Verwenden des Python-Konnektors¶
Unter diesem Thema werden zahlreiche Beispiele bereitgestellt, die veranschaulichen, wie Sie den Snowflake-Konnektor verwenden können, um Snowflake-Standardoperationen wie Benutzeranmeldung, Datenbank- und Tabellenerstellung, Warehouse-Erstellung, Einfügen/Laden von Daten sowie Abfragen durchzuführen.
Im Beispielcode am Ende dieses Themas werden einzelne Beispiele zu einem einzigen, funktionierenden Python-Programm zusammengeführt.
Bemerkung
Snowflake bietet jetzt erstklassige Python-APIs für die Verwaltung von Snowflake-Kernressourcen wie Datenbanken, Schemas, Tabellen, Aufgaben und Warehouses, ohne SQL zu verwenden. Weitere Informationen dazu finden Sie unter Snowflake Python APIs: Verwalten von Snowflake-Objekten mit Python.
Erstellen einer Datenbank, eines Schemas und eines Warehouse¶
Erstellen Sie nach der Anmeldung mit den Befehlen CREATE DATABASE, CREATE SCHEMA und CREATE WAREHOUSE eine Datenbank, ein Schema und ein Warehouse, falls diese noch nicht vorhanden sind.
Das folgende Beispiel zeigt, wie sich ein Warehouse mit dem Namen tiny_warehouse, eine Datenbank mit dem Namen testdb und ein Schema mit dem Namen testschema erstellen lassen. Beachten Sie, dass Sie beim Erstellen des Schemas entweder den Namen der Datenbank angeben müssen, in der das Schema erstellt werden soll, oder bereits mit der Datenbank verbunden sein müssen, in der das Schema erstellt werden soll. Im folgenden Beispiel wird vor dem Befehl CREATE SCHEMA ein USE DATABASE-Befehl ausgeführt, um sicherzustellen, dass das Schema in der korrekten Datenbank erstellt wird.
Verwenden von Datenbank, Schema und Warehouse¶
Geben Sie Datenbank und Schema an, in denen Sie Tabellen erstellen möchten. Geben Sie auch das Warehouse an, das Ressourcen für die Ausführung von DML-Anweisungen und -Abfragen bereitstellen soll.
Folgendes Beispiel zeigt die Verwendung von Datenbank testdb, Schema testschema und Warehouse tiny_warehouse (zuvor erstellt):
Erstellen von Tabellen und Einfügen von Daten¶
Verwenden Sie den Befehl CREATE TABLE, um Tabellen zu erstellen, und den Befehl INSERT, um die Tabellen mit Daten zu füllen.
Erstellen Sie beispielsweise eine Tabelle mit dem Namen testtable, und fügen Sie zwei Zeilen in die Tabelle ein:
Laden von Daten¶
Anstatt Daten mit einzelnen INSERT-Befehlen in Tabellen einzufügen, können Sie Daten aus Dateien, die entweder an einem internen oder externen Speicherort bereitgestellt werden, per Massenladen hinzufügen.
Kopieren von Daten von einem internen Speicherort¶
Um Daten aus Dateien auf Ihrem Hostcomputer in eine Tabelle zu laden, verwenden Sie zunächst den Befehl PUT für das Staging der Datei an einem internen Speicherort. Verwenden Sie dann den Befehl COPY INTO <Tabelle>, um die Daten aus den Dateien in die Tabelle zu kopieren.
Beispiel:
Hier werden die CSV-Daten in einem lokalen Verzeichnis namens
/tmp/datain einer Linux- oder macOS-Umgebung gespeichert. Das Verzeichnis enthält dann Dateien mit den Namenfile0,file1, …file100.
Kopieren von Daten von einem externen Speicherort¶
Um Daten aus Dateien, die bereits in einem externen Stagingbereich (z. B. Ihr S3-Bucket) bereitgestellt wurden, in eine Tabelle zu laden, verwenden Sie den Befehl COPY INTO <Tabelle>.
Beispiel:
Wobei:
s3://<S3-Bucket>/data/gibt den Namen Ihres S3-Buckets an.Den Dateien im Bucket wird
datavorangestellt.Der Zugriff auf den Bucket erfolgt über eine Speicherintegration, die mit CREATE STORAGE INTEGRATION von einem Kontoadministrator (d. h. einem Benutzer mit der Rolle ACCOUNTADMIN) oder einer Rolle mit der globalen Berechtigung CREATE INTEGRATION erstellt wurde. Bei Verwendung einer Speicherintegration benötigen Benutzer für den Zugriff auf einen privaten Speicherort keine Anmeldeinformationen mehr.
Bemerkung
In diesem Beispiel wird die Anweisung mit der Funktion format() zusammengestellt. Wenn in Ihrer Umgebung das Risiko von Angriffen durch Einschleusung von SQL-Befehlen besteht, sollten Sie möglicherweise das Binden von Werten vorziehen, anstatt format() zu verwenden.
Abfragen von Daten¶
Mit dem Snowflake-Konnektor für Python können Sie Folgendes übermitteln:
Eine synchrone Abfrage, die die Kontrolle an Ihre Anwendung zurückgibt, nachdem die Abfrage abgeschlossen ist.
Eine asynchrone Abfrage, die die Kontrolle an Ihre Anwendung zurückgibt, bevor die Abfrage abgeschlossen ist.
