Paramètres¶
Snowflake fournit des paramètres qui vous permettent de contrôler le comportement de votre compte, des sessions utilisateur individuelles et des objets. Tous les paramètres ont des valeurs par défaut. Vous pouvez définir ces paramètres et les remplacer à différents niveaux, en fonction du type de paramètre (compte, session ou objet).
Hiérarchie des paramètres et types¶
Cette section décrit les différents types de paramètres et les niveaux auxquels chaque type peut être défini. Il existe trois types de paramètres :
Le diagramme suivant illustre la relation hiérarchique entre les différents types de paramètres et la manière dont les paramètres individuels peuvent être remplacés à chaque niveau :
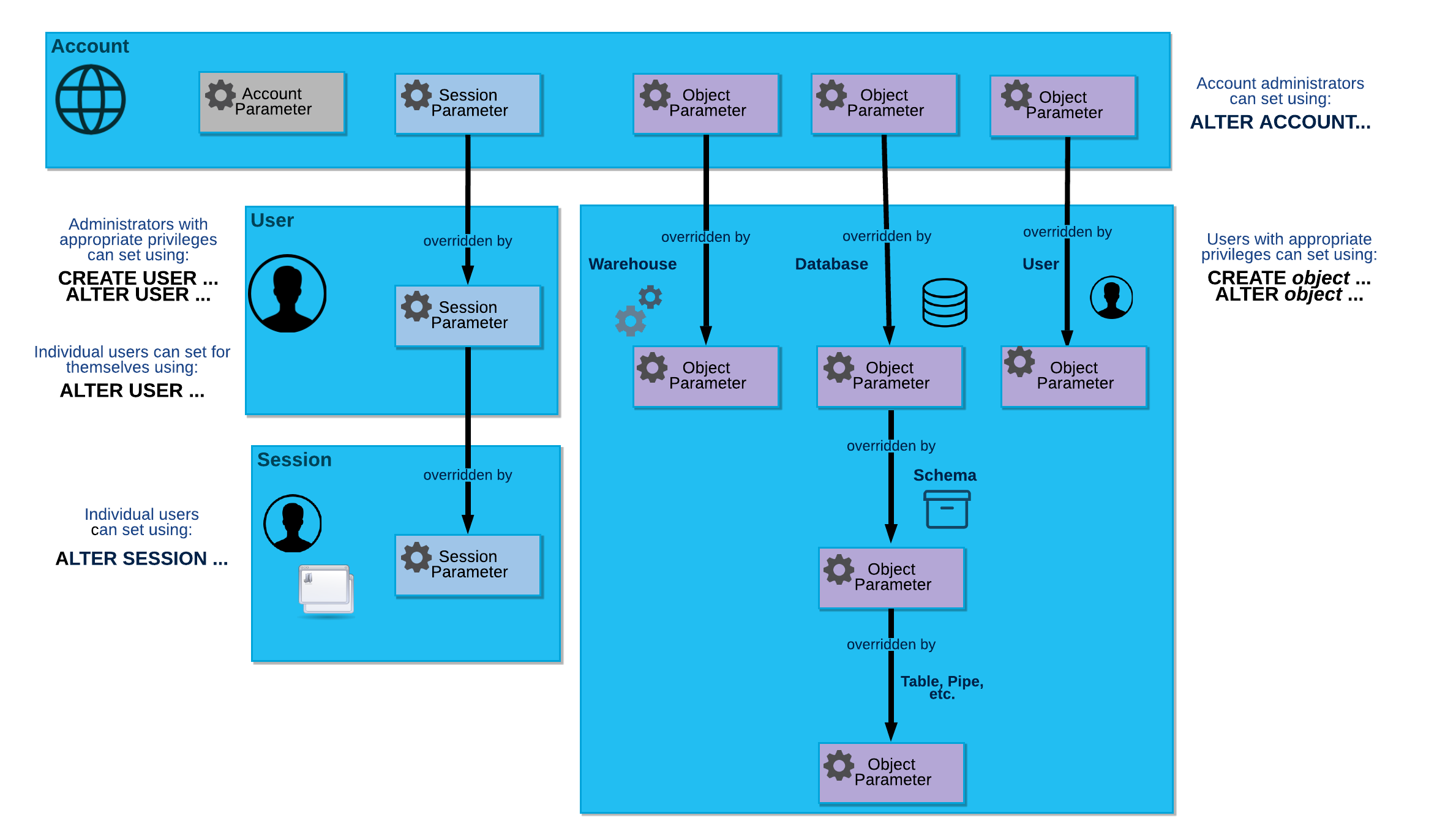
Paramètres du compte¶
Vous ne pouvez définir des paramètres de compte qu’au niveau du compte, si vous utilisez un rôle auquel le privilège a été accordé pour définir le paramètre. Pour définir un paramètre de compte, vous exécutez la commande ALTER ACCOUNT.
Snowflake fournit les paramètres de compte suivants :
Paramètre |
Remarques |
|---|---|
ACCOUNT_LEVEL_FILE_EXTENSIONS_ALLOW_LIST_FOR_PRIVATE_WORKSPACES |
Utilisé pour spécifier les extensions de fichiers autorisées dans les espaces de travail privés du compte. |
ACCOUNT_LEVEL_FILE_EXTENSIONS_ALLOW_LIST_FOR_SHARED_WORKSPACES |
Utilisé pour spécifier les extensions de fichiers autorisées dans les espaces de travail partagés du compte. |
Utilisé pour permettre aux clients d’accéder aux valeurs des variables de liaison. |
|
Utilisé pour activer la mise en cache de connexion dans l’authentification unique (SSO) basée sur un navigateur pour les clients fournis par Snowflake. |
|
Utilisé pour spécifier les types de charges de travail autorisés dans votre compte à se déployer vers Snowpark Container Services. |
|
Utilisé pour le chiffrement des fichiers mis en zone de préparation pour le chargement ou le déchargement des données ; pourrait nécessiter une installation et une configuration supplémentaires (voir description pour plus de détails). |
|
Utilisé pour activer le traitement interrégional des appels Snowflake Cortex dans une région différente si l’appel ne peut pas être traité dans la région de votre compte. |
|
Utilisé pour définir la version par défaut de tous les futurs objets de projet dbt créés dans un compte. |
|
Permet de désactiver l’octroi de privilèges directement aux utilisateurs. Pour plus d’informations, voir les notes sur l’utilisation pour GRANT des privilèges aux USERS. |
|
Utilisé pour spécifier les types de charges de travail qui ne sont pas autorisés dans votre compte à se déployer vers Snowpark Container Services. |
|
Contrôle si les événements de la classification des données sensibles sont consignés dans le tableau des événements de l’utilisateur. |
|
Contrôle si les événements des budgets sont enregistrés dans le tableau des événements. |
|
Permet d’activer ou de désactiver l’optimisation des coûts de sortie de l’exécution automatique des listings. |
|
Permet à la fonction SYSTEM$GET_PRIVATELINK_CONFIG de retourner la clé |
|
Autorise la fonction SYSTEM$GET_PRIVATELINK_CONFIG à renvoyer les clés |
|
Utilisé pour activer ou désactiver les notebooks privés sur un compte Snowflake. |
|
ENABLE_SPCS_BLOCK_STORAGE_SNOWFLAKE_FULL_ENCRYPTION_ENFORCEMENT |
Utilisé pour activer l’application du chiffrement SNOWFLAKE_FULL pour les volumes de stockage en bloc et les instantanés Snowpark Container Services. |
Contrôle si Snowflake collecte des données de télémétrie pour la propagation des balises. |
|
Utilisé pour spécifier le choix pour un référentiel d’images de refuser d’utiliser Tri-Secret Secure et Periodic Rekeying. |
|
Permet de définir la planification d’actualisation de toutes les annonces d’un compte. |
|
Permet de définir la période minimale de conservation des données dans le cadre de la conservation des données historiques pour les opérations Time Travel. |
|
C’est le seul paramètre de compte qui peut être défini par les administrateurs de compte (c’est-à-dire les utilisateurs avec le rôle système ACCOUNTADMIN) ou les administrateurs de sécurité (c’est-à-dire les utilisateurs avec le rôle système SECURITYADMIN). . Pour plus d’informations, voir Paramètres d’objet. |
|
Utilisé pour spécifier s’il faut capturer le texte SQL d’une instruction SQL tracée. |
|
Utilisé pour activer ou désactiver les Espaces de travail en tant qu’éditeur SQL par défaut pour le compte. |
Note
Les paramètres de compte ne sont pas affichés dans la sortie par défaut de SHOW PARAMETERS. Pour des informations sur l’affichage des paramètres de compte, voir Affichage des paramètres et de leurs valeurs (dans ce chapitre).
Paramètres de session¶
La plupart des paramètres sont des paramètres de session, qui peuvent être réglés aux niveaux suivants :
- Compte:
Les administrateurs de compte peuvent exécuter la commande ALTER ACCOUNT pour définir les paramètres de session du compte.
Les valeurs que vous définissez à ce niveau deviennent les valeurs par défaut pour les utilisateurs individuels et leurs sessions.
- Utilisateur:
Les administrateurs avec les privilèges appropriés (généralement, un utilisateur qui s’est vu accorder le rôle SECURITYADMIN) peut exécuter la commande ALTER USER pour remplacer les paramètres de session des utilisateurs individuels. En outre, des utilisateurs individuels peuvent exécuter la commande ALTER USER pour remplacer les paramètres de sessions par défaut pour eux-mêmes.
Les valeurs que vous avez définies pour un utilisateur deviennent les valeurs par défaut dans toute session lancée par cet utilisateur.
- Session:
Les utilisateurs peuvent exécuter la commande ALTER SESSION pour remplacer les paramètres de session pour la session en cours.
Note
Par défaut, seuls les paramètres de session sont affichés dans la sortie de SHOW PARAMETERS. Pour plus d’informations sur l’affichage des paramètres de compte et d’objet, voir Affichage des paramètres et de leurs valeurs (dans cette rubrique).
Paramètres d’objet¶
Vous pouvez définir les paramètres d’objet aux niveaux suivants :
- Compte:
Les administrateurs de compte peuvent exécuter la commande ALTER ACCOUNT pour définir les paramètres d’objet du compte.
Les valeurs que vous définissez à ce niveau deviennent les valeurs par défaut des objets individuels créés dans le compte.
- Objet:
Les utilisateurs disposant des privilèges appropriés peuvent utiliser les commandes CREATE <objet> ou ALTER <objet> pour remplacer les paramètres d’objet d’un objet individuel.
Snowflake fournit les paramètres d’objet suivants :
Paramètre |
Type d’objet |
Remarques |
|---|---|---|
Procédure stockée Snowflake Scripting |
||
Base de données, schéma |
Spécifie un préfixe à utiliser dans le chemin d’écriture des fichiers de table Apache Iceberg™. |
|
Base de données, schéma, table Apache Iceberg™ |
||
Compte, base de données, schéma, table Apache Iceberg™ |
Ce paramètre n’est pris en charge que pour les tables Iceberg gérées par Snowflake que vous synchronisez avec Open Catalog. |
|
Fonctions et modèles Cortex AI |
Noms séparés par des virgules des modèles de langage Cortex autorisés, |
|
Table |
Spécifie la planification d’exécution des fonctions de métrique des données associées à la table. Toutes les fonctions de métrique des données de la table ou de la vue suivent la même planification. |
|
Base de données, Schéma, Table |
||
Base de données, Schéma, Table |
||
Base de données, schéma |
||
Base de données, schéma |
||
Compte |
Configuration de vos propres pools de calcul pour les applications Streamlit |
|
Compte, base de données, schéma |
||
Compte, utilisateur |
||
Compte, base de données, schéma, table Apache Iceberg™ |
Ce paramètre n’est pris en charge que pour les tables Iceberg gérées par Snowflake. |
|
Compte, base de données, schéma, table Apache Iceberg™ |
||
Utilisateur |
Affecte l’historique des requêtes qui échouent en raison d’erreurs de syntaxe ou d’analyse. |
|
Utilisateur |
Affecte la rédaction des messages d’erreur relatifs aux objets sécurisés dans les métadonnées. |
|
Base de données, compte |
||
Base de données, schéma, table Apache Iceberg™ |
||
Table Apache Iceberg™ |
||
Compte, base de données, schéma |
||
Compte, base de données, schéma, projet DCM, procédure stockée, fonction, table dynamique, table Iceberg, tâche, service. |
Messages de journalisation des APIs de journalisation. |
|
Compte, base de données, schéma, projet DCM, procédure stockée, fonction, table dynamique, table Iceberg, tâche, service. |
Événements du journal (type d’enregistrement EVENT) écrits dans le tableau des événements. |
|
Entrepôt |
||
Base de données, Schéma, Table |
||
Compte, base de données, schéma, procédure stockée, fonction |
||
Utilisateur |
Il s’agit du seul paramètre utilisateur pouvant être défini des administrateurs de comptes (des utilisateurs titulaires du rôle système ACCOUNTADMIN) ou des administrateurs de sécurité (des utilisateurs titulaires du rôle système SECURITYADMIN). Si ce paramètre est défini sur le compte et sur un utilisateur du même compte, la politique réseau au niveau de l’utilisateur prévaut sur la politique réseau au niveau du compte. |
|
Table Apache Iceberg™ |
Spécifie la structure du chemin d’accès aux fichiers de données Parquet écrits dans des tables Iceberg partitionnées. |
|
Schéma, canal |
||
Utilisateur |
||
Utilisateur |
||
Base de données, schéma, format de fichier, table Apache Iceberg™ |
Ne peut être défini que pour les tables Iceberg qui utilisent un catalogue Iceberg externe. |
|
|
Base de données, Schéma, Table |
Utilisez ce paramètre pour activer les horodatages de lignes dans vos tables. Pour plus d’informations, voir Utiliser des horodatages de lignes pour mesurer la latence dans vos pipelines. |
|
Base de données, Schéma, Table |
Utilisez ce paramètre pour définir les horodatages de lignes par défaut pour les nouvelles tables dans un conteneur. Pour plus d’informations, voir Utiliser des horodatages de lignes pour mesurer la latence dans vos pipelines. |
Base de données, schéma, tâche, compte |
||
Base de données, schéma, tâche, compte |
||
Entrepôt |
Il s’agit également d’un paramètre de session (il peut être défini au niveau de l’objet et de la session). Pour plus de détails sur l’héritage et le remplacement, voir la description des paramètres. |
|
Entrepôt |
Il s’agit également d’un paramètre de session (il peut être défini au niveau de l’objet et de la session). Pour plus de détails sur l’héritage et le remplacement, voir la description des paramètres. |
|
Base de données, schéma, table Apache Iceberg™ |
Ce paramètre n’est pris en charge que pour les tables Iceberg qui utilisent Snowflake comme catalogue. |
|
Base de données, Schéma, Tâche |
||
Base de données, Schéma, Tâche |
||
Compte, base de données, schéma, procédure stockée, fonction |
||
Base de données, Schéma, Tâche |
||
Base de données, Schéma, Tâche |
||
Base de données, Schéma, Tâche |
Note
Par défaut, les paramètres d’objet ne sont pas affichés dans la sortie de SHOW PARAMETERS. Pour des informations sur l’affichage des paramètres d’objet, voir Affichage des paramètres et de leurs valeurs (dans cette rubrique).
Affichage des paramètres et de leurs valeurs¶
Pour voir les paramètres définis et leurs valeurs par défaut, exécutez la commande SHOW PARAMETERS. Vous pouvez exécuter la commande avec différents paramètres de commande pour afficher différents types de paramètres :
Affichage des paramètres de session¶
Par défaut, la commande affiche les paramètres de session seulement :
Affichage des paramètres d’objet¶
Pour afficher les paramètres d’objet d’un objet spécifique, ajoutez la clause IN avec le type et le nom de l’objet. Par exemple :
Affichage de tous les paramètres (y compris les paramètres de compte et d’objet)¶
Pour afficher tous les paramètres, y compris les paramètres de compte et d’objet, inclure la clause IN ACCOUNT :
Limitation de la liste des paramètres par nom¶
Vous pouvez spécifier la clause LIKE pour limiter la liste des paramètres par leur nom. Par exemple :
Pour afficher les paramètres de session dont les noms contiennent le mot « time » :
Pour afficher tous les paramètres dont le nom commence par « time » :
Note
Vous devez spécifier la clause LIKE avant la clause IN.
ABORT_DETACHED_QUERY¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Booléen
- Description:
Spécifie l’action que Snowflake effectue pour les requêtes en cours si la connectivité est perdue en raison d’une interruption abrupte d’une session (p. ex. panne de réseau, arrêt du navigateur, interruption de service).
- Valeurs:
TRUE: les requêtes en cours sont interrompues 5 minutes après la perte de connexion.FALSE: les requêtes en cours sont terminées.- Par défaut:
FALSE
Note
Pour les pilotes clients, la fermeture de la connexion du côté client (comme l’appel de
connection.close()) est différente de la déconnexion effective de la session Snowflake. La fermeture de la connexion peut être associée au nettoyage des ressources appartenant à la connexion, y compris, mais sans s’y limiter, la déconnexion de la session. L’exécution d’une déconnexion de session implique également que toutes les requêtes encore en cours d’exécution dans la même session (par exemple, les requêtes soumises de manière asynchrone) sont annulées après quelques minutes lorsque la session est déconnectée, même si le paramètreABORT_DETACHED_QUERY est défini surfalse(la valeur par défaut).Par conséquent, certains pilotes Snowflake implémentent leur propre logique métier pour décider si la déconnexion de la session est effectuée lors de la fermeture de la connexion.
Actuellement, cette fonctionnalité est implémentée dans les pilotes suivants :
La plupart des requêtes nécessitent des ressources de calcul pour être exécutées. Ces ressources sont fournies par des entrepôts virtuels, qui consomment des crédits en fonctionnement. Si la session Snowflake n’est pas terminée lors de la fermeture de la connexion, les entrepôts peuvent continuer à exécuter et à consommer des crédits pour compléter toutes les requêtes en cours au moment où la connexion a été fermée, jusqu’à la valeur du paramètre STATEMENT_TIMEOUT_IN_SECONDS, qui a une valeur par défaut de deux jours.
ACTIVE_PYTHON_PROFILER¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Chaîne (constante)
- Description:
Définit le profileur à utiliser pour la session lors du profilage du code du gestionnaire Python.
- Valeurs:
'LINE': faire en sorte que le profil se concentre sur l’activité d’utilisation de la ligne.'MEMORY': faire en sorte que le profil se concentre sur l’activité d’utilisation de la mémoire.- Par défaut:
Aucune.
ACCOUNT_LEVEL_FILE_EXTENSIONS_ALLOW_LIST_FOR_PRIVATE_WORKSPACES¶
- Type:
Compte — Ne peut être défini que pour le compte
- Type de données:
Chaîne
- Description:
Spécifie les extensions de fichiers autorisées dans les espaces de travail privés du compte. La valeur est une liste d’extensions séparées par des virgules, par exemple :
.ipynb,.sql,.txt. Si le paramètre est vide (par défaut), toutes les extensions de fichiers sont autorisées.Lorsque la liste d’autorisations est non vide :
Seules les extensions répertoriées sont autorisées ; toutes les autres sont bloquées.
Les fichiers chargés par le biais des espaces de travail avec une extension non autorisée échoueront immédiatement lors du chargement.
Si un fichier est renommé pour utiliser une extension non autorisée, le fichier devient inaccessible dans l’espace de travail.
Les fichiers préexistants dont les extensions ne sont pas autorisées n’apparaîtront pas dans les espaces de travail.
Les utilisateurs peuvent toujours utiliser la commande CLI``PUT`` Snowflake pour charger des fichiers avec des extensions non autorisées vers une zone de préparation virtuelle d’un espace de travail ou une zone de préparation virtuelle d’un objet de projet de notebook. Cependant, ces fichiers sont inaccessibles et ne peuvent pas être utilisés, visualisés, téléchargés ( via``GET``) ou répertoriés (via
LIST) à partir de l’espace de travail ou de l’environnement de l’objet de projet de notebook.Pour maintenir la fonctionnalité de base de l’espace de travail, incluez
.ipynbet.sqlà la liste d’autorisations.Les fichiers sans extension (par exemple,
Makefile) ne sont pas autorisés lorsque la liste est non vide.Les fichiers de points (par exemple,
.gitignoreou.venv) doivent être explicitement ajoutés à la liste.La correspondance des extensions est sensible à la casse. Par exemple, si
.txtfigure dans la liste,.TXTn’est pas autorisé.
