Snowpark Container Services : utilisation des tâches¶
Snowpark Container Services vous permet de déployer, de gérer et d’adapter plus facilement des applications conteneurisées. Après avoir créé une application et chargé l’image de l’application dans un référentiel de votre compte Snowflake, vous pouvez exécuter vos conteneurs d’application en tant que service.
Un service représente l’exécution par Snowflake de votre application conteneurisée sur un pool de calcul, qui est une collection de nœuds de machine virtuelle (VM). Il existe deux types de services :
services de longue durée. Un service de longue durée est un service Web qui ne se termine pas automatiquement. Une fois que vous avez créé un service, Snowflake gère le service en cours d’exécution. Par exemple, si un conteneur de service s’arrête, pour quelque raison que ce soit, Snowflake redémarre ce conteneur afin que le service fonctionne sans interruption.
Services de tâche. Un service de tâche se termine lorsque votre code se termine, de la même manière qu’une procédure stockée. Lorsque tous les conteneurs se terminent, le service de tâche est terminé.
Le schéma suivant montre l’architecture d’un service :
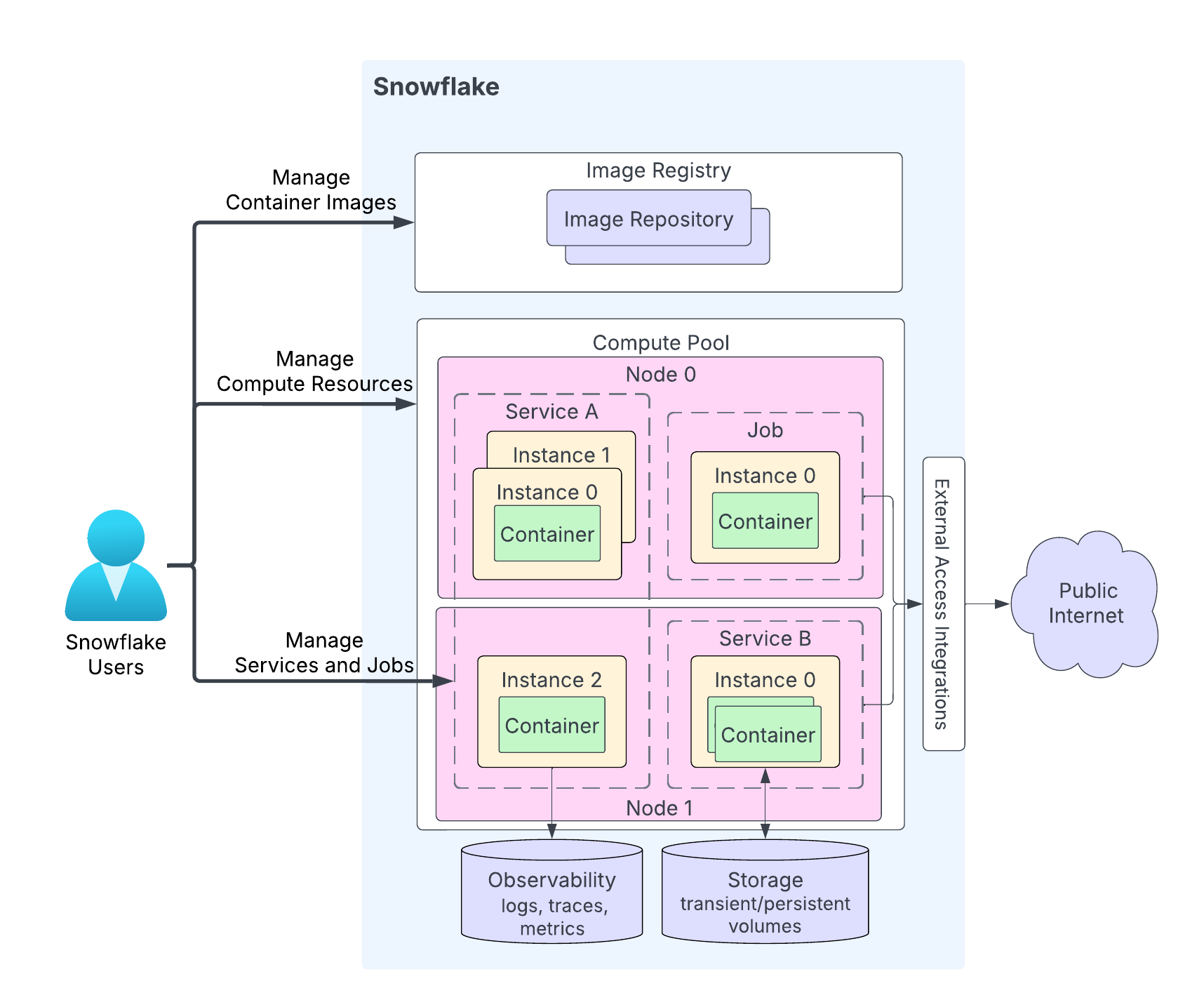
Les caractéristiques principales fort du schéma sont les suivantes :
Les utilisateurs chargent le code de leur application dans un référentiel de leur compte Snowflake. Le service de registre d’images sert d’API OCIv2 pour le stockage des images conformes à OCI dans un référentiel. Par exemple, vous pouvez utiliser Docker API pour charger des images dans un référentiel. Lorsque vous créez un service, vous spécifiez l’image à utiliser.
Un pool de calcul est l’endroit où Snowflake exécute vos services. Le schéma illustre un pool de calcul comportant deux nœuds de calcul (le nœud 0 et le nœud 1). Snowflake exécute votre instance de service sur un nœud. Lors de l’exécution de plusieurs instances de service, en fonction des exigences en matière de ressources, Snowflake peut les exécuter sur le même nœud ou les répartir sur plusieurs nœuds. Par exemple :
Le nœud 0 exécute le service A (deux instances sur les trois instances totales de ce service) et une tâche (avec une seule instance).
Le nœud 1 exécute la troisième instance du service A. Ce nœud exécute également une instance du service B.
Selon le code de votre application, une instance de service peut être constituée de plusieurs conteneurs. Alors que Snowflake peut distribuer des instances d’un service sur plusieurs nœuds d’un pool de calcul, tous les conteneurs d’une même instance de service s’exécutent toujours sur le même nœud de pool de calcul.
Les services peuvent éventuellement communiquer avec l’internet public.
Un service peut utiliser le stockage, y compris le stockage transitoire (par exemple, la mémoire et le disque local) et les volumes persistants (par exemple, les volumes de blocs).
Snowflake peut enregistrer les journaux, les traces et les métriques de vos services dans la table des événements de votre compte Snowflake.
Snowflake fournit des APIs pour vous permettre de créer et de gérer des référentiels, des pools de calcul et des services. Cette rubrique explique comment utiliser des services. Les APIs pour la gestion des services comprennent ce qui suit :
Commandes SQL :
Création d’un service. CREATE SERVICE, EXECUTE JOB SERVICE.
Modification d’un service. ALTER SERVICE, DROP SERVICE.
Obtention d’informations sur un service. SHOW SERVICES, DESCRIBE SERVICE et autres commandes.
Interfaces non SQL : APIs Snowflake Python, APIs Snowflake REST et Snowflake CLI.
Démarrer les services¶
Après avoir chargé le code de votre application dans un référentiel de votre compte Snowflake, vous pouvez démarrer un service. Les informations minimales requises pour démarrer un service incluent :
Un nom : nom du service.
Une spécification de service : cette spécification fournit à Snowflake les informations nécessaires à l’exécution de votre service. La spécification est un fichier YAML.
Un pool de calcul : Snowflake exécute votre service dans le pool de calcul spécifié.
Créer un service de longue durée¶
Utilisez CREATE SERVICE pour créer un service de longue durée.
Dans la plupart des cas, vous créez un service en indiquant une spécification en ligne, comme illustré ci-dessous :
CREATE SERVICE echo_service IN COMPUTE POOL tutorial_compute_pool FROM SPECIFICATION $$ spec: containers: - name: echo image: /tutorial_db/data_schema/tutorial_repository/my_echo_service_image:tutorial readinessProbe: port: 8000 path: /healthcheck endpoints: - name: echoendpoint port: 8000 public: true $$;
Créez un service en faisant référence à une spécification de service stockée dans une zone de préparation Snowflake. Lorsque vous déployez le service dans un environnement de production, vous pouvez appliquer le principe de séparation des préoccupations et charger la spécification dans une zone de préparation, en fournissant les informations de zone de préparation dans la commande CREATE SERVICE, comme indiqué :
CREATE SERVICE echo_service IN COMPUTE POOL tutorial_compute_pool FROM @tutorial_stage SPECIFICATION_FILE='echo_spec.yaml';
Exécuter un service associé aux tâches¶
Utilisez EXECUTE JOB SERVICE pour créer un service de tâche. Par défaut, cette commande s’exécute de manière synchrone et renvoie une réponse après la sortie de tous les conteneurs du service de tâche. Vous pouvez éventuellement spécifier le paramètre ASYNC pour exécuter le service de tâche de manière asynchrone.