Nachdem die Abfrage abgeschlossen wurde, verwenden Sie das Cursor-Objekt, um die Werte in den Ergebnissen abzurufen. Standardmäßig konvertiert der Snowflake-Konnektor für Python die Werte von Snowflake-Datentypen in native Python-Datentypen. (Beachten Sie, dass Sie die Werte auch als Zeichenfolgen zurückgeben und die Typkonvertierungen in Ihrer Anwendung durchführen können. Siehe Verbessern der Abfrageleistung durch Umgehen der Datenkonvertierung.)
Bemerkung
Standardmäßig werden die Werte aus NUMBER-Spalten als Gleitkommawerten mit doppelter Genauigkeit (float64) zurückgegeben. Um diese als Dezimalwerte (decimal.Decimal) in den Methoden fetch_pandas_all() und fetch_pandas_batches() zurückzugeben, setzen Sie den Parameter arrow_number_to_decimal in der Methode connect() auf True.
Ausführen einer synchronen Abfrage¶
Um eine synchrone Abfrage auszuführen, rufen Sie die Methode execute() im Cursor-Objekt auf. Beispiel:
Verwenden Sie das Cursor-Objekt, um die Werte in den Ergebnissen abzurufen, wie unter Verwenden von cursor zum Abrufen von Werten erläutert.
Ausführen einer asynchronen Abfrage¶
Der Snowflake-Konnektor für Python unterstützt asynchrone Abfragen (d. h. Abfragen, die dem Benutzer die Kontrolle zurückgeben, bevor die Abfrage abgeschlossen ist). Sie können eine asynchrone Abfrage übermitteln und mithilfe von Abrufen (Polling) feststellen, wann die Abfrage abgeschlossen ist. Nachdem die Abfrage abgeschlossen ist, können Sie die Ergebnisse abrufen.
Bemerkung
Um asynchrone Abfragen auszuführen, müssen Sie sicherstellen, dass der Konfigurationsparameter ABORT_DETACHED_QUERY den Wert FALSE hat (Standardwert).
Wenn die Verbindung zum Client unterbrochen wird:
Bei synchronen Abfragen werden alle laufenden synchronen Abfragen unabhängig vom Wert des Parameters sofort abgebrochen.
Für asynchrone Abfragen:
Wenn ABORT_DETACHED_QUERY auf
FALSEeingestellt ist, werden laufende asynchrone Abfragen weiter ausgeführt, bis sie normal beendet werden.Wenn ABORT_DETACHED_QUERY auf
TRUEeingestellt ist, bricht Snowflake automatisch alle laufenden asynchronen Abfragen ab, wenn die Verbindung zum Client nach fünf Minuten nicht wiederhergestellt ist.Sie können verhindern, dass die asynchrone Abfrage an der Fünf-Minuten-Marke abgebrochen wird, indem Sie
cursor.query_result(queryId)aufrufen. Dieser Aufruf ruft zwar nicht das tatsächliche Abfrageergebnis ab, da die Abfrage noch läuft, verhindert jedoch, dass die Abfrage abgebrochen wird. Der Aufruf vonquery_resultist eine synchrone Operation, die für Ihren speziellen Anwendungsfall geeignet sein kann oder auch nicht.
Mit dieser Funktion können Sie mehrere Abfragen parallel übermitteln, ohne auf den Abschluss jeder Abfrage warten zu müssen. Sie können innerhalb derselben Sitzung auch Kombinationen von synchronen und asynchronen Abfragen ausführen.
Bemerkung
Die Ausführung mehrerer Anweisungen in einer einzigen Abfrage setzt voraus, dass ein gültiges Warehouse in einer Sitzung verfügbar ist.
Schließlich können Sie eine asynchrone Abfrage über eine Verbindung übermitteln und die Ergebnisse über eine andere Verbindung abrufen. Beispielsweise kann ein Benutzer eine Abfrage mit langer Laufzeit über Ihre Anwendung initiieren, die Anwendung beenden und die Anwendung zu einem späteren Zeitpunkt erneut starten, um die Ergebnisse zu überprüfen.
Zum besseren Verständnis der Hierarchie der Geschäftslogik der Treiber und der Interaktion des Parameters ABORT_DETACHED_QUERY betrachten Sie das folgende Flussdiagramm:
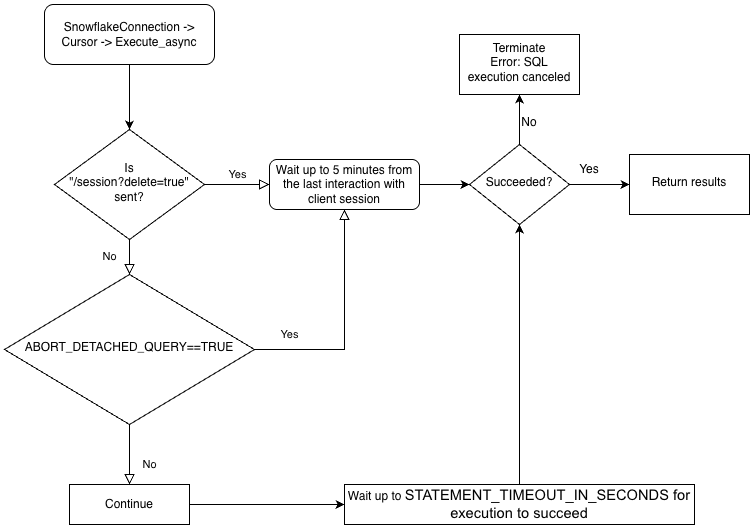
Übermitteln einer asynchronen Abfrage¶
Bemerkung
Asynchrone Abfragen unterstützen nicht PUT/GET-Anweisungen.
