Cortex AISQL Images¶
Cortex AI Images를 사용하면 다음을 수행할 수 있습니다.
이미지 비교
캡션 이미지
이미지 분류
이미지에서 엔터티 추출하기
검색 시스템에서 사용하기 위한 임베딩 벡터 생성
그래프와 차트의 데이터를 활용하여 질문에 답하기
다음 함수를 사용하여 이러한 작업을 수행할 수 있습니다.
입력 요구 사항¶
COMPLETE 멀티모달은 다음과 같은 특성을 가진 이미지를 처리할 수 있습니다.
요구 사항 |
값 |
|---|---|
파일 이름 확장자 |
|
스테이지 암호화 |
서버 측 암호화: |
데이터 타입 |
참고
스테이지에서 파일을 처리하는 기능은 현재 사용자 정의 네트워크 정책과 호환되지 않습니다.
이미지 처리를 위한 스테이지 만들기¶
처리할 이미지를 저장하기에 적합한 스테이지를 생성합니다. 스테이지에는 디렉터리 테이블과 서버 측 암호화가 있어야 합니다.
아래 SQL 에서 적절한 내부 스테이지를 생성합니다.
CREATE OR REPLACE STAGE input_stage
DIRECTORY = ( ENABLE = true )
ENCRYPTION = ( TYPE = 'SNOWFLAKE_SSE' );
다음의 SQL은 Amazon S3에 외부 스테이지를 생성합니다. Azure 및 GCP 외부 스테이지도 지원됩니다.
CREATE OR REPLACE STAGE input_stage
URL='s3://<s3-path>/'
DIRECTORY = ( ENABLE = true )
CREDENTIALS = (AWS_KEY_ID = <aws_key_id>
AWS_SECRET_KEY = <aws_secret_key>)
ENCRYPTION = ( TYPE = 'AWS_SSE_S3' );
참고
새 파일이나 업데이트된 파일이 가용할 때 외부 스테이지의 디렉터리 테이블을 자동으로 새로 고치려면 스테이지를 만들 때 AUTO_REFRESH = true 옵션을 전달하십시오. 자세한 내용은 CREATE STAGE 섹션을 참조하십시오.
이미지 분석¶
COMPLETE 함수는 단일 이미지 또는 여러 이미지를 처리합니다(예: 여러 이미지에서 엔터티의 차이점을 추출하는 경우). 함수 호출은 다음을 지정합니다.
사용할 멀티모달 모델
프롬프트
FILE 오브젝트를 통한 이미지 파일의 스테이지 경로입니다
비전 Q&A 예시¶
다음 예는 Anthropic의 Claude Sonnet 3.5 모델을 사용하여 @myimages 스테이지에 저장된 파이 차트 science-employment-slide.jpeg 를 요약한 것입니다.
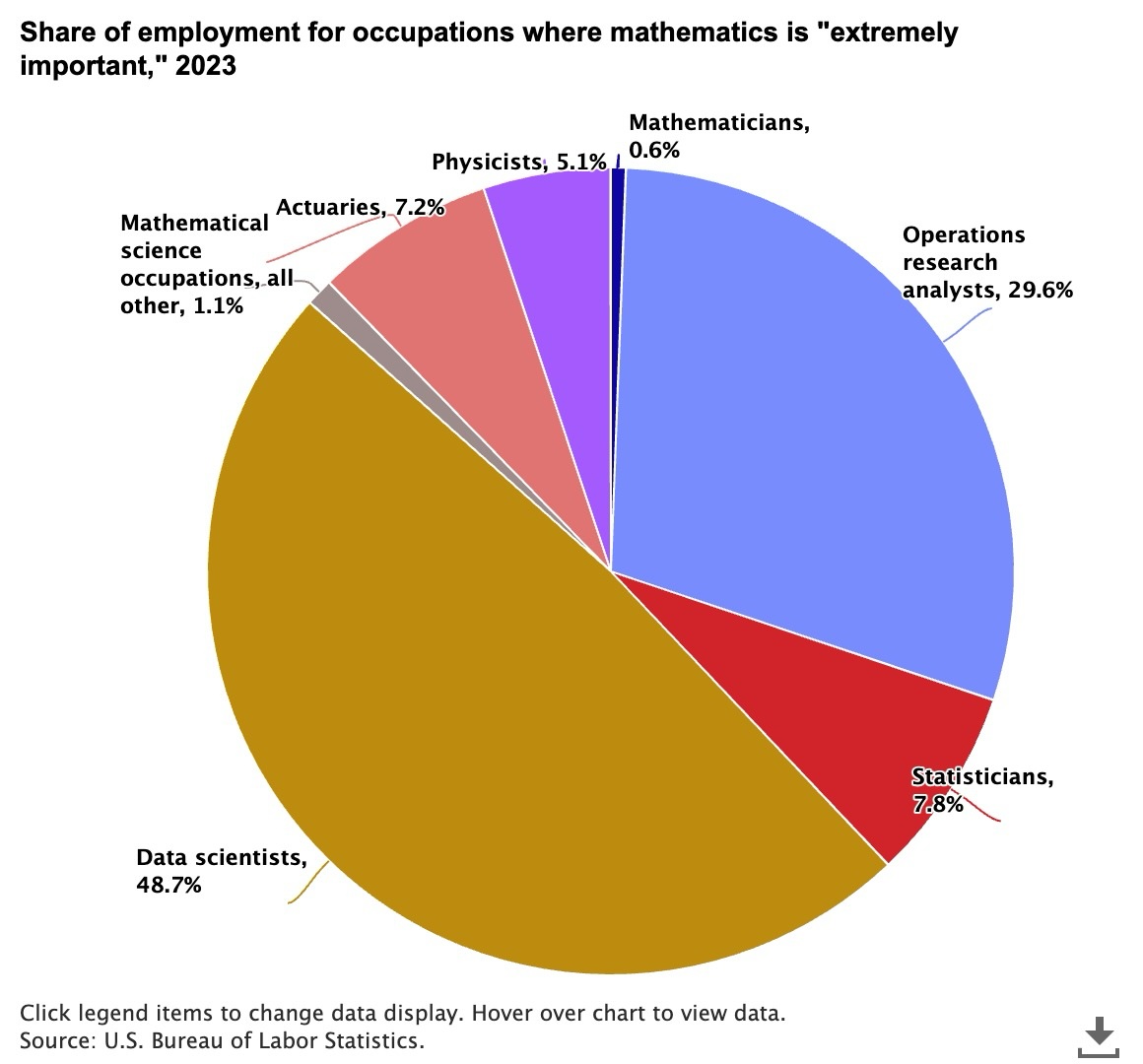
2023년 수학이 ‘매우 중요’하다고 여겨지는 직업의 분포도¶
SELECT AI_COMPLETE('claude-3-5-sonnet',
'Summarize the insights from this pie chart in 100 words',
TO_FILE('@myimages', 'science-employment-slide.jpeg'));
