Surveillance de l’activité des requêtes avec l’historique des requêtes¶
Pour surveiller l’activité des requêtes sur votre compte, vous pouvez utiliser :
Les pages Query History et Grouped Query History dans l”Snowsight.
Les Vue QUERY_HISTORY et Vue AGGREGATE_QUERY_HISTORY dans le schéma ACCOUNT_USAGE de la base de données SNOWFLAKE.
Interrogez la famille QUERY_HISTORY de fonctions de table dans INFORMATION_SCHEMA.
Dans la page Query History de l” Snowsight, vous pouvez procéder comme suit :
Surveillez les requêtes individuelles ou groupées qui sont exécutées par les utilisateurs de votre compte.
Afficher les détails des requêtes, notamment les données de performance. Dans certains cas, les détails de la requête ne sont pas disponibles.
Explorez chaque zone de préparation d’une requête exécutée dans le profil de requête.
La page Historique des requêtes vous permet d’explorer les requêtes exécutées dans votre compte Snowflake au cours des 14 derniers jours.
Dans une feuille de calcul, vous pouvez voir l’historique des requêtes exécutées dans cette feuille de calcul. Voir Afficher l’historique des requêtes.
Revoir l’historique des requêtes dans Snowsight¶
Pour accéder à la page Query History dans Snowsight, procédez comme suit :
Connectez-vous à Snowsight.
Dans le menu de navigation, sélectionnez Monitoring » Query History.
Accédez à Individual Queries ou Grouped Queries. Pour plus d’informations sur les requêtes groupées, voir Utiliser la vue Historique des requêtes groupées dans Snowsight.
Pour Individual Queries, filtrez votre vue pour obtenir les résultats les plus pertinents et les plus précis.
Si un bouton Load More apparaît en haut de la liste, cela signifie qu’il y a plus de résultats disponibles à charger. Vous pouvez obtenir le jeu de résultats suivant en sélectionnant Load More ou en faisant défiler la liste jusqu’en bas.
Privilèges requis pour consulter l’historique des requêtes¶
Vous pouvez toujours consulter l’historique des requêtes que vous avez exécutées.
Pour afficher l’historique d’autres requêtes, votre rôle actif influe sur ce que vous pouvez voir dans l” Query History :
Si votre rôle actif est le rôle ACCOUNTADMIN, vous pouvez consulter tout l’historique des requêtes pour le compte.
Si votre rôle actif dispose du privilège MONITOR ou OPERATE sur un entrepôt, vous pouvez visualiser les requêtes exécutées par d’autres utilisateurs qui utilisent cet entrepôt.
Si votre rôle actif se voit accorder le rôle de base de données GOVERNANCE_VIEWER pour la base de données SNOWFLAKE, ce dernier est suffisant pour pouvoir interroger les vues ACCOUNT_USAGE directement avec SQL, et il vous permet également de voir les Grouped Queries dans l’historique des requêtes. Cependant, ce rôle seul ne vous offre pas la possibilité de voir les Individual Queries des autres utilisateurs dans Snowsight. Pour pouvoir voir toutes les requêtes des utilisateurs (groupées comme individuelles), votre rôle doit être défini sur ACCOUNTADMIN ou se voir accorder les PRIVILEGES IMPORTED sur la base de données SNOWFLAKE. Alternativement, les deux privilèges suivants peuvent remplacer les PRIVILEGES IMPORTED :
Si votre rôle actif se voit attribuer le rôle de base de données READER_USAGE_VIEWER pour la base de données SNOWFLAKE, vous pouvez consulter l’historique des requêtes pour tous les utilisateurs des comptes de lecteur associés à votre compte. Voir Rôles des bases de données SNOWFLAKE.
Considérations relatives à l’utilisation de l’historique des requêtes¶
Lorsque vous examinez l” Query History de votre compte, tenez compte des éléments suivants :
Les détails des requêtes exécutées il y a plus de sept jours ne comprennent pas les informations User en raison de la politique de conservation des données pour les sessions. Vous pouvez utiliser le filtre utilisateur pour récupérer les requêtes exécutées par des utilisateurs individuels. Voir Filtrer l’historique des requêtes.
Pour les requêtes qui ont échoué en raison d’erreurs de syntaxe ou d’analyse, vous voyez
<redacted>au lieu de l’instruction SQL qui a été exécutée. Si vous disposez d’un rôle avec les privilèges appropriés, vous pouvez définir le paramètre ENABLE_UNREDACTED_QUERY_SYNTAX_ERROR pour afficher le texte intégral de la requête.Les filtres ainsi que les colonnes Started et End Time utilisent votre fuseau horaire actuel. Vous ne pouvez pas modifier ce paramètre. La définition du paramètre TIMEZONE pour la session ne modifie pas le fuseau horaire utilisé.
Filtrer l’historique des requêtes¶
Vous pouvez filtrer la liste de l’historique des requêtes de la manière suivante :
Statut de la requête, par exemple pour identifier les requêtes de longue durée, les requêtes ayant échoué et les requêtes en attente.
Utilisateur qui a effectué la recherche, notamment :
All pour voir tous les utilisateurs pour lesquels vous avez accès à l’historique des requêtes.
Utilisateur sous lequel vous vous êtes connecté (par défaut)
Utilisateurs individuels de Snowflake dans votre compte, si votre rôle vous permet de voir l’historique des requêtes pour d’autres utilisateurs.
Période pendant laquelle la requête a été exécutée, jusqu’à 14 jours.
Autres filtres, notamment les suivants :
SQL Text, par exemple, pour afficher les requêtes qui utilisent des instructions spécifiques, telles que GROUP BY.
Query ID, pour afficher les détails d’une requête spécifique.
Warehouse, pour afficher les requêtes qui ont été exécutées à partir d’un entrepôt spécifique.