Exécutez un service de tâche à l’aide d’une spécification en ligne : La commande attend que la tâche soit terminée :
EXECUTE JOB SERVICE IN COMPUTE POOL tutorial_compute_pool FROM SPECIFICATION $$ spec: containers: - name: main image: /tutorial_db/data_schema/tutorial_repository/my_job_image:latest env: SNOWFLAKE_WAREHOUSE: tutorial_warehouse args: - "--query=select current_time() as time,'hello'" - "--result_table=results" $$;
Vous pouvez éventuellement exécuter cette tâche de manière asynchrone à l’aide de la propriété
ASYNC.EXECUTE JOB SERVICE IN COMPUTE POOL tutorial_compute_pool NAME = example_job_service ASYNC = TRUE FROM SPECIFICATION $$ ... $$;
Lorsque vous exécutez une tâche asynchrone, vous pouvez utiliser la fonction d’aide <service_name>!SPCS_WAIT_FOR pour patienter jusqu’à ce que la tâche soit terminée.
CALL example_job_service!spcs_wait_for('DONE', 120)
Exécutez un service de tâche en utilisant les informations de la zone de préparation :
EXECUTE JOB SERVICE IN COMPUTE POOL tutorial_compute_pool NAME = example_job_service FROM @tutorial_stage SPECIFICATION_FILE='my_job_spec.yaml';
Exécuter plusieurs répliques d’un service associé aux tâches (tâches par lots)¶
Par défaut, EXECUTE JOB SERVICE exécute une seule instance de service associé aux tâches sur un pool de calcul pour exécuter la tâche. Toutefois, vous pouvez choisir d’exécuter plusieurs répliques de services associés aux tâches pour répartir la charge de travail entre les nœuds du pool de calcul. Par exemple, vous pouvez utiliser 10 répliques pour traiter un ensemble de données de 10 millions de lignes, chacune traitant 1 million de lignes.
Les tâches par lots prennent en charge des scénarios dans lesquels le travail peut être partitionné en tâches indépendantes (une par instance de service associé aux tâches (également appelée réplique)), qui peuvent potentiellement être exécutées simultanément. La capacité de Snowflake à exécuter les instances simultanément dépend de la taille du pool de calcul.
Pour exécuter une tâche par lot avec plusieurs instances, utilisez le paramètre REPLICAS facultatif de EXECUTE JOB SERVICE comme indiqué. L’exemple suivant exécute un service associé aux tâches avec 10 instances :
EXECUTE JOB SERVICE
IN COMPUTE POOL my_pool
NAME = example_job
REPLICAS = 10
FROM SPECIFICATION $$
spec:
containers:
- name: main
image: my_repo/my_job_image:latest
$$;
Lorsque le paramètre REPLICAS est spécifié dans EXECUTE JOB SERVICE, Snowflake renseigne les deux variables d’environnement suivantes dans le conteneur de tâche :
SNOWFLAKE_JOBS_COUNT: La valeur de la propriété REPLICAS spécifiée sur EXECUTE JOB SERVICE.SNOWFLAKE_JOB_INDEX: L’ID de l’instance du service associé aux tâches, en commençant par 0. Si vous avez trois répliques, les IDs de l’instance seront 0, 1 et 2.
Ces variables d’environnement sont fournies afin qu’un conteneur de tâche puisse les utiliser pour partitionner l’entrée et attribuer à chaque instance une partition spécifique à traiter. Par exemple, lors du traitement de 10 millions de lignes avec 10 répliques de tâches, l’instance avec l’index de tâche 0 traiterait les lignes de 1 à 1 million, l’instance avec l’index de tâche 1 traiterait les lignes de 1 à 2 millions, et ainsi de suite.
Utilisez la commande SHOW SERVICE INSTANCES IN SERVICE pour connaître l’état de chaque instance de service associé aux tâches.
Utilisez la commande DESCRIBE SERVICE pour obtenir l’état global du service associé aux tâches. Snowflake calcule l’état global du service associé aux tâches comme suit :
Si une instance échoue, l’état de la tâche est FAILED.
Si toutes les instances s’achèvent correctement, l’état de la tâche est DONE.
Si une instance est en cours d’exécution, l’état de la tâche est RUNNING.
Sinon, l’état du service associé aux tâches est PENDING.
Utilisation de modèles de spécifications¶
Il peut arriver que vous souhaitiez créer plusieurs services en utilisant la même spécification, mais avec des configurations différentes. Par exemple, vous supposez que vous définissez une variable d’environnement dans une spécification de service et vous souhaitez créer plusieurs services en utilisant la même spécification mais des valeurs différentes pour la variable d’environnement.
La spécification de modèles vous permet de définir des variables pour des valeurs de champ dans la spécification. Lorsque vous créez un service, vous fournissez des valeurs pour ces variables.
Dans un modèle de spécification, vous spécifiez des variables comme valeurs pour les différents champs de la spécification. Utilisez la syntaxe {{ variable_name }} pour spécifier ces variables. Ensuite, dans la commande CREATE SERVICE, spécifiez le paramètre USING pour définir les valeurs de ces variables.
Par exemple, le modèle de spécification en ligne de la commande CREATE SERVICE suivante utilise une variable nommée tag_name pour le nom de la balise d’image. Vous pouvez utiliser cette variable pour spécifier une balise d’image différente pour chaque service. Dans cet exemple, le paramètre USING définit la variable tag_name sur la valeur latest.
CREATE SERVICE echo_service
IN COMPUTE POOL tutorial_compute_pool
FROM SPECIFICATION $$
spec:
containers:
- name: echo
image: myorg-myacct.registry.snowflakecomputing.com/tutorial_db/data_schema/tutorial_repository/my_echo_service_image:{{ tag_name }}
...
endpoints:
- name: ...
...
$$
USING (tag_name=>'latest');
Si vous choisissez d’enregistrer le modèle de spécification dans une zone de préparation Snowflake de votre compte, vous pouvez pointer vers l’emplacement du modèle dans la commande CREATE SERVICE :
CREATE SERVICE echo_service
IN COMPUTE POOL tutorial_compute_pool
FROM @STAGE SPECIFICATION_TEMPLATE_FILE='echo.yaml'
USING (tag_name=>'latest');
Lignes directrices pour la définition des variables dans une spécification¶
Utilisez la syntaxe
{{ variable_name }}pour définir des variables en tant que valeurs de champ dans la spécification.Ces variables peuvent avoir des valeurs par défaut. Pour spécifier la valeur par défaut, utilisez la fonction
defaultdans la déclaration de la variable. Par exemple, la spécification suivante définit deux variables (character_nameetendpoint_name) avec des valeurs par défaut.spec: containers: - name: echo image: <image_name> env: CHARACTER_NAME: {{ character_name | default('Bob') }} SERVER_PORT: 8085 endpoints: - name: {{ endpoint_name | default('echo-endpoint') }} port: 8085
De plus, vous pouvez spécifier un paramètre booléen facultatif à la fonction
defaultpour indiquer si vous souhaitez que la valeur par défaut soit utilisée lorsqu’une valeur vide est transmise pour la variable. Considérez cette spécification :spec: containers: - name: echo image: <image_name> env: CHARACTER_NAME: {{ character_name | default('Bob', false) }} SERVER_PORT: 8085 endpoints: - name: {{ endpoint_name | default('echo-endpoint', true) }} port: 8085
Dans la spécification :
Pour la variable
character_name, le paramètre booléen est fixé àfalse. Par conséquent, si la variable est définie sur une valeur de chaîne vide (“”) pour ce paramètre, la valeur reste vide ; la valeur par défaut (« Bob ») n’est pas utilisée.Pour la variable
echo_endpoint, le paramètre booléen est fixé àtrue. Par conséquent, si vous donnez une valeur vide à ce paramètre, la valeur par défaut (« point de terminaison ») est utilisée.
Par défaut, le paramètre booléen de la fonction
defaultestfalse.
Lignes directrices pour la transmission de valeurs pour les variables de spécification¶
Spécifiez le paramètre USING dans la commande CREATE SERVICE pour fournir des valeurs aux variables. La syntaxe générale de USING est la suivante :
USING( var_name=>var_value, [var_name=>var_value, ... ] );
où :
var_nameest sensible à la casse et doit être un identificateur Snowflake valide (voir Exigences relatives à l’identificateur).var_valuepeut être une valeur alphanumérique ou une valeur JSON valide.Exemples :
-- Alphanumeric string and literal values USING(some_alphanumeric_var=>'blah123', some_int_var=>111, some_bool_var=>true, some_float_var=>-1.2) -- JSON string USING(some_json_var=>' "/path/file.txt" ') -- JSON map USING(env_values=>'{"SERVER_PORT": 8000, "CHARACTER_NAME": "Bob"}' ); -- JSON list USING (ARGS=>'["-n", 2]' );
Le paramètre USING dans CREATE SERVICE doit fournir des valeurs pour les variables de la spécification (à l’exception des variables pour lesquelles la spécification fournit des valeurs par défaut). Sinon, une erreur est renvoyée.