응답:
This pie chart shows the distribution of occupations where mathematics is considered "extremely important" in 2023.
Data scientists dominate with nearly half (48.7%) of all such positions, followed by operations research analysts
at 29.6%. The remaining positions are distributed among statisticians (7.8%), actuaries (7.2%), physicists (5.1%),
mathematicians (0.6%), and other mathematical science occupations (1.1%). This distribution highlights the growing
importance of data science in mathematics-intensive careers, while traditional mathematics roles represent a smaller
share of the workforce.
이미지 비교 예시¶
참고
현재 Anthropic(claude) 및 Meta(llama) 모델만 단일 프롬프트에서 여러 이미지를 참조할 수 있습니다. 다른 모델에 대한 다중 이미지 지원은 향후 릴리스에서 가용성이 향상될 수 있습니다.
PROMPT 도우미 함수 를 사용하여 한 번의 COMPLETE 호출로 여러 이미지를 처리할 수 있습니다. 다음 예시에서는 Anthropic의 Claude Sonnet 3.5 모델을 사용하여 @myimages 스테이지의 서로 다른 두 광고 크리에이티브를 비교합니다.

전기 자동차 광고 2개의 이미지¶
SELECT AI_COMPLETE('claude-3-5-sonnet',
PROMPT('Compare this image {0} to this image {1} and describe the ideal audience for each in two concise bullets no longer than 10 words',
TO_FILE('@myimages', 'adcreative_1.png'),
TO_FILE('@myimages', 'adcreative_2.png')
));
응답:
First image ("Discover a New Energy"):
• Conservative luxury SUV buyers seeking a subtle transition to electrification
Second image ("Electrify Your Drive"):
• Young, tech-savvy urbanites attracted to bold, progressive automotive design
이미지 분류 예시¶
다음 예시에서는 부동산 애플리케이션에서 이미지를 분류하기 위해 AI_CLASSIFY를 사용합니다.