Statement Type, pour afficher les requêtes qui utilisent un type d’instruction spécifique, comme DELETE, UPDATE, INSERT ou SELECT.
Duration, par exemple, pour identifier les requêtes de longue durée.
Session ID, pour afficher les requêtes exécutées au cours d’une session Snowflake spécifique.
Query Tag, pour afficher les requêtes avec une balise de requête spécifique définie par le paramètre de session QUERY_TAG.
Parameterized Query Hash, pour afficher les requêtes groupées en fonction de l’ID de hachage de requête défini spécifié dans le filtre. Pour plus d’informations, voir Utilisation du hachage de la requête paramétrée (query_parameterized_hash).
Client generated statements, pour visualiser les requêtes internes exécutées par un client, un pilote ou une bibliothèque, notamment l’interface Web. Par exemple, chaque fois qu’un utilisateur accède à la page Warehouses dans Snowsight, Snowflake exécute une instruction SHOW WAREHOUSES en arrière-plan. Cette instruction sera visible lorsque ce filtre est activé. Votre compte n’est pas facturé pour les instructions générées par le client.
Queries executed by user tasks, pour visualiser les instructions SQL exécutées ou les procédures stockées appelées par les tâches de l’utilisateur.
Show replication refresh history, pour afficher les requêtes utilisées pour effectuer des tâches d’actualisation de la réplication vers des régions et des comptes distants.
Si vous souhaitez obtenir des résultats en temps quasi réel, activez Auto Refresh. Lorsque l’option Auto Refresh est activée, la table est actualisée toutes les dix secondes.
Les colonnes suivantes apparaissent par défaut dans la table Queries par défaut :
SQL Text, le texte de l’instruction exécutée (toujours affiché).
Query ID, l’ID de la requête (toujours affiché).
Status, le statut de l’instruction exécutée (toujours affiché).
User, pour voir le nom d’utilisateur qui a exécuté une instruction.
Warehouse, pour voir l’entrepôt utilisé pour exécuter une instruction.
Duration, pour voir le temps nécessaire à l’exécution d’une instruction.
Started, pour voir l’heure à laquelle une instruction a commencé à être exécutée.
Si vous avez plus de résultats, vous ne pouvez pas trier la table. Si vous sélectionnez Load More en tête de liste après avoir trié la table, les nouveaux résultats seront ajoutés à la fin des données et l’ordre de tri ne s’appliquera plus.
Pour afficher des informations plus spécifiques, vous pouvez sélectionner Columns pour ajouter ou supprimer des colonnes de la table, par exemple :
All pour afficher toutes les colonnes.
User pour afficher l’utilisateur qui a exécuté l’instruction.
Warehouse pour afficher le nom de l’entrepôt utilisé pour exécuter l’instruction.
Warehouse Size pour afficher la taille de l’entrepôt utilisé pour exécuter l’instruction.
Duration pour afficher le temps d’exécution de l’instruction.
Started pour afficher l’heure de début de l’instruction.
End Time pour afficher l’heure de fin de l’instruction.
Session ID pour afficher l’ID de la session qui a exécuté l’instruction.
Client Driver pour afficher le nom et la version du client, du pilote ou de la bibliothèque utilisés pour exécuter l’instruction. Les instructions exécutées dans Snowsight affichent
Go 1.1.5.Bytes Scanned pour afficher le nombre d’octets analysés pendant le traitement de la requête.
Rows pour afficher le nombre de lignes renvoyées par une instruction.
Query Tag pour afficher l’ensemble des balises d’une requête.
Parameterized Query Hash pour afficher les requêtes groupées en fonction de l’ID de hachage de requête paramétré spécifié dans le filtre. Pour plus d’informations, voir Utilisation du hachage de la requête paramétrée (query_parameterized_hash).
Incident pour afficher les détails des instructions dont le statut d’exécution est incident, à des fins de dépannage ou de débogage.
Pour voir des détails supplémentaires sur une requête, sélectionnez une requête dans la table pour ouvrir les Query Details.
Utiliser la vue Historique des requêtes groupées dans Snowsight¶
Vous pouvez utiliser la vue Grouped Query History dans l”Snowsight pour surveiller l’utilisation et les performances des requêtes critiques et fréquemment exécutées. Cette vue graphique est basée sur les informations enregistrées dans Vue AGGREGATE_QUERY_HISTORY. Les requêtes exécutées sont groupées par un ID de hachage de requête paramétré. Vous pouvez suivre l’évolution des statistiques clés dans le temps et analyser les requêtes individuelles appartenant à chaque groupe.
Bien que cette vue comprenne toutes les requêtes effectuées sur Snowflake, elle est particulièrement utile pour surveiller et analyser les charges de travail Unistore qui exécutent un petit nombre d’instructions distinctes de manière répétée à un débit élevé. Pour les charges de travail qui impliquent des tables hybrides, il est difficile de contrôler les performances en examinant les requêtes individuelles.
Par exemple, votre charge de travail peut consister en des milliers de requêtes et d’insertions ponctuelles très similaires qui ne varient qu’en fonction de l’ID utilisateur, qui s’exécutent extrêmement rapidement et qui se répètent à un rythme tel qu’il est impossible de les analyser individuellement. Une vue d’ensemble de ces opérations est indispensable pour répondre à ce type de questions :
Quelles requêtes groupées (ou requêtes paramétrées) consomment le plus de temps ou de ressources dans mon compte ou dans ma charge de travail ?
Les performances d’une requête paramétrée ont-elles sensiblement changé au fil du temps ?
Quels sont les problèmes rencontrés par une requête paramétrée ? Verrouillage ? Mise en file d’attente ? Des temps de compilation longs ?
