Cortex Search¶
Get started with Cortex Search
개요¶
Cortex Search를 사용하면 Snowflake 데이터에서 지연 시간이 짧은 고품질의 “퍼지” 검색을 수행할 수 있습니다. 이는 대규모 언어 모델(LLMs)을 활용하는 `Retrieval Augmented Generation(RAG)<https://en.wikipedia.org/wiki/Prompt_engineering#Retrieval-augmented_generation>`_ 애플리케이션을 비롯하여 Snowflake 사용자를 위한 다양한 검색 환경을 지원합니다.
Cortex Search를 사용하면 임베딩, 인프라 유지 관리, 검색 품질 매개 변수 조정 또는 연속 인덱스 새로 고침에 대해 걱정할 필요 없이 몇 분 만에 텍스트 데이터에 대한 하이브리드(벡터 및 키워드) 검색 엔진을 구축하고 실행할 수 있습니다. 즉, 인프라와 검색 품질 조정에 소요되는 시간을 단축하고, 데이터를 활용해 고품질 채팅 및 검색 환경을 개발하는 데 더 많은 시간을 할애할 수 있습니다. AI 채팅 및 검색 애플리케이션을 강화하기 위해 Cortex Search를 사용하는 방법에 대한 단계별 지침은 Cortex Search 자습서 를 참조하십시오.
Cortex Search를 사용하는 시점¶
Cortex Search의 두 가지 주요 사용 사례는 RAG(retrieval augmented generation) 및 엔터프라이즈 검색입니다
LLM 챗봇용 RAG 엔진: 의미 체계 검색을 활용하여 사용자 지정, 상황에 맞는 응답을 제공함으로써 텍스트 데이터로 채팅 애플리케이션을 위한 RAG 엔진으로 Cortex Search를 사용할 수 있습니다.
엔터프라이즈 검색: Cortex Search를 애플리케이션에 내장된 고품질 검색창의 백엔드로 사용할 수 있습니다.
RAG용 Cortex Search¶
RAG(Retrieval augmented generation)는 기술 자료에서 데이터를 검색하여 대규모 언어 모델의 생성된 응답을 향상시키는 기술입니다. 다음 아키텍처 다이어그램은 Cortex Search와 Cortex LLM 함수 를 결합하여 Snowflake 데이터를 기술 자료로 사용하여 RAG가 적용된 엔터프라이즈 챗봇을 구축하는 방법을 보여줍니다.
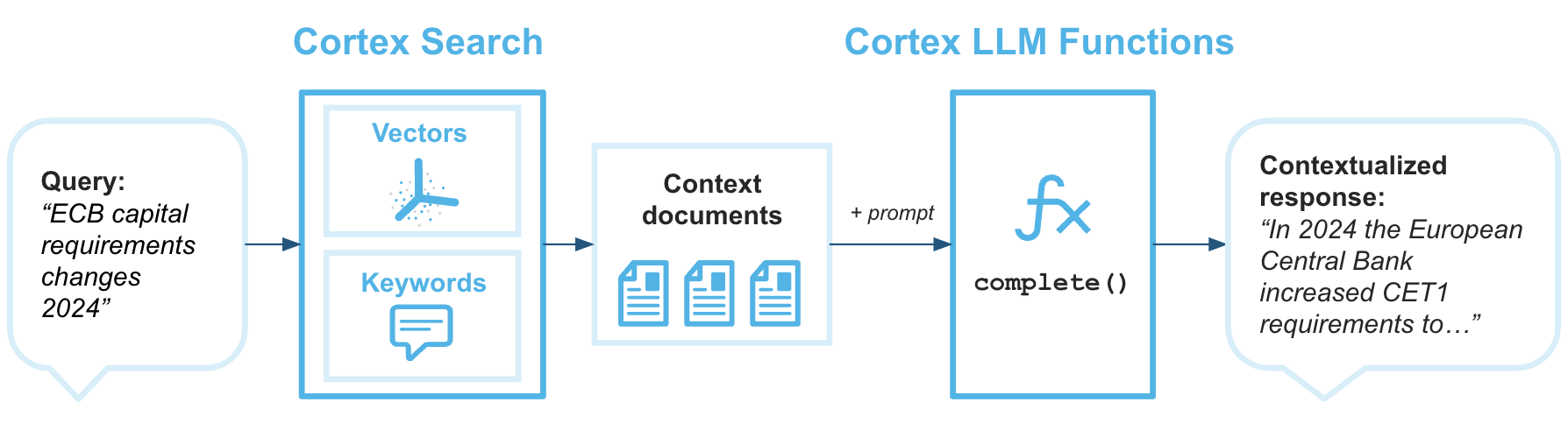
Cortex Search는 대규모 언어 모델에 최신 독점 데이터에 기반한 답변을 반환하는 데 필요한 컨텍스트를 제공하는 검색 엔진입니다.
예: Cortex Search Service 생성 및 쿼리¶
이 예제에서는 Cortex Search Service를 구축하고 REST API를 사용하여 쿼리하는 단계를 안내합니다. 서비스 쿼리에 대한 자세한 내용은 Cortex Search Service 쿼리하기 항목을 참조하십시오.
