Uso do conector Python¶
Este tópico fornece uma série de exemplos que ilustram como usar o conector Snowflake para realizar operações padrão do Snowflake, tais como login de usuário, criação de bancos de dados e tabelas, criação de warehouse, inserção/carregamento de dados e consulta.
O código de exemplo no final deste tópico combina os exemplos em um único programa Python operacional.
Nota
Snowflake agora fornece APIs Python de primeira classe para gerenciar os principais recursos do Snowflake, incluindo bancos de dados, esquemas, tabelas, tarefas e warehouses, sem usar SQL. Para obter mais informações, consulte Snowflake Python APIs: Gerenciamento de objetos Snowflake com Python.
Criação de um banco de dados, esquema e warehouse¶
Depois de fazer o login, crie um banco de dados, esquema e warehouse, se ainda não existirem, usando os comandos CREATE DATABASE, CREATE SCHEMA e CREATE WAREHOUSE.
O exemplo abaixo mostra como criar um warehouse chamado tiny_warehouse, um banco de dados chamado testdb e um esquema chamado testschema. Note que, quando você cria o esquema, deve especificar o nome do banco de dados no qual criar o esquema, ou você já deve estar conectado ao banco de dados no qual deve criar o esquema. O exemplo abaixo executa um comando USE DATABASE antes do comando CREATE SCHEMA para garantir que o esquema seja criado no banco de dados correto.
Uso do banco de dados, esquema e warehouse¶
Especifique o banco de dados e o esquema no qual você deseja criar tabelas. Especifique também o warehouse que fornecerá recursos para a execução de consultas e instruções DML.
Por exemplo, para utilizar o banco de dados testdb, esquema testschema e warehouse tiny_warehouse (criados anteriormente):
Criação de tabelas e inserção de dados¶
Use o comando CREATE TABLE para criar tabelas e o comando INSERT para preencher as tabelas com dados.
Por exemplo, crie uma tabela chamada testtable e insira duas linhas na tabela:
Carregamento de dados¶
Em vez de inserir dados em tabelas usando comandos INSERT individuais, você pode carregar dados em massa de arquivos preparados em um local interno ou externo.
Cópia de dados a partir de um local interno¶
Para carregar dados de arquivos de sua máquina host em uma tabela, primeiro use o comando PUT para preparar o arquivo em um local interno e depois use o comando COPY INTO <tabela> para copiar os dados dos arquivos para a tabela.
Por exemplo:
Onde seus dados CSV estão armazenados em um diretório local chamado
/tmp/dataem um ambiente Linux ou macOS e o diretório contém arquivos chamadosfile0,file1, …file100.
Cópia de dados de um local externo¶
Para carregar dados de arquivos já preparados em um local externo (ou seja, seu bucket S3) em uma tabela, use o comando COPY INTO <tabela>.
Por exemplo:
Onde:
s3://<bucket_s3>/data/especifica o nome do seu bucket S3Os arquivos no bucket são prefixados com
data.O bucket é acessado usando-se uma integração de armazenamento criada com CREATE STORAGE INTEGRATION por um administrador de conta (ou seja, um usuário com a função ACCOUNTADMIN) ou uma função com o privilégio global CREATE INTEGRATION. Uma integração de armazenamento permite que os usuários evitem fornecer credenciais para acessar um local de armazenamento privado.
Nota
Este exemplo usa a função format() para compor a instrução. Se seu ambiente tem um risco de ataques de injeção SQL, você pode preferir vincular valores em vez de usar format().
Consulta de dados¶
Com o conector Snowflake para Python, você pode enviar:
uma consulta síncrona, que retorna o controle ao seu aplicativo após a conclusão da consulta.
uma consulta assíncrona, que retorna o controle ao seu aplicativo antes que a consulta seja concluída.
Após a conclusão da consulta, você usa o objeto Cursor para buscar os valores nos resultados. Por padrão, o conector Snowflake para Python converte os valores dos tipos de dados do Snowflake em tipos de dados Python nativos. (Note que você pode escolher retornar os valores como cadeias de caracteres cordas e realizar as conversões de tipo em seu aplicativo. Consulte Aprimoramento do desempenho da consulta sem conversão de dados.)