Wenn cursor.execute_async(query) verwendet wird, verfolgt der Snowflake-Python-Treiber automatisch die asynchron übermittelten Abfragen. Wenn die Verbindung explizit mit connection.close() geschlossen oder der Kontextmanager mit connect()... verwendet wird, wird die Liste der asynchronen Abfragen geprüft. Wenn eine Abfrage noch ausgeführt wird, wird die Snowflake-seitige Sitzung nicht gelöscht.
Wenn innerhalb der gleichen Verbindung keine asynchronen Abfragen laufen, wird die zur Verbindung gehörende Snowflake-Sitzung abgemeldet, wenn connection.close() aufgerufen wird, wodurch implizit alle anderen Abfragen in derselben Sitzung abgebrochen werden.
This behavior also depends on the SQL ABORT_DETACHED_QUERY parameter.
Als bewährte Methode sollten Sie alle asynchronen Aufgaben mit langer Ausführungszeit (insbesondere solche, die nach dem Schließen der Verbindung fortgesetzt werden sollen) in einer separaten Verbindung isolieren.
Sie können über den Verbindungsparameter server_session_keep_alive (Standard: False) dieses automatische Verhalten überschreiben. Standardmäßig wird die Snowflake-Sitzung abgemeldet, wenn connection.close() nur aufgerufen wird, wenn darin keine asynchronen Abfragen ausgeführt werden. Das Standardverhalten berücksichtigt keine Synchronisierungsabfragen und verfolgt diese auch nicht.
Bei der Einstellung server_session_keep_alive=True, meldet sich connection.close() unabhängig vom Status der Abfragen nicht bei der Snowflake-Sitzung ab. Bei Verbindungen, die für asynchrone Abfragen mit langer Ausführungszeit vorgesehen sind, können durch Aktivierung dieser Einstellung der CPU Overhead reduziert und der Verbindungsaufbau beschleunigt werden.
Wichtig
Das Aktivieren dieses Parameters kann unerwartete, abrechenbare Auswirkungen haben (z. B. kann es dazu kommen, dass Abfragen bis zum konfigurierten Wert von STATEMENT_TIMEOUT_IN_SECONDS) ausgeführt werden. Snowflake empfiehlt dringend, dass Sie sorgfältig entscheiden, ob der Wert von server_session_keep_alive unbedingt geändert werden muss. Testen Sie die Änderung, wenn möglich, gründlich in Nicht-Produktionsumgebungen, bevor Sie sie in der Produktion implementieren.
Um eine asynchrone Abfrage zu übermitteln, rufen Sie die Methode execute_async() im Cursor-Objekt auf. Beispiel:
Nach dem Übermitteln der Abfrage:
Um festzustellen, ob die Abfrage noch ausgeführt wird, siehe Überprüfen des Status einer Abfrage.
Um die Ergebnisse der Abfrage abzurufen, siehe Verwenden der Abfrage-ID zum Abrufen von Abfrageergebnissen.
Beispiele für das Ausführen asynchroner Abfragen finden Sie unter Beispiele für asynchrone Abfragen.
Best Practices für asynchrone Abfragen¶
Beachten Sie beim Übermitteln von asynchronen Abfrage die folgenden bewährten Verfahren:
Stellen Sie vor der parallelen Ausführung von Abfragen sicher, dass Sie die Abhängigkeiten der Abfragen von anderen Abfragen genau kennen. Einige Abfragen sind voneinander und von der Ausführungsreihenfolge abhängig und sind daher nicht für die Parallelisierung geeignet. Beispielsweise kann eine INSERT-Anweisung offensichtlich erst beginnen, nachdem die entsprechende CREATE TABLE-Anweisung abgeschlossen wurde.
Stellen Sie sicher, dass die Anzahl der gestarteten Abfragen auf den verfügbaren Arbeitsspeicher abgestimmt ist. Das parallele Ausführen mehrerer Abfragen beansprucht normalerweise mehr Speicher, insbesondere wenn mehrere Ergebnis-Datasets gleichzeitig im Arbeitsspeicher gespeichert sind.
Behandeln Sie beim Abrufen (Polling) die seltenen Fälle, in denen eine Abfrage nicht erfolgreich ist.
Stellen Sie sicher, dass Anweisungen zur Transaktionssteuerung (BEGIN, COMMIT und ROLLBACK) nicht parallel zu anderen Anweisungen ausgeführt werden.
Beachten Sie, dass nicht garantiert werden kann, dass asynchrone Abfragen geordnete Ergebnisse liefern, selbst wenn die SQL selbst über eine ORDER BY-Klausel verfügt. Folglich garantiert die Funktion
result_scankeine geordneten Ergebnisse.
Abrufen der Snowflake-Abfrage-ID¶
Eine Abfrage-ID kennzeichnet jede von Snowflake ausgeführte Abfrage. Wenn Sie den Snowflake-Konnektor für Python zum Ausführen einer Abfrage verwenden, können Sie auf die Abfrage-ID über das Attribut sfqid im Cursor-Objekt zugreifen:
Sie können die Abfrage-ID für Folgendes verwenden:
Überprüfen des Status von Abfragen über die Weboberfläche.
Auf der Snowsight werden Abfrage-IDs auf der Seite Query History angezeigt. Siehe Abfrageaktivität mit Abfrageverlauf überwachen.
Programmgesteuertes Prüfen des Status einer Abfrage (z. B. um festzustellen, ob eine asynchrone Abfrage abgeschlossen ist).
Abrufen der Ergebnisse einer asynchronen Abfrage oder einer zuvor übermittelten synchronen Abfrage.
Siehe Verwenden der Abfrage-ID zum Abrufen von Abfrageergebnissen.
