Transactions¶
Une transaction est une séquence d’instructions SQL qui sont validées ou annulées en tant qu’unité.
Introduction¶
Qu’est-ce qu’une transaction ?¶
Une transaction est une séquence d’instructions SQL qui sont traitées comme une unité atomique. Toutes les instructions de la transaction sont soit appliquées (validées), soit annulées (rétablies) ensemble. Les transactions de Snowflake garantissent les propriétés ACID.
Une transaction peut inclure à la fois des lectures et des écritures.
Les transactions suivent ces règles :
Les transactions ne sont jamais imbriquées. Par exemple, vous ne pouvez pas créer une transaction externe qui annulerait une transaction interne qui a été validée, ni créer une transaction externe qui validerait une transaction interne qui a été rétablie.
Une transaction est associée à une seule session. Plusieurs sessions ne peuvent pas partager la même transaction. Pour plus d’informations sur le traitement des transactions dont les threads se chevauchent dans la même session, voir Transactions et multithread.
Terminologie¶
Dans cette rubrique :
Le terme DDL comprend des instructions CTAS (CREATE TABLE AS SELECT) ainsi que d’autres instructions DDL qui définissent les objets de base de données.
Le terme DML fait référence aux instructions INSERT, UPDATE, DELETE, MERGE et TRUNCATE.
Le terme instruction de requête fait référence aux instructions SELECT et CALL.
Bien qu’une instruction CALL (qui appelle une procédure stockée) soit une instruction unique, la procédure stockée qu’elle appelle peut contenir plusieurs instructions. Il existe des règles spéciales pour les procédures et les transactions stockées.
Transactions explicites¶
Une transaction peut être démarrée explicitement en exécutant une instruction BEGIN. Snowflake prend en charge les synonymes BEGINWORK et BEGINTRANSACTION. Snowflake recommande d’utiliser BEGIN TRANSACTION.
Une transaction peut être terminée explicitement en exécutant COMMIT ou ROLLBACK. Snowflake prend en charge le synonyme COMMIT WORK pour COMMIT et le synonyme ROLLBACK WORK pour ROLLBACK.
En général, si une transaction est déjà active, les instructions BEGIN TRANSACTION sont ignorées. Les utilisateurs devraient toutefois éviter les instructions BEGIN TRANSACTION supplémentaires, car les instructions supplémentaires rendent beaucoup plus difficile le couplage des instructions COMMIT (ou ROLLBACK) par les lecteurs humains avec l’instruction BEGIN TRANSACTION correspondante.
Une exception à cette règle concerne un appel de procédure stocké imbriqué. Pour plus de détails, voir Transactions scopées.
Note
Les transactions explicites ne doivent contenir que des instructions DML et des instructions d’interrogation. Les instructions DDL valident implicitement des transactions actives (pour plus de détails, voir la section DDL).
Transactions implicites¶
Les transactions peuvent être commencées et terminées implicitement, sans TRANSACTION BEGIN ou COMMIT/ROLLBACK explicite. Les transactions implicites se comportent de la même manière que les transactions explicites. Toutefois, les règles qui déterminent le début de la transaction implicite sont différentes des règles qui déterminent le début d’une transaction explicite.
Les règles d’arrêt et de démarrage dépendent de la nature de l’instruction : instruction DDL, instruction DML ou instruction de requête. Si l’instruction est une instruction DML ou d’interrogation, les règles dépendent de l’activation ou non de AUTOCOMMIT.
DDL¶
Chaque instruction DDL s’exécute comme une transaction distincte.
Si une instruction DDL est exécutée alors qu’une transaction est active, l’instruction DDL :
Valide implicitement la transaction active.
Exécute l’instruction DDL comme une transaction distincte.
Comme une instruction DDL est une transaction propre, vous ne pouvez pas annuler une instruction DDL ; la transaction contenant le DDL est terminée avant que vous puissiez exécuter le ROLLBACK explicite.
Si une instruction DDL est immédiatement suivie d’une instruction DML, cette instruction DML lance implicitement une nouvelle transaction.
AUTOCOMMIT¶
Snowflake prend en charge un paramètre AUTOCOMMIT . Le paramètre par défaut pour AUTOCOMMIT est TRUE (activé).
Alors que AUTOCOMMIT est activé :
Chaque instruction en dehors d’une transaction explicite est traitée comme si elle se trouvait à l’intérieur de sa propre transaction implicite à instruction unique. En d’autres termes, cette instruction est automatiquement validée si elle réussit, et automatiquement annulée si elle échoue.
Les instructions à l’intérieur d’une transaction explicite ne sont pas affectées par AUTOCOMMIT. Par exemple, les instructions à l’intérieur d’une TRANSACTION BEGIN … ROLLBACK explicite sont annulées même si AUTOCOMMIT est TRUE.
Alors que AUTOCOMMIT est désactivé :
Une TRANSACTION BEGIN implicite est exécutée à :
Première instruction DML à la fin d’une transaction. Cela est vrai indépendamment de ce qui a mis fin à la transaction précédente (par exemple, instruction DDL, ou un COMMIT ou ROLLBACK explicite).
Première instruction DML après la désactivation d’AUTOCOMMIT.
Un COMMIT implicite est exécuté à la suite (si une transaction est déjà active) :
Lorsqu’une instruction DDL est exécutée.
Lorsqu’une instruction
ALTER SESSION SET AUTOCOMMITest exécutée, que la nouvelle valeur soit TRUE ou FALSE, et que la nouvelle valeur est différente de la valeur précédente ou pas. Par exemple, même si vous réglez AUTOCOMMIT sur FALSE alors qu’elle est déjà FALSE, un COMMIT implicite est exécuté.
Un ROLLBACK implicite est exécuté à la suite (si une transaction est déjà active) :
À la fin d’une session.
À la fin d’une procédure stockée.
Que la transaction active de la procédure stockée ait été lancée explicitement ou implicitement, Snowflake annule la transaction active et émet un message d’erreur.
Prudence
Ne pas modifier les paramètres AUTOCOMMIT à l’intérieur d’une procédure stockée. Vous obtiendrez un message d’erreur.
Mélanger les débuts et les fins implicites et explicites d’une transaction¶
Pour éviter d’écrire un code confus, vous devez éviter de mélanger des débuts et des fins implicites et explicites dans la même transaction. Les éléments suivants sont légaux, mais à éviter :
Une transaction commencée implicitement peut se terminer par un COMMIT ou un ROLLBACK explicite.
Une transaction commencée explicitement peut se terminer par un COMMIT ou un ROLLBACK implicite.
Échec des instructions dans le cadre d’une transaction¶
Bien qu’une transaction soit validée ou annulée en tant qu’unité, cela ne veut pas dire qu’elle réussit ou échoue en tant qu’unité. Si une instruction échoue dans le cadre d’une transaction, vous pouvez toujours valider la transaction, plutôt que de l’annuler.
