Important
Avis préalable : Le connecteur Kafka classique (v3 et versions antérieures) est entièrement pris en charge aujourd’hui, mais il devrait devenir obsolète à l’avenir.
Action : Aucun changement immédiat n’est requis. Vos charges de travail actuelles sont sécurisées et continuent d’être entièrement prises en charge.
Chronologie : Snowflake prévoit de publier une annonce formelle d’obsolescence à la mi-2026. Après l’annonce, une période de migration de 18 mois commence avant la fin de vie du produit.
Recommandation : Utilisez le Snowflake Conector pour Kafka (v4) pour toutes les nouvelles implémentations.
Pour des conseils sur la migration, consultez Migrer de v3 à v4.
Vue d’ensemble du connecteur Kafka¶
Ce chapitre fournit une vue d’ensemble d’Apache Kafka et du connecteur Snowflake pour Kafka.
Note
Le connecteur Kafka est soumis aux Conditions du connecteur.
Introduction à Apache Kafka¶
Le logiciel Apache Kafka utilise un modèle de publication et d’abonnement pour écrire et lire des flux d’enregistrements, similaires à une file d’attente de messages ou à un système de messagerie d’entreprise. Kafka permet aux processus de lire et d’écrire des messages de manière asynchrone. Un abonné n’a pas besoin d’être connecté directement à un éditeur ; un éditeur peut mettre en file d’attente un message dans Kafka pour que l’abonné puisse le recevoir plus tard.
Une application publie des messages dans un sujet et une application s’abonne à un sujet pour recevoir ces messages. Kafka peut traiter, ainsi que transmettre, des messages ; cependant, cela sort du cadre de ce document. Les sujets peuvent être divisés en partitions pour augmenter l’évolutivité.
Kafka Connect est un framework permettant de connecter Kafka à des systèmes externes, y compris des bases de données. Un cluster Kafka Connect est un cluster distinct du cluster Kafka. Le cluster Kafka Connect prend en charge les connecteurs en cours d’exécution et de dimensionnement (composants prenant en charge la lecture et/ou l’écriture entre systèmes externes).
Le connecteur Kafka est conçu pour fonctionner dans un cluster Kafka Connect afin de lire les données des sujets Kafka et de les écrire dans des tables Snowflake.
Snowflake fournit deux versions du connecteur :
Une version de la version du paquet Confluent de Kafka.
Pour plus d’informations sur Kafka Connect, voir : https://docs.confluent.io/current/connect/.
Note
Une version hébergée du connecteur Kafka est disponible dans Confluent Cloud. Pour plus d’informations, voir https://docs.confluent.io/current/cloud/connectors/cc-snowflake-sink.html.
Une version du paquet logiciel open source (OSS) Apache Kafka.
Pour plus d’informations sur Apache Kafka, voir : https://kafka.apache.org/.
Du point de vue de Snowflake, un sujet Kafka génère un flux de lignes à insérer dans une table Snowflake. En général, chaque message Kafka contient une ligne.
Kafka, à l’instar de nombreuses plates-formes de publication/abonnement de messages, permet d’établir une relation multiple entre éditeurs et abonnés. Une seule application peut publier sur de nombreux sujets et une seule application peut s’abonner à plusieurs sujets. Avec Snowflake, le schéma typique est qu’un sujet fournit des messages (lignes) pour une table Snowflake.
La version actuelle du connecteur Kafka est limitée au chargement de données dans Snowflake. Le connecteur Kafka prend en charge deux méthodes de chargement de données :
Pour plus d’informations, reportez-vous à Chargement de données dans Snowflake et à Utilisation de Connecteur Snowflake pour Kafka avec Snowpipe Streaming.
Tables cibles pour les rubriques Kafka¶
Les sujets Kafka peuvent être mappés sur des tables Snowflake existantes dans la configuration Kafka. Si les sujets ne sont pas mappés, le connecteur Kafka crée une nouvelle table pour chaque sujet en utilisant le nom du sujet.
