Important
- Advance notice: The classic Kafka connector (v3 and earlier) is fully supported today, but it is planned for future deprecation.
- Action: No immediate changes are required. Your current workloads are safe and continue to be fully supported.
- Timeline: Snowflake plans to issue a formal deprecation announcement in mid-2026. After the announcement, an 18-month migration window begins before end-of-life.
- Recommendation: Use the Snowflake Connector for Kafka (v4) for all new implementations.
For migration guidance, see Migrate from v3 to v4.
Overview of the Kafka connector¶
This topic provides an overview of the Apache Kafka and the Snowflake Connector for Kafka.
Note
The Kafka connector is subject to the Connector Terms.
Introduction to Apache Kafka¶
Apache Kafka software uses a publish and subscribe model to write and read streams of records, similar to a message queue or enterprise messaging system. Kafka allows processes to read and write messages asynchronously. A subscriber does not need to be connected directly to a publisher; a publisher can queue a message in Kafka for the subscriber to receive later.
An application publishes messages to a topic, and an application subscribes to a topic to receive those messages. Kafka can process, as well as transmit, messages; however, that is outside the scope of this document. Topics can be divided into partitions to increase scalability.
Kafka Connect is a framework for connecting Kafka with external systems, including databases. A Kafka Connect cluster is a separate cluster from the Kafka cluster. The Kafka Connect cluster supports running and scaling out connectors (components that support reading and/or writing between external systems).
The Kafka connector is designed to run in a Kafka Connect cluster to read data from Kafka topics and write the data into Snowflake tables.
Snowflake provides two versions of the connector:
-
A version for the Confluent package version of Kafka.
For more information about Kafka Connect, see https://docs.confluent.io/current/connect/.
Note
A hosted version of the Kafka connector is available in Confluent Cloud. For information, see https://docs.confluent.io/current/cloud/connectors/cc-snowflake-sink.html.
-
A version for the open source software (OSS) Apache Kafka package.
For more information about Apache Kafka, see https://kafka.apache.org/.
From the perspective of Snowflake, a Kafka topic produces a stream of rows to be inserted into a Snowflake table. In general, each Kafka message contains one row.
Kafka, like many message publish/subscribe platforms, allows a many-to-many relationship between publishers and subscribers. A single application can publish to many topics, and a single application can subscribe to multiple topics. With Snowflake, the typical pattern is that one topic supplies messages (rows) for one Snowflake table.
The current version of the Kafka connector is limited to loading data into Snowflake. The Kafka connector supports two data loading methods:
For more information, refer to Load Data into Snowflake and Using Snowflake Connector for Kafka With Snowpipe Streaming.
Target tables for Kafka topics¶
Kafka topics can be mapped to existing Snowflake tables in the Kafka configuration. If the topics are not mapped, then the Kafka connector creates a new table for each topic using the topic name.
The connector converts the topic name to a valid Snowflake table name using the following rules:
- Lowercase topic names are converted to uppercase table names.
- If the first character in the topic name is not a letter (
a-z, orA-Z) or an underscore character (_), then the connector prepends an underscore to the table name. - If any character inside the topic name is not a legal character for a Snowflake table name, then that character is replaced with the underscore character. For more information about which characters are valid in table names, see Identifier requirements.
Note that if the Kafka connector needs to adjust the name of the table created for a Kafka topic, it is possible that the names of two tables in the same schema could be identical. For example, if you are reading data from topics numbers+x and numbers-x, the tables created for these topics would both be NUMBERS_X. To avoid accidental duplication of table names, the connector appends a suffix to the table name. The suffix is an underscore followed by a generated hash code.
Tip
Snowflake recommends that, when possible, you choose topic names that follow the rules for Snowflake identifier names.
Schema of tables for Kafka topics¶
The schema for a table loaded by the Kafka connector depends on the table type and how you configure the connector:
- Most tables use the default schema described in this section.
- When you use schema detection and evolution, the schema contains columns that match the user-defined schema.
- When you ingest into an Iceberg table, the schema includes the same default columns (
record_contentandrecord_metadata). However, they are structured type columns instead of VARIANT.
By default, with Snowpipe or Snowpipe Streaming, every Snowflake table loaded by the Kafka connector has a schema consisting of two VARIANT columns:
- RECORD_CONTENT. This contains the Kafka message.
- RECORD_METADATA. This contains metadata about the message, for example, the topic from which the message was read.
If Snowflake creates the table, then the table contains only these two columns. If the user creates the table for the Kafka Connector to add rows to, then the table can contain more than these two columns (any additional columns must allow NULL values because data from the connector does not include values for those columns).
The RECORD_CONTENT column contains the Kafka message.
A Kafka message has an internal structure that depends upon the information being sent. For example, a message from an IoT (Internet of Things) weather sensor might include the timestamp at which the data was recorded, the location of the sensor, the temperature, humidity, etc. A message from an inventory system might include the product ID and the number of items sold, perhaps along with a timestamp indicating when they were sold or shipped.