Lorsqu’une instruction DML ou CALL dans une transaction échoue, les modifications apportées par cette instruction échouée sont annulées. Toutefois, la transaction reste active jusqu’à ce que la transaction entière soit validée ou annulée. Si la transaction est validée, les modifications apportées par les instructions réussies sont appliquées.
Prenons par exemple le code suivant, qui insère deux valeurs valides et une valeur non valide dans une table :
Si les instructions après l’échec de l’instruction INSERT sont exécutées alors la sortie de l’instruction SELECT finale comprend les lignes avec les valeurs entières 1 et 2, même si l’une des autres instructions de la transaction a échoué.
Note
Les instructions après l’échec de l’instruction INSERT peuvent ou non être exécutées. Le comportement dépend de la manière dont les instructions sont exécutées et de la manière dont les erreurs sont gérées.
Par exemple :
Si ces instructions se trouvent à l’intérieur d’une procédure stockée écrite dans le langage Exécution de scripts Snowflake, l’instruction INSERT qui échoue déclenche une exception.
Si l’exception n’est pas traitée, la procédure stockée ne se termine jamais, et l’instruction COMMIT n’est jamais exécutée, de sorte que la transaction ouverte est implicitement annulée. Dans ce cas, la table ne contient pas les valeurs
1ou2.Si la procédure stockée gère l’exception et valide les instructions avant l’instruction INSERT qui a échoué, mais n’exécute pas les instructions après l’instruction INSERT qui a échoué, seule la ligne avec la valeur
1est stockée dans la table.
Si ces instructions ne se trouvent pas à l’intérieur d’une procédure stockée, le comportement dépend de la façon dont les instructions sont exécutées. Par exemple :
Si les instructions sont exécutées par Snowsight, l’exécution s’arrête à la première erreur.
Si les instructions sont exécutées par SnowSQL en utilisant l’option
-f(nom de fichier), alors l’exécution ne s’arrête pas à la première erreur, et les instructions après l’erreur sont exécutées.
Transactions et multithread¶
Bien que plusieurs sessions ne puissent pas partager la même transaction, plusieurs threads utilisant une seule connexion partagent la même session et partagent donc la même transaction. Ce comportement peut entraîner des résultats inattendus, tels qu’un thread annulant le travail effectué dans un autre thread.
Cette situation peut se produire lorsqu’une application client utilisant un pilote Snowflake (tel que le pilote JDBC Snowflake) ou un connecteur (tel que Snowflake Connector pour Python) est multithread. Si deux threads ou plus partagent la même connexion, ces threads partagent également la transaction actuelle dans cette connexion. Un BEGIN TRANSACTION, COMMIT ou ROLLBACK par un thread affecte tous les threads utilisant cette connexion partagée. Si les threads s’exécutent de manière asynchrone, les résultats peuvent être imprévisibles.
De la même façon, la modification du paramètre AUTOCOMMIT dans un thread affecte le paramètre AUTOCOMMIT dans tous les autres threads qui utilisent la même connexion.
Snowflake recommande que les programmes client multithread effectuent au moins l’une des opérations suivantes :
Utiliser une connexion distincte pour chaque thread.
Notez que même avec des connexions séparées, votre code peut toujours atteindre des conditions de course qui génèrent une sortie imprévisible ; par exemple, un thread peut supprimer des données avant qu’un autre thread tente de les mettre à jour.
Exécuter les threads de manière synchrone plutôt qu’asynchrone, pour contrôler l’ordre dans lequel les étapes sont effectuées.
Transactions et procédures stockées¶
En général, les règles décrites dans les sections précédentes s’appliquent également aux procédures stockées. Cette section fournit des informations supplémentaires spécifiques aux procédures stockées.
Une transaction peut être à l’intérieur d’une procédure stockée, ou une procédure stockée peut être à l’intérieur d’une transaction ; cependant, une transaction ne peut pas être en partie à l’intérieur et en partie à l’extérieur d’une procédure stockée, ni démarrée dans une procédure stockée et terminée dans une autre procédure stockée.
Par exemple :
Vous ne pouvez pas commencer une transaction avant d’appeler la procédure stockée, puis terminer la transaction à l’intérieur de la procédure stockée. Si vous essayez de faire cela, Snowflake signale une erreur similaire à ce qui suit :
Vous ne pouvez pas commencer une transaction à l’intérieur de la procédure stockée, puis terminer la transaction au retour de la procédure. Si une transaction est lancée à l’intérieur d’une procédure stockée et qu’elle est toujours active lorsque la procédure stockée se termine, une erreur se produit et la transaction est annulée.
Ces règles s’appliquent également aux procédures stockées imbriquées. Si la procédure A appelle la procédure B, la procédure B ne peut pas terminer une transaction qui a été démarrée dans la procédure A ou inversement. Chaque BEGIN TRANSACTION dans A doit avoir un COMMIT correspondant (ou ROLLBACK) dans A, et chaque BEGIN TRANSACTION dans B doit avoir un COMMIT correspondant (ou ROLLBACK) dans B.
Si une procédure stockée contient une transaction explicite, cette transaction ne peut contenir qu’une partie ou la totalité du corps de la procédure stockée. Par exemple, dans la procédure stockée suivante, seules certaines instructions font partie d’une transaction explicite. (Cet exemple, et plusieurs exemples ultérieurs, utilisent un pseudo-code pour plus de simplicité).
Transactions ne se chevauchant pas¶
Les sections ci-dessous décrivent :
L’utilisation d’une procédure stockée à l’intérieur d’une transaction.
L’utilisation d’une transaction dans le cadre d’une procédure stockée.
Utilisation d’une procédure stockée dans une transaction¶
Dans le cas le plus simple, une procédure stockée est considérée comme faisant partie d’une transaction si les conditions suivantes sont remplies :
Un BEGINTRANSACTION est exécuté avant que la procédure stockée ne soit appelée.
Un COMMIT (ou ROLLBACK) correspondant est exécuté après la fin de la procédure stockée.
Le corps de la procédure stockée ne contient pas de BEGINTRANSACTION explicite ou implicite ou COMMIT (ou ROLLBACK).
La procédure stockée à l’intérieur de la transaction suit les règles de la transaction de clôture :
Si la transaction est validée, alors toutes les instructions à l’intérieur de la procédure sont validées.
Si la transaction est annulée, toutes les instructions de la procédure sont annulées.
Le pseudo-code suivant montre une procédure stockée appelée entièrement à l’intérieur d’une transaction explicite :
Cela équivaut à exécuter la séquence d’instructions suivante :
Utilisation d’une transaction dans une procédure stockée¶
Vous pouvez exécuter zéro, une ou plusieurs transactions à l’intérieur d’une procédure stockée. Le pseudo-code suivant montre un exemple de deux transactions dans une procédure stockée :
La procédure stockée pourrait être appelée comme indiqué ici :
Cela équivaut à exécuter la séquence suivante :
Dans ce code, quatre transactions distinctes sont exécutées. Chaque transaction soit commence et se termine en dehors de la procédure, soit commence et se termine à l’intérieur de la procédure. Aucune transaction n’est fractionnée à travers une procédure (en partie à l’intérieur et en partie à l’extérieur de la procédure stockée). Aucune transaction n’est imbriquée dans une autre transaction.
