Introduction to streams¶
Un objet flux enregistre les modifications apportées aux tables en langage de manipulation des données (DML), notamment les insertions (y compris COPY INTO), les mises à jour et les suppressions, ainsi que les métadonnées relatives à chaque modification, afin que des actions puissent être effectuées à l’aide des données modifiées. Ce processus est appelé « capture de données modifiées » (CDC). Cette rubrique présente les concepts clés de la capture des données de modification à l’aide de flux.
Un flux de table individuel suit les modifications apportées aux lignes d’une table source. Un flux de table (également appelé simplement « flux ») rend disponible une « table de modifications » de ce qui a changé, au niveau de la ligne, entre deux instants transactionnels d’une table. Cela permet d’interroger et de consommer une séquence d’enregistrements de modification de manière transactionnelle.
Des flux peuvent être créés pour interroger les données de changement sur les objets suivants :
Tables standard, y compris les tables partagées.
Vues, y compris les vues sécurisées
Offset storage¶
Une fois créé, un flux prend logiquement un instantané initial de chaque ligne de l’objet source (par exemple, une table, une table externe ou les tables sous-jacentes d’une vue) en initialisant un point dans le temps (appelé décalage) en tant que version transactionnelle actuelle de l’objet. Le système de suivi des modifications utilisé par le flux enregistre ensuite les informations relatives aux modifications DML après la prise de cet instantané. Les enregistrements de modifications fournissent l’état d’une ligne avant et après la modification. Les informations de modification reflètent la structure de colonne de l’objet source suivi et incluent des colonnes de métadonnées supplémentaires décrivant chaque événement de modification.
Les flux utilisent le schéma de table actuel. Toutefois, étant donné que les flux peuvent lire des données supprimées pour suivre les modifications au fil du temps, toute modification de schéma incompatible entre le décalage et l’avance peut entraîner l’échec de la requête.
Notez que le flux lui-même ne contient aucune donnée de table. Un flux stocke uniquement un décalage de l’objet source et renvoie des enregistrements CDC en exploitant l’historique de gestion des versions de l’objet source. Lorsque le premier flux d’une table est créé, plusieurs colonnes masquées sont ajoutées à la table source et commencent à stocker les métadonnées de traçage des modifications. Ces colonnes consomment une petite quantité de stockage. Les enregistrements CDC renvoyés lors de l’interrogation d’un flux reposent sur une combinaison du décalage stocké dans le flux et des métadonnées de suivi des modifications stockées dans la table. Notez que pour Streams on Views, le suivi des modifications doit être activé explicitement pour la vue et les tables sous-jacentes afin d’ajouter les colonnes cachées à ces tables.
Il peut être utile de considérer un flux comme un signet, indiquant un moment précis dans les pages d’un livre (c’est-à-dire l’objet source). Un signet peut être jeté et d’autres signets insérés à différents endroits dans un livre. De même, un flux peut être détruit et d’autres flux créés au même moment ou à des moments différents (soit en créant les flux consécutivement à des moments différents, soit en utilisant Time Travel) pour consommer les enregistrements de modification d’un objet à des décalages identiques ou différents.
Un exemple de consommateur d’enregistrements CDC est un pipeline de données dans lequel seules les données des tables en zone de préparation qui ont été modifiées depuis la dernière extraction sont transformées et copiées dans d’autres tables.
Table versioning¶
Une nouvelle version de la table est créée chaque fois qu’une transaction qui comprend une ou plusieurs instructions DML est validée dans la table. Cela s’applique aux types de tables suivants :
Tables standards
Tables de répertoire
Tables dynamiques
Tables externes
Tables Apache Iceberg™
Tables sous-jacentes d’une vue
Dans l’historique des transactions pour une table, un décalage de flux est situé entre deux versions de la table. L’interrogation d’un flux renvoie les changements causés par les transactions effectuées après le décalage et à l’heure actuelle ou avant.
L’exemple suivant montre une table source avec 10 versions validées dans la chronologie. Le décalage pour le flux s1 se situe actuellement entre les versions de table v3 et v4. Lorsque le flux est interrogé (ou consommé), les enregistrements renvoyés comprennent toutes les transactions entre la version de la table v4, la version immédiatement après le décalage du flux dans la chronologie de la table, et v10, la version la plus récente de la table validée dans la chronologie, elle comprise.
