ML Observability: monitoramento do comportamento do modelo ao longo do tempo¶
O comportamento do modelo pode mudar com o tempo devido a desvios de entrada, suposições de treinamento obsoletas e problemas de pipeline de dados, além dos fatores usuais, incluindo alterações no hardware e software subjacentes e a natureza fluida do tráfego. O ML Observability permite que você acompanhe a qualidade dos modelos de produção implantados por meio do Snowflake Model Registry em várias dimensões, como desempenho, desvio e volume. Além disso, ele permite monitorar o desempenho do modelo em diferentes segmentos de seus dados usando colunas categóricas de cadeia de caracteres.
Atualmente, o monitor de modelos suporta modelos de regressão e classificação binária.
Nota
Para se aprofundar e começar a usar o ML Observability, consulte o guia de início rápido.
Fluxo de trabalho do ML Observability¶
Quando você usa um modelo que foi registrado no Snowflake Model Registry para inferência, receberá resultados na forma de um Snowpark ou pandas DataFrame, dependendo do tipo de entrada DataFrame passada para o método de inferência. Esses dados normalmente se originam no Snowflake. Mesmo nos casos em que a inferência é executada fora do Snowflake, é comum armazenar os resultados no Snowflake. O ML Observability permite que você monitore o desempenho do seu modelo em ambos os cenários, trabalhando com os dados de inferência armazenados. O fluxo de trabalho típico é mostrado abaixo.
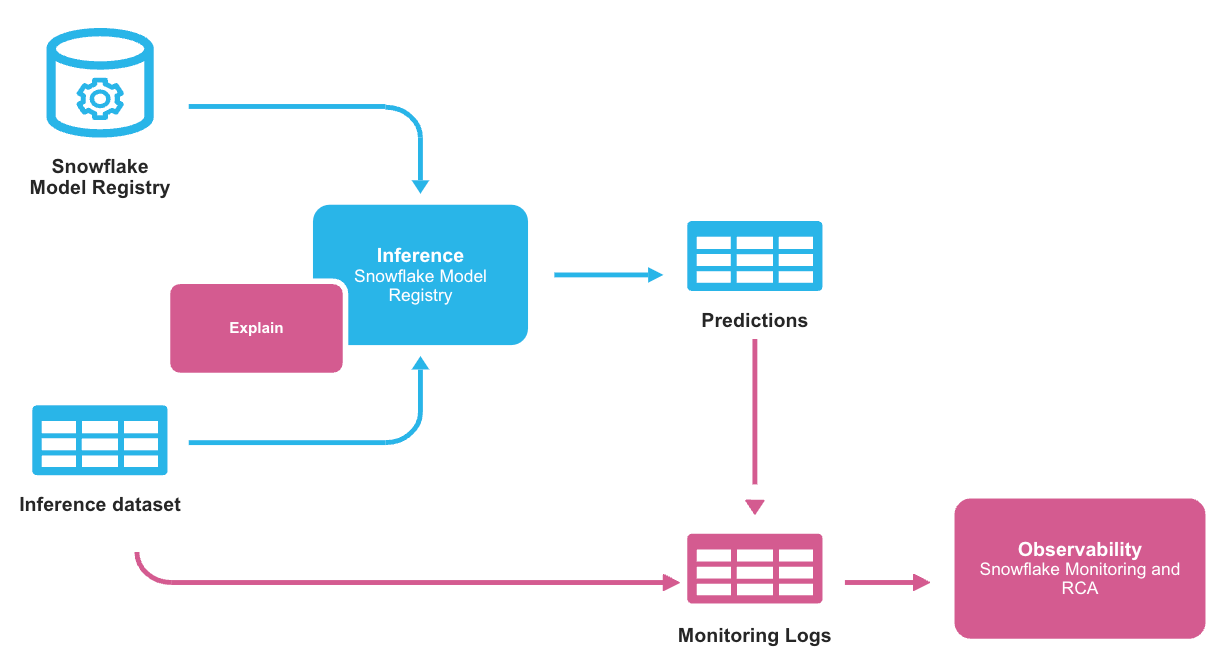
Os registros de monitoramento armazenam os dados de inferência e as previsões para que o recurso ML Observability possa observar as alterações nas previsões ao longo do tempo. Os registros de monitoramento são armazenados em uma tabela que contém um ID, um carimbo de data/hora, recursos, previsões e um rótulo de verdade básica, que indica se uma determinada linha é uma previsão ou dados observados. A estrutura básica é mostrada abaixo.