Exemples¶
Ces exemples illustrent la création de services à l’aide de modèles de spécification. Les commandes CREATE SERVICE présentées dans ces exemples utilisent la spécification en ligne.
Exemple 1 : fournir des valeurs simples¶
Dans le tutoriel 1, vous créez un service en fournissant une spécification en ligne. L’exemple suivant est une version modifiée du même exemple où la spécification définit deux variables : image_url et SERVER_PORT. Notez que la variable SERVER_PORT est répétée à trois endroits. C’est l’un des avantages ajoutés de l’utilisation de variables, qui garantit que tous les champs censés avoir la même valeur ont bien la même valeur.
CREATE SERVICE echo_service
IN COMPUTE POOL tutorial_compute_pool
MIN_INSTANCES=1
MAX_INSTANCES=1
FROM SPECIFICATION_TEMPLATE $$
spec:
containers:
- name: echo
image: {{ image_url }}
env:
SERVER_PORT: {{SERVER_PORT}}
CHARACTER_NAME: Bob
readinessProbe:
port: {{SERVER_PORT}}
path: /healthcheck
endpoints:
- name: echoendpoint
port: {{SERVER_PORT}}
public: true
$$
USING (image_url=>' "/tutorial_db/data_schema/tutorial_repository/my_echo_service_image:latest" ', SERVER_PORT=>8000 );
Dans cette commande CREATE SERVICE, le paramètre USING fournit des valeurs pour les deux variables de spécification. La valeur image_url comprend des barres obliques et un signe deux-points. Il ne s’agit pas de caractères alphanumériques. Par conséquent, l’exemple met la valeur entre guillemets pour en faire une valeur de chaîne JSON valide. La spécification du modèle étend la spécification suivante :
spec:
containers:
- name: echo
image: /tutorial_db/data_schema/tutorial_repository/my_echo_service_image:latest
env:
SERVER_PORT: 8000
CHARACTER_NAME: Bob
readinessProbe:
port: 8000
path: /healthcheck
endpoints:
- name: echoendpoint
port: 8000
public: true
Exemple 2 : fournir une valeur JSON¶
Dans le tutoriel 1, la spécification définit deux variables d’environnement (SERVER_PORT et CHARACTER_NAME) comme indiqué :
spec:
containers:
- name: echo
image: /tutorial_db/data_schema/tutorial_repository/my_echo_service_image:latest
env:
SERVER_PORT: 8000
CHARACTER_NAME: Bob
…
Vous pouvez modéliser cette spécification en utilisant une variable pour le champ env. Cela vous permet de créer plusieurs services avec des valeurs différentes pour les variables d’environnement. La commande CREATE SERVICE suivante utilise une variable (env_values) pour le champ env.
CREATE SERVICE echo_service
IN COMPUTE POOL tutorial_compute_pool
MIN_INSTANCES=1
MAX_INSTANCES=1
FROM SPECIFICATION_TEMPLATE $$
spec:
containers:
- name: echo
image: /tutorial_db/data_schema/tutorial_repository/my_echo_service_image:latest
env: {{env_values}}
readinessProbe:
port: {{SERVER_PORT}} #this and next tell SF to connect to port 8000
path: /healthcheck
endpoints:
- name: echoendpoint
port: {{SERVER_PORT}}
public: true
$$
USING (env_values=>'{"SERVER_PORT": 8000, "CHARACTER_NAME": "Bob"}' );
Le paramètre USING dans CREATE SERVICE fournit une valeur à la variable env_values. La valeur est un mappage JSON qui fournit les valeurs des deux variables d’environnement.
Exemple 3 : fournir une liste comme valeur de la variable¶
Dans le tutoriel 2, la spécification comprend le champ args qui inclut deux arguments.
spec:
container:
- name: main
image: /tutorial_db/data_schema/tutorial_repository/my_job_image:latest
env:
SNOWFLAKE_WAREHOUSE: tutorial_warehouse
args:
- "--query=select current_time() as time,'hello'"
- "--result_table=results"
Dans une version de modèle de la spécification, vous pouvez fournir ces arguments sous la forme d’une liste JSON, comme indiqué :
spec:
container:
- name: main
image: /tutorial_db/data_schema/tutorial_repository/my_job_image:latest
env:
SNOWFLAKE_WAREHOUSE: tutorial_warehouse
args: {{ARGS}}
$$
USING (ARGS=>$$["--query=select current_time() as time,'hello'", "--result_table=results"]$$ );
Mettre à l’échelle les services¶
Par défaut, Snowflake exécute une instance du service dans le pool de calcul spécifié. Pour gérer des charges de travail importantes, vous pouvez exécuter plusieurs instances de service en définissant les propriétés MIN_INSTANCES et MAX_INSTANCES, qui spécifient le nombre minimum d’instances du service au début et le nombre maximum d’instances que Snowflake peut ajouter en cas de besoin.
Exemple
CREATE SERVICE echo_service
IN COMPUTE POOL tutorial_compute_pool
FROM @tutorial_stage
SPECIFICATION_FILE='echo_spec.yaml'
MIN_INSTANCES=2
MAX_INSTANCES=4;
Lorsque plusieurs instances de service sont en cours d’exécution, Snowflake fournit automatiquement un équilibreur de charge pour répartir les requêtes entrantes.
Snowflake ne considère pas le service comme étant READY tant qu’au moins deux instances ne sont pas disponibles. Tant que le service n’est pas prêt, Snowflake bloque l’accès à celui-ci, ce qui signifie que les fonctions de service associées ou les demandes d’entrée sont refusées jusqu’à ce que la disponibilité soit confirmée.
Dans certains cas, vous souhaiterez peut-être que Snowflake considère que le service est prêt (et transmet les demandes entrantes) même si moins d’instances que le minimum spécifié sont disponibles. Vous pouvez y parvenir en définissant la propriété MIN_READY_INSTANCES.
Considérez ce scénario : pendant la maintenance ou une mise à niveau progressive du service, Snowflake peut mettre fin à une ou plusieurs instances de service. Cela pourrait conduire à moins d’instances disponibles que la valeur MIN_INSTANCES spécifiée, ce qui empêche le service d’entrer à l’état READY. Dans ce cas, vous pouvez définir MIN_READY_INSTANCES sur une valeur inférieure à MIN_INSTANCES pour garantir que le service puisse continuer à accepter des requêtes.
Exemple
CREATE SERVICE echo_service
IN COMPUTE POOL tutorial_compute_pool
FROM @tutorial_stage
SPECIFICATION_FILE='echo_spec.yaml'
MIN_INSTANCES=2
MAX_INSTANCES=4
MIN_READY_INSTANCES=1;
Pour plus d’informations, voir CREATE SERVICE.
Activer la mise à l’échelle automatique¶
Pour configurer Snowflake afin qu’il évalue automatiquement le nombre d’instances de service en cours d’exécution, définissez les paramètres MIN_INSTANCES et MAX_INSTANCES dans la commande CREATE SERVICE. Vous pouvez également utiliser ALTER SERVICE pour modifier ces valeurs. La mise à l’échelle automatique se produit lorsque MAX_INSTANCES est supérieur à MIN_INSTANCES.
Snowflake commence par créer le nombre minimum d’instances de service sur le pool de calcul spécifié. Snowflake augmente ou réduit ensuite le nombre d’instances de service en fonction de demandes de ressources à 80 % du CPU. Snowflake surveille en permanence l’utilisation du CPU dans le pool de calcul, en regroupant les données d’utilisation de toutes les instances de service en cours d’exécution.
Lorsque l’utilisation agrégée du CPU (pour toutes les instances de service) dépasse 80 %, Snowflake déploie une instance de service supplémentaire dans le pool de calcul. Si l’utilisation agrégée du CPU tombe en dessous de 80 %, Snowflake réduit son activité en supprimant une instance de service en cours d’exécution. Snowflake utilise une fenêtre de stabilisation de cinq minutes pour éviter les mises à l’échelle fréquentes. La propriété de service target_instances indique le nombre cible d’instances de service vers lesquelles Snowflake s’adapte.
Notez les comportements de mise à l’échelle suivants :
La mise à l’échelle des instances de service est limitée par les paramètres MIN_INSTANCES et MAX_INSTANCES configurés pour le service.
Si une mise à l’échelle est nécessaire et que les nœuds du pool de calcul n’ont pas la capacité de ressources nécessaire pour démarrer une autre instance de service, la mise à l’échelle automatique du pool de calcul peut être déclenchée. Pour plus d’informations, voir Mise à l’échelle automatique des nœuds d’un pool de calcul.
Si vous spécifiez les paramètres MAX_INSTANCES et MIN_INSTANCES lors de la création d’un service, mais que vous ne spécifiez pas les exigences en matière de mémoire et de CPU pour votre instance de service dans le fichier de spécification du service, aucune mise à l’échelle automatique ne se produit ; Snowflake démarre avec le nombre d’instances spécifié par le paramètre MIN_INSTANCES et ne fera pas de mise à l’échelle automatique.