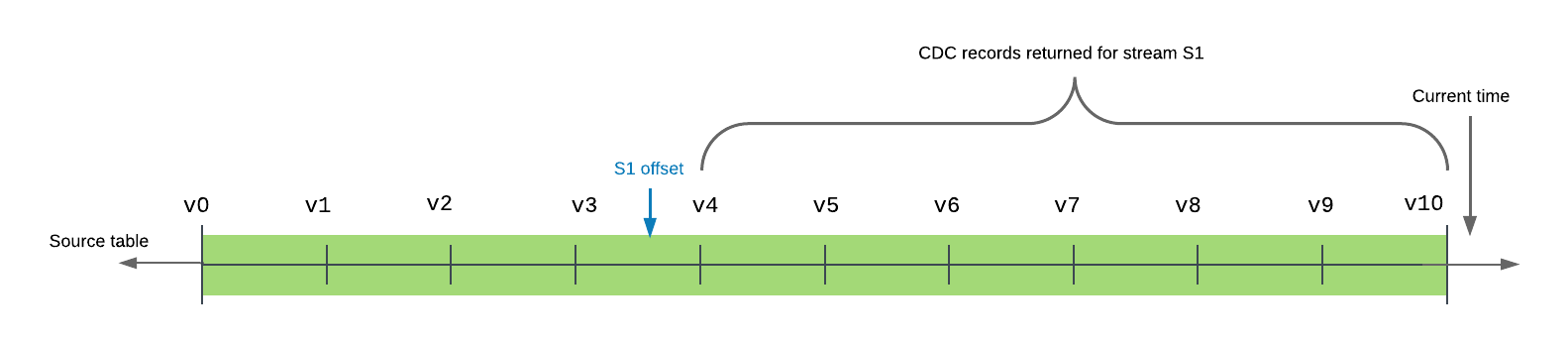
Un flux fournit l’ensemble minimal de changements entre son décalage actuel et la version actuelle de la table.
Plusieurs demandes peuvent consommer indépendamment les mêmes données de modification d’un flux sans modifier le décalage. Un flux avance le décalage uniquement lorsqu’il est utilisé dans une transaction DML. Cela inclut une transaction Create Table As Select (CTAS) ou une transaction d’emplacement COPY INTO et ce comportement s’applique à la fois aux transactions explicites et aux transactions autocommit. (Par défaut, lorsqu’une instructionDML est exécutée, une transaction de validation automatique est implicitement lancée et la transaction est validée à la fin de l’instruction. Ce comportement est contrôlé avec le paramètre AUTOCOMMIT.) L’interrogation d’un flux seul ne fait pas avancer son décalage, même dans le cadre d’une transaction explicite ; le contenu du flux doit être consommé dans une instruction DML.
Note
Pour avancer le décalage d’un flux à la version actuelle de la table sans consommer les données de modification dans une opération DML, effectuez l’une des actions suivantes :
Recréez le flux (en utilisant la syntaxe CREATE OR REPLACE STREAM).
Insérez les données de modification actuelles dans une table temporaire. Dans l’instruction INSERT, interrogez le flux mais incluez une clause WHERE qui filtre toutes les données de modification (par exemple,
WHERE 0 = 1).
Lorsqu’une instruction SQL interroge un flux dans une transaction explicite, le flux est interrogé au point d’avance du flux (c’est-à-dire l’horodatage) lorsque la transaction a commencé plutôt que lorsque l’instruction a été exécutée. Ce comportement concerne à la fois les instructions DML et CREATE TABLE … AS SELECT (CTAS) qui remplissent une nouvelle table avec des lignes d’un flux existant.
Une instruction DML qui sélectionne un flux utilise toutes les données de modification du flux tant que la transaction est validée. Pour vous assurer que plusieurs instructions ont accès aux mêmes enregistrements de modification dans le flux, entourez-les d’une instruction de transaction explicite (BEGIN .. COMMIT). Cela verrouille le flux. Les mises à jour DML de l’objet source dans les transactions parallèles sont suivies par le système de suivi des modifications mais ne mettent pas à jour le flux tant que l’instruction de transaction explicite n’est pas validée et que les données de modification existantes ne sont pas utilisées.
Repeatable read isolation¶
Les flux prennent en charge l’isolation de lecture répétable. En mode de lecture répétable, plusieurs instructions SQL d’une transaction voient le même jeu d’enregistrements dans un flux. Cela diffère du mode de lecture validée pris en charge pour les tables, dans lequel les instructions voient toutes les modifications apportées par les instructions précédentes exécutées dans la même transaction, même si ces modifications ne sont pas encore validées.
