분류(Snowflake Cortex ML 기반 함수)¶
분류는 머신 러닝 알고리즘을 사용하여 학습 데이터에서 감지된 패턴을 사용하여 데이터를 다양한 클래스로 분류합니다. 이진 분류(2개 클래스) 및 다중 클래스 분류(3개 이상의 클래스)가 지원됩니다. 분류의 일반적인 사용 사례에는 고객 이탈 예측, 신용 카드 사기 감지, 스팸 감지가 포함됩니다.
분류에는 분류 모델 오브젝트를 만들어 학습 데이터에 대한 참조를 전달하는 작업이 포함됩니다. 모델은 제공된 학습 데이터에 적합합니다. 그런 다음 결과 스키마 수준 분류 모델 오브젝트를 사용하여 새로운 데이터 요소를 분류하고 평가 API를 통해 모델의 정확성을 이해합니다.
중요
법적 고지. 이 Snowflake Cortex ML 기반 함수는 머신 러닝 기술을 기반으로 합니다. 제공된 머신 러닝 기술 및 결과는 부정확하거나 부적절하거나 편향될 수 있습니다. 자동 파이프라인에 내장된 결과를 포함하여 머신 러닝 출력을 기반으로 한 의사 결정에는 모델 생성 콘텐츠가 정확하도록 보장하기 위해 사람의 감독 및 검토 프로세스가 있어야 합니다. Snowflake Cortex ML 기반 함수 쿼리는 다른 SQL 쿼리로 처리되며 메타데이터 로 간주될 수 있습니다.
메타데이터. Snowflake Cortex ML 기반 함수를 사용하면 Snowflake는 메타데이터 필드 에 언급된 내용 외에 ML 함수에서 반환된 일반 오류 메시지를 로그에 기록합니다. 이러한 오류 로그는 발생하는 문제를 해결하고 이러한 함수를 개선하여 더 나은 서비스를 제공하는 데 도움이 됩니다.
자세한 내용은 Snowflake AI 신뢰 및 안전 FAQ 를 참조하십시오.
분류 모델 정보¶
Snowflake Cortex Classification 함수는 그라데이션 부스팅 머신 을 통해 구동됩니다. 이진 분류의 경우 모델은 곡선 아래 영역 손실 함수를 사용하여 학습됩니다. 다중 클래스 분류의 경우 모델은 로지스틱 손실 함수를 사용하여 학습됩니다.
분류에 사용하기에 적합한 학습 데이터 세트에는 각 데이터 요소의 레이블이 지정된 클래스를 나타내는 대상 열과 하나 이상의 특징 열이 포함됩니다.
분류 모델은 특징 및 레이블에 대해 숫자, 부울 및 문자열 데이터 타입을 지원합니다. 숫자 특징은 연속형으로 처리되는 반면, 문자열 및 부울 특징은 카테고리형으로 처리됩니다. 숫자 특징을 카테고리형으로 처리하려면 해당 특징을 문자열로 형변환하십시오. 모델은 특징의 NULL 값을 처리할 수 있습니다. 레이블 열의 카디널리티는 1보다 크고 데이터 세트의 행 수보다 작아야 합니다.
추론 데이터에는 학습 데이터와 동일한 특징 이름 및 유형이 있어야 합니다. 카테고리형 특징이 학습 데이터 세트에 없는 값을 갖는 것은 오류가 아닙니다. 학습 데이터 세트에 없는 추론 데이터의 열은 무시됩니다.
분류 모델의 예측 품질을 평가할 수 있습니다. 평가 프로세스에서는 원본 데이터에 대해 추가 모델이 학습되지만 일부 데이터 요소는 보류됩니다. 그런 다음 보류된 데이터 요소는 추론에 사용되며 예측된 클래스는 실제 클래스와 비교됩니다.
현재 제한 사항¶
학습 및 추론 데이터는 숫자, 부울 또는 문자열이어야 합니다. 다른 유형은 이러한 유형 중 하나로 형변환되어야 합니다.
분류 알고리즘을 선택하거나 수정할 수 없습니다.
모델 매개 변수는 수동으로 지정하거나 조정할 수 없습니다.
학습은 최대 1,000개의 열과 1,000만 개의 행을 지원하지만, 이 한도 미만에서는 메모리가 부족할 가능성이 있습니다. 이 경우에는 더 큰 웨어하우스를 사용해 보십시오.
SNOWFLAKE.ML.CLASSIFICATION 인스턴스는 복제할 수 없습니다. 분류 모델이 포함된 데이터베이스를 복제하는 경우 모델을 현재 건너뛰게 됩니다.
분류 준비하기¶
분류를 사용하려면 먼저 다음을 수행해야 합니다.
모델을 학습시키고 실행할 가상 웨어하우스를 선택합니다.
분류 모델을 생성하는 데 필요한 권한을 부여합니다.
SNOWFLAKE.ML 스키마를 포함하도록 검색 경로를 수정 할 수도 있습니다.