Quelle est la fréquence de réussite ou d’échec d’une requête paramétrée ? Moins d’un pour cent du temps, ou plus souvent ?
Comment utiliser l’historique des requêtes groupées ?¶
Pour accéder à l”Grouped Query History dans l”Snowsight, procédez comme suit :
Connectez-vous à Snowsight.
Dans le menu de navigation, sélectionnez Monitoring » Query History » Grouped Queries. La page vous présente des requêtes groupées par leur ID de hachage de requête paramétrée.
Note
Les requêtes individuelles n’apparaissent pas immédiatement dans la liste Grouped Queries. Le temps de latence pour la mise à jour de la liste à partir des enregistrements de la vue AGGREGATE_QUERY_HISTORY peut atteindre 180 minutes (3 heures), mais la liste est souvent alimentée beaucoup plus rapidement.
Sélectionnez n’importe quelle requête groupée pour voir les statistiques de performance pour ce hachage de requêtes paramétré. L”Snowsight affiche le nombre total de requêtes exécutées, le nombre de requêtes qui ont échoué, la latence (p50, p90, p99) et les exécutions par minute. La section inférieure de la page présente quelques échantillons de requêtes individuelles exécutées dans le cadre de ce hachage ; vous pouvez sélectionner chaque requête pour en voir les détails.
Par exemple, au cours de la dernière journée, environ 540 requêtes ont été exécutées dans ce groupe, pour une durée totale d’environ 3 heures :
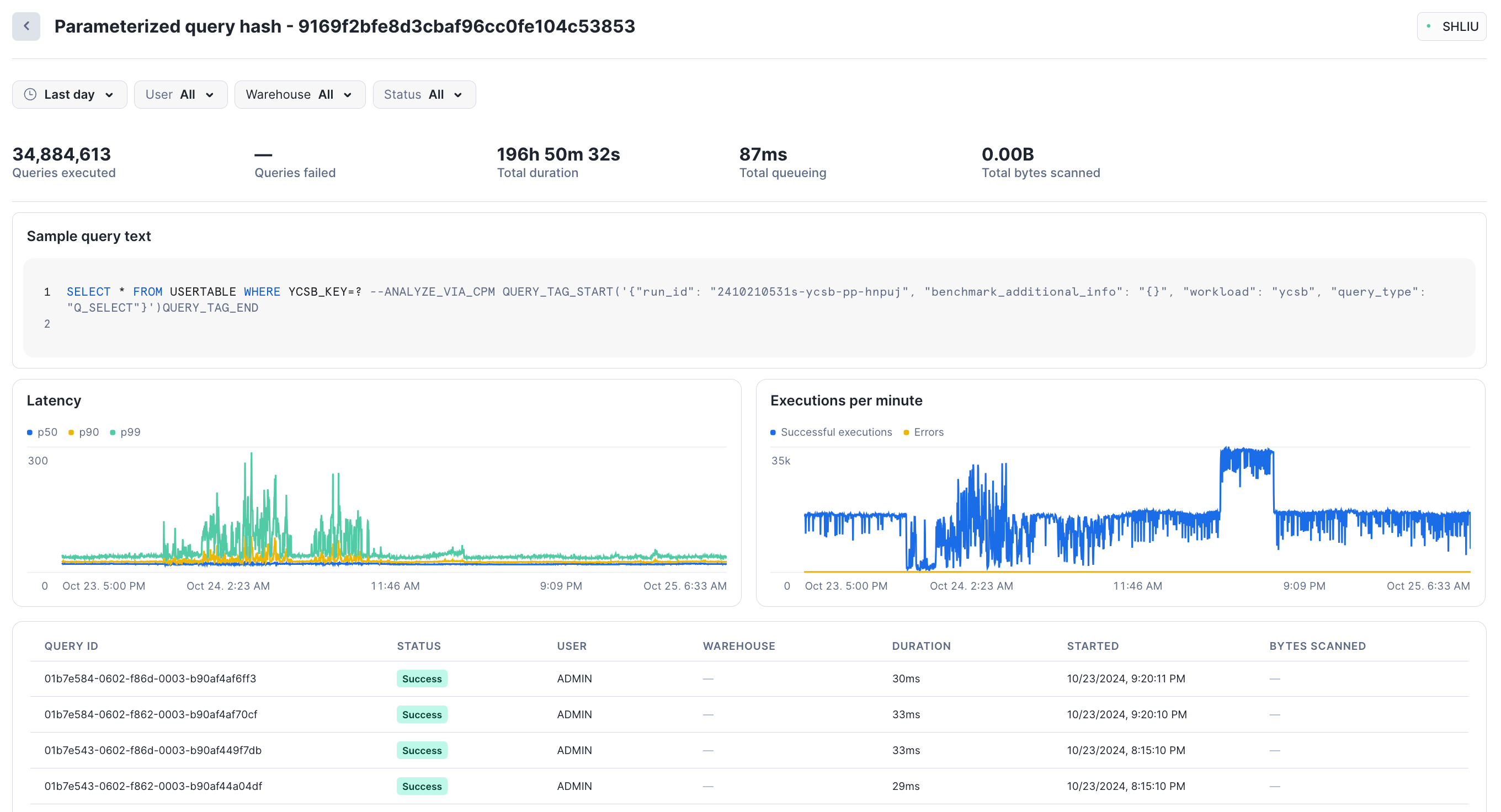
Dans la vue Parameterized query hash, vous pouvez filtrer les requêtes par état, comme``Failed`` ou Successful. Dans les deux vues Grouped Queries et Parameterized query hash, vous pouvez filtrer par plage de dates, par utilisateur et par entrepôt. La plage de dates est limitée à un maximum des 14 derniers jours de l’historique des requêtes groupées. Vous ne pouvez pas récupérer d’informations sur les requêtes qui ont été exécutées il y a plus de 14 jours.
