MERGE, TRUNCATE 문을 나타냅니다.
쿼리 문 이라는 용어는 SELECT 및 CALL 문을 나타냅니다.
(저장 프로시저 를 호출하는) CALL 문은 단일 문이지만, 이 문이 호출하는 저장 프로시저는 여러 문을 포함할 수 있습니다. 저장 프로시저와 트랜잭션에 대한 특별한 규칙 이 있습니다.
명시적 트랜잭션¶
트랜잭션은 BEGIN 문을 실행하여 명시적으로 시작할 수 있습니다. Snowflake는 BEGIN WORK 와 BEGIN TRANSACTION을 동의어로 지원합니다. Snowflake에서는 BEGIN TRANSACTION을 사용할 것을 권장합니다.
COMMIT 또는 ROLLBACK 을 실행하여 트랜잭션을 명시적으로 종료할 수 있습니다. Snowflake는 COMMIT WORK 를 COMMIT의 동의어, ROLLBACK WORK를 ROLLBACK의 동의어로 지원합니다.
일반적으로, 트랜잭션이 이미 활성 상태이면 모든 BEGIN TRANSACTION 문이 무시됩니다. 하지만 사용자는 추가 BEGIN TRANSACTION 문을 피해야 하는데, 이러한 문을 사용하면 다른 사람이 읽을 때 COMMIT(또는 ROLLBACK) 문과 그에 대응되는 BEGIN TRANSACTION 문을 짝지어 읽기가 훨씬 더 어려워지기 때문입니다.
이 규칙의 한 가지 예외는 중첩 저장 프로시저 호출과 관련된 것입니다. 자세한 내용은 범위 지정 트랜잭션 섹션을 참조하십시오.
참고
명시적 트랜잭션은 DML 문과 쿼리 문만 포함해야 합니다. DDL 문은 암시적으로 활성 트랜잭션을 커밋합니다(자세한 내용은 DDL 섹션 참조).
암시적 트랜잭션¶
트랜잭션은 명시적 BEGIN TRANSACTION 또는 COMMIT/ROLLBACK 없이 암시적으로 시작하고 종료할 수 있습니다. 암시적 트랜잭션은 명시적 트랜잭션과 같은 방식으로 동작합니다. 하지만 암시적 트랜잭션이 시작되는 시점을 결정하는 규칙은 명시적 트랜잭션이 시작되는 시점을 결정하는 규칙과 다릅니다.
중지 및 시작에 대한 규칙은 문이 DDL 문, DML 문 또는 쿼리 문인지에 따라 다릅니다. 문이 DML 또는 쿼리 문인 경우 규칙은 AUTOCOMMIT 의 사용 여부에 따라 다릅니다.
DDL¶
각 DDL 문은 별개의 트랜잭션으로 실행됩니다.
트랜잭션이 활성 상태에서 DDL 문이 실행될 경우 DDL 문은 다음을 수행합니다.
암시적으로 활성 트랜잭션을 커밋합니다.
DDL 문을 별개의 트랜잭션으로 실행합니다.
DDL 문은 자체 트랜잭션이므로 DDL 문을 롤백할 수 없습니다. DDL을 포함한 트랜잭션이 완료되어야 명시적 ROLLBACK을 실행할 수 있습니다.
DDL 문 바로 다음에 DML 문이 뒤따를 경우 그 DML 문은 암시적으로 새 트랜잭션을 시작합니다.
AUTOCOMMIT¶
Snowflake는 AUTOCOMMIT 매개 변수를 지원합니다. AUTOCOMMIT의 기본 설정은 TRUE(활성화됨)입니다.
AUTOCOMMIT이 활성화된 상태에서는 다음 사항이 적용됩니다.
명시적 트랜잭션 외부의 문은 각각 그 자신의 암시적 단일 문 트랜잭션 내부에 있는 것처럼 처리됩니다. 다시 말해, 해당 문이 성공하면 자동으로 커밋되고 실패하면 자동으로 롤백됩니다.
명시적 트랜잭션 내부의 문은 AUTOCOMMIT의 영향을 받지 않습니다. 예를 들어, 명시적 BEGIN TRANSACTION … ROLLBACK 내부의 문은 AUTOCOMMIT이 TRUE이더라도 롤백됩니다.
AUTOCOMMIT이 비활성화된 상태에서는 다음 사항이 적용됩니다.
암시적 BEGIN TRANSACTION은 다음에서 실행됩니다.
트랜잭션 종료 후 첫 번째 DML 문. 이는 무엇이 선행 트랜잭션(예: DDL 문, 명시적 COMMIT 또는 ROLLBACK)을 종료했는지에 상관없이 적용됩니다.
AUTOCOMMIT을 비활성화 후 첫 번째 DML 문.
암시적 COMMIT은 다음과 같은 경우에 실행됩니다(트랜잭션이 이미 활성 상태인 경우).
DDL 문이 실행되는 경우.
새 값이 TRUE 또는 FALSE인지, 이전 값과 다른지 여부에 관계없이
ALTER SESSION SET AUTOCOMMIT문이 실행되는 경우. 예를 들어, AUTOCOMMIT이 이미 FALSE일 때 이를 FALSE로 설정하더라도 암시적 COMMIT 이 실행됩니다.
암시적 ROLLBACK은 다음과 같은 경우에 실행됩니다(트랜잭션이 이미 활성 상태인 경우).
세션 종료 시.
저장 프로시저 종료 시.
저장 프로시저의 활성 트랜잭션이 명시적으로나 암시적으로 시작되었는지에 상관없이, Snowflake는 활성 트랜잭션을 롤백하고 오류 메시지를 발행합니다.
조심
저장 프로시저 내에서 AUTOCOMMIT 설정을 변경하지 마십시오. 오류 메시지가 나타납니다.
트랜잭션의 암시적 시작 및 종료와 명시적 시작 및 종료 혼용하기¶
혼란을 일으키는 코드를 작성하지 않으려면 같은 트랜잭션에서 암시적 시작 및 종료와 명시적 시작 및 종료를 혼용하면 안 됩니다. 다음은 정당하긴 하지만 권장하는 방법은 아닙니다.
암시적으로 시작한 트랜잭션을 명시적 COMMIT 또는 ROLLBACK으로 종료할 수 있습니다.
명시적으로 시작한 트랜잭션을 암시적 COMMIT 또는 ROLLBACK으로 종료할 수 있습니다.
트랜잭션 내에서 실패한 문¶
트랜잭션이 한 단위로 커밋되거나 롤백되더라도 이는 한 단위로 성공하거나 실패한다는 것과는 다른 사안입니다. 트랜잭션 내에서 문이 실패하더라도 트랜잭션을 롤백하는 대신 계속 커밋할 수 있습니다.
트랜잭션의 DML 문 또는 CALL 문이 실패하면 실패한 문으로 변경한 내용은 롤백됩니다. 하지만 전체 트랜잭션이 커밋되거나 롤백될 때까지 트랜잭션은 활성 상태를 유지합니다. 트랜잭션이 커밋되면 성공한 문에 의한 변경 내용이 적용됩니다.
예를 들어, 두 개의 유효한 값과 한 개의 잘못된 값을 테이블에 삽입하는 다음 코드를 생각해보십시오.
실패한 INSERT 문 이후의 문이 실행되면 트랜잭션에서 다른 문 중 하나가 실패하더라도 최종 SELECT 문의 출력에는 정수 값 1과 2가 있는 행이 포함됩니다.
참고
실패한 INSERT 문 이후의 문은 실행되거나 실행되지 않을 수 있습니다. 동작은 문의 실행 방식과 오류 처리 방식에 따라 다릅니다.
예:
이러한 문이 Snowflake Scripting 언어로 작성된 저장 프로시저 내부에 있는 경우 실패한 INSERT 문에서 예외가 발생합니다.