Le connecteur convertit le nom du sujet en un nom de table Snowflake valide en appliquant les règles suivantes :
Les noms de sujets en minuscules sont convertis en noms de tables en majuscules.
Si le premier caractère du nom du sujet n’est pas une lettre (
a-zouA-Z) ni un trait de soulignement (_), le connecteur ajoute un trait de soulignement au nom de la table.Si un caractère du nom du sujet n’est pas un caractère légal pour un nom de table Snowflake, ce caractère est remplacé par le caractère de soulignement. Pour plus d’informations sur les caractères valides dans les noms de tables, voir Exigences relatives à l’identificateur.
Notez que si le connecteur Kafka doit ajuster le nom de la table créée pour un sujet Kakfa, il est possible que les noms de deux tables du même schéma soient identiques. Par exemple, si vous lisez des données à partir des sujets numbers+x et numbers-x, les tables créées pour ces sujets sont toutes deux NUMBERS_X. Pour éviter la duplication accidentelle des noms de tables, le connecteur ajoute un suffixe au nom de la table. Le suffixe est un trait de soulignement suivi d’un code de hachage généré.
Astuce
Snowflake vous recommande, lorsque cela est possible, de choisir des noms de sujets qui respectent les règles applicables aux noms d’identificateurs Snowflake.
Schéma de tables pour les rubriques Kafka¶
Le schéma d’une table chargée par le connecteur Kafka dépend du type de table et de la manière dont vous configurez le connecteur :
La plupart des tables utilisent le schéma par défaut décrit dans cette section.
Lorsque vous utilisez l’évolution et la détection du schéma, le schéma contient des colonnes qui correspondent au schéma défini par l’utilisateur.
Lorsque vous intégrez une table Iceberg, le schéma inclut les mêmes colonnes par défaut (
record_contentetrecord_metadata). Cependant, ce sont des colonnes de type structuré au lieu de VARIANT.
Par défaut, avec Snowpipe ou Snowpipe Streaming, toutes les tables Snowflake chargées par le connecteur Kafka ont un schéma composé de deux colonnes VARIANT :
RECORD_CONTENT. Ceci contient le message Kafka.
RECORD_METADATA. Cela contient des métadonnées sur le message, par exemple, le sujet à partir duquel le message a été lu.
Si Snowflake crée la table, celle-ci ne contient que ces deux colonnes. Si l’utilisateur crée la table à laquelle le connecteur Kafka doit ajouter des lignes, la table peut contenir plus de ces deux colonnes (toute colonne supplémentaire doit autoriser des valeurs NULL car les données du connecteur n’incluent pas de valeurs pour ces colonnes).
La colonne RECORD_CONTENT contient le message Kafka.
Un message Kafka possède une structure interne qui dépend des informations envoyées. Par exemple, un message émis par un capteur météo IoT (Internet des Objets) peut inclure l’horodatage auquel les données ont été enregistrées, l’emplacement du capteur, la température, l’humidité, etc. Un message provenant d’un système d’inventaire peut inclure l’ID du produit et le nombre d’articles vendus, éventuellement accompagnés d’un horodatage indiquant le moment où ils ont été vendus ou expédiés.
En règle générale, chaque message d’un sujet spécifique a la même structure de base. Différents sujets utilisent généralement une structure différente.
Chaque message Kafka est transmis à Snowflake au format JSON ou au format Avro. Le connecteur Kafka stocke ces informations formatées dans une seule colonne de type VARIANT. Les données ne sont pas analysées et ne sont pas divisées en plusieurs colonnes dans la table Snowflake.
