AI_PARSE_DOCUMENT로 문서 구문 분석하기¶
AI_PARSE_DOCUMENT는 문서에서 텍스트, 데이터, 레이아웃 요소, 이미지를 추출하는 Cortex AI 함수입니다. 다른 함수와 함께 사용하여 다양한 사용 사례에 대한 사용자 지정 문서 처리 파이프라인을 생성할 수 있습니다(Cortex AI 함수: 문서 참조).
AI_PARSE_DOCUMENT를 사용한 이미지 추출에 대한 자세한 내용은 Cortex AI 함수: AI_PARSE_DOCUMENT를 사용하여 이미지 추출 섹션을 참조하세요.
함수는 내부 또는 외부 스테이지에 저장된 문서에서 텍스트와 레이아웃을 추출하고 테이블 및 헤더와 같은 읽기 순서와 구조를 유지합니다. 문서 저장에 적합한 스테이지를 만드는 방법에 대한 자세한 내용은 미디어 파일을 위한 스테이지 만들기 섹션을 참조하세요.
AI_PARSE_DOCUMENT는 문서 이해 및 레이아웃 분석을 위한 고급 AI 모델을 조율하여 복잡한 다중 페이지 문서를 높은 정확도로 처리합니다.
AI_PARSE_DOCUMENT 함수는 PDF 문서를 처리하기 위한 두 가지 모드를 제공합니다.
LAYOUT 모드는 대부분의 사용 사례, 특히 복잡한 문서에 대해 선호되는 선택입니다. 이는 특히 텍스트를 추출하거나 테이블과 같은 레이아웃 요소를 추출하는 데 최적화되어 있으므로 지식 기반 구축, 검색 시스템 최적화, AI 기반 애플리케이션 개선에 가장 적합한 선택입니다.
매뉴얼, 계약서, 제품 상세 페이지, 보험 증권 및 청구서, SharePoint 문서 등과 같은 문서에서 빠르고 고품질의 텍스트 추출을 위해서는 OCR 모드를 권장합니다.
두 모드 모두에서 page_split 옵션을 사용하여 응답에서 여러 페이지로 구성된 문서를 별도의 페이지로 분할합니다. page_filter 옵션을 사용하여 지정된 페이지만 처리할 수도 있습니다. ``page_filter``를 사용하는 경우 ``page_split``이 암시되므로 명시적으로 설정할 필요가 없습니다.
AI_PARSE_DOCUMENT는 수평으로 확장 가능하므로 여러 문서를 동시에 효율적으로 일괄 처리할 수 있습니다. 문서는 불필요한 데이터 이동을 피하기 위해 오브젝트 저장소에서 바로 처리할 수 있습니다.
참고
AI_PARSE_DOCUMENT 는 현재 사용자 지정 네트워크 정책 과 호환되지 않습니다.
예¶
간단한 레이아웃 예시¶
This example uses AI_PARSE_DOCUMENT’s LAYOUT mode to process a two-column research paper. The page_split parameter
is set to TRUE in order to separate the document into pages in the response. AI_PARSE_DOCUMENT returns the content in Markdown
format. The following shows rendered Markdown for one of the processed pages (page index 4 in the JSON output) next to
the original page. The raw Markdown is shown in the JSON response following the images.
원본 문서의 페이지 |
HTML로 렌더링된 추출된 마크다운 |
|---|---|

|

|
팁
이 이미지들을 더 읽기 쉬운 크기로 보려면 클릭하거나 탭하여 선택하세요.
다음은 원본 문서를 처리하기 위한 SQL 명령입니다.
AI_PARSE_DOCUMENT의 응답은 문서 페이지의 메타데이터와 텍스트를 포함하는 JSON 오브젝트입니다. 예를 들어, 다음과 같습니다. 간결함을 위해 일부 페이지 오브젝트가 생략되었습니다.