Notez que certains entrepôts sont des entrepôts internes gérés par Snowflake, et que ces entrepôts n’apparaissent pas dans le filtre Warehouse. De même, l’utilisateur SYSTEM n’apparaît pas dans le filtre User.
Au lieu d’utiliser des filtres, vous pouvez exécuter des requêtes agrégées qui renvoient des résultats filtrés. Consultez aussi l’Vue AGGREGATE_QUERY_HISTORY.
Liste des requêtes individuelles¶
Vous pouvez également consulter les Individual Queries. Cette vue ne reflète pas toutes les requêtes exécutées par les charges de travail Unistore, compte tenu du volume considérable de requêtes pouvant être créées sur des tables hybrides. Pour plus d’informations sur ce comportement, consultez la section Tables hybrides de Notes sur l’utilisation . Snowflake recommande à tous les utilisateurs ayant des charges de travail Unistore de commencer par surveiller la vue Grouped Queries.
Privilèges requis pour voir l’historique des requêtes groupées¶
Les utilisateurs peuvent toujours voir “historique des requêtes qu’ils ont effectuées. Le rôle actif d’un utilisateur influe sur la visibilité des autres requêtes. Vous pouvez voir à la fois Grouped Queries et Individual Queries si l’une des conditions suivantes est remplie :
Votre rôle actif est ACCOUNTADMIN.
Votre rôle actif a reçu les IMPORTED PRIVILEGES sur la base de données SNOWFLAKE (voir Permettre à d’autres rôles d’utiliser des schémas dans la base de données SNOWFLAKE).
Vous avez le rôle de base de données GOVERNANCE_VIEWER.
Si vous ne disposez d’aucun de ces rôles ou privilèges, vous ne pouvez voir que Individual Queries. Pour plus d’informations sur les privilèges d’accès, voir Surveillance de l’activité des requêtes avec l’historique des requêtes.
Examiner les détails et le profil d’une requête spécifique¶
Lorsque vous sélectionnez une requête dans l” Query History, vous pouvez consulter les détails et le profil de la requête.
Données de profils de requête expurgées d’une Snowflake Native App¶
Snowflake Native App Framework expurge les informations du profil de requête dans les contextes suivants :
Requêtes exécutées lors de l’installation ou de la mise à niveau de l’application.
Requêtes provenant d’une procédure stockée appartenant à l’application.
Requêtes contenant une vue ou une fonction non sécurisée appartenant à l’application.
Pour chacun de ces types de requêtes, Snowsight réduit les données du profil de la requête en un seul nœud vide au lieu d’afficher l’arbre complet du profil de la requête.
Examiner les détails de la requête¶
Pour examiner les détails d’une requête spécifique et visualiser les résultats d’une requête réussie, ouvrez les Query Details d’une requête.
Vous pouvez consulter les Details pour obtenir des informations sur l’exécution de la requête, notamment :
Le statut de la requête.
Heure de début de la requête, dans le fuseau horaire local de l’utilisateur.
Heure de fin de la requête, dans le fuseau horaire local de l’utilisateur.
Taille de l’entrepôt utilisée pour exécuter la requête.
La durée de la requête.
L’ID de la requête.
Balise de la requête, si elle existe.
Le statut du pilote. Pour plus de détails, voir View the Snowflake client version.
Nom et version du client, du pilote ou de la bibliothèque utilisés pour soumettre la requête. Par exemple,
Go 1.1.5pour les requêtes exécutées avec Snowsight.L’ID de la session.
Vous pouvez voir l’entrepôt utilisé pour exécuter la requête et l’utilisateur qui a exécuté la requête répertoriée au-dessus de l’onglet Query Details.
Examinez la section SQL Text pour vérifier le texte réel de la requête. Vous pouvez passer la souris sur le texte SQL pour ouvrir l’instruction dans une feuille de calcul ou copier l’instruction. Si la requête a échoué, vous pouvez consulter les détails de l’erreur.
La section Results affiche les résultats de la requête. Vous ne pouvez voir que les 10 000 premières lignes de résultats, et seul l’utilisateur qui a lancé la requête peut voir les résultats. Sélectionnez Export Results pour exporter l’ensemble des résultats dans un fichier CSV.
Examiner le profil de requête¶
L’onglet Query Profile vous permet d’explorer le plan d’exécution de la requête et de comprendre les détails granulaires de chaque étape de l’exécution.
Le profil de requête est un outil puissant permettant de comprendre la mécanique des requêtes. Il peut être utilisé quand vous avez besoin d’en savoir plus sur les performances ou le comportement d’une requête particulière. Il est conçu pour vous aider à repérer les erreurs classiques dans les expressions de requête SQL afin d’identifier les problèmes de performance et les possibilités d’amélioration.
Cette section fournit un bref aperçu de la manière de naviguer dans le profil de requête et de l’utiliser.