Typically, each message in a specific topic has the same basic structure. Different topics typically use different structure.
Each Kafka message is passed to Snowflake in JSON format or Avro format. The Kafka connector stores that formatted information in a single column of type VARIANT. The data is not parsed, and the data is not split into multiple columns in the Snowflake table.
The RECORD_METADATA column contains the following information by default:
| Field | Java Data Type | SQL Data Type | Required | Description |
|---|---|---|---|---|
| topic | String | VARCHAR | Yes | The name of the Kafka topic that the record came from. |
| partition | String | VARCHAR | Yes | The number of the partition within the topic. (Note that this is the Kafka partition, not the Snowflake micro-partition.) |
| offset | long | INTEGER | Yes | The offset in that partition. |
| CreateTime / LogAppendTime | long | BIGINT | No | This is the timestamp associated with the message in the Kafka topic. The value is milliseconds since midnight January 1, 1970, UTC. For more information, see: https://kafka.apache.org/0100/javadoc/org/apache/kafka/clients/producer/ProducerRecord.html |
| SnowflakeConnectorPushTime | long | BIGINT | No | Available only when using Snowpipe Streaming. A timestamp when a record was pushed into an Ingest SDK buffer. The value is the number of milliseconds since midnight January 1, 1970, UTC. For more information, see Estimating ingestion latency. |
| key | String | VARCHAR | No | If the message is a Kafka KeyedMessage, this is the key for that message. In order for the connector to store the key in the RECORD_METADATA, the key.converter parameter in the Kafka configuration properties must be set to “org.apache.kafka.connect.storage.StringConverter”; otherwise, the connector ignores keys. |
| schema_id | int | INTEGER | No | When using Avro with a schema registry to specify a schema, this is the schema’s ID in that registry. |
| headers | Object | OBJECT | No | A header is a user-defined key-value pair associated with the record. Each record can have 0, 1, or multiple headers. |
The amount of metadata recorded in the RECORD_METADATA column is configurable using optional Kafka configuration properties. For information, see Installing and configuring the Kafka connector.
The field names and values are case-sensitive.
Expressed in JSON syntax, a sample message might look similar to the following:
You can query the Snowflake tables directly by using the appropriate syntax for querying VARIANT columns.
Here is a simple example of extracting data based on the topic in the RECORD_METADATA:
The output would look similar to:
Alternatively, you can extract the data from these tables, flatten the data into individual columns, and store the data in other tables, which typically are easier to query.
Workflow for the Kafka connector¶
The Kafka connector completes the following process to subscribe to Kafka topics and create Snowflake objects:
- The Kafka connector subscribes to one or more Kafka topics based on the configuration information provided via the Kafka configuration file or command line (or the Confluent Control Center; Confluent only).
- The connector creates the following objects for each topic:
- One internal stage to temporarily store data files for each topic.
- One pipe to ingest the data files for each topic partition.
- One table for each topic. If the table specified for each topic does not exist, the connector creates it; otherwise, the connector creates the RECORD_CONTENT and RECORD_METADATA columns in the existing table and verifies that the other columns are nullable (and produces an error if they are not).
The following diagram shows the ingest flow for Kafka with the Kafka connector:
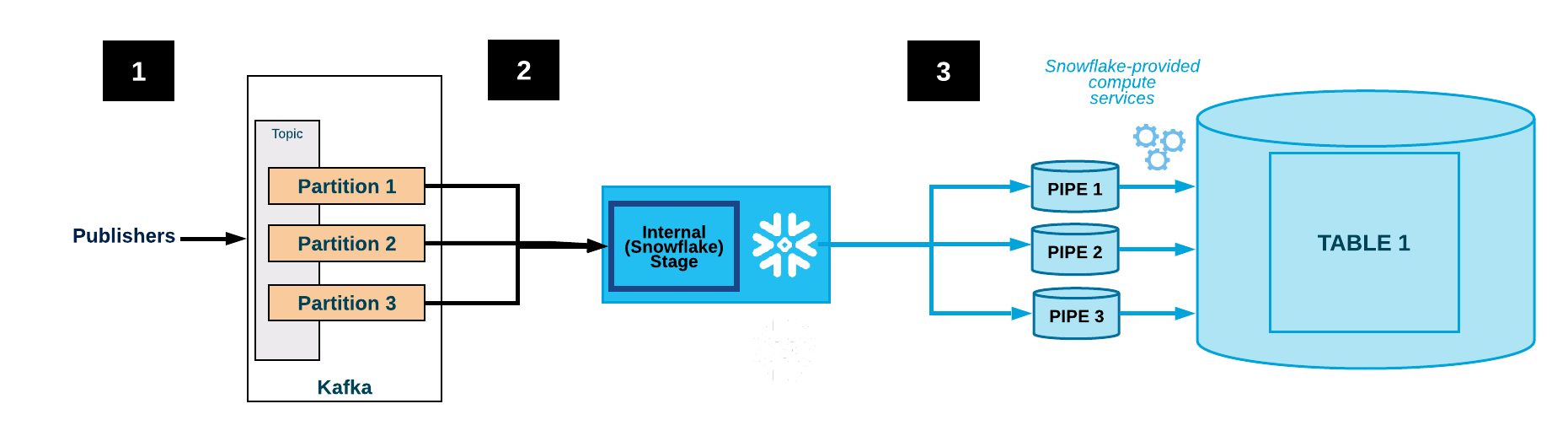
-
One or more applications publish JSON or Avro records to a Kafka cluster. The records are split into one or more topic partitions.
