Cortex Search¶
Get started with Cortex Search
Vue d’ensemble¶
Cortex Search permet une recherche « floue » à faible latence et de haute qualité sur vos données Snowflake. Il propose un large éventail d’expériences de recherche pour les utilisateurs de Snowflake, notamment les applications de génération augmentée par récupération (RAG) exploitant des Large Language Models (LLMs).
Cortex Search vous permet de démarrer avec un moteur de recherche hybride (vecteur et mot-clé) sur vos données textuelles en quelques minutes, sans avoir à vous soucier de l’intégration, de la maintenance de l’infrastructure, du réglage des paramètres de qualité de recherche ou des actualisations continues de l’index. Cela signifie que vous pouvez consacrer moins de temps au réglage de l’infrastructure et de la qualité de la recherche, et plus de temps au développement d’expériences de chat et de recherche de haute qualité en utilisant vos données. Découvrez les Tutoriels Cortex Search pour des instructions étape par étape sur l’utilisation de Cortex Search pour alimenter des applications de chat et de recherche AI.
Quand utiliser Cortex Search¶
Les deux principaux cas d’utilisation de Cortex Search sont la génération augmentée par récupération (RAG) et la recherche en entreprise.
Moteur RAG pour les chatbots LLM : utilisez Cortex Search comme moteur RAG pour applications de chat avec vos données textuelles en exploitant la recherche sémantique pour des réponses personnalisées et contextualisées.
Recherche en entreprise : utilisez Cortex Search comme backend pour une barre de recherche de haute qualité intégrée à votre application.
Cortex Search pour RAG¶
La génération augmentée par récupération (RAG) est une technique permettant de récupérer des données à partir d’une base de connaissances afin d’améliorer la réponse générée par un grand modèle linguistique. Le diagramme d’architecture suivant montre comment vous pouvez combiner Cortex Search avec les Fonctions LLM Cortex pour créer des chatbots d’entreprise avec RAG en utilisant vos données Snowflake comme base de connaissances.
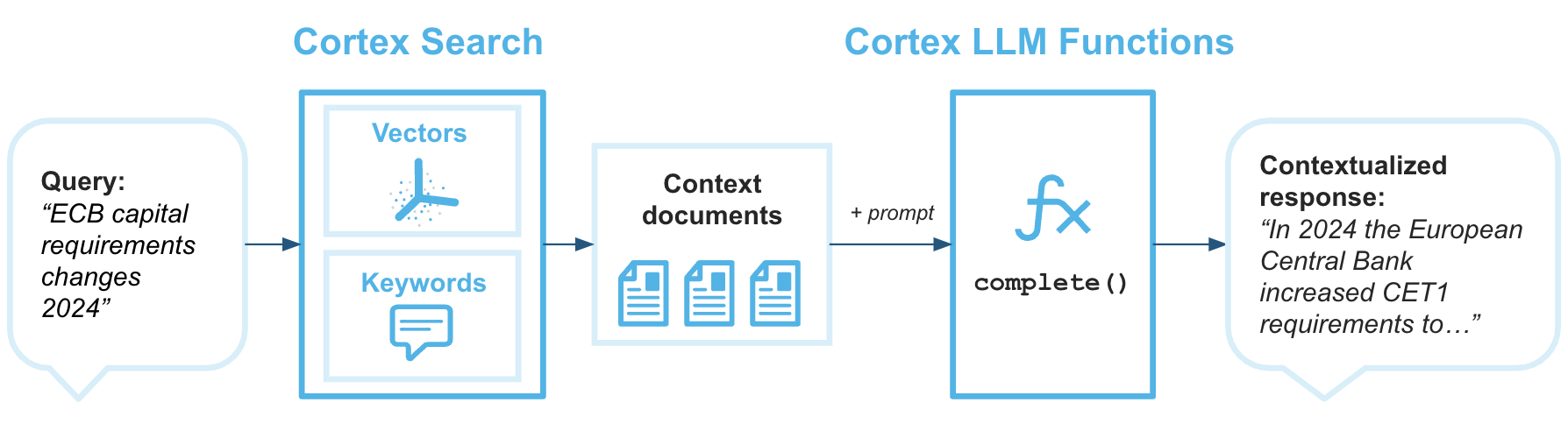
Cortex Search est le moteur de recherche qui fournit au modèle de langage étendu le contexte dont il a besoin pour renvoyer des réponses basées sur vos données propriétaires les plus récentes.
Exemple : Créer et interroger un Cortex Search Service¶
Cet exemple vous guide à travers les étapes de création d’un Cortex Search Service et de son interrogation à l’aide de la REST API. Consultez la rubrique Interrogation d’un Cortex Search Service pour plus de détails sur l’interrogation du service.