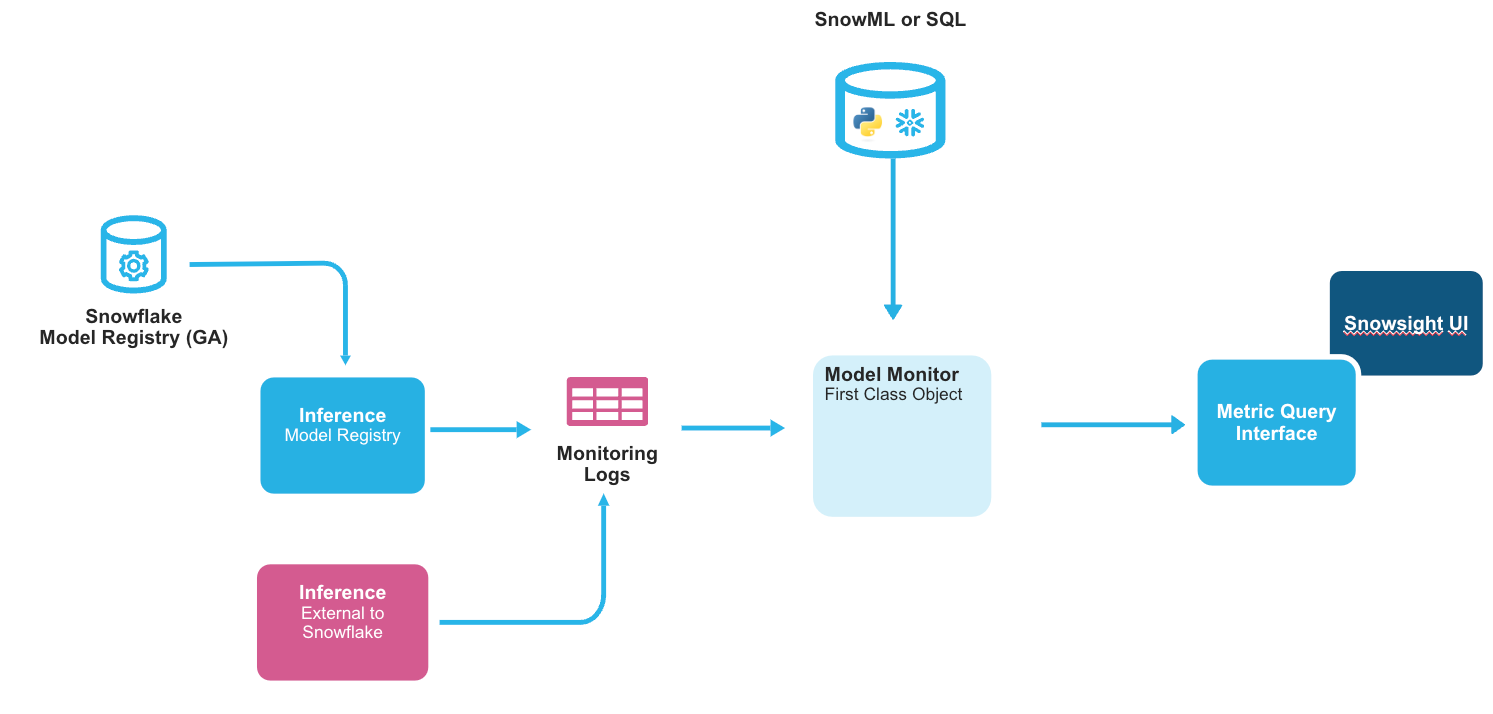
Você deve criar explicitamente um objeto de monitor de modelo para cada versão de modelo que deseja monitorar. Cada versão de modelo pode ter exatamente um monitor, e cada monitor pode monitorar exatamente uma versão de modelo; eles não podem ser compartilhados. O objeto monitor atualiza automaticamente os logs do monitor consultando os dados de origem e atualiza os relatórios de monitoramento com base nos logs.