- Par défaut:
Chaîne vide (toutes les extensions autorisées)
ALLOW_BIND_VALUES_ACCESS¶
- Type:
Compte — Peut uniquement être défini pour Compte
- Type de données:
Booléen
- Description:
Spécifie si les clients peuvent accéder aux valeurs de la variable de liaison en utilisant la fonction de table BIND_VALUES, la vue d’utilisation du compte QUERY_HISTORY, la vue d’utilisation de l’organisation QUERY_HISTORY, ou la fonction QUERY_HISTORY. Pour plus d’informations, voir Récupérer les valeurs des variables de liaison.
- Valeurs:
TRUE: permet de récupérer les valeurs des variables de liaison.FALSE: n’autorise pas la récupération des valeurs des variables de liaison.- Par défaut:
TRUE
ALLOW_CLIENT_MFA_CACHING¶
- Type:
Compte — Peut uniquement être défini pour Compte
- Type de données:
Booléen
- Description:
Spécifie si un jeton MFA peut être enregistré dans le keystore du système d’exploitation côté client pour promouvoir une connectivité continue et sécurisée sans que les utilisateurs aient besoin de répondre à une invitation MFA au début de chaque tentative de connexion à Snowflake. Pour plus de détails et la liste des clients fournis par Snowflake et pris en charge, voir Utilisation de la mise en cache des jetons MFA pour réduire le nombre d’invites lors de l’authentification — Facultatif.
- Valeurs:
TRUE: stocke un jeton MFA dans le keystore du système d’exploitation côté client pour permettre à l’application cliente d’utiliser le jeton MFA chaque fois qu’une nouvelle connexion est établie. Bien que cela soit vrai, les utilisateurs ne sont pas invités à répondre à des invites MFA supplémentaires.FALSE: ne stocke pas un jeton MFA. Les utilisateurs doivent répondre à une invite MFA chaque fois que l’application cliente établit une nouvelle connexion avec Snowflake.- Par défaut:
FALSE
ALLOW_ID_TOKEN¶
- Type:
Compte — Ne peut être défini que pour le compte
- Type de données:
Booléen
- Description:
Spécifie si un jeton de connexion peut être enregistré dans le magasin de clés du système d’exploitation côté client pour promouvoir une connectivité continue et sécurisée sans que les utilisateurs n’aient besoin d’entrer des informations de connexion au début de chaque tentative de connexion à Snowflake. Pour plus de détails et la liste des clients fournis par Snowflake et pris en charge, voir Utilisation de la mise en cache de connexion pour réduire le nombre d’invites pour l’authentification — Facultatif.
- Valeurs:
TRUE: stocke un jeton de connexion dans le magasin de clés du système d’exploitation côté client pour permettre à l’application cliente d’exécuter SSO sur navigateur sans inviter les utilisateurs à s’authentifier chaque fois qu’une nouvelle connexion est établie.FALSE: ne stocke pas de jeton de connexion. Les utilisateurs sont invités à s’authentifier chaque fois que l’application cliente établit une nouvelle connexion avec Snowflake. SSO à Snowflake est toujours possible si ce paramètre est défini sur false.- Par défaut:
FALSE
ALLOWED_SPCS_WORKLOAD_TYPES¶
- Type:
Compte — Ne peut être défini que pour le compte
- Type de données:
Chaîne
- Description:
Spécifie les types de charges de travail autorisés dans votre compte à se déployer vers Snowpark Container Services. Voir aussi DISALLOWED_SPCS_WORKLOAD_TYPES.
- Valeurs:
La valeur est une liste, séparée par des virgules, des types de charges de travail pris en charge suivants :
USER: Toutes les charges de travail directement déployées par les utilisateurs.NOTEBOOK: Snowflake Notebooks.STREAMLIT: Streamlit dans Snowflake.MODEL_SERVING: Service du modèle ML.ML_JOB: Tâches ML Snowflake.ALL: Toutes les charges de travail.
- Par défaut:
ALL
Note
Si vous configurez ALLOWED_SPCS_WORKLOAD_TYPES et DISALLOWED_SPCS_WORKLOAD_TYPES, DISALLOWED_SPCS_WORKLOAD_TYPES prévaut. Par exemple, si vous configurez ces deux paramètres et spécifiez la charge de travail NOTEBOOK, les charges de travail``NOTEBOOK`` ne peuvent pas s’exécuter sur Snowpark Container Services.
AUTO_EVENT_LOGGING¶
- Type:
Objet (pour les procédures stockées Snowflake Scripting)
- Type de données:
Chaîne (constante)
- Description:
Contrôle si des messages de journalisation et des événements de trace Snowflake Scripting sont ingérés automatiquement dans la table des événements. Pour définir ce paramètre, exécutez la commande ALTER PROCEDURE.
- Valeurs:
LOGGING: ajoute automatiquement les informations de journalisation supplémentaires suivantes à la table des événements lorsqu’une procédure est exécutée :BEGIN/END d’un bloc Snowflake Scripting.
BEGIN/END d’une requête de tâche enfant.
Cette information n’est ajoutée à la table des événements que si la valeur LOG_LEVEL effective est définie sur
TRACEpour la procédure stockée.TRACING: ajoute automatiquement les informations de trace supplémentaires suivantes à la table des événements lorsqu’une procédure stockée est exécutée :Interception des exceptions.
Informations sur l’exécution des tâches enfants.
Statistiques sur les tâches enfants.
Statistiques sur les procédures stockées, y compris le temps d’exécution et les valeurs d’entrée.
Cette information n’est ajoutée à la table des événements que si la valeur TRACE_LEVEL effective est définie sur
ALWAYSou surON_EVENTpour la procédure stockée.ALL: ajoute automatiquement les informations de journalisation ajoutées pour la valeurLOGGINGet les informations de traçage ajoutées pour la valeurTRACING.OFF: n’ajoute pas automatiquement des informations de journalisation ou de traçage à la table des événements.
- Par défaut:
OFF
Pour plus d’informations sur l’utilisation de ce paramètre, voir Définition des niveaux de journalisation, des métriques et du traçage, Ajouter automatiquement des messages de journal sur les blocs et les tâches enfants et Émettre automatiquement des événements de trace pour les tâches enfants et les exceptions.
AUTOCOMMIT¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Booléen
- Description:
Indique si la fonction de validation automatique est activée pour la session. La validation automatique détermine si une instruction DML, lorsqu’elle est exécutée sans transaction active, est automatiquement validée une fois l’instruction terminée avec succès. Pour plus d’informations, voir Transactions.
Note
Définir ce paramètre sur
FALSEarrête l’enregistrement des données d’utilisation dans le schéma ORGANIZATION_USAGE d’un compte d’organisation.- Valeurs:
TRUE: la validation automatique est activée.FALSE: la validation automatique est désactivée, ce qui signifie que les instructions DML doivent être explicitement validées ou annulées.- Par défaut:
TRUE
Note
La valeur FALSE n’est pas prise en charge pour les tâches.
AUTOCOMMIT_API_SUPPORTED (affichage seul)¶
- Type:
N/A
- Type de données:
Booléen
- Description:
Réservé à l’usage interne de Snowflake. Paramètre d’affichage seul qui indique si la prise en charge de l’API pour la validation automatique est activée pour votre compte. Si la valeur est
TRUE, vous pouvez activer ou désactiver la validation automatique via les APIs pour les pilotes/connecteurs suivants :
BASE_LOCATION_PREFIX¶
- Type:
Objet (pour bases de données et schémas) — Peut être défini pour Compte » Base de données » Schéma
- Type de données:
Chaîne
- Description:
Spécifie un préfixe que Snowflake doit utiliser dans le chemin d’écriture des tables Apache Iceberg™ gérées par Snowflake. Pour plus d’informations, voir la section relative aux répertoires de données et de métadonnées pour les tables Iceberg.
- Valeurs:
Tout préfixe de chaîne valide conforme aux conventions de nommage du stockage de votre fournisseur Cloud.
- Par défaut:
Aucun(e)
BINARY_INPUT_FORMAT¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Chaîne (constante)
- Description:
Format des valeurs VARCHAR passées en entrée des fonctions de conversion VARCHAR vers BINARY. Pour plus d’informations, voir Entrée et sortie binaires.
- Valeurs:
HEX,BASE64ouUTF8/UTF-8- Par défaut:
HEX
BINARY_OUTPUT_FORMAT¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Chaîne (constante)
- Description:
Le format des valeurs VARCHAR renvoyées en sortie par les fonctions de conversion BINARY vers VARCHAR. Pour plus d’informations, voir Entrée et sortie binaires.
- Valeurs:
HEXouBASE64- Par défaut:
HEX
CATALOG¶
- Type:
Objet (pour les bases de données, schémas et tables Apache Iceberg™) — Peut être défini pour Compte » Base de données » Schéma » Table Iceberg
- Type de données:
Chaîne
- Description:
Spécifie le catalogue des tables Apache Iceberg™. Pour plus d’informations, voir la documentation de tables Iceberg.
- Valeurs:
SNOWFLAKEou tout identificateur d’intégration de catalogue valide.- Par défaut:
Aucun(e)
CATALOG_SYNC¶
- Type:
Objet (pour bases de données, schémas et tables Iceberg) — Peut être défini pour Compte » Base de données » Schéma » Table Iceberg
- Type de données:
Chaîne
- Description:
Spécifie le nom de votre intégration de catalogue pour Snowflake Open Catalog. Snowflake synchronise les tables qui utilisent l’intégration de catalogue spécifiée avec votre compte Snowflake Open Catalog. Pour plus d’informations, voir Synchronisation d’une table gérée par Snowflake avec Snowflake Open Catalog.
- Valeurs:
Nom de toute intégration de catalogue existante pour Open Catalog.
- Par défaut:
Aucun(e)
CLIENT_ENABLE_LOG_INFO_STATEMENT_PARAMETERS¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Booléen
- Clients:
JDBC
- Description:
Permet aux utilisateurs de consigner les valeurs de données liées à PreparedStatements.
Pour voir les valeurs, vous devez non seulement définir ce paramètre au niveau de la session sur
TRUE, mais également définir le paramètre de connexion nomméTRACINGsurINFOouALL.Définissez
TRACINGsurALLpour afficher toutes les informations de débogage et toutes les informations de liaison.Définissez
TRACINGsurINFOpour afficher les valeurs des paramètres de liaison et moins d’informations annexes de débogage.
Prudence
Si vous liez des informations confidentielles, telles que des diagnostics médicaux ou des mots de passe, ces informations sont enregistrées. Snowflake recommande de s’assurer que le fichier journal est sécurisé ou d’utiliser uniquement des données de test lorsque vous définissez ce paramètre sur
TRUE.- Valeurs:
TRUEouFALSE.- Par défaut:
FALSE
CLIENT_ENCRYPTION_KEY_SIZE¶
- Type:
Compte — Ne peut être défini que pour le compte
- Type de données:
Entier
- Clients:
N’importe quel
- Description:
Indique la taille de la clé de chiffrement AES, en bits, utilisée par Snowflake pour chiffrer/déchiffrer les fichiers stockés sur des zones de préparation internes (pour charger/décharger des données), lorsque vous utilisez le type de chiffrement
SNOWFLAKE_FULL.- Valeurs:
128ou256- Par défaut:
128
Note
Ce paramètre n’est pas utilisé pour le chiffrement/déchiffrement de fichiers stockés dans des zones de préparation externes (c’est-à-dire des compartiments S3 ou des conteneurs Azure). Le chiffrement/déchiffrement de ces fichiers s’effectue à l’aide d’une clé de chiffrement externe explicitement spécifiée dans la commande COPY ou dans la zone de préparation externe nommée référencée dans la commande.
Si vous utilisez le pilote JDBC et que vous souhaitez définir ce paramètre sur 256 (pour un chiffrement fort), des fichiers de politique JCE supplémentaires doivent être installés sur chaque machine cliente à partir de laquelle les données sont chargées/déchargées. Pour plus d’informations sur l’installation des fichiers requis, voir Exigences Java pour le pilote JDBC.
Si vous utilisez le connecteur Python (ou SnowSQL) et que vous souhaitez définir ce paramètre sur 256 (pour un chiffrement fort), aucune installation ou tâche de configuration supplémentaire n’est nécessaire.
CLIENT_MEMORY_LIMIT¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Entier
- Clients:
JDBC, ODBC
- Description:
Paramètre qui spécifie la quantité maximale de mémoire que le pilote JDBC ou ODBC doit utiliser pour le jeu de résultats des requêtes (en MB).
Pour le pilote JDBC :
Pour simplifier la gestion de mémoire JVM, le paramètre définit une limite globale d’utilisation de la mémoire maximale pour toutes les requêtes.
CLIENT_RESULT_CHUNK_SIZE spécifie la taille maximale de chaque ensemble (ou morceau) de résultats de requête à télécharger (en MB). Le pilote pourrait avoir besoin de mémoire supplémentaire pour traiter un morceau ; si tel est le cas, il ajustera l’utilisation de la mémoire au moment de l’exécution pour traiter au moins un thread/une requête. Vérifiez que CLIENT_MEMORY_LIMIT est défini sur une valeur nettement supérieure à CLIENT_RESULT_CHUNK_SIZE pour vous assurer qu’une mémoire suffisante est disponible.
Pour le pilote ODBC :
Ce paramètre est pris en charge à partir de la version 2.22.0.
CLIENT_RESULT_CHUNK_SIZEn’est pas pris en charge.
Note
Le pilote tentera de respecter la valeur du paramètre, mais plafonnera l’utilisation à 80 % de la mémoire de votre système.
La limite d’utilisation de la mémoire définie dans ce paramètre ne s’applique pas aux autres opérations du pilote JDBC ou ODBC (par exemple, la connexion à la base de données, la préparation d’une requête ou les instructions PUT et GET).
- Valeurs:
Tout nombre valide de mégaoctets.
- Par défaut:
1536(effectivement 1,5 GB)La plupart des utilisateurs ne devraient pas avoir besoin de définir ce paramètre. Si ce paramètre n’est pas défini par l’utilisateur, le pilote démarre avec la valeur par défaut spécifiée ci-dessus.
En outre, le pilote JDBC gère activement sa mémoire de manière prudente pour éviter d’utiliser toute la mémoire disponible.
CLIENT_METADATA_REQUEST_USE_CONNECTION_CTX¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Booléen
- Clients:
JDBC, ODBC
- Description:
Pour certaines fonctions ODBC et méthodes JDBC, ce paramètre peut modifier la portée de la recherche par défaut pour qu’elle s’applique uniquement à la base de données/au schéma actuel et non plus à l’ensemble des bases de données/schémas. La recherche plus étroite renvoie généralement moins de lignes et s’exécute plus rapidement.
Par exemple, la méthode JDBC
getTables()accepte un nom de base de données et un nom de schéma comme arguments et renvoie les noms des tables de la base de données et du schéma. Si les arguments de base de données et de schéma sontnull, la méthode recherche par défaut l’ensemble des bases de données et schémas dans le compte. Définir CLIENT_METADATA_REQUEST_USE_CONNECTION_CTX surTRUErestreint la recherche à la base de données et au schéma actuels spécifiés par le contexte de connexion.En substance, la définition de ce paramètre sur
TRUEcrée la priorité suivante pour la base de données et le schéma :Valeurs transmises comme arguments aux fonctions/méthodes.
Valeurs spécifiées dans le contexte de connexion (le cas échéant).
Par défaut (toutes les bases de données et tous les schémas).
Pour plus de détails, consultez les informations ci-dessous.
Ce paramètre s’applique aux éléments suivants :
Méthodes de pilote JDBC (pour la classe
DatabaseMetaData) :getColumnsgetCrossReferencegetExportedKeysgetForeignKeysgetFunctionsgetImportedKeysgetPrimaryKeysgetSchemasgetTables
Fonctions du pilote ODBC :
SQLTablesSQLColumnsSQLPrimaryKeysSQLForeignKeysSQLGetFunctionsSQLProcedures
- Valeurs:
TRUE: si les arguments de base de données et de schéma sontnull, le pilote récupère uniquement les métadonnées pour la base de données et le schéma spécifiés par le contexte de connexion.L’interaction est décrite plus en détail dans le tableau ci-dessous.
FALSE: si les arguments de base de données et de schéma sontnull, le pilote récupère les métadonnées de l’ensemble des bases de données et schémas du compte.- Par défaut:
FALSE- Remarques complémentaires:
Le contexte de connexion fait simplement référence à la base de données et au schéma actuels de la session, qui peuvent être définis à l’aide de l’une des options suivantes :
Spécifiez l’espace de noms par défaut pour l’utilisateur qui se connecte à Snowflake (et lance la session). Ceci peut être défini pour l’utilisateur à l’aide de la commande CREATE USER ou ALTER USER, mais doit être défini avant que l’utilisateur ne se connecte.
Spécifiez la base de données et le schéma lors de la connexion à Snowflake via le pilote.
Émettez une commande USE DATABASE ou USE SCHEMA dans la session.
Si la base de données ou le schéma a été spécifié par plusieurs de ces options, l’option la plus récente s’applique.
Lorsque CLIENT_METADATA_REQUEST_USE_CONNECTION_CTX est défini sur
TRUE:argument de base de données
argument de schéma
Base de données utilisée
Schéma utilisé
Non nul
Non nul
Argument
Argument
Non nul
Nul
Argument
Tous les schémas
Nul
Non nul
Contexte de connexion
Argument
Nul
Nul
Contexte de connexion
Contexte de la session
Note
Pour le pilote JDBC, ce comportement s’applique à la version 3.6.27 (et ultérieure). Pour le pilote ODBC, ce comportement s’applique à la version 2.12.96 (et ultérieure).
Si vous souhaitez rechercher uniquement la base de données du contexte de connexion, mais souhaitez rechercher tous les schémas de cette base de données, consultez CLIENT_METADATA_USE_SESSION_DATABASE.
CLIENT_METADATA_USE_SESSION_DATABASE¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Booléen
- Clients:
JDBC
- Description:
Ce paramètre s’applique uniquement aux méthodes affectées par CLIENT_METADATA_REQUEST_USE_CONNECTION_CTX.
Ce paramètre s’applique uniquement lorsque les deux conditions suivantes sont remplies :
CLIENT_METADATA_REQUEST_USE_CONNECTION_CTX est
FALSEou non défini.Aucune base de données ou schéma n’est transmis à la fonction ODBC ou à la méthode JDBC correspondante.
Pour certaines fonctions ODBC et méthodes JDBC, ce paramètre peut modifier la portée de la recherche par défaut pour qu’elle s’applique uniquement à la base de données actuelle et non plus à l’ensemble des bases de données. La recherche plus étroite renvoie généralement moins de lignes et s’exécute plus rapidement.
Pour plus de détails, consultez les informations ci-dessous.
- Valeurs:
TRUE:Le pilote recherche tous les schémas dans la base de données du contexte de connexion. (Pour plus d’informations sur le contexte de connexion, consultez la documentation concernant CLIENT_METADATA_REQUEST_USE_CONNECTION_CTX.)
FALSE:Le pilote recherche tous les schémas dans toutes les bases de données.
- Par défaut:
FALSE- Remarques complémentaires:
Lorsque la base de données est null, le schéma est null et CLIENT_METADATA_REQUEST_USE_CONNECTION_CTX est FALSE :
CLIENT_METADATA_USE_SESSION_DATABASE
Comportement
FALSE
Tous les schémas de toutes les bases de données sont recherchés.
TRUE
Tous les schémas de la base de données actuelle sont recherchés.