Les enregistrements delta renvoyés par les flux d’une transaction correspondent à la plage allant de la position actuelle du flux jusqu’à l’heure de début de la transaction. La position du flux avance à l’heure de début de la transaction si la transaction est validée ; sinon, elle reste à la même position.
Prenons l’exemple suivant :
Durée |
Transaction 1 |
Transaction 2 |
|---|---|---|
1 |
Commencez une transaction. |
|
2 |
Interrogez le flux |
|
3 |
Mettez à jour des lignes dans une table |
|
4 |
Interrogez le flux |
|
5 |
Validez la transaction. Si le flux a été utilisé dans des instructions DML dans la transaction, la position du flux passe à l’heure de début de la transaction. |
|
6 |
Commencez une transaction. |
|
7 |
Interrogez le flux |
Dans la transaction 1, toutes les requêtes pour diffuser s1 affichent le même jeu d’enregistrements. Les modifications DML apportées à la table t1 sont enregistrées dans le flux uniquement lorsque la transaction est validée.
Dans la transaction 2, les requêtes sur le flux affichent les modifications enregistrées dans la table dans la Transaction 1. Notez que si la Transaction 2 avait commencé avant que la Transaction 1 soit validée, les requêtes adressées au flux auraient renvoyé un instantané du flux de la position du flux au début de la Transaction 2 et n’afficheraient aucune modification validée par la Transaction 1.
Stream columns¶
Un flux stocke un décalage pour l’objet source et non les colonnes ou les données réelles de la table. Lorsqu’il est interrogé, un flux accède aux données historiques et les renvoie sous la même forme que l’objet source (c’est-à-dire les mêmes noms de colonnes et le même ordre) avec les colonnes supplémentaires suivantes :
- METADATA$ACTION:
Indique l’opération DML (INSERT, DELETE) enregistrée.
- METADATA$ISUPDATE:
Indique si l’opération faisait partie d’une instruction UPDATE. Les mises à jour des lignes de l’objet source sont représentées par une paire d’enregistrements DELETE et INSERT dans le flux avec des valeurs de colonne de métadonnées METADATA$ISUPDATE définies sur TRUE.
Notez que les flux enregistrent les différences entre deux décalages. Si une ligne est ajoutée puis mise à jour dans le décalage actuel, la modification delta est une nouvelle ligne. La ligne METADATA$ISUPDATE enregistre une valeur FALSE.
- METADATA$ROW_ID:
Spécifie un ID de ligne unique et immuable pour le suivi des modifications dans le temps. Si CHANGE_TRACKING est désactivé et réactivé ultérieurement sur l’objet source du flux, l’ID de ligne pourrait changer.
Snowflake offre les garanties suivantes en ce qui concerne METADATA$ROW_ID :
Le METADATA$ROW_ID dépend de l’objet source du flux.
Par exemple, un flux
stream1sur la tabletable1et un fluxstream2sur la tabletable1produisent les mêmes METADATA$ROW_ID pour les mêmes lignes, mais un fluxstream_viewsur la vueview1n’est pas garanti de produire les mêmes METADATA$ROW_ID questream1, même siviewest défini à l’aide de l’instructionCREATE VIEW view AS SELECT * FROM table1.Un flux sur un objet source et un flux sur le clone de l’objet source produisent les mêmes METADATA$ROW_ID pour les lignes qui existent au moment du clonage.
Un flux sur un objet source et un flux sur la réplication de l’objet source produisent les mêmes METADATA$ROW_ID pour les lignes qui ont été répliquées.
Types of streams¶
Les types de flux suivants sont disponibles en fonction des métadonnées enregistrées par chacun :
- Standard:
Pris en charge pour les flux sur les tables standard, les tables dynamiques, les tables Apache Iceberg™ gérées par Snowflake, les tables de répertoire ou les vues. Un flux standard (c’est-à-dire delta) suit toutes les modifications DML apportées à l’objet source, notamment les insertions, les mises à jour et les suppressions (y compris les troncatures de table). Ce type de flux effectue une jointure sur les lignes insérées et supprimées dans le jeu de modifications pour fournir le delta de niveau ligne. En tant qu’effet net, par exemple, une ligne qui est insérée puis supprimée entre deux points de temps transactionnels dans une table est supprimée dans le delta (c’est-à-dire qu’elle n’est pas renvoyée lorsque le flux est interrogé).
