Snowpipe Streaming¶
Snowpipe Streaming est le service d’ingestion en temps réel de Snowflake construit sur l’architecture haute performance. Il permet aux applications de charger des données en continu directement dans les tables Snowflake à l’arrivée des lignes, sans mettre en zone de préparation de fichiers ni gérer de stockage intermédiaire. Les données sont disponibles pour les requêtes quelques secondes seulement après leur ingestion, ce qui permet de répondre à divers cas d’utilisation, allant des pipelines de télémétrie IoT à la capture des données modifiées (CDC) pour la détection des fraudes et l’analyse en direct.
Snowpipe Streaming fournit :
Un débit pouvant atteindre jusqu’à 10 GB/s par table
À partir de 5 secondes de latence de bout en bout, de l’ingestion à la requête
Livraison unique grâce au suivi intégré des jetons de décalage
Ingestion ordonnée dans chaque canal
Streaming vers des tables :doc:` Apache Iceberg</user-guide/tables-iceberg>` gérées par Snowflake
Pourquoi utiliser Snowpipe Streaming¶
Livraison unique : Le suivi intégré des jetons de décalage permet une sémantique « unique ». Votre application assure le suivi des décalages validés et effectue une relecture à partir de la dernière position validée lors de la reprise, ce qui permet d’éviter les doublons et la perte de données. Pour plus d’informations, voir Jetons de décalage et livraison unique .
Ingestion ordonnée : Les lignes sont ingérées dans l’ordre dans chaque canal. Les canaux sont mappés naturellement aux partitions sources (par exemple, les partitions des sujets Kafka), ce qui permet une relecture déterministe et une récupération sans perte.
Débit élevé, faible latence : Conçu pour prendre en charge des vitesses d’ingestion pouvant atteindre 10 GB/s par table, les données étant disponibles pour les requêtes en seulement 5 secondes.
Transformations en cours : Nettoyez, restructurez et transformez les données lors de leur ingestion à l’aide de la syntaxe de commande COPY dans l’objet PIPE. Filtrez les lignes, réorganisez les colonnes, effectuez des conversions de types et appliquez des expressions avant que les données ne soient enregistrées dans la table cible, sans avoir à créer d’étape ETL.
Pré-clustering au moment de l’ingestion : Triez les données lors de l’ingestion pour optimiser les performances des requêtes sur les tables avec des clés de clustering.
Prise en charge des tables Apache Iceberg : Diffusez des données dans des tables Iceberg gérées par Snowflake, y compris des tables Iceberg v2 et Iceberg v3. Pour plus d’informations, voir Architecture hautes performances de Snowpipe Streaming avec les tables Apache Iceberg™.
Évolution du schéma : Adaptez automatiquement les schémas de table aux structures de données changeantes. Snowflake peut ajouter de nouvelles colonnes détectées dans le flux entrant sans modifications manuelles des DDL.
Pipelines simplifiés : les SDKs écrivent des lignes directement dans des tables, sans passer par des fichiers en zone de préparation ou un stockage intermédiaire dans le Cloud.
Sans serveur et évolutif : Les ressources de calcul s’adaptent automatiquement en fonction de la charge d’ingestion. Aucune infrastructure à gérer.
Tarif transparent : Facturation basée sur le débit calculée en crédits par GB non compressé des données ingérées. Pour plus d’informations, voir Snowpipe Streaming high-performance architecture: Understand your costs.
Comment se connecter¶
Snowpipe Streaming prend en charge plusieurs chemins d’ingestion pour s’adapter à différentes charges de travail :
Intégration |
Mieux adapté à |
|---|---|
Applications personnalisées à haut débit. Nécessite Java 11 ou supérieur. |
|
SDKPython (`référence d’API Python<https://docs.snowflake.com/en/user-guide/snowpipe-streaming-sdk-python/reference/latest/index>`_) |
Ingénierie des données et workflows natifs Python. Requiert Python 3.9 ou une version ultérieure. |
Charges de travail légères, appareils IoT et déploiements Edge. |
|
Ingestion de rubrique Apache Kafka. |
Les SDKs Java et Python utilisent un noyau client basé sur Rust pour améliorer les performances côté client et réduire l’utilisation des ressources.
