Snowflake ML: 엔드투엔드 머신 러닝¶
Snowflake ML은 관리 데이터를 기반으로 단일 플랫폼에서 엔드투엔드 머신 러닝을 위한 통합 기능 세트입니다. ML 개발 및 생산화를 위한 통합 환경으로, CPU 및 GPU 컴퓨팅에서 대규모 분산 특성 공학, 모델 학습 및 추론에 최적화되어 별도의 튜닝이나 구성 없이도 사용할 수 있습니다.
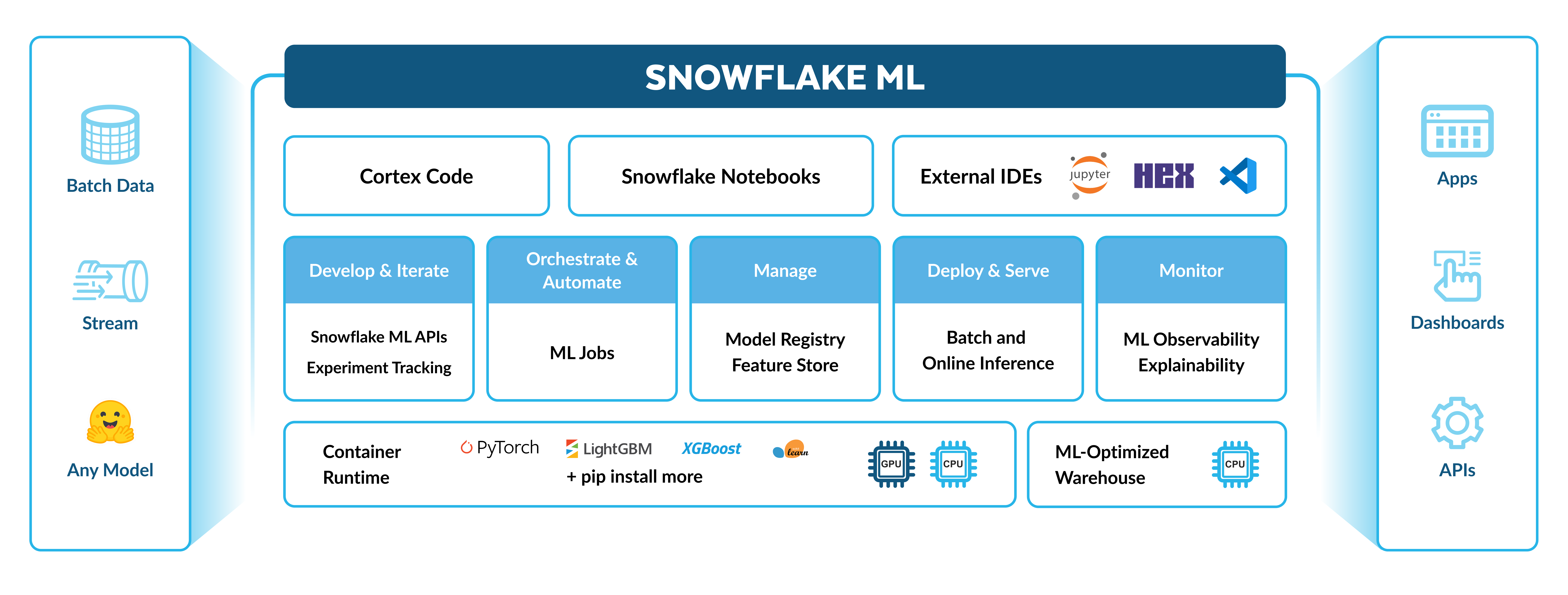
Snowflake에서 엔드투엔드 ML 워크플로를 원활하게 확장할 수 있습니다. 다음을 수행할 수 있습니다.
데이터 준비하기
Snowflake Feature Store로 특성 생성 및 사용하기
CPUs 또는 GPUs에서 Container Runtime의 Snowflake Notebooks 오픈 소스 패키지를 사용하여 모델 학습시키기
설정된 메트릭에 대해 학습된 모델을 평가하는 실험 만들기
Snowflake ML Jobs를 사용한 파이프라인 운영하기
Snowflake Model Registry를 사용하여 추론을 위한 모델을 대규모로 배포
ML Observability 및 Explainability로 생산 모델 모니터링하기
ML Lineage를 사용하여 ML 파이프라인을 통해 소스 데이터에서 특성, 데이터 세트, 모델까지 추적하기
Snowflake ML 또한 유연하고 모듈식입니다. Snowflake에서 개발한 모델을 외부에 배포할 수 있으며, 외부에서 학습한 모델을 Snowflake로 쉽게 가져와 추론할 수 있습니다.