Suspension d’un service¶
Un service qui fonctionne depuis longtemps consomme des ressources de pool de calcul et engendre des coûts, mais vous pouvez suspendre le service lorsqu’il n’effectue pas de performances significatives. Lorsqu’aucun service ou job n’est actif sur un nœud de pool de calcul, le mécanisme de suspension automatique de Snowflake suspend le pool afin de réduire les coûts.
Pour suspendre un service, vous pouvez soit appeler explicitement ALTER SERVICE … SUSPEND pour suspendre un service, soit définir la propriété AUTO_SUSPEND_SECS en utilisant CREATE SERVICE ou ALTER SERVICE pour définir la durée d’inactivité après laquelle Snowflake suspend automatiquement le service.
![]() Fonctionnalité en avant-première — En accès libre
Fonctionnalité en avant-première — En accès libre
La configuration de la suspension automatique d’un service de Snowpark Container Services à l’aide de la propriété AUTO_SUSPEND_SECS est une fonctionnalité d’aperçu.
Lorsque la propriété AUTO_SUSPEND_SECS est définie, Snowflake suspend automatiquement un service s’il n’est pas déjà suspendu et s’il est inactif pendant plus de AUTO_SUSPEND_SECS secondes. Un service est inactif lorsque les deux conditions suivantes sont remplies :
Aucune requête en cours d’exécution n’inclut un appel de fonction de service à ce service.
Le statut du service est RUNNING.
Prudence
La suspension automatique ne permet pas de suivre le traitement des données initié par l’appel d’une fonction de service, là ou le traitement se poursuit après le retour de la fonction de service. Dans la mise en œuvre actuelle, la suspension automatique ne suit pas non plus les communications d’entrée et de service à service. Par conséquent, vous ne devez pas activer la suspension automatique pour les services qui offrent de telles fonctions, car cela pourrait perturber ces processus potentiellement en cours.
Lorsque Snowflake suspend un service, il arrête toutes les instances de service sur le pool de calcul. Si aucun autre service ne s’exécute sur le pool de calcul et si la suspension automatique est configurée pour le pool de calcul, Snowflake suspend également les nœuds du pool de calcul. Vous évitez ainsi de devoir payer pour un pool de calcul inactif.
Notez également ce qui suit :
La suspension automatique n’est pas prise en charge pour les services de tâche.
La suspension automatique n’est pas prise en charge sur les services avec des points de terminaison publics car Snowflake ne suit actuellement que le trafic des fonctions de service et non le trafic d’entrée pour décider quand un service est inactif.
Modifier et supprimer des services¶
Après avoir créé un service ou un service associé aux tâches, vous pouvez effectuer les actions suivantes :
Utilisez la commande DROP SERVICE pour supprimer un service d’un schéma (Snowflake met fin à tous les conteneurs de services).
Appelez la fonction <service_name>!SPCS_CANCEL_JOB permettant d’annuler un service associé aux tâches. Lorsque vous annulez une tâche, Snowflake arrête l’exécution de la tâche et supprime les ressources allouées à l’exécution de la tâche.
Utilisez la commande ALTER SERVICE pour modifier le service (par exemple, suspendez ou reprenez le service, modifiez le nombre d’instances en cours d’exécution et demandez à Snowflake de redéployer votre service à l’aide d’une nouvelle spécification de service).
Note
Vous ne pouvez pas modifier un service associé aux tâches.
Mettre fin au service¶
Lorsque vous suspendez un service (ALTER SERVICE … SUSPEND) ou supprimez un service (DROP SERVICE), Snowflake met fin à toutes les instances de service. De même, lorsque vous mettez à niveau le code de service (ALTER SERVICE … <fromSpecification>), Snowflake applique des mises à niveau progressives en mettant fin et en redéployant une instance de service à la fois.
Lors de la fin d’une instance de service, Snowflake envoie d’abord un signal SIGTERM à chaque conteneur de service. Le conteneur a la possibilité de traiter le signal et de s’arrêter correctement avec une fenêtre de 30 secondes. Sinon, après la période de grâce, Snowflake termine tous les processus du conteneur.
Mise à jour du code de service de redéploiement du service¶
Une fois qu’un service est créé, utilisez la commande ALTER SERVICE … <fromSpecification> pour mettre à jour le code du service et redéployer le service.
Commencez par charger le code d’application modifié dans votre référentiel d’images. Exécutez ensuite la commande ALTER SERVICE, soit en fournissant la spécification de service en ligne, soit en spécifiant le chemin d’accès à un fichier de spécification dans la zone de préparation Snowflake. Par exemple :
ALTER SERVICE echo_service
FROM SPECIFICATION $$
spec:
…
…
$$;
Dès réception de la requête, Snowflake redéploie le service en utilisant le nouveau code.
Note
Lorsque vous exécutez la commande CREATE SERVICE … <fromSpecification>, Snowflake enregistre la version spécifique de l’image fournie. Snowflake déploie cette même version d’image dans les scénarios suivants, même si l’image dans le référentiel a été mise à jour :
Lorsqu’un service suspendu est repris (en utilisant ALTER SERVICE … RESUME).
Lorsque la mise à l’échelle automatique ajoute davantage d’instances de service.
Lorsque les instances de service sont redémarrées pendant la maintenance du cluster.
Mais lorsque vous appelez ALTER SERVICE … <fromSpecification>, Snowflake utilise la dernière version du référentiel pour cette image.
Si vous êtes le propriétaire du service, la sortie de la commande DESCRIBE SERVICE inclut la spécification du service, qui inclut le condensé d’image (la valeur du champ sha256 dans la spécification), comme indiqué ci-dessous :
spec:
containers:
- name: "echo"
image: "/tutorial_db/data_schema/tutorial_repository/my_echo_service_image:latest"
sha256: "@sha256:8d912284f935ecf6c4753f42016777e09e3893eed61218b2960f782ef2b367af"
env:
SERVER_PORT: "8000"
CHARACTER_NAME: "Bob"
readinessProbe:
port: 8000
path: "/healthcheck"
endpoints:
- name: "echoendpoint"
port: 8000
public: true
ALTER SERVICE peut avoir un impact sur les communications (voir Utilisation d’un service) avec le service.
Si ALTER SERVICE … <fromSpecification> supprime un point de terminaison ou supprime les autorisations pertinentes requises pour utiliser un point de terminaison (voir serviceRoles dans la référence de spécification), l’accès au service échouera. Pour plus d’informations, voir Utilisation d’un service.
Pendant que la mise à niveau est en cours, de nouvelles connexions peuvent être acheminées vers la nouvelle version. Si la nouvelle version du service n’est pas rétrocompatible, elle perturbera toute utilisation active du service. Par exemple, les requêtes en cours utilisant une fonction de service peuvent échouer.
Note
Lors de la mise à jour du code de service qui fait partie d’une application native avec des conteneurs, vous pouvez utiliser la fonction système SYSTEM$WAIT_FOR_SERVICES permettant de mettre en pause le script d’installation de l’application native pour permettre la mise à niveau complète des services. Pour plus d’informations, voir Upgrade an app (Legacy).
Surveillance des mises à jour progressives¶
Lorsque plusieurs instances de service sont en cours d’exécution, Snowflake effectue une mise à jour progressive par ordre décroissant en fonction de l’ID des instances de service. Utilisez les commandes suivantes pour surveiller les mises à jour du service :
DESCRIBE SERVICE et SHOW SERVICES :
La colonne
is_upgradingdans la sortie indique TRUE si le service est en cours de mise à niveau.La colonne
spec_digestdans la sortie représente le condensé de spécifications de la spécification de service actuelle. Vous pouvez exécuter cette commande périodiquement ; un changement dans la valeurspec_digestindique qu’une mise à niveau du service a été déclenchée. La colonnespec_digestn’est utilisée qu’une fois queis_upgradingest sur FALSE. Dans le cas contraire, la mise à niveau du service est toujours en cours.Utilisez la commande SHOW SERVICE INSTANCES IN SERVICE pour vérifier si toutes les instances ont été mises à jour vers la dernière version comme expliqué ci-dessous.
SHOW SERVICE INSTANCES IN SERVICE :
La colonne
statusdans la sortie fournit le statut de chaque instance de service individuelle pendant que la mise à niveau progressive est en cours. Pendant la mise à niveau, vous observerez le statut de transition de chaque instance de service, tel que TERMINATING à PENDING, et PENDING à READY.Lors de la mise à niveau du service, la colonne
spec_digestdans la sortie de cette commande peut afficher une valeur différente de celle de SHOW SERVICES, qui renvoie toujours le dernier condensé de spécifications. Cette différence indique simplement que la mise à niveau du service est en cours et que les instances de service exécutent toujours l’ancienne version du service.
Obtenir des informations sur les services¶
Vous pouvez utiliser ces commandes :
Utilisez la commande DESCRIBE SERVICE permettant de récupérer les propriétés et le statut d’un service. La sortie renvoie toutes les propriétés du service.