Note
Nous vous recommandons de commencer par le SDK Snowpipe Streaming sur l’API REST pour bénéficier de l’amélioration des performances et de l’expérience de démarrage.
Pour commencer, voir le:doc:Tutoriel : Premiers pas avec le SDK<snowpipe-streaming-high-performance-getting-started> ou le Tutoriel : Premiers pas avec REST API.
Pour plus d’informations techniques sur l’objet PIPE, les canaux, les jetons de décalage et les types de données pris en charge, voir Concepts clés.
Recommandé pour :¶
Charges de travail de streaming à haut volume nécessitant un débit jusqu’à 10 GB/s
Analyses en temps réel et tableaux de bord avec une actualisation des données toutes les 5 secondes
Déploiements IoT et Edge à l’aide des API REST
Pipelines CDC (Change Data Capture ou) avec des garanties de livraison uniques
Apache Kafka topic ingestion using the Snowflake Connector for Kafka
Streaming dans les tables Apache Iceberg pour l’analyse des formats de table ouverts
Note
Recherche de streaming natif SQL ? Voir les Tables dynamiques et les Flux avec les Tâches pour les pipelines de streaming déclaratifs.
Comparaison de Snowpipe Streaming et de Snowpipe¶
Snowpipe Streaming est destiné à compléter Snowpipe, pas à le remplacer. Utilisez Snowpipe Streaming dans les scénarios où les données arrivent sous forme de lignes (par exemple, à partir des rubriques Apache Kafka, appareils IoT, ou des événements d’application) au lieu de fichiers. Avec Snowpipe Streaming, vous n’avez pas besoin de créer des fichiers pour charger des données dans des tables Snowflake.
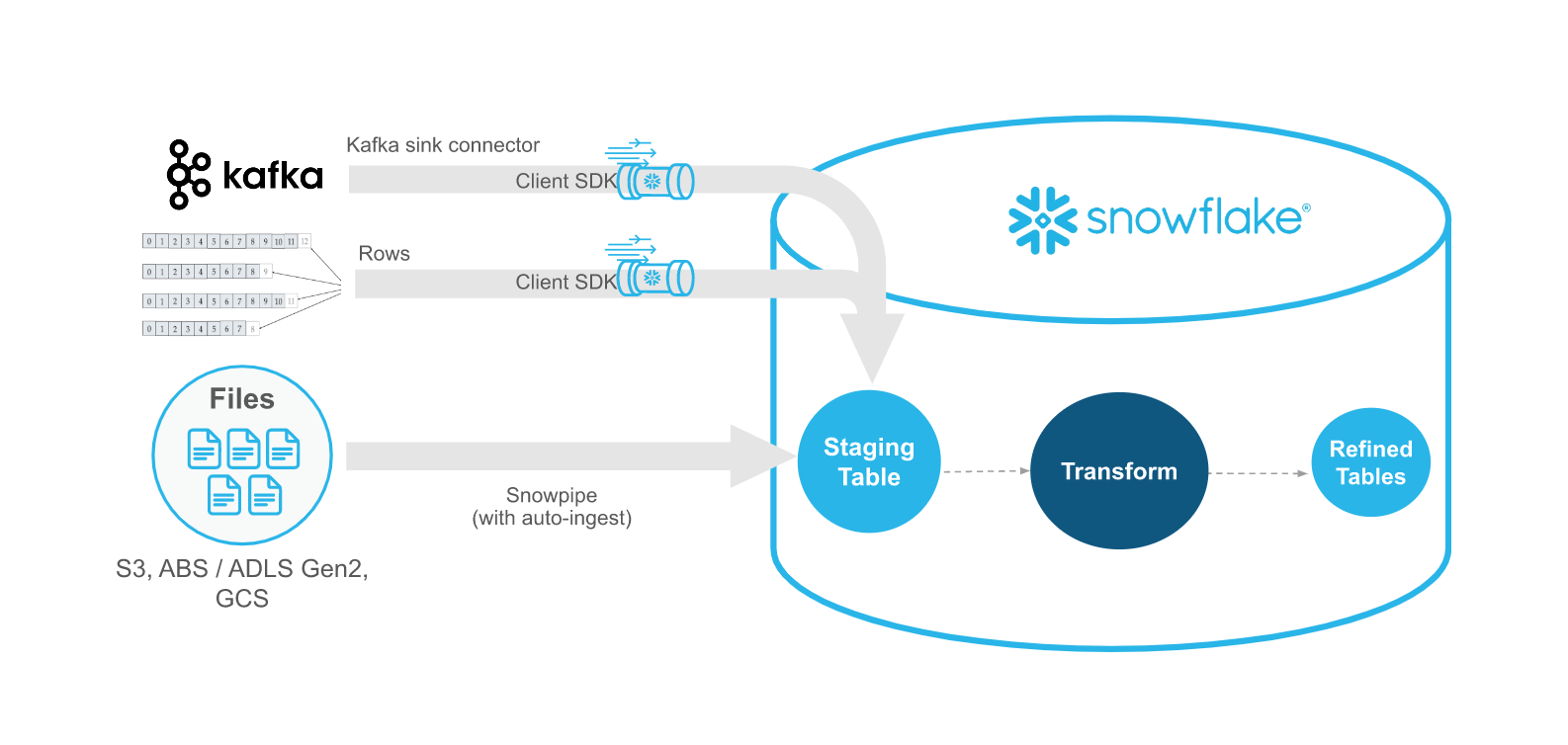
Le tableau suivant décrit les différences entre Snowpipe Streaming et Snowpipe :
Catégorie |
Snowpipe Streaming |
Snowpipe |
|---|---|---|
Forme des données à charger |
Lignes |