이 예제에서는 고객 지원 기록 데이터 세트 샘플을 사용합니다.
다음 명령을 실행하여 예제 데이터베이스와 스키마를 설정합니다.
다음 SQL 명령을 실행하여 데이터 세트를 생성합니다.
서비스 생성¶
단일 SQL 쿼리로 또는 Snowflake AI & ML Studio에서 Cortex Search Service를 구축할 수 있습니다. Cortex Search Service를 생성하면 Snowflake가 소스 데이터에 대한 변환기를 수행하여 지연 시간이 짧은 서비스를 제공할 수 있도록 준비합니다. 다음 섹션에서는 SQL과 Snowsight 의 Snowflake AI & ML Studio를 모두 사용하여 서비스를 구축하는 방법을 설명합니다.
참고
검색 서비스를 생성하면 검색 인덱스가 생성 프로세스의 일부로 빌드됩니다. 즉, 데이터 세트가 큰 경우 CREATE CORTEX SEARCH SERVICE 문을 완료하는 데 시간이 더 오래 걸릴 수 있습니다.
SQL 사용하기¶
다음 예제에서는 이전 섹션에서 만든 샘플 고객 지원 기록 데이터 세트에 CREATE CORTEX SEARCH SERVICE 를 사용하여 Cortex Search Service를 구축하는 방법을 보여 줍니다.
이 명령은 데이터에 대한 검색 서비스 구축을 트리거합니다. 이 예제에서:
서비스에 대한 쿼리는
transcript_text열에서 일치하는 항목을 검색합니다.
TARGET_LAG매개 변수는 Cortex Search Service가 하루에 한 번 정도 기본 테이블support_transcripts의 업데이트를 확인하도록 지정합니다.
region및agent_id열은 인덱스화되어transcript_text열에 대한 쿼리 결과와 함께 반환될 수 있습니다.
transcript_text열을 쿼리할 때region열을 필터 열로 사용할 수 있습니다.
cortex_search_wh웨어하우스는 처음에 지정된 쿼리의 결과를 구체화할 때와 기본 테이블이 변경될 때마다 사용됩니다.
참고
쿼리에 지정된 웨어하우스의 크기와 테이블의 행 수에 따라 이 CREATE 명령을 완료하는 데 최대 몇 시간이 걸릴 수 있습니다.
Snowflake는 각 서비스에 대해 MEDIUM 크기 미만의 전용 웨어하우스를 사용하는 것을 권장합니다.
ATTRIBUTES 필드의 열은 명시적 열거형 또는 와일드카드(
*)를 통해 소스 쿼리에 포함되어야 합니다.
Snowsight 사용하기¶
다음 단계에 따라 Snowsight 에서 Cortex Search Service를 생성합니다.
Snowsight 에 로그인합니다.
SNOWFLAKE.CORTEX_USER 데이터베이스 역할이 부여된 역할을 선택합니다.
탐색 메뉴에서 AI & ML » Cortex Search 를 선택합니다.
Create 를 선택합니다.
역할과 웨어하우스를 선택합니다.
역할에는 SNOWFLAKE.CORTEX_USER 데이터베이스 역할이 부여되어야 합니다. 웨어하우스는 서비스가 생성되고 새로 고쳐질 때 소스 쿼리의 결과를 구체화하는 데 사용됩니다.
서비스가 정의된 데이터베이스와 스키마를 선택합니다.
서비스 이름을 입력한 후 Next 를 선택합니다.
인덱싱할 데이터를 선택합니다.
테이블 또는 뷰를 선택하려면 :ui:`Table or view`를 선택합니다.
검색을 위해 인덱싱할 텍스트 데이터가 포함된 테이블 또는 뷰를 선택한 다음 Next`를 선택합니다. 예를 들어 ``support_transcripts` 테이블을 선택합니다.
스테이지에서 파일을 선택하려면 :ui:`Stage`를 선택합니다. (미리 보기)
검색을 위해 인덱싱할 파일이 포함된 스테이지를 선택한 다음 :ui:`Next`를 선택합니다.
참고
서비스를 정의할 때 여러 데이터 소스를 지정하거나 변환기를 수행하려면 SQL을 사용 합니다.
Table or view 를 선택한 경우:
검색 결과에 포함할 열(예:
transcript_text,region,agent_id)을 선택한 다음 :ui:`Next`를 선택합니다.검색할 열(예:
transcript_text)을 선택한 다음 :ui:`Next`를 선택합니다.특정 열을 기준으로 검색 결과를 필터링하려면 해당 열을 선택한 다음 :ui:`Next`를 선택합니다. 필터가 필요하지 않은 경우 :ui:`Skip this option`을 선택합니다.
:ui:`Stage`(미리 보기)를 선택한 경우 다음을 수행합니다.
처리된 데이터의 대상을 선택한 다음 :ui:`Next`를 선택합니다.
서비스에 대한 구성 매개 변수를 선택합니다.
서비스 콘텐츠가 기본 데이터 업데이트보다 지연되어야 하는 시간인 목표 지연 시간을 설정한 다음 Create 를 선택합니다.