Abbrechen einer in Ausführung befindlichen Abfrage.
Überprüfen des Status einer Abfrage¶
So überprüfen Sie den Status einer Abfrage:
Rufen Sie die Abfrage-ID aus dem Feld
sfqidim ObjektCursorab.Übergeben Sie die Abfrage-ID an die Methode
get_query_status()desConnection-Objekts, um die EnumerationskonstanteQueryStatuszurückzugeben, die den Status der Abfrage darstellt.Standardmäßig löst
get_query_status()keinen Fehler aus, wenn die Abfrage zu einem Fehler geführt hat. Wenn Sie möchten, dass ein Fehler ausgelöst wird, rufen Sie stattdessenget_query_status_throw_if_error()auf.Verwenden Sie die Enumerationskonstante
QueryStatus, um den Status der Abfrage zu überprüfen.Um festzustellen, ob die Abfrage noch ausgeführt wird (z. B. wenn es sich um eine asynchrone Abfrage handelt), übergeben Sie die Konstante an die Methode
is_still_running()desConnection-Objekts.Um festzustellen, ob ein Fehler aufgetreten ist, übergeben Sie die Konstante an die Methode
is_an_error().
Eine vollständige Liste der Enumerationskonstanten erhalten Sie mit
QueryStatus.
Im folgenden Beispiel wird eine asynchrone Abfrage ausgeführt und der Status der Abfrage überprüft:
Im folgenden Beispiel wird ein Fehler ausgelöst, wenn die Abfrage zu einem Fehler geführt hat:
Verwenden der Abfrage-ID zum Abrufen von Abfrageergebnissen¶
Bemerkung
Wenn Sie eine synchrone Abfrage ausgeführt haben, indem Sie die Methode execute() für ein Cursor-Objekt aufgerufen haben, ist die Abfrage-ID zum Abrufen der Ergebnisse nicht erforderlich. Sie können einfach die Werte aus den Ergebnissen abrufen, wie unter Verwenden von cursor zum Abrufen von Werten erläutert.
Wenn Sie die Ergebnisse einer asynchronen Abfrage oder einer zuvor übermittelten synchronen Abfrage abrufen möchten, führen Sie die folgenden Schritte aus:
Rufen Sie die Abfrage-ID der Abfrage ab. Siehe Abrufen der Snowflake-Abfrage-ID.
Rufen Sie die Methode
get_results_from_sfqid()imCursor-Objekt auf, um die Ergebnisse abzurufen.Verwenden Sie das
Cursor-Objekt, um die Werte in den Ergebnissen abzurufen, wie unter Verwenden von cursor zum Abrufen von Werten erläutert.
Falls die Abfrage noch ausgeführt wird, müssen Sie beachten, dass die Fetch-Methoden (fetchone(), fetchmany(), fetchall() usw.) auf den Abschluss der Abfrage warten.
Beispiel:
Verwenden von cursor zum Abrufen von Werten¶
Rufen Sie Werte aus einer Tabelle mit der Cursorobjektiterator-Methode ab.
Um beispielsweise Spalten mit dem Namen „col1“ und „col2“ aus der zuvor mit testtable erstellten Tabelle (siehe Erstellen von Tabellen und Einfügen von Daten) abzurufen, verwenden Sie Code, der dem folgenden ähnelt:
Alternativ bietet der Snowflake-Konnektor für Python ein abgekürztes Verfahren:
Wenn Sie ein einzelnes Ergebnis (d. h. eine einzelnen Zeile) erhalten möchten, verwenden Sie die Methode fetchone:
Wenn Sie die angegebene Anzahl von Zeilen auf einmal erhalten möchten, verwenden Sie die Methode fetchmany mit der Anzahl der Zeilen:
Bemerkung
Verwenden Sie
fetchoneoderfetchmany, wenn das Resultset zu groß für den verfügbaren Speicher ist.
Wenn Sie alle Ergebnisse auf einmal erhalten müssen:
Um ein Zeitlimit (Timeout) für eine Abfrage festzulegen, führen Sie einen „begin“-Befehl aus, und fügen Sie einen Timeout-Parameter in die Abfrage ein. Wenn die Abfrage die Zeitdauer des Parameterwertes überschreitet, wird ein Fehler generiert und ein Rollback durchgeführt.
Im folgenden Code bedeutet der Fehler 604, dass die Abfrage abgebrochen wurde. Der Timeout-Parameter startet Timer() und bricht ab, wenn die Abfrage nicht innerhalb der angegebenen Zeit beendet wird.
Verwenden von DictCursor zum Abrufen von Werten nach Spaltenname¶
Wenn Sie einen Wert anhand des Spaltennamens abrufen möchten, erstellen Sie ein cursor-Objekt vom Typ DictCursor.
Beispiel:
Beispiele für asynchrone Abfragen¶
Im Folgenden finden Sie ein einfaches Beispiel für eine asynchrone Abfrage:
Im nächsten Beispiel wird eine asynchrone Abfrage von einer Verbindung aus übermittelt und das Ergebnis von einer anderen Verbindung aus abgerufen:
Abbrechen einer Abfrage über die Abfrage-ID¶
So brechen Sie eine Abfrage über die Abfrage-ID ab:
Ersetzen Sie die Zeichenfolge „queryID“ durch die tatsächliche Abfrage-ID. Um die ID für eine Abfrage zu erhalten, siehe Abrufen der Snowflake-Abfrage-ID.
