변칙 감지(Snowflake ML 함수)¶
개요¶
변칙 검색은 데이터에서 이상값을 식별하는 프로세스입니다. 변칙 감지 함수를 사용하면 시계열 데이터에서 이상값을 감지하는 모델을 훈련시킬 수 있습니다. 예상 범위에서 벗어나는 데이터 요소인 이상값은 데이터에서 파생된 통계 및 모델에 막대한 영향을 미칠 수 있습니다. 따라서 이상값을 찾아 제거하면 결과의 질을 개선하는 데 도움이 될 수 있습니다.
참고
Anomaly Detection은 머신 러닝을 기반으로 하는 Snowflake의 비즈니스 분석 도구 모음의 일부입니다.
이상값 감지 기능은 명백한 원인이 없을 때 문제의 원인이나 프로세스의 편차를 정확히 찾아내는 데 유용할 수 있습니다. 예:
로깅 파이프라인에서 문제가 발생하기 시작한 시점 확인하기.
Snowflake 컴퓨팅 비용이 예상보다 높은 날 식별하기.
변칙 검색은 단일 계열 또는 다중 계열의 데이터에서 작동합니다. 다중 계열 데이터는 여러 객의 독립적인 이벤트 스레드를 나타냅니다. 예를 들어 여러 매장의 매출 데이터가 있는 경우 매장 식별자를 기반으로 단일 모델별로 각 매장의 매출을 따로 확인할 수 있습니다.
데이터에는 다음을 포함해야 합니다.
타임스탬프 열.
각 타임스탬프에서 몇몇 관심 수량을 나타내는 대상 열.
참고
이상적으로는 Anomaly Detection 모델의 훈련 데이터에 동일한 간격(예: 매일)의 시간 스텝이 있는 것이 좋습니다. 그러나 모델 훈련은 누락되거나 중복되거나 잘못 정렬된 시간 단계가 있는 실제 데이터를 처리할 수 있습니다. 자세한 내용은 시계열 예측에서 실제 데이터 처리 섹션을 참조하십시오.
시계열 데이터에서 이상값을 감지하려면 Snowflake 기본 제공 클래스 ANOMALY_DETECTION(SNOWFLAKE.ML) 를 사용하고 다음 단계를 따르십시오.
변칙 검색 오브젝트를 생성하여 학습 데이터에 대한 참조를 전달합니다.
이 오브젝트는 사용자가 제공한 훈련 데이터에 모델을 맞추는 역할을 합니다. 이 모델은 스키마 수준 오브젝트입니다.
이 변칙 검색 모델 오브젝트를 사용하여 변칙을 검색하는 <model_name>!DETECT_ANOMALIES 메서드를 호출하여 분석할 데이터에 대한 참조를 전달합니다.
이 메서드는 이 모델을 사용하여 데이터의 이상값을 식별합니다.
변칙 검색은 예측 과 밀접한 관련이 있습니다. 변칙 검색 모델은 변칙을 확인하는 데이터와 동일한 기간 동안 예측을 생성한 다음, 실제 데이터를 예측과 비교하여 이상값을 식별합니다.
중요
법적 고지. 이 Snowflake ML 함수는 머신 러닝 기술로 구동되며, 사용 시기와 방법은 Snowflake가 아닌 사용자가 결정합니다. 제공된 머신 러닝 기술 및 결과는 부정확하거나 부적절하거나 편향될 수 있습니다. Snowflake는 자체 워크플로 내에서 사용할 수 있는 머신 러닝 모델을 제공합니다. 자동 파이프라인에 내장된 결과를 포함하여 머신 러닝 출력을 기반으로 한 의사 결정에는 모델 생성 콘텐츠가 정확하도록 보장하기 위해 사람의 감독 및 검토 프로세스가 있어야 합니다. Snowflake는 알고리즘(사전 학습되지 않음)을 제공하며, 알고리즘에 제공하는 데이터(예: 학습 및 추론) 및 결과 모델의 출력을 사용하여 내리는 의사결정에 대한 책임은 사용자에게 있습니다. 이 함수 또는 함수에 대한 쿼리는 다른 SQL 쿼리와 같이 취급되며 메타데이터 로 간주될 수 있습니다.
메타데이터. Snowflake ML 함수를 사용하면 ML 함수에서 반환된 일반 오류 메시지를 Snowflake에 로그합니다. 이러한 오류 로그는 발생하는 문제를 해결하고 이러한 함수를 개선하여 더 나은 서비스를 제공하는 데 도움이 됩니다.
자세한 내용은 Snowflake AI 신뢰 및 안전 FAQ 를 참조하십시오.
변칙 검색 알고리즘 정보¶
변칙 검색 알고리즘은 그라데이션 부스팅 머신 (GBM)으로 구동됩니다. ARIMA 모델과 마찬가지로, 이 알고리즘은 차분 변환을 사용하여 비정상 추세로 데이터를 모델링하고 과거 대상 데이터의 자동 회귀 지연을 모델 변수로 사용합니다.
또한 이 알고리즘은 과거 대상 데이터의 이동 평균을 사용하여 추세를 예측하는 데 도움을 주고, 타임스탬프 데이터에서 주기적인 캘린더 변수(예: 요일 및 주)를 자동으로 생성합니다.
과거 대상 및 타임스탬프 데이터만 있는 모델을 맞추거나 대상 값에 영향을 미쳤을 수 있는 외생 데이터(변수)를 포함할 수 있습니다. 외생 변수는 숫자형이나 범주형일 수 있으며 NULL일 수도 있습니다(외생 변수에 대해 NULL을 포함하는 행은 삭제되지 않음).
이 알고리즘은 범주형 변수에 대한 학습 시 원-핫 인코딩에 의존하지 않으므로, 차원이 많은(카디널리티가 높음) 범주형 데이터를 사용할 수 있습니다.
모델에 외생 변수가 포함된 경우 변칙 검색 시 미래의 타임스탬프에서 해당 변수의 값을 입력해야 합니다. 알맞은 외생 변수로는 날씨 데이터(기온, 강우량), 회사별 정보(과거 및 예정된 회사 휴무일, 광고 캠페인, 이벤트 일정) 또는 대상 변수를 예측하는 데 도움이 될 수 있다고 생각하는 기타 외부 요인을 들 수 있습니다.
선택적으로, 별개의 부울 열을 사용하여 개별 기록 행에 변칙 또는 비변칙 레이블을 지정할 수 있습니다.
예측 구간 은 특정 비율의 데이터가 속할 가능성이 있는 상한과 하한 내 값의 추정 범위입니다. 예를 들어 0.99의 값은 데이터 중 99%가 이 구간 내에서 나타날 가능성이 있다는 의미입니다. 변칙 검색 모델은 예측 구간을 벗어나는 모든 데이터를 변칙으로 식별합니다. 예측 구간을 지정하거나 기본값인 0.99를 사용할 수 있습니다. 이 값을 1.0에 매우 가까운 값, 예컨대 0.9999 또는 그보다 더 가까운 값으로 설정할 수 있습니다.
중요
Snowflake는 수시로 변칙 감지 알고리즘을 개선할 수 있습니다. 이러한 개선 사항은 Snowflake 정기 릴리스 프로세스를 통해 적용됩니다. 이 기능의 이전 버전으로 되돌릴 수는 없지만, 이전 버전으로 생성한 모델은 변칙 감지를 위해 해당 버전을 계속 사용합니다.
제한 사항¶
변칙 검색 알고리즘을 선택하거나 조정할 수 없습니다. 특히, 알고리즘은 추세, 계절성 또는 계절적 진폭을 재정의하는 매개 변수를 제공하지 않습니다. 이들은 데이터에서 유추됩니다.
주 변칙 검색 알고리즘의 최소 행 수는 시계열당 12개입니다. 2에서 11 사이의 관측값이 있는 시계열의 경우 변칙 검색은 모든 예측 값이 마지막으로 관측된 목표 값과 같은 “나이브한” 결과를 생성합니다. 레이블이 지정된 변칙 검색 사례의 경우 사용된 관측값 수는 레이블 열이 false인 행 수입니다.