Interface |
Description |
|---|---|
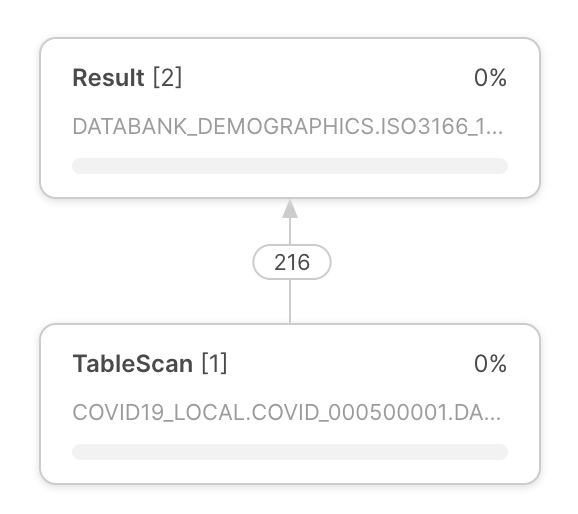
Plan d’exécution des requêtes |
Le plan d’exécution de la requête apparaît au centre du profil de la requête. Le plan d’exécution de la requête est composé de nœuds d’opérateurs, qui représentent les opérateurs rowset. Les flèches entre les nœuds d’opérateurs indiquent les rowsets qui sortent d’un opérateur et entrent dans un autre. |
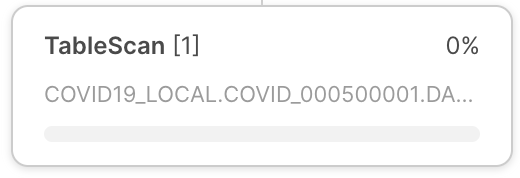
Noeud d’opérateur |
Chaque nœud d’opérateur comprend les éléments suivants :
|

Navigation dans le profil des requêtes |
Dans le coin supérieur gauche du profil des requêtes, utilisez les boutons pour :
Note Les étapes n’apparaissent que si la requête a été exécutée par étapes. |

Volets d’informations |
Le profil de requêtes fournit plusieurs volets d’informations. Les volets apparaissent dans le plan d’exécution de la requête. Les volets qui apparaissent dépendent de l’orientation du plan d’exécution de la requête. Le profil de requête comprend les volets d’information suivants :
Pour en savoir plus sur les informations disponibles dans ces volets, voir Interroger la référence du profil. |
Interroger des données historiques expurgées d’une Snowflake Native App¶
Pour les requêtes liées à une Snowflake Native App, les champs query_text et error_message sont expurgés de l’historique de la requête dans les contextes suivants :
Les requêtes sont exécutées lors de l’installation ou de la mise à niveau de l’application.
Requêtes provenant d’une tâche enfant d’une procédure stockée appartenant à l’application.
Dans chacune de ces situations, la cellule de l’historique de la requête dans Snowsight apparaît vide.
Interroger la référence du profil¶
Cette section décrit tous les éléments qui peuvent apparaître dans chaque volet d’informations. Le contenu exact des volets d’informations dépend du contexte du plan d’exécution de la requête.
Aperçu du profil¶
Le volet fournit des informations sur les tâches de traitement qui ont consommé du temps de requête. Le temps d’exécution indique le temps attribué à chaque tâche durant le traitement d’une requête. Le temps passé peut être réparti dans les catégories suivantes :
Processing — le temps consacré au traitement des données par le CPU.
Local Disk IO — l’heure à laquelle le traitement a été bloqué par l’accès au disque local.
Remote Disk IO — l’heure à laquelle le traitement a été bloqué par l’accès au disque distant.
Network Communication — l’heure à laquelle le traitement attendait le transfert des données réseau.
Synchronization — diverses activités de synchronisation entre les processus participants.
Initialization — le temps passé à configurer le traitement de la requête.
Hybrid Table Requests Throttling — le temps passé à limiter les requêtes pour lire et écrire des données stockées dans des tables hybrides.
informations sur les requêtes¶
Si certaines conditions affectent les performances de l’exécution des requêtes, ce panneau fournit des insights sur ces conditions. Chaque information comprend un message qui explique comment les performances de la requête peuvent être affectées et fournit une recommandation générale pour les étapes suivantes.
Pour plus d’informations, voir Utilisation des insights de requêtes pour améliorer les performances.
Note
Vous pouvez également accéder à ces insights en interrogeant les Vue QUERY_INSIGHTS.
Statistiques¶
Les diverses statistiques, regroupées dans les sections suivantes, constituent une source importante d’informations dans le panneau de détails :
IO — informations sur les opérations d’entrée-de sortie effectuées pendant la requête :
Progression de l’analyse — le pourcentage de données analysées pour une table donnée jusqu’à présent.
Octets analysés — le nombre d’octets analysés jusqu’à présent.
Pourcentage de données analysées à partir du cache — le pourcentage de données analysées à partir du cache du disque local.
Octets écrits — octets écrits (par exemple lors du chargement dans une table).
Octets écrits dans le résultat — octets écrits dans l’objet de résultat. Par exemple,
select * from . . .produirait un jeu de résultats sous forme de tableau représentant chaque champ de la sélection. En général, l’objet de résultats représente tout ce qui est produit comme résultat de la requête, et Octets écrits dans le résultat représente la taille du résultat retourné.Octets lus à partir d’un résultat — octets lus à partir de l’objet de résultat.
Octets externes analysés — octets lus à partir d’un objet externe, par exemple une zone de préparation.
DML — Statistiques des requêtes Data Manipulation Language (DML) :
Nombre de lignes insérées — nombre de lignes insérées dans une ou plusieurs tables.
Nombre de lignes mises à jour — nombre de lignes mises à jour dans une table.
Nombre de lignes supprimées — nombre de lignes supprimées dans une table.
Nombre de lignes déchargées — nombre de lignes déchargées lors de l’exportation des données.
Pruning — informations sur les effets de l’élagage de table :
Partitions analysées — nombre de partitions analysées jusqu’à présent.
Nombre total de partitions — nombre total de partitions dans une table donnée.
Spilling — informations sur l’utilisation du disque pour les opérations où les résultats intermédiaires ne rentrent pas dans la mémoire :
Octets déversés sur le stockage local — volume de données déversées sur le disque local (« spill to disk »).
Octets déversés sur le stockage distant — volume de données déversées sur le disque distant (« spill to disk »).
Network — communication réseau :
Octets envoyés sur le réseau — quantité de données envoyées sur le réseau.
