Tables dynamiques¶
Les tables dynamiques sont des tables qui s’actualisent automatiquement en fonction d’une requête définie et du niveau d’actualisation de la cible, ce qui simplifie la transformation des données et la gestion du pipeline sans nécessiter de mises à jour manuelles ou de planification personnalisée.
Lorsque vous créez une table dynamique, vous définissez une requête qui spécifie comment les données doivent être transformées à partir des objets de base. Snowflake gère la planification d’actualisation de la table dynamique et met à jour la table automatiquement pour refléter les modifications apportées aux objets de base en fonction de la requête.
Considérations clés et meilleures pratiques générales¶
Contraintes d’immuabilité : Utilisez des contraintes d’immuabilité pour vous permettre de contrôler les mises à jour des tables dynamiques. Les contraintes gardent des lignes spécifiques statiques tout en permettant des mises à jour incrémentielles du reste de la table. Elles empêchent les modifications non souhaitées aux données marquées et permettent aux actualisations normales de se produire pour d’autres parties de la table. Pour plus d’informations, voir Compréhension des contraintes d’immuabilité.
Clés primaires : Snowflake utilise des clés primaires fiables pour suivre les modifications plus efficacement dans les pipelines de tables dynamiques. Lorsqu’une table dynamique possède une clé primaire dérivée du système, les tables en aval peuvent utiliser l’actualisation incrémentielle même si la table en amont utilise le mode d’actualisation complet. Pour plus d’informations, voir Comprendre les clés primaires des tables dynamiques.
Considérations en matière de performances : les tables dynamiques utilisent un traitement incrémentiel pour les charges de travail qui le prennent en charge, ce qui peut améliorer les performances en traitant uniquement les données modifiées au lieu de recalculer des tables entières. Les performances dépendent de vos modèles de requêtes et de votre organisation des données. Pour obtenir des conseils sur l’optimisation des performances des tables dynamiques, voir Performances et optimisation des tables dynamiques.
Décomposer les tables dynamiques complexes : décomposez votre pipeline en tables dynamiques plus petites et ciblées pour améliorer les performances et simplifier le dépannage. Pour plus d’informations, voir Bonnes pratiques pour la création de tables dynamiques.
Fonctionnement des tables dynamiques¶
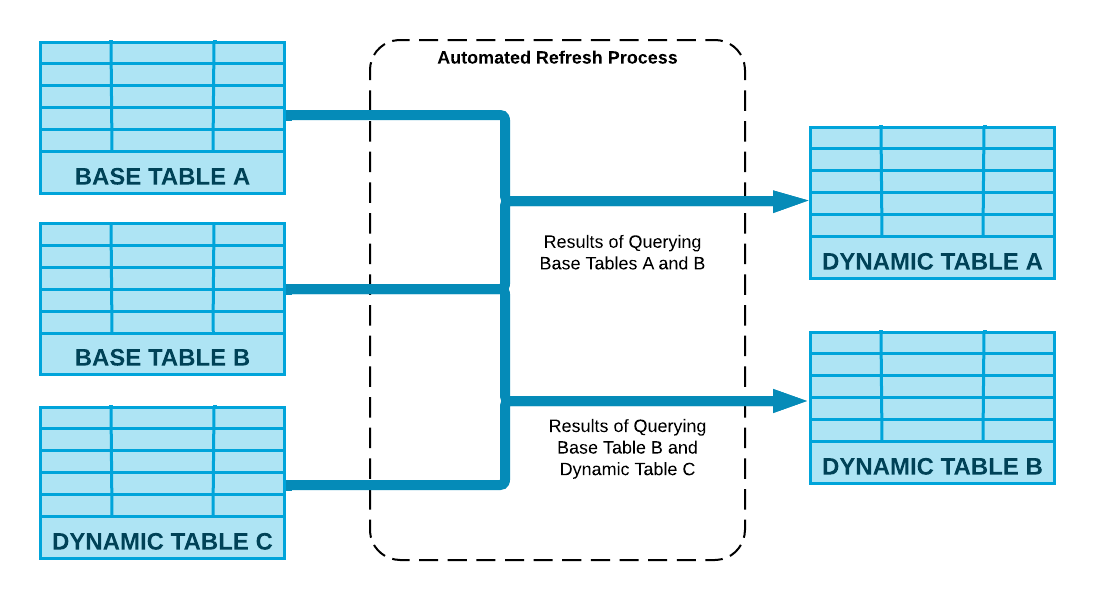
Snowflake exécute la requête de définition spécifiée dans votre CREATE DYNAMIC TABLE et vos tables dynamiques sont mises à jour via un processus d’actualisation automatisé.