Verbessern der Abfrageleistung durch Umgehen der Datenkonvertierung¶
Verwenden Sie zur Verbesserung der Abfrageleistung die Klasse SnowflakeNoConverterToPython im Modul snowflake.connector.converter_null, um die Datenkonvertierung vom internen Snowflake-Datentyp in den systemeigenen Python-Datentyp zu umgehen, z. B.:
Im Ergebnis werden alle Daten als Zeichenfolgen dargestellt, sodass die Anwendung für die Konvertierung in die systemeigenen Python-Datentypen verantwortlich ist. Beispielsweise sind TIMESTAMP_NTZ- und TIMESTAMP_LTZ-Daten die als Zeichenfolgen dargestellte Epochenzeit, und TIMESTAMP_TZ-Daten sind die Epochenzeit, gefolgt von einem Leerzeichen, gefolgt vom Offset zu UTC in Minuten, dargestellt als Zeichenfolge.
Das Binden der Daten wird nicht beeinflusst. Python-native Daten können weiterhin für Updates gebunden werden.
Herunterladen von Daten¶
Snowflake Connector für Python Version 3.14.0 hat den Verbindungsparameter unsafe_file_write eingeführt, der angibt, wie der Konnektor die Dateiberechtigungen beim Herunterladen von Dateien für einen Stagingbereich von Snowflake mit dem Befehl GET setzen soll. Diese Dateien sind immer im Besitz desselben Benutzers, der den Python-Prozess ausführt.
Standardmäßig lautet der Parameter unsafe_file_writeFalse, da so eine sicherere und strengere 600-Dateiberechtigung möglich ist, was bedeutet, dass nur der Eigentümer die Lese- und Schreibberechtigung für die heruntergeladenen Dateien hat. Andere Gruppen und Benutzer haben keine Berechtigungen für die mit dem GET-Befehl heruntergeladenen Dateien.
Wenn Ihre Organisation weniger restriktive Dateiberechtigungen für die Dateien verlangt, können Sie den Parameter unsafe_file_write auf True setzen. Wenn Sie diesen Parameter aktivieren, werden die Dateiberechtigungen für die von einem Stagingbereich heruntergeladenen Dateien auf 644 gesetzt, sodass der Eigentümer die Dateien lesen und schreiben kann, andere jedoch nur lesen dürfen. Diese Einstellung kann z. B. für einige ETL-Tools notwendig sein, die unter einem anderen Systembenutzer ausgeführt werden, der die heruntergeladenen Dateien lesen und verarbeiten können muss.
Wenn Sie sich nicht sicher sind, welchen Wert Sie verwenden sollen, wenden Sie sich an das Team, das für die geltenden Sicherheitsrichtlinien Ihres Unternehmens zuständig ist.
Binden von Daten¶
Um Werte anzugeben, die in einer SQL-Anweisung verwendet werden sollen, können Sie Literale in die Anweisung einschließen oder Variablen binden. Wenn Sie Variablen binden, fügen Sie einen oder mehrere Platzhalter in den Text der SQL-Anweisung ein, und geben Sie dann für jeden Platzhalter die Variable (den zu verwendenden Wert) an.
Im folgenden Beispiel wird die Verwendung von Literalen und die Bindung gegenübergestellt:
Literale:
Bindung:
Bemerkung
Es gibt eine Obergrenze für die Datengröße, die Sie binden oder in einem Batch kombinieren können. Weitere Details dazu finden Sie unter Begrenzung der Abfragetextgröße.
Snowflake unterstützt die folgenden Bindungstypen:
pyformatundformat, die Daten auf dem Client binden.qmarkundnumeric, die Daten auf dem Server binden.
Jeder Typ wird unten erklärt.
pyformat- oder format-Bindung¶
Sowohl die pyformat-Bindung als auch die format-Bindung binden Daten auf der Clientseite und nicht auf der Serverseite.
Standardmäßig unterstützt der Snowflake-Konnektor für Python sowohl pyformat als auch format, sodass Sie %(name)s oder %s als Platzhalter verwenden können. Beispiel:
Verwenden von
%(name)sals Platzhalter:Verwenden von
%sals Platzhalter:
Mit pyformat und format können Sie auch ein Listenobjekt verwenden, um Daten für den IN-Operator zu binden:
Das Prozentzeichen („%“) ist sowohl ein Platzhalterzeichen für SQL LIKE als auch ein Formatbindungszeichen für Python. Wenn Sie die Formatbindung verwenden und Ihr SQL-Befehl das Prozentzeichen enthält, müssen Sie möglicherweise das Prozentzeichen maskieren. Wenn Ihre SQL-Anweisung beispielsweise wie folgt lautet:
Dann sollte Ihr Python-Code wie folgt aussehen (beachten Sie das zusätzliche Prozentzeichen, um das ursprüngliche Prozentzeichen zu umgehen):
qmark- oder numeric-Bindung¶
Sowohl die qmark-Bindung als auch die numeric-Bindung binden Daten eher auf der Serverseite als auf der Clientseite:
Verwenden Sie für die
qmark-Bindung ein Fragezeichenzeichen (?), um anzugeben, an welcher Stelle in der Zeichenfolge der Wert einer Variablen eingefügt werden soll.Verwenden Sie für die
numeric-Bindung einen Doppelpunkt (:), gefolgt von einer Zahl, mit der die Position der Variablen angegeben wird, die an dieser Position ersetzt werden soll. So gibt beispielsweise:2die zweite Variable an.Verwenden Sie die numerische Bindung, um denselben Wert mehr als einmal in derselben Abfrage zu binden. Wenn Sie z. B. einen langen VARCHAR- oder BINARY- oder semistrukturierten Wert haben, den Sie mehr als einmal verwenden möchten, dann können Sie mit der
numeric-Bindung den Wert einmal an den Server senden und ihn mehrfach verwenden.
