Snowflake ML: aprendizado de máquina de ponta a ponta¶
O Snowflake ML é um conjunto integrado de recursos para aprendizado de máquina de ponta a ponta em uma única plataforma sobre seus dados governados. Trata-se de um ambiente unificado para o desenvolvimento e a produção de ML, otimizado para engenharia de recursos distribuídos em grande escala, treinamento de modelos e inferência na computação de CPU e GPU sem ajuste ou configuração manual.
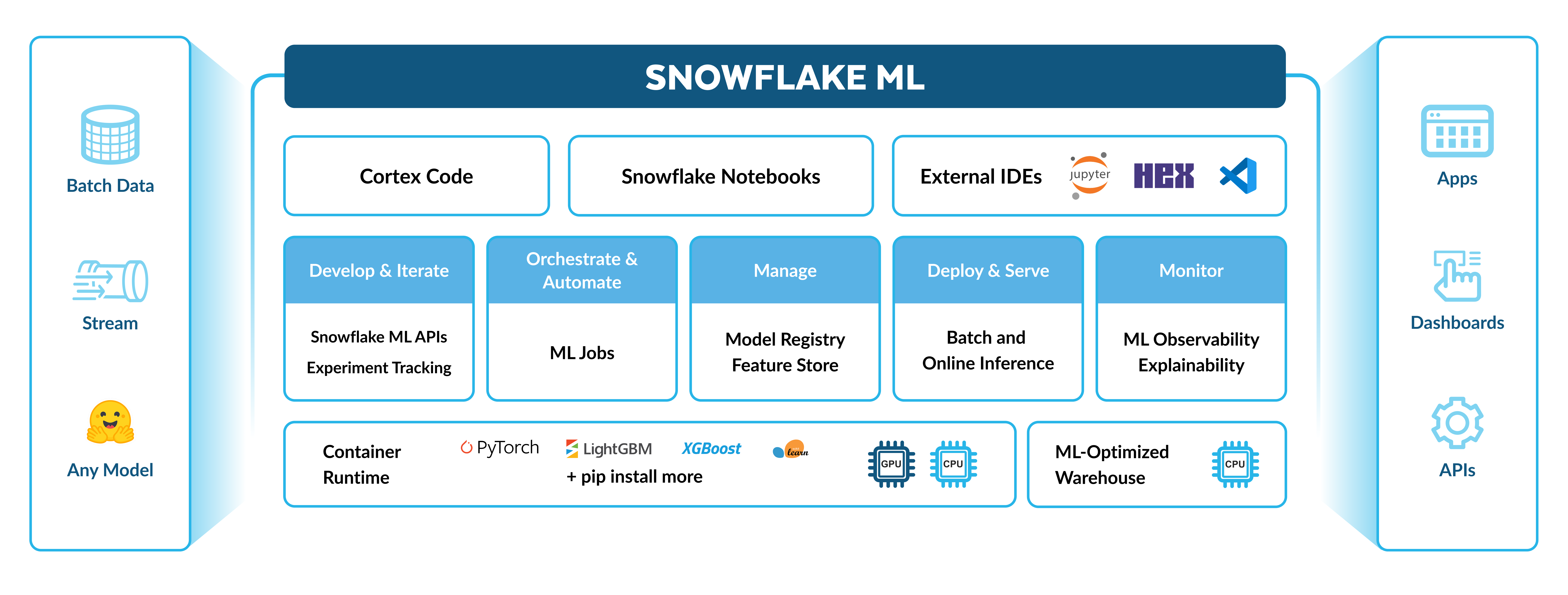
O dimensionamento de fluxos de trabalho de ML de ponta a ponta no Snowflake é otimizado. Você pode fazer o seguinte:
Preparar dados
Criar e usar recursos com o Snowflake Feature Store
Treinar modelos com CPUs ou GPUs usando um pacote de código aberto do Snowflake Notebooks no Container Runtime
Criar experimentos para avaliar seus modelos treinados em relação às métricas definidas
Operacionalizar seus pipelines usando o Snowflake ML Jobs
Implante seu modelo para inferência em escala com o Snowflake Model Registry
Monitorar seus modelos de produção com observabilidade e explicabilidade de ML
Usar a linhagem de ML para rastrear os dados de origem aos recursos, conjuntos de dados e modelos por todo o pipeline de ML
O Snowflake ML também é flexível e modular. Você pode implantar os modelos que desenvolveu no Snowflake fora do Snowflake, e os modelos treinados externamente podem ser facilmente trazidos para o Snowflake para inferência.