마지막 단계에서는 서비스가 생성되었는지 확인하고 서비스 이름과 데이터 소스를 표시합니다.
참고
Snowsight 에서 서비스를 생성하면 서비스 이름이 큰따옴표로 묶입니다. SQL로 서비스를 참조할 때의 의미에 대한 자세한 내용은 큰따옴표로 묶인 식별자 섹션을 참조하십시오.
사용 권한 부여¶
서비스와 인덱스가 생성된 후에는 customer_support와 같은 다른 역할에 서비스, 해당 데이터베이스 및 스키마에 대한 사용 권한을 부여할 수 있습니다.
서비스 미리 보기¶
서비스가 데이터로 올바르게 채워졌는지 확인하려면 SQL 환경에서 SEARCH_PREVIEW 함수 를 통해 서비스를 미리 볼 수 있습니다.
성공적인 샘플 쿼리 응답:
이 응답은 해당 서비스가 데이터로 채워져 있고 주어진 쿼리에 대해 적절한 결과를 제공하고 있음을 보여줍니다.
CORTEX_SEARCH_DATA_SCAN 테이블 함수를 사용하여 서비스 내용을 확인할 수도 있습니다.
애플리케이션에서 서비스 쿼리하기¶
검색 서비스를 생성하고, 역할에 사용 권한을 부여하고, 미리 본 후에는 이제 Python API 를 사용하여 애플리케이션에서 검색 서비스를 쿼리할 수 있습니다.
다음 코드는 Python API를 사용하여 North America 에 대한 쿼리와 가장 관련성이 높은 지원 티켓을 검색하고, internet issues 리전의 결과를 반환하도록 필터링하는 방법을 보여줍니다.
성공적인 샘플 쿼리 응답:
Cortex Search Service는 쿼리의 columns 필드에 지정된 모든 열을 반환합니다.
필수 권한¶
Cortex Search Service를 생성하려면 역할에 Cortex 임베딩 함수를 사용하는 데 필요한 권한이 있어야 합니다. 이를 위해서는 SNOWFLAKE.CORTEX_USER 데이터베이스 역할 또는 SNOWFLAKE.CORTEX_EMBED_USER 데이터베이스 역할을 서비스 생성자 역할에 부여해야 합니다. 다음 권한도 있어야 합니다.
서비스를 생성하는 스키마에 대한 CREATE CORTEX SEARCH SERVICE 또는 OWNERSHIP 권한
서비스가 쿼리하는 기본 테이블 또는 뷰에 대한 SELECT 권한
서비스를 새로 고치는 웨어하우스에 대한 USAGE 권한
Cortex Search Service에서 사용하는 모든 기본 오브젝트에서 변경 내용 추적을 활성화해야 합니다. 변경 내용 추적 요구 사항에 대한 자세한 내용은 변경 내용 추적 요구 사항 섹션을 참조하세요.
Cortex Search Service를 쿼리하려면 쿼리하는 사용자의 역할에 서비스 자체와 서비스가 위치한 데이터베이스 및 스키마에 대한 USAGE 권한이 있어야 합니다. Cortex Search 액세스 제어 요구 사항 섹션을 참조하십시오.
ALTER 명령을 사용하여 Cortex Search Service를 일시 중단하거나 다시 시작하려면 쿼리하는 사용자의 역할에 서비스에 대한 OPERATE 권한이 있어야 합니다. ALTER CORTEX SEARCH SERVICE 섹션을 참조하십시오.
중요
Cortex Search Service는 소유자의 권한 으로 검색을 수행하며 소유자의 권한으로 실행되는 다른 Snowflake 오브젝트와 동일한 보안 모델을 따릅니다. 자세한 내용은 Cortex Search 액세스 제어 요구 사항 을 참조하십시오.
Cortex Search 품질 이해하기¶
Cortex Search는 검색 및 순위 모델의 조합을 활용하여 조정이 거의 또는 전혀 필요 없는 높은 수준의 검색 품질을 제공합니다. Cortex Search는 기본적으로 문서를 검색하고 순위를 매기는 “하이브리드” 방식을 사용합니다. 각 검색어에는 다음이 활용됩니다.
의미 체계가 유사한 문서를 검색하는 벡터 검색.
어휘적으로 유사한 문서를 검색하는 키워드 검색.
결과 세트에서 가장 관련성이 높은 문서의 순위를 재조정하기 위한 의미 체계 순위 재지정.
이 하이브리드 검색 방법은 의미 체계 순위 재지정 단계와 결합되어 광범위한 데이터 세트와 쿼리에서 높은 검색 품질을 달성합니다.
숫자 부스트, 시간 감쇠를 적용하거나 구성 요소 가중치를 조정하거나 순위 재지정을 비활성화하여 검색 결과의 채점을 사용자 지정할 수 있습니다. 자세한 내용은 Cortex Search Scoring 사용자 지정하기 섹션을 참조하십시오.
Cortex Search 임베딩 모델¶
Cortex Search를 사용하면 사용자가 벡터 검색 스테이지에서 활용할 호스팅된 임베딩 모델을 선택할 수 있습니다. 다음 임베딩 모델은 Cortex Search에서 사용할 수 있습니다.