La colonne RECORD_METADATA contient les informations suivantes par défaut :
Champ |
Type de données . Java |
Type de données SQL . |
Obligatoire |
Description |
|---|---|---|---|---|
topic |
Chaîne |
VARCHAR |
Oui |
Le nom du sujet Kafka d’où provient l’enregistrement. |
partition |
Chaîne |
VARCHAR |
Oui |
Le numéro de la partition dans le sujet. (Notez qu’il s’agit de la partition Kafka, pas de la micro-partition Snowflake.) |
offset |
long |
INTEGER |
Oui |
Le décalage dans cette partition. |
CreateTime / . LogAppendTime |
long |
BIGINT |
Non |
Il s’agit de l’horodatage associé au message dans le sujet Kafka. La valeur est exprimée en millisecondes depuis minuit le 1er janvier 1970, UTC. Pour plus d’informations, voir https://kafka.apache.org/0100/javadoc/org/apache/kafka/clients/producer/ProducerRecord.html |
SnowflakeConnectorPushTime |
long |
BIGINT |
Non |
Disponible uniquement lors de l’utilisation de Snowpipe Streaming. Un horodatage lorsqu’un enregistrement a été transféré dans une mémoire tampon SDK Ingest. La valeur est le nombre de millisecondes depuis minuit le 1er janvier 1970, UTC. Pour plus d’informations, voir Estimation de la latence d’ingestion. |
key |
Chaîne |
VARCHAR |
Non |
Si le message est un KeyedMessage Kafka, il s’agit de la clé de ce message. Pour que le connecteur enregistre la clé dans RECORD_METADATA, le paramètre key.converter dans Propriétés de configuration de Kafka doit être défini sur « org.apache.kafka.connect.storage.StringConverter » ; sinon, le connecteur ignore les clés. |
id_schéma |
int |
INTEGER |
Non |
Lorsque vous utilisez Avro avec un registre de schéma pour spécifier un schéma, il s’agit de l’ID du schéma de ce registre. |
headers |
Objet |
OBJECT |
Non |
Un en-tête est une paire clé-valeur définie par l’utilisateur associée à l’enregistrement. Chaque enregistrement peut avoir 0, 1 ou plusieurs en-têtes. |
La quantité de métadonnées enregistrées dans la colonne RECORD_METADATA est configurable à l’aide des propriétés de configuration Kafka facultatives. Pour plus d’informations, voir Installation et configuration du connecteur Kafka.
Les noms de champs et les valeurs sont sensibles à la casse.
Exprimé avec la syntaxe JSON, un exemple de message pourrait ressembler à ceci :
Vous pouvez interroger directement les tables Snowflake en utilisant la syntaxe appropriée pour interroger les colonnes VARIANT.
Voici un exemple simple d’extraction de données basée sur le sujet dans RECORD_METADATA :
La sortie serait similaire à ce qui suit :
Vous pouvez également extraire les données de ces tables, les aplatir dans des colonnes individuelles et les stocker dans d’autres tables, qui sont généralement plus faciles à interroger.
Flux de travail du connecteur Kafka¶
Le connecteur Kafka termine le processus suivant pour s’abonner aux sujets Kafka et créer des objets Snowflake :
Le connecteur Kafka s’abonne à un ou plusieurs sujets Kafka en fonction des informations de configuration fournies via le fichier de configuration Kafka ou la ligne de commande (ou le centre de contrôle de Confluent ; Confluent uniquement).
Le connecteur crée les objets suivants pour chaque sujet :
Une zone de préparation interne pour stocker temporairement les fichiers de données pour chaque sujet.
Un canal pour intégrer les fichiers de données pour chaque partition de sujet.
Une table pour chaque sujet. Si la table spécifiée pour chaque sujet n’existe pas, le connecteur le crée. Sinon, le connecteur crée les colonnes RECORD_CONTENT et RECORD_METADATA dans la table existante et vérifie que les autres colonnes peuvent devenir null (et génère une erreur dans le cas contraire).