CLIENT_PREFETCH_THREADS¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Entier
- Clients:
JDBC, ODBC, Python, .NET
- Description:
Paramètre qui spécifie le nombre de threads utilisés par le client pour pré-extraire des ensembles de résultats volumineux. Le pilote tentera de respecter la valeur du paramètre, mais définira des valeurs minimum et maximum (en fonction des ressources de votre système) pour améliorer les performances.
- Valeurs:
1jusqu’à10- Par défaut:
4La plupart des utilisateurs ne devraient pas avoir besoin de définir ce paramètre. Si ce paramètre n’est pas défini par l’utilisateur, le pilote démarre avec la valeur par défaut spécifiée ci-dessus, mais gère également son nombre de threads de manière prudente pour éviter d’utiliser toute la mémoire disponible.
CLIENT_RESULT_CHUNK_SIZE¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Entier
- Clients:
JDBC, Node.js, SQL API, Go
- Description:
Paramètre spécifiant la taille maximale de chaque ensemble (ou morceau) de résultats de requête à télécharger (en MB). Le pilote JDBC télécharge les résultats de la requête en morceaux.
Voir aussi CLIENT_MEMORY_LIMIT.
- Valeurs:
16jusqu’à160- Par défaut:
160La plupart des utilisateurs ne devraient pas avoir besoin de définir ce paramètre. Si ce paramètre n’est pas défini par l’utilisateur, le pilote démarre avec la valeur par défaut spécifiée ci-dessus, mais gère également sa mémoire de manière prudente pour éviter d’utiliser toute la mémoire disponible.
CLIENT_RESULT_COLUMN_CASE_INSENSITIVE¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Booléen
- Clients:
JDBC
- Description:
Paramètre qui indique s’il faut faire correspondre le nom de colonne de façon insensible à la casse dans des méthodes
ResultSet.get*dans JDBC.- Valeurs:
TRUE: correspond aux noms des colonnes de façon insensible à la casse.FALSE: correspond aux noms des colonnes de façon sensible à la casse.- Par défaut:
FALSE
CLIENT_SESSION_KEEP_ALIVE¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Booléen
- Clients:
.NET, Golang, JDBC, Node.js, ODBC, Python,
- Description:
Paramètre qui indique s’il faut forcer un utilisateur à se reconnecter après une période d’inactivité dans une session.
- Valeurs:
TRUE: Snowflake garde la session active indéfiniment, tant que la connexion est active même s’il n’y a aucune activité de l’utilisateur.FALSE: l’utilisateur doit se reconnecter après quatre heures d’inactivité.- Par défaut:
FALSE
Note
Actuellement, le paramètre ne prend effet que lors de l’ouverture de la session. Vous pouvez modifier la valeur du paramètre au niveau de la session en exécutant une commande ALTER SESSION, mais cela n’affecte pas la fonctionnalité de maintien de la session, telle que la prolongation de la session. Pour plus d’informations sur le réglage du paramètre au niveau de la session, voir la documentation du client :
CLIENT_SESSION_KEEP_ALIVE_HEARTBEAT_FREQUENCY¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Entier
- Clients:
SnowSQL, JDBC, Python, Node.js
- Description:
Nombre de secondes entre les tentatives du client pour mettre à jour le jeton pour la session.
- Valeurs:
900jusqu’à3600- Par défaut:
3600
CLIENT_TIMESTAMP_TYPE_MAPPING¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Chaîne (constante)
- Clients:
N’importe quel
- Description:
Spécifie la variation TIMESTAMP_* à utiliser lors de la liaison de variables d’horodatage pour les applications JDBC ou ODBC qui utilisent l’API de liaison pour charger les données.
- Valeurs:
TIMESTAMP_LTZouTIMESTAMP_NTZ- Par défaut:
TIMESTAMP_LTZ
CORTEX_MODELS_ALLOWLIST¶
- Type:
Compte — Ne peut être défini que pour le compte
- Type de données:
Chaîne
- Description:
Spécifie les modèles auxquels les utilisateurs du compte peuvent accéder. Ce paramètre permet d’autoriser les modèles de listes pour tous les utilisateurs du compte. Si vous devez accorder à des utilisateurs spécifiques un accès supérieur à celui que vous avez spécifié dans la liste d’autorisation, vous devez utiliser le contrôle d’accès basé sur les rôles. Pour plus d’informations, voir Paramètre de la liste d’autorisation au niveau du compte.
Lorsque des utilisateurs font une requête, Snowflake Cortex évalue le paramètre pour déterminer si l’utilisateur peut accéder au modèle.
- Valeurs:
'All': permet d’accéder à tous les modèles, y compris les modèles affinés.Exemple :
'model1,model2,...': fournit l’accès aux modèles spécifiés dans une liste séparée par des virgules.Exemple :
'None': empêche l’accès à tout modèle.Exemple :
- Par défaut:
'All'
CORTEX_ENABLED_CROSS_REGION¶
- Type:
Compte — Ne peut être défini que pour le compte
- Type de données:
Chaîne
- Description:
Spécifie les régions dans lesquelles une demande d’inférence peut être traitée au cas où la demande ne peut pas être traitée dans la région où la demande est initialement placée. Spécifier
DISABLEDdésactive l’inférence interrégionale. Pour des exemples et des détails, voir Inférence interrégionale.- Valeurs:
Ce paramètre peut être défini sur l’une des valeurs suivantes :
DISABLEDANY_REGIONListe séparée par des virgules comprenant une ou plusieurs des valeurs suivantes :
AWS_APJAWS_AUAWS_EUAWS_USAWS_GLOBALAZURE_EUAZURE_USAZURE_GLOBALGCP_USGCP_GLOBAL
Explication de chaque valeur de paramètre¶ Valeur
Comportement
DISABLEDLes requêtes d’inférence seront traitées dans :
La région où la demande est placée.
ANY_REGIONLes requêtes d’inférence peuvent être acheminées vers :
N’importe quelle région prenant en charge l’inférence interrégionale (répertoriée dans cette table) et disposant d’une disponibilité, y compris la région où la demande est placée.
AWS_APJLes demandes d’inférence seront traitées dans la région où la demande est effectuée et dans les régions AWS suivantes
AWS Asie-Pacifique (Tokyo) ap-northeast-1
AWS Asie-Pacifique (Séoul) ap-northeast-2
AWS Asie-Pacifique (Osaka) ap-northeast-3
AWS Asie-Pacifique (Mumbai) ap-south-1
AWS Asie-Pacifique (Hyderabad) ap-south-2
AWS Asie-Pacifique (Singapour) ap-southeast-1
AWS Asie-Pacifique (Sydney) ap-southeast-2
AWS Asie-Pacifique (Melbourne) ap-southeast-4
AWS_AULes demandes d’inférence seront traitées dans la région où la demande est effectuée et dans les régions AWS suivantes
AWS Asie-Pacifique (Sydney) ap-southeast-2
AWS Asie-Pacifique (Melbourne) ap-southeast-4
AWS_EULes demandes d’inférence seront traitées dans la région où la demande est effectuée et dans les régions AWS suivantes qui sont (et seront) situées dans l’Union européenne :
AWS Europe (Francfort) eu-central-1
AWS Europe (Stockholm) eu-north-1
AWS Europe (Milan) eu-south-1
AWS Europe (Espagne) eu-south-2
AWS Europe (Irlande) eu-west-1
AWS Europe (Paris) eu-west-3
AWS_USLes demandes d’inférence seront traitées dans la région où la demande est effectuée et dans les régions AWS suivantes qui sont (et seront) situées aux États-Unis :
AWS US Est (Virginie du Nord) us-east-1
AWS US Est (Ohio) us-east-2
AWS US Ouest (Oregon) us-west-2
AWS_GlobalLes demandes d’inférence seront traitées dans la région où la demande est effectuée et dans les régions commerciales AWS suivantes.
AZURE_EULes demandes d’inférence seront traitées dans la région où la demande est effectuée et dans les régions Azure suivantes, qui sont (et seront) situées dans l’Union européenne :
Azure Europe (Pays-Bas) westeurope
Azure Europe (France) francecentral
Azure Europe (Allemagne) germanywestcentral
Azure Europe (Italie) italynorth
Azure Europe (Pologne) polandcentral
Azure Europe (Espagne) spaincentral
Azure Europe (Suède) swedencentral
AZURE_USLes demandes d’inférence seront traitées dans la région où la demande est effectuée et dans les régions Azure suivantes, qui sont (et seront) situées aux États-Unis :
Azure US (Virginie) eastus2
Azure US (Virginie) eastus
Azure US (Californie) westus
Azure US (Phoenix) westus3
Azure US (Illinois) northcentralus
Azure US (Texas) southcentralus
AZURE_GlobalLes demandes d’inférence seront traitées dans la région où la demande est effectuée et dans les régions commerciales Azure.
GCP_USLes demandes d’inférence seront traitées dans la région où la demande est effectuée et dans les régions GCP suivantes qui sont (et seront) situées aux États-Unis :
GCP US (Iowa) us-central1
GCP US (Oregon) us-west1
GCP US (Las Vegas) us-west4
GCP US (N. Virginia) us-east4
GCP_GlobalLes demandes d’inférence seront traitées dans la région où la demande est effectuée et dans les régions commerciales GCP suivantes.
- Par défaut:
La valeur par défaut dépend du moment et de l’emplacement où le compte a été créé :
ANY_REGIONpour les nouveaux comptes dans les nouvelles organisations au sein des régions commerciales créées après le 9 mars 2026.DISABLEDpour tous les autres comptes, y compris les régions gouvernementales.
CSV_TIMESTAMP_FORMAT¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Chaîne
- Description:
Spécifie le format des valeurs TIMESTAMP dans les fichiers CSV téléchargés depuis Snowsight.
Si ce paramètre n’est pas défini, TIMESTAMP_LTZ_OUTPUT_FORMAT sera utilisé pour les valeurs TIMESTAMP_LTZ, TIMESTAMP_TZ_OUTPUT_FORMAT sera utilisé pour les valeurs TIMESTAMP_TZ et TIMESTAMP_NTZ_OUTPUT_FORMAT pour les valeurs TIMESTAMP_NTZ.
Pour plus d’informations, voir Formats d’entrée et de sortie de la date et de l’heure ou Télécharger les résultats de votre requête.
- Valeurs:
Tout format d’horodatage valide et pris en charge.
- Par défaut:
Aucune valeur.
DATA_METRIC_SCHEDULE¶
- Type:
Objet (pour les tables)
- Type de données:
Chaîne
- Description:
Spécifie la planification d’exécution des fonctions de métrique des données associées à la table.
- Valeurs:
La planification peut être basée sur un nombre défini de minutes, une expression cron ou un événement de DML sur la table qui n’implique pas de reclustering. Pour plus de détails, voir :
- Par défaut:
60 MINUTE
DATA_RETENTION_TIME_IN_DAYS¶
- Type:
Objet (pour bases de données, schémas et tables) — Peut être défini pour Compte » Base de données » Schéma » Table
- Type de données:
Entier
- Description:
Nombre de jours pendant lesquels Snowflake conserve les données historiques pour effectuer des actions Time Travel (SELECT, CLONE, UNDROP) sur l’objet. Une valeur de
0désactive efficacement Time Travel pour la base de données, le schéma ou la table spécifiés. Pour plus d’informations, voir Compréhension et utilisation de la fonction Time Travel.- Valeurs:
0ou1(pour l’édition Standard)0à90(pour l’édition Enterprise ou ultérieure)- Par défaut:
1
DATE_INPUT_FORMAT¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Chaîne
- Description:
Spécifie le format d’entrée pour le type de données DATE. Pour plus d’informations, voir Formats d’entrée et de sortie de la date et de l’heure.
- Valeurs:
Tout format de date valide et pris en charge ou
AUTO(
AUTOspécifie que Snowflake tente de détecter automatiquement le format des dates stockées dans le système pendant la session)- Par défaut:
AUTO
DATE_OUTPUT_FORMAT¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Chaîne
- Description:
Spécifie le format d’affichage pour le type de données DATE. Pour plus d’informations, voir Formats d’entrée et de sortie de la date et de l’heure.
- Valeurs:
Tout format de date valide et pris en charge
- Par défaut:
YYYY-MM-DD
DEFAULT_DBT_VERSION¶
- Type:
Compte — Ne peut être défini que pour le compte
- Type de données:
Chaîne
- Description:
Specifies the default version for all future dbt project objects created in an account. Setting this value on the account enables organization administrators to opt-in to newer versions (for example, changing the default to
1.10.15) without requiring users to manually update CREATE DBT PROJECT DDL statements for every individual project. For more information, see Définir la version par défaut au niveau du compte.- Valeurs:
1.9.4ou1.10.15- Par défaut:
1.9.4
DEFAULT_DDL_COLLATION¶
- Type:
Objet (pour bases de données, schémas et tables) — Peut être défini pour Compte » Base de données » Schéma » Table
- Type de données:
Chaîne
- Description:
Définit le classement par défaut utilisé pour les opérations DDL suivantes :
ALTER TABLE … ADD COLUMN
La définition de ce paramètre oblige toutes les colonnes créées ultérieurement dans les objets affectés (table, schéma, base de données ou compte) à disposer du classement spécifié par défaut, sauf si le classement de la colonne est explicitement mentionné dans le DDL.
Par exemple, si
DEFAULT_DDL_COLLATION = 'en-ci', les deux instructions suivantes sont équivalentes :Note
Ce paramètre n’est pas pris en charge pour les tables dynamiques et Tables Apache Iceberg™. Ce paramètre n’est pas pris en charge sur les colonnes indexées pour les tableaux hybrides.
- Valeurs:
Toute spécification de classement valide et prise en charge.
- Par défaut:
Chaîne vide
Note
Pour définir le classement par défaut du compte, utilisez la commande suivante :
Le classement par défaut des colonnes de table peut être défini au niveau de la table, du schéma ou de la base de données lors de la création ou à tout moment par la suite :
DEFAULT_NOTEBOOK_COMPUTE_POOL_CPU¶
- Type:
Objet (pour bases de données et schémas) — Peut être défini pour Compte » Base de données » Schéma
- Type de données:
Chaîne
- Description:
Définit le pool de calcul préféré du CPU utilisé pour Notebooks sur Container Runtime CPU.
- Valeurs:
Nom d’un pool de calcul dans votre compte.
- Par défaut:
SYSTEM_COMPUTE_POOL_CPU (voir Pools de calcul du système).
DEFAULT_NOTEBOOK_COMPUTE_POOL_GPU¶
- Type:
Objet (pour bases de données et schémas) — Peut être défini pour Compte » Base de données » Schéma
- Type de données:
Chaîne
- Description:
Définit le pool de calcul préféré du GPU utilisé pour Notebooks sur Container Runtime GPU.
- Valeurs:
Nom d’un pool de calcul dans votre compte.
- Par défaut:
SYSTEM_COMPUTE_POOL_GPU (voir Pools de calcul du système).
DEFAULT_NULL_ORDERING¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Chaîne
- Description:
Spécifie l’ordre par défaut des valeurs NULL dans un jeu de résultats.
L’ordre des valeurs NULL dans les lignes dépend de la clause ORDER BY :
Lorsque l’ordre de tri est ASC (par défaut) et que ce paramètre est défini sur
LAST(par défaut), les valeurs NULL sont renvoyées en dernier. Par conséquent, sauf indication contraire, les valeurs NULL sont considérées comme plus élevées que toutes les valeurs autres que NULL.Lorsque l’ordre de tri est ASC et que ce paramètre est défini sur
FIRST, les valeurs NULL sont retournées en premier.Lorsque l’ordre de tri est DESC et que ce paramètre est défini sur
FIRST, les valeurs NULL sont retournées en dernier.Lorsque l’ordre de tri est DESC et que ce paramètre est défini sur
LAST, les valeurs NULL sont retournées en premier.
Si un ordre NULL est spécifié dans la clause ORDER BY avec NULLS FIRST ou NULLS LAST, l’ordre spécifié est prioritaire sur toute valeur de DEFAULT_NULL_ORDERING.
- Valeurs:
FIRST: les valeurs NULL sont inférieures à toutes les valeurs non NULL.LAST: les valeurs NULL sont supérieures à toutes les valeurs non NULL.- Par défaut:
LAST
DEFAULT_STREAMLIT_COMPUTE_POOL¶
- Type:
Compte — Peut uniquement être défini pour Compte
- Type de données:
Chaîne
- Description:
Spécifie le pool de calcul par défaut à utiliser pour les applications Streamlit d’exécution de conteneurs.
Lorsque vous exécutez CREATE STREAMLIT, si vous spécifiez une exécution de conteneurs dans la propriété RUNTIME_NAME et que vous ne spécifiez pas la propriété COMPUTE_POOL, Snowflake utilise le pool de calcul spécifié dans le paramètre DEFAULT_STREAMLIT_COMPUTE_POOL. Ce pool de calcul par défaut est résolu au moment de la création. Mettre à jour DEFAULT_STREAMLIT_COMPUTE_POOL ne mettra pas à jour la propriété COMPUTE_POOL sur les applications Streamlit existantes. Pour plus d’informations, voir Configuration de vos propres pools de calcul pour les applications Streamlit.
- Valeurs:
Nom d’un pool de calcul dans votre compte.
- Par défaut:
SYSTEM_COMPUTE_POOL_CPU
DEFAULT_STREAMLIT_NOTEBOOK_WAREHOUSE¶
- Type:
Objet (pour bases de données et schémas) — Peut être défini pour Compte » Base de données » Schéma
- Type de données:
Chaîne
- Description:
Spécifie le nom de l’entrepôt par défaut à utiliser lors de la création d’un carnet.
Pour plus d’informations, voir ALTER ACCOUNT, ALTER DATABASE, et ALTER SCHEMA.
- Valeurs:
Le nom de tout entrepôt existant.
- Par défaut:
SYSTEM$STREAMLIT_NOTEBOOK_WH
DISABLE_USER_PRIVILEGE_GRANTS¶
- Type:
Objet (pour les utilisateurs) — Ne peut être réglé que pour le compte
- Type de données:
Booléen
- Description:
Contrôle si les utilisateurs d’un compte peuvent accorder des privilèges directement à d’autres utilisateurs.
Désactiver les octrois de privilèges utilisateur (c’est-à-dire la définition de DISABLE_USER_PRIVILEGE_GRANTS sur
TRUE) n’affecte pas les autorisations existantes accordées aux utilisateurs. Les autorisations existantes accordées à des utilisateurs continuent de conférer des privilèges à ces utilisateurs. Pour plus d’informations, voir GRANT <privilèges> … TO USER.- Valeurs:
TRUE: les utilisateurs du compte ne peuvent pas accorder de privilèges à un autre utilisateur.FALSE: les utilisateurs du compte peuvent accorder des privilèges à un autre utilisateur.- Par défaut:
FALSE
DISALLOWED_SPCS_WORKLOAD_TYPES¶
- Type:
Compte — Ne peut être défini que pour le compte
- Type de données:
Chaîne
- Description:
Spécifie les types de charges de travail qui ne sont pas autorisés dans votre compte à être déployés vers Snowpark Container Services. Voir aussi ALLOWED_SPCS_WORKLOAD_TYPES.
- Valeurs:
La valeur est une liste, séparée par des virgules, des types de charges de travail pris en charge suivants :
USER: Toutes les charges de travail directement déployées par les utilisateurs.NOTEBOOK: Snowflake Notebooks.STREAMLIT: Streamlit dans Snowflake.MODEL_SERVING: Service du modèle ML.ML_JOB: Tâches ML Snowflake.ALL: Toutes les charges de travail.
- Par défaut:
Chaîne vide
Note
Si vous configurez les deux paramètres DISALLOWED_SPCS_WORKLOAD_TYPES et ALLOWED_SPCS_WORKLOAD_TYPES, Snowflake applique d’abord DISALLOWED_SPCS_WORKLOAD_TYPES. Par exemple, si vous configurez ces deux paramètres et spécifiez la charge de travail NOTEBOOK, les charges de travail NOTEBOOK ne peuvent pas s’exécuter sur Snowpark Container Services.
ENABLE_AUTOMATIC_SENSITIVE_DATA_CLASSIFICATION_LOG¶
- Type:
Compte — Ne peut être défini que pour le compte
- Type de données:
Booléen
- Description:
Contrôle si les événements de classification des données sensibles sont enregistrés dans le tableau des événements de l’utilisateur.