중요
모델 가격은 다양합니다. 표준 모델 가격은 `Snowflake Service Consumption Table`_에서 확인할 수 있습니다. 아래에 표시된 가격이 Snowflake Service Consumption Table에 표시된 모델 가격과 다른 경우, Snowflake Service Consumption Table의 가격이 우선 적용됩니다.
모델 이름입니다. |
출력 차원 |
컨텍스트 윈도우 크기(토큰) |
언어 지원 |
설명 |
|---|---|---|---|---|
|
768 |
512 |
영어 전용 |
Snowflake의 가장 실용적인 영어 전용 임베딩 모델입니다. 1억 1천만 개의 매개 변수가 있는 이 오픈 소스 모델은 Cortex Search에서 사용 가능한 모델 중 가장 빠른 인덱싱 시간을 제공합니다. 자세한 내용은 Arctic Embed 1.5 블로그 게시물 및 Arctic Embed 1.5 모델 카드 를 참조하십시오. |
|
1024 |
512 |
다국어 |
Snowflake의 가격 대비 성능이 우수한 다국어 임베딩 모델로, 컨텍스트 윈도우는 512개의 토큰입니다. 이 오픈 소스 568M 매개 변수 모델은 영어 및 비영어 데이터 세트 모두에서 높은 품질을 제공합니다. 자세한 내용은 `Arctic Embed 2 블로그 게시물<https://www.snowflake.com/en/engineering-blog/snowflake-arctic-embed-2-multilingual/>`_ 및 `Arctic Embed 2 모델 카드<https://huggingface.co/Snowflake/snowflake-arctic-embed-l-v2.0>`_를 참조하세요. |
|
1024 |
8192 |
다국어 |
Snowflake의 가격 대비 성능이 우수한 다국어 임베딩 모델로, 8000개의 토큰으로 확장된 컨텍스트 윈도우를 적용했습니다. 이 오픈 소스 568M 매개 변수 모델은 영어 및 비영어 데이터 세트 모두에서 높은 품질을 제공합니다. |
|
1024 |
32,000 |
다국어 |
Voyage의 다국어 임베딩 모델. 이 모델은 영어와 비영어 데이터 세트 모두에서 높은 품질을 제공합니다. 자세한 내용은 Voyage Multilingual 2 블로그 게시물 을 참조하십시오. |
일부 임베딩 모델은 특정 클라우드 리전에서만 Cortex Search를 사용할 수 있습니다. 리전을 기준으로 한 모델별 가용성 목록은 Cortex Search 리전별 가용성 섹션을 참조하십시오.
각 모델은 성능, 비용, 컨텍스트 윈도우 크기, 품질 특성이 다릅니다. 특정 워크로드에 가장 적합한 모델을 결정하려면 모델 사양을 신중하게 검토하세요. 각 모델의 100만 개의 토큰당 크레딧 비용을 가장 정확하게 확인하려면 `Snowflake Service Consumption Table`_을 참조하세요.
토큰, 모델 컨텍스트 윈도우, 텍스트 분할¶
토큰은 일련의 문자이며 대규모 언어 모델이 처리할 수 있는 가장 작은 텍스트 단위입니다. 대략적으로 토큰 하나는 영어 단어의 약 3/4, 즉 약 4개 문자에 해당합니다. 문자열의 토큰 수를 계산하려면 COUNT_TOKENS Cortex 함수</sql-reference/functions/count_tokens-snowflake-cortex>`를 사용합니다. 예를 들어, ``snowflake-arctic-embed-m-v1.5` 모델로 임베드할 문자열에 대한 토큰을 계산합니다.
각 벡터 임베딩 모델은 텍스트 입력에 대해 고정 크기의 컨텍스트 윈도우를 지원하며, 이는 앞선 임베딩 모델 테이블에 명시되어 있습니다. 인덱싱 및 서비스 처리 시 검색 열의 값에 포함된 토큰 수가 컨텍스트 윈도우 크기를 초과할 경우, Cortex Search는 의미 체계 검색을 위해 벡터 공간에 임베딩하기 전에 해당 문자열을 컨텍스트 윈도우 크기로 잘라냅니다. 그러나 Cortex Search는 키워드 기반 검색을 위해 텍스트 전체를 사용합니다.
Snowflake는 텍스트를 더 작은 청크로 분할하는 데 도움을 주는 기본 제공 함수를 제공합니다. 자세한 내용은 :doc:`SPLIT_TEXT_RECURSIVE_CHARACTER </sql-reference/functions/split_text_recursive_character-snowflake-cortex> ` 섹션을 참조하십시오.
최상의 검색 결과를 얻으려면 Cortex Search에서 검색 열의 텍스트를 512개 이하의 토큰(영어 단어 약 385개) 청크로 분할하는 것이 좋습니다. 현재 더 긴 컨텍스트 임베딩 모델(예: snowflake-arctic-embed-l-v2.0-8k)이 존재하지만, `연구 <https://www.snowflake.com/en/engineering-blog/impact-retrieval-chunking-finance-rag/>`_에 따르면 *더 작은 청크 크기가 일반적으로 더 높은 검색 성능과 다운스트림 LLM 응답 품질*을 가져옵니다. 더 작은 청크를 사용하면 주어진 쿼리에 대해 검색이 더 정밀해질 수 있으며, 검색 증강 생성(RAG) 시나리오에서는 다운스트림 LLM이 쿼리와 더 관련성이 높은 텍스트 청크를 수신하게 됩니다.