Cet exemple utilise un exemple d’ensemble de données de transcription de support client.
Exécutez les commandes suivantes pour configurer l’exemple de base de données et le schéma.
Exécutez les commandes SQL suivantes pour créer la base de données.
Créer le service¶
Vous pouvez créer un Cortex Search Service avec une seule requête SQL ou depuis le Studio AI & ML de Snowflake. Lorsque vous créez un Cortex Search Service, Snowflake effectue des transformations sur vos données sources pour les préparer à une diffusion à faible latence. Les sections suivantes montrent comment créer un service en utilisant à la fois SQL et dans le Studio AI & ML de Snowflake dans Snowsight.
Note
Lorsque vous créez un service de recherche, l’index de recherche est créé dans le cadre du processus de création. Cela signifie que l’instruction CREATE CORTEX SEARCH SERVICE peut prendre plus de temps à compléter pour des ensembles de données plus volumineux.
Utiliser SQL¶
L’exemple suivant montre comment créer un Cortex Search Service avec CREATE CORTEX SEARCH SERVICE sur l’exemple d’ensemble de données de transcription du support client créé dans la section précédente.
Cette commande déclenche la création du service de recherche pour vos données. Dans cet exemple :
Les requêtes adressées au service rechercheront des correspondances dans la colonne
transcript_text.Le paramètre
TARGET_LAGindique que le Cortex Search Service vérifiera les mises à jour de la table de basesupport_transcriptsenviron une fois par jour.Les colonnes
regionetagent_idseront indexées afin qu’elles puissent être renvoyées avec les résultats des requêtes sur la colonnetranscript_text.La colonne
regionsera disponible en tant que colonne de filtre lors de l’interrogation de la colonnetranscript_text.L’entrepôt
cortex_search_whsera utilisé pour matérialiser les résultats de la requête spécifiée initialement et à chaque fois que la table de base est modifiée.
Note
En fonction de la taille de l’entrepôt spécifié dans la requête et du nombre de lignes de votre table, l’exécution de cette commande CREATE peut prendre plusieurs heures.
Snowflake recommande d’utiliser un entrepôt dédié dont la taille ne dépasse pas la taille MEDIUM pour chaque service.
Les colonnes du champ ATTRIBUTES doivent être incluses dans la requête source, soit via une énumération explicite, soit via un caractère générique, (
*) .
Utiliser Snowsight¶
Suivez ces étapes pour créer un Cortex Search Service dans Snowsight :
Connectez-vous à Snowsight.
Choisissez un rôle auquel est accordé le rôle SNOWFLAKE.CORTEX_USER de base de données.
Dans le menu de navigation, sélectionnez AI & ML » Cortex Search.
Sélectionnez Create.
Sélectionnez un rôle et un entrepôt.
Le rôle doit se voir attribué le rôle de base de données SNOWFLAKE.CORTEX_USER. L’entrepôt est utilisé pour matérialiser les résultats de la requête source lorsque le service est créé et actualisé.
Sélectionnez une base de données et un schéma dans lesquels le service est défini.
Saisissez un nom pour votre service, puis sélectionnez Next.
Sélectionnez les données à indexer.
Pour sélectionner une table ou une vue, sélectionnez Table or view.
Sélectionnez la table ou la vue contenant les données textuelles à indexer pour la recherche, puis sélectionnez Next. Par exemple, sélectionnez la table
support_transcripts.Pour sélectionner des fichiers dans une zone de préparation, sélectionnez Stage. (Avant-première)
Sélectionnez la zone de préparation contenant les fichiers à indexer pour la recherche, puis sélectionnez Next.
Note
Si vous souhaitez spécifier plusieurs sources de données ou effectuer des transformations lors de la définition de votre service, utilisez SQL.
Si vous avez sélectionné Table or view :
Sélectionnez les colonnes que vous souhaitez inclure dans les résultats de la recherche, par exemple
transcript_text,regionetagent_id, puis sélectionnez Next.Sélectionnez la colonne qui sera recherchée, par exemple
transcript_text, puis sélectionnez Next.Si vous souhaitez pouvoir filtrer vos résultats de recherche en fonction de plusieurs colonnes particulières, sélectionnez ces colonnes, puis sélectionnez Next. Si vous n’avez besoin d’aucun filtre, sélectionnez Skip this option.
Si vous avez sélectionné Stage (Prévisualisation) :
Sélectionnez la destination de vos données traitées, puis sélectionnez Next.
Sélectionnez les paramètres de configuration du service.
Définissez votre latence cible, qui correspond au temps pendant lequel le contenu de votre service doit être en retard par rapport aux mises à jour des données de base, puis sélectionnez Create.