데이터 과학자 및 ML 엔지니어를 위한 기능¶
Container Runtime의 Snowflake Notebooks¶
Container Runtime의 Snowflake Notebooks 는 인프라 관리 없이도 Snowflake에서 대규모 모델을 학습시키고 파인 튜닝할 수 있는 Jupyter와 유사한 환경을 제공합니다. PyTorch, XGBoost 또는 Scikit-learn과 같은 사전 설치된 패키지로 학습을 시작하거나 HuggingFace 또는 PyPI 와 같은 오픈 소스 리포지토리에서 패키지를 설치하십시오. Container Runtime은 매우 효율적인 데이터 로딩, 분산 모델 학습, 하이퍼 매개 변수 튜닝을 제공하기 위해 Snowflake의 인프라에서 실행되도록 최적화되어 있습니다.
Snowflake 기능 스토어¶
Snowflake 기능 스토어 는 데이터에서 파생된 ML 특성을 정의, 관리, 저장, 검색할 수 있는 통합 솔루션입니다. Snowflake Feature Store는 일괄 처리 및 스트리밍 데이터 소스에서 자동화된 증분 새로 고침을 지원하므로, 기능 파이프라인을 한 번만 정의하면 새 데이터로 지속적으로 업데이트할 수 있습니다.
ML Jobs¶
:doc:`/developer-guide/snowflake-ml/ml-jobs/overview`를 사용하면 ML 파이프라인을 개발 및 자동화할 수 있습니다. ML Jobs를 통해 IDE(VS 코드, PyCharm, SageMaker Notebooks) 외부에서 작업하는 것을 선호하는 팀에서는 Snowflake의 Container Runtime으로 함수나 파일 또는 모듈을 디스패치할 수 있습니다.
실험¶
:doc:`실험</developer-guide/snowflake-ml/experiments>`을 사용하여 모델 학습 결과를 기록하고 조직화된 방식으로 모델 컬렉션을 평가합니다. 실험은 사용 사례에 가장 적합한 모델을 선택하여 프로덕션에 라이브로 제공하는 데 도움이 됩니다. 학습은 Snowflake에서 모델 학습 중에 실험에 기록하거나 이전 학습으로부터 자체 메타데이터와 아티팩트를 업로드할 수 있습니다. 학습을 마친 후 Snowsight 에서 모든 결과를 확인하고 요구 사항에 적합한 모델을 선택합니다.
Snowflake Model Registry 및 Model Serving¶
Snowflake Model Registry 에서는 Snowflake 또는 다른 플랫폼에서 학습받았는지 여부에 관계없이 모든 ML 모델을 로그하고 관리할 수 있습니다. Model Registry의 모델을 사용하여 대규모로 추론을 실행할 수 있습니다. Model Serving을 사용하여 추론을 위해 Snowpark Container Service에 모델을 배포할 수 있습니다.
ML Observability¶
ML Observability 는 Snowflake에서 모델 성능 메트릭을 모니터링하는 도구를 제공합니다. 프로덕션 환경의 모델을 추적하고, 성능 및 드리프트 메트릭을 모니터링하고, 성능 임계값에 대한 경고를 설정할 수 있습니다. 또한 ML Explainability 함수를 사용하여 학습된 위치에 관계없이 Snowflake Model Registry에 있는 모델에 대한 Shapley 값을 계산할 수 있습니다.
ML 계보¶
ML Lineage 는 원본 데이터에서 특성, 데이터 세트 및 모델에 이르기까지 ML 아티팩트의 엔드투엔드 계보를 추적할 수 있는 기능입니다. 이를 통해 ML 에셋의 전체 수명 주기에서 재현성, 규정 준수 및 디버깅이 가능합니다.
Snowflake 데이터 세트¶
Snowflake Datasets 는 머신 러닝 모델에서 수집하기에 적합한 버전이 변경되지 않는 데이터 스냅샷을 제공합니다.
비즈니스 분석가를 위한 기능¶
비즈니스 분석가의 경우, ML 함수 를 사용하여 SQL 로 조직 전체에서 예측 및 이상 징후 탐지와 같은 일반적인 시나리오의 개발 시간을 단축하십시오.
추가 리소스¶
Snowflake ML 을 시작하려면 다음 리소스를 참조하십시오.
현재 개발 중인 다른 특징에 대한 설명서를 일찍 살펴보고 싶으신 분은 Snowflake 담당자에게 문의하십시오.