Recursos para cientistas de dados e engenheiros de ML¶
Snowflake Notebooks no Container Runtime¶
O Snowflake Notebooks no Container Runtime fornece um ambiente semelhante ao Jupyter para treinamento e ajuste fino de modelos de grande escala no Snowflake, sem gerenciamento de infraestrutura. Comece o treinamento com pacotes pré-instalados, como PyTorch, XGBoost, ou Scikit-learn, ou instale qualquer pacote de repositórios de código aberto, como HuggingFace ou PyPI. O Container Runtime é otimizado para ser executado na infraestrutura do Snowflake, a fim de fornecer a você um carregamento de dados altamente eficiente, treinamento de modelos distribuídos e ajuste de hiperparâmetros.
Snowflake Feature Store¶
O Snowflake Feature Store é uma solução integrada para definir, gerenciar, armazenar e descobrir recursos de ML derivados dos seus dados. O Snowflake Feature Store oferece suporte à atualização incremental automatizada de fontes de dados em lote e streaming, de modo que os pipelines de recursos precisam ser definidos apenas uma vez para serem continuamente atualizados com novos dados.
Trabalhos ML¶
Use Snowflake ML Jobs para desenvolver e automatizar pipelines de ML. Os trabalhos de ML também permitem que equipes que preferem trabalhar de um IDE externo (código VS, PyCharm, notebooks SageMaker) para despachar funções, arquivos ou módulos para o Container Runtime do Snowflake.
Experimentos¶
Use os experimentos para registrar os resultados do treinamento do modelo e avaliar uma coleção de modelos de forma organizada. Os experimentos ajudam você a selecionar o melhor modelo para seu caso de uso e colocá-lo produção. O treinamento pode ser registrado em um experimento durante o treinamento do modelo no Snowflake, ou você pode carregar seus próprios metadados e artefatos do treinamento anterior. Depois de concluir o treinamento, visualize todos os resultados no Snowsight e escolha o modelo certo para suas necessidades.
Snowflake Model Registry e Model Serving¶
O Registro de modelo Snowflake permite o registro e o gerenciamento de todos os modelos de ML, independentemente de terem sido treinados no Snowflake ou em outras plataformas. Você pode usar os modelos do registro de modelos para executar a inferência em escala. Você pode usar o Model Serving para implementar os modelos no Snowpark Container Service para inferência.
Observabilidade de ML¶
Observabilidade de ML fornece ferramentas para monitorar as métricas de desempenho do modelo no Snowflake. Você pode rastrear modelos em produção, monitorar o desempenho e as métricas de desvio, bem como definir alertas para limites de desempenho. Além disso, use a função Explicabilidade de ML para calcular os valores de Shapley para modelos no Snowflake Model Registry, independentemente de onde eles foram treinados.
Linhagem de ML¶
Linhagem de ML é um recurso para rastrear a linhagem de ponta a ponta dos artefatos de ML, desde os dados de origem até os recursos, conjuntos de dados e modelos. Isso permite a reprodutibilidade, a conformidade e a depuração em todo o ciclo de vida dos ativos de ML.
Conjuntos de dados do Snowflake¶
Os conjuntos de dados Snowflake fornecem um instantâneo imutável e versionado dos dados, adequado para ingestão pelos seus modelos de aprendizado de máquina.
Recursos para analistas de negócios¶
Para analistas de negócios, use Funções ML para reduzir o tempo de desenvolvimento de cenários comuns, como previsão e detecção de anomalias em toda a organização com o SQL.
Recursos adicionais¶
Consulte os recursos a seguir para começar a usar o Snowflake ML:
Entre em contato com seu representante Snowflake para obter acesso antecipado à documentação sobre outros recursos atualmente em desenvolvimento.