L’étape finale confirme que votre service a été créé et affiche le nom du service et sa source de données.
Note
Lorsque vous créez le service à partir de Snowsight, le nom du service est entre guillemets. Pour plus de détails sur ce que cela signifie lors du référencement du service dans SQL, consultez Identificateurs entre guillemets doubles.
Accorder des autorisations d’utilisation¶
Une fois le service et l’index créés, vous pouvez accorder l’utilisation du service, de sa base de données et de son schéma à d’autres rôles tels que customer_support.
Prévisualiser le service¶
Pour confirmer que le service est correctement renseigné avec les données, vous pouvez prévisualiser le service via la fonction SEARCH_PREVIEW depuis un environnement SQL :
Exemple de réponse de requête réussie :
Cette réponse confirme que le service est rempli de données et fournit des résultats raisonnables pour la requête donnée.
Vous pouvez également utiliser la fonction de table CORTEX_SEARCH_DATA_SCAN pour inspecter le contenu du service.
Interrogez le service depuis votre application¶
Une fois que vous avez créé le service de recherche, accordé son utilisation à votre rôle et l’avez prévisualisé, vous pouvez désormais l’interroger à partir de votre application à l’aide de l”API Python.
Le code suivant montre l’utilisation de l’API Python pour récupérer le ticket d’assistance le plus pertinent pour une requête concernant internet issues, filtré pour renvoyer des résultats dans la région North America :
Exemple de réponse de requête réussie :
Les Cortex Search Services renvoient toutes les colonnes spécifiées dans le champ columns de votre requête.
Privilèges requis¶
Pour créer un Cortex Search Service, votre rôle doit disposer des privilèges requis pour utiliser les fonctions d’intégration Cortex, ce qui nécessite l’octroi du rôle de base de données SNOWFLAKE.CORTEX_USER ou du rôle de base de données SNOWFLAKE.CORTEX_EMBED_USER au rôle de créateur de service. Vous devez également disposer des privilèges suivants :
Le privilège CREATE CORTEX SEARCH SERVICE ou OWNERSHIP sur le schéma dans lequel vous créez le service.
Le privilège SELECT sur les tables ou vues sous-jacentes que le service interroge.
Le privilège USAGE sur l’entrepôt qui actualise le service.
Le suivi des modifications doit être activé pour tous les objets sous-jacents utilisés par un Cortex Search Service. Pour plus d’informations sur les exigences de suivi des modifications, consultez Exigences en matière de suivi des modifications.
Pour interroger un Cortex Search Service, le rôle de l’utilisateur effectuant la requête doit disposer des privilèges USAGE sur le service lui-même, ainsi que sur la base de données et le schéma dans lesquels le service réside. Consultez Exigences en matière de contrôle d’accès à Cortex Search.
Pour suspendre ou reprendre un Cortex Search Service à l’aide de la commande ALTER, le rôle de l’utilisateur qui interroge doit avoir le privilège OPERATE sur le service. Voir ALTER CORTEX SEARCH SERVICE.
Important
Les services Cortex Search Service effectuent des recherches avec les droits du propriétaire et suivent le même modèle de sécurité que les autres objets Snowflake qui s’exécutent avec les droits du propriétaire. Pour plus d’informations, voir Exigences en matière de contrôle d’accès à Cortex Search
Comprendre la qualité de Cortex Search¶
Cortex Search s’appuie sur un ensemble de modèles de récupération et de classement pour vous offrir un niveau élevé de qualité de recherche avec peu ou pas de réglage requis. Sous le capot, Cortex Search adopte une approche « hybride » pour récupérer et classer les documents. Chaque requête de recherche utilise :
Recherche vectorielle pour récupérer des documents sémantiquement similaires.
Recherche par mot-clé pour récupérer des documents lexicalement similaires.
Reclassement sémantique pour reclasser les documents les plus pertinents dans le jeu de résultats.
Cette approche de recherche hybride, couplée à une étape de reclassement sémantique, permet d’obtenir une qualité de recherche élevée sur une large gamme d’ensembles de données et de requêtes.
Vous pouvez personnaliser la notation des résultats de recherche en appliquant des renforcements numériques, des décroissances temporelles, des ajustements des poids des composants ou la désactivation du reclassement. Pour plus d’informations, voir Personnalisation de la notation des résultats de Cortex Search.
Modèles de représentation vectorielle de Cortex Search¶
Cortex Search permet aux utilisateurs de sélectionner un modèle d’intégration hébergé qui sera exploité dans la zone de préparation de récupération de la recherche vectorielle. Les modèles d’intégration suivants sont disponibles dans Cortex Search.