In den nächsten Abschnitten wird erklärt, wie Sie qmark- und numeric-Bindung verwenden:
Verwenden von qmark- oder numeric-Bindung¶
Um eine Stilbindung von qmark oder numeric zu verwenden, können Sie entweder eine der folgenden Schritte ausführen oder paramstyle als Teil der Parameter für die Verbindung beim Aufruf von connect() einstellen.
snowflake.connector.paramstyle='qmark'snowflake.connector.paramstyle='numeric'
Wenn Sie paramstyle auf qmark oder numeric setzen, müssen Sie ? oder :N (wobei N durch eine Zahl ersetzt wird) als Platzhalter verwenden.
Beispiel:
Verwenden von
?als Platzhalter:Verwenden von
:Nals Platzhalter:Die folgende Abfrage zeigt die Verwendung der
numeric-Bindung zur Wiederverwendung einer Variablen:
Verwenden von qmark- oder numeric-Bindung mit datetime-Objekten¶
Wenn Sie die Bindung qmark oder numeric verwenden, um Daten an einen Snowflake-Datentyp TIMESTAMP zu binden, setzen Sie die Bindungsvariable auf ein Tupel, das den Datentyp des Snowflake-Zeitstempels (TIMESTAMP_LTZ oder TIMESTAMP_TZ) und den Wert angibt. Beispiel:
Im Gegensatz zur clientseitigen Bindung benötigt die serverseitige Bindung den Snowflake-Datentyp für die Spalte. Die meisten gängigen Python-Datentypen weisen bereits implizite Zuordnungen zu Snowflake-Datentypen auf (z. B. int ist FIXED zugeordnet). Da die Python-datetime-Daten jedoch an einen von mehreren Snowflake-Datentypen (TIMESTAMP_NTZ, TIMESTAMP_LTZ oder TIMESTAMP_TZ) gebunden sein können und die Standardzuordnung TIMESTAMP_NTZ ist, müssen Sie den zu verwendenden Snowflake-Datentyp angeben.
Verwenden von Bindungsvariablen mit dem IN-Operator¶
qmark und numeric (serverseitige Bindung) unterstützen nicht die Verwendung von Bindungsvariablen mit dem IN-Operator.
Wenn Sie Bindungsvariablen mit dem IN-Operator verwenden müssen, verwenden Sie clientseitige Bindung (pyformat oder format).
Binden von Parametern an Variablen für Batcheinfügungen¶
In Ihrem Anwendungscode können Sie mehrere Zeilen in einen einzelnen Batch einfügen. Verwenden Sie dazu Parameter für Werte in einer INSERT-Anweisung. In der folgenden Anweisung werden z. B. Platzhalter für qmark-Bindungen in einer INSERT-Anweisung verwendet:
Zum Spezifizieren der einzufügenden Daten definieren Sie dann eine Variable, die eine Sequenz von Sequenzen ist (z. B. eine Liste von Tupeln):
Wie im obigen Beispiel gezeigt, ist jedes Element in der Liste ein Tupel, das die Spaltenwerte für eine einzufügende Zeile enthält.
Um die Bindung durchzuführen, rufen Sie die Methode executemany() auf und übergeben die Variable als zweites Argument. Beispiel:
Durch Binden von Daten auf dem Server (d. h. mittels qmark- oder numeric-Bindung) kann der Konnektor die Leistung von Batcheinfügungen optimieren.
Wenn Sie dieses Verfahren verwenden, um eine große Anzahl von Werten einzufügen, kann die Treiberleistung verbessert werden, indem die Daten (ohne Erstellen von Dateien auf dem lokalen Computer) an einen temporären Stagingbereich gestreamt werden. Der Treiber führt dies automatisch durch, wenn die Anzahl der Werte einen Schwellenwert überschreitet.
Außerdem müssen die aktuelle Datenbank und das aktuelle Schema für die Sitzung festgelegt sein. Wenn diese nicht festgelegt sind, kann der vom Treiber ausgeführte CREATE TEMPORARY STAGE-Befehl folgenden Fehler generieren:
Bemerkung
Alternative Möglichkeiten zum Laden von Daten in die Snowflake-Datenbank (einschließlich Massenladen mit dem COPY-Befehl) finden Sie unter Daten in Snowflake laden.
Angriffe durch Einschleusung von SQL-Befehlen verhindern¶
Binden Sie Daten nicht mit der Formatierungsfunktion von Python, da Sie eine Einschleusung von SQL-Befehlen riskieren. Beispiel:
Speichern Sie stattdessen die Werte in Variablen, und binden Sie diese Variablen dann mit qmark oder einem numerischen Bindungsformat ein.
Abrufen von Spaltenmetadaten¶
Für das Abrufen der Metadaten jeder Spalte im Resultset abzurufen (z. B. Name, Typ, Genauigkeit, Skala usw. jeder Spalte) gibt es folgende Möglichkeiten:
Nach dem Aufruf der Methode
execute()zur Ausführung der Abfrage können Sie mit dem AttributdescriptiondesCursor-Objekts auf die Metadaten zuzugreifen.Wenn Sie auf die Metadaten zugreifen möchten, ohne eine Abfrage ausführen zu müssen, rufen Sie die Methode
describe()auf.Die Methode
describeist im Snowflake-Konnektor für Python ab Version 2.4.6 verfügbar.
Das Attribut description wird auf einen der folgenden Werte gesetzt:
Version 2.4.5 und früher: Eine Liste von Tupeln.