External Functions — informations sur les appels à des fonctions externes :
Les statistiques suivantes sont affichées pour chaque fonction externe appelée par l’instruction SQL. Si la même fonction a été appelée plusieurs fois à partir de la même instruction SQL, les statistiques sont agrégées.
Nombre total d’appels — nombre de fois qu’une fonction externe a été appelée. (Cela peut être différent du nombre d’appels de fonctions externes dans le texte de l’instruction SQL en raison du nombre de lots dans lesquels les lignes sont divisées, du nombre de tentatives (en cas de problèmes de réseau transitoires), etc.)
Lignes envoyées — nombre de lignes envoyées aux fonctions externes.
Lignes reçues — nombre de lignes reçues en retour de fonctions externes.
Octets envoyés (entre régions) — nombre d’octets envoyés aux fonctions externes. Si le libellé inclut « (entre régions) », les données ont été envoyées entre plusieurs régions (ce qui peut avoir un impact sur la facturation).
Octets reçus (entre régions) — nombre d’octets reçus depuis des fonctions externes. Si le libellé inclut « (entre régions) », les données ont été envoyées entre plusieurs régions (ce qui peut avoir un impact sur la facturation).
Tentatives en raison d’erreurs transitoires — nombre de tentatives en raison d’erreurs transitoires.
Latence moyenne par appel — La durée moyenne par appel entre le moment où Snowflake a envoyé les données et reçu les données renvoyées.
Erreurs HTTP 4xx — nombre total de requêtes HTTP ayant renvoyé un code de statut 4xx.
Erreurs HTTP 5xx — nombre total de requêtes HTTP ayant renvoyé un code de statut 5xx.
Latence par appel réussi (moy) — latence moyenne pour les requêtes HTTP réussies.
Frais généraux moyens de latence dus à la limitation — frais généraux moyens par requête réussie en raison d’un ralentissement causé par la limitation (HTTP 429).
Tentatives de lots en raison de la limitation — nombre de lots qui ont fait l’objet de nouvelles tentatives en raison d’erreurs HTTP 429.
Temps de latence par appel réussi (P50) — temps de latence du 50e centile pour les requêtes HTTP réussies. 50 pour cent de toutes les requêtes acceptées ont été traitées en moins de temps.
Temps de latence par appel réussi (P90) — 90e centile de latence pour les requêtes HTTP réussies. 90 pour cent de toutes les requêtes acceptées ont été traitées en moins de temps.
Temps de latence par appel réussi (P95) — 95e centile de latence pour les requêtes HTTP réussies. 95 pour cent de toutes les requêtes réussies ont été traitées en moins de temps.
Temps de latence par appel réussi (P99) — 99e centile de latence pour les requêtes HTTP réussies. 99 pour cent de toutes les requêtes réussies ont été traitées en moins de temps.
Extension Functions — informations sur les appels aux fonctions d’extension :
Temps de chargement du gestionnaire d’UDF Java — temps de chargement du gestionnaire d’UDF Java.
Total des appels au gestionnaire d’UDF Java — nombre d’appels au gestionnaire d’UDF Java.
Durée maximale d’exécution du gestionnaire d’UDF Java — durée maximale d’exécution du gestionnaire d’UDF Java.
Temps moyen d’exécution du gestionnaire d’UDF Java — temps moyen d’exécution du gestionnaire d’UDF Java.
Appels process() d’UDTF Java — nombre de fois où la méthode de traitement d’UDTF Java a été appelée.
Temps d’exécution process() d’UDTF Java— temps nécessaire à l’exécution du traitement des UDTF Java.
Temps d’exécution moyen process() d’UDTF Java— temps moyen nécessaire à l’exécution du traitement des UDTF Java.
Appels au constructeur d’UDTF Java — nombre de fois où le constructeur d’UDTF Java a été appelé.
Temps d’exécution du constructeur d’UDTF Java — temps d’exécution du constructeur d’UDTF Java.
Temps d’exécution moyen du constructeur d’UDTF Java — temps d’exécution moyen du constructeur d’UDTF Java.
Appels endPartition() d’UDTF Java — nombre de fois où la méthode endPartition d’UDTF Java a été appelée.
Temps d’exécution endPartition() d’UDTF Java — temps nécessaire à l’exécution de la méthode endPartition d’UDTF Java.
Temps d’exécution moyen endPartition() d’UDTF Java — temps moyen nécessaire à l’exécution de la méthode endPartition d’UDTF Java.
Temps de téléchargement de dépendance d’UDF Java maximum — durée maximale de téléchargement des dépendances d’UDF Java.
Utilisation de mémoire JVM max — pic d’utilisation de la mémoire tel que rapporté par le JVM.
Temps de compilation du code en ligne d’UDF Java en ms — temps de compilation du code en ligne d’UDF Java.
Total des appels au gestionnaire d’UDF Python — nombre de fois où le gestionnaire d’UDF Python a été appelé.
Temps total d’exécution du gestionnaire d’UDF Python — temps total d’exécution du gestionnaire d’UDF Python.
Temps moyen d’exécution du gestionnaire d’UDF Python — temps moyen d’exécution du gestionnaire d’UDF Python.
Utilisation maximale de mémoire sandbox Python — utilisation maximale de la mémoire par l’environnement sandbox de Python.
Temps moyen de création de l’environnement Python : téléchargement et installation des paquets — temps moyen de création de l’environnement Python, y compris le téléchargement et l’installation des paquets.
Temps du solveur Conda — temps nécessaire à l’exécution du solveur Conda pour résoudre les paquets Python.
Temps de création de l’environnement Conda — temps nécessaire à la création de l’environnement Python.
Temps d’initialisation d’UDF Python — temps d’initialisation d’UDF Python.
Nombre d’octets de fichiers externes lus pour les UDFs — nombre d’octets de fichiers externes lus pour des UDFs.