Cada monitor encapsula as seguintes informações:
A versão do modelo a ser monitorada.
A tabela na qual os logs do monitor são armazenados.
A granularidade mínima de tempo em que os dados são armazenados (janela de agregação), atualmente com um mínimo de 1 dia.
Uma tabela de linha de base opcional para operações de métrica comparativa, como desvio.
Pré-requisitos¶
Antes de começar, certifique-se de ter o seguinte:
Uma conta Snowflake.
Versão 1.7.1 ou posterior do pacote Python
snowflake-ml-python.Familiaridade com o Snowflake Model Registry.
Criação de um monitor de modelo¶
Crie um monitor de modelo usando o comando CREATE MODEL MONITOR. O monitor de modelo deve ser criado no mesmo esquema que a versão do modelo a ser monitorada. Você deve ter o privilégio CREATE MODEL MONITOR no esquema em que o monitor é criado. Você pode criar um máximo de 250 monitores de modelo por conta.
Consulte CREATE MODEL MONITOR para obter mais detalhes sobre o comando CREATE MODEL MONITOR.
Dica
Para obter detalhes sobre outros comandos de SQL que você pode usar com monitores de modelos, consulte Comandos de monitoramento de modelo.
Como interromper e retomar temporariamente o monitoramento¶
Você pode suspender (parar temporariamente) um monitor de modelo usando ALTER MODEL MONITOR… SUSPEND. Para retomar o monitoramento, emita ALTER MODEL MONITOR… RESUME.
Suspensão automática em caso de falha de atualização¶
Os monitores de modelo suspendem automaticamente as atualizações quando encontram cinco falhas consecutivas de atualização relacionadas às tabelas de origem. Você pode visualizar o status e a causa da suspensão da atualização usando o comando DESCRIBE MODEL MONITOR. A saída inclui as seguintes colunas, entre outras:
aggregation_status: o valor dessa coluna é um objeto JSON. Um ou mais dos valores desse objeto serão SUSPENDED se o monitor de modelo for suspenso.aggregation_last_error: o valor dessa coluna é um objeto JSON que contém o erro específico de SQL que causou a suspensão.
Depois de resolver a causa raiz da falha de atualização, retome o monitor emitindo ALTER MODEL MONITOR… RESUME.
Adição de segmentos a um monitor de modelos¶
Os monitores de modelos oferecem suporte à segmentação, o que permite acompanhar a qualidade do modelo ao longo do tempo para subconjuntos específicos de seus dados, assim como para o conjunto de dados completo. Os segmentos são usados para agrupar os dados em unidades lógicas, como diferentes regiões ou grupos de usuários.
Criação de monitores com segmentos¶
Ao criar um monitor de modelos, é possível especificar colunas de segmento usando o parâmetro SEGMENT_COLUMNS. As colunas de segmento devem ser colunas de cadeia de caracteres em seus dados de origem.
Importante
Para criar segmentos em colunas numéricas, compacte-os em buckets com categorias válidas antes de criar o monitor. Por exemplo, você pode transformar uma coluna numérica TEMPERATURE em valores categóricos como “COLD” (< 32°F), “MODERATE” (32-80°F), and “HOT” (> 80ºF) antes de usá-la como uma coluna de segmento.
CREATE [OR REPLACE] MODEL MONITOR [IF NOT EXISTS] <NAME> WITH
--- all other existing parameters of CREATE MODEL MONITOR
SEGMENT_COLUMNS = (<segment_column_name_array>)
Para obter detalhes completos sobre sintaxe e parâmetro , consulte CREATE MODEL MONITOR.