Utilisez la commande SHOW SERVICES pour lister les services actuels (y compris les services de tâche) pour lesquels vous disposez d’autorisations. La sortie fournit certaines propriétés et le statut de ces services.
Par défaut, la sortie répertorie les services de la base de données et du schéma actuels. Vous pouvez également spécifier l’une des portées suivantes. Par exemple :
Répertoriez les services du compte, d’une base de données spécifique ou d’un schéma spécifique : Par exemple, utilisez le filtre IN ACCOUNT pour répertorier les services de votre compte Snowflake, quelle que soit la base de données ou le schéma auquel appartiennent les services. Ceci est utile si vous avez des services Snowflake créés dans plusieurs bases de données et schémas dans votre compte. Comme toutes les autres commandes, SHOW SERVICES IN ACCOUNTS est limitée par les privilèges et ne renvoie que les services pour lesquels le rôle que vous utilisez dispose d’autorisations de visualisation.
Vous pouvez également spécifier IN DATABASE ou IN SCHEMA pour établir la liste des services de la base de données ou du schéma actuel (ou spécifié).
Répertoriez les services exécutés dans un pool de calcul : Par exemple, utilisez le filtre IN COMPUTE POOL pour répertorier les services exécutés dans un pool de calcul.
Répertoriez les services qui commencent par un préfixe ou qui correspondent à un modèle : Vous pouvez appliquer les filtres LIKE et STARTS WITH pour filtrer les services par nom.
Répertoriez les services de travail ou excluez les services de travail de la liste : Vous pouvez utiliser SHOW JOB SERVICES ou SHOW SERVICES EXCLUDE JOBS pour répertorier uniquement les services de travail ou exclure certains services de travail.
Vous pouvez également combiner ces options pour personnaliser la sortie de SHOW SERVICES.
Utilisez la commande SHOW SERVICE INSTANCES IN SERVICE pour récupérer les propriétés des instances de service.
Utilisez la commande SHOW SERVICE CONTAINERS IN SERVICE pour récupérer les propriétés et le statut des instances de service.
Appelez la fonction GET_JOB_HISTORY permettant d’obtenir les historiques des tâches qui ont été exécutées dans un intervalle de temps spécifié.
Appelez la fonction <service_name>!SPCS_WAIT_FOR permettant d’attendre et de récupérer l’état du service – y compris l’état d’un service associé aux tâches – au bout d’un certain temps.
Surveiller les services¶
Snowpark Container Services propose des outils pour surveiller les pools de calcul de votre compte et les services exécutés sur ceux-ci. Pour plus d’informations, voir Snowpark Container Services : services de surveillance.
Utilisation d’un service¶
Après avoir créé un service, les utilisateurs du même compte (qui a créé le service) peuvent l’utiliser. Il existe trois méthodes pour utiliser un service, comme l’illustre le schéma. L’utilisateur doit accéder aux rôles disposant des privilèges nécessaires.
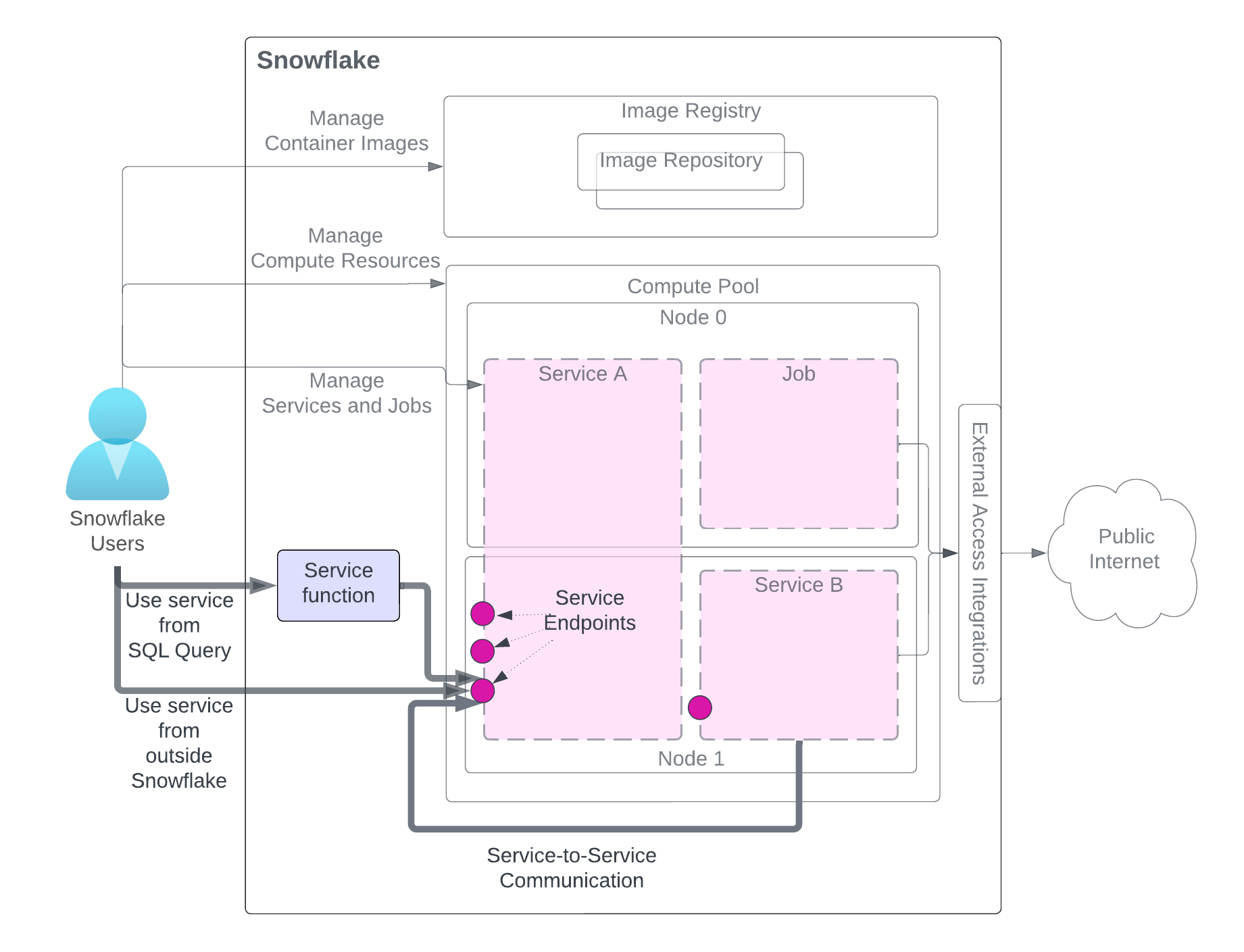
Le schéma met en évidence les méthodes d’utilisation du service, tandis que les autres composants liés au service sont grisés pour plus de clarté. Pour une explication détaillée des composants du service, reportez-vous au schéma au début de cette page.
Utilisez le service à partir d’une requête SQL (Fonction de service) : Vous créez une fonction de service, une fonction définie par l’utilisateur (UDF) associée à un service, et vous l’utilisez dans une requête SQL et tirez parti du traitement personnalisé des données que votre service fournit. Pour un exemple, voir le tutoriel 1.
Utilisez le service depuis l’extérieur de Snowflake (Entrée) : vous pouvez déclarer un ou plusieurs points de terminaison de service comme publics pour autoriser l’accès réseau au service. Ceci peut être utilisé pour construire des applications Web ou des APIs exposées sur vos données Snowflake. Pour un exemple, voir le tutoriel 1.
Utiliser le service d’un autre service (Communications de service à service) : Les services peuvent communiquer entre eux en utilisant le nom DNS du service attribué par Snowflake pour la communication de service à service. Pour un exemple, voir Tutoriel 4.
Comme le montre le schéma, lorsque vous communiquez avec un service à l’aide de l’une de ces méthodes, vous envoyez des requêtes aux points de terminaison que le service expose et vous obtenez des résultats.
Note
Les fonctions de service ne peuvent pas être utilisées pour communiquer avec un service associé aux tâches.
Les sections suivantes fournissent des détails.
Fonctions de service : utilisation d’un service à partir d’une requête SQL¶
Une fonction de service est une fonction définie par l’utilisateur (UDF) que vous créez à l’aide de CREATE FUNCTION (Snowpark Container Services). Cependant, au lieu d’écrire directement le code de l’UDF, vous associez l’UDF à votre point de terminaison de service. Notez que vous ne pouvez associer une fonction de service qu’à un point de terminaison de service prenant en charge le protocole HTTP (voir Champ spec.endpoints (facultatif)).