Nombre de fichiers externes accédés pour des UDFs — nombre de fichiers externes accédés pour des UDFs.
Si la valeur d’un champ, par exemple « Tentatives en raison d’erreurs transitoires » est nulle, le champ n’est pas affiché.
Nœuds les plus coûteux¶
Le volet liste tous les nœuds qui ont duré 1 % ou plus du temps total d’exécution de la requête (ou le temps d’exécution de l’étape de requête affichée, si la requête a été exécutée en plusieurs étapes de traitement). Le volet liste les nœuds par temps d’exécution par ordre décroissant, ce qui permet aux utilisateurs de localiser rapidement les nœuds les plus coûteux en termes de temps d’exécution.
Attributs¶
Les sections suivantes fournissent une liste des types d’opérateurs les plus courants et de leurs attributs :
Opérateurs d’accès et de production de données¶
- TableScan:
Représente l’accès à une table unique. Attributs :
Nom complet de la table — le nom entièrement qualifié de la table analysée
Alias de table — alias de table utilisé, le cas échéant.
Colonnes — liste des colonnes analysées.
Chemins de variante extraits — liste des chemins extraits à partir des colonnes VARIANT.
Mode d’analyse — ROW_BASED ou COLUMN_BASED (affiché uniquement pour les analyses de tables hybrides)
Prédicats d’accès — conditions de la requête qui sont appliquées lors de l’analyse de la table
- IndexScan:
Représente l’accès aux index secondaires sur les tables hybrides. Attributs :
Nom complet de la table — le nom entièrement qualifié de la table analysée qui contient l’index
Colonnes — liste des colonnes d’index analysées
Mode d’analyse — ROW_BASED ou COLUMN_BASED
Prédicats d’accès — conditions de la requête qui sont appliquées lors de l’analyse de l’index
Nom complet de l’index — le nom entièrement qualifié de l’index analysé
- ValuesClause:
Liste des valeurs fournies avec la clause VALUES. Attributs :
Nombre de valeurs — le nombre de valeurs produites.
Valeurs — la liste de valeurs produites.
- Générateur:
Génère des enregistrements à l’aide de la construction
TABLE(GENERATOR(...)). Attributs :rowCount — paramètre rowCount fourni.
timeLimit — paramètre timeLimit fourni.
- ExternalScan:
Représente l’accès aux données stockées dans les objets de zone de préparation. Peut faire partie des requêtes qui analysent directement les données des zones de préparation, mais aussi pour les opérations de chargement des données (comme les instructions COPY).
Attributs :
Nom de zone de préparation — le nom de la zone de préparation à partir de laquelle les données sont lues.
Type de zone de préparation — le type de la zone de préparation (p. ex. TABLE STAGE).
- InternalObject:
Représente l’accès à un objet de données interne (par exemple, une table de schéma d’information ou le résultat d’une requête précédente). Attributs :
Nom d’objet — le nom ou le type de l’objet accédé.
Opérateurs de traitement de données¶
- Filtre:
Représente une opération qui filtre les enregistrements. Attributs :
Condition de filtre - la condition utilisée pour effectuer le filtrage.
- Joindre:
Combine deux entrées sur une condition donnée. Attributs :
Type de jointure — Type de jointure (par ex. INNER, LEFT OUTER, etc.).
Condition de jointure d’égalité — pour les jointures qui utilisent des conditions basées sur l’égalité, cet attribut répertorie les expressions utilisées pour joindre les éléments.
Condition de jonction supplémentaire — certaines jonctions utilisent des conditions contenant des prédicats non basés sur l’égalité. Elles sont répertoriées ici.
Note
Les prédicats de jonction de non-égalité pourraient entraîner des vitesses de traitement beaucoup plus lentes et doivent être évités dans la mesure du possible.
- Agrégat:
Regroupe les entrées et calcule les fonctions d’agrégat. Peut représenter des constructions SQL, telles que GROUP BY et SELECT DISTINCT. Attributs :
Clés de groupement — si GROUP BY est utilisé, cela répertorie les expressions utilisées pour le groupement.
Fonctions d’agrégat – répertorie les fonctions calculées pour chaque groupe d’agrégats, p. ex. SUM.
- GroupingSets:
Représente des constructions, telles que GROUPING SETS, ROLLUP et CUBE. Attributs :
Ensembles de clés de groupement — liste des ensembles de groupement.
Fonctions d’agrégat — liste des fonctions calculées pour chaque groupe, p. ex. SUM.
- WindowFunction:
Calcule les fonctions de la fenêtre. Attributs :
Fonctions de la fenêtre — liste des fonctions de la fenêtre calculées.
- Trier:
Entrée d’ordres sur une expression donnée. Attributs :
Clés de tri — expression définissant l’ordre de tri.
- SortWithLimit:
Produit une partie de la séquence d’entrée après le tri, généralement le résultat d’une construction
ORDER BY ... LIMIT ... OFFSET ...dans SQL.Attributs :
Clés de tri — expression définissant l’ordre de tri.
Nombre de lignes — nombre de lignes produites.
Décalage — position dans la séquence ordonnée à partir de laquelle les tuples produits sont émis.
- Aplatir:
Traite les enregistrements VARIANT, en les aplatissant éventuellement sur un chemin spécifié. Attributs :
Entrée — l’expression d’entrée utilisée pour aplatir les données.
- JoinFilter:
Opération de filtrage spéciale qui enlève les tuples qui peuvent être identifiés comme ne correspondant pas à l’état d’une jonction plus loin dans le plan de requête. Attributs :
ID de jonction d’origine — la jonction utilisée pour identifier les tuples qui peuvent être filtrées.
- UnionAll:
Procède à la concaténation de deux entrées. Attributs : aucun.