Note
Les flux standards ne peuvent pas récupérer les données de changement pour les données géospatiales. Nous recommandons de créer des flux d’ajout uniquement sur les objets qui contiennent des données géospatiales.
- Ajouter uniquement:
Pris en charge pour les flux sur les tables standard, les tables dynamiques, les tables Apache Iceberg™ gérées par Snowflake ou les vues. Un flux append-only suit exclusivement les insertions de lignes. Les opérations de mise à jour, de suppression et de troncature ne sont pas prises en compte par les flux d’ajout uniquement. Par exemple, si 10 lignes sont initialement insérées dans une table, puis 5 de ces lignes sont supprimées avant d’avancer le décalage pour un flux d’ajout uniquement, le flux n’enregistrera que les 10 lignes insérées.
Un flux d’ajout uniquement renvoie spécifiquement les lignes ajoutées, ce qui le rend nettement plus performant qu’un flux standard pour l’extraction, le chargement et la transformation (ELT), ainsi que des scénarios similaires reposant uniquement sur l’insertion de lignes. Par exemple, une table source peut être tronquée immédiatement après la consommation des lignes d’un flux d’ajout uniquement, et les suppressions d’enregistrement ne contribuent pas à la surcharge la prochaine fois que le flux est interrogé ou consommé.
La création d’un flux d’ajout uniquement dans un compte cible utilisant un objet secondaire comme source n’est pas prise en charge.
- Insertion uniquement:
Prise en charge pour les flux sur Apache Iceberg™ géré en externe ou les tables externes. Un flux à insertion uniquement suit uniquement les insertions de lignes ; il n’enregistre pas les opérations de suppression qui suppriment des lignes d’un ensemble inséré (c’est-à-dire sans opération). Par exemple, entre deux décalages, si
File1est supprimé de l’emplacement de stockage Cloud référencé par la table externe etFile2est ajouté, le flux renvoie des enregistrements pour les lignes dansFile2uniquement, indépendamment du fait queFile1ait été ajouté avant ou dans l’intervalle de modification demandé. Contrairement au suivi des données CDC pour les tables standard, l’accès aux enregistrements historiques pour les fichiers dans le stockage Cloud n’est pas régi ou garanti par Snowflake.Les fichiers remplacés ou ajoutés sont essentiellement traités en tant que nouveaux fichiers : l’ancienne version du fichier est supprimée du stockage Cloud, mais le flux à insertion uniquement n’enregistre pas l’opération de suppression. La nouvelle version du fichier est ajoutée au stockage Cloud et le flux à insertion uniquement enregistre les lignes comme des insertions. Le flux n’enregistre pas les différences entre les anciennes et les nouvelles versions du fichier. Notez que les ajouts peuvent ne pas déclencher l’actualisation automatique des métadonnées de la table externe, comme dans le cas de l’utilisation de Azure AppendBlobs.