Par exemple, dans le tutoriel 1, vous créez un service nommé echo_service qui expose un point de terminaison (echoendoint) tel que défini dans la spécification du service :
spec:
…
endpoints:
- name: echoendpoint
port: 8080
echoendpoint est un nom de point de terminaison convivial qui représente le port correspondant (8080). Pour communiquer avec ce point de terminaison de service, vous créez une fonction de service en fournissant les paramètres SERVICE et ENDPOINT comme indiqué :
CREATE FUNCTION my_echo_udf (text varchar)
RETURNS varchar
SERVICE=echo_service
ENDPOINT=echoendpoint
AS '/echo';
Le paramètre AS fournit le chemin HTTP vers le code de service. Vous obtenez cette valeur de chemin à partir du code du service. Par exemple, les lignes de code suivantes proviennent de service.py dans Tutoriel 1.
@app.post("/echo")
def echo():
...
Vous appelez la fonction de service dans une instruction SELECT telle que la suivante :
SELECT service_function_name(<parameter-list>);
Snowflake dirige la requête vers le point de terminaison et le chemin du service associé.
Note
Une fonction de service est utilisée pour communiquer avec un service, et non avec une tâche. En d’autres termes, vous ne pouvez associer qu’un service (et non une tâche) à une fonction de service.
Format d’échange de données¶
Pour l’échange de données entre une fonction de service et un conteneur d’application, Snowflake suit le même format que celui utilisé par les fonctions externes (voir Formats de données). Par exemple, supposons que vous ayez des lignes de données stockées dans une table (input_table) :
"Alex", "2014-01-01 16:00:00"
"Steve", "2015-01-01 16:00:00"
…
Pour envoyer ces données à votre service, vous invoquez la fonction de service en lui transmettant ces lignes en tant que paramètres :
SELECT service_func(col1, col2) FROM input_table;
Snowflake envoie une série de requêtes au conteneur, avec des lots de lignes de données dans le corps de la requête dans ce format :
{
"data":[
[
0,
"Alex",
"2014-01-01 16:00:00"
],
[
1,
"Steve",
"2015-01-01 16:00:00"
],
…
[
<row_index>,
"<column1>",
"<column2>"
],
]
}
Le conteneur renvoie ensuite la sortie dans le format suivant :
{
"data":[
[0, "a"],
[1, "b"],
…
[ row_index, output_column1]
]
}
L’exemple de sortie présenté suppose que le résultat est une table à une colonne avec des lignes (« a », « b »…).
Configuration du traitement par lots¶
Les commandes CREATE FUNCTION and ALTER FUNCTION prennent en charge les paramètres qui configurent la manière dont Snowflake traite les lots de données traités par votre service.
Configuration de la taille des lots
Vous pouvez utiliser le paramètre MAX_BATCH_ROWS pour limiter la taille du lot, c’est-à-dire le nombre maximum de lignes que Snowflake envoie à votre service dans une seule requête. Cela permet de contrôler le volume des données transférées. Cela peut également se traduire par des lots plus nombreux et plus petits qui peuvent être traités en parallèle si votre service prend en charge plusieurs instances ou requêtes simultanées.
Gestion des erreurs
Vous pouvez utiliser les paramètres suivants pour le traitement des erreurs par lot :
ON_BATCH_FAILURE,MAX_BATCH_RETRIESetBATCH_TIMEOUT_SECS.
Par exemple, la commande ALTER FUNCTION suivante configure les paramètres MAX_BATCH_ROWS et MAX_BATCH_RETRIES de la fonction de service my_echo_udf :
ALTER FUNCTION my_echo_udf(VARCHAR) SET
MAX_BATCH_ROWS = 15
MAX_BATCH_RETRIES = 5;
Privilèges requis pour créer et gérer des fonctions de service¶
Pour créer et gérer des fonctions de service, un rôle doit disposer des privilèges suivants :
Le rôle actuel doit avoir le rôle de service accordé pour le point de terminaison référencé dans la commande CREATE FUNCTION ou ALTER FUNCTION.
Pour utiliser une fonction de service dans une requête SQL, la session en cours doit avoir un rôle avec des privilèges d’utilisation sur la fonction de service et le rôle de propriétaire de la fonction de service doit se voir accorder le rôle de service pour le point de terminaison de service associé.
L’exemple de script suivant montre comment vous pouvez accorder des autorisations de création et d’utilisation d’une fonction de service :
USE ROLE service_owner;
GRANT USAGE ON DATABASE service_db TO ROLE func_owner;
GRANT USAGE ON SCHEMA my_schema TO ROLE func_owner;
GRANT SERVICE ROLE ON service service_db.my_schema.my_service!all_endpoints_usage TO ROLE func_owner;
USE ROLE func_owner;
CREATE OR REPLACE test_udf(v VARCHAR)
RETURNS VARCHAR
SERVICE=service_db.my_schema.my_service
ENDPOINT=endpointname1
AS '/run';
SELECT test_udf(col1) FROM some_table;
ALTER FUNCTION test_udf(VARCHAR) SET
SERVICE = service_db.other_schema.other_service
ENDPOINT=anotherendpoint;
GRANT USAGE ON DATABASE service_db TO ROLE func_user;
GRANT USAGE ON SCHEMA my_schema TO ROLE func_user;
GRANT USAGE ON FUNCTION test_udf(varchar) TO ROLE func_user;
USE ROLE func_user;
SELECT my_test_udf('abcd');
Entrée : utilisation d’un service en dehors de Snowflake¶
Vous pouvez déclarer un ou plusieurs points de terminaison comme étant publics dans la spécification du service pour permettre aux utilisateurs d’utiliser le service à partir du public. Notez que les utilisateurs doivent être des utilisateurs Snowflake dans le même compte Snowflake que celui qui a créé le service.
spec:
...
endpoints:
- name: <endpoint name>
port: <port number>
public: true
Notez que l’entrée n’est autorisée qu’avec un point de terminaison HTTP (voir Champ spec.endpoints (facultatif)).
Authentification relative à l’entrée¶
Un utilisateur peut accéder à un point de terminaison public lorsqu’il se voit attribuer un rôle de service lui permettant d’accéder à ce point de terminaison. (voir Privilèges nécessaires pour accéder aux points de terminaison du service (rôles de service)).
Les utilisateurs peuvent ensuite accéder au point de terminaison public à l’aide d’un navigateur ou de manière programmatique.
Accès à un point de terminaison public en utilisant un navigateur : lorsqu’un navigateur est utilisé pour accéder à un point de terminaison public, Snowflake redirige automatiquement l’utilisateur vers une page de connexion. L’utilisateur doit fournir ses identifiants de connexion Snowflake pour se connecter. Une fois connecté, l’utilisateur a accès au point de terminaison. En coulisses, l’utilisateur génère un jeton OAuth depuis Snowflake. Le jeton OAuth est ensuite utilisé pour envoyer une demande au point de terminaison de service.
Pour un exemple, voir le tutoriel 1.
Accès à un point de terminaison public par programmation : les clients programmatiques peuvent accéder aux points de terminaison de trois façons :
Utilisation d’un jeton d’accès programmatique (PAT) : Votre application transmet le jeton dans l’en-tête
Authorizationdes requêtes au point de terminaison pour représenter son identité.Utilisation de l’authentification par paire de clés : Votre application génère un JWT en utilisant une paire de clés, échange le JWT avec Snowflake contre un jeton OAuth, puis transmet le jeton OAuth dans l’en-tête
Authorizationdes requêtes au point de terminaison pour représenter son identité.Utilisation du connecteur Python : Votre application utilise le connecteur Python pour générer un jeton de session, puis transmet le jeton de session dans l’en-tête
Authorizationdes requêtes au point de terminaison pour représenter son identité.
Pour des exemples connexes, voir Tutoriel 8.
En-têtes spécifiques à l’utilisateur dans les demandes d’entrée¶
Lorsqu’une requête pour un point de terminaison public arrive, Snowflake transmet automatiquement l’en-tête suivant avec la requête HTTP au conteneur.
Sf-Context-Current-User: <user_name>
Le code de votre conteneur peut éventuellement lire cet en-tête, savoir qui est l’appelant et appliquer une personnalisation spécifique au contexte pour différents utilisateurs. En outre, Snowflake peut éventuellement inclure l’en-tête Sf-Context-Current-User-Email. Pour inclure cet en-tête, contactez le support Snowflake.
Communications de service à service¶
Les instances de service peuvent communiquer directement entre elles sur TCP (y compris HTTP). Ceci est vrai tant pour les instances qui appartiennent au même service que pour les instances qui appartiennent à des services différents.
Les instances ne peuvent recevoir de communications (requêtes) que sur les points de terminaison déclarés dans la spécification du service. Le client (le service qui envoie la requête) doit disposer des rôles et des autorisations nécessaires pour se connecter à ce point de terminaison (voir Privilèges nécessaires pour accéder aux points de terminaison du service (rôles de service)).
Par défaut, une instance de service peut se connecter à d’autres instances du même service sur les points de terminaison déclarés. En termes plus généraux, le rôle de propriétaire d’un service a des autorisations pour se connecter aux points de terminaison des services ayant le même rôle de propriétaire.