가상 웨어하우스 선택하기¶
Snowflake 가상 웨어하우스 가 분류 머신 러닝 모델을 학습시키고 사용하기 위한 컴퓨팅 리소스를 제공합니다. 이 섹션에서는 프로세스에서 가장 시간이 많이 걸리고 메모리 집약적인 부분인 학습 단계에 중점을 두고서 분류에 가장 적합한 웨어하우스 유형 및 크기를 선택하는 방법에 대한 일반적인 지침을 제공합니다.
학습 데이터의 크기를 기준으로 웨어하우스 유형을 선택해야 합니다. 표준 웨어하우스는 Snowpark 메모리 한도가 더 낮으며 행 수가 적거나 특징이 있는 학습 작업에 더 적합합니다. 행과 특징의 수가 증가함에 따라 작업이 성공적으로 실행될 수 있도록 Snowpark에 최적화된 웨어하우스를 사용하는 것이 좋습니다. 최상의 성능을 위해 다른 동시 워크로드 없이 전용 웨어하우스를 사용하여 모델을 학습시키십시오.
다양한 데이터 크기와 웨어하우스 유형에 대한 학습 시간을 제공하는 아래 테이블을 사용하여 필요한 웨어하우스의 유형과 크기를 파악하십시오. 학습 시간은 주어진 값에 따라 달라질 수 있습니다.
웨어하우스 유형 및 크기 |
행 수 |
열 수 |
학습 시간(초) |
|---|---|---|---|
표준 XS |
1000 |
10 |
8 |
표준 XS |
10,000 |
100 |
27 |
표준 XS |
100,000 |
1000 |
323 |
표준 XL |
1000 |
10 |
8 |
표준 XL |
10,000 |
100 |
15 |
표준 XL |
100,000 |
1000 |
300 |
Snowpark에 최적화된 XL |
1000 |
10 |
11 |
Snowpark에 최적화된 XL |
10,000 |
100 |
15 |
Snowpark에 최적화된 XL |
100,000 |
1000 |
375 |
분류 모델을 생성하는 권한 부여하기¶
분류 모델을 학습시키면 스키마 수준 오브젝트가 생성됩니다. 따라서 모델 생성에 사용하는 역할은 모델이 생성될 스키마에 대한 CREATE SNOWFLAKE ML CLASSIFICATION 권한이 있어야 스키마에 모델을 저장할 수 있습니다. 이 권한은 CREATE TABLE 또는 CREATE VIEW와 같은 다른 스키마 권한과 유사합니다.
분류 모델을 생성해야 하는 사람들이 사용할 analyst 라는 역할을 생성하는 것이 좋습니다.
다음 예에서 admin 역할은 스키마 admin_db.admin_schema 의 소유자입니다. analyst 역할은 이 스키마에서 모델을 생성해야 합니다.
USE ROLE admin;
GRANT USAGE ON admin_db TO ROLE analyst;
GRANT USAGE ON admin_schema TO ROLE analyst;
GRANT CREATE SNOWFLAKE.ML.CLASSIFICATION ON SCHEMA admin_db.admin_schema TO ROLE analyst;
이 스키마를 사용하기 위해 사용자는 analyst 역할을 맡습니다.
USE ROLE analyst;
USE SCHEMA admin_db.admin_schema;
analyst 역할이 analyst_db 데이터베이스에서 CREATE SCHEMA 권한을 가질 경우 이 역할은 새 스키마 analyst_db.analyst_schema 를 생성하고 해당 스키마에서 분류 모델을 생성할 수 있습니다.
USE ROLE analyst;
CREATE SCHEMA analyst_db.analyst_schema;
USE SCHEMA analyst_db.analyst_schema;
스키마에 대한 역할의 모델 생성 권한을 취소하려면 REVOKE <권한> 를 사용하십시오.
REVOKE CREATE SNOWFLAKE.ML.CLASSIFICATION ON SCHEMA admin_db.admin_schema FROM ROLE analyst;
모델 학습, 사용, 확인, 삭제 및 업데이트하기¶
참고
SNOWFLAKE.ML.CLASSIFICATION는 제한된 권한을 사용하여 실행되므로, 기본적으로 데이터에 액세스할 수 없습니다. 따라서 호출자의 권한을 전달하는 참조 로 테이블과 뷰를 전달해야 합니다. 테이블 또는 뷰에 대한 참조 대신 쿼리 참조 를 제공할 수도 있습니다.
학습, 추론 및 평가 API에 대한 자세한 내용은 CLASSIFICATION 참조 를 확인하십시오.
CREATE SNOWFLAKE.ML.CLASSIFICATION을 사용하여 모델을 만들고 학습시킵니다.
CREATE OR REPLACE SNOWFLAKE.ML.CLASSIFICATION <model_name>(...);
데이터 세트에 대해 추론(예측)을 실행하려면 모델의 PREDICT 메서드를 사용하십시오.
SELECT <model_name>!PREDICT(...);
모델을 평가하려면 제공된 평가 메서드를 호출하십시오.