Data flow¶
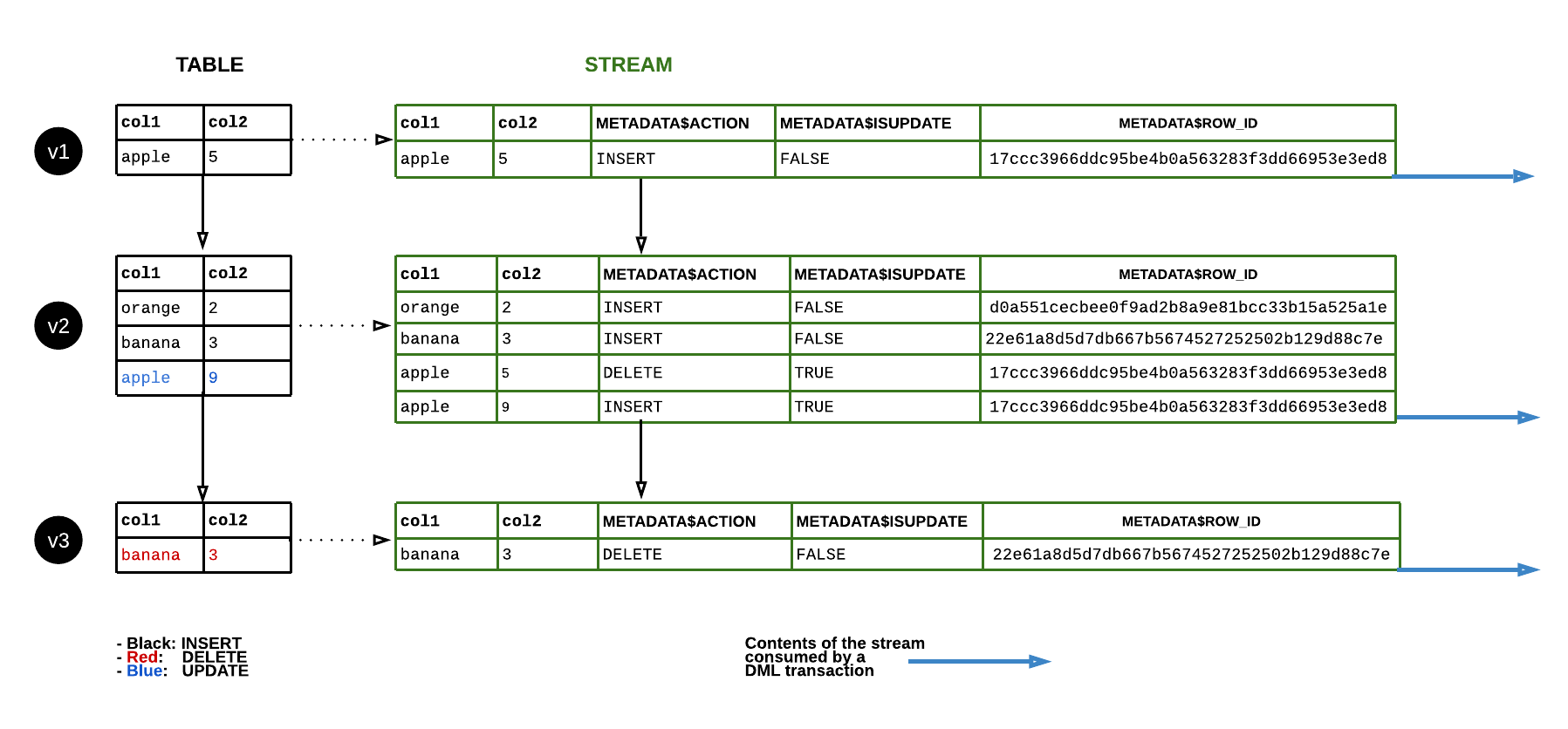
Le diagramme suivant montre comment le contenu d’un flux standard change lorsque les lignes de la table source sont mises à jour. Chaque fois qu’une instruction DML consomme le contenu du flux, la position du flux avance pour suivre le prochain ensemble de modifications de la table DML (c’est-à-dire les modifications apportées à une version de table) :
Data retention period and staleness¶
Un flux devient obsolète lorsque son décalage est en dehors de la période de conservation des données pour sa table source (ou les tables sous-jacentes d’une vue source). Lorsqu’un flux devient périmé, les données historiques et tous les enregistrements de modifications non consommés pour la table source ne sont plus accessibles. Pour continuer à suivre les nouveaux enregistrements de modifications, vous devez recréer le flux à l’aide de la commande CREATE STREAM.
Pour empêcher un flux de devenir périmé, consommez les enregistrements de flux dans une instruction DML pendant la période de conservation de la table et consommez régulièrement ses données de modification avant son horodatage STALE_AFTER (c’est-à-dire dans la période de conservation prolongée des données pour l’objet source). De plus, l’appel de SYSTEM$STREAM_HAS_DATA sur le flux empêchera également celui-ci de devenir périmé tant que le flux est vide et que la fonction SYSTEM$STREAM_HAS_DATA renvoie FALSE.
Pour plus d’informations sur les périodes de conservation des données, voir Compréhension et utilisation de la fonction Time Travel.
Note
Les flux sur les tables ou les vues partagées ne prolongent pas la période de conservation des données pour la table ou les tables sous-jacentes, respectivement. Pour plus d’informations, voir Flux sur les objets partagés.
Si la période de conservation des données pour une table est inférieure à 14 jours et qu’un flux n’a pas été consommé, Snowflake prolonge temporairement cette période pour éviter que le flux ne devienne obsolète. La période de conservation est étendue au décalage du flux, jusqu’à un maximum de 14 jours par défaut, quelle que soit votre édition Snowflake. Le nombre maximal de jours pendant lesquels Snowflake peut prolonger la période de conservation des données est déterminé par la valeur du paramètre MAX_DATA_EXTENSION_TIME_IN_DAYS. Une fois le flux consommé, la période de conservation prolongée des données revient à la valeur par défaut de la table.