Important
La tarification du modèle varie. La tarification du modèle canonique est disponible dans le Tableau de consommation du service Snowflake. Si un prix indiqué ci-dessous diffère du prix indiqué pour le modèle dans le Tableau de consommation du service Snowflake, le Tableau de consommation du service Snowflake prévaut.
Nom du modèle |
Dimensions de la sortie |
Taille de la fenêtre contextuelle (jetons) |
Prise en charge des langages |
Description |
|---|---|---|---|---|
|
768 |
512 |
Anglais uniquement |
Le modèle d’intégration le plus pratique de Snowflake, en anglais uniquement. Ce modèle open-source de 110 millions de paramètres permet d’obtenir les temps d’indexation les plus rapides parmi les modèles disponibles dans Cortex Search. Pour plus d’informations, consultez le billet de blog Arctic Embed 1.5 et la carte modèle Arctic Embed 1.5. |
|
1024 |
512 |
Multilingue |
Modèle d’intégration multilingue économique de Snowflake avec une fenêtre contextuelle de 512 jetons. Ce modèle open-source de 568 millions de paramètres produit une haute qualité sur les ensembles de données anglais et non anglais. Pour plus d’informations, consultez l’article de blog Arctic Embed 2 et la Carte du modèle Arctic Embed 2. |
|
1024 |
8192 |
Multilingue |
Modèle d’intégration multilingue économique de Snowflake, avec une fenêtre contextuelle augmentée de 8 000 jetons. Ce modèle open-source de 568 millions de paramètres produit une haute qualité sur les ensembles de données anglais et non anglais. |
|
1024 |
32,000 |
Multilingue |
Le modèle d’intégration multilingue de Voyage. Ce modèle permet d’obtenir une qualité élevée sur les jeux de données anglais ou non. Pour plus d’informations, consultez le billet de blog Voyage Multilingual 2 |
Certains modèles de représentation vectorielle ne sont disponibles que dans certaines régions du Cloud pour Cortex Search. Pour obtenir la liste des disponibilités par modèle et par région, voir Disponibilité régionale Cortex Search.
Chaque modèle présente des caractéristiques différentes en matière de performance, de coût, de taille de la fenêtre contextuelle et de qualité. Examinez attentivement les spécifications du modèle afin de déterminer le modèle le mieux adapté à votre charge de travail spécifique. Reportez-vous au Tableau de consommation du service Snowflake pour une vue la plus précise du coût de chaque modèle en crédits par million de jetons.
Jetons, fenêtres contextuelles du modèle et division de texte¶
Un jeton est une séquence de caractères et constitue la plus petite unité de texte pouvant être traitée par un grand modèle de langage. À titre approximatif, un jeton équivaut à environ 3/4 d’un mot anglais, soit environ 4 caractères. Pour calculer le nombre de jetons dans une chaîne, utilisez la fonction Cortex COUNT_TOKENS. Par exemple, le calcul des jetons d’une chaîne à intégrer avec le modèle snowflake-arctic-embed-m-v1.5 :
Chaque modèle d’intégration vectorielle prend en charge une fenêtre contextuelle de taille fixe pour les entrées de texte, indiquée dans le tableau des modèles d’intégration précédent. Lors de l’indexation et de la mise à disposition, lorsque le nombre de jetons d’une valeur dans la colonne de recherche dépasse la taille de la fenêtre contextuelle, Cortex Search tronque la chaîne à la taille de la fenêtre contextuelle avant de l’intégrer dans l’espace vectoriel pour la recherche sémantique. Cependant, Cortex Search utilise le corps entier du texte pour la récupération basée sur des mots-clés.
Snowflake fournit des fonctions intégrées pour aider à diviser le texte en morceaux plus petits. Pour plus d’informations, voir SPLIT_TEXT_RECURSIVE_CHARACTER.
Pour des résultats de recherche optimaux avec Cortex Search, Snowflake recommande de diviser le texte de votre colonne de recherche en morceaux ne dépassant pas 512 jetons (environ 385 mots anglais). Bien qu’il existe aujourd’hui des modèles d’intégration à contexte plus long, tels que snowflake-arctic-embed-l-v2.0-8k, la recherche montre qu’une taille de morceau plus petite entraîne généralement une meilleure qualité de la récupération et de la réponse du LLM en aval. Avec des morceaux plus petits, la récupération peut être plus précise pour une requête donnée et, dans une génération augmentée de récupération (RAG), le LLM en aval reçoit des morceaux de texte plus pertinents pour la requête.
Actualise¶
Le contenu diffusé dans un Cortex Search Service est basé sur les résultats d’une requête spécifique. Lorsque les données sous-jacentes à un Cortex Search Service changent, le service est mis à jour pour refléter ces modifications. Ces mises à jour sont appelées actualisations. Ce processus est automatisé et consiste à analyser la requête qui sous-tend la table.