Nota
Por padrão, os valores das colunas NUMBER são retornados como valores de ponto flutuante de precisão dupla (float64). Para retorná-los como valores decimais (decimal.Decimal) nos métodos fetch_pandas_all() e fetch_pandas_batches(), defina o parâmetro arrow_number_to_decimal no método connect() como True.
Realização de uma consulta síncrona¶
Para realizar uma consulta síncrona, chame o método execute() no objeto Cursor. Por exemplo:
Use o objeto Cursor para buscar os valores nos resultados, como explicado em Uso de cursor para buscar valores.
Realização de uma consulta assíncrona¶
O conector Snowflake para Python aceita consultas assíncronas (ou seja, consultas que retornam o controle ao usuário antes que sejam concluídas). Você pode enviar uma consulta assíncrona e usar sondagens para determinar quando a consulta foi concluída. Após a conclusão da consulta, você pode obter os resultados.
Nota
Para realizar consultas assíncronas, é necessário garantir que o parâmetro de configuração ABORT_DETACHED_QUERY seja FALSE (valor padrão).
Se a conexão com o cliente for perdida:
Para consultas síncronas, todas as consultas síncronas em andamento são abortadas imediatamente, independentemente do valor do parâmetro.
Para consultas assíncronas:
Se ABORT_DETACHED_QUERY estiver definido como
FALSE, as consultas assíncronas em andamento continuarão a ser executadas até terminarem normalmente.Se ABORT_DETACHED_QUERY estiver definido como
TRUE, o Snowflake abortará automaticamente todas as consultas assíncronas em andamento quando uma conexão do cliente não for restabelecida após cinco minutos.Você pode evitar que a consulta assíncrona seja abortada na marca de cinco minutos chamando
cursor.query_result(queryId). Embora essa chamada não recupere o resultado real de consulta, pois a consulta ainda está em execução, ela impede que a consulta seja cancelada. Invocarquery_resulté uma operação síncrona, que pode ou não ser apropriada para o seu caso de uso específico.
Com esse recurso, você pode enviar várias consultas em paralelo sem esperar que cada consulta seja concluída. Você também pode executar uma combinação de consultas síncronas e assíncronas durante a mesma sessão.
Nota
A execução de várias instruções em uma única consulta requer que um warehouse válido esteja disponível em uma sessão.
Finalmente, você pode enviar uma consulta assíncrona a partir de uma conexão e verificar os resultados de uma conexão diferente. Por exemplo, um usuário pode iniciar uma consulta de longa duração a partir de seu aplicativo, sair do aplicativo e reiniciá-lo posteriormente para verificar os resultados.
Para entender melhor a hierarquia da lógica de negócios dos drivers e a interação do parâmetro ABORT_DETACHED_QUERY, consulte o seguinte fluxograma:
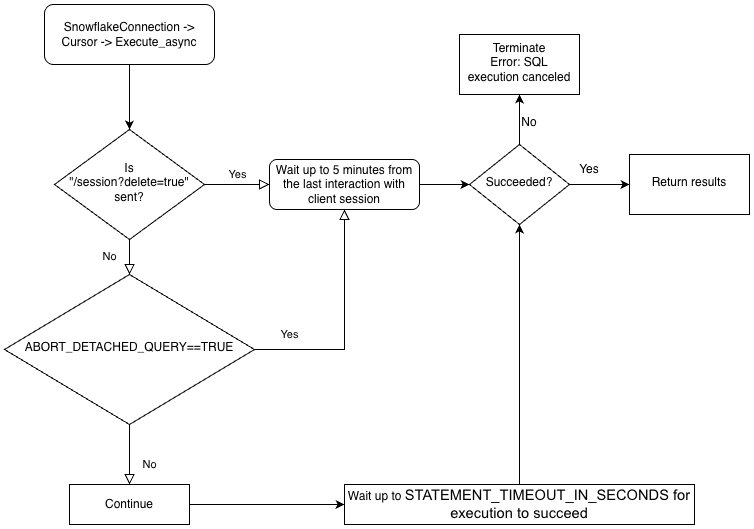
Envio de uma consulta assíncrona¶
Nota
Consultas assíncronas não oferecem suporte a instruções PUT/GET.