예외가 처리되지 않으면 저장 프로시저가 결코 완료되지 않고 COMMIT이 결코 실행되지 않으므로, 열린 트랜잭션이 암시적으로 롤백됩니다. 그 경우에는 테이블에 값
1또는2가 없습니다.저장 프로시저가 예외를 처리하고 실패한 INSERT 문 이전의 문을 커밋하지만, 실패한 INSERT 문 이후의 문을 실행하지 않을 경우에는 값이
1인 행만 테이블에 저장됩니다.
이러한 문이 저장 프로시저 내부에 없을 경우 동작이 문의 실행 방식에 따라 결정됩니다. 예:
Snowsight 를 통해 문이 실행되면 첫 번째 오류 발생 시 실행이 중지됩니다.
-f(파일 이름) 옵션을 사용하여 SnowSQL에서 문이 실행되면 첫 번째 오류 발생 시 실행이 중지되지 않고 오류 발생 이후의 문이 실행됩니다.
트랜잭션과 다중 스레딩¶
여러 세션이 같은 트랜잭션을 공유할 수는 없지만, 단일 연결을 사용하는 여러 스레드 가 같은 세션을 공유하므로 같은 트랜잭션을 공유합니다. 이 동작은 한 스레드가 다른 스레드에서 수행된 작업을 롤백하는 것과 같은 예기치 않은 결과로 이어질 수 있습니다.
이런 상황은 Snowflake 드라이버(예: Snowflake JDBC 드라이버) 또는 커넥터(예: Snowflake Connector for Python)를 사용하는 클라이언트 애플리케이션이 다중 스레드로 처리될 때 발생할 수 있습니다. 둘 이상의 스레드가 같은 연결을 공유하는 경우 해당 스레드가 그 연결에서 현재 트랜잭션 역시 공유합니다. 한 스레드에 의한 BEGIN TRANSACTION, COMMIT 또는 ROLLBACK은 그러한 공유 연결을 사용하는 모든 스레드에 영향을 줍니다. 스레드가 비동기로 실행 중인 경우 결과를 예측할 수 없습니다.
마찬가지로, 한 스레드의 AUTOCOMMIT 설정을 변경하면 같은 연결을 사용하는 다른 모든 스레드의 AUTOCOMMIT 설정에 영향을 줍니다.
Snowflake에서는 다중 스레드 클라이언트 프로그램이 다음 중 한 가지 이상을 수행하도록 할 것을 권장합니다.
각 스레드에 대해 별도의 연결 사용.
별도의 연결을 사용하더라도 코드가 여전히 예측할 수 없는 출력을 생성하는 경합 상태에 직면할 수 있습니다. 예를 들어, 한 스레드가 데이터를 삭제한 후 다른 스레드가 그 데이터의 업데이트를 시도할 수 있습니다.
스레드를 비동기가 아니라 동기로 실행하여 단계 수행 순서 제어.
저장 프로시저와 트랜잭션¶
일반적으로, 이전 섹션에서 설명한 규칙은 저장 프로시저에도 적용됩니다. 이 섹션에서는 저장 프로시저에 특정한 추가 정보를 제공합니다.
트랜잭션이 저장 프로시저 내부에 있거나 저장 프로시저가 트랜잭션 내부에 있을 수 있지만, 트랜잭션이 일부는 저장 프로시저 내부에 있고 일부는 외부에 있거나, 한 저장 프로시저에서 시작되고 다른 저장 프로시저에서 완료될 수는 없습니다.
예:
저장 프로시저를 호출하기 전에 트랜잭션을 시작한 다음, 저장 프로시저 내에서 트랜잭션을 완료할 수 없습니다. 이렇게 하려고 하면 Snowflake가 다음과 같은 오류를 보고합니다.
저장 프로시저 내에서 트랜잭션을 시작한 다음, 프로시저에서 반환 후 트랜잭션을 완료할 수 없습니다. 트랜잭션이 저장 프로시저 내에서 시작되고 저장 프로시저 완료 시에도 계속 활성 상태인 경우에는 오류가 발생하고 트랜잭션이 롤백됩니다.
이러한 규칙은 중첩 저장 프로시저에도 적용됩니다. 프로시저 A 가 프로시저 B 를 호출하는 경우 프로시저 B 는 프로시저 A 에서 시작된 트랜잭션을 완료할 수 없으며 그 반대의 경우도 마찬가지입니다. A 의 각 BEGIN TRANSACTION은 A 에 그에 상응하는 COMMIT(또는 ROLLBACK)이 있어야 하고, B 의 각 BEGIN TRANSACTION은 B 에 그에 상응하는 COMMIT(또는 ROLLBACK)이 있어야 합니다.
저장 프로시저가 명시적 트랜잭션을 포함하는 경우 그 트랜잭션은 저장 프로시저 본문의 일부 또는 전부를 포함할 수 있습니다. 예를 들어, 다음 저장 프로시저에서는 문 중 일부만 명시적 트랜잭션 내부에 있습니다. (이 예와 그 뒤를 잇는 여러 예에서는 단순성을 기하기 위해 의사 코드를 사용합니다.)
겹치지 않는 트랜잭션¶
아래 섹션에서는 다음 내용을 설명합니다.
트랜잭션 내에서 저장 프로시저 사용하기.
저장 프로시저 내에서 트랜잭션 사용하기.
트랜잭션 내에서 저장 프로시저 사용하기¶
가장 간단한 사례에서, 저장 프로시저는 다음 조건이 충족되는 경우 트랜잭션 내부에 있는 것으로 간주됩니다.
저장 프로시저가 호출되기 전에 BEGIN TRANSACTION이 실행됩니다.
저장 프로시저가 완료된 후 해당 COMMIT (또는 ROLLBACK)이 실행됩니다.
저장 프로시저의 본문은 명시적이거나 암시적인 BEGIN TRANSACTION 또는 COMMIT(또는 ROLLBACK)을 포함하지 않습니다.
트랜잭션 내부의 저장 프로시저는 자신을 둘러싸는 트랜잭션의 규칙을 따릅니다.
트랜잭션이 커밋되면 프로시저 내의 모든 문이 커밋됩니다.
트랜잭션이 롤백되면 프로시저 내의 모든 문이 롤백됩니다.
다음 의사 코드는 명시적 트랜잭션 내에서 전적으로 호출되는 저장 프로시저를 보여줍니다.
이것은 다음 문 시퀀스를 실행하는 것과 같습니다.
저장 프로시저에서 트랜잭션 사용하기¶
저장 프로시저 내에서 0개, 1개 또는 그 이상의 트랜잭션을 실행할 수 있습니다. 다음 의사 코드는 한 저장 프로시저에 있는 두 트랜잭션의 예를 보여줍니다.
저장 프로시저는 여기에 나타낸 것처럼 호출할 수 있습니다.
이것은 다음 시퀀스를 실행하는 것과 같습니다.
이 코드에서는 네 개의 트랜잭션이 따로 실행됩니다. 각 트랜잭션은 프로시저 외부에서 시작되고 완료되거나 프로시저 내부에서 시작되고 완료됩니다. 일부는 저장 프로시저 내부에, 일부는 저장 프로시저 외부에서 프로시저 경계를 가로질러 트랜잭션이 분할되지 않습니다. 어떤 트랜잭션도 다른 트랜잭션에 중첩되지 않습니다.
범위 지정 트랜잭션¶
트랜잭션을 포함하는 저장 프로시저 는 다른 트랜잭션 내에서 호출할 수 있습니다. 예를 들어, 저장 프로시저 내부의 트랜잭션은 트랜잭션을 포함하는 또 다른 저장 프로시저에 대한 호출을 포함할 수 있습니다.