Le diagramme ci-dessous montre le flux d’intégration pour Kafka avec le connecteur Kafka :
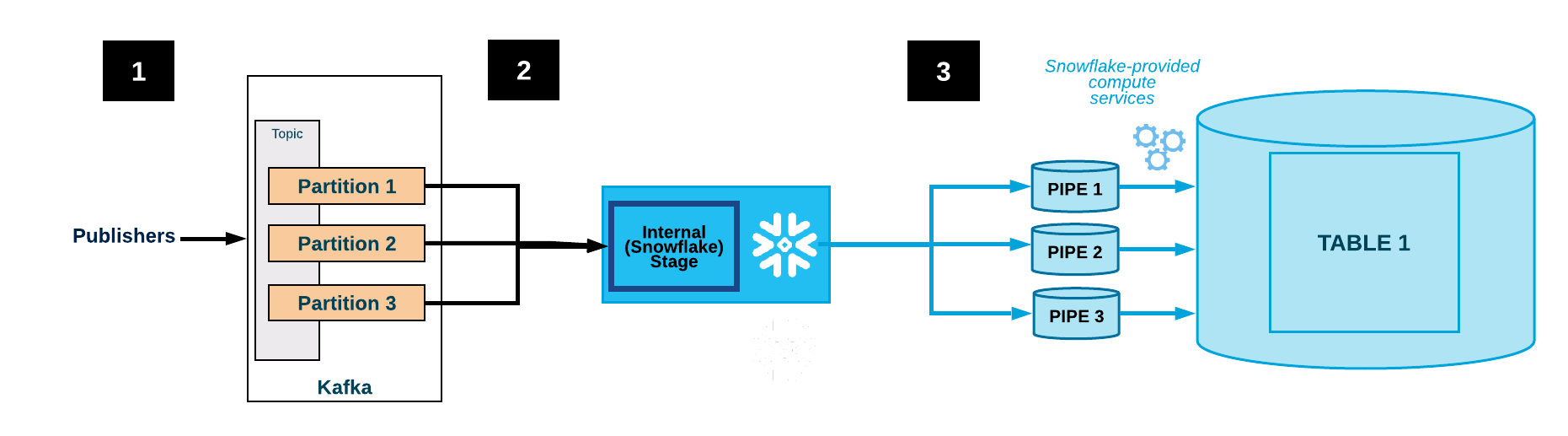
Une ou plusieurs applications publient des enregistrements JSON ou Avro dans un cluster Kafka. Les enregistrements sont divisés en une ou plusieurs partitions de sujet.
Le connecteur Kafka met en mémoire tampon les messages des sujets Kafka. Lorsqu’un seuil (temps ou mémoire ou nombre de messages) est atteint, le connecteur écrit les messages dans un fichier temporaire d’une zone de préparation interne. Le connecteur déclenche Snowpipe pour intégrer le fichier temporaire. Snowpipe copie un pointeur vers le fichier de données dans une file d’attente.
Un entrepôt virtuel fourni par Snowflake charge les données du fichier en zone de préparation dans la table cible (c’est-à-dire la table spécifiée dans le fichier de configuration du sujet) via le canal créé pour la partition de sujet Kafka.
(Ne s’affiche pas) Le connecteur surveille Snowpipe et supprime chaque fichier de la zone de préparation interne après avoir vérifié que les données du fichier ont été chargées dans la table.
Si un échec empêche le chargement des données, le connecteur déplace le fichier dans la zone de préparation de la table et génère un message d’erreur.
Le connecteur répète les étapes 2-4.
Attention
Snowflake interroge l”insertReport API pendant une heure. Si le statut d’un fichier ingéré n’aboutit pas dans l’heure qui suit, les fichiers en cours d’ingestion sont déplacés vers une zone de préparation de table.
Il faut compter au moins une heure pour que ces fichiers soient disponibles sur la zone de préparation de table. Les fichiers ne sont déplacés vers la zone de préparation de la table que lorsque leur statut d’ingestion n’a pas pu être trouvé dans l’heure précédente.
Tolérance aux pannes¶
Kafka et le connecteur Kafka sont tous deux tolérants aux pannes. Les messages ne sont ni dupliqués ni détruits en silence.
La logique de déduplication des données dans le workflow Snowpipe dans la chaîne de chargement des données élimine les copies doubles des données répétitives, sauf dans de rares cas. Si une erreur est détectée lors du chargement d’un enregistrement par Snowpipe (par exemple, l’enregistrement ne respecte pas le format JSON ou Avro), l’enregistrement n’est pas chargé ; il est déplacé vers une zone de préparation de la table.