- Valeurs:
TRUE: Snowflake enregistre les événements pour la classification des données sensibles dans le tableau des événements utilisateur.FALSE: les événements pour la classification des données sensibles ne sont pas enregistrés.- Par défaut:
TRUE
ENABLE_BUDGET_EVENT_LOGGING¶
- Type:
Compte — Ne peut être défini que pour le compte
- Type de données:
Booléen
- Description:
Contrôle si les données de télémétrie sont collectées pour des budgets.
- Valeurs:
TRUE: Snowflake enregistre les données de télémétrie liées aux budgets dans un tableau des événements.FALSE: Snowflake n’enregistre pas les données de télémétrie qui sont liées aux budgets.- Par défaut:
TRUE
ENABLE_DATA_COMPACTION¶
- Type:
Objet (pour bases de données, schémas et tables Iceberg) — Peut être défini pour Compte » Base de données » Schéma » Table Iceberg
- Type de données:
Booléen
- Description:
Spécifie si Snowflake doit activer le compactage des données sur des Tables Apache Iceberg™ gérées par Snowflake.
- Valeurs:
TRUE: Snowflake effectue le compactage des données sur les tables.FALSE: Snowflake n’effectue pas de compactage de données sur les tables.- Par défaut:
TRUE
ENABLE_EGRESS_COST_OPTIMIZER¶
- Type:
Compte — Ne peut être défini que pour le compte
- Type de données:
Booléen
- Description:
Active ou désactive l’outil d’optimisation des coûts de sortie de l’exécution automatique inter-Cloud des listings.
- Valeurs:
TRUE: activer l’outil d’optimisation des coûts de sortie.FALSE: désactiver l’optimiseur de coûts de sortie.- Par défaut:
FALSE
Pour plus d’informations, voir Réplication automatique pour les annonces.
ENABLE_GET_DDL_USE_DATA_TYPE_ALIAS¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Booléen
- Description:
Spécifie si la sortie renvoyée par la fonction GET_DDL contient les synonymes de type de données spécifiés dans l’instruction DDL d’origine. Les synonymes de type de données sont également appelés alias de type de données.
- Valeurs:
TRUE: Affiche les alias de type de données spécifiés dans l’instruction DDL d’origine.FALSE: Remplace les alias de type de données spécifiés dans l’instruction DDL d’origine avec des noms de types de données Snowflake standard.
Vous pouvez définir ce paramètre sur TRUE pour générer des instructions DDL utilisant la fonction GET_DDL qui spécifie des alias de type de données tels que définis dans les instructions SQL d’origine, qui peuvent être nécessaires pour préserver l’intégrité du modèle de données lors des migrations.
Voici quelques exemples d’alias de types de données :
CHAR est un alias pour le type de données VARCHAR.
BIGINT est un alias pour le type de données NUMBER.
DATETIME est un alias pour le type de données TIMESTAMP_NTZ.
L’instruction suivante crée une table en utilisant les alias des types de données :
Lorsque ce paramètre est défini sur FALSE, la fonction GET_DDL renvoie la sortie suivante :
Lorsque ce paramètre est défini sur TRUE, la fonction GET_DDL renvoie la sortie suivante :
- Par défaut:
FALSE
ENABLE_ICEBERG_MERGE_ON_READ¶
- Type:
Objet (pour les bases de données, schémas et tables Apache Iceberg™) — Peut être défini pour Compte » Base de données » Schéma » Table Iceberg
- Type de données:
Booléen
- Description:
Spécifie s’il convient d’activer le comportement de fusion sur lecture pour les Tables Apache Iceberg™ gérées par Snowflake. Pour plus d’informations, voir Utiliser les suppressions de niveau ligne.
- Valeurs:
TRUE: activer le comportement de fusion sur lecture :Si vous utilisez le format Iceberg v2 avec des tables Iceberg, permet d’utiliser des suppressions au niveau des lignes via des fichiers de suppression positionnels.
Si vous utilisez le format Iceberg v3 avec des tables Iceberg, permet d’utiliser des suppressions au niveau des lignes via des vecteurs de suppression.
Pour plus d’informations sur le comportement de fusion sur lecture et de copie sur écriture, consultez Utiliser les suppressions de niveau ligne.
Note
Pour spécifier la version Iceberg des tables, utilisez le paramètre ICEBERG_VERSION_DEFAULT ou le paramètre ICEBERG_VERSION.
FALSE: Active le comportement de copie sur écriture pour les opérations DML.- Par défaut:
TRUE
ENABLE_IDENTIFIER_FIRST_LOGIN¶
- Type:
Compte — Ne peut être défini que pour le compte
- Type de données:
Booléen
- Description:
Détermine le flux de connexion pour les utilisateurs. Lorsque cette option est activée, Snowflake demande aux utilisateurs leur nom d’utilisateur ou leur adresse e-mail avant de leur présenter des méthodes d’authentification. Pour plus de détails, voir Connexion avec identificateur d’abord.
- Valeurs:
TRUE: Snowflake utilise un flux de connexion avec identificateur d’abord pour authentifier les utilisateurs.FALSE: Snowflake présente toutes les options de connexion possibles, même si ces options ne s’appliquent pas à un utilisateur particulier.- Par défaut:
FALSE
ENABLE_INTERNAL_STAGES_PRIVATELINK¶
- Type:
Compte — Ne peut être défini que pour le compte
- Type de données:
Booléen
- Description:
Indique si la fonction SYSTEM$GET_PRIVATELINK_CONFIG renvoie la clé
private-internal-stagesdans le résultat de la requête. La valeur correspondante dans le résultat de la requête est utilisée pendant le processus de configuration pour la connexion privée à des zones de préparation internes. La valeur de ce paramètre affecte également le comportement des fonctions système liées à la connectivité privée. Par exemple,TRUEactive SYSTEM$REVOKE_STAGE_PRIVATELINK_ACCESS etFALSEdésactive SYSTEM$REVOKE_STAGE_PRIVATELINK_ACCESS.- Valeurs:
TRUE: renvoie la clé et la valeurprivate-internal-stagesdans le résultat de la requête.FALSE: ne renvoie pas la clé et la valeurprivate-internal-stagesdans le résultat de la requête.- Par défaut:
FALSE
ENABLE_SNOWFLAKE_MANAGED_STORAGE_VOLUME_PRIVATELINK¶
- Type:
Compte — Ne peut être défini que pour le compte
- Type de données:
Booléen
- Description:
Spécifie si la fonction SYSTEM$GET_PRIVATELINK_CONFIG renvoie les clés
privatelink-snowflake-managed-storage-volume-nfsetprivatelink-snowflake-managed-storage-volume-fsdans le résultat de la requête sur les déploiements Azure. Les valeurs correspondantes dans le résultat de la requête sont utilisées pendant le processus de configuration pour la connexion privée aux volumes de stockage gérés par Snowflake. La valeur de ce paramètre affecte également le comportement des fonctions système liées à la connexion privée. Par exemple,TRUEdésactive SYSTEM$REVOKE_SNOWFLAKE_MANAGED_STORAGE_VOLUME_PRIVATELINK_ACCESS etFALSEdésactive SYSTEM$REVOKE_SNOWFLAKE_MANAGED_STORAGE_VOLUME_PRIVATELINK_ACCESS.- Valeurs:
TRUE: Renvoie le clésprivatelink-snowflake-managed-storage-volume-nfsetprivatelink-snowflake-managed-storage-volume-fset les valeurs dans le résultat de la requête pour les déploiements Azure.FALSE: ne renvoie pas ces clés et valeurs dans le résultat de la requête.- Par défaut:
FALSE
ENABLE_NOTEBOOK_CREATION_IN_PERSONAL_DB¶
- Type:
Utilisateur — Peut être défini pour Compte > Utilisateur
- Type de données:
Booléen
- Description:
Indique si les utilisateurs peuvent créer des notebooks privés (stockés dans leurs bases de données personnelles). Lorsque TRUE, les utilisateurs du compte peuvent créer des notebooks privés (en supposant que les autres privilèges nécessaires sont accordés).
- Valeurs:
TRUE: Permet aux utilisateurs de créer des notebooks privés.FALSE: Empêche les utilisateurs de créer des notebooks privés.- Par défaut:
FALSE
ENABLE_SPCS_BLOCK_STORAGE_SNOWFLAKE_FULL_ENCRYPTION_ENFORCEMENT¶
- Type:
Compte — Ne peut être défini que pour le compte
- Type de données:
Booléen
- Description:
Permet d’appliquer le type de chiffrement SNOWFLAKE_FULL pour les volumes de stockage en bloc et instantanés Snowpark Container Services.
- Valeurs:
TRUE: Renforce la création des volumes de stockage en bloc et instantanés SPCS uniquement avec le type de chiffrement SNOWFLAKE_FULL. Le type de chiffrement SNOWFLAKE_SSE n’est pas autorisé. Tous les volumes de stockage en blocs et instantanés existants avec le type de chiffrement SNOWFLAKE_SSE doivent être migrés vers SNOWFLAKE_FULL avant d’activer ce paramètre. Définir la valeur du paramètre sur TRUE avec les volumes chiffrés ou les résultats d’instantanés SNOWFLAKE_FULL existants entraîne une erreur.FALSE: Les types de chiffrement SNOWFLAKE_SSE et SNOWFLAKE_FULL sont autorisés pour les volumes de stockage en bloc et les instantanés SPCS du compte.- Par défaut:
FALSE
ENABLE_TAG_PROPAGATION_EVENT_LOGGING¶
- Type:
Compte — Ne peut être défini que pour le compte
- Type de données:
Booléen
- Description:
Contrôle si les données de télémétrie sont collectées pour la propagation automatique des balises.
- Valeurs:
TRUE: Snowflake enregistre les données de télémétrie liées à la propagation des balises dans un tableau des événements.FALSE: Snowflake n’enregistre pas les données de télémétrie liées à la propagation des balises.- Par défaut:
FALSE
ENABLE_TRI_SECRET_AND_REKEY_OPT_OUT_FOR_IMAGE_REPOSITORY¶
- Type:
Compte — Ne peut être défini que pour le compte
- Type de données:
Booléen
- Description:
Spécifie le choix pour le référentiel d’images de refuser d’utiliser Tri-Secret Secure et Periodic Rekeying.
- Valeurs:
TRUE: annule Tri-Secret Secure et la resaisie périodique pour le référentiel d’images.FALSE: Interdit la création d’un référentiel d’images pour Tri-Secret Secure et la resaisie périodique pour les comptes. Interdit également l’activation de Tri-Secret Secure et de la resaisie périodique pour les comptes qui ont activé le référentiel d’images.- Par défaut:
FALSE
ENABLE_UNHANDLED_EXCEPTIONS_REPORTING¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Booléen
- Description:
Spécifie si Snowflake peut capturer – dans une table d’événements – les messages du journal ou les données d’événement de trace pour les exceptions non gérées dans la procédure ou le code du gestionnaire des UDF. Pour plus d’informations, voir Capturer des messages provenant d’exceptions non gérées.
- Valeurs:
TRUE: les données relatives aux exceptions non gérées sont capturées en tant que données d’enregistrement ou de trace si l’enregistrement et le traçage sont activés.FALSE: les données relatives aux exceptions non gérées ne sont pas capturées.- Par défaut:
TRUE
ENABLE_UNLOAD_PHYSICAL_TYPE_OPTIMIZATION¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Booléen
- Description:
Spécifie s’il faut définir le schéma pour les fichiers Parquet déchargés en fonction des types de données de colonne logiques (c’est-à-dire les types dans la requête de déchargement SQL ou la table source) ou des valeurs de colonne déchargées (c’est-à-dire les plus petits types de données et la précision qui prend en charge les valeurs dans les colonnes de sortie de la table source ou de l’instruction de déchargement SQL).
- Valeurs:
TRUE: le schéma des fichiers de données Parquet déchargés est déterminé par les valeurs des colonnes de la table source ou de la requête de déchargement SQL. Snowflake optimise les colonnes de la table en réglant la plus petite précision qui accepte toutes les valeurs. Le déchargeur suit ce schéma lors de l’écriture des valeurs dans les fichiers Parquet. Le type de données et la précision d’une colonne de sortie sont réglés sur le plus petit type de données et la précision qui prennent en charge ses valeurs dans l’instruction de déchargement SQL ou la table source. Acceptez ce paramètre pour de meilleures performances et des fichiers de données plus petits.FALSE: le schéma est déterminé par les types de données des colonnes logiques. Définissez cette valeur pour un schéma de fichier de sortie cohérent.- Par défaut:
TRUE
ENABLE_UNREDACTED_QUERY_SYNTAX_ERROR¶
- Type:
Utilisateur — Peut être défini pour Compte » Utilisateur
- Type de données:
Booléen
- Description:
Contrôle si le texte de la requête est rédigé si une requête SQL échoue en raison d’une erreur de syntaxe ou d’analyse. Si
FALSE, le contenu d’une requête qui a échoué est rédigé dans les vues, les pages et les fonctions qui fournissent un historique des requêtes.Seuls les utilisateurs dont le rôle est doté du privilège AUDIT ou qui en héritent peuvent définir le paramètre ENABLE_UNREDACTED_QUERY_SYNTAX_ERROR.
Lorsque vous utilisez la commande ALTER USER pour définir le paramètre sur
TRUEpour un utilisateur particulier, modifiez l’utilisateur qui doit voir le texte de la requête, et non l’utilisateur qui a exécuté la requête (s’il s’agit d’utilisateurs différents).- Valeurs:
TRUE: désactive la rédaction du texte de la requête pour les requêtes qui échouent en raison d’une erreur de syntaxe ou d’analyse.FALSE: rédige le contenu d’une requête à partir de vues, de pages et de fonctions qui fournissent un historique des requêtes lorsqu’une requête échoue en raison d’une erreur de syntaxe ou d’analyse.- Par défaut:
FALSE
ENABLE_UNREDACTED_SECURE_OBJECT_ERROR¶
- Type:
Utilisateur — Peut être défini pour Compte » Utilisateur
- Type de données:
Booléen
- Description:
Contrôle si les messages d’erreur relatifs aux objets sécurisés sont expurgés dans les métadonnées. Pour plus d’informations, voir Objets sécurisés : Réaction aux informations contenues dans les messages d’erreur.
Seuls les utilisateurs dont le rôle est doté du privilège AUDIT ou qui en héritent peuvent définir le paramètre ENABLE_UNREDACTED_SECURE_OBJECT_ERROR.
Lorsque vous utilisez la commande ALTER USER pour définir le paramètre sur
TRUEpour un utilisateur particulier, modifiez l’utilisateur qui doit voir les messages d’erreur expurgés dans les métadonnées, et non l’utilisateur qui a provoqué l’erreur.- Valeurs:
TRUE: désactive la rédaction des messages d’erreur relatifs aux objets sécurisés dans les métadonnées.FALSE: expurge le contenu des messages d’erreur relatifs aux objets sécurisés dans les métadonnées.- Par défaut:
FALSE
ENFORCE_NETWORK_RULES_FOR_INTERNAL_STAGES¶
- Type:
Compte — Ne peut être défini que pour le compte
- Type de données:
Booléen
- Description:
Spécifie si une politique réseau qui utilise des règles de réseau peut restreindre l’accès aux zones de préparation internes AWS.
Ce paramètre n’a aucun effet sur les politiques réseau qui n’utilisent pas de règles de réseau.
Ce paramètre au niveau du compte affecte à la fois les politiques réseau au niveau du compte et au niveau de l’utilisateur.
Pour plus de détails sur l’utilisation des politiques réseau et des règles de réseau pour restreindre l’accès à des zones de préparation internes AWS, y compris sur l’utilisation de ce paramètre, consultez Protection des zones de préparation internes sur AWS.
- Valeurs:
TRUE: permet aux politiques de réseau qui utilisent des règles de réseau de restreindre l’accès aux zones de préparation internes AWS. La règle de réseau doit également utiliser lesMODEetTYPEappropriés pour restreindre l’accès à la zone de préparation interne.FALSE: les politiques réseau ne limitent jamais l’accès aux zones de préparation internes.- Par défaut:
FALSE
ENFORCE_NETWORK_RULES_FOR_SNOWFLAKE_MANAGED_STORAGE_VOLUME¶
- Type:
Compte — Ne peut être défini que pour le compte
- Type de données:
Booléen
- Description:
Spécifie si une politique réseau qui utilise des règles réseau peut restreindre l’accès aux volumes de stockage gérés par Snowflake AWS.
Ce paramètre n’a aucun effet sur les politiques réseau qui n’utilisent pas de règles de réseau.
Ce paramètre au niveau du compte affecte uniquement les politiques réseau au niveau du compte.
Pour plus de détails sur l’utilisation des politiques réseau et des règles réseau pour restreindre l’accès aux volumes de stockage gérés par Snowflake, voir Protection des volumes de stockage gérés par Snowflake sur AWS.
- Valeurs:
TRUE: Autorise les politiques réseau qui utilisent des règles réseau pour restreindre l’accès aux volumes de stockage gérés par Snowflake. La règle de réseau doit également utiliser les bonsMODEet:code:TYPEpour restreindre l’accès au volume.FALSE: les politiques réseau ne restreignent jamais l’accès aux volumes de stockage gérés par Snowflake.- Par défaut:
FALSE
ERROR_ON_NONDETERMINISTIC_MERGE¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Booléen
- Description:
Indique s’il faut retourner une erreur lorsque la commande MERGE est utilisée pour mettre à jour ou supprimer une ligne cible qui joint plusieurs lignes sources et que le système ne peut pas déterminer l’action à effectuer sur la ligne cible.
- Valeurs:
TRUE: une erreur est retournée qui inclut les valeurs d’une des lignes cibles qui a causé l’erreur.FALSE: aucune erreur n’est renvoyée et la fusion se termine avec succès, mais les résultats de la fusion ne sont pas déterministes.- Par défaut:
TRUE
ERROR_ON_NONDETERMINISTIC_UPDATE¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Booléen
- Description:
Indique s’il faut retourner une erreur lorsque la commande UPDATE est utilisée pour mettre à jour une ligne cible qui joint plusieurs lignes sources et que le système ne peut pas déterminer l’action à effectuer sur la ligne cible.
- Valeurs:
TRUE: une erreur est retournée qui inclut les valeurs d’une des lignes cibles qui a causé l’erreur.FALSE: aucune erreur n’est retournée et la mise à jour est terminée, mais les résultats de la mise à jour ne sont pas déterministes.- Par défaut:
FALSE
EVENT_TABLE¶
- Type:
Objet — Peut être défini pour Compte » Base de données
- Type de données:
Chaîne
- Description:
Spécifie le nom de la table d’événements pour connecter les messages des procédures stockées et les UDFs contenus par l’objet auquel la table d’événements est associée.
L’association d’une table d’événements à une base de données est disponible à partir de Enterprise Edition.
- Valeurs:
Toute table d’événements existante créée par l’exécution de la commande CREATE EVENT TABLE.
- Par défaut:
Aucun(e)
EXTERNAL_OAUTH_ADD_PRIVILEGED_ROLES_TO_BLOCKED_LIST¶
- Type:
Compte — Ne peut être défini que pour le compte
- Type de données:
Booléen
- Description:
Détermine si les rôles ACCOUNTADMIN, ORGADMIN, GLOBALORGADMIN et SECURITYADMIN peuvent être utilisés comme rôle principal lors de la création d’une session Snowflake basée sur le jeton d’accès du serveur d’autorisation External OAuth.
- Valeurs:
TRUE: ajoute les rôles ACCOUNTADMIN, ORGADMIN, GLOBALORGADMIN et SECURITYADMIN à la propriétéEXTERNAL_OAUTH_BLOCKED_ROLES_LISTde l’intégration de sécurité External OAuth, ce qui signifie que ces rôles ne peuvent pas être utilisés comme rôle principal lors de la création d’une session Snowflake utilisant l’authentification External OAuth.FALSE: retire les rôles ACCOUNTADMIN, ORGADMIN, GLOBALORGADMIN et SECURITYADMIN de la liste des rôles bloqués définis par la propriétéEXTERNAL_OAUTH_BLOCKED_ROLES_LISTde l’intégration de sécurité External OAuth.- Par défaut:
TRUE
EXTERNAL_VOLUME¶
Objet (pour les bases de données, schémas et tables Apache Iceberg™) — Peut être défini pour Compte » Base de données » Schéma » Table Iceberg
- Type de données:
Chaîne
- Description:
Spécifie le volume externe des tables Apache Iceberg™. Pour plus d’informations, voir la documentation de tables Iceberg.