-
The Kafka connector buffers messages from the Kafka topics. When a threshold (time or memory or number of messages) is reached, the connector writes the messages to a temporary file in the internal stage. The connector triggers Snowpipe to ingest the temporary file. Snowpipe copies a pointer to the data file into a queue.
-
A Snowflake-provided virtual warehouse loads data from the staged file into the target table (i.e. the table specified in the configuration file for the topic) via the pipe created for the Kafka topic partition.
-
(Not shown) The connector monitors Snowpipe and deletes each file in the internal stage after confirming that the file data was loaded into the table.
If a failure prevented the data from loading, the connector moves the file into the table stage and produces an error message.
-
The connector repeats steps 2-4.
Attention
Snowflake polls the insertReport API for one hour. If the status of an ingested file does not
succeed within this hour, the files being ingested are moved to a table stage.
It may take at least one hour for these files to be available on the table stage. Files are only moved to the table stage when their ingestion status could not be found within the previous hour.
Fault tolerance¶
Both Kafka and the Kafka connector are fault-tolerant. Messages are neither duplicated nor silently dropped.
Data deduplication logic in the Snowpipe workflow in the data loading chain eliminates duplicate copies of repeating data except in rare cases. If an error is detected while Snowpipe loads a record (for example, the record was not well-formed JSON or Avro), then the record is not loaded; instead, the record is moved to a table stage.
The Kafka connector with Snowpipe Streaming supports dead-letter queues (DLQ) for error handling. For more information, refer to Error Handling and DLQ Properties for the Kafka Connector with Snowpipe Streaming.
Limitations of fault tolerance with the connector¶
Kafka Topics can be configured with a limit on storage space or retention time.
- The default retention time is 7 days. If the system is offline for more than the retention time, then expired records will not be loaded. Similarly, if Kafka’s storage space limit is exceeded, some messages will not be delivered.
- If messages in the Kafka topic are deleted or updated, these changes might not be reflected in the Snowflake table.
Attention
Instances of the Kafka connector do not communicate with each other. If you start multiple instances of the connector on the same topics or partitions, then multiple copies of the same row might be inserted into the table. This is not recommended; each topic should be processed by only one instance of the connector.
It is theoretically possible for messages to flow from Kafka faster than Snowflake can ingest them. In practice, however, this is unlikely. If it does occur, then solving the problem would require performance tuning of the Kafka Connect cluster. For example:
- Tuning the number of nodes in the Connect cluster.
- Tuning the number of tasks allocated to the connector.
- Understanding the impact of the network bandwidth between the connector and the Snowflake deployment.
Important
There is no guarantee that rows are inserted in the order that they were originally published.
Supported platforms¶
The Kafka connector can run in any Kafka Connect cluster, and can send data to a Snowflake account on any supported cloud platform.
Protobuf data support¶
Kafka connector 1.5.0 (or higher) supports protocol buffers (protobuf) via a protobuf converter. For details, see Loading protobuf data using the Snowflake Connector for Kafka.
Billing information¶
There is no direct charge for using the Kafka connector. However, there are indirect costs:
- Snowpipe is used to load the data that the connector reads from Kafka, and Snowpipe processing time is charged to your account.
- Data storage is charged to your account.
Kafka connector limitations¶
Single Message Transformations (SMTs) are applied to messages as they flow through Kafka Connect. When you configure the Kafka configuration properties, if you set either key.converter or value.converter to one of the following values, then SMTs are not supported on the corresponding key or value:
com.snowflake.kafka.connector.records.SnowflakeJsonConvertercom.snowflake.kafka.connector.records.SnowflakeAvroConvertercom.snowflake.kafka.connector.records.SnowflakeAvroConverterWithoutSchemaRegistry
When neither key.converter or value.converter is set, then most SMTs are supported, with the current exception of regex.router.
Although the Snowflake converters do not support SMTs, Kafka connector version 1.4.3 (or higher) supports many community-based converters such as the following:
io.confluent.connect.avro.AvroConverterorg.apache.kafka.connect.json.JsonConverter
For more information about SMTs, see https://docs.confluent.io/current/connect/transforms/index.html.