Transactions scopées¶
Une procédure stockée qui contient une transaction peut être appelée à partir d’une autre transaction. Par exemple, une transaction à l’intérieur d’une procédure stockée peut inclure un appel vers une autre procédure stockée qui contient une transaction.
Snowflake ne traite pas la transaction interne comme étant imbriquée ; au contraire, la transaction interne est une transaction séparée. Snowflake les appelle « transactions scopées autonomes » (ou simplement « transactions scopées »).
Le point de départ et le point d’arrivée de chaque transaction scopée déterminent les instructions qui sont incluses dans la transaction. Le début et la fin peuvent être explicites ou implicites. Chaque instruction SQL fait partie d’une seule transaction. Un ROLLBACK ou un COMMIT délimitant ne « défait » pas un COMMIT ou un ROLLBACK délimité.
Note
Les termes « interne » et « externe » sont couramment utilisés pour décrire des opérations imbriquées, telles que les appels de procédures stockées imbriquées. Cependant, les transactions dans Snowflake ne sont pas vraiment « imbriquées » ; par conséquent, pour réduire la confusion lors de la référence aux transactions, ce document utilise fréquemment les termes « délimité » et « délimitant » plutôt que « interne » ou « externe ».
Le diagramme ci-dessous montre deux procédures stockées et deux transactions scopées. Dans cet exemple, chaque procédure stockée contient sa propre transaction indépendante. La première procédure stockée appelle la deuxième procédure stockée, de sorte que les procédures se chevauchent dans le temps, mais pas dans leur contenu. Toutes les instructions qui se trouvent dans la case grisée concernent une transaction ; toutes les autres instructions concernent une autre transaction.
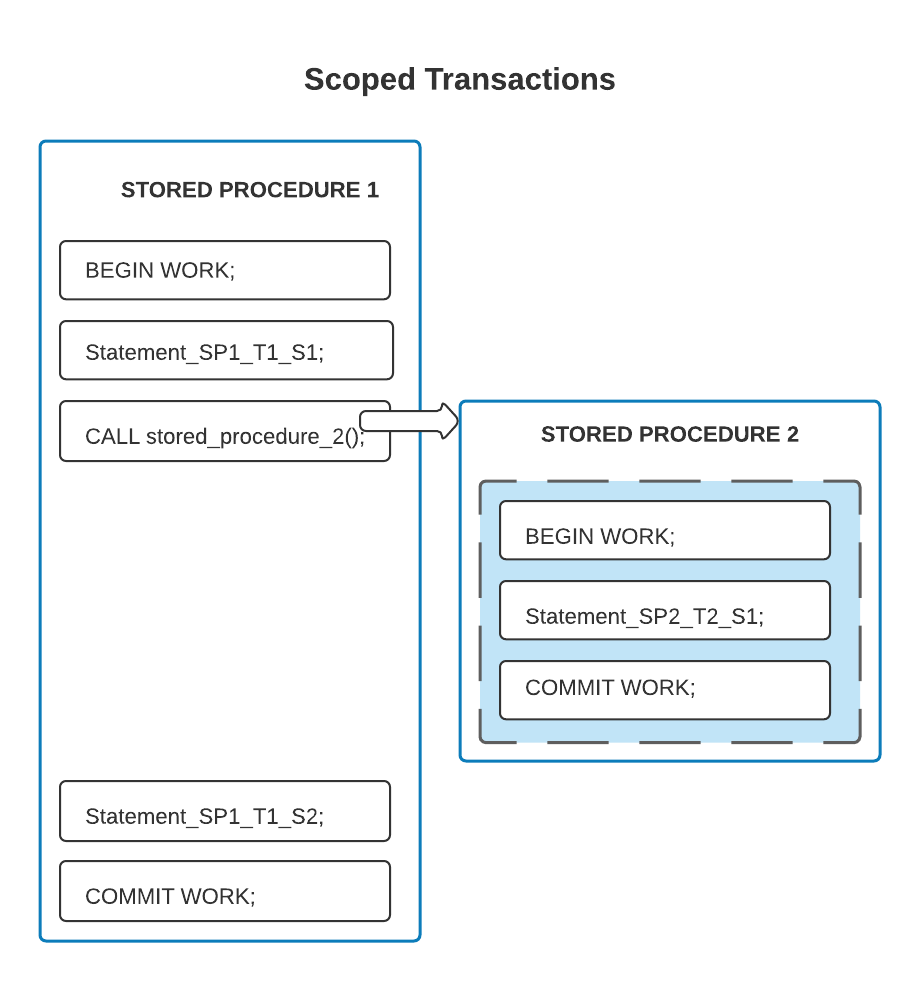
Dans l’exemple suivant, les limites de la transaction sont différentes de celles de la procédure stockée ; la transaction qui commence dans la procédure stockée délimitante comprend certaines des instructions de la procédure stockée englobée, mais pas toutes.
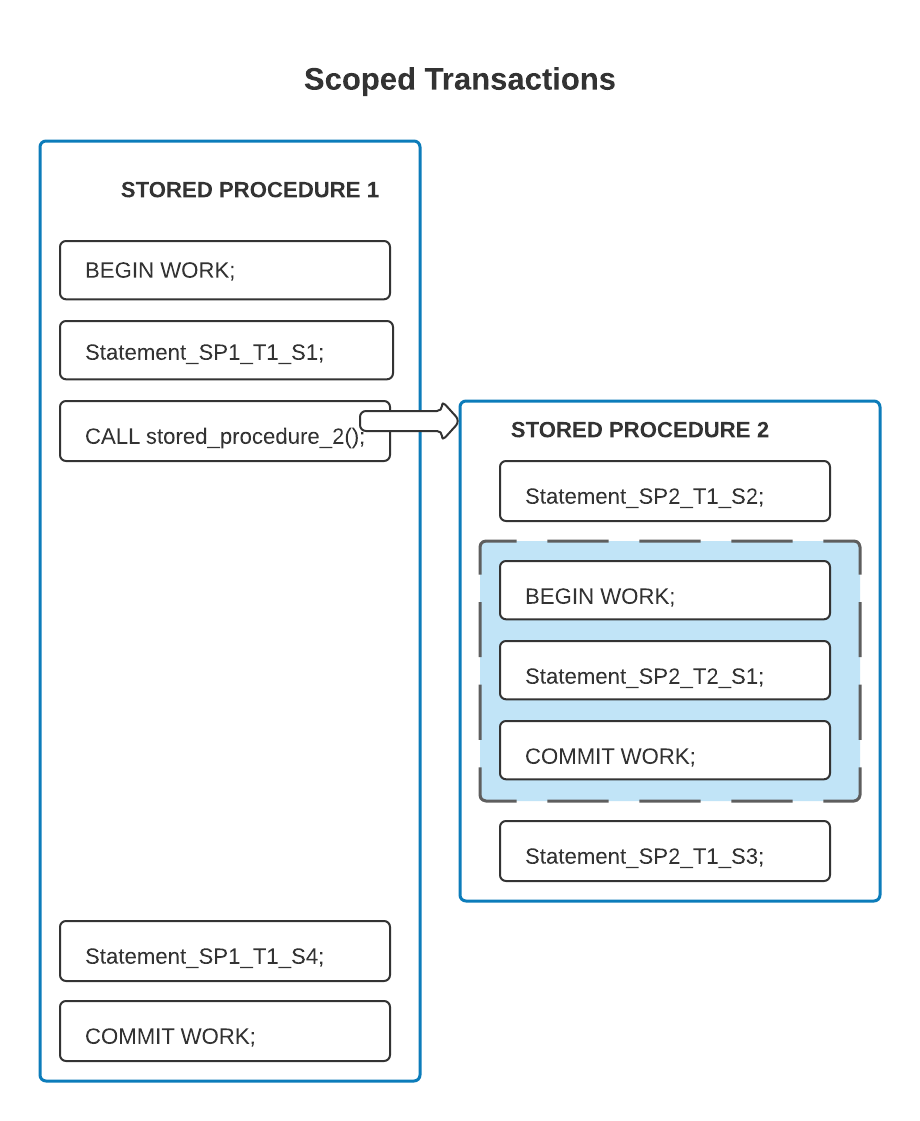
Dans le code ci-dessus, la deuxième procédure stockée contient certaines instructions (SP2_T1_S2 et SP2_T1_S3) qui se trouvent dans le scope de la première transaction. Seule l’instruction SP2_T2_S1, à l’intérieur de la case grisée, est dans le scope de la deuxième transaction.