- Valeurs:
Tout identificateur de volume externe valide.
- Par défaut:
Aucun(e)
GEOGRAPHY_OUTPUT_FORMAT¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Chaîne (constante)
- Description:
Format d’affichage pour les valeurs GEOGRAPHY.
Pour EWKT et EWKB, le SRID est toujours 4326 dans la sortie. Consultez la note sur le traitement d’EWKT et d’EWKB.
- Valeurs:
GeoJSON,WKT,WKB,EWKT, ouEWKB- Par défaut:
GeoJSON
GEOMETRY_OUTPUT_FORMAT¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Chaîne (constante)
- Description:
Format d’affichage pour les valeurs GEOMETRY.
- Valeurs:
GeoJSON,WKT,WKB,EWKT, ouEWKB- Par défaut:
GeoJSON
HYBRID_TABLE_LOCK_TIMEOUT¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Entier
- Description:
Nombre de secondes à attendre lors de la tentative d’acquisition de verrous au niveau des lignes sur une table hybride, avant l’expiration du délai et l’abandon de l’instruction.
- Valeurs:
0à un nombre entier quelconque (sans limite). Une valeur de0désactive le verrouillage d’attente (c’est-à-dire que l’instruction doit acquérir le verrouillage immédiatement ou s’arrêter). Cette valeur spécifie la durée pendant laquelle l’instruction attendra tous les verrous au niveau des lignes qu’elle doit acquérir après chaque tentative d’exécution (1 heure par défaut). Si l’instruction ne peut pas acquérir tous les verrous, elle peut être réessayée et la même période d’attente est appliquée.- Par défaut:
3600(1 heure)
Voir aussi LOCK_TIMEOUT.
ICEBERG_VERSION¶
- Type:
Objet (pour les tables Apache Iceberg™) — Ne peut être défini que pour les tables Apache Iceberg™
- Type de données:
Entier
- Description:
Spécifie la version de la spécification Apache Iceberg™ à laquelle la table est conforme. Si vous utilisez le paramètre ICEBERG_VERSION_DEFAULT pour spécifier la version Iceberg par défaut à un niveau supérieur, ce paramètre remplace le paramètre par défaut. Vous pouvez spécifier une version Iceberg pour les tables Iceberg gérées par Snowflake et les tables Iceberg gérées en externe que vous créez dans une base de données liée à un catalogue.
Prudence
Avant d’utiliser d’autres moteurs pour mettre à niveau une version de format de tables Iceberg dans les propriétés de table vers la v3, assurez-vous que la table n’est pas utilisée par des moteurs ou des applications qui ne prennent pas encore en charge la v3. La rétrogradation des versions de format n’est pas prise en charge dans la spécification Apache Iceberg. Par conséquent, tous les lecteurs et rédacteurs doivent prendre en charge la v3. La version par défaut des tables Iceberg dans Snowflake est la v2, qui peut être configurée en v3 si nécessaire. L’utilisation de Snowflake pour effectuer des mises à niveau de version sur place n’est pas prise en charge pour le moment.
Note
Vous pouvez définir ce paramètre lors de la création d’une table Iceberg à l’aide de la commande CREATEICEBERGTABLE (Snowflake comme catalogue Iceberg) ou CREATE ICEBERG TABLE (catalogue Iceberg REST). Vous ne pouvez pas utiliser la commande ALTER ICEBERG TABLE pour modifier cette configuration pour une table existante.
- Valeurs:
2: La table est conforme à la version 2 d’Iceberg.3: La table est conforme à la version 3 d’Iceberg.- Par défaut:
2
ICEBERG_VERSION_DEFAULT¶
- Type:
Objet (pour bases de données et schémas) — Peut être défini pour Compte » Base de données » Schéma
- Type de données:
Entier
- Description:
Spécifie la version de la spécification Apache Iceberg™ à laquelle se conformer lors de la création de nouvelles tables Iceberg gérées par Snowflake.
Prudence
Avant d’utiliser d’autres moteurs pour mettre à niveau une version de format de tables Iceberg dans les propriétés de table vers la v3, assurez-vous que la table n’est pas utilisée par des moteurs ou des applications qui ne prennent pas encore en charge la v3. La rétrogradation des versions de format n’est pas prise en charge dans la spécification Apache Iceberg. Par conséquent, tous les lecteurs et rédacteurs doivent prendre en charge la v3. La version par défaut des tables Iceberg dans Snowflake est la v2, qui peut être configurée en v3 si nécessaire. L’utilisation de Snowflake pour effectuer des mises à niveau de version sur place n’est pas prise en charge pour le moment.
Note
Pour définir la version d’une table spécifique, définissez le paramètre ICEBERG_VERSION à la place. Voir ICEBERG_VERSION.
- Valeurs:
2: La table est conforme à la version 2 d’Iceberg.3: La table est conforme à la version 3 d’Iceberg.- Par défaut:
2
INITIAL_REPLICATION_SIZE_LIMIT_IN_TB¶
- Type:
Compte — Ne peut être défini que pour le compte
- Type de données:
Nombre.
- Description:
Définit la limite de taille maximale estimée lors de la réplication initiale d’une base de données principale vers une base de données secondaire (dans TB). Définissez ce paramètre sur tout compte qui stocke une base de données secondaire. Cette limite de taille permet d’empêcher les comptes d’engager accidentellement des frais de réplication de base de données importants.
Pour supprimer la taille limite, définissez la valeur sur
0.0.Notez qu’aucune limite de taille par défaut n’est actuellement appliquée aux actualisations suivantes d’une base de données secondaire.
- Valeurs:
0.0et au-dessus avec une échelle d’au moins 1 (par exemple20.5,32.25,33.333, etc.).- Par défaut:
10.0
JDBC_ENABLE_PUT_GET¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Booléen
- Description:
Indique s’il faut autoriser les commandes PUT et GET à accéder aux systèmes de fichiers locaux.
- Valeurs:
TRUE: JDBC active les commandes PUT et GET.FALSE: JDBC désactive les commandes PUT et GET.- Par défaut:
TRUE
JDBC_TREAT_DECIMAL_AS_INT¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Booléen
- Description:
Indique comment JDBC traite les colonnes ayant une échelle de zéro (
0).- Valeurs:
TRUE: JDBC traite une colonne dont l’échelle est nulle comme BIGINT.FALSE: JDBC traite une colonne dont l’échelle est nulle comme DECIMAL.- Par défaut:
TRUE
JDBC_TREAT_TIMESTAMP_NTZ_AS_UTC¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Booléen
- Description:
Spécifie comment JDBC traite les valeurs TIMESTAMP_NTZ.
Par défaut, lorsque le pilote JDBC récupère une valeur de type TIMESTAMP_NTZ à partir de Snowflake, il convertit la valeur en durée chronométrée en utilisant le fuseau horaire JVM du client.
Les utilisateurs qui souhaitent conserver le fuseau horaire UTC pour la conversion peuvent régler ce paramètre sur
TRUE.Ce paramètre s’applique uniquement au pilote JDBC.
- Valeurs:
TRUE: le pilote utilise UTC pour obtenir la valeur de TIMESTAMP_NTZ en durée chronométrée.FALSE: le pilote utilise le fuseau horaire actuel JVM du client pour obtenir la valeur de TIMESTAMP_NTZ en durée chronométrée.- Par défaut:
FALSE
JDBC_USE_SESSION_TIMEZONE¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Booléen
- Description:
Précise si le pilote JDBC utilise le fuseau horaire du JVM ou le fuseau horaire de la session (spécifié par le paramètre TIMEZONE) pour les méthodes
getDate(),getTime()etgetTimestamp()de la classeResultSet.- Valeurs:
TRUE: le pilote JDBC utilise le fuseau horaire de la session.FALSE: le pilote JDBC utilise le fuseau horaire du JVM.- Par défaut:
TRUE
JSON_INDENT¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Entier
- Description:
Indique le nombre d’espaces vides pour indenter chaque nouvel élément dans une sortie JSON de la session. Spécifie également s’il faut insérer des caractères de nouvelle ligne après chaque élément.
- Valeurs:
0jusqu’à16(une valeur de
0retourne une sortie compacte en supprimant tous les espaces vides et les caractères de nouvelle ligne de la sortie)- Par défaut:
2
Note
Ce paramètre ne concerne pas les sorties JSON déchargées d’une table dans un fichier en utilisant la commande COPY INTO <emplacement>. La commande décharge toujours les données JSON au format NDJSON :
Chaque enregistrement de la table est séparé par un caractère de nouvelle ligne.
Dans chaque enregistrement, le formatage est compact (c’est-à-dire qu’il n’y a pas d’espaces ni de caractères de retour à la ligne).
JS_TREAT_INTEGER_AS_BIGINT¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Booléen
- Description:
Indique comment le pilote Snowflake Node.js traite les colonnes numériques ayant une échelle de zéro (
0), par exemple INTEGER ou NUMBER(p, 0).- Valeurs:
TRUE: JavaScript traite une colonne dont l’échelle est nulle comme Bigint.FALSE: JavaScript traite une colonne dont l’échelle est nulle comme Number.- Par défaut:
FALSE
Note
Par défaut, les colonnes INTEGER Snowflake (y compris BIGINT, NUMBER(p, 0), etc.) sont converties en type de données JavaScript Number. Toutefois, les plus grandes valeurs légales entières de Snowflake sont supérieures aux plus grandes valeurs légales JavaScript. Pour convertir les colonnes INTEGER Snowflake au format JavaScript Bigint, qui peut stocker des valeurs supérieures à JavaScript Number, définissez le paramètre de session JS_TREAT_INTEGER_AS_BIGINT.
Pour des exemples d’utilisation de ce paramètre, voir Récupération des types de données entiers en tant que Bigint.
LISTING_AUTO_FULFILLMENT_REPLICATION_REFRESH_SCHEDULE¶
- Type:
Compte — Ne peut être défini que pour le compte
- Type de données:
Chaîne
- Description:
Définit l’intervalle de temps utilisé pour actualiser les produits de données basés sur le paquet d’application dans d’autres régions.
- Valeurs:
num MINUTES:Une valeur comprise entre
1et11520. Doit inclure l’unité MINUTES.USING CRON expr time_zone:Spécifie une expression cron et un fuseau horaire pour l’actualisation. Prend en charge un sous-ensemble de la syntaxe standard de l’utilitaire cron.
Pour une liste de fuseaux horaires, voir la Liste des fuseaux horaires de la base de données tz de la rubrique Wikipédia. L’expression cron comprend les champs suivants :
Les caractères spéciaux suivants sont acceptés :
*Caractère générique. Spécifie toute occurrence du champ.
LSignifie « dernier ». Lorsqu’il est utilisé dans le champ du jour de la semaine, il vous permet de spécifier des constructions telles que « le dernier vendredi » (« 5L ») d’un mois donné. Dans le champ du mois, il spécifie le dernier jour du mois.
/nIndique l’instance nth d’une unité de temps donnée. Chaque quanta de temps est calculé indépendamment. Par exemple, si
4/3est spécifié dans le champ du mois, l’actualisation est planifiée pour avril, juillet et octobre. Par exemple, tous les trois mois, à partir du quatrième mois de l’année. Le même calendrier est maintenu les années suivantes. En d’autres termes, la réactualisation n’est pas prévue en janvier (3 mois après l’exécution d’octobre).
Note
L’expression cron est actuellement évaluée par rapport au fuseau horaire spécifié. La modification de la valeur du paramètre TIMEZONE pour le compte (ou la définition de la valeur au niveau de l’utilisateur ou de la session) ne modifie pas le fuseau horaire de l’actualisation.
L’expression cron définit toutes les heures d’exécution valides de l’actualisation. Snowflake tente d’actualiser les annonces en fonction de cette planification ; toutefois, tout moment d’exécution valide est ignoré si une exécution précédente n’a pas été terminée avant le début du moment d’exécution valide suivant.
Lorsqu’un jour de mois et un jour de semaine spécifiques sont inclus dans l’expression cron, l’actualisation est planifiée les jours satisfaisant le jour du mois ou le jour de la semaine. Par exemple,
SCHEDULE = 'USING CRON 0 0 10-20 * TUE,THU UTC'planifie une actualisation à 0 heure entre le 10e et le 20e jour de n’importe quel mois, ainsi que tous les mardis et jeudis en dehors de ces dates.
- Par défaut:
Aucun(e)
LOCK_TIMEOUT¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Entier
- Description:
Nombre de secondes à attendre avant d’essayer de verrouiller une ressource, avant de faire expirer et d’annuler l’instruction.
- Valeurs:
0à un nombre entier quelconque (sans limite). Une valeur de0désactive le verrouillage d’attente (l’instruction doit acquérir le verrouillage immédiatement ou s’arrêter). Si plusieurs ressources doivent être verrouillées par l’instruction, le délai d’attente s’applique séparément à chaque tentative de verrouillage.- Par défaut:
43200(12 heures)
Voir aussi HYBRID_TABLE_LOCK_TIMEOUT.
LOG_LEVEL¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
Objet (pour les bases de données, les schémas, les projets DCM, les procédures stockées, les UDFs, les tables dynamiques, les tables Iceberg, les tâches, les services) — Peut être défini pour :
Compte » Base de données » Schéma » Projet DCM
Compte » Base de données » Schéma » Procédure
Compte » Base de données » Schéma » Fonction
Compte » Base de données » Schéma » Table dynamique
Compte » Base de données » Schéma » Table Iceberg (gérée en externe)
Compte » Base de données » Schéma » Tâche
Compte » Base de données » Schéma » Service
- Type de données:
Chaîne (constante)
- Description:
Spécifie le niveau de gravité des messages de journal produits par les APIs de journalisation qui doivent être ingérés et mis à disposition dans le tableau des événements actif. Les messages de journal du niveau spécifié (et des niveaux plus sévères) sont ingérés. Pour plus d’informations sur les niveaux de journalisation, consultez Définition des niveaux de journalisation, des métriques et du traçage.
- Valeurs:
TRACEDEBUGINFOWARNERRORFATALOFF
- Par défaut:
OFF- Remarques complémentaires:
Le tableau suivant énumère les niveaux de messages de journal ingérés lorsque vous attribuez un niveau au paramètre
LOG_LEVEL.Réglage des paramètres de LOG_LEVEL
Niveaux de messages du journal ingérés
TRACETRACEDEBUGINFOWARNERRORFATAL
DEBUGDEBUGINFOWARNERRORFATAL
INFOINFOWARNERRORFATAL
WARNWARNERRORFATAL
ERRORERRORFATAL
FATALERROR(Uniquement pour les procédures stockées Scala, les UDFs Java et les UDTFs Java. Pour plus d’informations, voir Définition des niveaux de journalisation, des métriques et du traçage.)FATAL
Si ce paramètre est défini à la fois dans la session et dans l’objet (ou schéma, base de données ou compte), la valeur la plus verbeuse est utilisée. Voir Comment Snowflake détermine le niveau en vigueur.
LOG_EVENT_LEVEL¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
Objet (pour les bases de données, les schémas, les projets DCM, les procédures stockées, les UDFs, les tables dynamiques, les tables Iceberg, les tâches, les services) — Peut être défini pour :
Compte » Base de données » Schéma » Projet DCM
Compte » Base de données » Schéma » Procédure
Compte » Base de données » Schéma » Fonction
Compte » Base de données » Schéma » Table dynamique
Compte » Base de données » Schéma » Table Iceberg (gérée en externe)
Compte » Base de données » Schéma » Tâche
Compte » Base de données » Schéma » Service
- Type de données:
Chaîne (constante)
- Description:
Spécifie le niveau de gravité des événements du journal (lignes avec type d’enregistrement EVENT) qui doivent être ingérés et mis à disposition dans le tableau des événements actifs. Les événements du journal du niveau spécifié (et des niveaux plus sévères) sont ingérés. Pour connaître les valeurs de gravité prises en charge et la manière de combiner les niveaux, voir Définition des niveaux de journalisation, des métriques et du traçage.
- Valeurs:
TRACEDEBUGINFOWARNERRORFATALOFF
- Par défaut:
OFF- Remarques complémentaires:
Le tableau suivant énumère les niveaux des événements de journal ingérés lorsque vous attribuez un niveau au paramètre
LOG_EVENT_LEVEL.Réglage des paramètres de LOG_EVENT_LEVEL
Niveaux d’événements du journal ingérés
TRACETRACEDEBUGINFOWARNERRORFATAL
DEBUGDEBUGINFOWARNERRORFATAL
INFOINFOWARNERRORFATAL
WARNWARNERRORFATAL
ERRORERRORFATAL
FATALERRORFATAL
Si ce paramètre est défini à la fois dans la session et dans l’objet (ou schéma, base de données ou compte), la valeur la plus verbeuse est utilisée. Voir Comment Snowflake détermine le niveau en vigueur.
LOGIN_IDP_REDIRECT (affichage seul)¶
- Type:
Compte
- Type de données:
VARCHAR
- Description:
Paramètre d’affichage seul qui contient un objet JSON récapitulant les valeurs que quelqu’un a définies pour la propriété de compte
LOGIN_IDP_REDIRECT.L’objet JSON contient un mappage entre les interfaces Snowflake et les intégrations de sécurité SAML. SAML Les intégrations de sécurité sont utilisées pour mettre en œuvre l’authentification unique (SSO). Si une interface est mappée à une intégration de sécurité SAML, alors les utilisateurs qui accèdent à l’interface sont redirigés vers le fournisseur d’identité tiers (IdP) pour s’authentifier ; Ils ne voient jamais l’écran de connexion de Snowflake.
For a conceptual overview and configuration examples, see Redirection automatique des utilisateurs vers votre fournisseur d’identité. For the syntax used to set the property, see ALTER ACCOUNT.
MAX_CONCURRENCY_LEVEL¶
- Type:
Objet (pour entrepôts) — Peut être défini pour Compte » Entrepôt virtuel
- Type de données:
Nombre
- Description:
Spécifie le niveau de simultanéité des instructions SQL (requêtes et DML) exécutées par un entrepôt. Lorsque le niveau est atteint, l’opération exécutée varie selon que l’entrepôt virtuel est à un ou plusieurs clusters :
Simple cluster ou multi-clusters (en mode Maximisé) : Les instructions sont mises en file d’attente jusqu’à ce que les ressources déjà allouées soient libérées ou que des ressources supplémentaires soient fournies, ce qui peut être réalisé en augmentant la taille de l’entrepôt.
Multi-cluster (en mode Mise à l’échelle automatique) : Des clusters supplémentaires sont démarrés.
MAX_CONCURRENCY_LEVEL peut être utilisé conjointement avec le paramètre STATEMENT_QUEUED_TIMEOUT_IN_SECONDS pour s’assurer qu’un entrepôt n’est jamais en attente.
En général, cela limite le nombre d’instructions qui peuvent être exécutées simultanément par un cluster d’entrepôts, mais il y a des exceptions. Dans les cas suivants, le nombre réel d’instructions exécutées simultanément par un entrepôt peut être supérieur ou inférieur au niveau spécifié :
Instructions plus petites et plus basiques : D’autres instructions peuvent s’exécuter simultanément parce que des petites instructions s’exécutent généralement sur un sous-ensemble de ressources de calcul disponibles dans un entrepôt. Cela signifie qu’elles ne comptent que pour une fraction du niveau de concurrence.
Instructions plus grandes et plus complexes : Moins d’instructions peuvent être exécutées simultanément.