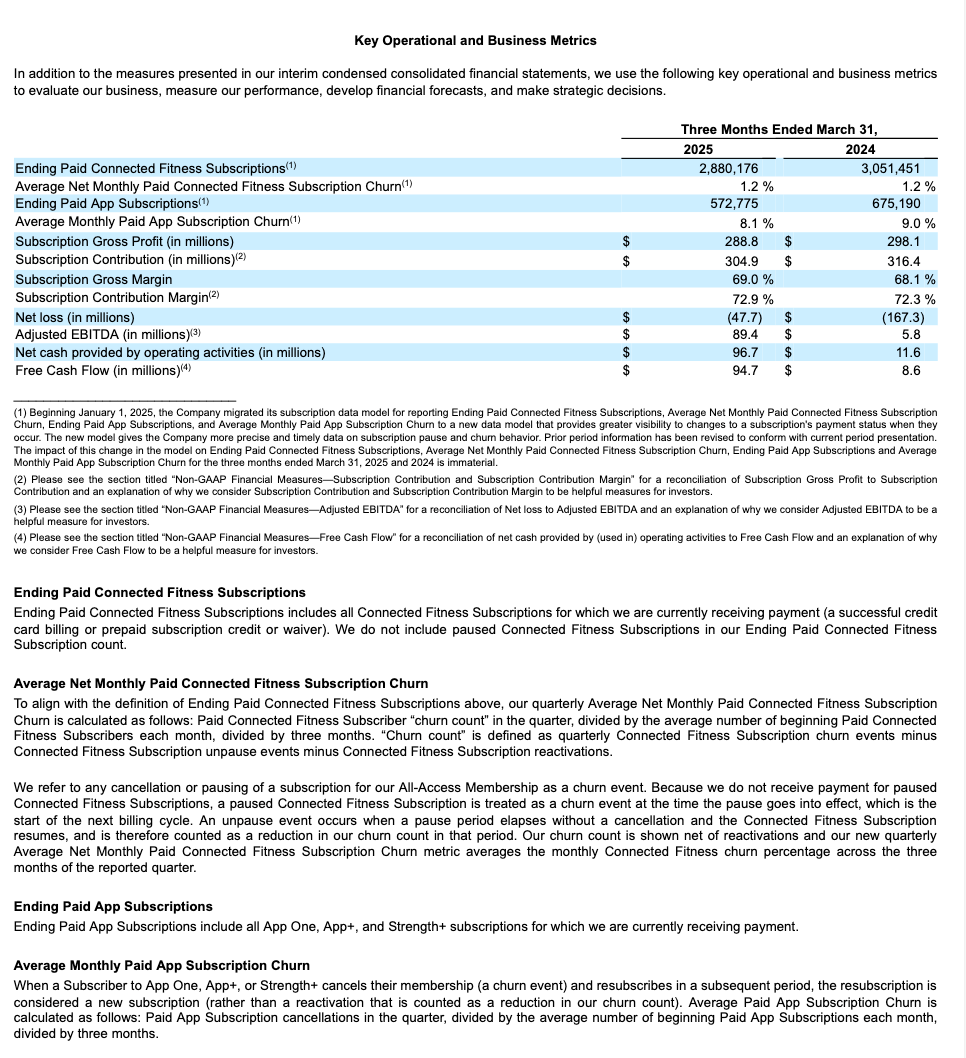
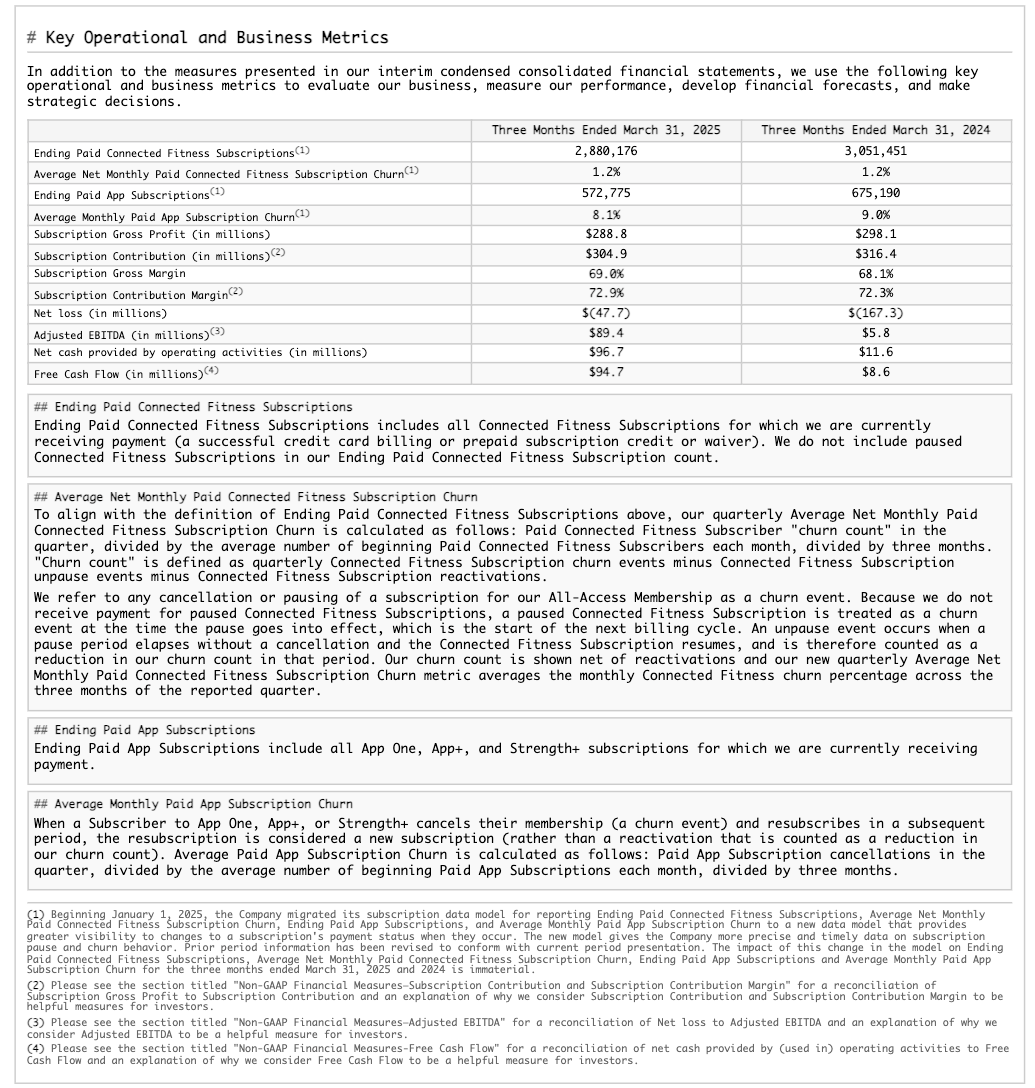
테이블 구조 추출 예시¶
이 예시에서는 10-K 제출 서류에서 테이블을 포함한 구조적 레이아웃을 추출하는 방법을 보여줍니다. 다음은 처리된 페이지 중 하나(JSON 출력에서 페이지 인덱스 28)에 대한 렌더링 결과를 보여줍니다.
원본 문서의 페이지 |
HTML로 렌더링된 추출된 마크다운 |
|---|---|
|
|
팁
이 이미지들을 더 읽기 쉬운 크기로 보려면 클릭하거나 탭하여 선택하세요.
다음은 원본 문서를 처리하기 위한 SQL 명령입니다.
AI_PARSE_DOCUMENT의 응답은 문서 페이지의 메타데이터와 텍스트를 포함하는 JSON 오브젝트입니다. 예를 들어, 다음과 같습니다. 간결함을 위해 이전에 표시된 페이지를 제외한 모든 결과는 생략되었습니다.
슬라이드 데크 예시¶
이 예시에서는 프레젠테이션에서 구조적 레이아웃을 추출하는 방법을 보여줍니다. 아래에는 처리된 슬라이드 중 하나(JSON 출력에서 페이지 인덱스 17)의 렌더링 결과를 보여줍니다.
원본 문서의 슬라이드 |
HTML로 렌더링된 추출된 마크다운 |
|---|---|

|

|
팁
이 이미지들을 더 읽기 쉬운 크기로 보려면 클릭하거나 탭하여 선택하세요.
다음은 원본 문서를 처리하기 위한 SQL 명령입니다.
AI_PARSE_DOCUMENT의 응답은 프레젠테이션 슬라이드의 메타데이터와 텍스트를 포함하는 JSON 오브젝트입니다. 예를 들어, 다음과 같습니다. 간결함을 위해 일부 슬라이드의 결과는 생략되었습니다.