Snowflake는 내부 트랜잭션을 중첩된 것으로 취급하지 않으며, 대신 내부 트랜잭션은 별개의 트랜잭션 입니다. Snowflake는 이러한 “자율 범위 지정 트랜잭션”(또는 간단히 “범위 지정 트랜잭션”)을 호출합니다.
각 범위 지정 트랜잭션의 시작점과 종료점에 따라 트랜잭션에 포함되는 문이 결정됩니다. 시작과 끝은 명시적이거나 암시적일 수 있습니다. 각 SQL 문은 단 하나의 트랜잭션 중 일부입니다. 둘러싸는 ROLLBACK 또는 COMMIT은 포함된 COMMIT 또는 ROLLBACK을 실행 취소하지 않습니다.
참고
“내부” 및 “외부”라는 용어는 중첩된 저장 프로시저 호출과 같은 중첩된 작업을 설명할 때 흔히 사용됩니다. 하지만 Snowflake의 트랜잭션은 실제로 “중첩”되지 않으므로, 이 문서에서는 혼동을 줄이기 위해 트랜잭션이라고 지칭할 때 “내부”와 “외부”라는 말 대신 “포함된”과 “둘러싸는”이라는 용어를 자주 사용합니다.
아래 다이어그램에는 두 개의 저장 프로시저와 두 개의 범위 지정 트랜잭션이 표시되어 있습니다. 이 예에서 각 저장 프로시저는 자체 독립 트랜잭션을 포함합니다. 첫 번째 저장 프로시저는 두 번째 저장 프로시저를 호출하므로 프로시저는 시간상으로는 겹치지만, 내용상으로는 겹치지 않습니다. 음영 처리된 내부 상자 안의 모든 문은 한 트랜잭션에 있습니다. 다른 모든 문은 또 다른 트랜잭션에 있습니다.
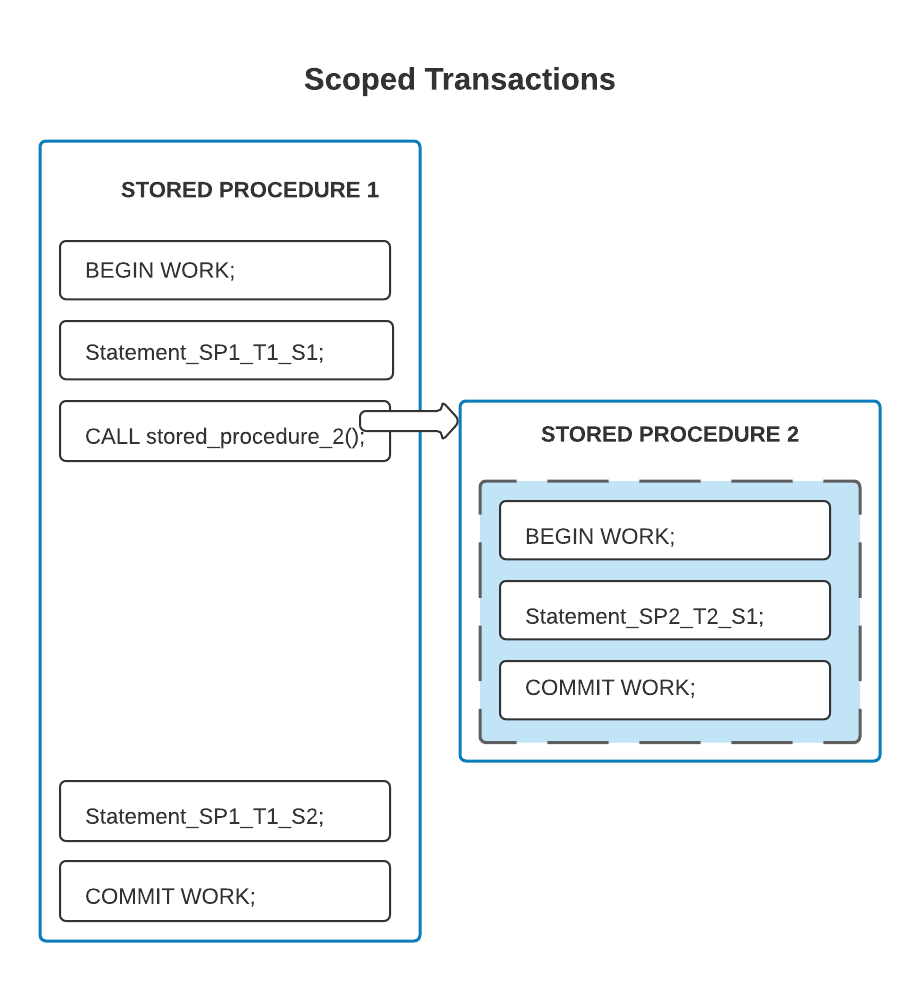
다음 예에서 트랜잭션 경계는 저장 프로시저 경계와 다릅니다. 즉, 둘러싸는 저장 프로시저에서 시작하는 트랜잭션은 둘러싸인 저장 프로시저의 일부 문을 포함하되, 모든 문을 포함하는 것은 아닙니다.
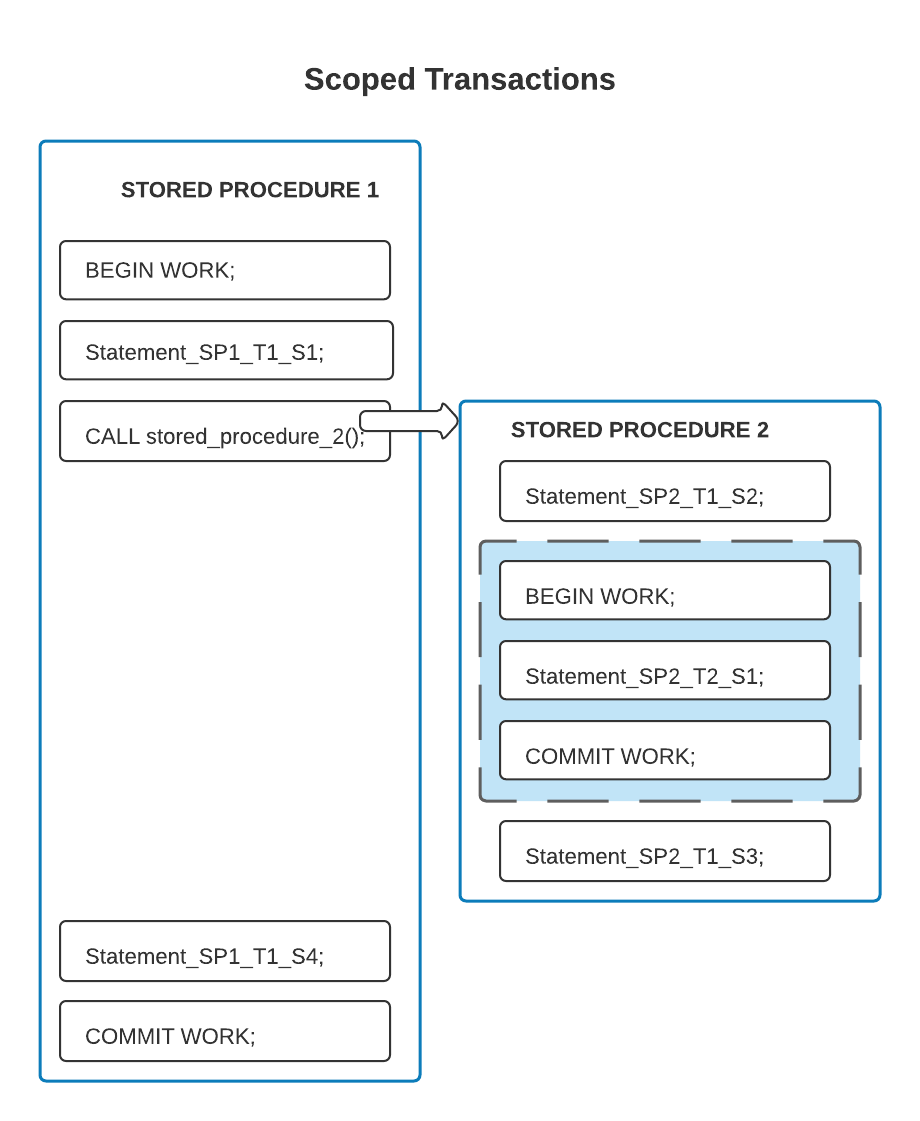
위의 코드에서 두 번째 저장 프로시저는 첫 번째 트랜잭션의 범위에 있는 일부 문(SP2_T1_S2 및 SP2_T1_S3)을 포함합니다. 음영 처리된 내부 상자 안에 있는 문 SP2_T2_S1 만 두 번째 트랜잭션의 범위에 있습니다.