- ExternalFunction:
Représente le traitement par une fonction externe.
Opérateurs DML¶
- Insérer:
Ajoute des enregistrements à une table via une opération INSERT ou COPY. Attributs :
Expressions d’entrée — les expressions insérées.
Noms de table — noms des tables auxquelles les enregistrements sont ajoutés.
- Supprimer:
Supprime des enregistrements d’une table. Attributs :
Nom de table — le nom de la table dont les enregistrements sont supprimés.
- Mettre à jour:
Met à jour les enregistrements d’une table. Attributs :
Nom de table — le nom de la table mise à jour.
- Fusionner:
Effectue une opération MERGE sur une table. Attributs :
Nom de table complet — le nom de la table mise à jour.
- Décharger:
Représente une opération COPY qui exporte les données d’une table vers un fichier dans une zone de préparation. Attributs :
Emplacement - le nom de la zone de préparation où les données sont sauvegardées.
Opérateurs de métadonnées¶
Certaines requêtes comprennent des étapes qui sont de pures opérations de métadonnées/de catalogue plutôt que des opérations de traitement de données. Ces étapes se composent d’un seul opérateur. Quelques exemples :
- Commandes DDL et de transactions:
Utilisées pour créer ou modifier des objets, des sessions, des transactions, etc. Généralement, ces requêtes ne sont pas traitées par un entrepôt virtuel et donnent lieu à un profil à une seule étape correspondant à l’instruction SQL correspondante. Par exemple :
CREATE DATABASE | SCHEMA | …
ALTER DATABASE | SCHEMA | TABLE | SESSION | …
DROP DATABASE | SCHEMA | TABLE | …
COMMIT
- Commande de création de table:
Commande DDL pour créer une table. Par exemple :
CREATE TABLE
Comme les autres commandes DDL, ces requêtes donnent un profil à une seule étape. Cependant, elles peuvent aussi faire partie d’un profil à plusieurs étapes, comme lorsqu’elles sont utilisées dans une instruction CTAS. Par exemple :
CREATE TABLE … AS SELECT …
- Réutilisation de résultats de requête:
Une requête qui réutilise le résultat d’une requête précédente.
- Résultat basé sur les métadonnées:
Requête dont le résultat est calculé à partir de métadonnées uniquement, sans accéder à aucune donnée. Ces requêtes ne sont pas traitées par un entrepôt virtuel. Par exemple :
SELECT COUNT(*) FROM …
SELECT CURRENT_DATABASE()
Opérateurs divers¶
- Résultat:
Renvoie le résultat de la requête. Attributs :
Liste des expressions - les expressions produites.
Problèmes de requête courants identifiés par le profil de requête¶
Cette section décrit les problèmes que vous pouvez identifier et résoudre à l’aide du profil de requête.
« Explosion » de jonctions¶
L’une des erreurs courantes des utilisateurs de SQL est de joindre des tables sans fournir de condition de jonction (résultant en un « produit cartésien »), ou de fournir une condition où les enregistrements d’une table correspondent à plusieurs enregistrements d’une autre table. Pour de telles requêtes, l’opérateur Join produit significativement plus de tuples qu’il n’en consomme (souvent par ordre de grandeur).
Ceci peut être observé en regardant le nombre d’enregistrements produits par un opérateur Join, et se reflète généralement aussi dans un opérateur Join chronophage.
UNION sans ALL¶
Dans SQL, il est possible de combiner deux ensembles de données avec les constructions UNION ou UNION ALL. La différence est que UNION ALL concatène simplement les entrées, tandis que UNION fait la même chose, mais supprime également les doublons.
Une erreur classique est d’utiliser UNION alors que la sémantique UNION ALL est suffisante. Ces requêtes apparaissent dans le profil de requête en tant qu’opérateur UnionAll avec un opérateur Aggregate supplémentaire (qui effectue l’élimination des doublons).
Requêtes trop volumineuses pour la mémoire¶
Pour certaines opérations (par exemple l’élimination des doublons dans un grand ensemble de données), la quantité de mémoire disponible pour les serveurs utilisée pour exécuter l’opération peut ne pas être suffisante pour contenir les résultats intermédiaires. En conséquence, le moteur de traitement des requêtes commencera à déverser les données sur le disque local. Si l’espace disque local n’est pas suffisant, les données déversées sont alors enregistrées sur des disques distants.
Ce déversement peut avoir un effet important sur les performances de la requête (surtout si le disque distant est utilisé pour le déversement). Pour remédier à cette situation, nous recommandons les choses suivantes :
Utilisez un entrepôt plus grand (ce qui a pour effet d’augmenter l’espace mémoire/espace disque local disponible pour l’opération), et/ou
Traitez les données par lots de plus petite taille.
Nettoyage inefficace¶
Snowflake collecte des statistiques complètes sur les données lui permettant de ne pas lire les parties inutiles d’une table selon les filtres de requête. Toutefois, pour que cela ait un effet, l’ordre de stockage des données doit être corrélé avec les attributs du filtre de requête.
L’efficacité de l’élagage s’observe en comparant les statistiques Partitions analysées et Nombre total de partitions dans les opérateurs TableScan. Si la première est une petite fraction de la seconde, alors l’élagage est efficace. Dans le cas contraire, l’élagage n’a eu aucun effet.
Bien entendu, l’élagage ne peut aider que pour les requêtes qui filtrent réellement une quantité importante de données. Si les statistiques d’élagage n’indiquent pas de réduction de données, mais qu’il y a un opérateur Filter au-dessus de TableScan qui filtre un certain nombre d’enregistrements, cela peut indiquer qu’une autre organisation des données pourrait être utile pour cette requête.
Pour plus d’informations sur l’élagage, voir Fonctionnement des structures de table dans Snowflake.