Les Cortex Search Services ont les mêmes propriétés d’actualisation que les tables dynamiques. Consultez la rubrique Comprendre l’initialisation et l’actualisation des tables dynamiques pour comprendre les caractéristiques d’actualisation d’un Cortex Search Service.
La requête source d’un Cortex Search Service doit être candidate à l’actualisation incrémentielle de la table dynamique. Pour plus de détails sur ces exigences, consultez Prise en charge de l’actualisation incrémentielle. Cette restriction est conçue pour empêcher tout coût incontrôlable indésirable associé au calcul d’intégration vectorielle. Pour plus d’informations sur les constructions qui ne sont pas prises en charge pour l’actualisation incrémentielle de la table dynamique, consultez Requêtes prises en charge pour les tables dynamiques.
Clés primaires¶
Une clé principale d’un Cortex Search Service est un ensemble facultatif de colonnes qui identifient de manière unique chaque ligne de la requête source (c’est-à-dire que une seule ligne possède cette combinaison exacte de valeurs dans les colonnes désignées). Pour être utilisées avec les Cortex Search Services, les colonnes de clé principale doivent être de type de données TEXT.
Une clé principale peut être spécifiée lors de la création du service comme suit :
Les colonnes de clé principale des services existants peuvent être modifiées avec ALTER CORTEX SEARCH SERVICE ... SET PRIMARY KEY (...). Pour une syntaxe détaillée, voir ALTER CORTEX SEARCH SERVICE.
Les services avec des clés principales peuvent utiliser un chemin d’actualisation optimisé lorsque les données sous-jacentes du service changent. Ce chemin optimisé peut entraîner des réductions importantes du coût et de la latence d’une actualisation. Lorsque cette optimisation est activée, le service de recherche compacte périodiquement les informations d’index générées au cours d’une actualisation. Vous pouvez spécifier une fréquence cible pour les actualisations de l’index en définissant la propriété FULL_INDEX_BUILD_INTERVAL_DAYS sur le service. Pour plus d’informations sur la syntaxe, consultez CREATE CORTEX SEARCH SERVICE et ALTER CORTEX SEARCH SERVICE.
Note
FULL_INDEX_BUILD_INTERVAL_DAYS est une cible douce. Les reconstructions complètes peuvent se produire plus fréquemment que l’intervalle spécifié pour optimiser les performances de service en fonction de facteurs tels que la latence cible du service, le taux de modification des données sources du service et la taille globale du service.
Les requêtes adressées à des services possédant des clés principales peuvent également utiliser l”opérateur de filtre ``@primarykey` <label-cortex-search-query-filter-syntax>`.
Important
L’ensemble des valeurs de colonne de clé principale doit être unique pour chaque ligne de la requête source. Les doublons sont ignorés dans l’index de recherche résultant.
Cortex Search multi-index¶
Cortex Search peut indexer plusieurs colonnes ou utiliser des intégrations vectorielles personnalisées pour les requêtes, vous offrant ainsi une flexibilité supplémentaire dans la façon dont votre Cortex Search Service interprète les données et répond aux requêtes des utilisateurs. Vous devez utiliser Cortex Search multi-index lorsque vous avez un cas d’utilisation qui comporte un ou plusieurs des éléments suivants :
Champs de recherche multiples : Les utilisateurs doivent effectuer une recherche dans différents champs d’un enregistrement.
Intégrations vectorielles fournies par l’utilisateur : Vous disposez d’intégrations vectorielles pré-calculées pour une ou plusieurs colonnes avant l’ingestion dans Cortex Search Service.
Types de recherche mixtes : Vous souhaitez prendre en charge la recherche dans différents champs avec une préférence pour un type de recherche.
Utilisez des index de texte pour les champs où les correspondances de mots-clés exactes ou floues sont importantes. Les codes, les noms et les catégories de produits en sont quelques exemples.
Utilisez des index vectoriels pour les champs contenant du texte plus long où la compréhension sémantique est utile. Il peut s’agir, par exemple, de descriptions de produits, d’avis d’utilisateurs et de tickets d’assistance.
Pertinence spécifique au champ : Différents champs de vos données doivent contribuer différemment à la pertinence d’un résultat de recherche.
Par exemple, pour un cas d’utilisation de recherche dans un catalogue de produits, vous pouvez créer un service multi-index où :
Les noms de produits et les SKUs sont des index de texte pour une correspondance lexicale précise.
Les descriptions de produits sont des index vectoriels destinés à la correspondance sémantique.
Les noms de catégories et de marques sont à la fois des index de texte et vectoriels pour prendre en charge les correspondances lexicales et sémantiques.
