Tables hybrides¶
Une table hybride est un type de table Snowflake optimisé pour une faible latence et un débit élevé à l’aide de lectures et d’écritures aléatoires basées sur un index. Les tables hybrides fournissent un moteur de stockage basé sur les lignes qui prend en charge le verrouillage de ligne pour les scénarios de haute concurrence. Les tables hybrides appliquent également des contraintes d’unicité et d’intégrité référentielle, qui sont essentielles pour les charges de travail transactionnelles. Vous pouvez utiliser une table hybride avec d’autres tables et fonctionnalités Snowflake pour optimiser les charges de travail Unistore qui rassemblent les données transactionnelles et analytiques en une seule plateforme.
Les cas d’utilisation susceptibles de bénéficier des tables hybrides sont les suivants :
Métadonnées pour les applications et les workflows, telles que le maintien de l’état d’un workflow d’ingestion qui nécessite des mises à jour à haute concurrence d’une table unique à partir de milliers de tâches worker parallèles.
Service à faible latence d’agrégats précalculés via une API ou une interface utilisateur.
Applications transactionnelles légères utilisant des modèles de données relationnels.
Astuce
Avant de créer et d’utiliser des tables hybrides, vous devez vous familiariser avec certaines fonctions et limites non prises en charge.
Architecture¶
Les tables hybrides s’intègrent parfaitement à l’architecture existante de Snowflake. Les clients se connectent au même service de base de données Snowflake. Les requêtes sont compilées et optimisées dans la couche de services Cloud et exécutées dans le même moteur de requête et les mêmes entrepôts virtuels que les tables standard. Cette architecture présente plusieurs avantages clés :
Les fonctionnalités de la plateforme Snowflake telles que la gouvernance des données fonctionnent d’emblée avec les tables hybrides.
Vous pouvez exécuter des charges de travail hybrides mélangeant des requêtes opérationnelles et analytiques.
Vous pouvez joindre des tables hybrides à d’autres tables Snowflake ; les requêtes sont exécutées de manière native et efficace dans le même moteur de requête. Aucune fédération n’est obligatoire.
Vous pouvez exécuter une transaction atomique sur des tables hybrides et d’autres tables Snowflake. Il n’est pas nécessaire d’orchestrer votre propre validation en deux phases.
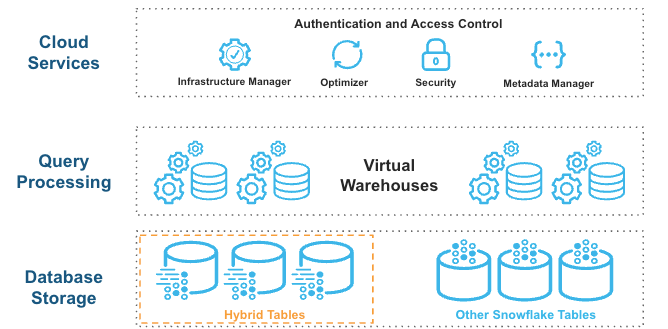
Les tables hybrides s’appuient sur un magasin de lignes comme magasin de données principal pour offrir d’excellentes performances de requêtes opérationnelles. Lorsque vous écrivez dans une table hybride, les données sont écrites directement dans le magasin de lignes. Les données sont copiées de manière asynchrone dans le stockage d’objets afin d’améliorer les performances et l’isolation de la charge de travail des analyses volumineuses, sans incidence sur les charges de travail opérationnelles en cours. Certaines données peuvent également être mises en cache au format colonne dans votre entrepôt afin d’améliorer les performances des requêtes analytiques. Il vous suffit d’exécuter des instructions SQL sur la table hybride logique et l’optimiseur de requêtes de Snowflake décide où lire les données afin de fournir les meilleures performances. Vous obtenez une vue cohérente de vos données sans avoir à vous soucier de l’infrastructure sous-jacente.
Note
Étant donné que le stockage principal des tables hybrides est un magasin de lignes, les tables hybrides ont généralement une empreinte de stockage plus grande que les tables standard. La principale raison de cette différence est que les données en colonnes des tables standard atteignent souvent des taux de compression plus élevés. Pour obtenir des informations sur les coûts de stockage, voir Évaluation du coût des tables hybrides.
Fonctionnalités¶
Les tables hybrides offrent des fonctionnalités supplémentaires qui ne sont pas prises en charge par les autres types de table Snowflake.
Fonctionnalité |
Tables hybrides |
Tables standards |
|---|---|---|
Disposition des données principales |
Orientation lignes, avec un stockage secondaire en colonnes |
Micro-partitions en colonnes |
Verrouillage |
Au niveau de la ligne |
Partition ou table |
Contraintes PRIMARY KEY |
Obligatoire, appliqué |
Facultatif ; non appliqué |
Contraintes FOREIGN KEY |
Facultatif, appliqué (intégrité référentielle) |
Facultatif ; non appliqué |
Contraintes UNIQUE |
Facultatives (sauf pour PRIMARY KEY), appliquées |
Facultatif ; non appliqué |
Contraintes NOT NULL |
Facultatives (sauf pour PRIMARY KEY), appliquées |
Obligatoire, appliqué |
Index |
Pris en charge à des fins de performances ; mis à jour de manière synchrone lors de l’écriture |
Le service d’optimisation de la recherche indexe les colonnes pour de meilleures performances en matière de recherche de points ; les lots sont mis à jour/maintenus de manière asynchrone |
Une contrainte est appliquée lorsqu’elle empêche une colonne d’être mise à jour de certaines manières. Par exemple, une colonne déclarée NOT NULL ne peut pas contenir une valeur NULL. Une tentative de copie ou d’insertion d’une valeur NULL dans une colonne NOT NULL entraîne toujours une erreur.
Pour les tables hybrides, vous ne pouvez pas définir la propriété NOT ENFORCED sur les contraintes PRIMARY KEY, FOREIGN KEY et UNIQUE. La définition de cette propriété entraîne une erreur « propriété de contrainte non valide ». Pour plus d’informations sur les règles relatives aux contraintes, voir Contraintes des tables hybrides.
Une contrainte est obligatoire lorsqu’une ou plusieurs colonnes d’une table doivent avoir une telle contrainte, ce qui n’est vrai que pour les contraintes PRIMARY KEY sur les tables hybrides.
Quand utiliser une table hybride ?¶
Même si les tables standards Snowflake devraient offrir de meilleures performances en cas de requêtes analytiques volumineuses, les tables hybrides permettent d’obtenir des résultats plus rapides en cas de requêtes opérationnelles à court terme. Les tables hybrides assurent un haut niveau de concurrence et une faible latence pour de nombreuses charges de travail. Les types de requêtes suivants sont les plus susceptibles de bénéficier des tables hybrides :
Lectures de points aléatoires basées sur un index qui récupèrent un petit nombre d’enregistrements, tels que les objets des clients
Écritures aléatoires à haute concurrence, y compris les insertions, les mises à jour et les fusions
Les applications utilisent généralement une combinaison de tables hybrides et de tables standard, avec différents ensembles de données stockés dans chaque type de table. Par exemple, vous pouvez avoir des données que vous chargez, analysez et regroupez fréquemment en masse à des fins d’analytiques, et d’autres données auxquelles vous accédez une ligne à la fois, en les filtrant sur une colonne ID à haute concurrence. Vous pouvez combiner l’utilisation de tables standard et de tables hybrides dans une même base de données en fonction des besoins de votre charge de travail.