다음의 SQL은 AI_CLASSIFY 함수를 사용하여 이미지를 거실, 주방, 욕실, 정원 또는 안방 침실 이미지로 분류합니다.
SELECT AI_CLASSIFY(TO_FILE('@my_images', 'REAL_ESTATE_STAGING.PNG'),
['Living Area', 'Kitchen', 'Bath', 'Garden', 'Master Bedroom']) AS room_classification;
응답:
{ "labels": [ "Living Area" ] }
아래의 SQL은 위 이미지에서 발견된 오브젝트를 소파, 창문, 테이블, 텔레비전 또는 예술 작품으로 분류합니다.
SELECT AI_CLASSIFY (TO_FILE ('@my_images', 'REAL_ESTATE_STAGING.PNG'),
['Couch', 'Window', 'Table', 'Television', 'Art'], {'output_mode': 'multi'} )
AS living_room_objects;
응답:
{
"labels": [
"Art",
"Couch",
"Table",
"Window"
]
}
이미지 검색¶
AI_EMBED를 사용하면 대상 이미지와 유사한 이미지를 찾을 수 있습니다. 먼저, AI_EMBED 함수를 사용하여 대상 이미지의 임베딩 벡터를 생성하고, 대상 이미지의 시각적 특징을 추상적인 벡터 공간, 즉 이미지 특징의 수치적 표현으로 매핑합니다. 그런 다음, 벡터 유사성 함수를 사용하여 이 임베딩 벡터를 다른 이미지의 임베딩 벡터와 비교하여 공통적이거나 유사한 시각적 특징을 기반으로 한 유사성 점수를 산출할 수 있습니다. 이 점수는 대상 이미지와의 유사성에 따라 이미지를 분류, 순위 지정 또는 필터링하는 데 사용할 수 있습니다.

|

|
예를 들어, 위의 이미지가 주어졌을 때, 다음의 SQL은 각 이미지에 대한 임베딩 벡터를 생성한 다음, 코사인 유사도를 사용하여 벡터들을 비교합니다. 결과값 약 0.5는 이미지들이 어느 정도 유사함을 나타냅니다. 두 사진 모두 도시 환경에서 촬영되었으며 배경에 군중이 등장하지만, 주요 피사체는 서로 다릅니다.
WITH ai_image_embeddings as (
SELECT
AI_EMBED('voyage-multimodal-3',
TO_FILE ('@my_images', 'CITY_WALKING1.PNG')) as image1_embeddings,
AI_EMBED('voyage-multimodal-3',
TO_FILE ('@my_images', 'CITY_WALKING2.PNG')) as image2_embeddings
)
SELECT VECTOR_COSINE_SIMILARITY(image1_embeddings,image2_embeddings) as similarity FROM ai_image_embeddings;
0.5359029029
대상 이미지와 유사한 이미지를 찾으려면 AI_SIMILARITY를 사용할 수 있습니다. 아래 예시는 수천 장의 이미지에 대해 유사성 점수를 계산하고, 아래 오토바이 광고와 가장 유사한 광고 크리에이티브를 반환합니다.

SELECT
TO_FILE('@ad_images', relative_path) as ALL_ADS
FROM DIRECTORY(@ad_images)
WHERE AI_SIMILARITY(TO_FILE('@ad_images', 'image_226.jpg'), ALL_ADS) >= 0.5;
이 쿼리는 유사성 점수가 0.50보다 큰 다중 모달 테이블의 이미지를 반환합니다. 확인된 이미지 중 하나(image_226.jpg)는 우리가 참조용으로 사용한 이미지입니다.
+-----------------------------------------------------------+
| {} ALL_ADS |
+-----------------------------------------------------------+
| { "CONTENT_TYPE": "image/jpeg", |
| "ETAG": "686897696a7c876b7e", |
| "LAST_MODIFIED": "Wed, 26 Mar 2025 18:11:45 GMT", |
| "RELATIVE_PATH": "image_226.jpg", |
| "SIZE": 39086, |
| "STAGE": "@ad_images" } |
+-----------------------------------------------------------+
| { "CONTENT_TYPE": "image/jpeg", |
| "ETAG": "e7b678c7a696798686", |
| "LAST_MODIFIED": "Wed, 26 Mar 2025 18:11:57 GMT", |
| "RELATIVE_PATH": "image_441.jpg", |
| "SIZE": 12650, |
| "STAGE": "@ad_images" }, |
+-----------------------------------------------------------+
모델 제한 사항¶
Snowflake Cortex에서 사용 가능한 모든 모델에는 모델의 컨텍스트 윈도우 로 알려진 총 입력 및 출력 토큰 수에 제한이 있습니다. 컨텍스트 윈도우 크기는 토큰 단위로 측정됩니다. 컨텍스트 윈도우 제한을 초과하는 입력은 오류가 발생합니다.