Pour voir des exemples de création d’un Cortex Search Service multi-index, consultez CREATE CORTEX SEARCH SERVICE … TEXT INDEXES .. VECTOR INDEXES. Pour voir des exemples d’interrogation d’un service multi-index, consultez Interroger un Cortex Search Service - Requêtes multi-index.
Intégrations vectorielles fournies par l’utilisateur¶
Cortex Search multi-index vous permet d’utiliser des intégrations vectorielles pré-calculées à partir de n’importe quel modèle d’intégration (y compris les modèles open-source, commerciaux et entraînés personnalisés). Intégrations vectorielles fournies par l’utilisateur quand :
Vous souhaitez utiliser un modèle d’intégration non disponible nativement dans Cortex Search, ou vous souhaitez réutiliser les intégrations que vous avez déjà générées pour réduire les coûts et améliorer les performances.
Vous souhaitez combiner vos intégrations vectorielles avec les index de texte Cortex Search pour la récupération hybride.
Lorsque vous spécifiez un nom de colonne dans la clause VECTORINDEXES, mais sans spécifier de modèle, Cortex Search traite le contenu de la colonne comme des intégrations vectorielles fournies par l’utilisateur. Les vecteurs fournis par l’utilisateur sont indexés tels quels et n’entraînent aucun coût d’intégration.
Note
Vous ne pouvez pas charger de vecteurs directement dans une table Snowflake. Au lieu de cela, convertissez un tableau de nombres en type de données VECTOR lors de l’insertion ou de la mise à jour de données dans la table source pour votre Cortex Search Service. Voir:ref:label-data_type_vector_conversion pour des détails et des exemples sur la façon de procéder.
Cortex Search choisit l’un des modes suivants au moment de la recherche, selon que vous fournissez un vecteur de requête ou un texte de requête dans votre requête de recherche :
Mode |
Heure de l’index |
Heure de la requête |
|---|---|---|
Entièrement géré par l’utilisateur |
Fournir des vecteurs dans une colonne VECTOR |
Fournir un vecteur de requête via multi_index_query |
Géré par l’utilisateur avec des intégrations de requête gérées |
Fournir des vecteurs dans une colonne VECTOR |
Cortex Search intègre le texte de la requête en utilisant le modèle spécifié |
Suspension de l’indexation et de la mise à disposition¶
De la même manière que les tables dynamiques, les Cortex Search Services suspendent automatiquement leur état d’indexation lorsqu’ils rencontrent cinq échecs d’actualisation consécutifs liés à la requête source. Si vous rencontrez cette défaillance pour votre service, vous pouvez voir l’erreur SQL lors de l’utilisation du DESCRIBE CORTEX SEARCH SERVICE ou du Vue CORTEX_SEARCH_SERVICES. La sortie des deux inclut les colonnes suivantes :
La colonne INDEXING_STATE, qui est SUSPENDED pour un service suspendu.
La colonne INDEXING_ERROR qui contient l’erreur SQL spécifique rencontrée dans la requête source.
Une fois le problème racine résolu, vous pouvez reprendre le service avec ALTER CORTEX SEARCH SERVICE <name> RESUME INDEXING. Pour une syntaxe détaillée, voir ALTER CORTEX SEARCH SERVICE.
Considérations relatives aux clients¶
Un Cortex Search Service entraîne des coûts de la manière suivante :
Catégorie |
Description |
|---|---|
Calcul de l’entrepôt virtuel |
Un Cortex Search Service nécessite un entrepôt virtuel pour actualiser le service : pour exécuter des requêtes sur les objets de base lorsqu’ils sont initialisés et actualisés, y compris l’orchestration des tâches d’intégration de texte et la création de l’index de recherche. Ces opérations utilisent des ressources de calcul, qui consomment des crédits. Si aucun changement n’est identifié lors d’une actualisation, les crédits de l’entrepôt virtuel ne sont pas consommés puisqu’il n’y a pas de nouvelles données à actualiser. |
Calcul des jetons EMBED_TEXT |
Un Cortex Search Service intègre automatiquement chaque ligne de texte dans la colonne de recherche spécifiée dans le paramètre |
Cortex Search multi-index |
Les Cortex Search Services multi-index ont des coûts qui dépendent de la façon dont vous intégrez les jetons et du nombre de colonnes que vous indexez. Des vecteurs d’intégration plus grands ou un nombre plus élevé de colonnes d’index entraînent des coûts plus élevés. Les intégrations sont calculées chaque fois qu’une ligne est insérée ou mise à jour. Les intégrations sont traitées de manière incrémentielle lors de l’évaluation de la requête source, de sorte que le coût d’intégration n’est engagé que pour les documents ajoutés ou modifiés. |
Calcul de service |