CALL <model_name>!SHOW_EVALUATION_METRICS();
CALL <model_name>!SHOW_GLOBAL_EVALUATION_METRICS();
CALL <model_name>!SHOW_THRESHOLD_METRICS();
CALL <model_name>!SHOW_CONFUSION_MATRIX();
모델의 특징 중요도 순위를 표시하려면 해당 SHOW_FEATURE_IMPORTANCE 메서드를 호출하십시오.
CALL <model_name>!SHOW_FEATURE_IMPORTANCE();
학습 중에 생성된 로그를 조사하려면 SHOW_TRAINING_LOGS 메서드를 사용하십시오.
CALL <model_name>!SHOW_TRAINING_LOGS();
팁
이러한 메서드를 사용하는 예는 예 를 참조하십시오.
모든 분류 모델을 보려면 SHOW 명령을 사용하십시오.
SHOW SNOWFLAKE.ML.CLASSIFICATION;
분류 모델을 삭제하려면 DROP 명령을 사용하십시오.
DROP SNOWFLAKE.ML.CLASSIFICATION <model_name>;
모델은 변경할 수 없으며 자체적으로 업데이트할 수 없습니다. 모델을 업데이트하려면 기존 모델을 삭제하고 새 모델을 학습시키십시오. 이 목적에는 CREATE 명령의 CREATE OR REPLACE 베리언트가 유용합니다.
예¶
예제를 위한 데이터 설정하기¶
이 항목의 예제에서는 두 개의 테이블을 사용합니다. 첫 번째 테이블 training_purchase_data 에는 이진 레이블 열과 다중 클래스 레이블 열이라는 두 개의 특징 열이 있습니다. 두 번째 테이블은 prediction_purchase_data 라고 하며 두 개의 특징 열이 있습니다. 아래의 SQL을 사용하여 이러한 테이블을 만드십시오.
CREATE OR REPLACE TABLE training_purchase_data AS (
SELECT
CAST(UNIFORM(0, 4, RANDOm()) as VARCHAR) as user_interest_score,
UNIFORM(0, 3, RANDOM()) as user_rating, FALSE AS label,
'not_interested' AS class
FROM TABLE(GENERATOR(rowCount => 100))
UNION ALL
SELECT
CAST(UNIFORM(4, 7, RANDOM()) AS VARCHAR) AS user_interest_score,
UNIFORM(3, 7, RANDOM()) AS user_rating, FALSE AS label,
'add_to_wishlist' AS class
FROM TABLE(GENERATOR(rowCount => 100))
UNION ALL
SELECT
CAST(UNIFORM(7, 10, RANDOM()) AS VARCHAR) AS user_interest_score,
UNIFORM(7, 10, RANDOM()) AS user_rating,
TRUE as label, 'purchase' AS class
FROM TABLE(GENERATOR(rowCount => 100))
);
CREATE OR REPLACE table prediction_purchase_data AS (
SELECT
CAST(UNIFORM(0, 4, RANDOM()) AS VARCHAR) AS user_interest_score,
UNIFORM(0, 3, RANDOM()) AS user_rating
FROM TABLE(GENERATOR(rowCount => 100))
UNION ALL
SELECT
CAST(UNIFORM(4, 7, RANDOM()) AS VARCHAR) AS user_interest_score,
UNIFORM(3, 7, RANDOM()) AS user_rating
FROM TABLE(GENERATOR(rowCount => 100))
UNION ALL
SELECT
CAST(UNIFORM(7, 10, RANDOM()) AS VARCHAR) AS user_interest_score,
UNIFORM(7, 10, RANDOM()) AS user_rating
FROM TABLE(GENERATOR(rowCount => 100))
);
이진 분류자 학습 및 사용하기¶
먼저 학습용 이진 데이터가 포함된 뷰를 만듭니다.
CREATE OR REPLACE view binary_classification_view AS
SELECT uuid, user_interest_score, user_rating, label
FROM training_purchase_data;
SELECT * FROM binary_classification_view;
SELECT 문은 다음 형식으로 결과를 반환합니다.
+---------------------+-------------+-------+
| USER_INTEREST_SCORE | USER_RATING | LABEL |
|---------------------+-------------+-------|
| 4 | 0 | False |
| 3 | 3 | False |
| 0 | 0 | False |
| 3 | 0 | False |
| 0 | 2 | False |
+---------------------+-------------+-------+
이 뷰를 사용하여 이진 분류 모델을 만들고 훈련시킵니다.
CREATE OR REPLACE SNOWFLAKE.ML.CLASSIFICATION model_binary(
INPUT_DATA => SYSTEM$REFERENCE('view', 'binary_classification_view'),
TARGET_COLNAME => 'label'
);
모델을 생성한 후 모델의 PREDICT 메서드를 사용하여 레이블이 지정되지 않은 구매 데이터의 레이블을 추론합니다. OBJECT_CONSTRUCT 함수를 사용하여 INPUT_DATA 인자에 대한 특징의 키-값 페어를 만들 수 있습니다.