Le tableau suivant présente des exemples de valeurs DATA_RETENTION_TIME_IN_DAYS et MAX_DATA_EXTENSION_TIME_IN_DAYS, indiquant à quelle fréquence le contenu du flux doit être consommé pour éviter l’obsolescence :
DATA_RETENTION_TIME_IN_DAYS |
MAX_DATA_EXTENSION_TIME_IN_DAYS |
Consommer des flux en X jours |
|---|---|---|
14 |
0 |
14 |
1 |
14 |
14 |
0 |
90 |
90 |
Pour vérifier le statut d’obsolescence d’un flux, utilisez la commande DESCRIBE STREAM ou SHOW STREAMS. L’horodatage de la colonne STALE_AFTER indique la période de conservation étendue des données pour l’objet source. Il indique la date à laquelle il est prévu que le flux devienne obsolète ou quand il est devenu obsolète, si l’horodatage est dans le passé. Cet horodatage est calculé en ajoutant la valeur la plus élevée des paramètres DATA_RETENTION_TIME_IN_DAYS ou MAX_DATA_EXTENSION_TIME_IN_DAYS de l’objet source à la dernière heure de consommation du flux.
Note
Si la période de conservation des données pour la table source est définie au niveau du schéma ou de la base de données, le rôle actuel doit avoir accès au schéma ou à la base de données pour calculer la valeur STALE_AFTER.
La consommation de données de modification pour un flux met à jour l’horodatage STALE_AFTER. Même si la lecture du flux peut se poursuivre pendant un certain temps après l’horodatage STALE_AFTER, le flux peut devenir obsolète à tout moment. La colonne STALE indique si le flux est censé être obsolète, bien qu’il puisse ne pas l’être encore.
Pour empêcher un flux de devenir périmé, consommez régulièrement ses données de modification avant son horodatage STALE_AFTER (c’est-à-dire dans la période de conservation prolongée des données pour l’objet source). Ne vous fiez pas aux résultats d’un flux après l’écoulement de la période STALE_AFTER car la fonction STREAM_HAS_DATA peut renvoyer des résultats inattendus.
Une fois l’horodatage STALE_AFTER expiré, le flux peut devenir obsolète à tout moment, même s’il ne contient aucun enregistrement non consommé. L’interrogation d’un flux peut renvoyer aucun enregistrement, même s’il existe des données de modification pour l’objet source. Par exemple, un flux d’ajout uniquement effectue le suivi uniquement des insertions de lignes, mais il met à jour et supprime également les enregistrements de modification dans l’objet source. De plus, certaines écritures de table, comme le reclustering, ne génèrent pas de données de modification. La consommation des données de modification pour un flux avance son décalage à la date actuelle, que les versions intermédiaires contiennent ou non des données de modification.
Important
La recréation d’un objet (à l’aide de la syntaxe CREATE OR REPLACE TABLE) détruit son historique, ce qui rend également caduc tout flux sur la table ou la vue. En outre, la recréation ou la destruction de l’une des tables sous-jacentes d’une vue rend caduc tout flux sur la vue.
Actuellement, lorsqu’une base de données ou un schéma contenant un flux et que sa table source (ou les tables sous-jacentes d’une vue source) est clonée, tous les enregistrements non consommés dans le flux clone sont inaccessibles. Ce comportement est cohérent avec Time Travel pour les tables. Si une table est clonée, les données historiques pour le clone de table commencent à l’heure/le moment où le clone a été créé.
Renommer un objet source n’interrompt pas un flux et ne le rend pas caduc. En outre, si un objet source est détruit et qu’un nouvel objet est créé avec le même nom, tous les flux liés à l’objet d’origine sont non liés au nouvel objet.
Multiple consumers of streams¶
Nous recommandons aux utilisateurs de créer un flux séparé pour chaque consommateur d’enregistrements de modification pour un objet. Le terme « consommateur » désigne une tâche, un script ou un autre mécanisme qui consomme les enregistrements de modifications pour un objet en utilisant une transaction DML. Comme indiqué précédemment dans cette rubrique, un flux n’avance son décalage que lorsqu’il est utilisé dans une transaction DML. Il s’agit notamment d’une transaction Create Table As Select (CTAS) ou d’une transaction d’emplacement COPY INTO.