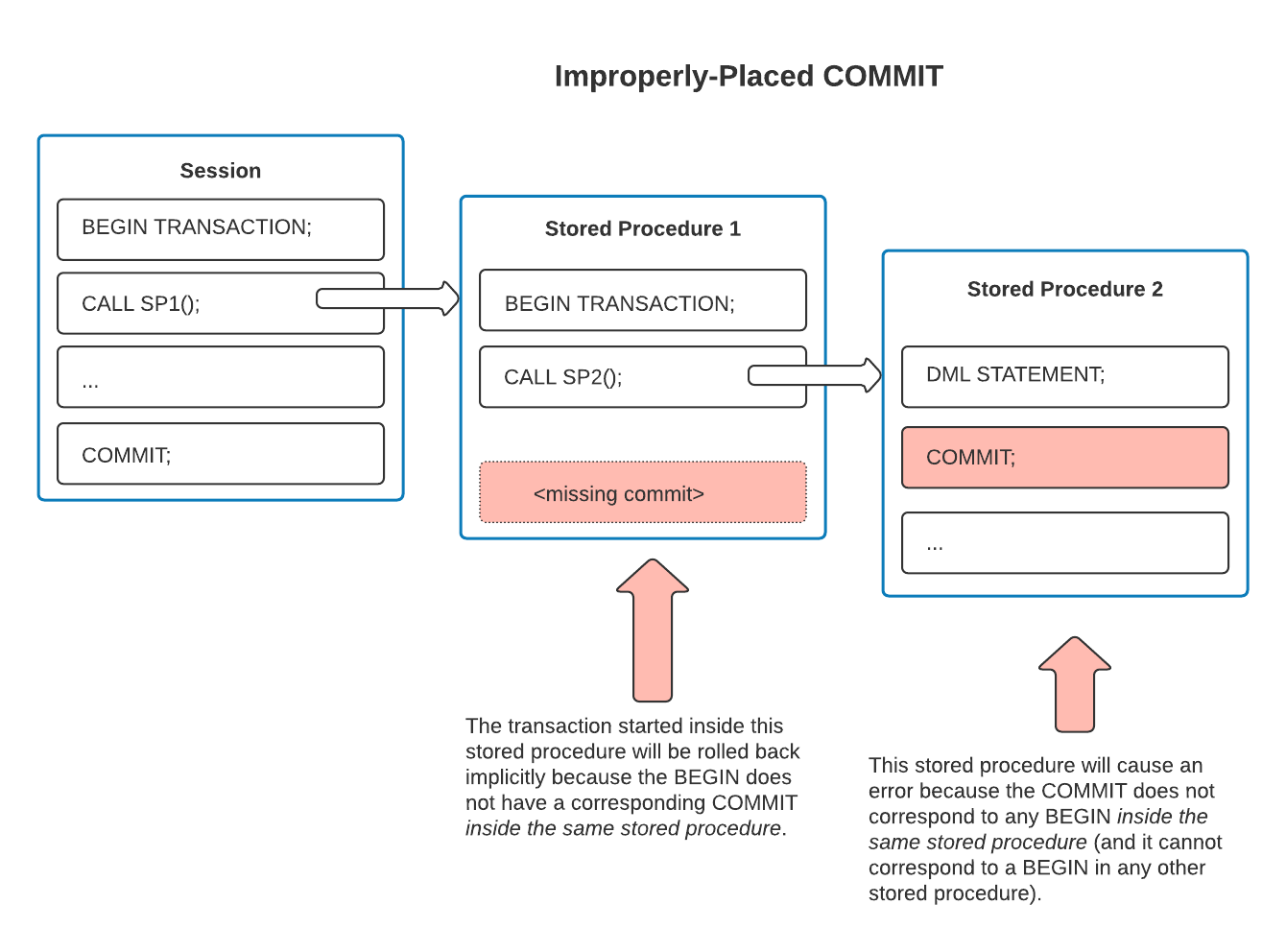
다음 예에서는 트랜잭션이 같은 저장 프로시저 내에서 시작되고 끝나지 않을 경우 발생하는 문제를 보여줍니다. 이 예에는 BEGIN 문과 같은 수의 COMMIT 문이 있습니다. 하지만 BEGIN 문과 COMMIT 문은 올바른 쌍이 아니므로, 이 예에는 다음의 두 가지 오류가 있습니다.
둘러싸는 저장 프로시저는 범위 지정 트랜잭션을 시작하지만 명시적으로 완료하지는 않습니다. 따라서 범위 지정 트랜잭션은 그 저장 프로시저의 끝에서 오류를 일으키고 활성 트랜잭션이 암시적으로 롤백됩니다.
두 번째 저장 프로시저는 COMMIT 을 포함하지만, 그 저장 프로시저에는 대응하는 BEGIN 이 없습니다. 이 COMMIT은 첫 번째 저장 프로시저에서 시작된 미해결 트랜잭션을 커밋하지 않습니다. 대신에, 잘못 쌍을 이룬 COMMIT 은 오류의 원인이 됩니다.
다음 예에서는 시간이 겹치는 세 개의 범위 지정 트랜잭션을 보여줍니다. 이 예에서는 저장 프로시저 p1() 이 트랜잭션 내부에서 다른 저장 프로시저 p2() 를 호출하고 p2() 는 자체 트랜잭션을 포함하므로, p2() 에서 시작된 트랜잭션도 독립적으로 실행됩니다. (이 예에서는 의사 코드를 사용합니다.)
이 세 가지 범위 지정 트랜잭션에서는 다음 사항이 적용됩니다.
저장 프로시저 외부의 트랜잭션은
A및E문을 포함합니다.저장 프로시저
p1()의 트랜잭션은 문B및D를 포함합니다.p2()의 트랜잭션은 문C를 포함합니다.
범위 지정 트랜잭션에 대한 규칙은 재귀 저장 프로시저 호출에도 적용됩니다. 재귀 호출은 특정 유형의 중첩 호출일 뿐이며, 중첩 호출과 동일한 트랜잭션 규칙을 따릅니다.
조심
겹치는 범위 지정 트랜잭션이 같은 데이터베이스 오브젝트(예: 테이블)를 조작하는 경우 교착 상태 가 발생할 수 있습니다. 범위 지정 트랜잭션은 필요할 때만 사용해야 합니다.
저장 프로시저 내부의 트랜잭션에 대한 암시적 커밋¶
대부분의 DDL 문을 포함한 일부 명령은 모든 활성 트랜잭션을 암시적으로 커밋합니다. 외부 저장 프로시저가 트랜잭션을 열고 내부 저장 프로시저가 이러한 명령을 실행하는 경우 이 명령은 다음 오류 메시지를 반환합니다.
예를 들어, 내부 프로시저의 DROP TAG 문은 외부 프로시저에서 시작된 트랜잭션을 암시적으로 커밋하려고 시도하므로 다음 코드는 실패합니다.