Quando cursor.execute_async(query) é usado, o driver Snowflake para Python faz o controle automático das consultas enviadas de forma assíncrona. Quando a conexão é explicitamente fechada com connection.close() ou o gerenciador de contexto é usado com connect()..., a lista de consultas assíncronas é examinada e, se alguma delas ainda estiver em execução, a sessão do lado do Snowflake não será excluída.
Se nenhuma consulta assíncrona estiver em execução dentro da mesma conexão, a sessão do Snowflake pertencente à conexão será desconectada quando connection.close() for chamado, o que implicitamente cancela todas as outras consultas sendo executadas na mesma sessão.
This behavior also depends on the SQL ABORT_DETACHED_QUERY parameter.
Como prática recomendada, isole todas as tarefas assíncronas de longa duração (especialmente aquelas que devem continuar após o fechamento da conexão) em uma conexão separada.
Você pode usar o parâmetro de conexão server_session_keep_alive (padrão: False) para substituir esse comportamento automático. Por padrão, a sessão do Snowflake é desconectada quando connection.close() é chamado somente quando nenhuma consulta assíncrona está sendo executada nele. O comportamento padrão não considera ou rastreia consultas de sincronização.
Quando server_session_keep_alive=True, connection.close() não desconecta a sessão do Snowflake, seja qual for o status das consultas. Para conexões projetadas para emitir consultas assíncronas de longa duração, a habilitação dessa configuração pode reduzir a sobrecarga de CPU e acelerar o processo de fechamento de conexão.
Importante
A habilitação desse parâmetro pode ter efeitos inesperados e faturáveis (por exemplo, pode deixar as consultas em execução até o valor configurado de STATEMENT_TIMEOUT_IN_SECONDS). A Snowflake recomenda fortemente que você decida com critério se há necessidade de alterar o valor padrão server_session_keep_alive e, se possível, testar minuciosamente a alteração em ambientes que não são de produção antes de implementá-la em produção.
Para enviar uma consulta assíncrona, chame o método execute_async() no objeto Cursor. Por exemplo:
Após enviar a consulta:
Para determinar se a consulta ainda está em andamento, consulte Verificação do status de uma consulta.
Para recuperar os resultados da consulta, consulte Uso do ID de consulta para recuperar os resultados de uma consulta.
Para exemplos de realização de consultas assíncronas, consulte Exemplos de consultas assíncronas.
Práticas recomendadas para consultas assíncronas¶
Ao enviar uma consulta assíncrona, siga estas práticas recomendadas:
Certifique-se de que você saiba quais consultas dependem de outras consultas antes de executar qualquer consulta em paralelo. Algumas consultas são interdependentes e sensíveis à ordem e, portanto, não são adequadas para paralelização. Por exemplo, obviamente uma instrução INSERT não deve começar até que a instrução CREATE TABLE correspondente tenha terminado.
Assegure-se de não fazer muitas consultas para a memória que você tem disponível. Executar várias consultas em paralelo normalmente consome mais memória, especialmente se mais de um conjunto de resultados for armazenado na memória ao mesmo tempo.
Ao realizar uma sondagem, trate dos raros casos em que uma consulta não tenha êxito.
Certifique-se de que as instruções de controle de transações (BEGIN, COMMIT e ROLLBACK) não sejam executadas em paralelo com outras instruções.
Esteja ciente de que consultas assíncronas não têm garantia de retornar resultados ordenados, mesmo que o SQL em si tenha uma cláusula ORDER BY. Consequentemente, a :função codenowrap:
result_scannão garante resultados ordenados.
Recuperação da ID de consulta do Snowflake¶
Uma ID de consulta identifica cada consulta executada pelo Snowflake. Quando você usa o conector Snowflake para Python para executar uma consulta, pode acessar a ID da consulta através do atributo sfqid no objeto Cursor:
Você pode usar a ID da consulta para:
Verificar o status da consulta na interface da Web.
No Snowsight, os IDs das consultas são exibidos na página Query History. Consulte Monitoramento da atividade de consulta com o Histórico de consultas.
Verificar o status da consulta (por exemplo, para determinar se uma consulta assíncrona foi concluída) de forma programática.
Consulte Verificação do status de uma consulta.
Recuperar os resultados de uma consulta assíncrona ou de uma consulta síncrona previamente enviada.
Consulte Uso do ID de consulta para recuperar os resultados de uma consulta.
Cancelar uma consulta em andamento.