허용 가능한 최소 데이터 세분성은 1초입니다. (타임스탬프의 간격이 1초 이상이어야 합니다.)
계절적 구성 요소의 최소 세분성은 1분입니다. (이 함수는 더 작은 시간 델타에서 주기적 패턴을 감지할 수 없습니다.)
자동 회귀 기능의 “계절 길이”는 입력 빈도(시간별 데이터의 경우 24, 일별 데이터의 경우 7 등)에 연결됩니다.
일단 학습시킨 변칙 검색 모델은 변경할 수 없습니다. 새 데이터로 기존 모델을 업데이트할 수 없으며 완전히 새 모델을 학습시켜야 합니다. 모델은 버전 관리를 지원하지 않습니다. 일반적으로 새로운 데이터를 수신하는 빈도에 따라 하루에 한 번, 일주일에 한 번, 한 달에 한 번 등 일정한 주기로 모델을 재훈련시켜 모델이 변화하는 트렌드를 따라잡을 수 있도록 해야 합니다.
이 기능은 테스트 데이터의 변칙만 감지하며, 훈련 데이터의 변칙은 감지하지 못합니다. 또한 테스트 데이터의 타임스탬프는 모두 훈련 데이터의 타임스탬프보다 커야 합니다. 학습 데이터가 실제 이상값이 없는 일반적인 기간을 포함하도록 하거나 부울 열에서 알려진 이상값에 레이블을 지정하십시오.
모델을 복제하거나 역할 또는 계정 간에 모델을 공유할 수 없습니다. 스키마 또는 데이터베이스를 복제할 때 모델 오브젝트를 건너뜁니다.
ANOMALY_DETECTION 클래스의 인스턴스를 복제 할 수 없습니다.
변칙 검색 준비하기¶
변칙 검색을 사용하려면 먼저 다음을 수행해야 합니다.
모델을 학습시키고 실행할 가상 웨어하우스를 선택합니다.
SNOWFLAKE.ML을 포함하도록 검색 경로를 수정 할 수도 있습니다.
가상 웨어하우스 선택하기¶
Snowflake 가상 웨어하우스 는 이 기능에 대한 머신 러닝 모델의 훈련 및 사용을 위한 컴퓨팅 리소스를 제공합니다. 이 섹션에서는 학습 단계(프로세스에서 가장 시간이 많이 걸리고 메모리 집약적인 부분)에 중점을 두고서 이 목적에 가장 적합한 웨어하우스 크기 및 유형을 선택하는 방법에 대한 일반적인 지침을 제공합니다.
단일 계열 데이터를 기반으로 학습시키기¶
단일 계열 데이터에 대해 학습된 모델의 경우 학습 데이터의 크기를 기준으로 웨어하우스 유형을 선택해야 합니다. 표준 웨어하우스는 Snowpark 메모리 한도 가 더 낮으며 행 수가 적거나 외생적 특징이 있는 학습 작업에 더 적합합니다. 훈련 데이터에 외생적 기능이 포함되어 있지 않은 경우, 데이터 세트의 행 수가 5백만 개 이하인 경우 표준 웨어하우스에서 훈련시킬 수 있습니다. 학습 데이터가 5개 이상의 외생적 특징을 사용하는 경우 최대 행 수가 적습니다. 그렇지 않은 경우 대규모 학습 작업을 위해 Snowpark에 최적화된 웨어하우스 를 사용하는 것이 좋습니다.
일반적으로 단일 계열 데이터의 경우 웨어하우스 크기가 커진다고 해서 학습 시간이 빨라지거나 메모리 제한이 높아지지는 않습니다. 대략적인 경험 법칙에 따르면 학습 시간은 시계열의 행 수에 비례합니다. 예를 들어, 평가가 꺼져 있는(CONFIG_OBJECT => {'evaluate': False}) XS 표준 웨어하우스에서 10만 개 행 데이터 세트에 대한 훈련에는 약 60초가 걸리고, 100만 개 행 데이터 세트에 대한 훈련에는 약 125초가 걸립니다. 평가를 켜면 훈련 시간은 사용한 분할 수에 따라 거의 선형적으로 증가합니다.
최상의 성능을 위해 모델을 학습하기 위한 다른 동시 워크로드 없이 전용 웨어하우스를 사용하는 것이 좋습니다.
다중 계열 데이터에 대한 학습¶
단일 계열 데이터와 마찬가지로, 가장 큰 시계열의 행 수를 기반으로 웨어하우스 유형을 선택하십시오. 가장 큰 시계열에 5백만 개 이상의 행이 포함된 경우 학습 작업이 표준 웨어하우스의 메모리 제한을 초과할 가능성이 큽니다.
단일 계열 데이터와 달리, 다중 계열 데이터는 더 큰 웨어하우스 크기에서 훨씬 더 빠르게 학습됩니다. 다음 데이터 요소가 선택의 안내자 역할을 할 수 있습니다. 다시 말해, 이러한 모든 시간은 평가가 꺼진 상태에서 수행됩니다.
웨어하우스 유형 및 크기 |
시계열 수 |
시계열당 행 수 |
학습 시간(초) |
|---|---|---|---|
표준 XS |
1 |
100,000 |
60초 |
표준 XS |
10 |
100,000 |
204초 |
표준 XS |
100 |
100,000 |
720초 |
표준 XL |
10 |
100,000 |
104초 |
표준 XL |
100 |
100,000 |
211초 |
표준 XL |
1000 |
100,000 |
840초 |
Snowpark에 최적화된 XL |
10 |
100,000 |
65초 |
Snowpark에 최적화된 XL |
100 |
100,000 |
293초 |
Snowpark에 최적화된 XL |
1000 |
100,000 |
831초 |
변칙 검색하기¶
추론 단계는 웨어하우스 크기에 관계없이 입력 데이터 세트에서 행 100개를 처리하는 데 약 1초가 걸립니다.
변칙 검색 오브젝트 생성 권한 부여하기¶
변칙 검색 모델을 학습시키면 스키마 수준 오브젝트가 생성됩니다. 따라서 모델 생성에 사용하는 역할은 모델이 생성되는 스키마에 대한 CREATE SNOWFLAKE.ML.ANOMALY_DETECTION 권한이 있어야 스키마에 모델을 저장할 수 있습니다. 이 권한은 CREATE TABLE 또는 CREATE VIEW와 같은 다른 스키마 권한과 유사합니다.
변칙을 검색해야 하는 사람들이 사용할 analyst 라는 역할을 생성하는 것이 좋습니다.
다음 예에서 admin 역할은 스키마 admin_db.admin_schema 의 소유자입니다. analyst 역할은 이 스키마에서 모델을 생성해야 합니다.
USE ROLE admin;
GRANT USAGE ON DATABASE admin_db TO ROLE analyst;
GRANT USAGE ON SCHEMA admin_schema TO ROLE analyst;
GRANT CREATE SNOWFLAKE.ML.ANOMALY_DETECTION ON SCHEMA admin_db.admin_schema TO ROLE analyst;
이 스키마를 사용하기 위해 사용자는 analyst 역할을 맡습니다.
USE ROLE analyst;
USE SCHEMA admin_db.admin_schema;
analyst 역할이 analyst_db 데이터베이스에서 CREATE SCHEMA 권한을 가질 경우 이 역할은 새 스키마 analyst_db.analyst_schema 를 생성하고 해당 스키마에서 변칙 검색 모델을 생성할 수 있습니다.
USE ROLE analyst;
CREATE SCHEMA analyst_db.analyst_schema;
USE SCHEMA analyst_db.analyst_schema;
스키마에 대한 역할의 모델 생성 권한을 취소하려면 REVOKE <privileges> … FROM ROLE 를 사용하십시오.
REVOKE CREATE SNOWFLAKE.ML.ANOMALY_DETECTION ON SCHEMA admin_db.admin_schema FROM ROLE analyst;
예제를 위한 데이터 설정하기¶
다음 섹션의 예에서는 매일의 기상 데이터(습도 및 온도)와 함께 다양한 매장에서 판매하는 상품의 일일 매출을 포함한 샘플 데이터 세트를 사용합니다. 데이터 세트에는 해당 날짜가 휴일인지 표시하는 열도 포함됩니다.