다국어 문서 예시¶
이 예시에서는 독일어 기사에서 구조적 레이아웃을 추출함으로써 AI_PARSE_DOCUMENT의 다국어 기능을 보여줍니다. AI_PARSE_DOCUMENT는 이미지나 인용문이 포함된 경우에도 본문 텍스트의 읽기 순서를 유지합니다.
원본 문서의 페이지 |
HTML로 렌더링된 추출된 마크다운 |
|---|---|

|

|
팁
이 이미지들을 더 읽기 쉬운 크기로 보려면 클릭하거나 탭하여 선택하세요.
다음은 원본 문서를 처리하기 위한 SQL 명령입니다. 문서가 한 페이지로 구성되어 있으므로, 이 예시에서는 페이지 분할이 필요하지 않습니다.
AI_PARSE_DOCUMENT의 응답은 문서의 메타데이터와 텍스트를 포함하는 JSON 오브젝트입니다. 예를 들어, 다음과 같습니다.
Snowflake Cortex는 지원되는 모든 언어(이 경우 영어, 언어 코드 'en')로 다음과 같이 번역을 생성할 수 있습니다:
번역은 다음과 같습니다.
OCR 모드 사용¶
OCR 모드는 스캔된 문서(예: 스크린샷 또는 텍스트 이미지가 포함된 PDFs)에서 텍스트를 추출합니다. 이는 레이아웃을 유지하지 않습니다.
출력:
문서의 특정 페이지만 처리¶
This example demonstrates using the page_filter option to extract specific pages from a document, specifically
the first page of a 55-page research paper. Keep in mind that page indexes starts at 0 and ranges are inclusive of
the start value but exclusive of the end value. For example, start: 0, end: 1 returns only the first page (index 0).
결과:
여러 문서 분류¶
여러 문서를 분류하려면 먼저 디렉터리에서 문서 위치를 검색하고 이러한 위치를 FILE 오브젝트로 변환하여 파일 테이블을 만듭니다.
그런 다음, 테이블의 각 문서에 AI_PARSE_DOCUMENT를 적용하고 결과를 처리합니다. 예를 들어, 결과를 AI_CLASSIFY에 전달하여 문서를 유형별로 분류합니다. 이 방법은 문서 컬렉션에서 문서를 일괄적으로 분석하는 데 효율적입니다.
이 쿼리는 각 문서에 대한 분류 레이블을 반환합니다.
입력 요구 사항¶
AI_PARSE_DOCUMENT는 디지털 문서와 스캔 문서 모두에 최적화되어 있습니다. 다음 테이블은 입력 문서의 제한 사항 및 요구 사항을 나열합니다.
최대 파일 크기 |
100 MB |
|---|---|
문서당 최대 페이지 수 |
500 |
최대 페이지 해상도 |
|
지원되는 파일 유형 |
PDF, PPTX, DOCX, JPEG, JPG, PNG, TIFF, TIF, HTML, TXT |
스테이지 암호화 |
서버 측 암호화: |
글꼴 크기 |
최상의 결과를 얻으려면 8포인트 이상 |
지원되는 문서 기능 및 제한 사항¶
페이지 방향 |
AI_PARSE_DOCUMENT는 자동으로 페이지 방향을 감지합니다. |
|---|---|
페이지 분할 |
AI_PARSE_DOCUMENT는 여러 페이지로 구성된 문서를 개별 페이지로 분할하고 각각을 별도로 구문 분석할 수 있습니다. 이 방법은 최대 크기를 초과하는 큰 문서를 처리하는 데 유용합니다. |
페이지 필터링 |
AI_PARSE_DOCUMENT는 페이지 범위를 지정하여 문서의 모든 페이지가 아닌 일부 페이지를 처리할 수 있습니다. 이 방법은 찾고 있는 정보가 어떤 페이지에 있는지 알고 있을 때 유용합니다. |
문자 |
AI_PARSE_DOCUMENT 는 다음 문자를 감지합니다.
|
이미지 |
AI_PARSE_DOCUMENT는 문서 내 이미지에 대한 마크업을 생성하지만, 현재 실제 이미지를 추출하지는 않습니다. |
구조화된 요소들 |
AI_PARSE_DOCUMENT는 테이블과 양식을 자동으로 감지하고 추출합니다. |
글꼴 |
AI_PARSE_DOCUMENT는 대부분의 세리프 및 산세리프 글꼴의 텍스트를 인식하지만, 장식용 또는 필기체 글꼴의 경우 인식에 어려움이 있을 수 있습니다. 이 함수는 손글씨를 인식하지 못합니다. |
지원되는 언어¶
AI_PARSE_DOCUMENT는 다음 언어에 대해 훈련되었습니다.