Consulte Cancelamento usando a ID da consulta.
Verificação do status de uma consulta¶
Para verificar o status de uma consulta:
Obtenha a ID da consulta no campo
sfqiddo objetoCursor.Passe a ID da consulta ao método
get_query_status()do objetoConnectionpara retornar a constanteQueryStatusenum que representa o status da consulta.Por padrão,
get_query_status()não indica um erro se a consulta resultar em um erro. Se quiser indicar um erro, chameget_query_status_throw_if_error()em vez disso.Use a constante da enumeração
QueryStatuspara verificar o status da consulta.Para determinar se a consulta ainda está em execução (por exemplo, se for uma consulta assíncrona), passe a constante para o método
is_still_running()do objetoConnection.Para determinar se ocorreu um erro, passe a constante para o método
is_an_error().
Para a lista completa de constantes de enumeração, consulte
QueryStatus.
O exemplo a seguir executa uma consulta assíncrona e verifica o status da consulta:
O exemplo a seguir indica um erro se a consulta tiver resultado em um erro:
Uso do ID de consulta para recuperar os resultados de uma consulta¶
Nota
Se você executou uma consulta síncrona chamando o método execute() para um objeto Cursor, não precisa usar a ID da consulta para recuperar os resultados. Você pode simplesmente buscar os valores nos resultados, como explicado em Uso de cursor para buscar valores.
Se quiser recuperar os resultados de uma consulta assíncrona ou de uma consulta síncrona previamente enviada, siga estes passos:
Obtenha a ID da consulta. Consulte Recuperação da ID de consulta do Snowflake.
Chame o método
get_results_from_sfqid()no objetoCursorpara recuperar os resultados.Use o objeto
Cursorpara buscar os valores nos resultados, como explicado em Uso de cursor para buscar valores.
Observe que se a consulta ainda estiver em execução, os métodos de busca (fetchone(), fetchmany(), fetchall(), etc.) aguardarão que a consulta seja concluída.
Por exemplo:
Uso de cursor para buscar valores¶
Busque valores de uma tabela usando o método do iterador de objetos do cursor.
Por exemplo, para buscar colunas chamadas “col1” e “col2” da tabela chamada testtable, que foi criada anteriormente (em Criação de tabelas e inserção de dados), use um código semelhante ao seguinte:
O conector Snowflake para Python também fornece um atalho conveniente:
Se precisar obter um único resultado (ou seja, uma única linha), use o método fetchone:
Se precisar obter o número de linhas especificado de cada vez, use o método fetchmany com o número de linhas:
Nota
Use
fetchoneoufetchmanyse o conjunto de resultados for grande demais para caber na memória.
Se precisar obter todos os resultados de uma só vez:
Para definir um tempo limite para uma consulta, execute um comando “begin” e inclua um parâmetro de tempo limite na consulta. Se a consulta exceder a duração do valor do parâmetro, um erro é produzido e ocorre uma reversão.
No código a seguir, o erro 604 significa que a consulta foi cancelada. O parâmetro de tempo limite inicia Timer() e o cancela se a consulta não for concluída dentro do tempo especificado.
Uso de DictCursor para buscar valores por nome de coluna¶
Se quiser buscar um valor por nome de coluna, crie um objeto cursor do tipo DictCursor.
Por exemplo:
Exemplos de consultas assíncronas¶
A seguir está um exemplo simples de uma consulta assíncrona:
O próximo exemplo envia uma consulta assíncrona a partir de uma conexão e recupera os resultados de uma conexão diferente:
Cancelamento usando a ID da consulta¶
Cancele uma consulta usando a ID da consulta:
Substitua a cadeia “queryID“ pela ID real da consulta. Para obter a ID de uma consulta, consulte Recuperação da ID de consulta do Snowflake.
Aprimoramento do desempenho da consulta sem conversão de dados¶
Para melhorar o desempenho da consulta, use a classe SnowflakeNoConverterToPython no módulo snowflake.connector.converter_null para ignorar as conversões de dados do tipo de dados interno do Snowflake para o tipo de dados nativo do Python, por exemplo:
Como resultado, todos os dados são representados em forma de cadeia de caracteres, de modo que o aplicativo é responsável pela sua conversão nos tipos de dados Python nativos. Por exemplo, os dados de TIMESTAMP_NTZ e TIMESTAMP_LTZ são a hora de época representada em forma de cadeia de caracteres, e os dados de TIMESTAMP_TZ são a hora de época seguida por um espaço seguido pela diferença para UTC em minutos representada em forma de cadeia de caracteres.