다음 문을 실행하여 모델에 대한 학습 데이터가 포함된
historical_sales_data라는 테이블을 생성합니다.
CREATE OR REPLACE TABLE historical_sales_data ( store_id NUMBER, item VARCHAR, date TIMESTAMP_NTZ, sales FLOAT, label BOOLEAN, temperature NUMBER, humidity FLOAT, holiday VARCHAR); INSERT INTO historical_sales_data VALUES (1, 'jacket', to_timestamp_ntz('2020-01-01'), 2.0, false, 50, 0.3, 'new year'), (1, 'jacket', to_timestamp_ntz('2020-01-02'), 3.0, false, 52, 0.3, null), (1, 'jacket', to_timestamp_ntz('2020-01-03'), 5.0, false, 54, 0.2, null), (1, 'jacket', to_timestamp_ntz('2020-01-04'), 30.0, true, 54, 0.3, null), (1, 'jacket', to_timestamp_ntz('2020-01-05'), 8.0, false, 55, 0.2, null), (1, 'jacket', to_timestamp_ntz('2020-01-06'), 6.0, false, 55, 0.2, null), (1, 'jacket', to_timestamp_ntz('2020-01-07'), 4.6, false, 55, 0.2, null), (1, 'jacket', to_timestamp_ntz('2020-01-08'), 2.7, false, 55, 0.2, null), (1, 'jacket', to_timestamp_ntz('2020-01-09'), 8.6, false, 55, 0.2, null), (1, 'jacket', to_timestamp_ntz('2020-01-10'), 9.2, false, 55, 0.2, null), (1, 'jacket', to_timestamp_ntz('2020-01-11'), 4.6, false, 55, 0.2, null), (1, 'jacket', to_timestamp_ntz('2020-01-12'), 7.0, false, 55, 0.2, null), (1, 'jacket', to_timestamp_ntz('2020-01-13'), 3.6, false, 55, 0.2, null), (1, 'jacket', to_timestamp_ntz('2020-01-14'), 8.0, false, 55, 0.2, null), (2, 'umbrella', to_timestamp_ntz('2020-01-01'), 3.4, false, 50, 0.3, 'new year'), (2, 'umbrella', to_timestamp_ntz('2020-01-02'), 5.0, false, 52, 0.3, null), (2, 'umbrella', to_timestamp_ntz('2020-01-03'), 4.0, false, 54, 0.2, null), (2, 'umbrella', to_timestamp_ntz('2020-01-04'), 5.4, false, 54, 0.3, null), (2, 'umbrella', to_timestamp_ntz('2020-01-05'), 3.7, false, 55, 0.2, null), (2, 'umbrella', to_timestamp_ntz('2020-01-06'), 3.2, false, 55, 0.2, null), (2, 'umbrella', to_timestamp_ntz('2020-01-07'), 3.2, false, 55, 0.2, null), (2, 'umbrella', to_timestamp_ntz('2020-01-08'), 5.6, false, 55, 0.2, null), (2, 'umbrella', to_timestamp_ntz('2020-01-09'), 7.3, false, 55, 0.2, null), (2, 'umbrella', to_timestamp_ntz('2020-01-10'), 8.2, false, 55, 0.2, null), (2, 'umbrella', to_timestamp_ntz('2020-01-11'), 3.7, false, 55, 0.2, null), (2, 'umbrella', to_timestamp_ntz('2020-01-12'), 5.7, false, 55, 0.2, null), (2, 'umbrella', to_timestamp_ntz('2020-01-13'), 6.3, false, 55, 0.2, null), (2, 'umbrella', to_timestamp_ntz('2020-01-14'), 2.9, false, 55, 0.2, null);
다음 문을 실행하여 분석할 데이터가 포함된
new_sales_data라는 테이블을 생성합니다.
CREATE OR REPLACE TABLE new_sales_data ( store_id NUMBER, item VARCHAR, date TIMESTAMP_NTZ, sales FLOAT, temperature NUMBER, humidity FLOAT, holiday VARCHAR); INSERT INTO new_sales_data VALUES (1, 'jacket', to_timestamp_ntz('2020-01-16'), 6.0, 52, 0.3, null), (1, 'jacket', to_timestamp_ntz('2020-01-17'), 20.0, 53, 0.3, null), (2, 'umbrella', to_timestamp_ntz('2020-01-16'), 3.0, 52, 0.3, null), (2, 'umbrella', to_timestamp_ntz('2020-01-17'), 70.0, 53, 0.3, null);
모델 학습, 사용, 확인, 삭제 및 업데이트하기¶
CREATE SNOWFLAKE.ML.ANOMALY_DETECTION 를 사용하여 모델을 만들고 학습시킵니다. 이 모델은 사용자가 제공한 데이터 세트를 기반으로 학습됩니다.
CREATE SNOWFLAKE.ML.ANOMALY_DETECTION mydetector(...);
SNOWFLAKE.ML.ANOMALY_DETECTION 생성자에 대한 자세한 내용은 ANOMALY_DETECTION(SNOWFLAKE.ML) 섹션을 참조하십시오. 모델 생성의 예는 변칙 검색하기 섹션을 참조하십시오.
참고
SNOWFLAKE.ML.ANOMALY_DETECTION은 제한된 권한을 사용하여 실행되므로, 기본적으로 데이터에 액세스할 수 없습니다. 따라서 호출자의 권한을 전달하는 참조 로 테이블과 뷰를 전달해야 합니다. 테이블 또는 뷰에 대한 참조 대신 쿼리 참조 를 제공할 수도 있습니다.
이 참조를 생성하려면 테이블 이름, 뷰 이름 또는 쿼리와 함께 TABLE 키워드 를 사용하거나 SYSTEM$REFERENCE 또는 SYSTEM$QUERY_REFERENCE 함수를 호출하면 됩니다.
변칙을 검색하려면 모델의 <model_name>!DETECT_ANOMALIES 메서드를 호출하십시오.
CALL mydetector!DETECT_ANOMALIES(...);
메서드의 테이블 형식 출력에서 열을 선택하려면 FROM 절에서 메서드를 호출 하면 됩니다.
SELECT ts, forecast FROM TABLE(mydetector!DETECT_ANOMALIES(...));
모델 목록을 보려면 SHOW SNOWFLAKE.ML.ANOMALY_DETECTION 명령을 사용하십시오.
SHOW SNOWFLAKE.ML.ANOMALY_DETECTION;
모델을 제거하려면 DROP SNOWFLAKE.ML.ANOMALY_DETECTION 명령을 사용하십시오.
DROP SNOWFLAKE.ML.ANOMALY_DETECTION <name>;
모델을 업데이트하려면 모델을 삭제하고 새 모델을 학습시키십시오. 모델은 변경할 수 없으며 자체적으로 업데이트할 수 없습니다.
변칙 검색하기¶
다음 섹션에서는 변칙 검색을 사용하여 이상값을 감지하는 방법을 보여줍니다. 이들 섹션에서는 단일 시계열과 다중 시계열에 대한 변칙, 외생 변수의 유무에 따른 변칙, 사용자 정의 예측 구간과 지도 학습(레이블 지정) 접근 방식을 사용할 때의 변칙을 검색하는 예를 제시합니다.
단일 시계열에 대한 변칙 검색하기(비지도 학습)¶
데이터에서 변칙을 검색하려면 다음을 수행하십시오.
과거 데이터를 사용하여 변칙 검색 모델을 학습시킵니다.
학습된 변칙 검색 모델을 사용하여 과거 데이터 또는 예상 데이터에서 변칙을 검색합니다. 테스트 데이터의 타임스탬프는 학습 데이터의 타임스탬프를 연대순으로 따라야 합니다. 모델 학습에 2개 이상의 데이터 요소가 필요한데, 나이브하지 않은 결과를 얻으려면 12개 이상, 비선형 결과를 얻으려면 60개 이상이 필요합니다.
모델 생성 및 사용에 사용되는 매개 변수에 대한 정보는 ANOMALY_DETECTION(SNOWFLAKE.ML) 섹션을 참조하십시오.
