Bonnes pratiques pour les tables dynamiques¶
Cette rubrique présente les meilleures pratiques et les points importants à prendre en compte lors de la création et de la gestion de tables dynamiques.
Meilleures pratiques générales :
Meilleures pratiques pour la création de tables dynamiques :
Meilleures pratiques pour l’actualisation de tables dynamiques :
Meilleures pratiques pour l’optimisation des performances :
Meilleures pratiques générales¶
Utiliser le privilège MONITOR pour afficher les métadonnées¶
Pour les scénarios où l’utilisateur n’a besoin que de voir les métadonnées et l’Information Schema d’une table dynamique (par exemple, les rôles détenus par les scientifiques des données), utilisez un rôle qui a le privilège MONITOR sur cette table dynamique. Bien que le privilège OPERATE accorde cet accès, il inclut également la capacité de modifier les tables dynamiques, ce qui fait de MONITOR l’option la plus appropriée pour les scénarios dans lesquels un utilisateur n’a pas besoin de modifier une table dynamique.
Pour plus d’informations, voir Contrôle de l’accès aux tables dynamiques.
Simplification des expressions composées en clés de regroupement¶
Si une clé de regroupement contient une expression composée plutôt qu’une colonne de base, matérialisez l’expression dans une table dynamique, puis appliquez l’opération de regroupement sur la colonne matérialisée dans une autre table dynamique. Pour plus d’informations, voir Actualisation incrémentielle par les opérateurs.
Utiliser des tables dynamiques pour mettre en œuvre des dimensions qui changent lentement¶
Les tables dynamiques peuvent être utilisées pour mettre en œuvre les dimensions à variation lente de type 1 et 2 (SCDs). Lors de la lecture d’un flux de modifications, utilisez des fonctions de fenêtre sur des clés par enregistrement ordonnées en fonction de l’horodatage des modifications. Grâce à cette méthode, les tables dynamiques gèrent de manière transparente les insertions, les suppressions et les mises à jour qui se produisent dans le désordre afin de simplifier la création de SCD. Pour plus d’informations, voir Changement lent des dimensions avec les tables dynamiques.
Bonnes pratiques pour la création de tables dynamiques¶
Lier des pipelines de tables dynamiques¶
Lorsque vous définissez une nouvelle table dynamique, plutôt que de définir une grande table dynamique avec de nombreuses instructions imbriquées, utilisez plutôt de petites tables dynamiques avec des pipelines.
Vous pouvez configurer une table dynamique pour interroger d’autres tables dynamiques. Par exemple, imaginez un scénario dans lequel votre pipeline de données extrait des données d’une table de mise en zone de préparation pour mettre à jour diverses tables de dimensions (par exemple, client, produit, date et heure). En outre, votre pipeline met à jour une table de ventes agrégée sur la base des informations provenant de ces tables de dimensions. En configurant les tables de dimensions pour qu’elles interrogent la table de mise en zone de préparation et la table des ventes agrégées pour qu’elle interroge les tables de dimensions, vous créez un effet de cascade similaire à un graphique de tâches.
Dans cette configuration, l’actualisation de la table des ventes agrégées n’est exécutée qu’une fois que les actualisations des tables de dimension ont été effectuées avec succès. Cela permet de garantir la cohérence des données et d’atteindre les objectifs en matière de délais. Grâce à un processus d’actualisation automatisé, toute modification apportée aux tables sources déclenche des actualisations dans toutes les tables dépendantes au moment opportun.