Nenhum impacto ocorre nos dados vinculados; os dados nativos Python ainda podem ser vinculados para atualizações.
Download de dados¶
O Snowflake Connector para Python versão 3.14.0 introduziu o parâmetro de conexão unsafe_file_write que especifica como o conector deve definir as permissões de arquivo ao fazer download de arquivos para um estágio do Snowflake com o comando GET. Esses arquivos são sempre de propriedade do mesmo usuário que executa o processo Python.
Por padrão, o parâmetro unsafe_file_write é False para fornecer uma permissão de arquivo 600 mais segura e rigorosa, o que significa que somente o proprietário tem permissões de leitura e gravação dos arquivos baixados. Outros grupos e usuários não têm permissões para os arquivos baixados com o comando GET.
Se a sua organização exigir permissões de arquivo menos restritivas para os arquivos, você pode definir o parâmetro unsafe_file_write como True. A ativação desse parâmetro define as permissões de arquivo para os arquivos baixados de um estágio como 644, o que permite que o proprietário leia e grave os arquivos, mas permite que outros apenas os leiam. Essa configuração pode ser necessária, por exemplo, para algumas ferramentas de ETL que são executadas por um usuário de sistema diferente que precisa ler e processar os arquivos baixados.
Se não tiver certeza de qual valor usar, consulte a equipe responsável pela política de segurança aplicável da sua organização.
Vinculação de dados¶
Para especificar valores a serem usados em uma instrução SQL, você pode incluir literais na instrução ou vincular variáveis. Quando você vincula variáveis, insere um ou mais espaços reservados no texto da instrução SQL e então especifica a variável (o valor a ser usado) para cada espaço reservado.
O exemplo a seguir contrasta o uso de literais e a vinculação:
Literais:
Vinculação:
Nota
Há um limite máximo para o tamanho dos dados que você pode vincular ou que pode combinar em um lote. Para obter mais detalhes, consulte Limites no tamanho do texto de consulta.
O Snowflake aceita os seguintes tipos de vinculação:
pyformateformat, que vinculam dados no cliente.qmarkenumeric, que vinculam dados no servidor.
Cada uma é explicada abaixo.
Vinculação de pyformat ou format¶
Tanto a vinculação pyformat como format vincula dados no lado do cliente, e não no lado do servidor.
Por padrão, o conector Snowflake para Python aceita tanto pyformat como format, de modo que você pode usar %(name)s ou %s como o espaço reservado. Por exemplo:
Uso de
%(name)scomo o espaço reservado:Uso de
%scomo o espaço reservado:
Com pyformat e format, você também pode usar um objeto de lista para vincular dados para o operador IN:
O caractere de porcentagem (“%”) é tanto um caractere curinga para SQL LIKE como um caractere de vinculação de formato para Python. Se você usar a vinculação de formato e se seu comando SQL contiver o caractere de porcentagem, poderá ser necessário usar um caractere de escape com o caractere de porcentagem. Por exemplo, se sua instrução SQL for:
então seu código Python será parecido com o seguinte (note o sinal de porcentagem extra para o escape do sinal de porcentagem original):
Vinculação de qmark ou numeric¶
Tanto a vinculação qmark como numeric vincula dados no lado do servidor, e não no lado do cliente.
Para a vinculação
qmark, use um caractere de interrogação (?) para indicar em que parte da cadeia de caracteres você quer que o valor de uma variável seja inserido.Para a vinculação
numeric, use dois pontos (:) seguido por um número para indicar a posição da variável que você deseja substituir naquela posição. Por exemplo,:2especifica a segunda variável.Use a vinculação numérica para vincular o mesmo valor mais de uma vez na mesma consulta. Por exemplo, se tiver um valor longo VARCHAR ou BINARY ou semiestruturado que você quer usar mais de uma vez, então a vinculação
numericpermite que você envie o valor para o servidor uma vez e o use várias vezes.