Pour qu’un service client puisse se connecter à un point de terminaison d’un service dont le rôle propriétaire est différent, le rôle propriétaire du service client a besoin du rôle de service qui accorde l’accès au point de terminaison d’un autre service pour appeler ce point de terminaison. Pour plus d’informations, voir Privilèges nécessaires pour accéder aux points de terminaison du service (rôles de service).
Si vous souhaitez empêcher vos services de communiquer entre eux (pour des raisons de sécurité, par exemple), utilisez différents rôles Snowflake pour créer ces services.
Une instance de service peut être jointe en utilisant soit l’adresse IP du service, soit les adresses IP de l’instance de service.
Les requêtes utilisant l’adresse IP du service sont routées vers un répartiteur de charge qui, à son tour, achemine les requêtes vers une instance de service sélectionnée de manière aléatoire.
Les requêtes utilisant l’adresse IP de l’instance de service sont routées directement vers l’instance de service concernée. Vous devez utiliser l’IP de l’instance de service lorsque vous vous connectez à un point de terminaison défini à l’aide du champ
portRange(voir Champ spec.endpoints (facultatif)).
Les deux adresses IP peuvent être découvertes à l’aide du nom DNS que Snowflake attribue automatiquement à chaque service. Notez qu’il n’est pas possible d’utiliser DNS pour se connecter à une instance spécifique. Par exemple, il n’est pas logique de construire une URL en utilisant le nom de l’instance de service DNS, car il n’y a aucun moyen d’utiliser le nom de l’instance de service DNS pour faire référence à une instance de service spécifique.
Les adresses IP de l’instance de service sont indiquées dans la sortie de la commande SHOW SERVICE INSTANCES IN SERVICE lorsque le bundle de changements de comportement 2025_01 est activé.
Pour un exemple de communication de service à service, voir Tutoriel 4.
Notez que si un point de terminaison de service est créé uniquement pour permettre des communications de service à service, le protocole TCP doit être utilisé (voir Champ spec.endpoints (facultatif)).
Nom du service DNS¶
Le format du nom DNS est le suivant :
<service-name>.<hash>.svc.spcs.internal
Utilisez SHOW SERVICES (ou DESCRIBE SERVICE) pour obtenir le nom DNS d’un service. Le nom DNS qui précède est un nom pleinement qualifié. Les services créés dans le même schéma peuvent communiquer en utilisant uniquement <service-name>. Les services qui se trouvent dans un schéma ou une base de données différents doivent fournir le hachage, comme <nom-service>.<hachage> ou fournir le nom complet (<nom-service>.<hachage>.svc.spcs.internal).
Utilisez la fonction SYSTEM$GET_SERVICE_DNS_DOMAIN pour trouver le domaine DNS pour un schéma donné. Le domaine de hachage DNS est spécifique à la version actuelle du schéma. Remarques :
Si ce schéma ou sa base de données est renommé, le hachage ne change pas.
Si le schéma est supprimé puis recréé (par exemple à l’aide de CREATE OR REPLACE SCHEMA), le nouveau schéma aura un nouveau hachage. Si vous UNDROP un schéma, le hachage reste le même.
Les noms DNS présentent les limitations suivantes :
Le nom de votre service doit être un label DNS valide. (Voir aussi https://www.ietf.org/rfc/rfc1035.html#section-2.3.1). Sinon, la création d’un service échouera.
Snowflake remplace le trait de soulignement (_) dans le nom du service par un tiret (-) dans le nom DNS.
Un nom DNS est uniquement destiné aux communications internes au sein de Snowflake entre les services fonctionnant dans le même compte. Il n’est pas accessible depuis Internet.
Nom DNS des instances de service¶
Le format du nom des instances de service DNS est le suivant :
instances.<service-name>.<hash>.svc.spcs.internal
Il renvoie à une liste d’adresses IP d’instances de service, une pour chaque instance du service. Notez qu’il n’y a pas d’ordre garanti dans la liste des adresses IP renvoyées par DNS. Ce nom DNS ne doit être utilisé qu’avec des APIs DNS, et non comme nom d’hôte dans une URL. L’idée est que votre application utilise ce nom d’hôte avec des APIs DNS pour collecter l’ensemble des IPs d’instances de service et se connecte ensuite directement par programme à ces IPs d’instances.
Cette liste d’adresses IP permet de créer un réseau maillé pour la communication directe entre des instances de services spécifiques.
Quel nom DNS choisir ?¶
Les considérations suivantes s’appliquent au choix du nom DNS à utiliser lors de la connexion à un service dans le cadre d’une communication de service à service.
Utilisez le nom du service DNS lorsque l’une des conditions suivantes est remplie :
Vous devez accéder à un port de destination spécifique de la manière la plus simple possible.
Vous souhaitez que chaque requête soit envoyée à une instance de service sélectionnée de manière aléatoire.
Vous ne savez pas comment votre cadre d’application exécute et cache les réponses DNS.
Utilisez le nom DNS de l’instance de service ou l’IP de l’instance de service lorsque l’une des conditions suivantes est remplie :
Vous souhaitez découvrir les adresses IP de toutes les instances de service.
Vous voulez sauter un équilibreur de charge intermédiaire.
Vous utilisez des frameworks ou des bases de données distribuées, telles que Ray ou Cassandra, qui utilisent les adresses IP des instances de service en tant qu’identités.
Gérer les types de services autorisés dans votre compte¶
Snowflake prend en charge différents types de services (types de charges de travail) que vous pouvez créer dans votre compte. Ces types incluent les charges de travail déployées par l’utilisateur, telles que les services et les tâches, ainsi que les charges de travail propriétaires qui sont gérées par Snowflake, telles que les notebooks, le service de modèles et les tâches de ML. Pour une liste des types de charge de travail, consultez ALLOWED_SPCS_WORKLOAD_TYPES.
Lorsque vous répertoriez les services dans votre compte à l’aide de SHOW SERVICES, vous pouvez inclure un filtre pour répertorier uniquement des types de charge de travail spécifiques. Par exemple, vous pouvez afficher uniquement les services déployés par l’utilisateur :
SHOW SERVICES OF TYPE USER;
Vous pouvez restreindre les types de charge de travail qui sont autorisés dans votre compte Snowflake en utilisant les paramètres ALLOWED_SPCS_WORKLOAD_TYPES et DISALLOWED_SPCS_WORKLOAD_TYPES au niveau du compte. Par exemple, pour n’autoriser que les charges de travail NOTEBOOK, exécutez l’instruction suivante :
ALTER ACCOUNT SET ALLOWED_SPCS_WORKLOAD_TYPES = NOTEBOOK;
Note
Les types de charge de travail spécifiés dans DISALLOWED_SPCS_WORKLOAD_TYPES ne peuvent pas être déployés. Si vous configurez à la fois ALLOWED_SPCS_WORKLOAD_TYPES et DISALLOWED_SPCS_WORKLOAD_TYPES, la liste des charges de travail non autorisées est prioritaire. Par exemple, si les deux paramètres spécifient le type de charge de travail NOTEBOOK, les charges de travail NOTEBOOK ne peuvent pas s’exécuter sur Snowpark Container Services.
Les services qui sont créés avant que vous ne configuriez ces paramètres au niveau du compte continuent de s’exécuter. Toutefois, si vous suspendez un service dont le type de charge de travail est interdit, vous ne pouvez pas le redémarrer.
Pour supprimer tous les services précédemment créés dont les types sont interdits, exécutez la commande ALTER COMPUTE POOL … STOP ALL OF TYPE.
Transmission d’identifiants de connexion à un conteneur à l’aide de secrets Snowflake¶
Il existe de nombreuses raisons pour lesquelles vous pourriez vouloir transmettre des identifiants de connexion gérés par Snowflake à votre conteneur. Par exemple, votre service peut communiquer avec des points de terminaison externes (en dehors de Snowflake), auquel cas vous devrez fournir des identifiants de connexion dans votre conteneur pour que votre code d’application puisse les utiliser.
Pour fournir des identifiants de connexion, stockez-les d’abord dans des objets de secrets Snowflake. Ensuite, dans la spécification du service, utilisez containers.secrets pour spécifier quels objets de secrets utiliser et où les placer à l’intérieur du conteneur. Vous pouvez soit transmettre ces identifiants de connexion à des variables d’environnement dans les conteneurs, soit les rendre disponibles dans des fichiers locaux dans les conteneurs.
Spécification des secrets Snowflake¶
Spécifiez un secret Snowflake par nom ou référence (la référence n’est applicable que dans le cas de Native Application) :
Transmettez le secret Snowflake par nom : vous pouvez transmettre un nom de secret comme valeur de champ
snowflakeSecret.... secrets: - snowflakeSecret: objectName: '<secret-name>' <other info about where in the container to copy the secret> ...