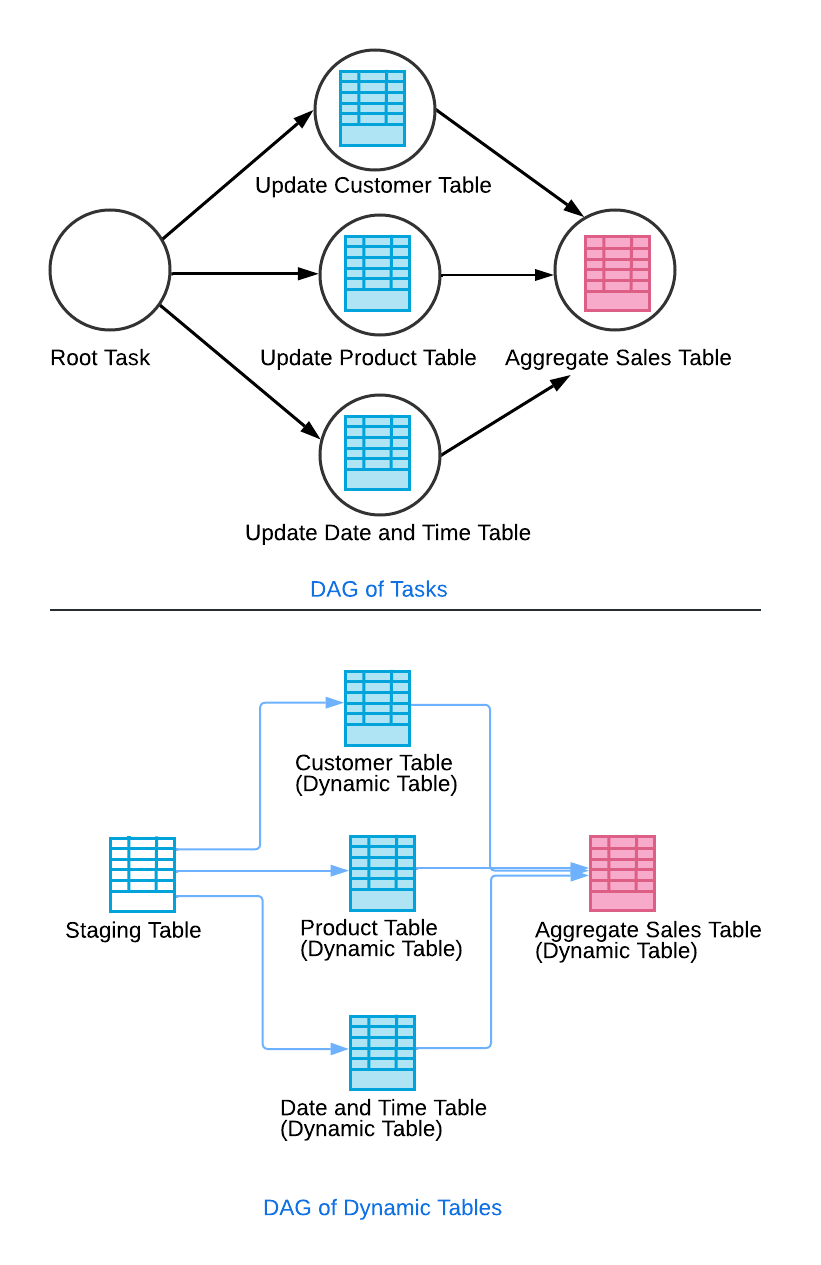
Utilisez une table dynamique « contrôleur » pour les graphiques de tâches complexes¶
Lorsque vous avez un graphique complexe de tables dynamiques avec de nombreuses racines et feuilles et que vous souhaitez effectuer des opérations liées aux performances (par exemple, changement de décalage, actualisation manuelle, suspension) sur le graphique de tâches complet avec une seule commande, procédez comme suit :
Définissez la valeur de
TARGET_LAGde toutes vos tables dynamiques surDOWNSTREAM.Créez une table dynamique « contrôleur » qui lit toutes les feuilles de votre graphique de tâches. Pour vous assurer que ce contrôleur ne consomme pas de ressources, procédez comme suit :
CREATE DYNAMIC TABLE controller TARGET_LAG = <target_lag> WAREHOUSE = <warehouse> AS SELECT 1 A FROM <leaf1>, …, <leafN> LIMIT 0;
Utilisez le contrôleur pour contrôler l’ensemble du graphique. Par exemple :
Définissez une nouvelle latence cible pour le graphique de tâches.
ALTER DYNAMIC TABLE controller SET TARGET_LAG = <new_target_lag>Actualisez manuellement le graphique de tâches.