Adição de segmentos a monitores novos ou existentes¶
Você pode adicionar colunas de segmento a monitores existentes usando o comando ALTER MODEL MONITOR:
ALTER MODEL MONITOR <NAME> ADD SEGMENT_COLUMN = <segment_column_name>
Você também pode remover colunas de segmentos de monitores existentes:
ALTER MODEL MONITOR <NAME> DROP SEGMENT_COLUMN = <segment_column_name>
Para saber a sintaxe completa e opções, consulte ALTER MODEL MONITOR.
Definição do segmento no monitoramento de segmentos na UI¶
Você pode configurar e gerenciar segmentos por meio das configurações de monitoramento de segmentos na UI:
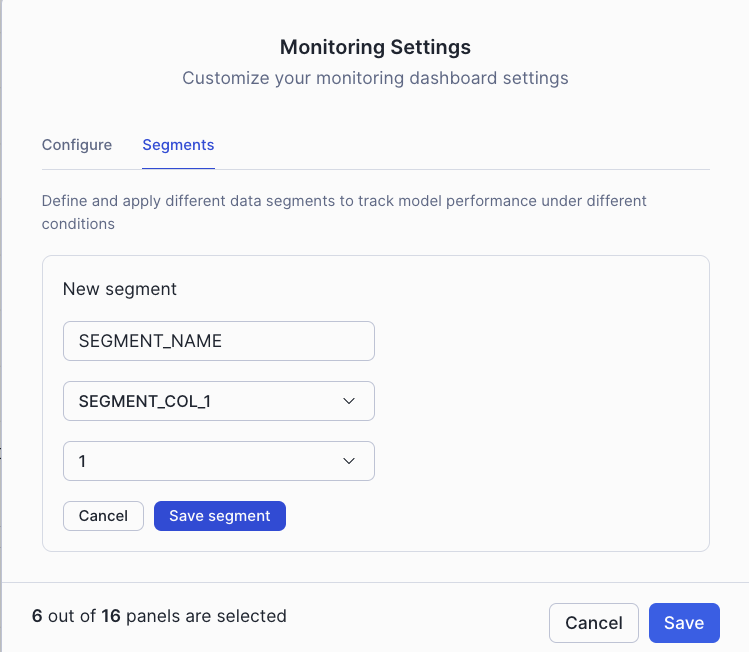
A interface de configurações de segmentos permite definir e configurar quais segmentos monitorar para seu modelo.
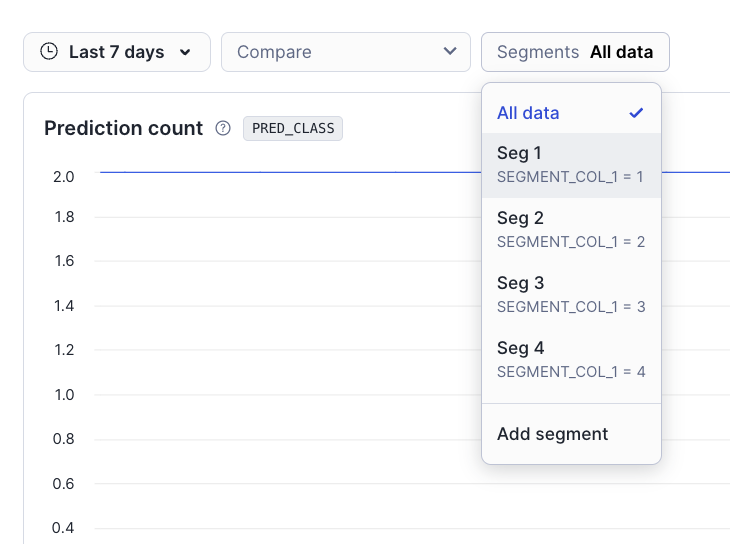
Use o seletor de segmentos no painel do monitor de modelos¶
No painel do monitor de modelos, é possível usar o seletor de segmentos para exibir métricas para segmentos específicos de seus dados:
Considerações de desempenho para segmentos¶
O desempenho depende de muitos fatores, como número de recursos, número de colunas de segmentos, valores exclusivos por coluna de segmentos, tamanho e tipo do warehouse, janela de agregação, total de linhas e linhas por janela de agregação.