- Par défaut:
8
Astuce
Cette valeur est par défaut uniquement et peut être modifiée à tout moment :
L’abaissement du niveau de concurrence pour un entrepôt permet de limiter le nombre de requêtes simultanées exécutées dans un entrepôt. Lorsque moins de requêtes sont en concurrence pour les ressources de l’entrepôt à un moment donné, une requête peut potentiellement se voir attribuer plus de ressources, ce qui peut se traduire par des performances plus rapides, en particulier pour une requête volumineuse/complexe et à plusieurs instructions.
L’augmentation du niveau de simultanéité pour un entrepôt peut réduire les ressources de calcul qui sont disponibles par instruction ; toutefois, cela ne limite pas nécessairement le nombre total de requêtes simultanées pouvant être exécutées par l’entrepôt, pas plus qu’elle n’impacte nécessairement la performance totale de l’entrepôt, qui dépend de la nature des requêtes en cours d’exécution.
Notez que, comme décrit précédemment, ce paramètre impacte les entrepôts multi-clusters (en mode Mise à l’échelle automatique), car Snowflake lance automatiquement un nouveau cluster dans l’entrepôt multi-clusters pour éviter les files d’attente. Ainsi, abaisser le niveau de simultanéité pour un entrepôt multi-clusters (en mode Mise à l’échelle automatique) augmente potentiellement le nombre de clusters actifs à tout moment.
De plus, n’oubliez pas que Snowflake distribue automatiquement des ressources pour chaque instruction lorsqu’elle est soumise et que le montant alloué est dicté par les exigences individuelles de l’instruction. Sur cette base, et grâce à nos observations des modèles de requêtes des utilisateurs au fil du temps, nous avons sélectionné une valeur par défaut qui équilibre la performance et l’utilisation des ressources.
Ainsi, avant de changer la valeur par défaut, nous vous recommandons de tester le changement en ajustant le paramètre par petits incréments et en observant l’impact sur un ensemble représentatif de vos requêtes.
MAX_DATA_EXTENSION_TIME_IN_DAYS¶
- Type:
Objet (pour bases de données, schémas et tables) — Peut être défini pour Compte » Base de données » Schéma » Table
- Type de données:
Entier
- Description:
Nombre maximum de jours pendant lesquels Snowflake peut prolonger la période de conservation des données des tables pour éviter que les flux sur les tables ne deviennent obsolètes. Par défaut, si le paramètre DATA_RETENTION_TIME_IN_DAYS d’une table source est inférieur à 14 jours, et qu’un flux n’a pas été consommé, Snowflake prolonge temporairement cette période jusqu’au décalage du flux, jusqu’à un maximum de 14 jours, quelle que soit l”édition de Snowflake pour votre compte. Le paramètre MAX_DATA_EXTENSION_TIME_IN_DAYS vous permet de limiter cette période de prolongation automatique afin de contrôler les coûts de stockage pour la conservation des données ou pour des raisons de conformité.
Le paramètre peut être défini au niveau du compte, de la base de données, du schéma ou de la table. Notez que la définition du paramètre au niveau du compte ou du schéma n’affecte que les tables pour lesquelles le paramètre n’a pas encore été explicitement défini à un niveau inférieur (par exemple, au niveau de table par le propriétaire de la table). Une valeur de 0 désactive efficacement l’extension automatique pour la base de données, le schéma ou la table spécifiés. Pour plus d’informations sur les flux et l’obsolescence, voir Introduction to streams.
- Valeurs:
0à90(90 jours) — une valeur de0désactive l’extension automatique de la période de conservation des données. Pour augmenter la valeur maximale des tables pour votre compte, contactez l’assistance Snowflake.- Par défaut:
14
Note
Ce paramètre peut entraîner une conservation des données plus longue que la conservation par défaut. Avant de l’augmenter, vérifiez que la nouvelle valeur correspond à vos exigences de conformité.
La conservation des tables n’est pas étendue aux flux sur les tables partagées. Si vous partagez une table, assurez-vous de définir la durée de conservation de la table suffisamment longue pour que votre consommateur de données puisse consommer le flux. Si un fournisseur partage une table avec, par exemple, une conservation de 7 jours et conserve l’extension par défaut de 14 jours, le flux sera obsolète après 14 jours dans le compte fournisseur et après 7 jours dans le compte consommateur.
METRIC_LEVEL¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
Objet (pour les bases de données, les schémas, les procédures stockées et les UDFs) — Peut être défini pour le compte » Base de données » Schéma » Procédure et compte » Base de données » Schéma » Fonction
- Type de données:
Chaîne (constante)
- Description:
Contrôle la manière dont les données de métriques sont ingérées dans la table des événements. Pour plus d’informations sur les niveaux des métriques, voir Définition des niveaux de journalisation, des métriques et du traçage.
- Valeurs:
ALL: toutes les données de métriques seront enregistrées dans la table des événements.NONE: aucune donnée de métriques ne sera enregistrée dans la table des événements.- Par défaut:
NONE
MULTI_STATEMENT_COUNT¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Entier (constant)
- Clients:
SQL API, JDBC, .NET, ODBC
- Description:
Nombre d’instructions à exécuter lors de l’utilisation de la fonctionnalité multi-instructions.
- Valeurs:
0: nombre variable d’instructions.1: une instruction.Plus que
1: lorsque MULTI_STATEMENT_COUNT est défini comme paramètre de session, vous pouvez spécifier le nombre exact d’instructions à exécuter.Les nombres négatifs ne sont pas autorisés.
- Par défaut:
1
MIN_DATA_RETENTION_TIME_IN_DAYS¶
- Type:
Compte — Ne peut être défini que pour le compte
- Type de données:
Entier
- Description:
Nombre de jours pendant lesquels Snowflake conserve les données historiques pour effectuer des actions de Time Travel (SELECT, CLONE, UNDROP) sur un objet. Si un nombre minimum de jours pour la conservation des données est défini sur un compte, la période de conservation des données pour un objet est déterminée par MAX(DATA_RETENTION_TIME_IN_DAYS, MIN_DATA_RETENTION_TIME_IN_DAYS).
Pour plus d’informations, voir Compréhension et utilisation de la fonction Time Travel.
- Valeurs:
0ou1(pour l’édition Standard)0à90(pour l’édition Enterprise ou ultérieure)- Par défaut:
0
Note
Ce paramètre s’applique uniquement aux tables permanentes et ne s’applique pas aux objets suivants :
Tables transitoires
Tables temporaires
Tables externes
Vues matérialisées
Flux
Ce paramètre ne peut être défini que par les administrateurs de comptes (c’est-à-dire les utilisateurs ayant le rôle ACCOUNTADMIN ou un autre rôle auquel est attribué le rôle ACCOUNTADMIN).
La définition de la période minimale de conservation des données ne modifie aucune valeur du paramètre DATA_RETENTION_TIME_IN_DAYS existante définie sur les bases de données, les schémas ou les tables. Le durée de conservation effective sur une base de données, un schéma ou une table est MAX(DATA_RETENTION_TIME_IN_DAYS, MIN_DATA_RETENTION_TIME_IN_DAYS).
NETWORK_POLICY¶
- Type:
Compte — Ne peut être défini que pour le compte (peut être défini par les administrateurs de compte et les administrateurs de sécurité)
- Type:
Objet (pour les utilisateurs) — Peut être défini pour Compte » Utilisateur
- Type de données:
Chaîne
- Description:
Spécifie la stratégie réseau à appliquer pour votre compte. Les stratégies réseau permettent de restreindre l’accès à votre compte en fonction de l’adresse IP des utilisateurs. Pour plus de détails, voir Contrôle du trafic réseau avec des politiques réseau.
- Valeurs:
Toute stratégie réseau existante (créée à l’aide de CREATE NETWORK POLICY)
- Par défaut:
Aucun(e)
Note
C’est le seul paramètre de compte qui peut être défini par les administrateurs de sécurité (c’est-à-dire les utilisateurs ayant le rôle SECURITYADMIN) ou les administrateurs ayant un rôle supérieur.
NOORDER_SEQUENCE_AS_DEFAULT¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Booléen
- Description:
Spécifie si la propriété ORDER ou NOORDER est définie par défaut lorsque vous créez une nouvelle séquence ou ajoutez une nouvelle colonne de table.
Les propriétés ORDER et NOORDER déterminent si les valeurs sont générées pour la séquence ou la colonne auto-incrémentée dans l’ordre croissant ou décroissant.
- Valeurs:
TRUE: lorsque vous créez une nouvelle séquence ou que vous ajoutez une nouvelle colonne de table, la propriété NOORDER est définie par défaut.NOORDER précise que l’ordre croissant des valeurs n’est pas garanti.
Par exemple, si une séquence comporte
START 1 INCREMENT 2, les valeurs générées peuvent être1,3,101,5,103, etc.NOORDER peut améliorer les performances lorsque plusieurs opérations INSERT doivent être effectuées simultanément (par exemple, lorsque plusieurs clients exécutent plusieurs instructions INSERT).
FALSE: lorsque vous créez une nouvelle séquence ou que vous ajoutez une nouvelle colonne de table, la propriété ORDER est définie par défaut.ORDER spécifie que les valeurs générées pour une séquence ou une colonne auto-incrémentée sont dans l’ordre croissant sont en ordre croissant (ou, si l’intervalle est une valeur négative, en ordre décroissant).
Par exemple, si une séquence ou une colonne auto-incrémentée comporte
START 1 INCREMENT 2, les valeurs générées peuvent être1,3,5,7,9, etc.
Si vous définissez ce paramètre, la valeur que vous définissez remplace la valeur du bundle de changements de comportement 2024_01.
- Par défaut:
TRUE
ODBC_TREAT_DECIMAL_AS_INT¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Booléen
- Description:
Indique comment ODBC traite les colonnes ayant une échelle de zéro (
0).- Valeurs:
TRUE: ODBC traite une colonne dont l’échelle est nulle comme BIGINT.FALSE: ODBC traite une colonne dont l’échelle est nulle comme DECIMAL.- Par défaut:
FALSE
OAUTH_ADD_PRIVILEGED_ROLES_TO_BLOCKED_LIST¶
- Type:
Compte — Ne peut être défini que pour le compte
- Type de données:
Booléen
- Description:
Détermine si les rôles ACCOUNTADMIN, ORGADMIN, GLOBALORGADMIN et SECURITYADMIN peuvent être utilisés comme rôle principal lors de la création d’une session Snowflake basée sur le jeton d’accès du serveur d’autorisation de Snowflake.
- Valeurs:
TRUE: ajoute les rôles ACCOUNTADMIN, ORGADMIN, GLOBALORGADMIN et SECURITYADMIN à la propriétéBLOCKED_ROLES_LISTde l’intégration de sécurité Snowflake OAuth, ce qui signifie que ces rôles ne peuvent pas être utilisés comme rôle principal lors de la création d’une session Snowflake avec Snowflake OAuth.FALSE: retire les rôles ACCOUNTADMIN, ORGADMIN, GLOBALORGADMIN et SECURITYADMIN de la liste des rôles bloqués définis par la propriétéBLOCKED_ROLES_LISTde l’intégration de sécurité Snowflake OAuth.- Par défaut:
TRUE
OPT_OUT_ERROR_LOGGING¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Booléen
- Description:
Indique si la journalisation des erreurs DML est autorisée.
- Valeurs:
TRUE: la journalisation des erreurs DML n’est pas activée, qu’elle soit activée ou non pour des tables spécifiques.FALSE: la journalisation des erreurs DML se comporte normalement :La journalisation des erreurs DML est activée pour les tables qui ont le paramètre ERROR_LOGGING au niveau de la table défini sur
TRUE.La journalisation des erreurs DML est désactivée pour les tables qui ont le paramètre ERROR_LOGGING au niveau de la table défini sur
FALSE.
- Par défaut:
FALSE
Pour plus d’informations, voir Journalisation des erreurs DML.
PERIODIC_DATA_REKEYING¶
- Type:
Compte — Ne peut être défini que pour le compte
- Type de données:
Booléen
- Description:
Ce paramètre ne s’applique qu’à l’édition Enterprise (ou supérieure). Il active/désactive le rechiffrement des données de tables avec de nouvelles clés sur une base annuelle pour fournir des niveaux supplémentaires de protection des données.
Vous pouvez activer et désactiver la saisie à tout moment. L’activation/désactivation de la re-saisie n’entraîne pas d’écarts dans vos données chiffrées :
Si la re-saisie est activée pendant un certain temps puis désactivée, toutes les données déjà étiquetées pour la nouvelle saisie sont re-saisies, mais aucune autre donnée n’est re-saisie jusqu’à ce que vous renouveliez l’opération.
Si la re-saisie est activée, Snowflake re-saisit automatiquement toutes les données dont les clés répondent aux critères (c’est-à-dire les clés datant de plus d’un an).
Pour plus d’informations sur la nouvelle saisie des données chiffrées, voir Comprendre la gestion des clés de chiffrement dans Snowflake.
- Valeurs:
TRUE: les données sont resaisies après un an à compter de la date du dernier chiffrement des données. La resaisie se fait en arrière-plan, de sorte qu’aucun temps d’arrêt ne soit observé et que les données/tables concernées soient toujours disponibles.FALSE: les données ne sont pas resaisies.- Par défaut:
FALSE
Note
Il existe des frais associés à la ressaisie des données parce que, après la ressaisie des données, les anciennes données (avec l’ancien chiffrement par clé) sont conservées dans Fail-safe pendant la période de temps standard (7 jours). Pour cette raison, la resaisie périodique est désactivée par défaut. Pour activer la resaisie périodique, vous devez l’activer explicitement.
De plus, les frais associés à Fail-safe pour la resaisie ne sont pas indiqués individuellement sur votre relevé mensuel ; ils sont inclus dans le total Fail-safe de votre compte chaque mois.
Pour plus d’informations sur Fail-safe, voir Compréhension et affichage de Fail-safe.
PIPE_EXECUTION_PAUSED¶
- Type:
Objet — Peut être défini pour Compte » Schéma » Canal
- Type de données:
Booléen
- Description:
Indique s’il faut interrompre ou non le fonctionnement d’un canal, principalement en vue du transfert de propriété du canal vers un autre rôle :
Un administrateur de compte (utilisateur avec le rôle ACCOUNTADMIN) peut définir ce paramètre au niveau du compte, mettant en pause ou reprenant effectivement tous les canaux du compte.
De même, un utilisateur avec le privilège MODIFY sur le schéma peut interrompre ou reprendre tous les canaux au niveau du schéma.
Le propriétaire du canal peut définir ce paramètre pour un canal.
Notez que la définition du paramètre au niveau du compte ou du schéma n’affecte que les canaux pour lesquels le paramètre n’a pas encore été explicitement défini à un niveau inférieur (par exemple, au niveau du canal par le propriétaire du canal).
Ceci permet le cas d’utilisation pratique dans lequel un administrateur de compte peut mettre en pause tous les canaux au niveau du compte, alors qu’un propriétaire de canal peut toujours avoir un canal individuel en cours de fonctionnement.
- Valeurs:
TRUE: interrompt le canal. Lorsque le paramètre est réglé sur cette valeur, la fonction SYSTEM$PIPE_STATUS afficheexecutionStateen tant quePAUSED. Notez que le propriétaire du canal peut continuer à soumettre des fichiers dans un canal mis en pause ; cependant, les fichiers ne sont pas traités avant la reprise du canal.FALSE: reprend le canal, mais seulement si la propriété du canal n’a pas été transférée alors qu’il était en pause. Lorsque le paramètre est réglé sur cette valeur, la fonction SYSTEM$PIPE_STATUS afficheexecutionStateen tant queRUNNING.Si la propriété du canal a été transférée à un autre rôle après la pause du canal, ce paramètre ne peut pas être utilisé pour reprendre le canal. Au lieu de cela, utilisez la fonction SYSTEM$PIPE_FORCE_RESUME pour explicitement forcer la reprise du canal.
Cela permet au nouveau propriétaire d’utiliser SYSTEM$PIPE_STATUS pour évaluer le statut du canal (par exemple, déterminer combien de fichiers sont en attente de chargement) avant de reprendre le canal.
- Par défaut:
FALSE(les canaux fonctionnent par défaut)
Note
En général, il n’est pas nécessaire de mettre les canaux en pause, sauf pour transférer la propriété.
PATH_LAYOUT¶
- Type:
Objet (pour les tables Apache Iceberg™) — Peut être défini pour une table Iceberg
- Type de données:
Chaîne (constante)
- Description:
Spécifie la structure de chemin d’accès que Snowflake utilise lors de l’écriture de fichiers de données Parquet dans les tables Iceberg. Vous pouvez spécifier ce paramètre lorsque vous créez une table, mais vous ne pouvez pas spécifier ce paramètre lorsque vous modifiez une table.
Note
Pour les tables gérées en externe que vous créez dans une base de données Snowflake standard, Snowflake déduit et respecte le schéma de partitionnement spécifié par la table distante.
- Valeurs:
FLAT: Snowflake écrit tous les fichiers de données Parquet dans le répertoiredata/de la table.HIERARCHICAL: Snowflake écrit des données partitionnées sous le répertoiredata/pour la table en utilisant une structure de chemin d’accès hiérarchique. Avec cette structure, chaque colonne de partition est représentée par un niveau de répertoire dans le chemin d’accès. Pour définir ces colonnes de partition, utilisez le paramètre PARTITION BY. Cette structure est également appelée partitionnement de « style Hive ».Si vous spécifiez la structure hiérarchique, mais que vous ne spécifiez pas de clause PARTITION BY avec la commande, Snowflake stocke les fichiers de données Parquet en utilisant un chemin d’accès de structure plate. Vous ne pouvez pas utiliser la commande ALTER ICEBERG TABLE pour activer ultérieurement une structure de chemin d’accès hiérarchique pour la table. Vous pouvez définir ce paramètre sur HIERARCHICAL sans spécifier de clause PARTITION BY si vous ne souhaitez pas utiliser le partitionnement avec des chemins d’accès hiérarchiques pour le moment, mais que vous pourriez le faire à l’avenir.
- Par défaut:
FLAT
Pour plus d’informations, voir Répertoires de données et de métadonnées.
PREVENT_UNLOAD_TO_INLINE_URL¶
- Type:
Objet (pour les utilisateurs) — Peut être défini pour Compte » Utilisateur
- Type de données:
Booléen
- Description:
Spécifie s’il faut empêcher les opérations de déchargement de données ad hoc vers des emplacements de stockage Cloud externes (c’est-à-dire des instructions COPY INTO <emplacement> qui spécifient l’URL de stockage Cloud et les paramètres d’accès directement dans l’instruction). Pour un exemple, voir Déchargement des données d’une table directement dans des fichiers d’un emplacement externe.
- Valeurs:
TRUE: les instructions COPY INTO <location> doivent référencer soit une zone de préparation interne (Snowflake) ou externe nommée soit une zone de préparation interne utilisateur ou table. Une zone de préparation externe nommée doit stocker l’URL de stockage Cloud et les paramètres d’accès dans sa définition.FALSE: les opérations de déchargement de données ad hoc vers des emplacements de stockage Cloud externes sont autorisées.- Par défaut:
FALSE
PREVENT_UNLOAD_TO_INTERNAL_STAGES¶
- Type:
Utilisateur — Peut être défini pour Compte » Utilisateur
- Type de données:
Booléen
- Description:
Indique s’il faut empêcher les opérations de déchargement de données vers des zones de préparation internes (Snowflake) à l’aide d’instructions COPY INTO <emplacement>.
- Valeurs:
TRUE: le déchargement des données des tables Snowflake vers une zone de préparation interne, y compris les zones de préparation utilisateur, les zones de préparation de table ou les zones de préparation internes nommées est évité.FALSE: le déchargement des données vers des zones de préparation internes est autorisé, mais se limite uniquement par les restrictions par défaut du type de zone de préparation :L’utilisateur actuel ne peut décharger des données que sur sa propre zone de préparation utilisateur.
Les utilisateurs ne peuvent décharger des données sur des zones de préparation de table que lorsque leur rôle actif dispose du privilège OWNERSHIP sur la table.
Les utilisateurs ne peuvent décharger des données sur des zones de préparation internes nommées que si leur rôle actif dispose du privilège WRITE sur la zone de préparation.