ALTER DYNAMIC TABLE controller REFRESH
À propos des pipelines de clonage de tables dynamiques¶
Clonez tous les éléments du pipeline de tables dynamiques dans la même commande clone pour éviter les réinitialisations de votre pipeline. Pour ce faire, vous pouvez consolider tous les éléments du pipeline (par exemple, les tables de base, les vues et les tables dynamiques) dans le même schéma ou la même base de données. Pour plus d’informations, voir Limitations connues relatives aux tables dynamiques.
Utiliser des tables dynamiques transitoires pour réduire les coûts de stockage¶
Les tables dynamiques transitoires conservent les données de manière fiable dans le temps et prennent en charge Time Travel dans la période de conservation des données, mais ne conservent pas les données au-delà de la période Fail-safe. Par défaut, les données des tables dynamiques sont conservées pendant 7 jours dans le stockage Fail-safe. Pour les tables dynamiques avec un taux d’actualisation élevé, cela peut augmenter considérablement la consommation de stockage. Par conséquent, vous ne devez rendre une table dynamique transitoire que si ses données ne nécessitent pas le même niveau de protection et de récupération des données que les tables permanentes.
Vous pouvez créer une table dynamique transitoire ou cloner des tables dynamiques existantes en tables dynamiques transitoires à l’aide de l’instruction CREATE DYNAMIC TABLE.
Meilleures pratiques pour l’actualisation des tables dynamiques¶
Utiliser des entrepôts dédiés pour les actualisations¶
Les tables dynamiques nécessitent un entrepôt virtuel pour effectuer les actualisations. Pour bien comprendre les coûts liés à vos pipelines de tables dynamiques, vous devriez tester vos tables dynamiques à l’aide d’entrepôts dédiés, de sorte que la consommation de l’entrepôt virtuel attribuée aux tables dynamiques puisse être isolée. Pour plus d’informations, voir Compréhension du coût des tables dynamiques.
Utiliser la latence en aval¶
La latence en aval indique que la table dynamique doit être actualisée lorsque d’autres tables dynamiques dépendantes doivent l’être. Vous devriez utiliser la latence en aval comme meilleure pratique en raison de sa facilité d’utilisation et de sa rentabilité. Sans latence en aval, la gestion d’une chaîne de tables dynamiques complexes nécessiterait d’assigner individuellement à chaque table sa propre latence cible et de gérer les contraintes associées, au lieu de surveiller uniquement le niveau d’actualisation des données de la table finale. Pour plus d’informations, voir Comprendre la latence cible.
Définir le mode d’actualisation pour toutes les tables dynamiques de production¶
Le mode d’actualisation d’une table dynamique est déterminé au moment de la création et est immuable par la suite. S’il n’est pas spécifié explicitement, le mode d’actualisation est par défaut AUTO , ce qui sélectionne un mode d’actualisation en fonction de divers facteurs tels que la complexité de la requête ou les constructions, opérateurs ou fonctions non pris en charge.
Pour déterminer le mode le mieux adapté à votre casse, expérimentez les modes d’actualisation et les recommandations automatiques. Pour un comportement cohérent entre les versions de Snowflake, définissez explicitement le mode d’actualisation sur toutes les tables de production. Le comportement de AUTO peut changer selon les versions de Snowflake, ce qui peut entraîner des changements inattendus dans les performances s’il est utilisé dans les pipelines de production.
Pour vérifier le mode d’actualisation de vos tables dynamiques, consultez Afficher le mode d’actualisation de tables dynamiques.
Meilleures pratiques pour optimiser les performances¶
Pour optimiser les performances de vos tables dynamiques, vous devez comprendre le système, expérimenter des idées et itérer en fonction des résultats. Par exemple :
Développez des moyens d’améliorer votre pipeline de données en fonction de vos besoins en matière de coût, de décalage des données et de temps de réponse.
Implémentez les actions suivantes :
Commencez par un petit ensemble de données fixes pour développer rapidement des requêtes.
Testez les performances avec des données en mouvement.
Développez l’ensemble de données pour vous assurer qu’il répond à vos besoins.
Ajustez votre charge de travail en fonction des résultats obtenus.
Répétez si nécessaire, en priorisant les tâches ayant le plus grand impact sur les performances.
De plus, utilisez la latence en aval pour gérer efficacement les dépendances d’actualisation entre les tables, en garantissant que les actualisations ne se produisent que lorsque cela est nécessaire. Pour plus d’informations, consultez la documentation sur les performances.