변칙 검색 모델 학습시키기¶
변칙 검색 모델 오브젝트를 생성하려면 CREATE SNOWFLAKE.ML.ANOMALY_DETECTION 명령을 실행하십시오.
예를 들어 store_id 가 1인 매장의 재킷 판매를 분석하고 싶다고 가정해 보겠습니다.
변칙 검색을 위해 모델을 학습시키기 위해 데이터를 반환하는 쿼리를 디자인하거나 뷰를 만듭니다.
이 예에서는 CREATE VIEW 명령을 실행하여 날짜 및 판매 정보가 포함된
view_with_training_data라는 뷰를 만듭니다.CREATE OR REPLACE VIEW view_with_training_data AS SELECT date, sales FROM historical_sales_data WHERE store_id=1 AND item='jacket';
변칙 검색 오브젝트를 만들고 그 뷰에서 데이터에 대해 해당 모델을 학습시킵니다.
이 예에서는 CREATE SNOWFLAKE.ML.ANOMALY_DETECTION 명령을 실행하여
basic_model이라는 변칙 검색 오브젝트를 만듭니다. 다음 인자를 전달합니다.CREATE OR REPLACE SNOWFLAKE.ML.ANOMALY_DETECTION basic_model( INPUT_DATA => TABLE(view_with_training_data), TIMESTAMP_COLNAME => 'date', TARGET_COLNAME => 'sales', LABEL_COLNAME => '');
이 예제에서는 뷰에 대한 참조를 INPUT_DATA 인자로 전달합니다. 이 예제에서는 TABLE 키워드를 사용하여 참조를 생성 합니다. 또는 SYSTEM$REFERENCE 를 호출하여 참조를 생성할 수 있습니다.
레이블 열의 목적은 어떤 행이 알려진 변칙인지 모델에 알리는 것입니다. 이 예제에서는 비지도 학습을 사용하므로 레이블 열을 사용할 필요가 없습니다. 빈 문자열을 레이블 열의 이름으로 전달합니다.
팁
INPUT_DATA 인자에 대한 뷰를 생성하지 않으려면 인라인 뷰 역할을 하는 SELECT 문을 사용하는 쿼리에 대한 참조 를 전달할 수 있습니다.
TABLE 키워드를 사용하여 이 쿼리 참조를 생성할 수 있습니다. 예:
CREATE OR REPLACE SNOWFLAKE.ML.ANOMALY_DETECTION basic_model( INPUT_DATA => TABLE(SELECT date, sales FROM historical_sales_data WHERE store_id=1 AND item='jacket'), TIMESTAMP_COLNAME => 'date', TARGET_COLNAME => 'sales', LABEL_COLNAME => '');
백슬래시로 작은따옴표 및 기타 특수 문자를 모두 이스케이프 처리하십시오.
TABLE 키워드를 사용하는 대신 SYSTEM$QUERY_REFERENCE 를 호출하여 쿼리 참조를 생성할 수 있습니다.
명령이 성공적으로 실행되면 변칙 검색 인스턴스가 성공적으로 생성되었다는 메시지가 표시됩니다.
+--------------------------------------------+ | status | +--------------------------------------------+ | Instance basic_model successfully created. | +--------------------------------------------+
변칙 검색 모델을 사용하여 변칙 검색하기¶
변칙 검색 오브젝트를 생성하면 모델이 학습되어 스키마에 저장됩니다. 변칙 검색 오브젝트를 사용하여 변칙을 검색하려면 오브젝트의 <model_name>!DETECT_ANOMALIES 메서드를 호출하십시오. 예:
분석을 위한 데이터를 반환하는 쿼리를 디자인하거나 뷰를 만듭니다.
이 예에서는 CREATE VIEW 명령을 실행하여 날짜 및 판매 정보가 포함된
view_with_data_to_analyze라는 뷰를 만듭니다.CREATE OR REPLACE VIEW view_with_data_to_analyze AS SELECT date, sales FROM new_sales_data WHERE store_id=1 and item='jacket';
변칙 검색 모델용 오브젝트를 사용하여(이 예에서는 앞서 만든
basic_model) <model_name>!DETECT_ANOMALIES 메서드를 호출합니다.CALL basic_model!DETECT_ANOMALIES( INPUT_DATA => TABLE(view_with_data_to_analyze), TIMESTAMP_COLNAME =>'date', TARGET_COLNAME => 'sales' );
이 메서드는 검색기의 예측과 함께 현재 뷰
view_with_data_to_analyze에 있는 데이터의 행을 포함하는 테이블을 반환합니다. 이 테이블의 열에 대한 설명은 반환 섹션을 참조하십시오.
출력
가독성을 위해 결과를 반올림했습니다.
+--------+-------------------------+----+----------+--------------+--------------+------------+--------------+--------------+
| SERIES | TS | Y | FORECAST | LOWER_BOUND | UPPER_BOUND | IS_ANOMALY | PERCENTILE | DISTANCE |
+--------|-------------------------+----+----------+--------------+--------------+------------+--------------+--------------|
| NULL | 2020-01-16 00:00:00.000 | 6 | 4.6 | -7.185885251 | 16.385885251 | False | 0.6201873452 | 0.3059728606 |
| NULL | 2020-01-17 00:00:00.000 | 20 | 9 | -2.785885251 | 20.785885251 | False | 0.9918932208 | 2.404072476 |
+--------+-------------------------+----+----------+--------------+--------------+------------+--------------+--------------|
결과를 테이블에 직접 저장하려면 CREATE TABLE … AS SELECT … 를 사용하고 FROM 절에서 DETECT_ANOMALIES 메서드를 호출 합니다.
CREATE TABLE my_anomalies AS
SELECT * FROM TABLE(basic_model!DETECT_ANOMALIES(
INPUT_DATA => TABLE(view_with_data_to_analyze),
TIMESTAMP_COLNAME =>'date',
TARGET_COLNAME => 'sales'
));
위의 예제와 같이 메서드를 호출할 때 CALL 명령어를 생략합니다. 대신, 호출을 괄호로 묶고 그 앞에 TABLE 키워드를 붙입니다.
레이블이 지정된 데이터로 변칙 검색 모델 학습시키기¶
이전 예제에서는 모델의 결과가 부정확하게 나타납니다. 이는 아마도 다음과 같은 이유 때문일 것입니다.
변칙 검색 모델은 매우 적은 수의 입력 데이터를 기반으로 학습되었습니다.
2020-01-03에 더 많은 수의 재킷(30개)이 판매되었습니다. 이로 인해 예측치가 상방으로 치우쳐 예측 구간의 크기가 증가했습니다.
더 많은 학습 데이터를 포함하거나 학습 데이터에 레이블을 지정하여(지도 학습) 변칙 검색 모델의 정확도를 개선할 수 있습니다. 레이블이 지정된 학습 데이터에는 각 행이 알려진 변칙인지 여부를 나타내는 추가 부울 열이 있습니다. 레이블을 지정하면 변칙 검색 모델이 학습 데이터의 알려진 변칙에 대한 과적합을 방지하는 데 도움이 될 수 있습니다.
학습 데이터에 레이블이 지정된 데이터를 포함하려면 CREATE SNOWFLAKE.ML.ANOMALY_DETECTION 명령의 LABEL_COLNAME 생성자 인자에 레이블이 포함된 열을 지정하십시오. 예:
학습 데이터와 함께 레이블을 반환하는 쿼리를 디자인하거나 뷰를 만듭니다.
이 예에서는 CREATE VIEW 명령을 실행하여
label이라는 명령에 레이블이 포함된view_with_labeled_data라는 뷰를 만듭니다.CREATE OR REPLACE VIEW view_with_labeled_data_for_training AS SELECT date, sales, label FROM historical_sales_data WHERE store_id=1 and item='jacket';
변칙 검색 모델에 대한 오브젝트를 만들고 해당 뷰의 데이터를 기반으로 모델을 학습시킵니다.