As seções a seguir explicam como usar a vinculação qmark e numeric:
Uso da vinculação qmark ou numeric¶
Para usar a vinculação de estilo qmark ou numeric, é possível executar um dos seguintes ou definir paramstyle como parte dos parâmetros de conexão ao chamar connect().
snowflake.connector.paramstyle='qmark'snowflake.connector.paramstyle='numeric'
Se você definir paramstyle como qmark ou numeric, precisará usar ? ou :N (onde N é substituído por um número) como os espaços reservados, respectivamente.
Por exemplo:
Uso de
?como o espaço reservado:Uso de
:Ncomo o espaço reservado:A consulta a seguir mostra como usar a vinculação
numericpara reutilizar uma variável:
Uso da vinculação qmark ou numeric com objetos datetime¶
Ao usar a vinculação qmark ou numeric para vincular dados a um tipo de dados TIMESTAMP do Snowflake, defina a variável de vinculação como uma tupla que especifica o tipo de dados de carimbo de data/hora do Snowflake (TIMESTAMP_LTZ ou TIMESTAMP_TZ) e o valor. Por exemplo:
Ao contrário da vinculação do lado do cliente, a vinculação do lado do servidor requer o tipo de dados Snowflake para a coluna. A maioria dos tipos de dados Python mais comuns já tem mapeamentos implícitos para os tipos de dados Snowflake (por exemplo, int é mapeado para FIXED). Entretanto, como os dados Python datetime podem ser vinculados a um de vários tipos de dados Snowflake (TIMESTAMP_NTZ, TIMESTAMP_LTZ ou TIMESTAMP_TZ), e o mapeamento padrão é TIMESTAMP_NTZ, deve-se especificar o tipo de dados Snowflake a ser utilizado.
Uso de variáveis de vinculação com o operador IN¶
qmark e numeric (vinculação do lado do servidor) não aceitam o uso de variáveis de vinculação com o operador IN.
Se precisar usar variáveis de vinculação com o operador IN, use a vinculação do lado do cliente (pyformat ou format).
Vinculação de parâmetros com variáveis para inserções em lote¶
No código de seu aplicativo, você pode inserir várias linhas como um único lote. Para isso, utilizar parâmetros para valores em uma instrução INSERT. Por exemplo, a seguinte instrução usa os espaços reservados de lugar para qmark vinculação em uma instrução INSERT:
Então, para especificar os dados que devem ser inseridos, defina uma variável que seja uma sequência de sequências (por exemplo, uma lista de tuplas):
Como mostrado no exemplo acima, cada item da lista é uma tupla que contém os valores da coluna para uma linha a ser inserida.
Para realizar a vinculação, chame o método executemany(), passando a variável como o segundo argumento. Por exemplo:
Se você estiver vinculando dados no servidor (ou seja, usando a vinculação qmark ou numeric), o conector pode otimizar o desempenho das inserções em lote através da vinculação.
Quando você usa esta técnica para inserir um grande número de valores, o driver pode melhorar o desempenho ao transmitir os dados (sem criar arquivos na máquina local) para um estágio temporário de ingestão. O driver faz isso automaticamente quando o número de valores excede um limite.
Além disso, o banco de dados e o esquema atual da sessão devem ser definidos. Se não forem definidos, o comando CREATE TEMPORARY STAGE executado pelo driver pode falhar com o seguinte erro:
Nota
Para formas alternativas de carregar dados no banco de dados Snowflake (incluindo carregamento em massa usando o comando COPY), consulte Carregamento de dados para o Snowflake.
Evite ataques de injeção SQL¶
Evite vincular dados usando a função de formatação Python porque você corre o risco de sofrer injeção SQL. Por exemplo:
Em vez disso, armazene os valores em variáveis e depois vincule essas variáveis usando o estilo de vinculação qmark ou numeric.
Recuperação de metadados de coluna¶
Para recuperar metadados sobre cada coluna do conjunto de resultados (por exemplo, o nome, tipo, precisão, escala, etc. de cada coluna), use uma das seguintes abordagens:
Para acessar os metadados após chamar o método
execute()para executar a consulta, use o atributodescriptiondo objetoCursor.Para acessar os metadados sem ter que executar a consulta, chame o método
describe().O método
describeestá disponível no conector do Snowflake para Python 2.4.6 e em versões mais recentes.