Versionen 2.4.6 und später: Eine Liste von ResultMetadata-Objekten. (Die Methode
describegibt ebenfalls diese Liste zurück.)
Jedes Tupel- und ResultMetadata-Objekt enthält die Metadaten zu einer Spalte (Spaltenname, Datentyp usw.). Sie können auf die Metadaten über den Index zugreifen oder ab Version 2.4.6 auch über das Attribut ResultMetadata.
Die folgenden Beispiele zeigen, wie Sie auf die Metadaten der zurückgegebenen Tupel und ResultMetadata-Objekte zugreifen können.
Beispiel: Abrufen der Spaltennamen-Metadaten nach Index (ab Version 2.4.5):
Im folgenden Beispiel wird das Attribut description verwendet, um die Liste der Spaltennamen nach der Ausführung einer Abfrage abzurufen. Das Attribut ist eine Liste von Tupeln. Das Beispiel greift auf den Spaltennamen des ersten Wertes in jedem Tupel zu.
Beispiel: Abrufen der Spaltennamen-Metadaten nach Attribut (ab Version 2.4.6):
Im folgenden Beispiel wird das Attribut description verwendet, um die Liste der Spaltennamen nach der Ausführung einer Abfrage abzurufen. Das Attribut ist eine Liste von ResultMetaData-Objekten. Das Beispiel greift auf den Spaltennamen aus dem Attribut name jedes ResultMetadata-Objekts zu.
Beispiel: Abrufen der Spaltennamen-Metadaten ohne Ausführen der Abfrage (ab Version 2.4.6):
Das folgende Beispiel verwendet die Methode describe, um die Liste der Spaltennamen abzurufen, ohne eine Abfrage ausführen zu müssen. Die Methode describe() gibt eine Liste von ResultMetaData-Objekten zurück. Das Beispiel greift auf den Spaltennamen aus dem Attribut name jedes ResultMetadata-Objekts zu.
Fehlerbehandlung¶
Die Anwendung muss auf Ausnahmen, die vom Snowflake-Konnektor ausgelöst werden, korrekt reagieren und entscheiden, ob die Codeausführung fortgesetzt oder abgebrochen wird.
Verwenden von execute_stream zum Ausführen von SQL-Skripten¶
Mit der Funktion execute_stream können Sie ein oder mehrere SQL-Skripte in einem Stream ausführen:
Bemerkung
Eine zusätzliche Konfiguration kann erforderlich sein, wenn sql_stream Kommentare enthält. Siehe Verwendung von execute_stream zur Ausführung von SQL-Skripten.
Schließen der Verbindung¶
Als Best Practice schließen Sie die Verbindung, indem Sie die Methode close aufrufen:
Dadurch wird sichergestellt, dass die gesammelten Clientmetriken an den Server übermittelt werden und die Sitzung gelöscht wird. Außerdem helfen try-finally Blöcke sicherzustellen, dass die Verbindung geschlossen wird, auch wenn mittendrin eine Ausnahme ausgelöst wird:
Vorsicht
Mehrere nicht geschlossene Verbindungen können Ihre Systemressourcen erschöpfen und schließlich zu einem Absturz der Anwendung führen.
Verwenden eines Kontextmanagers zum Verbinden und Steuern von Transaktionen¶
Der Snowflake-Konnektor für Python unterstützt einen Kontextmanager, der bei Bedarf Ressourcen zuweist und freigibt. Der Kontextmanager ist nützlich, um für Transaktionen auf Basis des Anweisungsstatus ein Commit oder ein Rollback auszuführen, wenn autocommit deaktiviert ist.
Im obigen Beispiel führt der Kontextmanager nach Fehlschlagen der dritten Anweisung ein Rollback der Änderungen in der Transaktion aus und schließt die Verbindung. Wenn alle Anweisungen erfolgreich waren, würde der Kontextmanager die Änderungen committen und die Verbindung schließen.
Der äquivalente Code mit try- und except-Blöcken ist wie folgt:
Verwenden des Datentyps VECTOR¶
Unterstützung für den Datentyp VECTOR Datentyp wurde in Version 3.6.0 des Snowflake Connector für Python eingeführt. Sie können den Datentyp VECTOR mit den Vektorähnlichkeitsfunktionen verwenden, um Anwendungen zu implementieren, die auf Vektorsuche oder Retrieval-Augmented-Generation basieren (RAG).
Das folgende Codebeispiel zeigt, wie Sie den Python-Konnektor verwenden, um Tabellen mit VECTOR-Spalten zu erstellen und die Funktion VECTOR_INNER_PRODUCT aufzurufen:
Das folgende Codebeispiel zeigt, wie Sie den Python-Konnektor verwenden, um die Funktion VECTOR_COSINE_SIMILARITY aufzurufen, um die nächstgelegenen Vektoren zu [1,2,3] zu finden:
Bemerkung
Variable Bindungen werden für VECTOR-Datentypen nicht unterstützt.
Protokollieren¶
Der Snowflake-Konnektor für Python nutzt das logging-Standardmodul von Python, um den Status in regelmäßigen Abständen zu protokollieren, sodass die Anwendung ihre Aktivitäten im Hintergrund verfolgen kann. Der einfachste Weg, die Protokollierung zu aktivieren, ist der Aufruf von logging.basicConfig() am Anfang der Anwendung.
Im folgenden Beispiel wird der Protokolliergrad auf INFO eingestellt, und die Protokolle werden in einer Datei namens /tmp/snowflake_python_connector.log gespeichert.
