Openflow 정보¶
Snowflake Openflow는 정형 및 비정형 텍스트, 이미지, 오디오, 비디오, 센서 데이터를 지원하는 수백 개의 프로세서를 통해 모든 데이터 소스와 모든 대상을 연결하는 통합 서비스입니다. Apache NiFi, Openflow를 사용하면 자체 클라우드에서 완전 관리형 서비스를 실행하여 완벽하게 제어할 수 있습니다.
참고
Openflow 플랫폼은 현재 AWS 및 |SPCS|에서 고객 소유의 VPCs에서 배포할 수 있습니다.
이 항목에서는 Openflow의 주요 기능, 장점, 아키텍처 및 워크플로, 사용 사례에 대해 설명합니다.
주요 기능 및 이점¶
- 개방형 및 확장 가능
Apache NiFi 기반의 확장 가능한 관리형 서비스로, 모든 데이터 소스에서 모든 대상으로 프로세서를 구축하고 확장할 수 있습니다.
- 통합된 데이터 통합 플랫폼
Openflow를 사용하면 데이터 엔지니어가 자체 VPC 또는 Snowflake 배포 내부에 배포할 수 있는 완전 관리형 서비스를 통해 복잡한 양방향 데이터 추출 및 로딩을 처리할 수 있습니다.
- 엔터프라이즈 지원
Openflow는 데이터 통합을 위해 즉시 사용 가능한 보안, 규정 준수, 통합 표시 여부 및 유지 관리 기능 후크를 제공합니다.
- 모든 유형의 데이터에 대한 고속 수집
데이터 소스에서 거의 모든 규모의 정형 및 비정형 데이터를 배치 및 스트림 모드로 Snowflake로 처리할 수 있는 단일 통합 플랫폼입니다.
- AI 처리에 대한 멀티모달 데이터의 연속 수집
거의 실시간에 가까운 비정형 데이터 수집으로 Sharepoint, Google Drive 등의 소스에서 가져온 데이터와 즉시 채팅할 수 있습니다.
Openflow 배포 유형¶
Openflow는 BYOC(Bring Your own Cloud) 및 SPCS(Snowpark Container Services) 버전 둘 다에서 지원됩니다.
- Openflow - Snowflake Deployment
 Feature — Generally Available
Feature — Generally AvailableSnowflake Openflow - Snowflake Deployment는 AWS 및 Azure :ref:`label-na_general_regions`의 모든 계정에서 사용할 수 있습니다.
Openflow - Snowflake Deployment, using Snowpark Container Services (SPCS), provides a streamlined and integrated solution for connectivity. Because SPCS is a self-contained service within Snowflake, it’s easy to deploy and manage. SPCS offers a convenient and cost-effective environment for running your data flows. A key advantage of Openflow - Snowflake Deployment is its native integration with Snowflake’s security model, which allows for seamless authentication, authorization, network security and simplified operations.
|OFSFSPCS-plural|를 구성할 때 :doc:`Openflow - Snowflake Deployment 설정<setup-openflow-spcs>`에 설명된 프로세스를 따릅니다.
- Openflow - Bring Your Own Cloud
- Feature — Generally Available
Snowflake Openflow BYOC deployments are available to all accounts in AWS 상업 리전.
Openflow - Bring Your Own Cloud (BYOC) provides a connectivity solution that you can use to connect public and private systems securely and handle sensitive data preprocessing locally, within the secure bounds of your organization’s cloud environment. BYOC refers to a deployment option where the Openflow data processing engine, or data plane, runs within your own cloud environment while Snowflake manages the overall Openflow service and control plane.
BYOC 배포를 구성할 때 :doc:`setup-openflow-byoc`에 설명된 프로세스를 따릅니다.
사용 사례¶
최소한의 관리로 모든 소스에서 데이터를 가져와 모든 대상에 저장하고, Snowflake의 기본 제공 데이터 보안 및 거버넌스와 함께 사용하려는 경우 Openflow를 사용합니다.
Openflow 사용 사례는 다음과 같습니다.