SELECT model_binary!PREDICT(INPUT_DATA => object_construct(*))
as prediction from prediction_purchase_data;
모델은 다음 형식으로 출력을 반환합니다. 예측 오브젝트에는 각 클래스에 대해 예측되는 확률과 최대 예측 확률을 기준으로 예측되는 클래스가 포함됩니다. 예측은 원래 특징이 제공된 것과 동일한 순서로 반환됩니다.
+--------------------------------------------------+
| PREDICTION |
|--------------------------------------------------|
| { |
| "class": "False", |
| "logs": null, |
| "probability": { |
| "False": 0.997954711, |
| "True": 0.002045289 |
| } |
| } |
| { |
| "class": "False", |
| "logs": null, |
| "probability": { |
| "False": 0.9972659439, |
| "True": 0.0027340561 |
| } |
| } |
| { |
| "class": "False", |
| "logs": null, |
| "probability": { |
| "False": 0.9971540571, |
| "True": 0.0028459429 |
| } |
| } |
| { |
| "class": "False", |
| "logs": null, |
| "probability": { |
| "False": 0.9971536503, |
| "True": 0.0028463497 |
| } |
| } |
| { |
| "class": "False", |
| "logs": null, |
| "probability": { |
| "False": 0.9972659439, |
| "True": 0.0027340561 |
| } |
| } |
+--------------------------------------------------+
예측에 특징을 결합하려면 다음과 같은 쿼리를 사용하십시오.
SELECT *, model_binary!PREDICT(
INPUT_DATA => object_construct(*))
as predictions from prediction_purchase_data;
+---------------------+-------------+----------------------------+
| USER_INTEREST_SCORE | USER_RATING | PREDICTIONS |
|---------------------+-------------+----------------------------|
| 4 | 0 | { |
| | | "class": "False", |
| | | "logs": null, |
| | | "probability": { |
| | | "False": 0.997954711, |
| | | "True": 0.002045289 |
| | | } |
| | | } |
| 2 | 3 | { |
| | | "class": "False", |
| | | "logs": null, |
| | | "probability": { |
| | | "False": 0.9972659439, |
| | | "True": 0.0027340561 |
| | | } |
| | | } |
| 3 | 2 | { |
| | | "class": "False", |
| | | "logs": null, |
| | | "probability": { |
| | | "False": 0.9971540571, |
| | | "True": 0.0028459429 |
| | | } |
| | | } |
| 1 | 1 | { |
| | | "class": "False", |
| | | "logs": null, |
| | | "probability": { |
| | | "False": 0.9971536503, |
| | | "True": 0.0028463497 |
| | | } |
| | | } |
| 0 | 3 | { |
| | | "class": "False", |
| | | "logs": null, |
| | | "probability": { |
| | | "False": 0.9972659439, |
| | | "True": 0.0027340561 |
| | | } |
| | | } |
+---------------------+-------------+----------------------------+
다중 클래스 분류자 학습 및 사용하기¶
학습용 이진 데이터가 포함된 뷰를 만듭니다.
CREATE OR REPLACE multiclass_classification_view AS
SELECT uuid, user_interest_score, user_rating, class
FROM training_purchase_data;
SELECT * FROM multiclass_classification_view;
이 SELECT 문은 다음 형식으로 결과를 반환합니다.
+---------------------+-------------+-----------------+
| USER_INTEREST_SCORE | USER_RATING | CLASS |
|---------------------+-------------+---------------- |
| 4 | 0 | not_interested |
| 3 | 3 | not_interested |
| 0 | 0 | add_to_wishlist |
| 3 | 0 | purchase |
| 0 | 2 | not_interested |
| 2 | 1 | purchase |
| 1 | 0 | not_interested |
+---------------------+-------------+-----------------+
이제 이 뷰에서 다중 클래스 분류 모델을 만듭니다.
CREATE OR REPLACE SNOWFLAKE.ML.CLASSIFICATION model_multiclass(
INPUT_DATA => SYSTEM$REFERENCE('view', 'multiclass_classification_view'),
TARGET_COLNAME => 'class'
);
모델을 생성한 후 모델의 PREDICT 메서드를 사용하여 레이블이 지정되지 않은 구매 데이터의 레이블을 추론합니다. OBJECT_CONSTRUCT 함수를 사용하여 INPUT_DATA 인자에 대한 키-값 페어를 자동으로 생성합니다.
SELECT *, model_multiclass!PREDICT(
INPUT_DATA => object_construct(*))
as predictions from prediction_purchase_data;
모델은 다음 형식으로 출력을 반환합니다. 예측 오브젝트에는 각 클래스에 대해 예측되는 확률과 최대 예측 확률을 기준으로 예측되는 클래스가 포함됩니다. 예측은 제공된 원래 특징과 동일한 순서로 반환되며 동일한 쿼리에 결합될 수 있습니다.