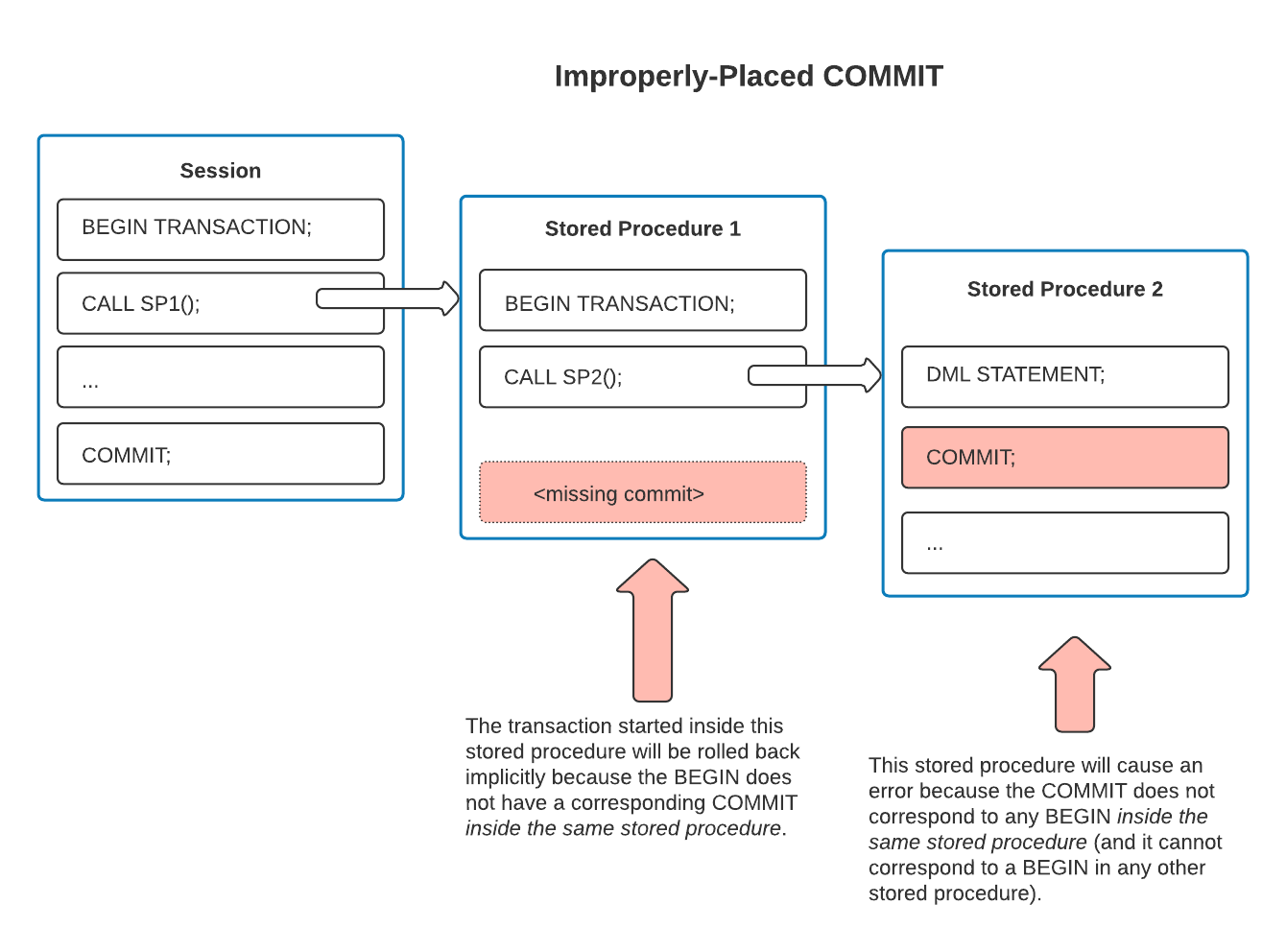
L’exemple suivant montre les problèmes qui se posent si une transaction ne commence et ne se termine pas dans le cadre de la même procédure stockée. L’exemple contient le même nombre d’instructions COMMIT que d’instructions BEGIN. Cependant, les instructions BEGIN et COMMIT ne sont pas couplées correctement, de sorte que cet exemple contient deux erreurs :
La procédure stockée délimitante démarre une transaction scopée, mais ne la termine pas explicitement. Par conséquent, cette transaction scopée cause une erreur à la fin de cette procédure stockée, et la transaction activée est implicitement annulée.
La deuxième procédure stockée contient un COMMIT, mais il n’y a pas de BEGIN correspondant dans cette procédure stockée. Ce COMMIT ne valide pas la transaction ouverte commencée dans la première procédure stockée. Au lieu de cela, l’appariement incorrect de COMMIT provoque une erreur.
L’exemple suivant montre trois transactions scopées qui se chevauchent dans le temps. Dans cet exemple, la procédure stockée p1() appelle une autre procédure stockée p2() à l’intérieur d’une transaction, et p2() contient sa propre transaction, de sorte que la transaction lancée dans p2() s’exécute également indépendamment. (Cet exemple utilise un pseudo-code).
Dans ces trois transactions scopées :
La transaction qui se trouve en dehors de toute procédure stockée contient les instructions
AetE.La transaction de la procédure stockée
p1()contient les instructionsBetDLa transaction dans
p2()contient l’instructionC.