이 오류를 방지하려면 다른 범위에서 시작된 활성 트랜잭션 내에서 호출될 수 있는 저장 프로시저 내의 DDL 문(또는 트랜잭션을 암시적으로 커밋하는 다른 명령)을 실행하지 마십시오.
저장 프로시저 종료 시 트랜잭션에 대한 암시적 ROLLBACK¶
AUTOCOMMIT이 비활성화되어 있을 때는 암시적 트랜잭션과 저장 프로시저의 결합에 특히 주의하십시오. 저장 프로시저 끝에서 실수로 트랜잭션을 활성 상태로 두면 트랜잭션이 롤백됩니다.
예를 들어, 다음 의사 코드 예에서는 저장 프로시저 끝에서 암시적 ROLLBACK 이 발생합니다.
이 예에서 AUTOCOMMIT을 설정하는 명령은 모든 활성 트랜잭션을 커밋합니다. 새 트랜잭션이 즉시 시작되지 않습니다. 이 저장 프로시저는 새 트랜잭션을 암시적으로 시작하는 DML 문을 포함합니다. 해당 암시적 BEGIN TRANSACTION은 저장 프로시저에 일치하는 COMMIT 또는 ROLLBACK이 없습니다. 저장 프로시저 끝에 활성 트랜잭션이 있으므로 해당 활성 트랜잭션이 암시적으로 롤백됩니다.
단일 트랜잭션에서 전체 저장 프로시저를 실행하려면 트랜잭션을 시작한 후 저장 프로시저를 호출하고, 호출 후에 트랜잭션을 커밋합니다.
이 경우, BEGIN 과 COMMIT 이 올바로 쌍을 이루고 코드가 오류 없이 실행됩니다.
대안으로서, 다음 의사 코드 예에서 볼 수 있듯이 BEGIN TRANSACTION과 COMMIT을 둘 다 저장 프로시저 내부에 넣습니다.
범위 지정 트랜잭션에서 잘못 페어링된 BEGIN/COMMIT 블록¶
범위 지정 트랜잭션에서 BEGIN/COMMIT 블록이 올바른 쌍을 이루지 않으면 Snowflake에서 오류를 보고합니다. 그 오류는 저장 프로시저가 완료되지 않도록 방지하거나 둘러싸는 트랜잭션이 커밋되지 않도록 방지하는 것과 같은 추가적인 영향을 미칠 수 있습니다. 예를 들어, 다음 의사 코드 예에서는 포함된 저장 프로시저뿐 아니라 둘러싸는 저장 프로시저의 문도 롤백됩니다.
이 예에서 삽입되는 유일한 값은 osp1_alpha 입니다. COMMIT이 BEGIN과 올바르게 쌍을 이루지 않으므로 다른 값은 어떤 것도 삽입되지 않습니다. 오류는 다음과 같이 처리됩니다.
프로시저
inner_sp2()가 완료되면 Snowflake가inner_sp2()의 BEGIN에 그에 해당하는 COMMIT(또는 ROLLBACK)이 없음을 감지합니다.Snowflake는
inner_sp2()에서 시작한 범위 지정 트랜잭션을 암시적으로 롤백합니다.inner_sp2()에 대한 CALL이 실패했으므로 Snowflake 역시 오류를 반환합니다.
inner_sp2()에 대한 CALL이 실패하고 CALL 문이outer_sp1()에 있었으므로, 저장 프로시저outer_sp1()자체도 실패해 계속하지 않고 오류를 반환합니다.outer_sp1()이 실행을 완료하지 않으므로 다음 사항이 적용됩니다.값
osp1_delta및osp1_omega에 대한 INSERT 문은 결코 실행되지 않습니다.outer_sp1()에서 열린 트랜잭션은 커밋되지 않고 암시적으로 롤백되므로,osp1_beta값의 삽입은 커밋되지 않습니다.
Apache Iceberg™ 테이블과 트랜잭션¶
Snowflake 트랜잭션 원칙은 일반적으로 Apache Iceberg™ 테이블에 적용됩니다. Iceberg 테이블에만 해당하는 트랜잭션에 대한 자세한 내용은 트랜잭션에 관한 Iceberg 항목 을 참조하십시오.
READ COMMITTED 격리 수준¶
READ COMMITTED는 테이블에 대해 현재 유일하게 지원되는 격리 수준입니다. 문에서 READ COMMITTED 격리를 사용할 경우 문이 시작되기 전에 커밋된 데이터만 보게 됩니다. 커밋되지 않은 데이터는 절대 보지 못합니다.
다중 문 트랜잭션 내에서 문이 실행될 때 다음 사항이 적용됩니다.
문에서는 문 이 시작되기 전에 커밋된 데이터만 봅니다. 같은 트랜잭션에 있는 두 개의 연속적인 문의 경우, 첫 번째 문과 두 번째 문이 실행되는 사이에 다른 트랜잭션이 커밋되면 서로 다른 데이터를 볼 수 있습니다.
문은 같은 트랜잭션 내에서 실행된 이전 문의 변경 사항이 아직 커밋되지 않았더라도 이러한 변경 사항을 봅니다.
세션 간 읽기 일관성¶
일반적으로 Snowflake는 DDL 및 DML 작업에 의해 도입된 변경 사항과 같이 주어진 세션 내에서 발생하는 모든 변경 사항에 대해 읽기 일관성을 유지합니다. 사용자가 새 세션을 시작하면 세션이 시작되기 전에 커밋된 모든 변경 사항과 세션 내에서 커밋된 모든 변경 사항이 해당 세션의 후속 쿼리에 즉시 표시됩니다. 이는 표준 동작이며 대부분의 워크로드에 대한 요구 사항과 일치합니다.
거의 동시적인 방식으로 쿼리를 실행하고 쿼리를 실행하는 **세션 전체**에서 읽기 일관성의 확장을 보장하기를 원하고 응답 시간에서 약간의 지연(보통 밀리초)을 감당할 수 있다면 READ_CONSISTENCY_MODE 매개 변수를 :code:`’GLOBAL’`로 설정합니다. 이 매개 변수를 설정하면 쿼리가 동시에 실행 중인 세션에서 발생하는 거의 동시 변경 사항을 읽도록 기본 동작을 변경할 수 있습니다. 이러한 수준의 일관성을 보장하는 다른 방법은 모든 쿼리를 동일한 세션에서 실행하는 것입니다.
예를 들어, 기본 'SESSION' 값을 사용합니다.
세션 1이 시작됩니다.
세션 2가 시작됩니다.
세션 1이 테이블 ``t``에 행을 삽입합니다.
세션 1이 테이블 ``t``에서 데이터를 선택하고 새 행을 즉시 확인합니다.
세션 2는 동일한 쿼리를 실행합니다. 세션 2에는 새 행이 표시되지 않을 수 있습니다.
이 시나리오에서 세션 1과 세션 2가 동일한 쿼리에 대해 동일한 결과를 얻도록 하려면 다음 세 단계 중 하나를 따릅니다. 가장 권장되는 단계부터 가장 적게 권장되는 단계까지 순서대로 나와 있습니다.
서로 종속된 모든 쿼리에 대해 단일 세션을 사용합니다. 이 경우:
세션 1에서 변경 사항이 커밋된 후 세션 2를 시작합니다. 이 경우:
ALTER ACCOUNT 명령을 사용하여 READ_CONSISTENCY_MODE를 :code:`’GLOBAL’`로 설정합니다.
이 매개 변수는 ACCOUNTADMIN 권한이 있는 사용자만 계정 수준에서 설정할 수 있습니다.
리소스 잠금¶
트랜잭션 작업은 테이블과 같은 리소스가 수정되는 동안 그 리소스에 대한 잠금을 획득합니다. 잠금은 잠금이 해제될 때까지 다른 문이 리소스를 수정하지 못하게 차단합니다.
대부분의 상황에서 다음 지침이 적용됩니다.