텍스트 모델의 경우 토큰은 일반적으로 약 4문자의 텍스트를 나타내므로 제한에 해당하는 단어 수는 토큰 수보다 적습니다.
이미지 모델의 경우 이미지당 토큰 수는 비전 모델의 아키텍처에 따라 달라집니다. 프롬프트 내의 토큰(예: “what animal is this?”)도 모델의 컨텍스트 윈도우에 기여합니다.
모델 |
컨텍스트 윈도우(토큰) |
파일 유형 |
파일 크기 |
프롬프트별 이미지 |
|---|---|---|---|---|
|
1,047,576 |
.jpg, .jpeg, .png, .webp, .gif |
10MB |
5 |
|
1,047,576 |
.jpg, .jpeg, .png, .webp, .gif |
10MB |
5 |
|
200,000 |
.jpg, .jpeg, .png, .webp, .gif |
3.75 MB [L1] |
20 |
|
200,000 |
.jpg, .jpeg, .png, .webp, .gif |
3.75 MB [L1] |
20 |
|
200,000 |
.jpg, .jpeg, .png, .webp, .gif |
3.75 MB [L1] |
20 |
|
200,000 |
.jpg, .jpeg, .png, .webp, .gif |
3.75 MB [L1] |
20 |
|
128,000 |
.jpg, .jpeg, .png, .webp, .gif, .bmp |
10 MB |
10 |
|
128,000 |
.jpg, .jpeg, .png, .webp, .gif, .bmp |
10 MB |
10 |
|
128,000 |
.jpg, .jpeg, .png, .webp, .gif, .bmp |
10 MB |
1 |
|
32,768 |
.jpg, .png, .pg, .gif, .bmp |
10 MB |
1 |
비용 고려 사항¶
청구는 처리된 토큰 수에 따라 조정됩니다. 이미지당 토큰 수는 비전 모델의 아키텍처에 따라 다릅니다.
인트로픽(
claude) 모델의 공식은 대략 토큰 = (너비(픽셀) x 높이(픽셀)) / 750입니다.Mistral(
pixtral) 모델은 각 이미지를 16x16픽셀 배치로 나누고 각 배치를 토큰으로 변환합니다. 토큰의 총 개수는 대략 (너비(픽셀)/16) * (높이(픽셀)/16)에 해당합니다.Meta (
llama) 모델은 이미지를 정사각형 타일로 타일링하려고 합니다. 이미지의 가로 세로 비율과 크기에 따라 타일의 수는 최대 16개까지 가능하며, 각 타일은 약 153개의 토큰으로 표현됩니다.Open AI 모델은 이미지 크기를 재조정하고 정사각형 패치로 타일화합니다. ``openai-gpt-4.1``의 경우, 이미지 비율과 크기에 따라 토큰 수는 211개(최대 512x512px 이미지), 352개(긴 변의 길이가 1024px인 직사각형 이미지), 또는 630개(최소 1024x1024px 정사각형 이미지)부터 913개(짧은 변의 길이가 1024px인 직사각형 이미지)까지 가능합니다. ``openai-o4-mini``의 경우, 재조정 로직이 더 복잡하며 토큰 수는 86개(128x512px)부터 1428개(2048x1024px)까지 다양하고 선형 패턴을 따르지 않습니다.
``voyage-multimodal-3``은 약 14x14px 크기의 이미지 패치 배열을 대상으로 작동합니다. 이미지는 최소 64개 패치에서 최대 2500개 패치로 구성된 격자에 덮이도록 재조정됩니다. 이미지 크기와 종횡비에 따라 입력 토큰 수는 66개에서 2502개까지 변동되며, 여기에 추가로 두 개의 이미지 토큰이 더해집니다.
참고
COUNT_TOKENS 함수는 현재 이미지 입력을 지원하지 않습니다.