Les règles relatives aux transactions scopées s’appliquent également aux appels de procédure stockée récursifs. Un appel récursif est juste un type spécifique d’appel imbriqué, et suit les mêmes règles de transaction qu’un appel imbriqué.
Prudence
Le chevauchement de transactions scopées peut entraîner un blocage si elles manipulent le même objet de base de données (par exemple, une table). Les transactions scopées ne doivent être utilisées qu’en cas de nécessité.
Validations implicites de transactions dans des procédures stockées¶
Certaines commandes, dont la plupart des instructions DDL, valident implicitement toute transaction active. Si une procédure stockée externe ouvre une transaction et qu’une procédure stockée interne exécute une telle commande, la commande renvoie le message d’erreur suivant :
Par exemple, le code suivant échoue, parce que l’instruction DROP TAG de la procédure interne tente de valider implicitement la transaction qui a été lancée dans la procédure externe :
Pour éviter cette erreur, n’exécutez pas d’instructions DDL (ou d’autres commandes qui valident implicitement des transactions) à l’intérieur d’une procédure stockée qui peut être appelée à partir d’une transaction active lancée dans un autre scope.
ROLLBACK implicite pour les transactions à la fin des procédures stockées¶
Lorsque AUTOCOMMIT est désactivé, soyez particulièrement prudent en combinant les transactions implicites et les procédures stockées. Si vous laissez accidentellement une transaction active à la fin d’une procédure stockée, la transaction est annulée.
Par exemple, l’exemple de pseudo-code suivant provoque un ROLLBACK implicite à la fin de la procédure stockée :
Dans cet exemple, la commande pour définir AUTOCOMMIT valide toute transaction active. Une nouvelle transaction n’est pas lancée immédiatement. La procédure stockée contient une instruction DML , qui lance implicitement une nouvelle transaction. Ce BEGINTRANSACTION implicite n’a pas de COMMIT ou ROLLBACK correspondant dans la procédure stockée. Comme il y a une transaction active à la fin de la procédure stockée, cette transaction active est implicitement annulée.
Si vous souhaitez exécuter l’ensemble de la procédure stockée en une seule transaction, lancez la transaction avant d’appeler la procédure stockée, et validez la transaction après l’appel :
Dans ce cas, les BEGIN et COMMIT sont correctement couplés, et le code s’exécute sans erreur.
Comme alternative, mettez BEGIN TRANSACTION et COMMIT dans la procédure stockée, comme indiqué dans l’exemple de pseudo-code suivant.
Blocs BEGIN/COMMIT incorrectement associés dans les transactions scopées¶
Si vous ne couplez pas correctement vos blocs BEGIN/COMMIT dans une transaction scopée, Snowflake signale une erreur. Cette erreur peut avoir d’autres conséquences, comme empêcher l’achèvement d’une procédure stockée ou empêcher la validation d’une transaction de clôture. Par exemple, dans l’exemple de pseudo-code suivant, certaines instructions de la procédure stockée délimitante, ainsi que la procédure stockée englobée, sont annulées :
Dans cet exemple, la seule valeur qui est insérée est osp1_alpha. Aucune des autres valeurs n’est insérée car un COMMIT n’est pas correctement associé à un BEGIN. L’erreur est traitée comme suit :
Lorsque la procédure
inner_sp2()se termine, Snowflake détecte que BEGIN dansinner_sp2()ne correspond pas à un COMMIT (ou ROLLBACK).Snowflake annule implicitement la transaction scopée qui a commencé en
inner_sp2().Snowflake renvoie également une erreur parce que CALL à
inner_sp2()a échoué.
Parce que le CALL à
inner_sp2()a échoué, et parce que cette instruction CALL se trouvait dansouter_sp1(), la procédure stockéeouter_sp1()elle-même échoue également et renvoie une erreur, au lieu de continuer.Parce que
outer_sp1()n’a pas fini de s’exécuter :Le s instructions INSERT des valeurs
osp1_deltaetosp1_omegane s’exécutent jamais.La transaction ouverte dans
outer_sp1()est implicitement annulée plutôt que validée, donc l’insertion de la valeurosp1_betan’est jamais validée.
Tables et transactions Apache Iceberg™¶
Les principes transactionnels Snowflake s’appliquent généralement aux tables Apache Iceberg™. Pour plus d’informations sur les transactions spécifiques aux tables Iceberg, consultez le Sujet iceberg sur les transactions.
Niveau d’isolation READ COMMITTED¶
READ COMMITTED est actuellement le seul niveau d’isolation pris en charge pour les tables. Dans le cas de l’isolation READ COMMITTED, une instruction ne voit que les données qui ont été validées avant le début de l’instruction. Elle ne voit jamais les données non validées.
Lorsqu’une instruction est exécutée dans une transaction à plusieurs instructions :
Une instruction ne voit que les données qui ont été validées avant le début de l”instruction. Deux instructions successives dans la même transaction peuvent voir des données différentes si une autre transaction est validée entre l’exécution de la première instruction et la deuxième.
Une instruction affiche les modifications apportées par les instructions précédentes exécutées dans la même transaction, même si ces modifications ne sont pas encore validées.
Cohérence de lecture entre les sessions¶
En général, Snowflake maintient la cohérence de lecture pour toutes les modifications qui se produisent dans une session donnée, comme les modifications introduites par les opérations DDL et DML. Lorsqu’un utilisateur démarre une nouvelle session, toutes les modifications qui ont été validées avant le démarrage de la session, ainsi que toutes les modifications qui sont validées au cours de la session, sont immédiatement visibles par les requêtes ultérieures dans cette session. Il s’agit d’un comportement standard qui répond aux exigences de la plupart des charges de travail.
Si vous souhaitez étendre la cohérence de lecture dans les sessions qui exécutent des requêtes de manière quasi simultanée, et que vous êtes prêt à accepter un petit délai des temps de réponse des requêtes (généralement en millisecondes), définissez le paramètre READ_CONSISTENCY_MODE sur 'GLOBAL'. En définissant ce paramètre, vous modifiez le comportement par défaut , de sorte que les requêtes lisent toutes les modifications quasi simultanées qui se produisent dans les sessions exécutées simultanément. Une autre façon de garantir ce niveau de cohérence est d’exécuter toutes les requêtes dans la même session.
Par exemple, en utilisant la valeur 'SESSION' par défaut :
La session 1 démarre.
La session 2 démarre.
La session 1 insère une ligne dans la table
t.La session 1 sélectionne les données de la table
tet voit immédiatement la nouvelle ligne.La session 2 exécute la même requête. La session 2 peut ne pas voir la nouvelle ligne.
Pour garantir que les sessions 1 et 2 obtiennent le même résultat pour la même requête dans ce scénario, suivez l’une des trois étapes suivantes, qui sont présentées dans l’ordre, de la plus recommandée à la moins recommandée :
Utilisez une seule session pour toutes les requêtes qui dépendent les unes des autres. Dans ce cas :
La session 1 démarre.