(AUTOCOMMIT과 명시적 COMMIT을 모두 포함하여) COMMIT 작업은 리소스를 잠그지만, 보통은 잠깐만 잠급니다.
CREATE TABLE, CREATE DYNAMIC TABLE, CREATE STREAM 및 ALTER TABLE 작업은 모두 CHANGE_TRACKING = TRUE를 설정할 때 기본 리소스를 잠그지만 보통은 잠시만 잠급니다. 테이블이 잠겨 있으면 UPDATE 및 DELETE DML 작업만 차단됩니다. INSERT 작업이 차단되지 않습니다.
UPDATE, DELETE, MERGE 문은 일반적으로 다른 UPDATE, DELETE, MERGE 문과 병렬로 실행되지 못하게 하는 잠금을 보유합니다.
하이브리드 테이블 의 경우 개별 행에 대해 잠금이 유지됩니다. UPDATE, DELETE, MERGE 문에 대한 잠금은 같은 행에서 작동하는 병렬 UPDATE, DELETE, MERGE 문만 방지합니다. 동일한 테이블의 다른 행에서는 UPDATE, DELETE, MERGE가 진행될 수 있습니다.
INSERT 및 COPY 문은 대부분 새 파티션만 씁니다. 이러한 문은 종종 다른 INSERT 및 COPY 작업과 병렬로 실행될 수 있으며, 때로는 UPDATE, DELETE 또는 MERGE 문과 병렬로 실행될 수 있습니다.
서로 다른 세션에서 동일한 오브젝트에 대해 INSERT 및 COPY 문과 DDL 문을 동시에 실행하면 불일치가 발생할 수 있으므로 피하십시오. 명시적 트랜잭션 의 오브젝트에서 INSERT 또는 COPY 문이 실행되는 경우 트랜잭션 기간 동안 다른 세션에서 동일한 오브젝트에 DDL 문이 실행되지 않도록 하십시오. 예를 들어, 한 세션의 테이블에서 INSERT 문을 실행하면서 다른 세션에서 테이블의 열 데이터 타입을 변경하는 DDL 문을 동시에 실행하지 마십시오.
문이 보유한 잠금은 트랜잭션의 COMMIT 또는 ROLLBACK 에서 해제됩니다.
잠금 시간 제한 매개 변수¶
LOCK_TIMEOUT 과 HYBRID_TABLE_LOCK_TIMEOUT 의 두 매개 변수가 잠금 시간 제한을 제어합니다.
LOCK_TIMEOUT 매개 변수¶
차단된 문은 기다리고 있던 리소스에 대한 잠금을 획득하거나 리소스를 사용할 있을 때까지 기다리는 동안 시간이 초과됩니다. LOCK_TIMEOUT 매개 변수를 설정하여 문이 차단되는 시간(초)을 설정할 수 있습니다.
예를 들어, 현재 세션의 잠금 시간 제한을 2시간(7,200초)으로 변경하는 방법은 다음과 같습니다.
HYBRID_TABLE_LOCK_TIMEOUT 매개 변수¶
하이브리드 테이블에서 차단된 문은 기다리고 있는 테이블에서 행 수준 잠금을 획득하거나 테이블이 사용 가능해질 때까지 기다리는 동안 시간이 초과됩니다. HYBRID_TABLE_LOCK_TIMEOUT 매개 변수를 설정하여 문이 차단되는 시간(초)을 설정할 수 있습니다.
예를 들어, 현재 세션의 하이브리드 테이블 잠금 시간 제한을 10분(600초)으로 변경하는 방법은 다음과 같습니다.
교착 상태¶
교착 상태는 동시 트랜잭션이 서로에 의해 잠긴 리소스를 기다리고 있을 때 발생할 수 있습니다.
다음 규칙을 참고하십시오.
자동 커밋 쿼리 문이 동시에 실행되는 동안에는 교착 상태가 발생할 수 없습니다. 이는 표준 테이블과 하이브리드 테이블 모두에 해당하는데, SELECT 문은 항상 읽기 전용이기 때문입니다.
표준 테이블에서는 자동 커밋 DML 작업으로 인해 교착 상태가 발생할 수 없지만, 하이브리드 테이블에서는 자동 커밋 DML 작업으로 인해 교착 상태가 발생할 수 있습니다.
트랜잭션이 명시적으로 시작되고 각 트랜잭션에서 여러 개의 문이 실행되는 경우 교착 상태가 발생할 수 있습니다. Snowflake는 교착 상태를 감지하고 교착 상태의 일부인 가장 최근 문을 희생하는 선택을 합니다. 이 문은 롤백되지만, 트랜잭션 자체는 활성 상태로 유지되므로 이를 커밋하거나 롤백해야 합니다.
교착 상태 감지에 시간이 걸릴 수 있습니다.
트랜잭션 및 잠금 관리하기¶
Snowflake는 트랜잭션과 잠금을 모니터링하고 관리하는 데 도움이 되는 다음 SQL 명령을 제공합니다.
LOCK_WAIT_HISTORY 뷰 는 잠금과 관련된 트랜잭션의 자세한 기록을 로그에 남겨 특정 잠금이 요청되고 획득된 시기를 보여줍니다.
또한, Snowflake는 세션 내 트랜잭션에 대한 정보를 얻기 위해 다음과 같은 컨텍스트 함수를 제공합니다.
SYSTEM$ABORT_TRANSACTION 함수를 호출하여 트랜잭션을 중단할 수 있습니다.
트랜잭션 중단하기¶
트랜잭션이 세션에서 실행 중이고 세션 연결이 갑자기 끊어져 트랜잭션의 커밋 또는 롤백을 막는 경우, 이 트랜잭션이 리소스에 대해 보유하고 있는 잠금을 비롯해 트랜잭션이 분리된 상태로 남습니다. 이런 일이 일어나는 경우 트랜잭션을 중단해야 할 수 있습니다.
실행 중인 트랜잭션을 중단하려면 트랜잭션을 시작한 사용자나 계정 관리자가 시스템 함수 SYSTEM$ABORT_TRANSACTION 을 호출할 수 있습니다.
사용자가 트랜잭션을 중단하지 않는 경우 다음 사항이 적용됩니다.
이 트랜잭션이 다른 트랜잭션에서 동일한 테이블을 잠그지 못하도록 차단하고 이와 동시에 5분 동안 유휴 상태인 경우, 트랜잭션은 자동으로 중단되어 롤백됩니다.
이 트랜잭션이 다른 트랜잭션에서 같은 테이블을 수정하지 못하게 차단하지 않고 4시간 이상 경과하면 자동으로 중단되고 롤백됩니다.
이 트랜잭션이 하이브리드 테이블에서 읽거나 테이블에 쓰고 5분 동안 유휴 상태가 되면 다른 트랜잭션이 같은 테이블을 수정하지 못하게 차단하는지 여부에 관계없이 자동으로 중단되고 롤백됩니다.
트랜잭션 내의 문 오류가 트랜잭션을 중단하도록 허용하려면 세션 또는 계정 수준에서 TRANSACTION_ABORT_ON_ERROR 매개 변수를 설정하십시오.
LOCK_WAIT_HISTORY 뷰로 차단된 트랜잭션 분석하기¶
LOCK_WAIT_HISTORY 뷰 는 차단된 트랜잭션 분석에 유용하게 쓰일 수 있는 트랜잭션 세부 정보를 반환합니다. 출력의 각 행에는 잠금을 기다리는 트랜잭션에 대한 세부 정보와 해당 잠금을 보유하고 있거나 해당 잠금을 앞서 기다리고 있던 트랜잭션의 세부 정보가 포함됩니다.
예를 들어 아래 시나리오를 참조하십시오.