이 예에서는 CREATE SNOWFLAKE.ML.ANOMALY_DETECTION 명령을 실행하여
model_trained_with_labeled_data라는 변칙 검색 오브젝트를 만듭니다. 다음 문으로 변칙 검색 오브젝트를 만듭니다.CREATE OR REPLACE SNOWFLAKE.ML.ANOMALY_DETECTION model_trained_with_labeled_data( INPUT_DATA => TABLE(view_with_labeled_data_for_training), TIMESTAMP_COLNAME => 'date', TARGET_COLNAME => 'sales', LABEL_COLNAME => 'label' );
이 새로운 변칙 검색 모델을 사용하여 단일 시계열에 대한 변칙 검색하기(비지도 학습) 에서 사용한 것과 동일한 인자를 전달하는 <model_name>!DETECT_ANOMALIES 메서드를 호출합니다.
CALL model_trained_with_labeled_data!DETECT_ANOMALIES( INPUT_DATA => TABLE(view_with_data_to_analyze), TIMESTAMP_COLNAME =>'date', TARGET_COLNAME => 'sales' );
이 메서드는 검색기의 예측과 함께 현재 뷰
view_with_data_to_analyze에 있는 데이터의 행을 포함하는 테이블을 반환합니다. 이 테이블의 열에 대한 설명은 반환 섹션을 참조하십시오.
출력
가독성을 위해 결과를 반올림했습니다.
+--------+-------------------------+----+----------+---------------+--------------+------------+--------------+------------+ | SERIES | TS | Y | FORECAST | LOWER_BOUND | UPPER_BOUND | IS_ANOMALY | PERCENTILE | DISTANCE | +--------|-------------------------+----+----------+---------------+--------------+------------+--------------+------------| | NULL | 2020-01-16 00:00:00.000 | 6 | 6 | 0.82 | 11.18 | False | 0.5 | 0 | | NULL | 2020-01-17 00:00:00.000 | 20 | 6 | -0.39 | 12.33 | True | 0.99 | 5.70 | +--------+-------------------------+----+----------+---------------+--------------+------------+--------------+------------+
변칙 검색을 위한 예측 구간 지정하기¶
다양한 수준의 민감도로 변칙을 검색할 수 있습니다. 변칙으로 분류할 관측값의 백분율을 지정하려면 <model_name>!DETECT_ANOMALIES 에 대한 구성 설정이 포함된 OBJECT 를 만들고 prediction_interval 키를 변칙으로 표시해야 하는 관측값의 백분율로 설정하십시오.
이 오브젝트를 생성하려면 오브젝트 상수 또는 OBJECT_CONSTRUCT 함수 중 하나를 사용할 수 있습니다.
그런 다음 <model_name>!DETECT_ANOMALIES 메서드 호출 시 이 오브젝트를 CONFIG_OBJECT 인자로 전달합니다.
기본적으로, prediction_interval 키와 연결된 값은 0.99로 설정되는데, 이는 데이터의 약 1%가 변칙으로 표시된다는 뜻입니다. 0과 1 사이의 값을 지정할 수 있습니다.
더 적은 관측값을 변칙으로 표시하려면
prediction_interval에 대해 더 높은 값을 지정하십시오.더 많은 관측값을 변칙으로 표시하려면
prediction_interval값을 줄이십시오.
다음 예에서는 prediction_interval 을 0.995로 설정하여 변칙 검색을 더 엄격하게 구성합니다. 또한 이 예에서는 (단일 시계열에 대한 변칙 검색하기(비지도 학습) 에서 설정한) 분석할 데이터가 포함된 뷰와 함께 (레이블이 지정된 데이터로 변칙 검색 모델 학습시키기 에서 설정한) 레이블이 지정된 데이터를 기반으로 학습된 모델을 사용합니다.
CALL model_trained_with_labeled_data!DETECT_ANOMALIES(
INPUT_DATA => TABLE(view_with_data_to_analyze),
TIMESTAMP_COLNAME => 'date',
TARGET_COLNAME => 'sales',
CONFIG_OBJECT => {'prediction_interval':0.995}
);
이 문은 현재 뷰 view_with_data_to_analyze 에 있는 데이터의 행을 포함하는 테이블을 생성합니다. 각 행에는 검색기의 예측치가 포함된 열이 포함됩니다. 이 모델의 결과가 레이블이 지정되지 않은 예보다 더 정확함을 알 수 있습니다.
출력
가독성을 위해 결과를 반올림했습니다.
+--------+-------------------------+----+----------+---------------+--------------+------------+--------------+------------+
| SERIES | TS | Y | FORECAST | LOWER_BOUND | UPPER_BOUND | IS_ANOMALY | PERCENTILE | DISTANCE |
+--------|-------------------------+----+----------+---------------+--------------+------------+--------------+------------|
| NULL | 2020-01-16 00:00:00.000 | 6 | 6 | 0.36 | 11.64 | False | 0.5 | 0 |
| NULL | 2020-01-17 00:00:00.000 | 20 | 6 | -0.90 | 12.90 | True | 0.99 | 5.70 |
+--------+-------------------------+----+----------+---------------+--------------+------------+--------------+------------+
분석을 위한 추가 열 포함하기¶
추가적인 열이 실제 변칙의 식별 능력 개선에 도움이 될 수 있는 경우 학습과 분석을 위한 데이터에 이러한 열을 포함할 수 있습니다(예: temperature, weather, is_black_friday).
분석을 위해 새 열을 포함하려면 다음을 수행하십시오.
학습 데이터의 경우 새 열을 포함하는 쿼리를 디자인하거나 뷰를 만들고 새 변칙 검색 오브젝트를 만들어 해당 뷰 또는 쿼리에 대한 참조를 전달합니다.
분석할 데이터의 경우 새 열을 포함하는 쿼리를 디자인하거나 뷰를 만들고 해당 뷰 또는 쿼리에 대한 참조를 <model_name>!DETECT_ANOMALIES 메서드로 전달합니다.
변칙 검색 모델은 추가 열을 자동으로 검색하고 사용합니다.
참고
CREATE SNOWFLAKE.ML.ANOMALY_DETECTION 명령을 실행할 때와 <model_name>!DETECT_ANOMALIES 메서드를 호출할 때 뷰 또는 쿼리에 동일한 추가 열 세트를 제공해야 합니다. 명령에 전달된 학습 데이터의 열과 함수에 전달된 분석용 데이터의 열이 일치하지 않으면 오류가 발생합니다.
예를 들어 temperature, humidity 및 holiday 열을 추가하려는 경우를 가정해 보겠습니다.
이러한 추가 열을 포함한 학습 데이터를 반환하는 쿼리를 디자인하거나 뷰를 만듭니다.
이 예에서는 CREATE VIEW 명령을 실행하여
view_with_training_data_extra_columns라는 뷰를 만듭니다.CREATE OR REPLACE VIEW view_with_training_data_extra_columns AS SELECT date, sales, label, temperature, humidity, holiday FROM historical_sales_data WHERE store_id=1 AND item='jacket';
변칙 검색 모델에 대한 오브젝트를 만들고 해당 뷰의 데이터를 기반으로 모델을 학습시킵니다.
이 예에서는 CREATE SNOWFLAKE.ML.ANOMALY_DETECTION 명령을 실행하여
model_with_additional_columns라는 변칙 검색 오브젝트를 만들어 새 뷰에 대한 참조를 전달합니다.CREATE OR REPLACE SNOWFLAKE.ML.ANOMALY_DETECTION model_with_additional_columns( INPUT_DATA => TABLE(view_with_training_data_extra_columns), TIMESTAMP_COLNAME => 'date', TARGET_COLNAME => 'sales', LABEL_COLNAME => 'label' );
이러한 추가 열을 포함하여 분석할 데이터를 반환하는 쿼리를 디자인하거나 뷰를 만듭니다.
이 예에서는 CREATE VIEW 명령을 실행하여
view_with_data_for_analysis_extra_columns라는 뷰를 만듭니다.CREATE OR REPLACE VIEW view_with_data_for_analysis_extra_columns AS SELECT date, sales, temperature, humidity, holiday FROM new_sales_data WHERE store_id=1 AND item='jacket';
이 새로운 변칙 검색 오브젝트를 사용하여 <model_name>!DETECT_ANOMALIES 메서드를 호출하여 새 뷰를 전달합니다.