새로 고침¶
Cortex Search Service에서 제공되는 콘텐츠는 특정 쿼리의 결과를 기반으로 합니다. Cortex Search Service의 기반 데이터가 변경되면 해당 서비스가 업데이트되어 변경 사항을 반영합니다. 이러한 업데이트를 새로 고침 이라고 합니다. 이 프로세스는 자동화되어 있으며 테이블의 기반이 되는 쿼리를 분석하는 작업을 포함합니다.
Cortex Search Services는 동적 테이블과 동일한 새로 고침 속성을 갖습니다. Cortex Search Service의 새로 고침 특성을 이해하려면 동적 테이블 초기화 및 새로 고침 이해 항목을 참조하십시오.
Cortex Search Service의 소스 쿼리는 동적 테이블 증분 새로 고침의 후보여야 합니다. 해당 요구 사항에 대한 자세한 내용은 증분 새로 고침 지원 섹션을 참조하십시오. 이러한 제한은 벡터 임베딩 계산과 관련된 원치 않는 비용 급증을 방지하기 위해 고안되었습니다. 동적 테이블 증분 새로 고침에 지원되지 않는 구성에 대한 자세한 내용은 동적 테이블에 대해 지원되는 쿼리 섹션을 참조하십시오.
기본 키¶
Cortex Search Service의 기본 키는 소스 쿼리의 각 행을 고유하게 식별하는 선택적 열 세트입니다(즉, 지정된 열에서 정확히 동일한 값 조합을 가진 행은 하나뿐임). Cortex Search Service와 함께 사용하려면 기본 키 열은 TEXT 데이터 타입이어야 합니다.
서비스 생성 시 다음과 같이 기본 키를 지정할 수 있습니다.
기존 서비스의 기본 키 열은 ``ALTER CORTEX SEARCH SERVICE … SET PRIMARY KEY (…)``로 수정할 수 있습니다. 자세한 구문은 ALTER CORTEX SEARCH SERVICE 섹션을 참조하세요.
기본 키가 있는 서비스는 서비스 기반 데이터가 변경될 때 최적화된 새로 고침 경로를 활용할 수 있습니다. 이 최적화된 경로를 통해 새로 고침 비용과 대기 시간을 크게 줄일 수 있습니다. 이 최적화를 활성화하면 검색 서비스가 새로 고침 중에 생성된 인덱스 정보를 주기적으로 압축합니다. 서비스에 FULL_INDEX_BUILD_INTERVAL_DAYS 속성을 설정하여 인덱스 새로 고침의 대상 빈도를 지정할 수 있습니다. 구문 세부 정보는 CREATE CORTEX SEARCH SERVICE 및 ALTER CORTEX SEARCH SERVICE 섹션을 참조하세요.
참고
``FULL_INDEX_BUILD_INTERVAL_DAYS``는 소프트 타겟입니다. 서비스 목표 지연, 서비스 소스 데이터의 변경률, 전체 서비스 크기와 같은 요소를 기반으로 서비스 성능을 최적화하기 위해 지정된 간격보다 전체 재빌드가 더 자주 발생할 수 있습니다.
기본 키를 사용하는 서비스에 대한 쿼리에서는 @primarykey :ref:`필터 연산자<label-cortex-search-query-filter-syntax>`도 활용할 수 있습니다.
중요
소스 쿼리의 각 행에 대해 기본 키 열 값의 세트는 고유해야 합니다. 중복 항목은 결과 검색 인덱스에서 무시됩니다.
다중 인덱스 Cortex Search¶
Cortex Search는 여러 열을 인덱싱하거나 쿼리에 사용자 지정 벡터 임베딩을 사용할 수 있으므로 Cortex Search Service가 데이터를 해석하고 사용자 요청에 응답하는 방식에 유연성을 더합니다. 다음 중 하나 이상을 특징으로 하는 사용 사례가 있는 경우 다중 인덱스 Cortex Search를 사용해야 합니다.
다중 검색 필드: 사용자는 레코드의 다양한 필드를 검색해야 합니다.
사용자 제공 벡터 임베딩: Cortex Search Service에 수집하기 전에 하나 이상의 열에 대해 미리 계산된 벡터 임베딩이 있습니다.
혼합 검색 유형: 검색 유형에 우선하여 다양한 필드 검색을 지원하려고 합니다.
정확한 키워드 또는 퍼지 키워드 일치가 중요한 필드에는 *텍스트 인덱스*를 사용합니다. 몇 가지 예로는 제품 코드, 이름, 카테고리 등이 있습니다.
의미 체계 이해가 중요한 더 긴 텍스트 내용이 있는 필드에는 벡터 인덱스 를 사용합니다. 예로는 제품 설명, 사용자 리뷰, 지원 사례 등이 있습니다.