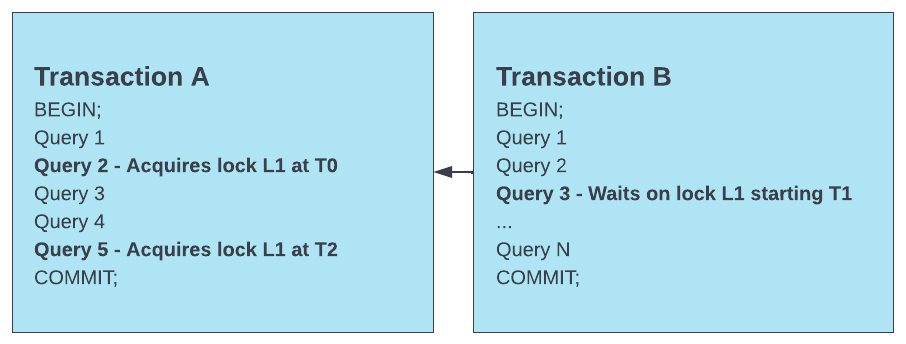
이 시나리오에서는 다음 데이터가 반환됩니다.
트랜잭션 B는 잠금을 기다리고 있는 트랜잭션입니다.
트랜잭션 B가 타임스탬프 T1에서 잠금을 요청했습니다.
트랜잭션 A는 잠금을 보유한 트랜잭션입니다.
트랜잭션 A의 쿼리 2는 차단 쿼리입니다.
쿼리 2는 트랜잭션 B(잠금을 기다리는 트랜잭션)가 기다리기 시작한 트랜잭션 A(잠금을 보유한 트랜잭션)의 첫 번째 문이므로 차단 쿼리입니다.
하지만 트랜잭션 A에서 이후의 쿼리(쿼리 5)도 잠금을 획득했습니다. 이러한 트랜잭션의 후속 동시 실행으로 인해 트랜잭션 A에서 잠금을 획득하는 다른 쿼리에서 트랜잭션 B가 차단될 수 있습니다. 따라서 첫 번째 차단 트랜잭션의 모든 쿼리를 조사해야 합니다.
하이브리드 테이블에 대한 트랜잭션 및 잠금 가시성 도 참조하십시오.
장시간 실행 중인 문 검사하기¶
지난 24시간 동안 잠금을 기다린 트랜잭션에 대한 Account Usage QUERY_HISTORY 뷰 를 쿼리합니다.
쿼리 결과를 검토하고 높은 TRANSACTION_BLOCKED_TIME 값을 가진 쿼리의 ID를 기록합니다.
이전 단계에서 식별된 쿼리에 대한 차단 트랜잭션을 찾으려면 해당 쿼리 ID를 가진 행에 대해 LOCK_WAIT_HISTORY 뷰를 쿼리하십시오.
결과의
blocker_queries열에 여러 쿼리가 있을 수 있습니다. 출력에서 각 블로커 쿼리의transaction_id에 유의하십시오.blocker_queries출력에서 각 트랜잭션의 QUERY_HISTORY 뷰를 쿼리합니다.쿼리 결과를 조사합니다. 트랜잭션의 문이 DML 문이고 잠긴 리소스에서 작동되는 경우 트랜잭션 중 어느 시점에서 잠금을 획득했을 수 있습니다.
트랜잭션 및 잠금 모니터링하기¶
SHOW TRANSACTIONS 명령을 사용하면 (현재 사용자의 모든 세션에서) 현재 사용자 또는 계정의 모든 세션에서 모든 사용자가 실행 중인 트랜잭션의 목록을 반환할 수 있습니다. 다음 예는 현재 사용자의 세션에 대한 것입니다.
모든 Snowflake 트랜잭션에는 고유한 트랜잭션 ID가 할당됩니다. id 값은 부호 있는 64비트(long) 정수입니다. 값의 범위는 -9,223,372,036,854,775,808(-2 63)~9,223,372,036,854,775,807(2 63 - 1)입니다.
CURRENT_TRANSACTION 함수를 사용하여 세션에서 현재 실행 중인 트랜잭션의 트랜잭션 ID를 반환할 수도 있습니다.
모니터링하려는 트랜잭션 ID를 알고 있는 경우 DESCRIBE TRANSACTION 명령을 사용하여 트랜잭션이 계속 실행 중이거나 커밋 또는 중단된 후에도 트랜잭션에 대한 세부 정보를 반환할 수 있습니다. 예:
하이브리드 테이블에 대한 트랜잭션 및 잠금 가시성¶
하이브리드 테이블에 액세스하거나 하이브리드 테이블 행에 대한 잠금을 수행하는 트랜잭션에 대한 명령 및 뷰의 출력을 확인할 때 다음 동작에 주의하십시오.
트랜잭션은 다른 트랜잭션을 차단하고 있거나 차단된 경우에만 나열됩니다.
하이브리드 테이블에 액세스하는 트랜잭션은 행 수준 잠금(
ROW타입)을 유지한다는 점에 유의하십시오. 두 트랜잭션이 동일한 테이블의 서로 다른 행에 액세스하는 경우 서로를 차단하지 않습니다.차단된 트랜잭션이 5초 이상 차단된 경우에만 트랜잭션이 나열됩니다.
트랜잭션이 더 이상 차단되지 않으면 출력에 계속 나타날 수 있지만 15초를 넘지는 않습니다.
마찬가지로, SHOW LOCKS 출력에서는 다음 규칙이 적용됩니다.
잠금은 한 트랜잭션이 잠금을 유지하는 상태이고 다른 트랜잭션이 해당 잠금에 대해 차단된 경우에만 나열됩니다.
type열에는 하이브리드 테이블 잠금이ROW를 표시합니다.resource열에는 항상 차단 중인 트랜잭션 ID가 표시됩니다. (차단된 트랜잭션은 이 ID를 가진 트랜잭션에 의해 차단됩니다.)많은 경우, 하이브리드 테이블에 대한 쿼리는 쿼리 ID를 생성하지 않습니다. 사용법 노트 섹션을 참조하십시오.
예:
LOCK_WAIT_HISTORY 뷰 에서 출력은 다음과 같이 동작합니다.
requested_at및acquired_at열은 하이브리드 테이블에서 트랜잭션 활동을 보고하기 위한 일반 규칙에 따라 행 수준 잠금이 요청되고 획득된 시점을 정의합니다.lock_type및object_name열은 모두Row값을 보여줍니다.schema_id및schema_name열은 항상 비어 있습니다(각각0과 NULL).object_id열에는 항상 차단 중인 오브젝트 ID가 표시됩니다.blocker_queries열은 정확히 하나의 요소를 가진 JSON 배열로, 차단 중인 트랜잭션을 보여줍니다.동일한 행에서 여러 트랜잭션이 차단된 경우에도 출력에서는 여러 행으로 표시됩니다.
예:
모범 사례¶
트랜잭션은 관련된 문을 포함하고 함께 성공하거나 실패해야 합니다(예: 한 계좌에서 돈을 인출하고 같은 돈을 다른 계좌에 입금). 롤백이 발생하는 경우 지급인이나 수취인이 결국 돈을 받게 되며, 그 돈은 결코 “사라지지” 않습니다(한 계좌에서 인출되었지만 다른 계좌에 입금되지 않음).
일반적으로, 한 트랜잭션은 관련된 문만 포함해야 합니다. 문을 덜 세분화한다는 것은 트랜잭션이 롤백될 때 실제로는 롤백할 필요가 없었던 유용한 작업을 롤백할 수도 있다는 뜻입니다.
표준 테이블의 경우 더 큰 규모의 트랜잭션을 수행하면 때로는 성능이 향상될 수 있지만, 하이브리드 테이블에서는 그렇지 않은 경우가 많습니다.