CALL model_with_additional_columns!DETECT_ANOMALIES( INPUT_DATA => TABLE(view_with_data_for_analysis_extra_columns), TIMESTAMP_COLNAME => 'date', TARGET_COLNAME => 'sales', CONFIG_OBJECT => {'prediction_interval':0.93} );
이 문은 검색기의 예측과 함께 현재 뷰
view_with_data_for_analysis_extra_columns에 있는 데이터의 행을 포함하는 테이블을 생성합니다. 출력 형식은 앞서 실행한 명령에 대해 표시된 출력 형식과 동일합니다.
출력
가독성을 위해 결과를 반올림했습니다.
+--------+-------------------------+----+----------+-------------+--------------+------------+--------------+------------+ | SERIES | TS | Y | FORECAST | LOWER_BOUND | UPPER_BOUND | IS_ANOMALY | PERCENTILE | DISTANCE | +--------|-------------------------+----+----------+-------------+--------------+------------+--------------+------------| | NULL | 2020-01-16 00:00:00.000 | 6 | 6 | 2.34 | 9.64 | False | 0.5 | 0 | | NULL | 2020-01-17 00:00:00.000 | 20 | 6 | 1.56 | 10.451 | True | 0.99 | 5.70 | +--------+-------------------------+----+----------+-------------+--------------+------------+--------------+------------+
다중 계열에서 변칙 검색하기¶
이전 섹션에서는 단일 계열에 대한 변칙을 검색하는 예를 제시했습니다. 이러한 예에서는 한 매장(매장 ID 1)에서 한 가지 유형의 품목(재킷) 판매에 대한 변칙을 플래그로 지정했습니다. 동시에 여러 시계열의 변칙(예: 여러 가지 품목과 매장의 조합에 대해)을 검색하려면 다음을 수행하십시오.
학습 데이터의 경우 계열을 식별하는 열이 포함된 쿼리를 디자인하거나 뷰를 만들고 새로운 변칙 검색 오브젝트를 만들어 해당 뷰 또는 쿼리에 대한 참조를 전달하고 SERIES_COLNAME 인자에 대한 계열 열의 이름을 지정합니다.
분석할 데이터에 대해 계열을 식별하는 열을 포함하는 쿼리를 디자인하거나 뷰를 만듭니다. <model_name>!DETECT_ANOMALIES 메서드를 호출하여 해당 뷰 또는 쿼리에 대한 참조를 전달하고 SERIES_COLNAME 인자에 대한 계열 열의 이름을 지정합니다.
예를 들어 store_id 및 item 열의 조합을 사용하여 계열을 식별하려는 경우를 가정해 보겠습니다.
계열에 대한 열이 포함된 학습 데이터를 반환하는 쿼리를 디자인하거나 뷰를 만듭니다.
이 예에서는 CREATE VIEW 명령을 실행하여 계열을 매장 ID와 품목의 조합으로 식별하는
store_item이라는 열이 포함된view_with_training_data_multiple_series라는 뷰를 만듭니다.CREATE OR REPLACE VIEW view_with_training_data_multiple_series AS SELECT [store_id, item] AS store_item, date, sales, label, temperature, humidity, holiday FROM historical_sales_data;
변칙 검색에 대한 오브젝트를 만들고 해당 뷰의 데이터를 기반으로 모델을 학습시킵니다.
이 예에서는 CREATE SNOWFLAKE.ML.ANOMALY_DETECTION 명령을 실행하여
model_for_multiple_series라는 변칙 검색 오브젝트를 만들어 새 뷰에 대한 참조를 전달하고 SERIES_COLNAME 인자에 대해store_item을 지정합니다.CREATE OR REPLACE SNOWFLAKE.ML.ANOMALY_DETECTION model_for_multiple_series( INPUT_DATA => TABLE(view_with_training_data_multiple_series), SERIES_COLNAME => 'store_item', TIMESTAMP_COLNAME => 'date', TARGET_COLNAME => 'sales', LABEL_COLNAME => 'label' );
계열 열을 포함하여 분석할 데이터를 반환하는 쿼리를 디자인하거나 뷰를 만듭니다.
이 예에서는 CREATE VIEW 명령을 실행하여 계열에 대해
store_item이라는 열이 포함된view_with_data_for_analysis_multiple_series라는 뷰를 만듭니다.CREATE OR REPLACE VIEW view_with_data_for_analysis_multiple_series AS SELECT [store_id, item] AS store_item, date, sales, temperature, humidity, holiday FROM new_sales_data;
이 새로운 변칙 검색 오브젝트를 사용하여 <model_name>!DETECT_ANOMALIES 메서드를 호출하여 새 뷰를 전달하고 SERIES_COLNAME 인자에 대해
store_item을 설정합니다.CALL model_for_multiple_series!DETECT_ANOMALIES( INPUT_DATA => TABLE(view_with_data_for_analysis_multiple_series), SERIES_COLNAME => 'store_item', TIMESTAMP_COLNAME => 'date', TARGET_COLNAME => 'sales', CONFIG_OBJECT => {'prediction_interval':0.995} );
이 문은 검색기의 예측과 함께 현재 뷰
view_with_data_for_analysis_multiple_series에 있는 데이터의 행을 포함하는 테이블을 생성합니다. 출력에는 계열을 식별하는 열이 포함됩니다.
출력
가독성을 위해 결과를 반올림했습니다.
+--------------+-------------------------+----+----------+---------------+--------------+------------+---------------+--------------+ | SERIES | TS | Y | FORECAST | LOWER_BOUND | UPPER_BOUND | IS_ANOMALY | PERCENTILE | DISTANCE | |--------------+-------------------------+----+----------+---------------+--------------+------------+---------------+--------------| | [ | 2020-01-16 00:00:00.000 | 3 | 6.3 | 2.07 | 10.53 | False | 0.01 | -2.19 | | 2, | | | | | | | | | | "umbrella" | | | | | | | | | | ] | | | | | | | | | | [ | 2020-01-17 00:00:00.000 | 70 | 2.9 | -1.33 | 7.13 | True | 1 | 44.54 | | 2, | | | | | | | | | | "umbrella" | | | | | | | | | | ] | | | | | | | | | | [ | 2020-01-16 00:00:00.000 | 6 | 6 | 0.36 | 11.64 | False | 0.5 | 0 | | 1, | | | | | | | | | | "jacket" | | | | | | | | | | ] | | | | | | | | | | [ | 2020-01-17 00:00:00.000 | 20 | 6 | -0.90 | 12.90 | True | 0.99 | 5.70 | | 1, | | | | | | | | | | "jacket" | | | | | | | | | | ] | | | | | | | | | +--------------+-------------------------+----+----------+---------------+--------------+------------+---------------+--------------+
변칙 시각화 및 결과 해석하기¶
Snowsight 를 사용하여 변칙 검색 결과를 검토하고 시각화합니다. Snowsight 에서는 <model_name>!DETECT_ANOMALIES 메서드를 호출할 때 결과가 워크시트 아래의 테이블에 표시됩니다.

Snowsight 의 차트 기능을 사용해 결과를 시각화할 수 있습니다.
<model_name>!DETECT_ANOMALIES 메서드를 호출한 후 결과 테이블 위의 Charts 를 선택합니다.
차트 오른쪽의 Data 섹션에서 다음을 수행하십시오.
Y 열을 선택하고 Aggregation 아래의 None 을 선택합니다.
TS 열을 선택하고 Bucketing 아래의 None 을 선택합니다.
LOWER_BOUND 및 UPPER_BOUND 열을 추가하고 Aggregation 아래의 None 을 선택합니다.
초기 시각화를 표시하려면 Chart 를 선택하십시오.

페이지 오른쪽에서 Add Column 을 선택하고 시각화하려는 열을 선택합니다.