La session 1 insère une ligne dans la table
t.La session 1 sélectionne les données de la table
tet voit immédiatement la nouvelle ligne.
Démarrez la session 2 après que les modifications ont été validées dans la session 1. Dans ce cas :
La session 1 démarre.
La session 1 insère une ligne dans la table
t.La session 2 démarre.
La session 1 sélectionne les données de la table
tet voit immédiatement la nouvelle ligne.La session 2 exécute la même requête et verra la nouvelle ligne.
Utilisez la commande ALTER ACCOUNT pour définir READ_CONSISTENCY_MODE sur
'GLOBAL':Ce paramètre ne peut être défini au niveau du compte que par un utilisateur ayant le privilège ACCOUNTADMIN.
Verrouillage des ressources¶
Les opérations transactionnelles acquièrent des verrous sur une ressource, telle qu’une table, lors de la modification de cette ressource. Les verrous empêchent les autres instructions de modifier la ressource jusqu’à ce que le verrou soit supprimé.
Les directives suivantes s’appliquent dans la plupart des situations :
Les opérations COMMIT (y compris AUTOCOMMIT et COMMIT explicite) verrouillent des ressources, mais généralement de manière brève.
Les opérations CREATE TABLE, CREATE DYNAMIC TABLE, CREATE STREAM et ALTER TABLE verrouillent toutes leurs ressources sous-jacentes lorsque CHANGE_TRACKING = TRUE est défini, mais généralement seulement brièvement. Seules les opérations UPDATE et DELETE DML sont bloquées lorsqu’une table est verrouillée. Les opérations INSERT ne sont pas bloquées.
Les instructions UPDATE, DELETE et MERGE détiennent des verrous qui les empêchent généralement de s’exécuter en parallèle avec d’autres instructions UPDATE, DELETE et MERGE.
Pour les tables hybrides, les verrous sont maintenus sur des rangées individuelles. Les verrous sur les instructions UPDATE, DELETE et MERGE empêchent uniquement les instructions parallèles UPDATE, DELETE et MERGE qui opèrent sur la même ligne ou les mêmes lignes. UPDATE, DELETE et MERGE sur différentes lignes d’une même table peuvent progresser.
La plupart des instructions INSERT et COPY n’écrivent que de nouvelles partitions. Ces instructions peuvent souvent être exécutées en parallèle avec d’autres opérations INSERT et COPY, et parfois en parallèle avec une instruction UPDATE, DELETE ou MERGE.
Évitez d’exécuter les instructions INSERT et COPY en même temps que les instructions DDL sur le même objet dans des sessions différentes, car cela peut entraîner des incohérences. Lorsque des instructions INSERT ou COPY sont exécutées sur un objet dans une transaction explicite, évitez les instructions DDL sur le même objet dans des sessions différentes pendant la durée de la transaction. Par exemple, n’exécutez pas les instructions INSERT sur une table dans une session tout en exécutant simultanément une instruction DDL qui modifie le type de données d’une colonne de la table dans une autre session.
Les verrous détenus par une instruction sont supprimés lors de l’opération COMMIT ou ROLLBACK de la transaction.
Paramètres de délai d’expiration des verrous¶
Deux paramètres contrôlent le délai d’expiration des verrous : LOCK_TIMEOUT et HYBRID_TABLE_LOCK_TIMEOUT.
paramètre LOCK_TIMEOUT¶
Une instruction bloquée obtient un verrouillage sur la ressource qu’elle attendait ou expire dans l’attente que la ressource devienne disponible. Vous pouvez définir la durée (en secondes) pendant laquelle une instruction doit être bloquée en définissant le paramètre LOCK_TIMEOUT.
Par exemple, pour modifier le délai de verrouillage à 2 heures (7 200 secondes) pour la session en cours :
paramètre HYBRID_TABLE_LOCK_TIMEOUT¶
Une instruction bloquée sur une table hybride obtient un verrouillage au niveau de la ligne sur la table qu’elle attend ou expire dans l’attente que la table devienne disponible. Vous pouvez définir la durée (en secondes) pendant laquelle une instruction doit être bloquée en définissant le paramètre HYBRID_TABLE_LOCK_TIMEOUT.
Par exemple, pour modifier le délai d’expiration du verrou de la table hybride à 10 minutes (600 secondes) pour la session en cours :
Interblocages¶
Des blocages peuvent survenir lorsque des transactions simultanées sont en attente sur des ressources qui sont bloquées les unes par rapport aux autres.
Relevez les règles suivantes :
Les blocages ne peuvent pas se produire lorsque des instructions de requête de validation automatique sont exécutées simultanément. Cette condition est vraie pour les tables standard et les tables hybrides car les instructions SELECT sont toujours en lecture seule.
Les blocages ne peuvent pas se produire avec la validation automatique des opérations DML sur les tables standard, mais elles peuvent se produire avec les opérations DML de validation automatique sur les tables hybrides.
Des blocages peuvent se produire lorsque les transactions sont démarrées explicitement et que plusieurs instructions sont exécutées dans chaque transaction. Snowflake détecte les blocages et choisit l’instruction la plus récente qui fait partie du blocage en tant que victime. L’instruction est annulée, mais la transaction elle-même est laissée active et doit être validée ou annulée.
La détection des blocages peut prendre du temps.
Gestion des transactions et des verrous¶
Snowflake fournit les commandes SQL suivantes pour vous aider à surveiller et à gérer les transactions et les verrous :
Vue LOCK_WAIT_HISTORY consigne un historique détaillé des transactions relatives au verrouillage, indiquant quand des verrous spécifiques ont été demandés et acquis.
En outre, Snowflake fournit les fonctions contextuelles suivantes pour obtenir des informations sur les transactions d’une session :
Vous pouvez appeler la fonction suivante pour annuler une transaction : SYSTEM$ABORT_TRANSACTION.
Annulation de transactions¶
Si une transaction est en cours d’exécution dans une session et que la session se déconnecte brusquement, empêchant la validation ou l’annulation de la transaction, la transaction est laissée dans un état détaché, y compris tout verrouillage que la transaction contient sur les ressources. Si cela se produit, vous devrez peut-être annuler la transaction.
Pour interrompre une transaction en cours, l’utilisateur qui a lancé la transaction ou un administrateur de compte peut appeler la fonction système, SYSTEM$ABORT_TRANSACTION.
Si la transaction n’est pas interrompue par l’utilisateur :
Et elle empêche une autre transaction d’acquérir un verrou sur la même table et elle est inactive pendant 5 minutes, elle est automatiquement interrompue et annulée.
Et elle n’empêche pas d’autres transactions de modifier la même table et elle est plus ancienne de 4 heures, elle est automatiquement interrompue et annulée.
Et elle lit ou écrit sur des tables hybrides, et est inactive pendant 5 minutes, elle est automatiquement interrompue et annulée, qu’elle empêche ou non d’autres transactions de modifier la même table.
Pour permettre à une erreur d’instruction dans une transaction d’annuler une transaction, définissez le paramètre TRANSACTION_ABORT_ON_ERROR au niveau de la session ou du compte.