비전 모델 선택하기¶
COMPLETE 함수는 다양한 함수, 지연 시간 및 비용의 여러 모델을 지원합니다. 크레딧당 성능을 최적화하려면 내용 크기와 작업 복잡도에 맞는 모델을 선택하십시오.
모델 |
MMMU |
Mathvista |
ChartQA |
DocVQA |
VQAv2 |
|---|---|---|---|---|---|
GPT-4o |
68.6 |
64.6 |
85.1 |
88.9 |
77.8 |
|
75.0 |
72.0 |
|||
|
81.6 |
84.3 |
|||
|
68.0 |
64.4 |
87.6 |
90.3 |
70.7 |
|
73.4 |
73.7 |
90 |
94.4 |
|
|
69.4 |
70.7 |
88.8 |
94.4 |
|
|
64.0 |
69.4 |
88.1 |
85.7 |
67 |
벤치마크는 다음과 같습니다.
MMMU: 대학 수준의 추론이 필요한 다학제적 작업에 대한 멀티모달 모델을 평가합니다.
Mathvista: 시각적 컨텍스트 내 수학적 추론 벤치마크.
ChartQA: 차트에 대한 복잡한 추론 문제를 평가합니다.
DocVQA 및 VQv2: 문서의 시각적 질문에 대한 답변 벤치마크.
다중 모달 임베딩의 경우, 현재는 voyage-multimodal-3 모델만 이용 가능합니다. voyage-multimodal-3``은 텍스트와 이미지를 임베딩할 수 있는 최첨단 다중 모달 임베딩 모델입니다. 이는 PDFs의 스크린샷, 슬라이드, 테이블, 그림 등의 소스에서 핵심 시각적 특징을 추출할 수 있어 복잡한 문서 파싱 워크플로의 필요성을 줄여줍니다. Voyage AI 내부 벤치마크에 따르면, ``voyage-multimodal-3 모델은 OpenAI CLIP Large, Amazon Titan Multimodal, Cohere Multimodal v3 등 경쟁 모델들을 능가하는 성능을 보입니다.
리전 가용성¶
이 기능에 대한 지원은 다음 Snowflake 리전에 있는 계정에서 기본적으로 사용할 수 있습니다.
모델
|
AWS US 서부 2
(오리건)
|
AWS US 동부 1
(북부 버지니아)
|
AWS 유럽 중부 1
(프랑크푸르트)
|
|---|---|---|---|
|
✔ |
✔ |
|
|
|||
|
|||
|
|||
|
✔ |
✔ |
✔ |
|
✔ |
||
|
✔ |
||
|
AI_COMPLETE는 :doc:`리전 간 추론</user-guide/snowflake-cortex/cross-region-inference>`을 통해 추가 리전에서 이용 가능합니다.
오류 조건¶
메시지 |
설명 |
|---|---|
원격 서비스 오류로 외부 함수 SYSTEM$COMPLETE_WITH_IMAGE_INTERNAL 요청에 실패: 400 ‘“invalid image path” |
파일 확장자 또는 파일 자체가 모델에서 허용되지 않습니다. 이 메시지는 파일 경로가 잘못되었음을 의미할 수도 있습니다. 즉, 파일이 지정된 위치에 존재하지 않습니다. 파일 이름은 대/소문자를 구분합니다. |
보안 오브젝트에 오류 발생 |
스테이지가 존재하지 않음을 나타낼 수 있습니다. 스테이지 이름을 확인하고 해당 스테이지가 존재하고 액세스할 수 있는지 확인합니다. |
외부 함수 _COMPLETE_WITH_PROMPT 에 대한 요청이 원격 서비스 오류로 인해 실패: 400 ‘“invalid request parameters: unsupported image format: image/** |
|
외부 함수 _COMPLETE_WITH_PROMPT 에 대한 요청이 원격 서비스 오류로 인해 실패: 400 ‘“invalid request parameters: Image data exceeds the limit of 5.00 MB” |
|
법적 고지 사항¶
입력 및 출력의 데이터 분류는 다음 테이블과 같습니다.
입력 데이터 분류 |
출력 데이터 분류 |
지정 |
|---|---|---|
Usage Data |
Customer Data |
일반적으로 사용 가능한 함수는 Covered AI 기능입니다. 미리 보기 함수는 Preview AI 기능입니다. [1] |
자세한 내용은 Snowflake AI 및 ML 섹션을 참조하십시오.