O atributo description é definido com um dos seguintes valores:
Versão 2.4.5 e anteriores: Uma lista de tuplas.
Versão 2.4.6 e posteriores: Uma lista de objetos ResultMetadata. (O método
describetambém retorna esta lista).
Cada tupla e objeto ResultMetadata contém os metadados de uma coluna (o nome da coluna, tipo de dados, etc.). Você pode acessar os metadados por índice ou, nas versões 2.4.6 e posteriores, por atributo ResultMetadata.
Os exemplos a seguir demonstram como acessar os metadados de tuplas e objetos ResultMetadata retornados.
Exemplo: Obter os metadados de nome da coluna por índice (versões 2.4.5 e anteriores):
O exemplo a seguir utiliza o atributo description para recuperar a lista de nomes de colunas após a execução de uma consulta. O atributo é uma lista de tuplas, e o exemplo acessa o nome da coluna a partir do primeiro valor em cada tupla.
Exemplo: Obter os metadados de nome da coluna por atributo (versões 2.4.6 e posteriores):
O exemplo a seguir utiliza o atributo description para recuperar a lista de nomes de colunas após a execução de uma consulta. O atributo é uma lista de objetos ResultMetaData, e o exemplo acessa o nome da coluna a partir do atributo name de cada objeto ResultMetadata.
Exemplo: Obter os metadados de nome da coluna sem executar a consulta (versões 2.4.6 e posteriores):
O exemplo a seguir usa o método describe para recuperar a lista de nomes de colunas sem executar uma consulta. O método describe() retorna uma lista de objetos ResultMetaData, e o exemplo acessa o nome da coluna a partir do atributo name de cada objeto ResultMetadata.
Tratamento de erros¶
O aplicativo precisa tratar as exceções levantadas pelo conector do Snowflake adequadamente e decidir continuar ou parar de executar o código.
Uso de execute_stream para executar scripts SQL¶
A função execute_stream permite a execução de um ou mais scripts SQL em um fluxo:
Nota
Poderá ser necessária uma configuração adicional se sql_stream contiver comentários. Consulte Como usar execute_stream para executar scripts SQL.
Encerramento da conexão¶
Como uma melhor prática, encerre a conexão chamando o método close:
Isso assegura que as métricas coletadas do cliente sejam enviadas ao servidor e a sessão seja excluída. Além disso, blocos try-finally ajudam a garantir que a conexão seja encerrada mesmo que uma exceção seja levantada:
Cuidado
Várias conexões não fechadas podem esgotar os recursos do sistema e, eventualmente, causar uma falha no aplicativo.
Uso do gerenciador de contexto para conectar e controlar transações¶
O conector do Snowflake para Python é compatível com um gerenciador de contexto que aloca e libera recursos conforme necessário. O gerenciador de contexto é útil para confirmar ou reverter transações com base no status da instrução quando autocommit está desabilitado.
No exemplo acima, quando a terceira instrução falha, o gerenciador de contexto reverte as mudanças na transação e encerra a conexão. Se todas as instruções forem bem-sucedidas, o gerenciador de contexto confirmará as mudanças e encerrará a conexão.
Um código equivalente com blocos try e except é o seguinte:
Uso do tipo de dados VECTOR¶
O suporte ao tipo de dados VECTOR foi introduzido na versão 3.6.0 do conector Python do Snowflake. Você pode usar o tipo de dados VECTOR com as funções de similaridade de vetor para implementar aplicativos baseados em pesquisa de vetores ou geração aumentada de recuperação (RAG).
O exemplo de código a seguir mostra como usar o conector Python para criar tabelas com colunas VECTOR e chamar a função VECTOR_INNER_PRODUCT:
O exemplo de código a seguir mostra como usar o Python Connector para chamar o VECTOR_COSINE_SIMILARITY a fim de encontrar os vetores mais próximos de [1,2,3]:
Nota
As vinculações de variáveis não são suportadas para tipos de dados VECTOR.
Registro¶
O conector do Snowflake para Python utiliza o módulo Python padrão logging para registrar o status em intervalos regulares para que o aplicativo possa rastrear sua atividade em segundo plano. A maneira mais simples de habilitar o registro é chamar logging.basicConfig() no início do aplicativo.