Google Drive 및 Box 같은 비정형 데이터 소스에서 데이터를 수집하여 AI 어시스턴트에서 Snowflake Cortex로 채팅이 가능하도록 준비하거나 자체 사용자 지정 처리에 데이터를 사용하도록 할 수 있습니다.
데이터베이스 테이블의 변경 데이터 캡처(CDC)를 Snowflake로 복제하여 포괄적인 중앙 집중식 보고를 할 수 있습니다.
실시간에 가까운 분석을 위해 Apache Kafka와 같은 스트리밍 서비스의 실시간 이벤트를 Snowflake로 수집하십시오.
LinkedIn Ads와 같은 SaaS 플랫폼에서 Snowflake로 데이터를 수집하여 보고, 분석 및 인사이트를 얻을 수 있습니다.
Snowflake 및 NiFi :doc:`프로세서<processors/index>`와 :doc:`컨트롤러 서비스<controllers/index>`를 사용하여 Openflow 데이터 흐름을 만듭니다.
보안¶
Openflow는 업계 최고의 보안 기능을 사용하여 계정과 사용자는 물론 Snowflake에 저장하는 모든 데이터에 대해 최고 수준의 보안을 보장합니다. 몇 가지 주요 측면은 다음과 같습니다.
- 인증
런타임은 OAuth2를 사용하여 Snowflake에서 인증을 받습니다.
- 인증
Openflow는 RBAC 에 대해 세분화된 역할을 지원합니다.
ACCOUNTADMIN 을 사용하여 배포 및 런타임을 생성할 수 있는 권한을 부여합니다.
- 전송 중 암호화
Openflow 커넥터는 TLS 프로토콜을 지원하며, 데이터 수집을 위해 표준 Snowflake 클라이언트를 사용합니다.
Openflow 배포와 Openflow 컨트롤 플레인 간의 모든 통신은 TLS 프로토콜을 사용하여 암호화됩니다.
- 시크릿 관리(BYOC)
AWS 시크릿 관리자 또는 Hashicorp Vault와 통합. 자세한 내용은 구성 파일의 암호화된 비밀번호 섹션을 참조하십시오.
- Private Link 지원
Openflow 커넥터는 인바운드 AWS PrivateLink를 사용한 Snowflake에 대한 데이터 읽기 및 쓰기와 호환됩니다.
- Tri-Secret Secure 지원
Openflow Connector는 Tri-Secret Secure 와 호환되어 Snowflake에 데이터를 쓸 수 있습니다.
아키텍처¶
다음 다이어그램은 Openflow의 아키텍처를 보여줍니다.
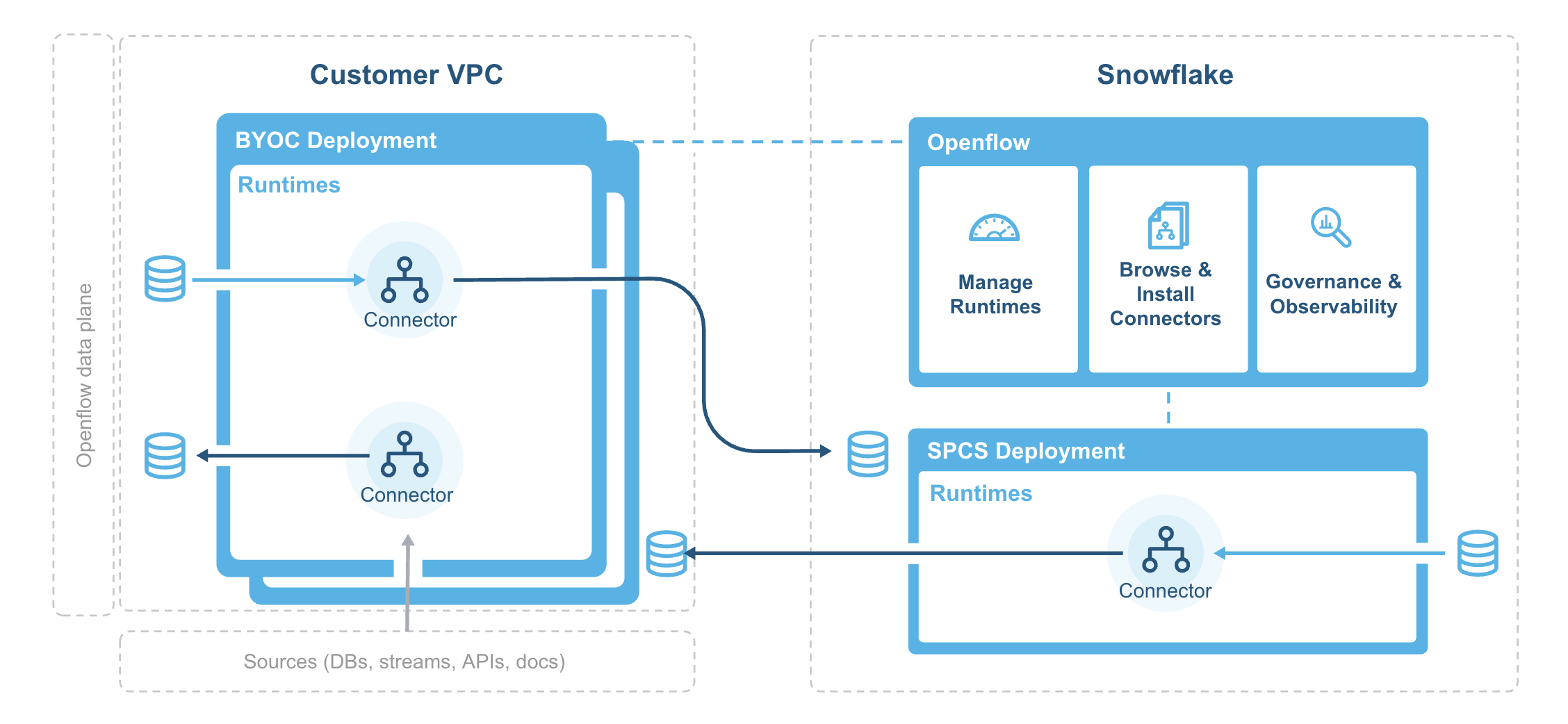
배포 에이전트는 VPC에 Openflow 배포 인프라를 설치하고 부트스트랩할 뿐만 아니라 Snowflake 시스템 이미지 레지스트리에서 컨테이너 이미지를 정기적으로 동기화합니다.
Openflow 구성 요소에는 다음이 포함됩니다.
- Deployments
A deployment is where your data flows execute, within individual runtimes. You will often have multiple runtimes to isolate different projects, teams, or for SDLC reasons, all associated with a single deployment. Deployments come in two types Bring Your Own Cloud (BYOC) and Openflow - Snowflake.