Choix du mode d’actualisation¶
Pour déterminer le mode le mieux adapté à votre cas d’utilisation, expérimentez les recommandations automatiques et les modes d’actualisation concrets (actualisations complètes et incrémentielles). Le mode le plus adapté pour les performances de vos tables dynamiques dépend du volume de modification des données et de la complexité de la requête. De plus, tester différents modes d’actualisation avec un entrepôt dédié permet d’isoler les coûts et d’améliorer le réglage des performances en fonction des charges de travail réelles.
Pour vérifier le mode d’actualisation de vos tables dynamiques, consultez Afficher le mode d’actualisation de tables dynamiques.
Mode d’actualisationAUTO : le système tente d’appliquer une actualisation incrémentielle par défaut. Lorsque l”actualisation incrémentielle n’est pas prise en charge ou ne fonctionne pas correctement, la table dynamique sélectionne automatiquement l’actualisation complète à la place.
Pour un comportement cohérent, définissez explicitement le mode d’actualisation sur toutes les tables de production. Le comportement de
AUTOpeut changer selon les versions de Snowflake, ce qui peut entraîner des changements inattendus dans les performances s’il est utilisé dans les pipelines de production.
Actualisation incrémentielle : met à jour la table dynamique avec uniquement les modifications depuis la dernière actualisation, ce qui la rend idéale pour les grands ensembles de données avec de petites mises à jour fréquentes.
Adapté pour les requêtes compatibles avec l’actualisation incrémentielle (par exemple, les fonctions déterministes, les jointures simples et les expressions de base dans
SELECT,WHEREetGROUP BY). Si des fonctionnalités non prises en charge sont présentes et que le mode d’actualisation est défini sur incrémentiel, Snowflake ne parviendra pas à créer la table dynamique.Une pratique fondamentale pour optimiser les performances avec une actualisation incrémentielle consiste à limiter le volume de modification à environ 5 % des données source, et à regrouper vos données par clés de regroupement pour réduire la surcharge de traitement.
Tenez compte du fait que certaines combinaisons d’opérations, comme les agrégations au-dessus de plusieurs jointures, peuvent ne pas fonctionner efficacement.
Actualisation complète : retraite l’intégralité du jeu de données et met à jour la table dynamique avec le résultat complet de la requête. À utiliser pour les requêtes complexes ou lorsque des modifications de données importantes nécessitent une mise à jour complète.
Utile lorsque l’actualisation incrémentielle n’est pas prise en charge en raison de requêtes complexes, de fonctions non déterministes ou de modifications majeures dans les données.
Pour plus d’informations, voir Comment le mode d’actualisation affecte-t-il les performances des tables dynamiques ?.
Performance d’actualisation à actualisation complète¶
Les tables dynamiques à actualisation complète ont des performances similaires à celles de CREATE TABLE … AS SELECT (également appelé CTAS). Elles peuvent être optimisées comme n’importe quelle autre requête de Snowflake.
Performance de l’actualisation incrémentielle¶
Pour vous aider à atteindre des performances optimales en matière d’actualisation incrémentielle pour vos tables dynamiques :
Maintenez les changements entre les actualisations à un niveau minimal, idéalement moins de 5 % de l’ensemble de données, tant pour les sources que pour la table dynamique.
Tenez compte du nombre de micropartitions modifiées et pas seulement du nombre de lignes. La quantité de travail qu’une actualisation incrémentielle doit effectuer est proportionnelle à la taille de ces micropartitions, et pas seulement aux lignes qui ont été modifiées.
Réduisez au minimum les opérations de regroupement telles que les jointures, GROUP BYs et PARTITION BYs dans votre requête. Décomposez les grandes expressions de tables communes (CTEs) en parties plus petites et créez une table dynamique pour chacune d’entre elles. Évitez de surcharger une table dynamique unique avec des agrégations ou des jointures excessives.
Assurez la localité des données en alignant les changements de table sur les clés de requête (par exemple, pour les jointures, GROUP BYs, PARTITION BYs). Si vos tables ne sont pas naturellement regroupées par ces clés, envisagez d’activer le clustering automatique.