- Par défaut:
FALSE
PYTHON_PROFILER_TARGET_STAGE¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Chaîne
- Description:
Spécifie le nom complet de la zone de préparation dans laquelle enregistrer un rapport lors du profilage du code du gestionnaire Python.
- Valeurs:
Nom complet de la zone de préparation dans laquelle enregistrer le rapport.
Utilisez une zone de préparation temporaire pour stocker les sorties uniquement pour la durée de la session.
Utilisez une zone de préparation permanente pour conserver la sortie du profilage en dehors du champ d’application d’une session.
Pour plus d’informations, voir Spécifiez la zone de préparation de Snowflake dans laquelle la sortie du profil doit être écrite.
- Par défaut:
''
PYTHON_PROFILER_MODULES¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Chaîne
- Description:
Spécifie la liste des modules Python à inclure dans un rapport lors du profilage du code de gestionnaire Python.
Utilisez ce paramètre pour spécifier les modules contenus dans les gestionnaires en zone de préparation ou qui contiennent des dépendances que vous souhaitez inclure dans le profil.
- Valeurs:
Liste de noms de modules Python séparés par des virgules.
Pour des exemples, voir Inclure des modules avec le paramètre PYTHON_PROFILER_MODULES et Profiler le code du gestionnaire en zone de préparation.
- Par défaut:
''
QUERY_TAG¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Chaîne (jusqu’à 2 000 caractères)
- Description:
Chaîne optionnelle qui peut être utilisée pour baliser les requêtes et autres instructions SQL exécutées dans une session. Les balises sont affichées dans la sortie des fonctions QUERY_HISTORY , QUERY_HISTORY_BY_*.
- Par défaut:
Aucun(e)
QUOTED_IDENTIFIERS_IGNORE_CASE¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
Objet — Peut être défini pour Compte » Base de données » Schéma » Table
- Type de données:
Booléen
- Description:
Spécifie si les lettres dans les identificateurs d’objet à double guillemet sont stockées et résolues comme des lettres majuscules. Par défaut, Snowflake préserve la casse des caractères alphabétiques lors du stockage et de la résolution des identificateurs entre guillemets doubles (voir Résolution de l’identificateur). Vous pouvez utiliser ce paramètre dans les situations où les applications tierces utilisent toujours des guillemets autour des identificateurs.
Note
Si vous modifiez ce paramètre par rapport à la valeur par défaut, vous risquez de ne pas pouvoir retrouver les objets qui ont été créés auparavant avec des identificateurs entre guillemets doubles et à casse mixte. Reportez-vous à Incidence de la modification du paramètre.
Lorsqu’il est défini sur une table, un schéma ou une base de données, ce paramètre affecte uniquement l’évaluation des noms de table dans les corps des vues et des fonctions définies par l’utilisateur (UDFs). Si votre compte utilise des identificateurs à double guillemet qui doivent être traités comme insensibles à la casse et que vous prévoyez de partager une vue ou une UDF avec un compte qui traite les identificateurs à guillemet double comme sensibles à la casse, vous pouvez définir cette option sur la vue ou l’UDF que vous prévoyez de partager. Cela permet à l’autre compte de résoudre correctement les noms de table dans la vue ou l’UDF.
- Valeurs:
TRUE: les lettres des identificateurs entre guillemets doubles sont stockées et résolues comme des lettres majuscules.FALSE: la casse des lettres dans les identificateurs entre guillemets est préservée. Snowflake résout et stocke les identificateurs dans la casse spécifiée.Pour plus d’informations, consultez Résolution de l’identificateur.
- Par défaut:
FALSE
Par exemple :
Identificateur |
Paramètre réglé sur |
Paramètre réglé sur |
|
|---|---|---|---|
|
se résout vers : |
|
|
|
se résout vers : |
|
|
|
se résout vers : |
|
|
|
se résout vers : |
|
|
READ_CONSISTENCY_MODE¶
- Type:
Compte — Ne peut être défini que pour le compte
- Type de données:
Chaîne
- Description:
Définit le niveau des garanties de cohérence requises pour les sessions avec des modifications quasi simultanées.
- Valeurs:
SESSION: Les modifications sont immédiatement visibles par les requêtes suivantes au sein de la même session, mais pas toujours immédiatement entre les sessions.GLOBAL: Les modifications sont immédiatement visibles par les requêtes suivantes au sein des sessions en cours d’exécution simultanée, mais avec un faible impact sur les temps de réponse aux requêtes (généralement en millisecondes).- Par défaut:
SESSION
Pour plus d’informations, voir Cohérence de lecture entre les sessions.
REPLACE_INVALID_CHARACTERS¶
- Type:
Objet — Peut être défini pour Compte » Base de données » Schéma » Table Iceberg
- Type de données:
Booléen
- Description:
Spécifie s’il faut remplacer les caractères UTF-8 non valides par le caractère de remplacement Unicode (�) dans les résultats de requête des tables Iceberg qui utilisent un catalogue externe.
- Valeurs:
TRUE: Snowflake remplace les caractères UTF-8 non valides par le caractère de remplacement Unicode.FALSE: Snowflake laisse les caractères UTF-8 non valides inchangés. Snowflake renvoie un message d’erreur utilisateur s’il rencontre un caractère UTF-8 non valide.- Par défaut:
FALSE
REQUIRE_STORAGE_INTEGRATION_FOR_STAGE_CREATION¶
- Type:
Compte — Ne peut être défini que pour le compte
- Type de données:
Booléen
- Description:
Spécifie s’il faut exiger un objet d’intégration de stockage comme informations d’identification Cloud lors de la création d’une zone de préparation externe nommée (à l’aide de CREATE STAGE) pour accéder à un emplacement de stockage dans un Cloud privé.
- Valeurs:
TRUE: la création d’une zone de préparation externe pour accéder à un emplacement de stockage dans le Cloud privé nécessite de référencer un objet d’intégration de stockage en tant qu’identifiants de Cloud.FALSE: la création d’une zone de préparation externe ne nécessite pas de référencer un objet d’intégration de stockage. Les utilisateurs peuvent à la place référencer des informations d’identification de fournisseur de Cloud explicites, telles que des clés secrètes ou des jetons d’accès, s’ils ont été configurés pour l’emplacement de stockage.- Par défaut:
FALSE
REQUIRE_STORAGE_INTEGRATION_FOR_STAGE_OPERATION¶
- Type:
Compte — Ne peut être défini que pour le compte
- Type de données:
Booléen
- Description:
Spécifie s’il faut utiliser une zone de préparation externe nommée faisant référence à un objet d’intégration de stockage en tant qu’informations d’identification Cloud lors du chargement ou du déchargement de données vers un emplacement de stockage Cloud privé.
- Valeurs:
TRUE: le chargement ou le déchargement de données vers un emplacement de stockage dans le Cloud privé nécessite l’utilisation d’une zone de préparation externe nommée qui référence un objet d’intégration de stockage ; la spécification d’une zone de préparation externe nommée faisant référence à des informations d’identification de fournisseur de Cloud explicites, telles que des clés secrètes ou des jetons d’accès, génère une erreur utilisateur.FALSE: les utilisateurs peuvent charger ou décharger des données vers un emplacement de stockage Cloud privé à l’aide d’une zone de préparation externe nommée qui fait référence aux informations d’identification du fournisseur de Cloud explicites.Si PREVENT_UNLOAD_TO_INLINE_URL est FALSE, les utilisateurs peuvent spécifier les informations d’identification du fournisseur de Cloud explicites directement dans l’instruction COPY.
- Par défaut:
FALSE
ROWS_PER_RESULTSET¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Nombre
- Clients:
SQL API
- Description:
Indique le nombre maximum de lignes retournées dans un jeu de résultats.
- Valeurs:
0à n’importe quel nombre (aucune limite) — une valeur de0ne spécifie pas de maximum.- Par défaut:
0
S3_STAGE_VPCE_DNS_NAME¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Chaîne
- Description:
Spécifie le nom DNS d’un point de terminaison d’interface Amazon S3. Les demandes envoyées à la zone de préparation interne d’un compte via AWS PrivateLink pour Amazon S3 utilisent ce point de terminaison pour se connecter.
Pour plus d’informations, consultez Accès à des zones de préparation internes avec des points de terminaison d’interface dédiés.
- Valeurs:
Nom DNS valide à l’échelle de la région d’un point de terminaison d’interface S3.
Le format standard commence par un astérisque (
*) et se termine parvpce.amazonaws.com(par exemple*.vpce-sd98fs0d9f8g.s3.us-west-2.vpce.amazonaws.com). Pour plus de détails sur l’obtention de cette valeur, consultez Configuration d’AWS.Les formats alternatifs incluent
bucket.vpce-xxxxxxxx.s3.<région>.vpce.amazonaws.cometvpce-xxxxxxxx.s3.<région>.vpce.amazonaws.com.- Par défaut:
Chaîne vide
SAML_IDENTITY_PROVIDER¶
- Type:
Compte — Ne peut être défini que pour le compte
- Type de données:
JSON
- Description:
Active l’authentification fédérée. Ce paramètre obsolète permet l’authentification fédérée. Ce paramètre accepte un objet JSON, entre guillemets simples, avec les champs suivants :
Où :
certificateSpécifie le certificat (généré par l’IdP) qui vérifie la communication entre l’IdP et Snowflake.
issuerIndique l’émetteur/EntityID de l’IdP.
En option.
Pour savoir comment obtenir cette valeur dans Okta et AD FS, consultez Migration d’une intégration de sécurité SAML2.
ssoUrlSpécifie le point de terminaison de l’URL (fourni par l’IdP) où Snowflake envoie les requêtes SAML.
typeSpécifie le type d’IdP utilisé pour l’authentification fédérée (
"OKTA","ADFS","Custom").labelSpécifie le texte du bouton de l’IdP sur la page de connexion de Snowflake. L’étiquette par défaut est
Single Sign On. Si vous modifiez l’étiquette par défaut, l’étiquette que vous spécifiez ne peut contenir que des caractères alphanumériques (les caractères spéciaux et les espaces vides ne sont pas pris en charge actuellement).Attention, si le champ
"type"est"Okta", il n’est pas nécessaire de spécifier une valeur pour le champlabel, car Snowflake affiche le logo Okta dans le bouton.
Pour plus d’informations, y compris des exemples de paramétrage, voir Migration d’une intégration de sécurité SAML2.
- Par défaut:
Aucun(e)
SEARCH_PATH¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Chaîne
- Description:
Spécifie le chemin à rechercher pour résoudre les noms d’objets non qualifiés dans les requêtes. Pour plus d’informations, consultez Résolution des noms dans les requêtes.
- Valeurs:
Liste de sujets séparés par des identificateurs. Un identificateur peut être un nom de schéma entièrement ou partiellement qualifié.
- Par défaut:
$current, $publicPour plus d’informations sur les paramètres par défaut, reportez-vous à chemin de recherche par défaut.
Note
Vous ne pouvez pas définir ce paramètre dans une chaîne de connexion client telle qu’une chaîne de connexion JDBC ou ODBC. Vous devez établir une session avant de définir un chemin de recherche.
Ce paramètre n’est pas pris en charge pour les tâches.
SERVERLESS_TASK_MAX_STATEMENT_SIZE¶
- Type:
Objet — Peut être défini pour Compte » Base de données » Schéma » Tâche
- Type de données:
Chaîne
- Description:
Spécifie la taille maximale autorisée de l’entrepôt pour Tâches sans serveur.
- Valeurs:
Toute taille d’entrepôt traditionnelle <label-warehouse_size> :
XSMALL,SMALL,MEDIUM,LARGE,XLARGE,X2LARGE. La taille maximale est deX2LARGE.Prend également en charge la syntaxe :
XXLARGE.- Par défaut:
X2LARGE
SERVERLESS_TASK_MIN_STATEMENT_SIZE¶
- Type:
Objet — Peut être défini pour Compte » Base de données » Schéma » Tâche
- Type de données:
Chaîne
- Description:
Spécifie la taille minimale autorisée de l’entrepôt pour Tâches sans serveur.
- Valeurs:
Toute taille d’entrepôt traditionnelle <label-warehouse_size> :
XSMALL,SMALL,MEDIUM,LARGE,XLARGE,X2LARGE. La taille maximale est deX2LARGE.Prend également en charge la syntaxe :
XXLARGE.- Par défaut:
XSMALL
SIMULATED_DATA_SHARING_CONSUMER¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Chaîne
- Description:
Spécifie le nom d’un compte consommateur à simuler pour tester/valider les données partagées, en particulier les vues sécurisées partagées. Lorsque ce paramètre est défini dans une session, les vues partagées retournent des lignes comme si elles étaient exécutées dans le compte consommateur spécifié plutôt que dans le compte fournisseur.
Note
Les simulations ne réussissent que lorsque le rôle actuel est le propriétaire de la vue. Si le rôle actuel ne possède pas la vue, les simulations échouent avec l’erreur suivante :
Pour plus d’informations, voir À propos de Secure Data Sharing et Créer et configurer des partages.
- Par défaut:
Aucun(e)
Important
Il s’agit d’un paramètre de session, ce qui signifie qu’il peut être défini au niveau du compte ; cependant, il ne s’applique qu’aux requêtes de test sur les vues partagées. Étant donné que le paramètre affecte toutes les requêtes d’une session, il ne doit jamais être défini au niveau du compte.
SQL_TRACE_QUERY_TEXT¶
- Type:
Compte — Ne peut être défini que pour le compte
- Type de données:
Chaîne (constante)
- Description:
Spécifie s’il faut capturer le fichier texteSQL d’une instruction SQL tracée.
- Valeurs:
ON: Les traces qui suivent une instruction SQL captureront le texte SQL et l’enregistreront dans le tableau des événements.OFF: les traces ne capturent pas le texte SQL dans le tableau des événements.Pour plus d’informations, voir Définition des niveaux de journalisation, des métriques et du traçage et Traçage des instructions SQL.
- Par défaut:
OFF
SSO_LOGIN_PAGE¶
- Type:
Compte — Ne peut être défini que pour le compte
- Type de données:
Booléen
- Description:
Ce paramètre obsolète désactive le mode de prévisualisation pour tester SSO (après avoir activé l’authentification fédérée) avant de le déployer aux utilisateurs :
- Valeurs:
TRUE: le mode de prévisualisation est désactivé et les utilisateurs verront le bouton pour SSO initié par Snowflake pour votre fournisseur d’identité (tel que spécifié dans SAML_IDENTITY_PROVIDER) sur la page de connexion principale de Snowflake.FALSE: le mode de prévisualisation est activé et SSO peut être testé à l’aide de l’URL suivante :Si votre compte est basé dans l’ouest US :
https://<account_identifier>.snowflakecomputing.com/console/login?fedpreview=trueSi votre compte est situé dans une autre région :
https://<account_identifier>.<region_id>.snowflakecomputing.com/console/login?fedpreview=true
Pour plus d’informations, voir :
- Par défaut:
FALSE
STATEMENT_QUEUED_TIMEOUT_IN_SECONDS¶
- Type:
Session et objet (pour les entrepôts)
Peut être défini pour Compte » Utilisateur » Session ; peut également être défini pour des entrepôts individuels
- Type de données:
Nombre
- Description:
Durée, en secondes, pendant laquelle une instruction SQL (requête, DDL, DML, etc.) reste en file d’attente pour un entrepôt avant d’être annulée par le système. Ce paramètre peut être utilisé conjointement avec le paramètre MAX_CONCURRENCY_LEVEL pour s’assurer qu’un entrepôt n’est jamais en attente.
Le paramètre peut être défini à différents niveaux dans la hiérarchie de la session (sur le compte, l’utilisateur et la session). Si le paramètre est défini à plus d’un niveau, les règles décrites dans Paramètres de session déterminent quelle valeur qui est utilisée.
Il peut également être défini pour un entrepôt individuel afin de contrôler la durée d’exécution de toutes les instructions SQL traitées par l’entrepôt. Lorsque le paramètre est défini à la fois dans la hiérarchie des sessions et dans l’entrepôt, le délai d’attente est la valeur non nulle la plus basse des deux paramètres.
Par exemple, supposons que le paramètre est défini sur les valeurs suivantes à différents niveaux :
Utilisateur - 10
Session - 20
Entrepôt - 15
Dans ce cas, la valeur du paramètre défini sur l’entrepôt est utilisée (15) car elle est inférieure à la valeur définie dans la hiérarchie des sessions (20). Le paramètre défini sur l’utilisateur (10) n’est pas pris en compte, car il est remplacé par le paramètre défini dans la session.
Note
Lorsque STATEMENT_QUEUED_TIMEOUT_IN_SECONDS et USER_TASK_TIMEOUT_MS sont tous deux définis, la valeur de USER_TASK_TIMEOUT_MS prévaut.
Lorsque vous comparez les valeurs de ces deux paramètres, notez que STATEMENT_QUEUED_TIMEOUT_IN_SECONDS est défini en unités de secondes, alors que USER_TASK_TIMEOUT_MS utilise des unités de millisecondes.
- Valeurs:
0à n’importe quel nombre (aucune limite) — une valeur de0spécifie qu’aucun délai d’expiration n’est appliqué. Une instruction restera en file d’attente tant que la file d’attente persistera.- Par défaut:
0(aucun délai d’expiration)
STATEMENT_TIMEOUT_IN_SECONDS¶
- Type:
Session et objet (pour les entrepôts)
Peut être défini pour Compte » Utilisateur » Session ; peut également être défini pour des entrepôts individuels
- Type de données:
Nombre
- Description:
Temps, en secondes, après lequel une instruction SQL en cours d’exécution (requête, DDL, DML, etc.) est annulée par le système.
Le paramètre peut être défini à différents niveaux dans la hiérarchie de la session (sur le compte, l’utilisateur et la session). Si le paramètre est défini à plus d’un niveau, les règles décrites dans Paramètres de session déterminent quelle valeur qui est utilisée.
Il peut également être défini pour un entrepôt individuel afin de contrôler la durée d’exécution de toutes les instructions SQL traitées par l’entrepôt. Lorsque le paramètre est défini à la fois dans la hiérarchie des sessions et dans l’entrepôt, le délai d’attente est la valeur non nulle la plus basse des deux paramètres.
Par exemple, supposons que le paramètre est défini sur les valeurs suivantes à différents niveaux :
Utilisateur - 10
Session - 20
Entrepôt - 15
Dans ce cas, la valeur du paramètre défini sur l’entrepôt est utilisée (15) car elle est inférieure à la valeur définie dans la hiérarchie des sessions (20). Le paramètre défini sur l’utilisateur (10) n’est pas pris en compte, car il est remplacé par le paramètre défini dans la session.
Lorsque USER_TASK_TIMEOUT_MS et STATEMENT_TIMEOUT_IN_SECONDS sont définis, le délai d’attente est la valeur non nulle la plus basse des deux paramètres. Lorsque vous comparez les valeurs de ces deux paramètres, notez que STATEMENT_TIMEOUT_IN_SECONDS est défini en unités de secondes, tandis que USER_TASK_TIMEOUT_MS utilise des unités de millisecondes.
Le paramètre défini s’applique à tout le temps pris par l’instruction, y compris le temps de file d’attente, le temps de verrouillage, le temps d’exécution, le temps de compilation, etc. Cela s’applique au temps global pris par l’instruction, et pas seulement au temps d’exécution de l’entrepôt.
- Valeurs:
0à604800(7 jours) — une valeur de0indique que le délai d’expiration maximal est appliqué.- Par défaut:
172800(2 jours)
STORAGE_SERIALIZATION_POLICY¶
- Type:
Objet (pour les bases de données, schémas et tables Apache Iceberg™) — Peut être défini pour Compte » Base de données » Schéma » Table Iceberg
- Type de données:
Chaîne (constante)
- Description:
Spécifie la politique de sérialisation de stockage des Tables Apache Iceberg™ gérées par Snowflake.
- Valeurs:
COMPATIBLE: Snowflake effectue un encodage et une compression qui garantissent l’interopérabilité avec les moteurs de calcul tiers.OPTIMIZED: Snowflake effectue un encodage et une compression qui garantissent les performances optimales des tables au sein de Snowflake.- Par défaut:
OPTIMIZED
STRICT_JSON_OUTPUT¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Booléen
- Description:
Ce paramètre spécifie si la sortie JSON dans une session est compatible avec la norme standard (comme décrit par http://json.org).