필드별 관련성: 데이터의 다양한 필드는 검색 결과의 관련성에 다르게 기여해야 합니다.
예를 들어 제품 카탈로그 검색 사용 사례의 경우 다중 인덱스 서비스를 생성할 수 있습니다. 여기서,
제품 이름 및 SKUs는 정확한 어휘 일치를 위한 *텍스트 인덱스*입니다.
제품 설명은 의미 체계 일치를 위한 *벡터 인덱스*입니다.
카테고리 이름과 브랜드 이름은 모두 텍스트 및 벡터 인덱스로, 어휘와 의미 일치를 모두 지원합니다.
다중 인덱스 Cortex Search Service를 생성하는 예제는 CREATE CORTEX SEARCH SERVICE … TEXT INDEXES .. VECTOR INDEXES 섹션을 참조하세요. 다중 인덱스 서비스를 쿼리하는 예제는 :ref:`Cortex Search Service 쿼리 - 다중 인덱스 쿼리<label-cortex_search_multi_query>`를 참조하세요.
사용자 제공 벡터 임베딩¶
다중 인덱스 Cortex Search를 사용하면 모든 임베딩 모델(오픈 소스, 상업용 및 사용자 지정 학습 모델 포함)에서 미리 계산된 벡터 임베딩을 사용할 수 있습니다. 사용자 제공 벡터 임베딩을 사용하는 경우:
Cortex Search에서 기본적으로 사용할 수 없는 임베딩 모델을 사용하거나 이미 생성한 임베딩을 재사용하여 비용을 절감하고 성능을 개선하려고 합니다.
하이브리드 검색을 위해 벡터 임베딩을 Cortex Search 텍스트 인덱스와 결합하려고 합니다.
VECTOR INDEXES 절에서 베어 열 이름은 지정하지만 모델은 지정하지 않는 경우, Cortex Search는 열의 내용을 사용자 제공 벡터 임베딩으로 처리합니다. 사용자 제공 벡터는 있는 그대로 인덱싱되며 임베딩 비용이 발생하지 않습니다.
참고
벡터는 Snowflake 테이블에 직접 로드할 수 없습니다. 대신, Cortex Search Service의 소스 테이블에 데이터를 삽입하거나 업데이트할 때 숫자 배열을 VECTOR 데이터 타입으로 캐스팅합니다. 이를 수행하는 방법에 대한 자세한 내용과 예제는 벡터 변환 섹션을 참조하세요.
Cortex Search는 검색 요청 시 쿼리 벡터를 제공하는지 또는 쿼리 텍스트를 제공하는지 여부에 따라 검색 시 다음 모드 중 하나를 선택합니다.
모드 |
인덱스 시간 |
쿼리 시간 |
|---|---|---|
완전 사용자 관리 |
VECTOR 열에 벡터 제공 |
multi_index_query를 통해 쿼리 벡터 제공 |
관리형 쿼리 임베딩을 사용한 사용자 관리 |
VECTOR 열에 벡터 제공 |
Cortex Search는 지정된 모델을 사용하여 쿼리 텍스트를 포함함 |
인덱싱 및 서비스 중단¶
Cortex Search Services는 동적 테이블과 마찬가지로 소스 쿼리와 관련된 새로 고침 실패가 5번 연속 발생하면 인덱싱 상태를 자동으로 일시 중단합니다. 서비스에서 이 오류가 발생하면 DESCRIBE CORTEX SEARCH SERVICE 또는 :doc:`/sql-reference/info-schema/cortex_search`를 사용하여 특정 SQL 오류를 확인할 수 있습니다. 두 명령의 출력에는 다음 열이 포함됩니다.
INDEXING_STATE 열로, 일시 중단된 서비스의 경우 SUSPENDED입니다.
INDEXING_ERROR 열로, 소스 쿼리에서 발생한 특정 SQL 오류가 포함됩니다.
루트 문제가 해결되면 ALTER CORTEX SEARCH SERVICE <이름> RESUME INDEXING 로 서비스를 재개할 수 있습니다. 자세한 구문은 ALTER CORTEX SEARCH SERVICE 섹션을 참조하십시오.
비용 고려 사항¶
Cortex Search Service는 다음과 같이 비용이 발생합니다.