Un Cortex Search Service utilise un calcul de service multi-locataire, séparé d’un entrepôt virtuel fourni par l’utilisateur, pour établir un service à faible latence et à haut débit. Le coût de calcul pour cette composante est calculé par GB par mois (GB/mo) de données indexées non compressées, les données indexées étant les données fournies par l’utilisateur dans la requête source de Cortex Search, plus les intégrations vectorielles calculées pour le compte de l’utilisateur. Vous supportez ces coûts tant que le service est disponible pour répondre aux requêtes, même si aucune requête n’est servie au cours d’une période donnée. Pour connaître le taux de crédit du service Cortex Search par GB/mo de données indexées, consultez la Snowflake Service Consumption Table. |
Stockage |
Les Cortex Search Services matérialisent la requête source dans une table stockée dans votre compte. Cette table est transformée en structures de données optimisées pour un service à faible latence, également stockées dans votre compte. Le stockage pour la table et les structures de données intermédiaires est basé sur un tarif forfaitaire par téraoctet (TB). |
Calcul des services Cloud |
Les Cortex Search Services utilisent le calcul Cloud Services pour identifier les changements dans les objets de base sous-jacents et déterminer si l’entrepôt virtuel doit être invoqué. Le coût de calcul des services Cloud est soumis à la contrainte selon laquelle Snowflake ne facture que si le coût quotidien des services Cloud est supérieur à 10 % du coût quotidien de l’entrepôt pour le compte. |
Pour connaître les meilleures pratiques en matière de gestion des coûts d’un Cortex Search Service, voir Comprendre les coûts de Cortex Search Services.
Pour visualiser les coûts de consommation liés aux services AI pour chaque service Cortex Search Service de votre compte, agrégés quotidiennement, consultez la vue CORTEX_SEARCH_DAILY_USAGE_HISTORY
Limitations connues¶
L’utilisation de Cortex Search est soumise aux limitations suivantes :
Taille de la table de base : Le résultat de la requête matérialisée dans le service de recherche doit avoir une taille inférieure à 100 millions de lignes pour maintenir une performance de service optimale. Si le résultat matérialisé de votre requête comporte plus de 100 millions de lignes, la requête de création échoue avec une erreur.
Note
Pour augmenter les limites de mise à l’échelle des lignes sur un Cortex Search Service au-dessus de 100 millions, veuillez contacter votre équipe de compte Snowflake.
Limitation de débit : Cortex Search renvoie un code de statut HTTP 429 si un client envoie des requêtes trop rapidement ou si le service est surchargé. La logique client appelant le service de recherche doit implémenter une logique d’interruption et de réessai pour traiter ces réponses 429 correctement.
Note
Pour augmenter le débit au-delà de 20 QPS pour un seul service de recherche ou 140 QPS pour tous les services de votre compte, contactez votre équipe de compte Snowflake.
Constructions de requête : les requêtes sources du Cortex Search Service doivent respecter les mêmes restrictions de requête que les tables dynamiques. Veuillez consulter le Limites des tables dynamiques pour plus de détails.
Conservation des données : Les Cortex Search Services ont les mêmes exigences que les tables dynamiques concernant la conservation des données. Plus précisément, vous ne pouvez pas définir le paramètre d’objet DATA_RETENTION_TIME_IN_DAYS dans vos tables de base sur zéro ni définir ce paramètre sur le schéma ou la base de données contenant le service de recherche. De plus, les services de recherche peuvent devenir obsolètes s’ils ne sont pas actualisés dans un délai de MAX_DATA_EXTENSION_TIME_IN_DAYS. Une fois obsolètes, ils doivent être recréés pour poursuivre les actualisations. Veuillez consulter le Limites des tables dynamiques pour plus de détails.
Clonage : Les Cortex Search Services ne prennent actuellement pas en charge le clonage. Snowflake envisage de fournir cette fonctionnalité dans une version ultérieure, mais ne peut indiquer quand.
Immuabilité de la table : Pendant leur exécution, vos Cortex Search Services nécessitent que les tables auxquelles ils accèdent ne soient pas modifiées ou supprimées. Pour mettre à jour en toute sécurité les tables utilisées par un Cortex Search Service, arrêtez le service avant d’effectuer vos modifications.
Disponibilité régionale¶
La prise en charge de cette fonctionnalité est disponible pour les comptes dans les régions Snowflake suivantes. La disponibilité de modèles d’intégration vectorielle spécifiques dans une région est indiquée par une coche.