De par sa conception, Snowflake autorise une entrée JSON qui contient des valeurs non standard ; cependant, ces valeurs non standard pourraient entraîner une sortie JSON dans Snowflake qui est incompatible avec d’autres plateformes et langages. Ce paramètre, lorsqu’il est activé, assure que les sorties de Snowflake sont valides/compatibles JSON.
- Valeurs:
TRUE: une sortie JSON stricte est activée, ce qui permet d’appliquer le comportement suivant :Valeurs manquantes et non définies dans l’entrée associée à JSON NULL.
Valeurs numériques non finies en entrée (Infini, -Infinité, NaN, etc.) mappées avec des chaînes avec des représentations JavaScript valides. Ceci permet la compatibilité avec JavaScript et permet également la conversion de ces valeurs en valeurs numériques.
FALSE: la sortie JSON stricte n’est pas activée.- Par défaut:
FALSE
Par exemple :
Entrée JSON non standard |
Paramètre réglé sur |
Paramètre réglé sur |
|
|---|---|---|---|
|
sorties : |
|
|
|
sorties : |
|
|
|
sorties : |
|
|
|
sorties : |
|
|
SUSPEND_TASK_AFTER_NUM_FAILURES¶
- Type:
Objet (pour bases de données, schémas et tâches) — Peut être défini pour Compte » Base de données » Schéma » Tâche
- Type de données:
Entier
- Description:
Nombre d’exécutions successives de tâches qui ont échoué après lequel une tâche autonome ou une tâche racine d’un graphique de tâches est suspendue automatiquement. Les exécutions de tâches qui ont échoué comprennent les exécutions dans lesquelles le code SQL dans le corps de la tâche produit une erreur de l’utilisateur ou expire. Les exécutions de tâches qui sont ignorées, annulées ou qui échouent en raison d’une erreur système sont considérées comme indéterminées et ne sont pas incluses dans le compte des exécutions de tâches qui ont échoué.
Lorsque le paramètre est défini sur
0, la tâche défaillante n’est pas automatiquement suspendue.Lorsque le paramètre est défini sur une valeur supérieure à
0, le comportement suivant s’applique aux exécutions de tâches autonomes ou de tâches racines d’un graphique de tâches :Une tâche autonome est automatiquement suspendue après que le nombre spécifié d’exécutions consécutives de la tâche ait échoué ou ait expiré.
Une tâche racine est automatiquement suspendue après l’échec ou l’expiration de toute tâche unique dans un graphique de tâches, après le nombre spécifié d’exécutions consécutives, après toutes les
TASK_AUTO_RETRY_ATTEMPTSpour cette tâche.Par exemple, si la valeur de
SUSPEND_TASK_AFTER_NUM_FAILURESest définie à 3 pour une tâche racine et que la valeur deTASK_AUTO_RETRY_ATTEMPTSest définie à 3 pour une tâche enfant, la tâche racine est suspendue après 9 échecs consécutifs de la tâche enfant.
La valeur par défaut du paramètre est
10, ce qui signifie que la tâche est automatiquement suspendue après 10 échecs consécutifs de l’exécution de la tâche.Lorsque vous définissez explicitement la valeur du paramètre au niveau du compte, de la base de données ou du schéma, le changement est appliqué aux tâches contenues dans l’objet modifié lors de leur prochaine exécution planifiée (y compris toute tâche enfant dans une exécution de graphique de tâches en cours).
La suspension d’une tâche autonome réinitialise son compte d’échecs d’exécution. La suspension de la tâche racine d’un graphique de tâches réinitialise le compte de chaque tâche du graphique de tâches.
- Valeurs:
0- Pas de limite supérieure.- Par défaut:
10
TASK_AUTO_RETRY_ATTEMPTS¶
- Type:
Objet (pour bases de données, schémas et tâches) — Peut être défini pour Compte » Base de données » Schéma » Tâche
- Type de données:
Entier
- Description:
Spécifie le nombre de tentatives de réessais automatiques du graphique de tâches. Si des graphiques de tâches se terminent dans un état
FAILED, Snowflake peut automatiquement réessayer les graphiques de tâches à partir de la dernière tâche du graphique qui a échoué. Les exécutions de tâches qui ont échoué comprennent les exécutions dans lesquelles le code SQL dans le corps de la tâche produit une erreur de l’utilisateur ou expire. Les exécutions de tâches qui sont ignorées ou annulées sont considérées comme indéterminées et ne sont pas incluses dans le décompte des exécutions de tâches qui ont échoué.La répétition automatique du graphique de tâches est désactivée par défaut. Pour activer cette fonction, définissez
TASK_AUTO_RETRY_ATTEMPTSsur une valeur supérieure à0.Lorsque vous définissez la valeur de paramètre au niveau du compte, de la base de données ou du schéma, le changement est appliqué aux tâches contenues dans l’objet modifié lors de leur exécution planifiée suivante.
- Valeurs:
0- Pas de limite supérieure.- Par défaut:
0
TIMESTAMP_DAY_IS_ALWAYS_24H¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Booléen
- Description:
Spécifie si la fonction DATEADD (et ses alias) considère toujours un jour comme étant exactement 24 heures pour des expressions qui couvrent plusieurs jours.
- Valeurs:
TRUE: une journée s’étale toujours exactement sur 24 heures.FALSE: une journée ne s’étale pas toujours sur 24 heures.- Par défaut:
FALSE
Important
Si défini sur TRUE, l’heure réelle de la journée pourrait ne pas être conservée lorsque l’heure d’été (DST) est en vigueur. Par exemple :
TIMESTAMP_INPUT_FORMAT¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Chaîne
- Description:
Spécifie le format d’entrée pour l’alias de type de données TIMESTAMP. Pour plus d’informations, voir Formats d’entrée et de sortie de la date et de l’heure.
- Valeurs:
Tout format d’horodatage valide et pris en charge, ou
AUTO(
AUTOspécifie que Snowflake tente de détecter automatiquement le format des horodatages stockés dans le système pendant la session)- Par défaut:
AUTO
TIMESTAMP_LTZ_OUTPUT_FORMAT¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Chaîne
- Description:
Spécifie le format d’affichage pour le type de données TIMESTAMP_LTZ. Si CSV_TIMESTAMP_FORMAT n’est pas défini, TIMESTAMP_LTZ_OUTPUT_FORMAT est utilisé lors du téléchargement des fichiers CSV. Pour plus d’informations, voir Formats d’entrée et de sortie de la date et de l’heure.
- Valeurs:
Tout format d’horodatage valide et pris en charge
- Par défaut:
Aucun(e)
TIMESTAMP_NTZ_OUTPUT_FORMAT¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Chaîne
- Description:
Spécifie le format d’affichage pour le type de données TIMESTAMP_NTZ. Si CSV_TIMESTAMP_FORMAT n’est pas défini, TIMESTAMP_NTZ_OUTPUT_FORMAT est utilisé lors du téléchargement des fichiers CSV. Pour plus d’informations, voir Formats d’entrée et de sortie de la date et de l’heure.
- Valeurs:
Tout format d’horodatage valide et pris en charge
- Par défaut:
YYYY-MM-DD HH24:MI:SS.FF3
TIMESTAMP_OUTPUT_FORMAT¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Chaîne
- Description:
Spécifie le format d’affichage de l’alias de type de données TIMESTAMP. Pour plus d’informations, voir Formats d’entrée et de sortie de la date et de l’heure.
- Valeurs:
Tout format d’horodatage valide et pris en charge
- Par défaut:
YYYY-MM-DD HH24:MI:SS.FF3 TZHTZM
TIMESTAMP_TYPE_MAPPING¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Chaîne
- Description:
Spécifie la variation TIMESTAMP_* à laquelle l’alias de type de données TIMESTAMP correspond.
- Valeurs:
TIMESTAMP_LTZ,TIMESTAMP_NTZouTIMESTAMP_TZ- Par défaut:
TIMESTAMP_NTZ
TIMESTAMP_TZ_OUTPUT_FORMAT¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Chaîne
- Description:
Spécifie le format d’affichage pour le type de données TIMESTAMP_TZ. Si CSV_TIMESTAMP_FORMAT n’est pas défini, TIMESTAMP_TZ_OUTPUT_FORMAT est utilisé lors du téléchargement des fichiers CSV. Pour plus d’informations, voir Formats d’entrée et de sortie de la date et de l’heure.
- Valeurs:
Tout format d’horodatage valide et pris en charge
- Par défaut:
Aucun(e)
TIMEZONE¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Chaîne (constante)
- Description:
Indique le fuseau horaire de la session.
- Valeurs:
Vous pouvez spécifier un nom de fuseau horaire ou un nom de lien de la version 2025b de la base de données de fuseaux horaires IANA (par exemple,
America/Los_Angeles,Europe/London,UTC,Etc/GMT, etc.).- Par défaut:
America/Los_Angeles
Note
Les noms de fuseaux horaires sont sensibles à la casse et doivent être entre guillemets simples (par ex.
'UTC').Snowflake ne prend pas en charge la majorité des abréviations de fuseaux horaires (par exemple,
PDT,EST, etc.) car une abréviation donnée peut faire référence à plusieurs fuseaux horaires différents. Par exemple,CSTpeut faire référence à l’heure normale centrale en Amérique du Nord (UTC-6), à l’heure normale de Cuba (UTC-5) et à l’heure normale de Chine (UTC+8).
TIME_INPUT_FORMAT¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Chaîne
- Description:
Spécifie le format d’entrée pour le type de données TIME. Pour plus d’informations, voir Formats d’entrée et de sortie de la date et de l’heure.
- Valeurs:
Tout format horaire valide et pris en charge ou
AUTO(
AUTOspécifie que Snowflake tente de détecter automatiquement le format des horaires stockés dans le système pendant la session)- Par défaut:
AUTO
TIME_OUTPUT_FORMAT¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Chaîne
- Description:
Spécifie le format d’affichage pour le type de données TIME. Pour plus d’informations, voir Formats d’entrée et de sortie de la date et de l’heure.
- Valeurs:
Tout format horaire valide et pris en charge
- Par défaut:
HH24:MI:SS
TRACE_LEVEL¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
Objet (pour les bases de données, les schémas, les procédures stockées et les UDFs) — Peut être défini pour le compte » Base de données » Schéma » Procédure et compte » Base de données » Schéma » Fonction
- Type de données:
Chaîne (constante)
- Description:
Contrôle la manière dont les événements de trace sont intégrés dans la table des événements. Pour plus d’informations sur les niveaux de trace, consultez Définition des niveaux de journalisation, des métriques et du traçage.
- Valeurs:
ALWAYS: Tous les spans et tous les événements de trace seront enregistrés dans la table des événements.ON_EVENT: les événements de trace ne seront enregistrés dans la table des événements que lorsque vos procédures stockées ou UDFs ajouteront explicitement des événements.OFF: aucun span ni trace ne sera enregistré(e) dans la table des événements.- Par défaut:
OFF
Note
Lors du traçage d’événements, vous devez également définir le paramètre LOG_LEVEL sur l’une des valeurs prises en charge.
TRANSACTION_ABORT_ON_ERROR¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
BOOLEAN
- Description:
Spécifie l’action à effectuer lorsqu’une instruction émise dans le cadre d’une transaction sans validation automatique est retournée avec une erreur.
- Valeurs:
TRUE: la transaction sans validation automatique est annulée. Toutes les instructions émises à l’intérieur de cette transaction échoueront jusqu’à ce qu’une instruction de validation ou d’annulation soit exécutée pour clôturer cette transaction.FALSE: la transaction sans validation automatique n’est pas annulée.- Par défaut:
FALSE
TRANSACTION_DEFAULT_ISOLATION_LEVEL¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Chaîne
- Description:
Indique le niveau d’isolation des transactions de la session utilisateur.
- Valeurs:
READ COMMITTED(uniquement la valeur actuellement prise en charge)- Par défaut:
READ COMMITTED
TWO_DIGIT_CENTURY_START¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Nombre
- Description:
Indique l’année de « début du siècle » pour les années à deux chiffres, c’est-à-dire l’année la plus ancienne que ces dates peuvent représenter. Ce paramètre permet d’éviter les dates ambiguës lors de l’importation ou de la conversion de données avec le composant de format de date
YY(années représentées par 2 chiffres).- Valeurs:
1900à2100(toute valeur en dehors de cette plage renvoie une erreur)- Par défaut:
1970
Par exemple :
Année |
Paramètre réglé sur |
Paramètre réglé sur |
Paramètre réglé sur |
Paramètre réglé sur |
Paramètre réglé sur |
|
|---|---|---|---|---|---|---|
|
devient : |
|
|
|
|
|
|
devient : |
|
|
|
|
|
|
devient : |
|
|
|
|
|
|
devient : |
|
|
|
|
|
UNSUPPORTED_DDL_ACTION¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Chaîne (constante)
- Description:
Détermine si une valeur non prise en charge (hors valeur par défaut) spécifiée pour une propriété de contrainte renvoie une erreur.
- Valeurs:
IGNORE: Snowflake ne retourne pas d’erreur pour les valeurs non prises en charge.FAIL: Snowflake renvoie une erreur pour les valeurs non prises en charge.- Par défaut:
IGNORE
Important
Ce paramètre ne détermine pas si la contrainte est créée. Snowflake ne crée pas de contraintes en utilisant des valeurs non prises en charge, peu importe comment ce paramètre est réglé.
Pour plus d’informations, consultez Propriétés des contraintes.
USE_CACHED_RESULT¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Booléen
- Description:
Indique s’il faut réutiliser les résultats de la requête mise en cache, le cas échéant, lorsqu’une requête correspondante est soumise.
- Valeurs:
TRUE: lorsqu’une requête est soumise, Snowflake vérifie si les résultats de la requête correspondent aux requêtes déjà exécutées et, si un résultat correspondant existe, utilise le résultat au lieu d’exécuter la requête. Cela peut aider à réduire le temps de requête car Snowflake récupère le résultat directement dans le cache.FALSE: Snowflake exécute chaque requête lorsqu’elle est soumise, qu’il existe ou non un résultat de requête correspondant.- Par défaut:
TRUE
USER_TASK_MANAGED_INITIAL_WAREHOUSE_SIZE¶
- Type:
Objet (pour bases de données, schémas et tâches) — Peut être défini pour Compte » Base de données » Schéma » Tâche
- Type de données:
Chaîne
- Description:
Spécifie la taille des ressources de calcul à provisionner pour la première exécution de la tâche, avant qu’un historique de la tâche ne soit disponible pour que Snowflake puisse déterminer une taille idéale. Une fois qu’une tâche a effectué avec succès quelques cycles, Snowflake ignore ce paramètre. Si l’historique des tâches n’est pas disponible pour une tâche donnée, les ressources de calcul reviennent à cette taille initiale.
Note
Ce paramètre s’applique uniquement aux tâches sans serveur.
La taille est équivalente aux ressources de calcul disponibles lors de la création d’un entrepôt. Si le paramètre est omis, les premières exécutions de la tâche s’effectuent en utilisant un entrepôt de taille moyenne (
MEDIUM).Vous pouvez modifier la taille initiale pour des tâches individuelles (en utilisant ALTER TASK) après la création de la tâche, mais avant qu’elle ait été exécutée avec succès une fois. La modification du paramètre après le démarrage de la première exécution de cette tâche n’a aucun effet sur les ressources de calcul pour les exécutions actuelles ou futures de la tâche.
Notez que la suspension et la reprise d’une tâche ne suppriment pas l’historique des tâches utilisé pour dimensionner les ressources de calcul. L’historique de la tâche n’est supprimé que si la tâche est recréée (en utilisant la syntaxe CREATE OR REPLACETASK).
- Valeurs:
Toute taille d’entrepôt traditionnelle <label-warehouse_size> :
XSMALL,SMALL,MEDIUM,LARGE,XLARGE,X2LARGE. La taille maximale est deX2LARGE.Prend également en charge la syntaxe :
XXLARGE.- Par défaut:
MEDIUM
USER_TASK_MINIMUM_TRIGGER_INTERVAL_IN_SECONDS¶
- Type:
Objet (pour bases de données, schémas et tâches) — Peut être défini pour Compte » Base de données » Schéma » Tâche
- Type de données:
Nombre
- Description:
Définit la fréquence d’exécution d’une tâche déclenchée en secondes. Si une tâche est déclenchée à nouveau pendant son exécution, Snowflake attend le nombre de secondes spécifié (après que l’exécution précédente a été planifiée) avant de démarrer l’exécution suivante.
Si vous définissez ce paramètre sur plus de 12 heures pour une tâche, celle-ci s’exécute toutes les 12 heures.
- Valeurs:
10-604800(1 semaine).- Par défaut:
30
USER_TASK_TIMEOUT_MS¶
- Type:
Objet (pour bases de données, schémas et tâches) — Peut être défini pour Compte » Base de données » Schéma » Tâche
- Type de données:
Nombre
- Description:
Spécifie la limite de temps sur une seule exécution de la tâche avant son expiration (en millisecondes).
Note
Avant d’augmenter considérablement le délai de tâches, demandez-vous si les instructions SQL dans les définitions de tâches pourraient être optimisées (soit en réécrivant les instructions, soit en utilisant des procédures stockées) ou si la taille de l’entrepôt pour les tâches avec des ressources de calcul gérées par l’utilisateur devrait être augmentée.
Lorsque STATEMENT_TIMEOUT_IN_SECONDS et USER_TASK_TIMEOUT_MS sont définis, le délai d’expiration est la valeur la plus basse non nulle des deux paramètres.
Lorsque STATEMENT_QUEUED_TIMEOUT_IN_SECONDS et USER_TASK_TIMEOUT_MS sont tous deux définis, la valeur de USER_TASK_TIMEOUT_MS prévaut.
Pour plus d’informations sur USER_TASK_TIMEOUT_MS, voir CREATETASK…USER_TASK_TIMEOUT.
- Valeurs:
0-604800000(7 jours). Une valeur de0spécifie que la valeur de délai d’attente maximum est appliquée.- Par défaut:
3600000(1 heure)
USE_WORKSPACES_FOR_SQL¶
- Type:
Compte — Ne peut être défini que pour le compte
- Type de données:
Chaîne (constante)
- Description:
Contrôle si l’éditeur d’espaces de travail est l’expérience de modification SQL par défaut pour le compte.
- Valeurs:
always: Définir l’éditeur par défaut à l’échelle du compte comme espaces de travail pour tous les utilisateurs.never: Revenir à l’éditeur précédent et ignorer temporairement tout BCR géré par Snowflake qui fait des espaces de travail l’environnement par défaut.Pour plus d’informations, voir Espaces de travail.
WEEK_OF_YEAR_POLICY¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Nombre
- Description:
Indique comment les semaines d’une année donnée sont calculées.
- Valeurs:
0: la sémantique utilisée est équivalente à la sémantique ISO, pour laquelle une semaine appartient à une année donnée si au moins 4 jours de cette semaine se situent dans cette année.1: le 1er janvier est inclus dans la première semaine de l’année et le 31 décembre est inclus dans la dernière semaine de l’année.- Par défaut:
0(comportement similaire à ISO)
Astuce
1 est la valeur la plus courante, d’après les commentaires que nous avons reçus. Pour plus d’informations, y compris des exemples, voir Semaines civiles et jours de semaine.
WEEK_START¶
- Type:
Session — Peut être défini pour Compte » Utilisateur » Session
- Type de données:
Nombre
- Description:
Indique le premier jour de la semaine (utilisé par des fonctions de date liées à la semaine).
- Valeurs:
0: le comportement hérité de Snowflake est utilisé (sémantique similaire à ISO).1(lundi) à7(dimanche) : toutes les fonctions liées à la semaine utilisent des semaines qui commencent le jour spécifié de la semaine.- Par défaut:
0(comportement hérité de Snowflake)
Astuce
1 est la valeur la plus courante, d’après les commentaires que nous avons reçus. Pour plus d’informations, y compris des exemples, voir Semaines civiles et jours de semaine.