카테고리 |
설명 |
|---|---|
가상 웨어하우스 컴퓨팅 |
텍스트 임베딩 작업 오케스트레이션 및 검색 인덱스 구축 등 서비스를 초기화 및 새로 고칠 때 기본 오브젝트에 대한 쿼리를 실행하기 위해 Cortex Search Service에는 가상 웨어하우스 가 필요합니다. 이러한 작업은 크레딧 을 소비하는 컴퓨팅 리소스를 사용합니다. 새로 고침 중에 변경 사항이 식별되지 않으면 새로 고칠 새로운 데이터가 없으므로 가상 웨어하우스 크레딧이 소비되지 않습니다. |
EMBED_TEXT 토큰 계산 |
Cortex Search Service는 |
다중 인덱스 Cortex Search |
다중 인덱스 Cortex Search Services의 비용은 토큰을 임베딩하는 방법 및 인덱싱하는 열 수에 따라 다릅니다. 임베딩 벡터가 크거나 인덱스 열 수가 많을수록 비용이 커집니다. 임베딩은 행이 삽입되거나 업데이트될 때마다 계산됩니다. 임베딩은 소스 쿼리 평가에서 점진적으로 처리되므로 임베딩 비용은 추가되거나 변경된 문서에 대해서만 발생합니다. |
컴퓨팅 제공 |
Cortex Search Service는 사용자가 제공하는 가상 웨어하우스와는 별도로 멀티테넌트 서비스 컴퓨팅을 사용하여 지연 시간이 짧고 처리량이 높은 서비스를 구축합니다. 이 구성 요소의 컴퓨팅 비용은 압축되지 않은 인덱스 데이터의 월당 GB(GB/월) 발생하며, 여기서 인덱스 데이터는 Cortex Search 소스 쿼리에서 사용자가 제공한 데이터와 사용자를 대신하여 계산된 벡터 임베딩을 말합니다. 특정 기간 동안 쿼리가 처리되지 않더라도 서비스가 쿼리에 응답할 수 있는 동안에는 이러한 비용이 발생합니다. 인덱스 데이터의 GB/월당 Cortex Search Serving 크레딧 요율은 Snowflake Service Consumption Table 을 참조하십시오. |
저장 |
Cortex Search Service는 소스 쿼리를 사용자의 계정에 저장된 테이블로 구체화합니다. 이 테이블은 지연 시간이 짧은 서비스 제공을 위해 최적화된 데이터 구조로 변환되어 사용자 계정에 저장됩니다. 테이블 및 중간 데이터 구조의 저장소는 테라바이트(TB)당 정액제를 기반으로 합니다. |
클라우드 서비스 컴퓨팅 |
Cortex Search Service는 클라우드 서비스 컴퓨팅 을 사용하여 기본 기본 오브젝트의 변경 사항과 가상 웨어하우스를 호출해야 하는지 여부를 식별합니다. 클라우드 서비스 컴퓨팅 비용은 일일 클라우드 서비스 비용이 계정의 일일 웨어하우스 비용의 10%보다 큰 경우에만 Snowflake가 요금을 청구하는 제약 조건을 따릅니다. |
Cortex Search Service 비용 관리에 대한 모범 사례는 Cortex Search Service 비용 이해하기 섹션을 참조하십시오.
계정의 각 Cortex Search Service에 대한 AI 서비스 관련 소비 비용을 매일 집계하여 보려면 CORTEX_SEARCH_DAILY_USAGE_HISTORY 뷰 를 참조하십시오.
알려진 제한 사항¶
Cortex Search의 사용에는 다음과 같은 제한이 적용됩니다.
기본 테이블 크기: 검색 서비스에서 구체화된 쿼리 결과의 크기가 1억 개 행 미만이어야 최적의 서비스 성능을 유지할 수 있습니다. 쿼리 결과의 구체화된 행 수가 1억 개를 초과하는 경우 생성 쿼리가 오류와 함께 실패합니다.
참고
Cortex Search Service의 행 크기 조정 한도를 1억 개 이상으로 늘리려면 Snowflake 계정 팀에 문의하십시오.
처리량 및 속도 제한: Cortex Search는 클라이언트가 요청을 너무 빨리 보내거나 서비스가 오버로드되는 경우 429 HTTP 상태 코드를 반환합니다. 검색 서비스를 호출하는 클라이언트 논리는 이러한 429 응답을 정상적으로 처리하기 위해 백오프 및 재시도 논리를 구현해야 합니다.
참고
단일 검색 서비스의 처리량을 20QPS 이상으로 늘리거나 계정의 모든 서비스에서 140QPS 이상으로 늘리려면 Snowflake 계정팀에 문의하세요.
쿼리 구성: Cortex Search Service 소스 쿼리는 동적 테이블과 동일한 쿼리 제한을 준수해야 합니다. 자세한 내용은 동적 테이블 제한 사항 섹션을 참조하십시오.
데이터 보존: Cortex Search Services에는 데이터 보존과 관련하여 동적 테이블과 동일한 요구 사항이 있습니다. 특히, 기본 테이블의 DATA_RETENTION_TIME_IN_DAYS 오브젝트 매개 변수를 0으로 설정하거나 검색 서비스가 포함된 스키마 또는 데이터베이스에서 이 매개 변수를 설정할 수 없습니다. 또한, MAX_DATA_EXTENSION_TIME_IN_DAYS 내에 새로 고침하지 않으면 검색 서비스가 부실해질 수 있습니다. 부실해진 경우 새로 고침을 재개하려면 다시 생성해야 합니다. 자세한 내용은 동적 테이블 제한 사항 섹션을 참조하세요.
복제: Cortex Search Services는 현재 :doc:`복제</user-guide/object-clone>`를 지원하지 않습니다. Snowflake는 향후 일부 릴리스에서 이 기능을 제공할 계획이지만 구체적인 일정은 보장할 수는 없습니다.
테이블 불변성: Cortex Search Service를 실행하는 동안에는 액세스하는 테이블이 수정되거나 삭제되지 않아야 합니다. Cortex Search Service에서 사용하는 테이블을 안전하게 업데이트하려면 변경 작업을 수행하기 전에 서비스를 중지하세요.