LOWER_BOUND
UPPER_BOUND
IS_ANOMALY
결과:
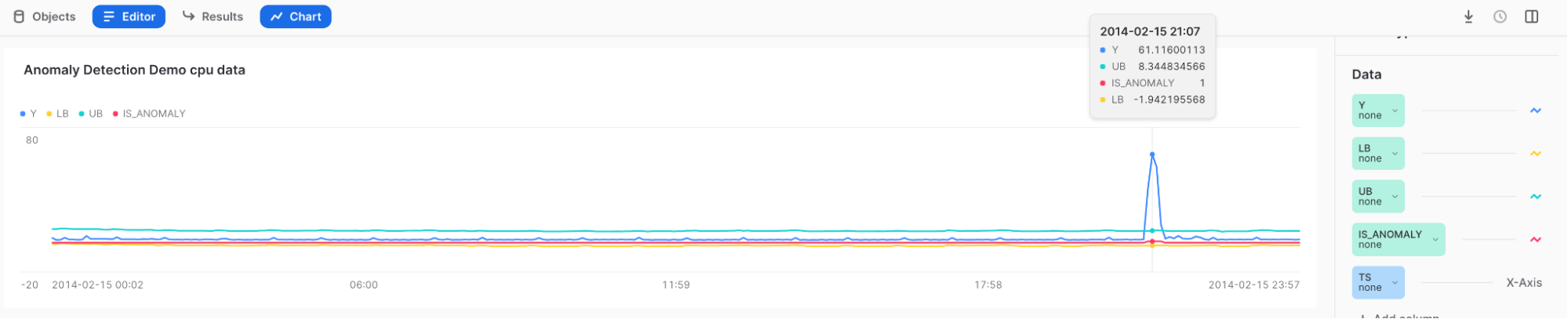
높은 스파이크를 마우스를 가리키면 Y가 상한 밖에 있고 IS_ANOMALY 필드에 1로 태그 지정되는 것을 볼 수 있습니다.
팁
결과를 더 잘 이해하려면 Top Insights 를 사용해 보십시오.
Snowflake 작업 및 경고로 변칙 검색 자동화하기¶
모델 재학습과 데이터의 변칙 여부 모니터링을 모두 수행하기 위해 Snowflake 작업 또는 경고 내에서 변칙 검색 함수를 사용하여 자동화된 변칙 검색 파이프라인을 생성할 수 있습니다.
Snowflake 작업으로 학습 반복하기¶
Snowflake 작업 을 사용하여 최신 데이터를 반영하도록 모델을 업데이트할 수 있습니다.
매시간 변칙 검색 오브젝트를 새로 고치는 작업을 생성하려면 다음 문을 실행하여 your_warehouse_name 을 웨어하우스 이름으로 바꾸십시오.
CREATE OR REPLACE TASK ad_model_retrain_task
WAREHOUSE = <your_warehouse_name>
SCHEDULE = '60 MINUTE'
AS
EXECUTE IMMEDIATE
$$
BEGIN
CREATE OR REPLACE SNOWFLAKE.ML.ANOMALY_DETECTION model_trained_with_labeled_data(
INPUT_DATA => TABLE(view_with_labeled_data_for_training),
TIMESTAMP_COLNAME => 'date',
TARGET_COLNAME => 'sales',
LABEL_COLNAME => 'label'
);
END;
$$;
기본적으로, 새로 생성된 작업은 일시 중단됩니다.
작업을 재개하려면 ALTER TASK … RESUME 명령을 실행하십시오.
ALTER TASK ad_model_retrain_task RESUME;
작업을 일시 중지하려면 ALTER TASK … SUSPEND 명령을 실행하십시오.
ALTER TASK ad_model_retrain_task SUSPEND;
Snowflake 작업으로 모니터링하기¶
Snowflake 작업을 사용하여 특정 빈도로 데이터를 모니터링할 수도 있습니다.
먼저, 변칙 검색 결과를 저장할 테이블을 만듭니다.
CREATE OR REPLACE TABLE anomaly_res_table (
ts TIMESTAMP_NTZ, y FLOAT, forecast FLOAT, lower_bound FLOAT, upper_bound FLOAT,
is_anomaly BOOLEAN, percentile FLOAT, distance FLOAT);
반복되는 변칙 검색 작업의 결과를 테이블에 저장하는 작업을 생성합니다. 이 예에서는 WAREHOUSE 매개 변수를 snowhouse 로 설정합니다. 이를 자체 웨어하우스로 바꿀 수 있습니다.
CREATE OR REPLACE TASK ad_model_monitoring_task
WAREHOUSE = snowhouse
SCHEDULE = '1 minute'
AS
EXECUTE IMMEDIATE
$$
BEGIN
INSERT INTO anomaly_res_table (ts, y, forecast, lower_bound, upper_bound, is_anomaly, percentile, distance)
SELECT * FROM TABLE(
model_trained_with_labeled_data!DETECT_ANOMALIES(
INPUT_DATA => TABLE(view_with_data_to_analyze),
TIMESTAMP_COLNAME => 'date',
TARGET_COLNAME => 'sales',
CONFIG_OBJECT => {'prediction_interval':0.99}
)
);
END;
$$;
작업을 재개하려면 ALTER TASK … RESUME 명령을 실행하십시오.
ALTER TASK ad_model_monitoring_task RESUME;
그러면 anomaly_res_table 에 각 작업 실행의 결과가 전부 포함됩니다.
작업을 일시 중지하려면 ALTER TASK … SUSPEND 명령을 실행하십시오.
ALTER TASK ad_model_monitoring_task SUSPEND;
Snowflake 경고로 모니터링하기¶
또한 Snowflake 경고 를 사용하여 특정 빈도로 데이터를 모니터링하고 검색된 변칙이 포함된 이메일을 보낼 수도 있습니다. 다음 문은 매분 변칙을 검색하는 경고를 생성합니다. 먼저, 변칙을 검색하는 저장 프로시저 를 정의한 다음 해당 저장 프로시저를 사용하는 경고를 생성합니다.
참고
저장 프로시저에서 메일을 보내려면 이메일 통합을 설정해야 합니다. 자세한 내용은 Snowflake의 알림 섹션을 참조하십시오.
CREATE OR REPLACE PROCEDURE extract_anomalies()
RETURNS TABLE()
LANGUAGE SQL
AS
$$
BEGIN
let res RESULTSET := (SELECT * FROM TABLE(
model_trained_with_labeled_data!DETECT_ANOMALIES(
INPUT_DATA => TABLE(view_with_data_to_analyze),
TIMESTAMP_COLNAME => 'date',
TARGET_COLNAME => 'sales',
CONFIG_OBJECT => {'prediction_interval':0.99}
))
WHERE is_anomaly = TRUE
);
RETURN TABLE(res);
END;
$$
;
CREATE OR REPLACE ALERT sample_sales_alert
WAREHOUSE = <your_warehouse_name>
SCHEDULE = '1 MINUTE'
IF (EXISTS (CALL extract_anomalies()))
THEN
CALL SYSTEM$SEND_EMAIL(
'sales_email_alert',
'your_email@snowflake.com',
'Anomalous Sales Data Detected in data stream',
CONCAT(
'Anomalous Sales Data Detected in data stream \n',
'Value outside of prediction interval detected in the most recent run at ',
current_timestamp(1)
));
경고를 시작하거나 재개하려면 ALTER ALERT … RESUME 명령을 실행하십시오.
ALTER ALERT sample_sales_alert RESUME;
경고를 일시 중지하려면 ALTER ALERT … SUSPEND 명령을 실행하십시오.
ALTER ALERT sample_sales_alert SUSPEND;
특징 중요도 이해하기¶
변칙 검색 모델을 사용하여 사용자가 선택하는 외생 변수, 자동으로 생성된 시간 특징(예: 요일 또는 주), 대상 변수의 변환(예: 이동 평균 및 자동 회귀 지연)을 포함하여, 모델에 사용되는 모든 특징의 상대적 중요도를 설명할 수 있습니다. 이 정보는 데이터에 실제로 영향을 미치는 요소를 파악하는 데 유용합니다.
<model_name>!EXPLAIN_FEATURE_IMPORTANCE 메서드는 모델의 트리가 각 특징을 사용하여 의사 결정을 내린 횟수를 계산합니다. 이러한 특징 중요도 점수는 합계가 1이 되도록 0과 1 사이의 값으로 정규화됩니다. 결과 점수는 학습된 모델에 있는 함수의 대략적인 순위를 나타냅니다.
