Beispiel für einen asynchronen Remotedienst für AWS¶
Unter diesem Thema wird ein Beispiel für eine asynchrone AWS Lambda-Funktion (Remotedienst) bereitgestellt. Sie können diese Beispielfunktion erstellen, indem Sie die gleichen Schritte wie unter Schritt 1: Remotedienst (AWS Lambda-Funktion) in der Management Console erstellen beschrieben ausführen.
Übersicht zum Code¶
Dieser Abschnitt der Dokumentation enthält Informationen zum Erstellen einer asynchronen externen Funktion auf AWS. (Bevor Sie Ihre erste asynchrone externe Funktion implementieren, sollten Sie zunächst den Konzeptionellen Überblick zu asynchronen externen Funktionen lesen.)
Auf AWS müssen asynchrone Remotedienste die folgenden Einschränkungen überwinden:
Da es sich bei HTTP POST und GET um separate Anforderungen handelt, muss der Remotedienst Informationen über den von der POST-Anforderung gestarteten Workflow aufbewahren, damit der Status später von der GET-Anforderung abgefragt werden kann.
Typischerweise ruft jeder HTTP POST und HTTP GET eine separate Instanz der Handlerfunktion(en) in einem separaten Prozess oder Thread auf. Die einzelnen Instanzen teilen sich den Speicher nicht. Damit der GET-Handler den Status oder die verarbeiteten Daten lesen kann, muss der GET-Handler auf eine gemeinsame Speicherressource zugreifen, die auf AWS verfügbar ist.
Die einzige Möglichkeit für den POST-Handler, den anfänglichen HTTP 202-Antwortcode zu senden, ist über eine
return-Anweisung (oder eine gleichwertige Anweisung), die die Ausführung des Handlers beendet. Daher muss der POST-Handler vor der Rückgabe von HTTP 202 einen unabhängigen Prozess (oder Thread) starten, um die eigentliche Datenverarbeitung des Remotedienstes durchzuführen. Dieser unabhängige Prozess benötigt typischerweise Zugriff auf den Speicher, der für den GET-Handler sichtbar ist.
Um diese Einschränkung für einen asynchronen Remotedienst zu überwinden, können beispielsweise drei Prozesse (oder Threads) und ein gemeinsamer Speicher verwendet werden:
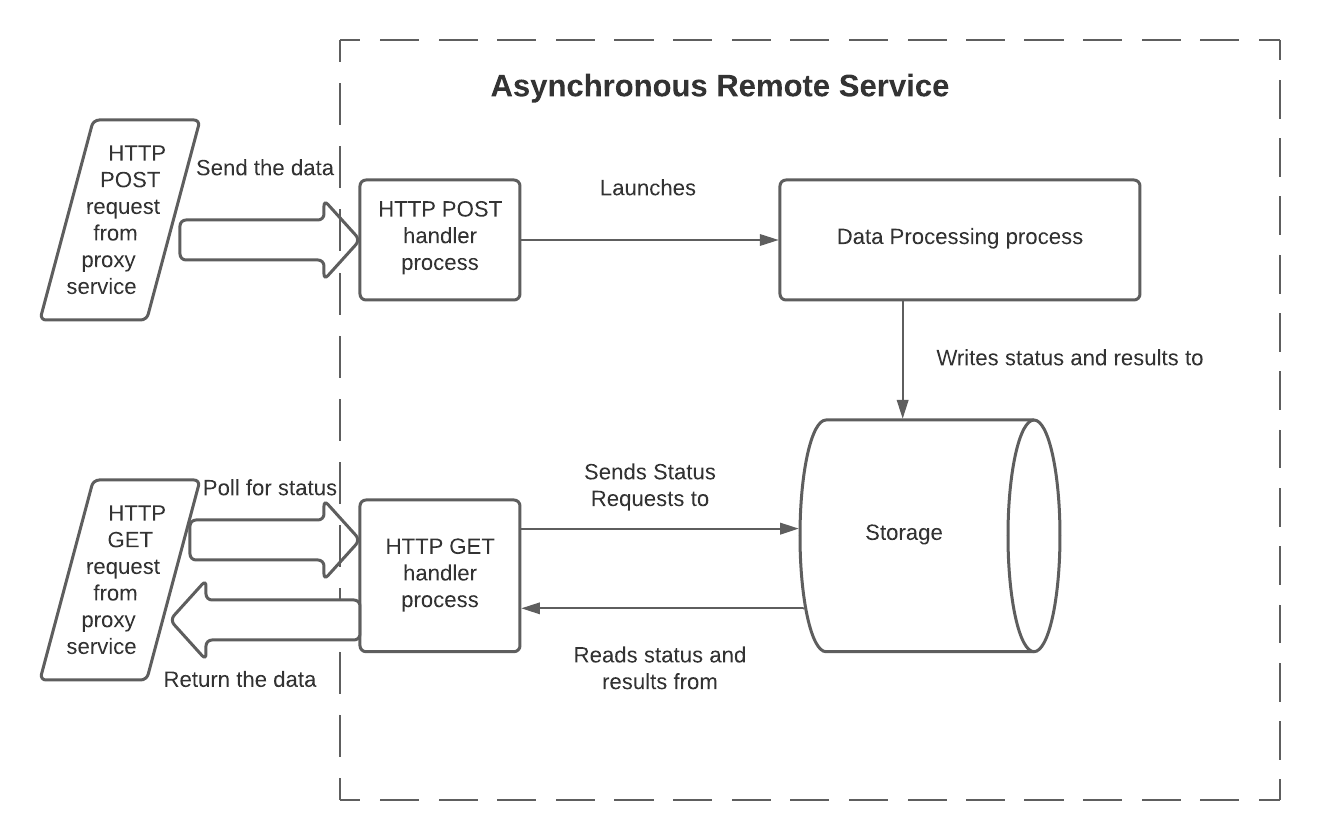
Im folgenden Modell haben die Prozesse die folgenden Aufgaben:
Der HTTP-POST-Handler:
Liest die Eingangsdaten. Bei einer Lambda-Funktion wird der Textbereich des Eingabeparameters
eventder Handler-Funktion ausgelesen.Liest die Batch-ID. Bei einer Lambda-Funktion wird die Kopfzeile des Eingabeparameters
eventgelesen.Startet den Datenverarbeitungsprozess und übergibt ihm die Daten und die Batch-ID. Die Daten werden normalerweise beim Aufruf übergeben, sie können aber auch durch Schreiben in einen externen Speicher übergeben werden.
Erfasst die Batch-ID im gemeinsamen Speicher, auf den sowohl der Datenverarbeitungsprozess als auch der HTTP-GET-Handler-Prozess zugreifen können.
Erfasst bei Bedarf, dass die Verarbeitung dieser Batches noch nicht abgeschlossen ist.
Gibt HTTP 202 zurück, wenn kein Fehler erkannt wurde.
Der Datenverarbeitungscode:
Liest die Eingangsdaten.
Verarbeitet die Daten.
Stellt das Ergebnis für den GET-Handler zur Verfügung (entweder durch Schreiben der Ergebnisdaten in den gemeinsamen Speicher oder durch Bereitstellung einer API, über den die Ergebnisse abgefragt werden können).
Aktualisiert in der Regel den Status dieses Batches (z. B. von
IN_PROGRESSinSUCCESS), um anzuzeigen, dass die Ergebnisse zum Lesen bereit sind.Beendet den Prozess. Optional kann dieser Prozess einen Fehlerindikator zurückgeben. Snowflake sieht dies nicht direkt (Snowflake sieht nur den HTTP-Rückgabecode von POST-Handler und GET-Handler), aber die Rückgabe eines Fehlerindikators aus dem Datenverarbeitungsprozess könnte bei der Fehlersuche hilfreich sein.
Der GET-Handler:
Liest die Batch-ID. Bei einer Lambda-Funktion wird die Kopfzeile des Eingabeparameters
eventgelesen.Liest den Speicher, um den aktuellen Status dieses Batches zu erhalten (z. B.
IN_PROGRESSoderSUCCESS).Wenn die Verarbeitung noch nicht abgeschlossen ist, dann wird 202 zurückgegeben.
Wenn die Verarbeitung erfolgreich abgeschlossen ist, dann:
Liest die Ergebnisse.
Bereinigt den Speicher.