리전 가용성¶
이 기능은 다음 Snowflake 리전의 계정에서 사용할 수 있습니다. 리전 내 특정 임베딩 모델의 사용 가능 여부는 체크 표시로 표시됩니다.
클라우드 공급자
|
리전
|
snowflake-arctic-embed-m-v1.5 |
snowflake-arctic-embed-l-v2.0 |
snowflake-arctic-embed-l-v2.0-8k |
voyage-multilingual-2 |
|---|---|---|---|---|---|
AWS
|
US 서부 2(오리건)
|
✔ |
✔ |
✔ |
✔ |
AWS
|
US 동부 2(오하이오)
|
✔ |
✔ |
✔ |
|
AWS
|
US 동부 1(북부 버지니아)
|
✔ |
✔ |
✔ |
✔ |
AWS
|
US 동부(상업용 공공 - 북부 버지니아)
|
✔ |
✔ |
✔ |
✔ |
AWS
|
캐나다(중부)
|
✔ |
✔ |
✔ |
|
AWS
|
남미(상파울루)
|
✔ |
✔ |
✔ |
|
AWS
|
유럽(아일랜드)
|
✔ |
✔ |
✔ |
|
AWS
|
유럽(런던)
|
✔ |
✔ |
✔ |
|
AWS
|
유럽 중부 1(프랑크푸르트)
|
✔ |
✔ |
✔ |
✔ |
AWS
|
유럽(스톡홀름)
|
✔ |
✔ |
✔ |
|
AWS
|
아시아 태평양(도쿄)
|
✔ |
✔ |
✔ |
✔ |
AWS
|
아시아 태평양(뭄바이)
|
✔ |
✔ |
✔ |
|
AWS
|
아시아 태평양(시드니)
|
✔ |
✔ |
✔ |
|
AWS
|
아시아 태평양(자카르타)
|
✔ |
✔ |
✔ |
|
AWS
|
아시아 태평양(서울)
|
✔ |
✔ |
✔ |
|
Azure
|
동부 US 2(버지니아)
|
✔ |
✔ |
✔ |
|
Azure
|
서부 US 2(워싱턴)
|
✔ |
✔ |
✔ |
|
Azure
|
중남부 US(텍사스)
|
✔ |
✔ |
✔ |
|
Azure
|
UK 남부(런던)
|
✔ |
✔ |
✔ |
|
Azure
|
북유럽(아일랜드)
|
✔ |
✔ |
✔ |
|
Azure
|
서부 유럽(네덜란드)
|
✔ |
✔ |
✔ |
✔ |
Azure
|
스위스 북부(취리히)
|
✔ |
✔ |
✔ |
|
Azure
|
인도 중부(푸네)
|
✔ |
✔ |
✔ |
|
Azure
|
일본 동부(도쿄, 사이타마)
|
✔ |
✔ |
✔ |
|
Azure
|
동남아시아(싱가포르)
|
✔ |
✔ |
✔ |
|
Azure
|
호주 동부(뉴사우스웨일즈)
|
✔ |
✔ |
✔ |
|
GCP
|
유럽 서부 2(런던)
|
✔ |
✔ |
✔ |
|
GCP
|
유럽 서부 3(프랑크푸르트)
|
✔ |
✔ |
✔ |
|
GCP
|
유럽 서부 4(네덜란드)
|
✔ |
✔ |
✔ |
|
GCP
|
중동 센트럴 2 (담맘)
|
✔ |
✔ |
✔ |
|
GCP
|
US 중부(아이오와)
|
✔ |
✔ |
✔ |
|
GCP
|
US 동부 4(북부 버지니아)
|
✔ |
✔ |
✔ |
참고
위의 리전 중 하나에서 리전 간 추론 매개 변수 를 지정하여 기본 리전에서 직접 지원되지 않는 모델에 액세스할 수 있습니다.
리전 간 추론을 사용하여 다음 리전에서만 Cortex Search를 사용할 수 있습니다. 리전 간 추론과 함께 Cortex Search을 사용하려면 리전 간 추론 매개 변수 를 사용하십시오.
AWS 유럽(파리)
AWS 유럽(취리히)
AWS 아시아 태평양(싱가포르)
AWS 아시아 태평양(오사카)
Azure 캐나다 중부(토론토)
Azure 중부 US(아이오와)
Azure UAE 북부(두바이)
참고
리전 간 추론을 사용할 때 리전 간 쿼리 지연 시간은 클라우드 공급자 인프라와 네트워크 상태에 따라 달라집니다. Snowflake는 리전 간 추론을 활성화하여 특정 사용 사례를 테스트할 것을 권장합니다.
법적 고지¶
입력 및 출력의 데이터 분류는 다음 테이블과 같습니다.
입력 데이터 분류 |
출력 데이터 분류 |
지정 |
|---|---|---|
Usage Data |
Customer Data |
일반적으로 사용 가능한 함수는 Covered AI 기능입니다. 미리 보기 함수는 Preview AI 기능입니다. [1] |
자세한 내용은 Snowflake AI 및 ML 섹션을 참조하십시오.