Le connecteur Kafka avec Snowpipe Streaming prend en charge les files d’attente de lettres mortes (DLQ) pour la gestion des erreurs. Pour plus d’informations, reportez-vous à Gestion des erreurs et propriétés DLQ du connecteur Kafka avec Snowpipe Streaming.
Limitations de la tolérance aux pannes avec le connecteur¶
Les sujets Kafka peuvent être configurés avec une limite d’espace de stockage ou de durée de conservation.
La durée de conservation par défaut est de 7 jours. Si le système est hors ligne pendant une durée supérieure à la durée de conservation, les enregistrements expirés ne seront pas chargés. De même, si la limite d’espace de stockage de Kafka est dépassée, certains messages ne seront pas remis.
Si les messages du sujet Kafka sont supprimés ou mis à jour, ces modifications risquent de ne pas être reflétées dans la table Snowflake.
Attention
Les instances du connecteur Kafka ne communiquent pas entre elles. Si vous démarrez plusieurs instances du connecteur Snowflake pour Apache Kafka sur les mêmes sujets ou partitions, plusieurs copies de la même ligne peuvent être insérées dans la table. Ceci n’est pas recommandé. Chaque sujet doit être traité par une seule instance du connecteur.
Il est théoriquement possible que les messages de Kafka soient transmis plus rapidement que Snowflake ne peut les ingérer. En pratique, cependant, cela est peu probable. Si cela se produit, la résolution du problème nécessite un réglage des performances du cluster Kafka Connect. Par exemple :
Réglage du nombre de nœuds du cluster Connect.
Réglage du nombre de tâches attribuées au connecteur.
Comprendre l’impact de la bande passante du réseau entre le déploiement du connecteur et celui de Snowflake.
Important
Il n’est pas garanti que les lignes soient insérées dans l’ordre dans lequel elles ont été publiées à l’origine.
Plateformes prises en charge¶
Le connecteur Kafka peut fonctionner dans n’importe quel cluster Kafka Connect et peut envoyer des données à un compte Snowflake sur n’importe quelle plate-forme Cloud prise en charge.
Prise en charge des données Protobuf¶
Le connecteur Kafka 1.5.0 (ou supérieur) prend en charge Protocol Buffers (protobuf) via un convertisseur protobuf. Pour plus de détails, voir Chargement de données Protobuf à l’aide du connecteur Snowflake pour Kafka.
Informations de facturation¶
Il n’y a pas de frais directs pour l’utilisation du connecteur Kafka. Cependant, il existe des coûts indirects :
Snowpipe est utilisé pour charger les données lues par le connecteur depuis Kafka, et le temps de traitement de Snowpipe est celui qui est facturé sur votre compte.
Le stockage des données est facturé sur votre compte.
Limitations du connecteur Kafka¶
Les SMTs (Single Message Transformations) sont appliqués aux messages lorsqu’ils transitent par Kafka Connect. Lorsque vous configurez Propriétés de configuration de Kafka, si vous définissez soit key.converter soit value.converter sur l’une des valeurs suivantes, alors les SMTs ne sont pas pris en charge sur la clé ou la valeur correspondante :
com.snowflake.kafka.connector.records.SnowflakeJsonConvertercom.snowflake.kafka.connector.records.SnowflakeAvroConvertercom.snowflake.kafka.connector.records.SnowflakeAvroConverterWithoutSchemaRegistry
Lorsque ni key.converter ni value.converter n’est défini, la plupart des SMTs sont pris en charge, à l’exception actuelle de regex.router.
Bien que les convertisseurs Snowflake ne prennent pas en charge les SMTs, la version du connecteur Kafka 1.4.3 (ou supérieure) prend en charge de nombreux convertisseurs communautaires tels que les suivants :
io.confluent.connect.avro.AvroConverterorg.apache.kafka.connect.json.JsonConverter
Pour plus d’informations sur les SMTs, voir https://docs.confluent.io/current/connect/transforms/index.html.