Les différents consommateurs de données de changement dans un même flux récupèrent différents deltas, sauf si Time Travel est utilisé. Lorsque les données de changement saisies à partir du dernier décalage dans un flux sont consommées en utilisant une transaction DML, le flux avance le décalage. Les données de modification ne sont plus disponibles pour le prochain consommateur. Pour consommer les mêmes données de modification pour un objet, créez plusieurs flux pour l’objet. Un flux ne stocke qu’un décalage pour l’objet source et aucune donnée réelle de colonne de table ; vous pouvez donc créer un nombre quelconque de flux pour un objet sans encourir de coûts importants.
Streams on views¶
Streams on Views prend en charge à la fois les vues locales et les vues partagées à l’aide de Snowflake Secure Data Sharing, y compris les vues sécurisées. Notez que, pour le moment, les flux ne peuvent pas suivre les modifications dans les vues matérialisées.
Les flux sont limités aux vues qui satisfont aux exigences suivantes :
- Tables sous-jacentes:
Toutes les tables sous-jacentes doivent être des tables natives.
La vue ne peut appliquer que les opérations suivantes :
Projections
Filters
Jointures intérieures ou transversales
UNION ALL
Les vues imbriquées et les sous-requêtes incluses dans la clause FROM sont prises en charge à condition que la requête entièrement développée réponde aux autres exigences spécifiées dans cette table.
- Voir la requête:
Exigences générales :
La requête peut sélectionner un nombre quelconque de colonnes.
La requête peut contenir un nombre quelconque de prédicats WHERE.
Les vues avec les opérations suivantes ne sont pas encore prises en charge :
Clauses GROUP BY
Clauses QUALIFY
Sous-requêtes ne figurant pas dans la clause FROM
Sous-requêtes non corrélées
Clauses LIMIT
Clauses DISTINCT
Fonctions :
Les fonctions de la liste de sélection doivent être des fonctions scalaires définies par le système.
- Suivi des modifications:
Le suivi des modifications doit être activé dans les tables sous-jacentes.
Avant de créer un flux sur une vue, vous devez activer le suivi des modifications sur les tables sous-jacentes de la vue. Pour obtenir des instructions, voir Enabling change tracking on views and underlying tables.
Join results behavior¶
Lorsque l’on examine les résultats d’un flux qui suit les modifications apportées à une vue contenant une jointure, il est important de comprendre quelles données sont jointes. Les changements survenus sur la table de gauche depuis le décalage du flux sont joints à la table de droite, les changements sur la table de droite depuis le décalage du flux sont joints à la table de gauche, et les changements sur les deux tables depuis le décalage du flux sont joints l’un à l’autre.
Prenons l’exemple suivant :
Deux tables sont créées :
Une vue est créée pour joindre les deux tables sur id. Chaque table a une seule ligne qui se joint à l’autre :
Un flux est créé pour suivre les modifications de la vue :
La vue a une entrée et le flux n’en a aucune puisqu’il n’y a eu aucune modification des tables depuis le décalage actuel du flux :
Une fois les mises à jour effectuées dans les tables sous-jacentes, la sélection de ordersByCustomerStream produira des enregistrements de orders x Δ customers + Δ orders x customers + Δ orders x Δ customers où :
Δ
orderset Δcustomerssont les changements qui se sont produits dans chaque table depuis le décalage du flux.Les commandes et les clients sont les contenus totaux des tables au décalage actuel du flux.
Notez qu’en raison des optimisations dans Snowflake, le coût du calcul de cette expression n’est pas toujours linéairement proportionnel à la taille des entrées.
Si une autre ligne de jonction est insérée dans orders, ordersByCustomer aura une nouvelle ligne :
Une sélection depuis ordersByCustomersStream produit une ligne, car Δ orders x customers contient la nouvelle insertion et orders x Δ customers + Δ orders x Δ customers est vide :
Si une autre ligne de jonction est ensuite insérée dans customers alors ordersByCustomer aura un total de trois nouvelles lignes :
Une sélection depuis ordersByCustomersStream produit trois lignes, car Δ orders x customers, orders x Δ customers, et Δ orders x Δ customers produisent chacun une ligne :
Notez que pour les flux d’ajout uniquement, Δ orders et Δ customers contiendront uniquement les insertions de lignes, tandis que orders et customers contiendront le contenu complet des tables, y compris les mises à jour effectuées avant le décalage du flux.