+---------------------+-------------+--------------------------------------+
| USER_INTEREST_SCORE | USER_RATING | PREDICTIONS |
|---------------------+-------------+--------------------------------------|
| 4 | 0 | { |
| | | "class": "not_interested", |
| | | "logs": null, |
| | | "probability": { |
| | | "add_to_wishlist": 0.0114593962, |
| | | "not_interested": 0.988124481, |
| | | "purchase": 0.0004161228 |
| | | } |
| | | } |
| 2 | 3 | { |
| | | "class": "not_interested", |
| | | "logs": null, |
| | | "probability": { |
| | | "add_to_wishlist": 0.060358652, |
| | | "not_interested": 0.9283297874, |
| | | "purchase": 0.0113115606 |
| | | } |
| | | } |
| 3 | 2 | { |
| | | "class": "not_interested", |
| | | "logs": null, |
| | | "probability": { |
| | | "add_to_wishlist": 0.0004839615, |
| | | "not_interested": 0.9990937618, |
| | | "purchase": 0.0004222767 |
| | | } |
| | | } |
| 1 | 1 | { |
| | | "class": "not_interested", |
| | | "logs": null, |
| | | "probability": { |
| | | "add_to_wishlist": 0.0004852349, |
| | | "not_interested": 0.9991116684, |
| | | "purchase": 0.0004030968 |
| | | } |
| | | } |
| 0 | 3 | { |
| | | "class": "not_interested", |
| | | "logs": null, |
| | | "probability": { |
| | | "add_to_wishlist": 0.0515227848, |
| | | "not_interested": 0.937059287, |
| | | "purchase": 0.0114179283 |
| | | } |
| | | } |
+---------------------+-------------+--------------------------------------+
결과를 테이블에 저장하고 예측 탐색하기¶
모델의 PREDICT 메서드 호출 결과를 쿼리로 직접 읽을 수 있지만, 결과를 테이블에 저장하면 예측을 편리하게 탐색할 수 있습니다.
CREATE OR REPLACE TABLE my_predictions AS
SELECT *, model_multiclass!PREDICT(INPUT_DATA => object_construct(*)) as predictions from prediction_purchase_data;
SELECT * FROM my_predictions;
그런 다음 추가 쿼리에서 키 및 예측 열을 탐색할 수 있습니다. 아래 쿼리는 예측을 탐색합니다.
SELECT
predictions:class AS predicted_class,
predictions:probability AS predicted_probabilities,
predictions:probability:not_interested AS not_interested_class_probability,
predictions['probability']['purchase'] AS purchase_class_probability
FROM my_predictions;
위 쿼리는 다음 형식으로 결과를 반환합니다.
+-------------------+------------------------------------+----------------------------------+----------------------------+
| PREDICTED_CLASS | PREDICTED_PROBABILITIES | NOT_INTERESTED_CLASS_PROBABILITY | PURCHASE_CLASS_PROBABILITY |
|-------------------+------------------------------------+----------------------------------+----------------------------|
| "not_interested" | { | 0.988124481 | 0.0004161228 |
| | "add_to_wishlist": 0.0114593962, | | |
| | "not_interested": 0.988124481, | | |
| | "purchase": 0.0004161228 | | |
| | } | | |
| "not_interested" | { | 0.988124481 | 0.0004161228 |
| | "add_to_wishlist": 0.0114593962, | | |
| | "not_interested": 0.988124481, | | |
| | "purchase": 0.0004161228 | | |
| | } | | |
| "not_interested" | { | 0.9990628483 | 0.0004207292 |
| | "add_to_wishlist": 0.0005164225, | | |
| | "not_interested": 0.9990628483, | | |
| | "purchase": 0.0004207292 | | |
| | } | | |
| "add_to_wishlist" | { | 0.0011554733 | 0.0032013896 |
| | "add_to_wishlist": 0.9956431372, | | |
| | "not_interested": 0.0011554733, | | |
| | "purchase": 0.0032013896 | | |
| | } | | |
| "add_to_wishlist" | { | 0.0011554733 | 0.0032013896 |
| | "add_to_wishlist": 0.9956431372, | | |
| | "not_interested": 0.0011554733, | | |
| | "purchase": 0.0032013896 | | |
| | } | | |
+-------------------+------------------------------------+----------------------------------+----------------------------+
평가 함수 사용하기¶
기본적으로, 평가는 모든 인스턴스에서 활성화됩니다. 그러나 평가는 config 오브젝트 인자를 사용하여 수동으로 활성화하거나 비활성화할 수 있습니다. ‘evaluate’ 키가 FALSE 값으로 지정되면 평가를 사용할 수 없습니다.
CREATE OR REPLACE SNOWFLAKE.ML.CLASSIFICATION model(
INPUT_DATA => SYSTEM$REFERENCE('view', 'binary_classification_view'),
TARGET_COLNAME => 'label',
CONFIG_OBJECT => {'evaluate': TRUE}
);
평가가 활성화되면 여기에 표시된 평가 API를 사용하여 평가 메트릭을 얻을 수 있습니다.
CALL model!SHOW_EVALUATION_METRICS();
CALL model!SHOW_GLOBAL_EVALUATION_METRICS();
CALL model!SHOW_THRESHOLD_METRICS();
CALL model!SHOW_CONFUSION_MATRIX();
반환된 메트릭에 대한 설명은 평가 메트릭 이해하기 섹션을 참조하십시오.