Le schéma suivant montre comment ce processus calcule les modifications apportées aux objets de base et les fusionne dans la table dynamique en utilisant les ressources de calcul associées à la table.
Latence cible¶
Utilisez la latence cible pour définir le niveau d’actualisation de vos données. En général, le niveau d’actualisation des données de la table ne sera pas si éloigné du niveau d’actualisation des données de la table de base. Avec la latence cible, vous contrôlez la fréquence d’actualisation de la table et la manière dont les données restent à jour. La latence cible affecte la fréquence d’actualisation et les coûts de calcul.
Pour plus d’informations, voir Comprendre la latence cible des tables dynamiques. Pour obtenir des conseils sur la manière de trouver l’équilibre entre l’actualisation des données et la performance, voir Optimiser les performances des tables dynamiques.
Modes d’actualisation des tables dynamiques¶
Les tables dynamiques visent à s’actualiser dans la latence cible que vous spécifiez. Par exemple, une latence cible de 5 minutes garantit que les données de la table dynamique n’ont pas plus de 5 minutes de retard sur les données mises à jour de la table de base. Vous définissez le mode d’actualisation lorsque vous créez la table et, par la suite, les actualisations peuvent être effectuées selon une planification ou manuellement.
Pour plus d’informations, voir Comprendre l’initialisation et l’actualisation des tables dynamiques et Actualiser manuellement les tables dynamiques.
Quand utiliser les tables dynamiques¶
Les tables dynamiques sont idéales pour les scénarios suivants :
Vous souhaitez matérialiser les résultats de la requête sans écrire de code personnalisé.
Vous souhaitez éviter de suivre manuellement les dépendances de données et de gérer des planifications d’actualisation. Les tables dynamiques vous permettent de définir les résultats du pipeline de manière déclarative, sans gérer manuellement les étapes de transformation.
Vous souhaitez enchaîner ensemble plusieurs tables pour les transformations de données dans un pipeline.
Vous n’avez pas besoin de contrôle précis sur les planifications d’actualisation, et il vous suffit de spécifier un niveau d’actualisation cible pour le pipeline. Snowflake gère l’orchestration des actualisations de données, y compris la planification et l’exécution, en fonction de vos exigences d’actualisation cibles.
Exemples de cas d’utilisation¶
Dimensions à changement lent (SCDs) : les tables dynamiques peuvent être utilisées pour mettre en œuvre les types 1 et 2 de SCDs en lisant un flux de modifications et en utilisant des fonctions de fenêtre sur des clés par enregistrement ordonnées par un horodatage des modifications. Cette méthode permet de gérer les insertions, les suppressions et les mises à jour qui se produisent dans le désordre, ce qui simplifie la création de SCDs. Pour plus d’informations, voir Changement lent des dimensions avec les tables dynamiques.
jointures et agrégations : pour permettre des requêtes rapides, vous pouvez utiliser des tables dynamiques pour précalculer de manière incrémentielle les jointures lentes et les agrégations. Pour obtenir des conseils sur l’optimisation de ces opérateurs pour l’actualisation incrémentielle, voir Optimiser les requêtes pour l’actualisation incrémentielle.
Passage du lot à la diffusion en continu : les tables dynamiques permettent de passer en toute transparence du lot à la diffusion en continu avec une seule commande ALTER DYNAMIC TABLE. Vous pouvez contrôler la fréquence d’actualisation dans votre pipeline afin d’équilibrer le coût et le niveau d’actualisation des données.