- 컨트롤 플레인
The control plane is a layer containing all components used to manage and observe Openflow runtimes. This includes the Openflow service and API, which users interact with via the Openflow canvas or through interaction with Openflow APIs. On Openflow - Snowflake Deployments, the Control Plane consists of Snowflake-owned public cloud infrastructure and services as well as the control plane application itself.
- BYOC deployments
BYOC 배포`는 *사용자*의 클라우드 환경에 배포되는 런타임의 컨테이너 역할을 하는 배포입니다. 컴퓨팅, 인프라, 저장소 사용량에 따라 요금이 부과됩니다. 자세한 내용은 :doc:`cost-byoc 섹션을 참조하십시오.
- Openflow - Snowflake Deployments
Openflow - Snowflake Deployments are containers for runtimes and are deployed using a compute pool. They incur utilization charges based on their uptime and usage of compute. See Openflow Snowflake Deployment 비용 및 확장 고려 사항 for more information.
- 런타임
Runtimes host data pipelines, with the framework providing security, simplicity, and scalability. You can deploy Openflow runtimes in your VPC using Openflow. You can deploy Openflow connectors to your runtimes, and also build completely new pipelines using Openflow processors and controller services.
- Openflow - Snowflake Deployment 런타임
Openflow - Snowflake Deployment Runtimes are deployed as Snowpark Container Services service to an Openflow - Snowflake Deployment deployment, which is represented by an underlying compute pool. Customers request a Runtime through the deployment, which executes a request on behalf of the user to service. Once created, customers access it via a web browser at the URL generated for that underlying service.