Eine umfassendere Protokollierung kann durch Einstellen des Protokolliergrads auf DEBUG wie folgt aktiviert werden:
Die optionale, aber empfohlene Formatierungsklasse SecretDetector stellt sicher, dass ein bestimmter Satz bekannter vertraulicher Informationen maskiert wird, bevor diese in die Protokolldateien des Python-Konnektors von Snowflake geschrieben werden. Verwenden Sie für SecretDetector folgenden Code:
Bemerkung
botocoreundboto3sind über das AWS (Amazon Web Services) SDK für Python verfügbar.
Protokollierungskonfigurationsdatei¶
Alternativ können Sie den Protokolliergrad und das Verzeichnis, in dem die Protokolldateien gespeichert werden sollen, auch einfach in der Konfigurationsdatei config.toml angeben. Weitere Informationen zu dieser Datei finden Sie unter Verbinden mit der Datei connections.toml.
Bemerkung
Dieses Feature zur Konfiguration der Protokollierung unterstützt die Protokolliergrade, die im Python-Protokollierungsdokument definiert sind.
Weitere Informationen zu Protokolliergraden finden Sie im Basic Logging Tutorial von Python.
Diese Protokollierungskonfigurationsdatei verwendet toml, um die Protokollierungsparameter save_logs, level und path wie folgt zu definieren:
Wobei:
save_logsbestimmt, ob Protokolle gespeichert werden sollen.levelgibt den Protokolliergrad an. Wenn nicht definiert, ist der Treiber standardmäßig aufINFOeingestellt.pathbezeichnet das Verzeichnis, in dem die Protokolldateien gespeichert werden sollen. Wenn nicht definiert, speichert der Treiber die Protokolle im Standardverzeichnis$SNOWFLAKE_HOME/logs/.
Bemerkung
Wenn Ihre config.toml-Datei keinen Abschnitt [log] enthält, werden die Protokollmeldungen nicht gespeichert.
Die Protokollmeldungen eines einzelnen Tages werden an die Datei python-connector.log angehängt, die später in python-connector.log.YYYY-MM-DD umbenannt wird.
Beispielprogramm¶
Der folgende Beispielcode kombiniert die meisten der in den vorangegangenen Abschnitten beschriebenen Beispiele zu einem funktionierenden Python-Programm: Dieses Beispiel enthält zwei Teile:
Eine übergeordnete Klasse („python_veritas_base“) enthält den Code für viele gängige Operationen, z. B. das Herstellen einer Verbindung zum Server.
Eine untergeordnete Klasse („python_connector_example“) repräsentiert die kundenspezifischen Teile eines bestimmten Clients, z. B. zum Abfragen einer Tabelle.
Dieser Beispielcode wird direkt aus einem unserer Tests importiert, um sicherzustellen, dass er in einem neueren Build des Produkts ausgeführt wurde.
Da dies aus einem Test stammt, enthält es eine kleine Menge Code, um einen alternativen Port und ein alternatives Protokoll festzulegen, die in einigen Tests verwendet werden. Benutzer sollten Protokoll oder Portnummer nicht festlegen. Lassen Sie diese Werte stattdessen aus, und verwenden Sie die Standardeinstellungen.
Dies enthält auch einige Abschnittsmarkierungen (manchmal als „Snippet-Tags“ bezeichnet), um Code zu identifizieren, der unabhängig in die Dokumentation importiert werden kann. Abschnittsmarkierungen sehen normalerweise ähnlich aus wie:
Diese Abschnittsmarkierungen sind im Benutzercode nicht erforderlich.
Der erste Teil des Codebeispiels enthält die allgemeinen Unterroutinen für:
Lesen Sie Befehlszeilenargumente (z. B. „–warehouse MyWarehouse“), die Verbindungsinformationen enthalten.
Stellen Sie eine Verbindung zum Server her.
Erstellen und verwenden Sie ein Warehouse, eine Datenbank und ein Schema.
Löschen Sie das Schema, die Datenbank und das Warehouse, wenn Sie damit fertig sind.
Der zweite Teil des Codebeispiels erstellt eine Tabelle, fügt Zeilen ein usw.:
Gehen Sie folgendermaßen vor, um dieses Beispiel auszuführen:
Kopieren Sie den ersten Teil des Codes in eine Datei mit dem Namen „python_veritas_base.py“.
Kopieren Sie den zweiten Teil des Codes in eine Datei mit dem Namen „python_connector_example.py“.
Setzen Sie die Umgebungsvariable SNOWSQL_PWD auf Ihr Kennwort, zum Beispiel:
Führen Sie das Programm über eine Befehlszeile ähnlich der folgenden aus (ersetzen Sie die Benutzer- und Kontoinformationen natürlich durch Ihre eigenen Benutzer- und Kontoinformationen).
Warnung
Dies löscht das Warehouse, die Datenbank und das Schema am Ende des Programms! Verwenden Sie nicht den Namen einer vorhandenen Datenbank, da Sie diese verlieren werden!
Und hier ist die Ausgabe:
Hier ist ein längeres Beispiel:
Bemerkung
Achten Sie darauf, dass Sie in dem Abschnitt, in dem Sie Ihre Konto- und Anmeldeinformationen festlegen, die Variablen bei Bedarf so ersetzen, dass sie Ihren Snowflake-Anmeldeinformationen (Name, Kennwort usw.) entsprechen.
In diesem Beispiel wird die Anweisung mit der Funktion format() zusammengestellt. Wenn in Ihrer Umgebung das Risiko von Angriffen durch Einschleusung von SQL-Befehlen besteht, sollten Sie möglicherweise das Binden von Werten vorziehen, anstatt format() zu verwenden.