Fichiers. Si votre pipeline de données existant génère des fichiers dans un stockage Blob, nous vous recommandons d’utiliser Snowpipe à la place. |
Commande de données |
Insertions ordonnées dans chaque canal. |
Non pris en charge. Snowpipe peut charger des données à partir de fichiers dans un ordre différent des horodatages de création des fichiers dans le stockage cloud. |
Historique de chargement |
Historique de chargement enregistré dans la vue SNOWPIPE_STREAMING_FILE_MIGRATION_HISTORY (Account Usage). |
Historique de chargement enregistré dans COPY_HISTORY (Account Usage) et la fonction COPY_HISTORY (Information Schema). |
Objet du canal |
L’objet PIPE est la couche de traitement côté serveur pour l’ensemble de l’ingestion en streaming. IL gère la validation des schémas, les transformations en cours et le pré-clustering. Un canal par défaut est créé automatiquement pour chaque table, ou vous pouvez créer un canal personnalisé pour un traitement avancé. |
Un objet Canal met en file d’attente et charge les données des fichiers en zone de préparation dans les tables cibles. |
Dans cette section¶
Concepts clés
Prise en main
Cibles d’ingestion
Opérations
Référence
Architecture classique¶
Important
L’architecture classique, qui utilise le `SDK Java snowflake-ingest-sdk<https://mvnrepository.com/artifact/net.snowflake/snowflake-ingest-sdk>`_, est planifié pour devenir obsolète. Aucun changement immédiat n’est requis. Les charges de travail actuelles continuent d’être entièrement prises en charge.
Pour plus de détails, voir Avis d’obsolescence prévue.
Si vous avez des charges de travail existantes fonctionnant sur l’architecture classique, voir Architecture classique. Pour une comparaison détaillée des différences, voir Comparaison entre les performances les plus élevées et les SDKs classiques.
Si vous mettez à niveau vers l’architecture hautes performances, voir Guide de migration.