Analyse des transactions bloquées avec la vue LOCK_WAIT_HISTORY¶
L” Vue LOCK_WAIT_HISTORY renvoie les détails de la transaction qui peuvent être utiles pour analyser les transactions bloquées. Chaque ligne du résultat comprend les détails d’une transaction qui attend un verrou et les détails des transactions qui détiennent ce verrou ou qui attendent ce verrou.
Par exemple, voir le scénario ci-dessous :
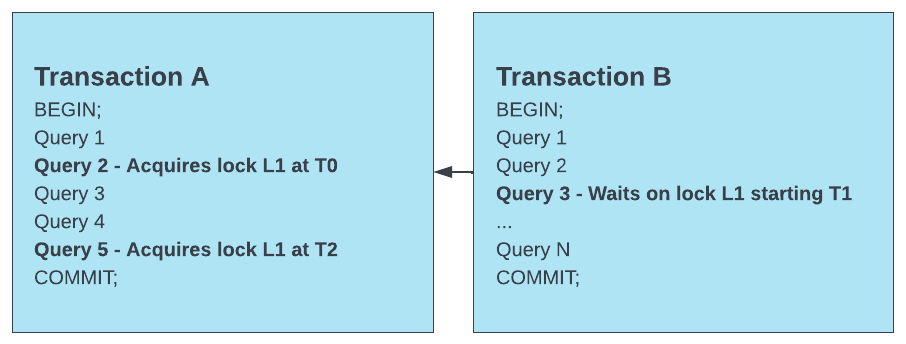
Dans ce scénario, les données suivantes sont renvoyées :
La transaction B est la transaction qui attend un verrou.
La transaction B a demandé le verrouillage à l’horodatage T1.
La transaction A est la transaction qui détient le verrou.
La requête 2 de la transaction A est la requête de blocage.
La requête 2 est la requête de blocage, car il s’agit de la première instruction de la transaction A (la transaction qui détient le verrou) sur laquelle la transaction B (la transaction qui attend le verrou) a commencé à attendre.
Cependant, notez qu’une requête ultérieure dans la transaction A (requête 5) a également acquis le verrou. Il est possible que des exécutions concurrentes ultérieures de ces transactions entraînent le blocage de la transaction B sur une autre requête qui acquiert le verrou dans la transaction A. Par conséquent, vous devez examiner toutes les requêtes dans la première transaction de blocage.
Voir aussi Visibilité des transactions et des verrous pour les tables hybrides.
Examen d’une instruction longue durée¶
Interroger la Vue QUERY_HISTORY Account Usage pour les transactions qui ont attendu des verrouillages au cours des 24 dernières heures :
Examinez les résultats de la requête et notez les IDs des requêtes avec des valeurs TRANSACTION_BLOCKED_TIME élevées.
Pour trouver les transactions de blocage pour les requêtes identifiées à l’étape précédente, interrogez la vue LOCK_WAIT_HISTORY pour les lignes avec ces IDs de requêtes :
Il peut y avoir plusieurs requêtes dans la colonne
blocker_queriesdans les résultats. Notez letransaction_idde chaque requête de blocage dans la sortie.Interroger la vue QUERY_HISTORY pour chaque transaction dans la sortie
blocker_queries:Analyser les résultats de la requête. Si une instruction de la transaction était une instruction DML et qu’elle opérait sur la ressource verrouillée, il se peut qu’elle ait acquis le verrou à un moment donné au cours de la transaction.
Surveillance des transactions et des verrous¶
Vous pouvez utiliser la commande SHOW TRANSACTIONS pour renvoyer une liste des transactions exécutées par l’utilisateur actuel (dans toutes les sessions de cet utilisateur) ou par tous les utilisateurs dans toutes les sessions du compte. L’exemple suivant concerne les sessions de l’utilisateur actuel.
Chaque transaction Snowflake se voit attribuer un ID de transaction unique. La valeur id est un entier signé de 64 bits (de long). La plage de valeurs va de -9 223 372 036 854 775 808 (-2 63) à 9 223 372 036 854 775 807 (2 63 - 1).
Vous pouvez également utiliser la fonction CURRENT_TRANSACTION pour renvoyer l’ID de la transaction en cours d’exécution dans la session.
Si vous connaissez l’ID de transaction que vous souhaitez surveiller, vous pouvez utiliser la commande DESCRIBE TRANSACTION permettant de renvoyer des détails sur la transaction, alors qu’elle est toujours en cours d’exécution ou après sa validation ou son annulation. Par exemple :
Visibilité des transactions et des verrous pour les tables hybrides¶
Lorsque vous examinez la sortie des commandes et des vues pour les transactions qui accèdent aux tables hybrides ou aux verrous sur les lignes des tables hybrides, notez le comportement suivant :
Les transactions ne sont répertoriées que si elles bloquent d’autres transactions ou si elles sont bloquées.
Gardez à l’esprit que les transactions qui accèdent aux tables hybrides détiennent des verrous au niveau des lignes (type
ROW). Si deux transactions accèdent à des lignes différentes dans la même table, elles ne se bloquent pas mutuellement.Les transactions ne sont répertoriées que si une transaction bloquée a été bloquée pendant plus de 5 secondes.
Lorsqu’une transaction n’est plus bloquée, elle peut toujours apparaître dans la sortie, mais pendant 15 secondes maximum.
De même, dans la sortie SHOW LOCKS, les règles suivantes s’appliquent :
Un verrou n’est répertorié que si une transaction détient le verrou et que l’autre transaction est bloquée sur ce verrou particulier.
Dans la colonne
type, les verrous de table hybrides montrentROW.La colonne
resourceaffiche toujours l’ID de la transaction bloquante. (La transaction bloquée est bloquée par la transaction avec cet ID.)Dans de nombreux cas, les requêtes sur les tables hybrides ne génèrent pas d’IDs de requête. Voir Notes sur l’utilisation.
Par exemple :
Dans Vue LOCK_WAIT_HISTORY, la sotie se comporte comme suit :
Les colonnes
requested_atetacquired_atdéfinissent le moment où les verrous au niveau des lignes ont été demandés et acquis, sous réserve des règles générales de reporting de l’activité de transaction avec des tables hybrides.Les colonnes
lock_typeetobject_namemontrent la valeurRow.Les colonnes
schema_idetschema_namesont toujours vides (0et NULL, respectivement).La colonne
object_idaffiche toujours l’ID de l’objet bloquant.La colonne
blocker_queriesest une table JSON avec exactement un élément, qui montre la transaction bloquante.Même si plusieurs transactions sont bloquées sur la même ligne, elles sont affichées sous forme de plusieurs lignes dans la sortie.
Par exemple :
Meilleures pratiques¶
Une transaction doit contenir des instructions qui sont liées et qui doivent réussir ou échouer ensemble, par exemple, le retrait d’argent d’un compte et le dépôt de ce même argent sur un autre compte. En cas d’annulation, le payeur ou le bénéficiaire se retrouve avec l’argent ; l’argent ne « disparaît » jamais (il est retiré d’un compte mais n’est jamais déposé sur l’autre compte).