점수가 서로 가까운 특징은 그 중요도가 비슷합니다. 극히 간단한 계열의 경우(예: 대상 열에 상수 값이 있는 경우) 모든 특징 중요도 점수가 0일 수 있습니다.
서로 매우 비슷한 여러 특징을 사용하면 해당 특징들의 중요도 점수가 낮아질 수 있습니다. 예를 들어, 한 가지 특징이 판매 품목의 수량 이고 다른 특징이 재고 품목의 수량 인 경우 보유 수량보다 더 많이 판매할 수 없고 판매할 수량보다 더 많은 재고가 쌓이지 않도록 재고를 적절히 관리하려고 하므로 이들 값이 상관 관계를 가질 수 있습니다. 두 특징이 동일한 경우 모델은 의사 결정을 할 때 이들을 상호 교환 가능한 것으로 취급할 수 있으므로, 특징 중 하나만 포함된 경우 해당 점수의 절반인 특징 중요도 점수가 도출됩니다.
특징 중요도로 지연 특징 도 알 수 있습니다. 학습 중에 모델은 학습 데이터의 빈도(매시간, 매일 또는 매주)를 유추합니다. 기능 lagx (예: lag24)는 x 시간 단위 전 대상 변수의 값입니다. 예를 들어 데이터가 시간별 데이터로 유추되는 경우 lag24 는 대상 변수 24시간 전을 나타냅니다.
대상 변수(이동 평균 등)의 다른 모든 변환은 결과 테이블에 aggregated_endogenous_features 로 요약됩니다.
제한 사항¶
특징 중요도를 계산하는 데 사용되는 기법을 선택할 수 없습니다.
특징 중요도 점수는 모델의 정확성에 중요한 특징에 대한 직관을 얻는 데 도움이 될 수 있지만, 실제 값을 추정치로 간주해야 합니다.
예¶
모델에 대한 특징의 상대적 중요도를 이해하려면 모델을 학습시킨 다음 <model_name>!EXPLAIN_FEATURE_IMPORTANCE 를 호출하십시오. 이 예에서는 먼저 두 개의 외생 변수로 임의 데이터를 생성하는데, 한 변수는 임의적이므로 모델에 그다지 중요하지 않을 가능성이 있으며 다른 하나는 대상의 복사본이므로 모델에 더 중요할 가능성이 있습니다.
다음 문을 실행하여 데이터를 생성하고 이를 기반으로 모델을 학습시키고 특징의 중요도를 가져옵니다.
CREATE OR REPLACE VIEW v_random_data AS SELECT
DATEADD('minute', ROW_NUMBER() over (ORDER BY 1), '2023-12-01')::TIMESTAMP_NTZ ts,
MOD(SEQ1(),10) y,
UNIFORM(1, 100, RANDOM(0)) exog_a
FROM TABLE(GENERATOR(ROWCOUNT => 500));
CREATE OR REPLACE VIEW v_feature_importance_demo AS SELECT
ts,
y,
exog_a
FROM v_random_data;
SELECT * FROM v_feature_importance_demo;
CREATE OR REPLACE SNOWFLAKE.ML.ANOMALY_DETECTION anomaly_model_feature_importance_demo(
INPUT_DATA => TABLE(v_feature_importance_demo),
TIMESTAMP_COLNAME => 'ts',
TARGET_COLNAME => 'y',
LABEL_COLNAME => ''
);
CALL anomaly_model_feature_importance_demo!EXPLAIN_FEATURE_IMPORTANCE();
출력
이 예제에서는 임의 데이터를 사용하므로 출력 결과가 아래와 정확히 일치할 것이라 여기지 마십시오.
+--------+------+--------------------------------------+-------+-------------------------+
| SERIES | RANK | FEATURE_NAME | SCORE | FEATURE_TYPE |
+--------+------+--------------------------------------+-------+-------------------------+
| NULL | 1 | aggregated_endogenous_trend_features | 0.36 | derived_from_endogenous |
| NULL | 2 | exog_a | 0.22 | user_provided |
| NULL | 3 | epoch_time | 0.15 | derived_from_timestamp |
| NULL | 4 | minute | 0.13 | derived_from_timestamp |
| NULL | 5 | lag60 | 0.07 | derived_from_endogenous |
| NULL | 6 | lag120 | 0.06 | derived_from_endogenous |
| NULL | 7 | hour | 0.01 | derived_from_timestamp |
+--------+------+--------------------------------------+-------+-------------------------+
학습 로그 검사하기¶
CONFIG_OBJECT => 'ON_ERROR': 'SKIP' 을 사용하여 여러 계열을 학습시키는 경우 전체 학습 프로세스가 실패하지 않고서 개별 시계열 모델이 학습에 실패할 수 있습니다. 실패한 시계열과 그 이유를 이해하려면 <model_instance>!SHOW_TRAINING_LOGS 를 호출하십시오.
예¶
CREATE TABLE t_error(date TIMESTAMP_NTZ, sales FLOAT, series VARCHAR);
INSERT INTO t_error VALUES
(TO_TIMESTAMP_NTZ('2019-12-20'), 1.0, 'A'),
(TO_TIMESTAMP_NTZ('2019-12-21'), 2.0, 'A'),
(TO_TIMESTAMP_NTZ('2019-12-22'), 3.0, 'A'),
(TO_TIMESTAMP_NTZ('2019-12-23'), 2.0, 'A'),
(TO_TIMESTAMP_NTZ('2019-12-24'), 1.0, 'A'),
(TO_TIMESTAMP_NTZ('2019-12-25'), 2.0, 'A'),
(TO_TIMESTAMP_NTZ('2019-12-26'), 3.0, 'A'),
(TO_TIMESTAMP_NTZ('2019-12-27'), 2.0, 'A'),
(TO_TIMESTAMP_NTZ('2019-12-28'), 1.0, 'A'),
(TO_TIMESTAMP_NTZ('2019-12-29'), 2.0, 'A'),
(TO_TIMESTAMP_NTZ('2019-12-30'), 3.0, 'A'),
(TO_TIMESTAMP_NTZ('2019-12-31'), 2.0, 'A'),
(TO_TIMESTAMP_NTZ('2020-01-01'), 2.0, 'A'),
(TO_TIMESTAMP_NTZ('2020-01-02'), 3.0, 'A'),
(TO_TIMESTAMP_NTZ('2020-01-03'), 3.0, 'A'),
(TO_TIMESTAMP_NTZ('2020-01-04'), 7.0, 'A'),
(TO_TIMESTAMP_NTZ('2020-01-06'), 10.0, 'B'), -- the same timestamp used again and again
(TO_TIMESTAMP_NTZ('2020-01-06'), 13.0, 'B'),
(TO_TIMESTAMP_NTZ('2020-01-06'), 12.0, 'B'),
(TO_TIMESTAMP_NTZ('2020-01-06'), 15.0, 'B'),
(TO_TIMESTAMP_NTZ('2020-01-06'), 14.0, 'B'),
(TO_TIMESTAMP_NTZ('2020-01-06'), 18.0, 'B'),
(TO_TIMESTAMP_NTZ('2020-01-06'), 12.0, 'B');
CREATE SNOWFLAKE.ML.ANOMALY_DETECTION model(
INPUT_DATA => TABLE(SELECT date, sales, series FROM t_error),
SERIES_COLNAME => 'series',
TIMESTAMP_COLNAME => 'date',
TARGET_COLNAME => 'sales',
LABEL_COLNAME => '',
CONFIG_OBJECT => {'ON_ERROR': 'SKIP'}
);
CALL model!SHOW_TRAINING_LOGS();
출력
+--------+--------------------------------------------------------------------------+
| SERIES | LOGS |
+--------+--------------------------------------------------------------------------+
| "B" | { "Errors": [ "At least two unique timestamps are required." ] } |
| "A" | NULL |
+--------+--------------------------------------------------------------------------+
비용 고려 사항¶
ML 함수 사용 비용에 대한 자세한 내용은 ML 함수 개요에서 비용 고려 사항 섹션을 참조하십시오.