Fournisseur Cloud
|
Region
|
snowflake-arctic-embed-m-v1.5 |
snowflake-arctic-embed-l-v2.0 |
snowflake-arctic-embed-l-v2.0-8k |
voyage-multilingual-2 |
|---|---|---|---|---|---|
AWS
|
US Ouest 2 (Oregon)
|
✔ |
✔ |
✔ |
✔ |
AWS
|
US Est 2 (Ohio)
|
✔ |
✔ |
✔ |
|
AWS
|
US East 1 (N. du Nord)
|
✔ |
✔ |
✔ |
✔ |
AWS
|
US East (Commercial Gov - N. Virginia)
|
✔ |
✔ |
✔ |
✔ |
AWS
|
Canada (Centre)
|
✔ |
✔ |
✔ |
|
AWS
|
Amérique du Sud (São Paulo)
|
✔ |
✔ |
✔ |
|
AWS
|
Europe (Irlande)
|
✔ |
✔ |
✔ |
|
AWS
|
Europe (Londres)
|
✔ |
✔ |
✔ |
|
AWS
|
Europe Central 1 (Francfort)
|
✔ |
✔ |
✔ |
✔ |
AWS
|
Europe (Stockholm)
|
✔ |
✔ |
✔ |
|
AWS
|
Asie-Pacifique (Tokyo)
|
✔ |
✔ |
✔ |
✔ |
AWS
|
Asie Pacifique (Mumbai)
|
✔ |
✔ |
✔ |
|
AWS
|
Asie-Pacifique (Sydney)
|
✔ |
✔ |
✔ |
|
AWS
|
Asie-Pacifique (Jakarta)
|
✔ |
✔ |
✔ |
|
AWS
|
Asie-Pacifique (Seoul)
|
✔ |
✔ |
✔ |
|
Azure
|
Est US 2 (Virginie)
|
✔ |
✔ |
✔ |
|
Azure
|
Ouest US 2 (Washington)
|
✔ |
✔ |
✔ |
|
Azure
|
Sud-Central US (Texas)
|
✔ |
✔ |
✔ |
|
Azure
|
UK Sud (Londres)
|
✔ |
✔ |
✔ |
|
Azure
|
Europe du Nord (Irlande)
|
✔ |
✔ |
✔ |
|
Azure
|
Europe de l’Ouest (Pays-Bas)
|
✔ |
✔ |
✔ |
✔ |
Azure
|
Suisse Nord (Zurich)
|
✔ |
✔ |
✔ |
|
Azure
|
Inde centrale (Pune)
|
✔ |
✔ |
✔ |
|
Azure
|
Japon Est (Tokyo, Saitama)
|
✔ |
✔ |
✔ |
|
Azure
|
Asie du Sud-Est (Singapour)
|
✔ |
✔ |
✔ |
|
Azure
|
Australie Est (Nouvelle-Galles du Sud)
|
✔ |
✔ |
✔ |
|
GCP
|
Europe Ouest 2 (Londres)
|
✔ |
✔ |
✔ |
|
GCP
|
Europe Ouest 3 (Francfort)
|
✔ |
✔ |
✔ |
|
GCP
|
Europe Ouest 4 (Pays-Bas)
|
✔ |
✔ |
✔ |
|
GCP
|
Moyen-Orient central 2 (Dammam)
|
✔ |
✔ |
✔ |
|
GCP
|
US Central 1 (Iowa)
|
✔ |
✔ |
✔ |
|
GCP
|
US East 4 (Virginie du Nord)
|
✔ |
✔ |
✔ |
Note
Vous pouvez spécifier le paramètre d’inférence interrégionale dans l’une des régions ci-dessus pour accéder aux modèles qui ne sont pas directement pris en charge dans votre région par défaut.
Cortex Search est disponible dans les régions suivantes uniquement en utilisant l’inférence interrégionale. Pour utiliser Cortex Search avec l’inférence interrégionale, utilisez le paramètre d’inférence interrégionale.
AWS Europe (Paris)
AWS Europe (Zurich)
AWS Asie-Pacifique (Singapour)
AWS Asie-Pacifique (Osaka)
Azure Canada Central (Toronto)
Azure Central US (Iowa)
Azure UAE Nord (Dubaï)
Note
Lors de l’utilisation de l’inférence interrégionale, la latence des requêtes entre les régions dépend de l’infrastructure du fournisseur Cloud et du statut du réseau. Snowflake vous recommande de tester votre cas d’utilisation spécifique avec l’inférence interrégionale activée.
Avis juridiques¶
La classification des données d’entrées et de sorties est présentée dans la table suivante.
Classification des données d’entrée |
Classification des données de sortie |
Désignation |
|---|---|---|
Usage Data |
Customer Data |
Les fonctions généralement disponibles sont des fonctions AI couvertes. Les fonctions d’aperçu sont les fonctions AI d’aperçu. [1] |
Pour plus d’informations, reportez-vous à Snowflake AI et ML.