모델 역할 및 사용 권한¶
각 분류 모델 인스턴스는 mladmin 과 mlconsumer 의 두 가지 모델 역할을 포함합니다. 이러한 역할의 범위는 모델 자체인 model!mladmin 과 model!mlconsumer 로 지정됩니다. 모델 오브젝트의 소유자(처음에는 모델 오브젝터의 생성자)는 model!mladmin 및 model!mlconsumer 역할을 자동으로 부여받으며 이러한 역할을 계정 역할과 데이터베이스 역할에 부여할 수 있습니다.
mladmin 역할은 예측 방법 및 평가 방법을 포함하되 이에 국한되지 않고 모델 오브젝트에서 호출 가능한 모든 API의 사용을 허용합니다. mlconsumer 역할은 다른 탐색적 API가 아닌 예측 API에서만 사용을 허용합니다.
다음 SQL 예에서는 분류 모델 역할을 다른 역할에 부여하는 방법을 보여줍니다. r1 역할은 분류 모델을 생성할 수 있으며, r2 역할에 mlconsumer 권한을 부여하여 r2 가 해당 모델의 PREDICT 메서드를 호출할 수 있도록 합니다. 그런 다음 r1 은 mladmin 역할을 다른 역할인 r3 에 부여하여 r3 이 모델의 모든 메서드를 호출할 수 있도록 합니다.
먼저 r1 역할은 모델 오브젝트를 생성하여 r1 을 모델 model 의 소유자로 만듭니다.
USE ROLE r1;
CREATE OR REPLACE SNOWFLAKE.ML.CLASSIFICATION model(
INPUT_DATA => SYSTEM$REFERENCE('TABLE', 'test_classification_dataset'),
TARGET_COLNAME => 'LABEL'
);
아래 문을 실행하면 r2 역할이 모델의 PREDICT 메서드를 호출할 수 없음을 확인할 수 있습니다.
USE ROLE r2;
SELECT model!PREDICT(1); -- privilege error
다음으로, r1 은 r2 에 mlocnosumer 인스턴스 역할을 부여하고 그 후에 r2 는 모델의 PREDICT 메서드를 호출할 수 있습니다.
USE ROLE r1;
GRANT SNOWFLAKE.ML.CLASSIFICATION ROLE model!mlconsumer TO ROLE r2;
USE ROLE r2;
CALL model!PREDICT(
INPUT_DATA => system$query_reference(
'SELECT object_construct(*) FROM test_classification_dataset')
);
마찬가지로, r3 역할은 mladmin 인스턴스 역할 없이는 모델의 평가 메트릭을 확인할 수 없습니다.
USE ROLE r3;
CALL model!SHOW_EVALUATION_METRICS(); -- privilege error
역할 r1 이 필요한 역할을 r3 에 부여하면 r3 이 모델의 SHOW_EVALUATION_METRICS 메서드를 호출할 수 있습니다.
USE ROLE r1;
GRANT SNOWFLAKE.ML.CLASSIFICATION ROLE model!mladmin TO ROLE r3;
USE ROLE r3;
CALL model!SHOW_EVALUATION_METRICS();
다음과 같이 권한을 철회할 수 있습니다.
USE ROLE r1;
REVOKE SNOWFLAKE.ML.CLASSIFICATION ROLE model!mlconsumer FROM ROLE r2;
REVOKE SNOWFLAKE.ML.CLASSIFICATION ROLE model!mladmin FROM ROLE r3;
다음 명령을 사용하여 이러한 각 인스턴스 역할이 부여된 계정 역할과 데이터베이스 역할을 확인합니다.
SHOW GRANTS TO SNOWFLAKE.ML.CLASSIFICATION ROLE <model_name>!mladmin;
SHOW GRANTS TO SNOWFLAKE.ML.CLASSIFICATION ROLE <model_name>!mlconsumer;
평가 메트릭 이해하기¶
메트릭은 모델이 새 데이터를 예측하는 정확도를 측정합니다. Snowflake 분류는 현재 전체 데이터 세트에서 무작위 샘플을 선택하여 모델을 평가합니다. 새 모델은 이러한 행 없이 학습된 다음, 해당 행이 추론 입력으로 사용됩니다. 무작위 샘플 부분은 EVALUATION_CONFIG 오브젝트의 test_fraction 키를 사용하여 구성할 수 있습니다.
show_evaluation_metrics 의 메트릭¶
show_evaluation_metrics 는 각 클래스에 대해 다음 값을 계산합니다. SHOW_EVALUATION_METRICS 섹션을 참조하십시오.
양성 인스턴스: 관심 클래스 또는 예측되는 클래스에 속하는 데이터(행)의 인스턴스입니다.
음성 인스턴스: 관심 클래스에 속하지 않거나 예측되는 데이터와 반대되는 데이터(행)의 인스턴스입니다.
진양성(TP): 양성 인스턴스를 올바르게 예측한 것입니다.