Notez que vous pouvez éventuellement spécifier
<secret-name>directement comme la valeursnowflakeSecret.Transmettez le secret Snowflake par référence : lorsque vous utilisez les services de conteneurs Snowpark pour créer une Native App (une application avec des conteneurs), le producteur et les consommateurs de l’application utilisent des comptes Snowflake différents. Dans certains contextes, une Native App Snowflake installée doit accéder à des objets de secrets existants dans le compte consommateur et qui existent en dehors de l’objet APPLICATION. Dans ce cas, les développeurs peuvent utiliser la syntaxe de spécification « secrets par référence » pour gérer les identifiants de connexion comme indiqué :
containers: - name: main image: <url> secrets: - snowflakeSecret: objectReference: '<reference-name>' <other info about where in the container to copy the secret>
Notez que la spécification utilise
objectReferenceau lieu deobjectNamepour fournir un nom de référence secret.
Spécification du placement des secrets à l’intérieur du conteneur¶
Vous pouvez demander à Snowflake de placer les secrets dans les conteneurs en tant que variables d’environnement ou de les écrire dans des fichiers de conteneur locaux.
Transmettre des secrets en tant que variables d’environnement¶
Pour transmettre des secrets Snowflake aux conteneurs en tant que variables d’environnement, incluez envVarName dans le champ containers.secrets.
containers:
- name: main
image: <url>
secrets:
- snowflakeSecret: <secret-name>
secretKeyRef: username | password | secret_string | 'access_token'
envVarName: '<env-variable-name>'
La valeur secretKeyRef dépend du type de secret Snowflake. Les valeurs possibles sont les suivantes :
usernameoupasswordsi le secret Snowflake est de typepassword.secret_stringsi le secret Snowflake est de typegeneric_string.
Notez que Snowflake ne met pas à jour les secrets transmis en tant que variables d’environnement après la création d’un service.
Exemple 1 : transmission de secrets de type password comme variables d’environnement¶
Dans cet exemple, vous créez l’objet secret Snowflake suivant de type password :
CREATE SECRET testdb.testschema.my_secret_object
TYPE = password
USERNAME = 'snowman'
PASSWORD = '1234abc';
Pour fournir cet objet secret Snowflake aux variables d’environnement (par exemple, LOGIN_USER et LOGIN_PASSWORD) dans votre conteneur, ajoutez le champ containers.secrets suivant dans le fichier de spécification :
containers:
- name: main
image: <url>
secrets:
- snowflakeSecret: testdb.testschema.my_secret_object
secretKeyRef: username
envVarName: LOGIN_USER
- snowflakeSecret: testdb.testschema.my_secret_object
secretKeyRef: password
envVarName: LOGIN_PASSWORD
Dans cet exemple, la valeur snowflakeSecret est un nom d’objet complet, car les secrets peuvent être stockés dans un schéma différent de celui du service en cours de création.
Dans cet exemple, le champ containers.secrets est une liste de deux objets snowflakeSecret :
Le premier objet fait correspondre
usernamede l’objet secret de Snowflake à la variable d’environnementLOGIN_USERde votre conteneur.Le second objet fait correspondre
passwordde l’objet secret de Snowflake à la variable d’environnementLOGIN_PASSWORDde votre conteneur.
Exemple 2 : passer des secrets de type generic_string comme variables d’environnement¶
Dans cet exemple, vous créez l’objet secret Snowflake suivant de type generic_string :
CREATE SECRET testdb.testschema.my_secret
TYPE=generic_string
SECRET_STRING='
some_magic: config
';
Pour fournir cet objet secret Snowflake aux variables d’environnement (par exemple, GENERIC_SECRET) dans votre conteneur, vous ajoutez le champ containers.secrets suivant dans le fichier de spécification :
containers:
- name: main
image: <url>
secrets:
- snowflakeSecret: testdb.testschema.my_secret
secretKeyRef: secret_string
envVarName: GENERIC_SECRET
Écrire des secrets dans des fichiers de conteneurs locaux¶
Pour rendre les secrets Snowflake disponibles pour votre conteneur d’application dans des fichiers de conteneur locaux, incluez un champ containers.secrets : pour rendre les secrets Snowflake disponibles pour votre conteneur d’application dans les fichiers de conteneur locaux, incluez directoryPath dans containers.secrets :
containers:
- name: <name>
image: <url>
...
secrets:
- snowflakeSecret: <snowflake-secret-name>
directoryPath: '<local directory path in the container>'
Snowflake renseigne les fichiers nécessaires pour le secret dans ce directoryPath spécifié ; la spécification de secretKeyRef n’est pas nécessaire. Selon le type de secret, Snowflake crée les fichiers suivants dans le conteneur sous le chemin de répertoire que vous avez fourni :
usernameetpasswordsi le secret Snowflake est de typepassword.secret_stringsi le secret Snowflake est de typegeneric_string.access_tokensi le secret Snowflake est de typeoauth2.
Note
Après la création d’un service, si l’objet secret de Snowflake est mis à jour, Snowflake mettra à jour les fichiers secrets correspondants dans les conteneurs en cours d’exécution.
Exemple 1 : transmission de secrets de type password dans des fichiers de conteneurs locaux¶
Dans cet exemple, vous créez l’objet secret Snowflake suivant de type password :
CREATE SECRET testdb.testschema.my_secret_object
TYPE = password
USERNAME = 'snowman'
PASSWORD = '1234abc';
Pour que ces identifiants de connexion soient disponibles dans les fichiers conteneurs locaux, ajoutez le champ containers.secrets suivant dans le fichier de spécification :
containers:
- name: main
image: <url>
secrets:
- snowflakeSecret: testdb.testschema.my_secret_object
directoryPath: '/usr/local/creds'
Lorsque vous démarrez votre service, Snowflake crée deux fichiers à l’intérieur du conteneur : /usr/local/creds/username et /usr/local/creds/password. Votre code d’application peut alors lire ces fichiers.
Exemple 2 : transmission de secrets de type generic_string dans des fichiers de conteneurs locaux¶
Dans cet exemple, vous créez l’objet secret Snowflake suivant de type generic_string :
CREATE SECRET testdb.testschema.my_secret
TYPE=generic_string
SECRET_STRING='
some_magic: config
';
Pour fournir cet objet de secret Snowflake dans les fichiers de conteneurs locaux, vous ajoutez le champ containers.secrets suivant dans le fichier de spécifications :
containers:
- name: main
image: <url>
secrets:
- snowflakeSecret: testdb.testschema.my_secret
directoryPath: '/usr/local/creds'
Lorsque vous démarrez votre service, Snowflake crée ce fichier à l’intérieur des conteneurs : /usr/local/creds/secret_string.
Exemple 3 : transmission de secrets de type oauth2 dans des fichiers de conteneurs locaux¶
Dans cet exemple, vous créez l’objet secret Snowflake suivant de type oauth2 :
CREATE SECRET testdb.testschema.oauth_secret
TYPE = OAUTH2
OAUTH_REFRESH_TOKEN = '34n;vods4nQsdg09wee4qnfvadH'
OAUTH_REFRESH_TOKEN_EXPIRY_TIME = '2023-12-31 20:00:00'
API_AUTHENTICATION = my_integration;
Pour que ces identifiants de connexion soient disponibles dans les fichiers conteneurs locaux, ajoutez le champ containers.secrets suivant dans le fichier de spécification :
containers:
- name: main
image: <url>
secrets:
- snowflakeSecret: testdb.testschema.oauth_secret
directoryPath: '/usr/local/creds'
Snowflake récupère le jeton d’accès de l’objet secret OAuth et crée /usr/local/creds/access_token dans les conteneurs.
Lorsqu’un service utilise des secrets de type oauth2, le service est censé utiliser ce secret pour accéder à une destination Internet. Un secret oauth doit être autorisé par l’intégration d’accès externe (EAI) ; sinon CREATE SERVICE ou EXECUTE JOB SERVICE échoueront. Cette exigence d’EAI supplémentaire ne s’applique qu’aux secrets de type oauth2 et non aux autres types de secrets.
En résumé, les étapes typiques de la création d’un tel service sont les suivantes :
Créez un secret de type oauth2 (voir plus haut).
Créez un EAI pour permettre l’utilisation du secret par un service. Par exemple :
CREATE OR REPLACE EXTERNAL ACCESS INTEGRATION example_eai ALLOWED_NETWORK_RULES = (<name>) ALLOWED_AUTHENTICATION_SECRETS = (testdb.testschema.oauth_secret) ENABLED = true;
Créez un service qui inclut un champ
containers.secretsdans la spécification. Il spécifie également la propriété facultative EXTERNAL_ACCESS_INTEGRATIONS pour inclure un EAI afin de permettre l’utilisation du secret oauth2.Exemple de commande CREATE SERVICE (avec spécification en ligne) :
CREATE SERVICE eai_service IN COMPUTE POOL MYPOOL EXTERNAL_ACCESS_INTEGRATIONS = (example_eai) FROM SPECIFICATION $$ spec: containers: - name: main image: <url> secrets: - snowflakeSecret: testdb.testschema.oauth_secret directoryPath: '/usr/local/creds' endpoints: - name: api port: 8080 $$;
Pour plus d’informations sur la sortie, voir Configuration de la sortie réseau.
Lignes directrices et limitations¶
Pour plus d’informations, voir Snowpark Container Services : Lignes directrices et limitations.