OCR 모드 |
LAYOUT 모드 |
|---|---|
|
|
리전 가용성¶
AI_PARSE_DOCUMENT에 대한 지원은 다음 Snowflake 리전의 계정에서 사용할 수 있습니다.
AWS |
Azure |
Google Cloud Platform |
|---|---|---|
US 서부 2(오리건) |
동부 US 2(버지니아) |
US 중부(아이오와) |
US 동부(오하이오) |
서부 US 2(워싱턴) |
|
US 동부 1(북부 버지니아) |
유럽(네덜란드) |
|
유럽(아일랜드) |
||
유럽 중부 1(프랑크푸르트) |
||
Europe West 2 (London) |
||
아시아 태평양(시드니) |
||
아시아 태평양(도쿄) |
AI_PARSE_DOCUMENT는 다른 Snowflake 리전에서 리전 간 지원을 제공합니다. Cortex AI 리전 간 지원 활성화에 대한 정보는 리전 간 추론 섹션을 참조하세요.
액세스 제어 요구 사항¶
AI_PARSE_DOCUMENT 함수를 사용하려면 ACCOUNTADMIN 역할을 가진 사용자가 함수를 호출할 사용자에게 SNOWFLAKE.CORTEX_USER 데이터베이스 역할을 부여해야 합니다. 자세한 내용은 Cortex LLM 권한 항목을 참조하세요.
비용 고려 사항¶
Cortex AI_PARSE_DOCUMENT 함수는 처리된 문서당 페이지 수에 따라 컴퓨팅 비용이 발생합니다. 다음은 다양한 파일 형식에 대해 페이지가 계산되는 방식을 설명합니다.
페이지 파일 형식(PDF, DOCX)의 경우, 문서 내 각 페이지가 페이지 단위로 청구됩니다.
이미지 파일 형식(JPEG, JPG, TIF, TIFF, PNG)의 경우 각 개별 이미지 파일이 페이지 단위로 청구됩니다.
HTML 및 TXT 파일의 경우, 3,000자 단위로 구성된 각 청크가 페이지 단위로 청구됩니다. 마지막 청크는 3,000자 미만일 수 있습니다.
Snowflake는 더 작은 웨어하우스(MEDIUM보다 크지 않음)에서 Cortex AI_PARSE_DOCUMENT 함수를 호출하는 쿼리를 실행할 것을 권장합니다. 웨어하우스가 크다고 성능이 향상되는 것은 아닙니다.
오류 조건¶
Snowflake Cortex AI_PARSE_DOCUMENT는 다음과 같은 오류 메시지를 표시할 수 있습니다.
메시지 |
설명 |
|---|---|
|
입력 문서에 지원되지 않는 언어가 포함되어 있습니다 |
|
문서가 지원되지 않는 형식입니다. |
|
이 파일 형식은 지원되지 않으며 바이너리 파일로 이해됩니다. |
|
문서가 500페이지 제한을 초과합니다. |
|
이미지 입력 또는 변환된 문서 페이지가 지원되는 크기보다 큽니다. |
|
페이지가 지원되는 크기보다 큽니다. |
|
문서가 100MB보다 큽니다. |
|
파일이 존재하지 않습니다. |
|
권한이 부족하여 파일에 액세스할 수 없습니다. |
|
시간 제한이 발생했습니다. |
|
시스템 오류가 발생했습니다. 잠시 기다린 후 다시 시도하세요. |
법적 고지¶
입력 및 출력의 데이터 분류는 다음 테이블과 같습니다.
입력 데이터 분류 |
출력 데이터 분류 |
지정 |
|---|---|---|
Usage Data |
Customer Data |
일반적으로 사용 가능한 함수는 Covered AI 기능입니다. 미리 보기 함수는 Preview AI 기능입니다. [1] |
자세한 내용은 Snowflake AI 및 ML 섹션을 참조하십시오.