Por exemplo, para definir o nível de registro como INFO e armazenar os registros em um arquivo chamado /tmp/snowflake_python_connector.log:
Um registro mais abrangente pode ser habilitado definindo o nível de registro como DEBUG, como segue:
A classe formatadora opcional mas recomendada SecretDetector garante que um certo conjunto de informações confidenciais conhecidas seja mascarado antes de ser gravado nos arquivos de log do conector do Snowflake para Python. Para usar SecretDetector, use um código semelhante ao seguinte:
Nota
botocoreeboto3estão disponíveis através do AWS (Amazon Web Services) SDK para Python.
Arquivo de configuração do registro em log¶
Alternativamente, você pode facilmente especificar o nível de log e o diretório no qual salvar os arquivos de log no arquivo de configuração config.toml. Para mais informações sobre este arquivo, consulte Conexão usando o arquivo connections.toml.
Nota
Este recurso de configuração de registro oferece suporte a níveis de registro conforme definido no documento de registro do Python.
Para obter mais informações sobre os níveis de registro em log, consulte o Tutorial básico de registro em log do Python.
Esse arquivo de configuração de registro em log usa toml para definir os parâmetros de registro em log save_logs, level e path, como se segue:
onde:
save_logsdetermina se os logs devem ser salvos.levelespecifica o nível de registro em log. Se não for definido, o driver assume como padrãoINFO.pathidentifica o diretório no qual salvar os arquivos de log. Se não for definido, o driver salvará os logs no diretório padrão$SNOWFLAKE_HOME/logs/.
Nota
Se o seu arquivo config.toml não contiver uma seção [log], as mensagens de log não são salvas.
As mensagens de log de um único dia são anexadas ao arquivo python-connector.log, que mais tarde é renomeado para python-connector.log.YYYY-MM-DD.
Exemplo de programa¶
O seguinte código de exemplo combina muitos dos exemplos descritos nas seções anteriores em um programa Python operacional. Este exemplo contém duas partes:
Uma classe pai (“python_veritas_base”) contém o código para muitas operações comuns, tais como a conexão ao servidor.
Uma classe filha (“python_connector_example”) representa as porções personalizadas de um determinado cliente; por exemplo, consultar uma tabela.
Este código de exemplo é importado diretamente de um de nossos testes para ajudar a garantir que tenha sido executado em um build recente do produto.
Como é retirado de um teste, o exemplo inclui uma pequena quantidade de código para definir uma porta e um protocolo alternativos utilizados em alguns testes. Os usuários não podem definir o protocolo ou número da porta; em vez disso, devem omiti-los e usar os padrões.
Ele também contém alguns marcadores de seção (às vezes chamados de “snippet tags”) para identificar o código que pode ser importado independentemente para a documentação. Os marcadores de seção normalmente se assemelham a:
Estes marcadores de seção não são necessários em um código de usuário.
A primeira parte do código de exemplo contém as sub-rotinas comuns para:
Ler argumentos de linha de comando (por exemplo, “–warehouse MyWarehouse“) que contêm informações de conexão.
Conectar-se ao servidor.
Criar e utilizar um warehouse, um banco de dados e um esquema.
Descartar o esquema, banco de dados e warehouse ao terminar de usá-los.
A segunda parte do código de exemplo cria uma tabela, insere linhas nela, etc:
Para executar esse exemplo, faça o seguinte:
Copie o primeiro trecho de código para um arquivo chamado “python_veritas_base.py”.
Copie o segundo trecho de código para um arquivo chamado “python_connector_example.py”.
Defina a variável de ambiente SNOWSQL_PWD com sua senha; por exemplo:
Execute o programa usando uma linha de comando semelhante à seguinte (substitua as informações de usuário e conta por suas próprias informações de usuário e conta, é claro).
Aviso
Isso exclui o warehouse, o banco de dados e o esquema no final do programa! Não use o nome de um banco de dados existente porque você vai perdê-lo!
Aqui está a saída:
Aqui está um exemplo mais longo:
Nota
Na seção onde você define suas informações de conta e login, certifique-se de substituir as variáveis conforme necessário para corresponder às suas informações de login do Snowflake (nome, senha, etc.).
Este exemplo usa a função format() para compor a instrução. Se seu ambiente tem um risco de ataques de injeção SQL, você pode preferir vincular valores em vez de usar format().