Gibt die Ergebnisse zusammen mit HTTP-Code 200 zurück.
Wenn der gespeicherte Status einen Fehler anzeigt, dann:
Bereinigt den Speicher.
Gibt einen Fehlercode zurück.
Beachten Sie, dass der GET-Handler für einen Batch möglicherweise mehrfach aufgerufen wird, wenn die Verarbeitung so lange dauert, dass mehrere HTTP-GET-Anforderungen gesendet werden.
Von diesem Modell gibt es viele mögliche Varianten. Beispiel:
Die Batch-ID und der Status könnten am Anfang des Datenverarbeitungsprozesses geschrieben werden und nicht am Ende des POST-Prozesses.
Die Datenverarbeitung kann in einer separaten Funktion (z. B. einer separaten Lambda-Funktion) oder sogar als komplett separater Dienst erfolgen.
Der Datenverarbeitungscode muss nicht unbedingt in den gemeinsamen Speicher schreiben. Stattdessen können die verarbeiteten Daten auf andere Weise zur Verfügung gestellt werden. Eine API kann z. B. die Batch-ID als Parameter annehmen und die Daten zurückgeben.
Der Implementierungscode sollte die Möglichkeit in Betracht ziehen, dass die Verarbeitung zu lange dauert oder fehlschlägt, und daher müssen alle Teilergebnisse bereinigt werden, um nicht unnötig Speicherplatz zu verbrauchen.
Der Speichermechanismus muss über mehrere Prozesse (oder Threads) hinweg gemeinsam genutzt werden können. Mögliche Speichermechanismen sind:
Von AWS bereitgestellte Speichermechanismen, wie z. B.:
Festplattenplatz (z. B. Amazon Elastic File System (EFS) ).
Ein lokaler Datenbankserver, der über AWS (z. B. Amazon DynamoDB ) verfügbar ist.
Speicher, der sich außerhalb von AWS befindet, aber von AWS aus zugänglich ist.
Der Code für jeden der obigen drei Prozesse kann als separate Lambda-Funktion geschrieben werden (eine für den POST-Handler, eine für die Datenverarbeitungsfunktion und eine für den GET-Handler), oder als eine einzige Funktion, die auf verschiedene Weise aufgerufen werden kann.
Der folgende Python-Beispielcode ist eine einzelne Lambda-Funktion, die separat für den POST-, den Datenverarbeitungs- und den GET-Prozess aufgerufen werden kann.
Beispielcode¶
Dieser Code zeigt eine Beispielabfrage mit Ausgabe. Der Fokus in diesem Beispiel liegt auf den drei Prozessen und wie sie interagieren, nicht auf dem gemeinsamen Speichermechanismus (DynamoDB) oder die Datentransformation (Standpunktanalyse). Der Code ist so strukturiert, dass es einfach ist, den Beispielspeichermechanismus und die Datentransformation durch andere zu ersetzen.
Der Einfachheit halber folgendes Beispiel:
Einige wichtige Werte (z. B. die AWS-Region) werden hart kodiert.
Setzt das Vorhandensein einiger Ressourcen voraus (z. B. die Tabelle „Jobs“ in Dynamo).
Beispielaufruf und Ausgabe¶
Hier ist ein Beispielaufruf der asynchronen externen Funktion zusammen mit einer Beispielausgabe, einschließlich der Ergebnisse der Standpunktanalyse:
Hinweise zum Beispielcode¶
Die Datenverarbeitungsfunktion wird durch folgenden Aufruf gestartet:
Der InvocationType sollte, wie oben gezeigt, „Event“ (Ereignis) sein, weil der zweite Prozess (oder Thread) asynchron sein muss und
Eventder einzige Typ von nicht blockierendem Aufruf ist, der durch dieinvoke()-Methode verfügbar ist.Die Datenverarbeitungsfunktion gibt einen HTTP 200-Code zurück. Dieser HTTP 200-Code wird jedoch nicht direkt an Snowflake zurückgegeben. Snowflake sieht keinen HTTP-Code 200, bis ein GET den Status abfragt und sieht, dass die Datenverarbeitungsfunktion die Verarbeitung dieses Batches erfolgreich abgeschlossen hat.