진음성(TN): 음성 인스턴스를 올바르게 예측한 것입니다.
가양성(FP): 양성 인스턴스를 잘못 예측한 것입니다.
가음성(FN): 음성 인스턴스를 잘못 예측한 것입니다.
위의 값을 사용하여 각 클래스에 대해 다음 메트릭이 보고됩니다. 각 메트릭에 대해 값이 높을수록 더욱 예측적인 모델임을 나타냅니다.
정밀도: 전체 예측 양성에 대한 진양성의 비율입니다. 예측된 양성 인스턴스 중 실제로 양성인 인스턴스의 수를 측정한 것입니다.
재현율(민감도): 전체 실제 양성에 대한 진양성의 비율입니다. 실제 양성 인스턴스 중 올바르게 예측된 인스턴스의 수를 측정한 것입니다.
F1 점수: 정밀도와 재현율의 조화 평균입니다. 이 점수는 특히 클래스 분포가 고르지 않은 경우 정밀도와 재현율 간의 균형을 제시합니다.
show_global_evaluation_metrics 의 메트릭¶
show_global_evaluation_metrics 는 show_evaluation_metrics 에서 계산한 클래스별 메트릭을 평균하여 모델에서 예측한 모든 클래스에 대한 전체(전역) 메트릭을 계산합니다. SHOW_GLOBAL_EVALUATION_METRICS 섹션을 참조하십시오.
현재 macro 및 weighted 평균화는 정밀도, 재현율, F1, AUC 메트릭에 사용됩니다.
로지스틱 손실(LogLoss)은 모델 전체에 대해 계산됩니다. 예측의 목적은 손실 함수를 최소화하는 것입니다.
show_threshold_metrics 의 메트릭¶
show_threshold_metrics 는 각 클래스의 특정 임계값에 대한 원시 개수와 메트릭을 제공합니다. 이는 ROC 및 PR 곡선을 플로팅하거나 원하는 경우 임계값 조정을 수행하는 데 사용할 수 있습니다. 임계값은 각 특정 클래스에 대해 0에서 1까지의 범위에서 변하며 예측 확률이 할당됩니다. SHOW_THRESHOLD_METRICS 섹션을 참조하십시오.
해당 클래스에 속할 것으로 예상되는 확률이 지정된 임계값을 초과하는 경우 샘플은 어떤 클래스에 속하는 것으로 분류됩니다. 진양성, 진음성, 가양성, 가음성은 음성 클래스를 고려 중인 클래스에 속하지 않는 모든 인스턴스로 간주하여 계산됩니다. 그러면 다음 메트릭이 계산됩니다.
진양성률(TPR): 모델이 올바르게 식별하는 실제 양성 인스턴스의 비율입니다(재현율과 동일).
가양성률(FPR): 양성으로 잘못 예측된 실제 음성 인스턴스의 비율입니다.
정확도: 총 예측 수에 대한 올바른 예측(진양성 및 진음성 모두)의 비율로, 모델의 성능을 전반적으로 측정하는 메트릭입니다. 이 메트릭은 불균형 사례에서 오해를 불러일으킬 수 있습니다.
지원: 지정된 데이터 세트에서 클래스의 실제 발생 횟수입니다. 지원 값이 높을수록 데이터 세트에서 클래스가 더 크게 표현된다는 의미입니다. 지원은 그 자체가 모델의 메트릭이 아니라 데이터 세트의 특성입니다.
show_confusion_matrix 의 혼동 행렬¶
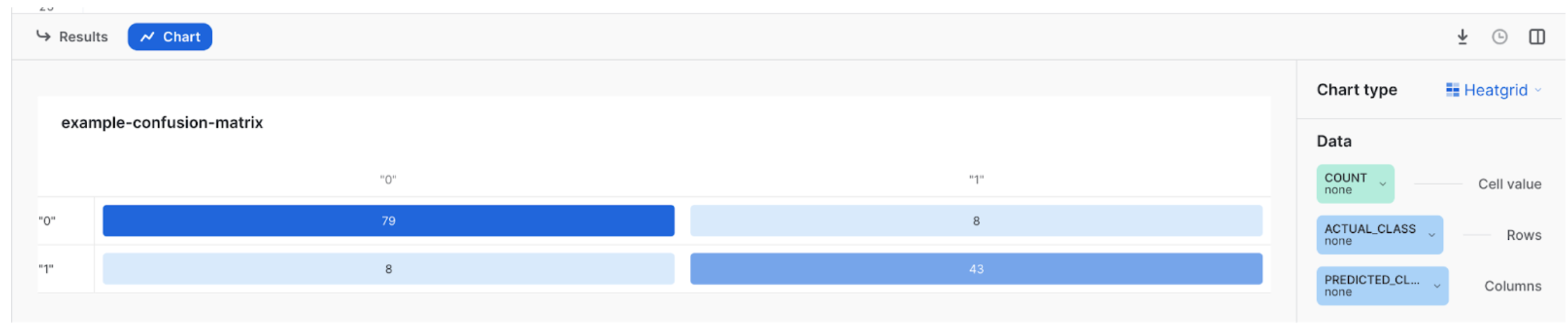
혼동 행렬은 예측 값과 실제 값을 비교하고 양성 인스턴스와 음성 인스턴스를 올바르게 식별하는 능력을 평가하여 모델의 성능을 평가하는 데 사용되는 테이블입니다. 목표는 행렬의 대각선에 있는 인스턴스 수를 최대화하고 대각선을 벗어난 인스턴스 수를 최소화하는 것입니다. SHOW_CONFUSION_MATRICX 섹션을 참조하십시오.