CHANGES clause: Read-only alternative to streams¶
Comme alternative aux flux, Snowflake prend en charge l’interrogation des métadonnées de suivi des modifications pour les tables ou les vues à l’aide de la clause CHANGES pour les instructions SELECT. La clause CHANGES permet d’interroger les métadonnées de suivi des modifications entre deux points dans le temps sans avoir à créer un flux avec un décalage transactionnel explicite. L’utilisation de la clause CHANGES ne fait pas avancer le décalage (c’est-à-dire consommer des enregistrements). Plusieurs requêtes peuvent récupérer les métadonnées de suivi des modifications entre différents points de départ et points de terminaison transactionnels. Cette option nécessite de spécifier un point de départ transactionnel pour les métadonnées à l’aide d’une clause AT | BEFORE ; le point de terminaison de l’intervalle de suivi des modifications peut être défini à l’aide de la clause END facultative.
Un flux stocke la version transactionnelle actuelle d’une table et est la source appropriée d’enregistrements CDC dans la plupart des scénarios. Pour les scénarios peu fréquents qui nécessitent de gérer le décalage pendant des périodes arbitraires, la clause CHANGES est disponible pour votre usage.
Actuellement, les éléments suivants doivent correspondre avant que les métadonnées de suivi des modifications soient enregistrées :
- Tables:
Soit activer le suivi des modifications sur la table (en utilisant ALTER TABLE … CHANGE_TRACKING = TRUE), soit créer un flux sur la table (en utilisant CREATE STREAM).
- Vues:
Activez le suivi des modifications sur la vue et ses tables sous-jacentes. Pour obtenir des instructions, voir Enabling change tracking on views and underlying tables.
L’activation du traçage des modifications ajoute une paire de colonnes masquées à la table et commence à stocker les métadonnées de traçage des modifications. Les valeurs de ces colonnes de données cachées CDC fournissent les données d’entrée des colonnes de métadonnées du flux. Les colonnes consomment une petite quantité de stockage.
Aucune métadonnée de suivi des modifications de l’objet n’est disponible pendant la période précédant la satisfaction de l’une de ces conditions.
Required access privileges¶
L’interrogation d’un flux nécessite un rôle avec au minimum les autorisations de rôle suivantes :
Objet |
Privilège |
Remarques |
|---|---|---|
Base de données |
USAGE |
|
Schéma |
USAGE |
|
Flux |
SELECT |
|
Table |
SELECT |
Les flux sur les tables uniquement. |
Vue |
SELECT |
Streams on Views seulement. |
Zone de préparation externe |
USAGE |
Les flux sur les tables de répertoire (sur les zones de préparation externes) uniquement |
Zone de préparation interne |
READ |
Les flux sur les tables de répertoire (sur les zones de préparation internes) uniquement |
Billing for streams¶
Comme décrit dans Période de conservation des données et obsolescence (dans ce chapitre), lorsqu’un flux n’est pas consommé régulièrement, Snowflake prolonge temporairement la période de conservation des données pour la table source ou les tables sous-jacentes de la vue source. Si la période de conservation des données de la table est inférieure à 14 jours, alors en arrière-plan, elle est étendue à la valeur la plus petite liée au décalage transactionnel du flux ou à 14 jours (si la période de conservation des données pour la table est inférieure à 14 jours), quelle que soit l” édition Snowflake de votre compte.
L’étendue de la période de conservation des données nécessite un stockage supplémentaire qui se reflétera dans vos frais de stockage mensuels.
Le coût principal associé à un flux est le temps de traitement utilisé par un entrepôt virtuel pour interroger le flux. Ces frais apparaissent sur votre facture en tant que crédits Snowflake familiers.
Limitations¶
Les limitations suivantes s’appliquent pour les flux :
Vous ne pouvez pas utiliser de flux standard ou de flux append-only sur les tables Apache Iceberg™ qui utilisent un catalogue externe. (Les flux à insertion uniquement sont pris en charge.)
Vous ne pouvez pas suivre les modifications d’une vue avec des clauses GROUP BY.
Après avoir ajouté ou modifié une colonne sur NOT NULL, les requêtes sur les flux peuvent échouer si le flux génère des lignes avec des valeurs NULL non autorisées. Cela se produit si le schéma du flux applique la contrainte NOT NULL, qui ne correspond pas aux données historiques renvoyées par le flux.
Lorsqu”une tâche est déclenchée par Streams on Views, toute modification apportée aux tables référencées par la requête Streams on Views déclenche également cette tâche, quels que soient les jointures, les agrégations ou les filtres de la requête.
Les flux ne sont pas pris en charge sur les tables externes partitionnées ou les tables Apache Iceberg™ partitionnées gérées par un catalogue externe.