이전의 글머리 기호 항목에서는 실제로 그룹으로 커밋하거나 롤백해야 하는 문만 그룹화하는 것이 중요하다고 강조했지만, 때로는 더 큰 트랜잭션이 유용할 수 있습니다. Snowflake에서는 대부분의 데이터베이스와 마찬가지로, 트랜잭션 관리에 리소스를 사용합니다. 예를 들어, 한 트랜잭션에 10개의 행을 삽입하는 것이 일반적으로 10개의 트랜잭션에 따로 각각 한 행을 삽입하는 것보다 빠르고 저렴합니다. 여러 문을 단일 트랜잭션으로 결합하면 성능을 개선할 수 있습니다.
지나치게 큰 트랜잭션은 병렬 처리를 줄이거나 교착 상태를 늘릴 수 있습니다. (이전 글머리 기호 항목에서 설명한 대로) 성능 향상을 위해 관련 없는 문을 그룹화하기로 한 경우, 트랜잭션이 리소스에 대한 잠금 을 획득할 수 있고, 이를 통해 다른 쿼리가 지연되거나 교착 상태 로 이어질 수 있습니다.
하이브리드 테이블의 경우:
일반적으로 AUTOCOMMIT DML 문은 AUTOCOMMIT DML 이 아닌 문보다 훨씬 더 빠르게 실행됩니다.
상대적으로 작은 AUTOCOMMIT DML 문은 AUTOCOMMIT DML 문이 아닌 문보다 훨씬 더 빠르게 실행됩니다.5초 이내에 실행되거나 1MB 이하의 데이터에 액세스하는 DML 문은 더 오래 실행되거나 더 큰 DML 문에서는 사용할 수 없는 고속 모드를 활용합니다.
Snowflake에서는 AUTOCOMMIT을 활성화된 상태로 유지하고 명시적 트랜잭션을 가능한 한 많이 사용할 것을 권장합니다. 명시적 트랜잭션을 사용하면 이를 읽는 사람이 트랜잭션의 시작 및 종료 위치를 더 쉽게 알 수 있습니다. 이것이 AUTOCOMMIT과 함께 결합되면, 예컨대 저장 프로시저의 끝에서처럼, 코드에서 의도하지 않은 롤백이 발생할 가능성이 감소합니다.
암시적으로 새 트랜잭션을 시작하려면 그냥 AUTOCOMMIT을 변경하지 마십시오. 대신에 새 트랜잭션이 시작되는 위치를 더 명확하게 하려면 BEGIN TRANSACTION을 사용하십시오.
한 행에서 둘 이상의 BEGIN TRANSACTION 문을 실행하지 마십시오. 추가 BEGIN TRANSACTION 문을 사용하면 트랜잭션의 실제 시작 위치를 알기 더 어려워지고, COMMIT/ROLLBACK 명령을 그에 대응되는 BEGIN TRANSACTION과 쌍을 이루기 더 어려워집니다.
예¶
범위 지정 트랜잭션과 저장 프로시저의 간단한 예¶
다음은 범위 지정 트랜잭션의 간단한 예입니다. 저장 프로시저는 값이 12인 행을 삽입한 다음 롤백하는 트랜잭션을 포함합니다. 외부 트랜잭션이 커밋합니다. 출력은 외부 트랜잭션의 범위에 있는 모든 행이 유지되는 반면, 내부 트랜잭션 범위의 행은 유지되지 않음을 보여줍니다.
저장 프로시저의 일부만 자체 트랜잭션 내부에 있으므로, 저장 프로시저에 있지만 저장 프로시저의 트랜잭션 외부에 있는 INSERT 문으로 삽입된 값이 유지됩니다.
다음 두 테이블을 만듭니다.
저장 프로시저를 만듭니다.
저장 프로시저를 호출합니다.
결과는 00, 11, 13, 09를 포함해야 합니다. ID = 12인 행을 포함하면 안 됩니다. 이 행은 롤백되어 포함된 트랜잭션의 범위에 있었습니다. 다른 모든 행은 외부 트랜잭션 범위에 있고 커밋되었습니다. 특히 IDs 11과 13이 있는 행은 저장 프로시저 내부, 하지만 가장 안쪽 트랜잭션 외부에 있었는데, 둘러싸는 트랜잭션의 범위에 있고 그 트랜잭션과 함께 커밋되었습니다.
트랜잭션의 성공과 독립적으로 정보 기록하기¶
다음은 범위 지정 트랜잭션을 사용하는 방법을 보여주는 간단하면서도 실용적인 예입니다. 이 예에서 트랜잭션은 특정 정보를 기록하며, 기록된 정보는 트랜잭션 자체의 성공 여부에 상관없이 보존됩니다. 시도한 각 작업의 성공 여부와 관계없이, 이 기법을 사용해 이러한 작업을 전부 추적할 수 있습니다.
다음 두 테이블을 만듭니다.
저장 프로시저를 만듭니다.
저장 프로시저를 호출합니다.
트랜잭션이 롤백되었으므로 데이터 테이블이 비어 있습니다.
하지만 로깅 테이블은 비어 있지 않습니다. 로깅 테이블로의 삽입은 data_table로의 삽입과는 별도의 트랜잭션에서 수행되었습니다.
범위 지정 트랜잭션과 저장 프로시저의 예¶
다음 몇 가지 예에서는 아래에 표시된 테이블과 저장 프로시저를 사용합니다. 적절한 매개 변수를 전달함으로써, 호출자는 저장 프로시저 내에서 BEGIN TRANSACTION, COMMIT, ROLLBACK 문이 실행되는 위치를 제어할 수 있습니다.
테이블 만들기:
이 프로시저는 둘러싸는 저장 프로시저로, 이 저장 프로시저로 전달된 매개 변수에 따라 둘러싸는 트랜잭션을 만들 수 있습니다.
이 프로시저는 내부 저장 프로시저로, 이 저장 프로시저로 전달된 매개 변수에 따라 포함된 트랜잭션을 만들 수 있습니다.
세 가지 수준의 중간 수준 커밋하기¶
다음 예에는 3개의 트랜잭션이 있습니다. 이 예에서는 “중간” 수준(가장 바깥쪽 트랜잭션이 둘러싸고 가장 안쪽 트랜잭션을 둘러싸는 트랜잭션)을 커밋합니다. 그러면 가장 바깥쪽 트랜잭션과 가장 안쪽 트랜잭션이 롤백됩니다.
그 결과, 중간 트랜잭션의 행만(12, 21, 23) 커밋됩니다. 외부 트랜잭션과 내부 트랜잭션의 행은 커밋되지 않습니다.
세 가지 수준의 중간 수준 롤백하기¶
다음 예에는 3개의 트랜잭션이 있습니다. 이 예에서는 “중간” 수준(가장 바깥쪽 트랜잭션이 둘러싸고 가장 안쪽 트랜잭션을 둘러싸는 트랜잭션)을 롤백합니다. 그러면 가장 바깥쪽 트랜잭션과 가장 안쪽 트랜잭션이 커밋됩니다.
그 결과, 중간 트랜잭션의 행(12, 21, 23)을 제외한 모든 행이 커밋됩니다.
저장 프로시저의 트랜잭션에 오류 처리 사용하기¶
다음 코드는 저장 프로시저의 트랜잭션에 대한 간단한 오류 처리를 보여줍니다. 매개 변수 값 ‘fail’이 전달되면 저장 프로시저가 존재하는 두 개의 테이블과 존재하지 않는 한 테이블에서 삭제를 시도하고, 저장 프로시저는 오류를 포착해 오류 메시지를 반환합니다. 매개 변수 값 ‘fail’이 전달되지 않으면 이 프로시저는 존재하는 두 테이블에서 삭제를 시도하고 성공합니다.
테이블과 저장 프로시저를 만듭니다.
저장 프로시저를 호출하고 오류를 강제로 발생시킵니다.
오류를 강제하지 않고 저장 프로시저를 호출합니다.