En général, une transaction ne doit contenir que des instructions connexes. Rendre une instruction moins granulaire signifie que lorsqu’une transaction est annulée, elle peut annuler un travail utile qui n’avait pas besoin d’être annulé.
Des transactions plus volumineuses peuvent améliorer les performances dans certains cas pour les tables standard, mais généralement pas pour les tables hybrides.
Bien que le point précédent ait souligné l’importance de ne regrouper que les instructions qui doivent réellement être validées ou annulées en tant que groupe, des transactions plus importantes peuvent parfois être utiles. Dans Snowflake, comme dans la plupart des bases de données, la gestion des transactions consomme des ressources. Par exemple, l’insertion de 10 lignes dans une transaction est généralement plus rapide et moins coûteuse que l’insertion d’une ligne dans chacune des 10 transactions séparées. La combinaison de plusieurs instructions en une seule opération peut améliorer les performances.
Des transactions trop importantes peuvent réduire le parallélisme ou accroître les blocages. Si vous décidez de regrouper des instructions non liées pour améliorer les performances (comme décrit au point précédent), gardez à l’esprit qu’une transaction peut acquérir des verrous sur les ressources, ce qui peut retarder d’autres requêtes ou entraîner des blocages.
Pour les tables hybrides :
Les instructions AUTOCOMMIT DML sont en général beaucoup plus rapides que les instructions non AUTOCOMMIT DML.
Les instructions AUTOCOMMIT DML relativement petites s’exécutent beaucoup plus rapidement que les instructions non AUTOCOMMIT DML. Les instructions DML qui s’exécutent en moins de 5 secondes ou n’accèdent pas à plus de 1 MB de données bénéficient d’un mode rapide qui n’est pas disponible pour les instructions DML plus longues ou plus volumineuses.
Snowflake recommande de garder AUTOCOMMIT activé et d’utiliser autant que possible des transactions explicites. L’utilisation de transactions explicites permet aux lecteurs humains de voir plus facilement où commencent et où finissent les transactions. Ceci, combiné avec AUTOCOMMIT, rend votre code moins susceptible de subir des annulations involontaires, par exemple à la fin d’une procédure stockée.
Évitez de modifier AUTOCOMMIT simplement pour lancer implicitement une nouvelle transaction. Utilisez plutôt BEGIN TRANSACTION pour rendre plus évident le point de départ d’une nouvelle transaction.
Évitez d’exécuter plusieurs instructions BEGIN TRANSACTION à la suite. Les instructions BEGIN TRANSACTION supplémentaires rendent plus difficile de voir où une transaction commence réellement, et rendent plus difficile le couplage des commandes COMMIT/ROLLBACK avec les commandes BEGIN TRANSACTION correspondantes.
Exemples¶
Exemple simple de transaction scopée et de procédure stockée¶
Voici un exemple simple de transactions scopées. La procédure stockée contient une transaction qui insère une ligne avec la valeur 12 et qui s’annule ensuite. La transaction extérieure est validée. La sortie montre que toutes les lignes du champ d’application de la transaction externe sont conservées, tandis que la ligne du champ d’application de la transaction interne n’est pas conservée.
Notez qu’étant donné que seule une partie de la procédure stockée se trouve à l’intérieur de sa propre transaction, les valeurs insérées par les instructions INSERT qui sont dans la procédure stockée, mais en dehors de la transaction de la procédure stockée, sont conservées.
Créer deux tables :
Créez la procédure stockée :
Appelez la procédure stockée :
Les résultats devraient comprendre 00, 11, 13 et 09. La ligne avec ID = 12 ne doit pas être incluse. Cette ligne se trouvait dans le champ d’application de la transaction délimitée, qui a été annulée. Toutes les autres lignes étaient dans le champ d’application de la transaction extérieure, et ont été validées. Notez en particulier que les lignes avec IDs 11 et 13 étaient à l’intérieur de la procédure stockée, mais en dehors de la transaction la plus interne ; elles sont dans le champ de la transaction délimitante, et ont été validées avec celle-ci.
Consignation des informations indépendamment du succès d’une transaction¶
Voici un exemple simple et pratique de la manière d’utiliser une transaction scopée. Dans cet exemple, une transaction enregistre certaines informations ; ces informations enregistrées sont conservées, que la transaction elle-même réussisse ou échoue. Cette technique peut être utilisée pour suivre toutes les tentatives d’action, que chacune ait réussi ou non.
Créer deux tables :
Créez la procédure stockée :
Appelez la procédure stockée :
Le tableau des données est vide car la transaction a été annulée :
Toutefois, la table de journalisation n’est pas vide ; l’insertion dans la table de journalisation a été effectuée dans une transaction distincte de l’insertion dans data_table.
Exemples de transactions scopées et de procédures stockées¶
Les quelques exemples suivants utilisent les tables et les procédures stockées présentées ci-dessous. En transmettant les paramètres appropriés, l’appelant peut contrôler où les instructions BEGIN TRANSACTION, COMMIT et ROLLBACK sont exécutées dans les procédures stockées.
Créer les tables :
Cette procédure est la procédure stockée délimitante et, selon les paramètres qui lui sont transmis, elle peut créer une transaction délimitante (de clôture).
Cette procédure est la procédure interne stockée et, selon les paramètres qui lui sont transmis, elle peut créer une transaction délimitée.
Valider le niveau intermédiaire de trois niveaux¶
Cet exemple contient 3 transactions. Cet exemple valide le niveau « intermédiaire » (la transaction délimitée par la transaction la plus extérieure et délimitant la transaction la plus intérieure). Cela annule les transactions les plus extérieures et les plus intérieures.
Il en résulte que seules les lignes de la transaction intermédiaire (12, 21 et 23) sont validées. Les lignes de la transaction extérieure et de la transaction intérieure ne sont pas validées.
Annuler le niveau intermédiaire de trois niveaux¶
Cet exemple contient 3 transactions. Cet exemple annule le niveau « intermédiaire » (la transaction délimitée par la transaction la plus extérieure et délimitant la transaction la plus intérieure). Cela valide les transactions les plus extérieures et les plus intérieures.
Il en résulte que toutes les lignes à l’exception de celles se trouvant dans la transaction intermédiaire (12, 21 et 23) sont validées.
Utilisation du traitement des erreurs avec les transactions dans les procédures stockées¶
Le code suivant indique un traitement d’erreur simple pour une transaction dans une procédure stockée. Si la valeur du paramètre « fail » est transmise, la procédure stockée tente de supprimer deux tables qui existent et une table qui n’existe pas, et la procédure stockée détecte l’erreur et renvoie un message d’erreur. Si la valeur du paramètre « fail » n’est pas transmise, la procédure tente de supprimer deux tables qui existent, et aboutit.
Créer les tables et la procédure stockée :
Appeler la procédure stockée et forcer une erreur :
Appeler la procédure stockée sans forcer une erreur :