Snowsight에서는 다음과 같이 혼동 행렬을 시각화할 수 있습니다.
CALL model_binary!SHOW_CONFUSION_MATRIX();
결과는 다음과 같습니다.
+--------------+--------------+-----------------+-------+------+
| DATASET_TYPE | ACTUAL_CLASS | PREDICTED_CLASS | COUNT | LOGS |
|--------------+--------------+-----------------+-------+------|
| EVAL | false | false | 37 | NULL |
| EVAL | false | true | 1 | NULL |
| EVAL | true | false | 0 | NULL |
| EVAL | true | true | 22 | NULL |
+--------------+--------------+-----------------+-------+------+
혼동 행렬을 시각화하려면 Chart, Chart Type, Heatgrid 를 차례로 클릭하십시오. 데이터에서 Cell values 에는 NONE을 선택하고, Rows 에는 PREDICTED_CLASS를 선택하고, Columns 에는 ACTUAL_CLASS를 선택합니다. 결과는 아래 그림과 유사하게 나타납니다.
특징 중요도 이해하기¶
분류 모델은 모델에 사용된 모든 특징의 상대적 중요도를 설명할 수 있습니다. 이 정보는 데이터에 실제로 영향을 미치는 요소를 이해하는 데 유용합니다.
SHOW_FEATURE_IMPORTANCE 메서드는 모델의 트리가 각 특징을 사용하여 의사 결정을 내린 횟수를 계산합니다. 이러한 특징 중요도 점수는 합계가 1이 되도록 0과 1 사이의 값으로 정규화됩니다. 결과 점수는 학습된 모델에 있는 함수의 대략적인 순위를 나타냅니다.
점수가 서로 가까운 특징은 그 중요도가 비슷합니다. 서로 매우 비슷한 여러 특징을 사용하면 해당 특징들의 중요도 점수가 낮아질 수 있습니다.
제한 사항¶
특징 중요도를 계산하는 데 사용되는 기법을 선택할 수 없습니다.
특징 중요도 점수는 모델의 정확성에 중요한 특징에 대한 직관을 얻는 데 도움이 될 수 있지만, 실제 값을 추정치로 간주해야 합니다.
예¶
CALL model_binary!SHOW_FEATURE_IMPORTANCE();
+------+---------------------+---------------+---------------+
| RANK | FEATURE | SCORE | FEATURE_TYPE |
|------+---------------------+---------------+---------------|
| 1 | USER_RATING | 0.9295302013 | user_provided |
| 2 | USER_INTEREST_SCORE | 0.07046979866 | user_provided |
+------+---------------------+---------------+---------------+
비용 고려 사항¶
분류 모델을 학습시키고 사용하면 컴퓨팅 및 저장소 비용이 발생합니다.
분류 기능(모델 학습, 모델로 예측, 메트릭 검색)에서 API를 사용하려면 모두 활성 웨어하우스가 필요합니다. 분류 함수 사용에 따른 컴퓨팅 비용은 웨어하우스에 청구됩니다. Snowflake 컴퓨팅 비용에 대한 일반 정보는 컴퓨팅 비용 이해하기 를 참조하십시오.
발생하는 저장소 요금은 학습 단계 중에 생성된 분류 모델 인스턴스의 저장을 반영합니다. 모델 인스턴스와 연결된 오브젝트를 보려면 Account Usage 뷰(예: ACCOUNT_USAGE.TABLES 및 ACCOUNT_USAGE.STAGES)로 이동하십시오. 분류 모델 오브젝트의 DATABASE 및 SCHEMA 열에는 NULL이 포함되어 있지만 모델 인스턴스에 포함된 오브젝트의 경우 INSTANCE_ID 열이 채워집니다. 이러한 오브젝트는 모델 인스턴스로 완전히 관리되며 오브젝트에 별도로 액세스하거나 삭제할 수 없습니다. 모델과 관련된 저장소 요금을 절감하려면 사용되지 않거나 더 이상 지원되지 않는 모델을 삭제하십시오.
Snowpark에서 분류 사용하기¶
session.call 은 아직 분류 모델과 호환되지 않습니다. Snowpark에서 분류 모델을 사용하려면 여기에 표시된 대로 session.sql 을 대신 사용하십시오.
session.sql("CREATE SNOWFLAKE.ML.CLASSIFICATION model(...)").collect()
session.sql("SELECT model!PREDICT(...)").collect()