O impacto do CREATE com SEGMENT_COLUMNS no desempenho é diretamente proporcional ao número de colunas de segmentos na solicitação
Se o desempenho do CREATE estiver lento com muitas colunas de segmento, considere adicionar uma coluna de segmentos por vez usando o comando ALTER
Cada combinação de coluna de segmentos e valor é consultada de forma independente, e pode haver diferenças no horário da última atualização com base em agendamento e outros fatores. Tentamos melhor atualizar todos os dados ao mesmo tempo.
Visualização de relatórios de monitoramento¶
Para visualizar os relatórios do monitor, acesse o painel ML Monitoring no Snowsight. No menu de navegação, selecione AI & ML » Models. A lista resultante contém todos os modelos no Snowflake Model Registry em todos os bancos de dados e esquemas aos quais sua função atual tem acesso.
Abra a página de detalhes de um modelo selecionando a linha correspondente na lista Models. A página de detalhes exibe as principais informações do modelo, incluindo a descrição do modelo, as tags, as versões e os monitores.
A lista Monitors na página de detalhes exibe a lista de monitores de modelo, as versões de modelo às quais estão anexados, seu status e quando foram criados.
Abra a página do painel de um monitor de modelo selecionando a linha correspondente na lista Monitores. O painel é preenchido com gráficos que exibem as principais métricas do modelo ao longo do tempo. Os gráficos exatos exibidos dependem do tipo de modelo no qual o monitor se baseia (ou seja, classificação binária ou regressão).
No painel, você pode realizar as seguintes ações:
Alterar o intervalo dos gráficos clicando no seletor de intervalo de tempo.
Alterar os gráficos exibidos clicando no botão Settings. (Passe o mouse sobre o nome de uma métrica para ver mais informações sobre ela)
Comparar os modelos de monitores clicando no menu suspenso do seletor de modelos Compare.
Para exibir mais informações sobre o modelo do monitor, selecione Display monitor details.
Consultar resultados de monitoramento¶
Cada monitor de modelo que você cria tem as seguintes métricas:
Métricas de desvio: alterações na distribuição ou mudanças nos dados
Métricas de desempenho: alterações na distribuição ou mudanças nos dados
Métricas de estatística: contagens ou valores nulos
Para consultar as métricas calculadas pelo monitor, use as funções de métrica do monitor. As funções de métrica obtêm as métricas dos objetos do monitor de modelos. Você pode usar os resultados das funções de métricas para criar painéis personalizados no Streamlit ou em outras ferramentas de monitoramento centralizado.
Importante
Você deve ter os seguintes privilégios para trabalhar com objetos do monitor de modelos:
Comando |
Privilégios obrigatórios |
|---|---|
CREATE MODEL MONITOR |
|
SHOW MODEL MONITORS |
Qualquer privilégio no monitor de modelo |
DESCRIBE MODEL MONITOR |
Qualquer privilégio no monitor de modelo |
ALTER MODEL MONITOR |
MODIFY no monitor de modelo |
DROP MODEL MONITOR |
OWNERSHIP no monitor de modelo |
Use o seguinte template SQL para obter a métrica de desvio do monitor de modelos.
SELECT *
FROM TABLE(MODEL_MONITOR_DRIFT_METRIC (
<model_monitor_name>,
<drift_metric_name>,
<column_name>,
<granularity>,
<start_time>,
<end_time>,
<extra_args>
)
)
Use o seguinte template SQL para obter a métrica de desempenho do monitor de modelos.
SELECT *
FROM TABLE(MODEL_MONITOR_PERFORMANCE_METRIC (
<model_monitor_name>,
<metric_name>,
<granularity>,
<start_time>,
<end_time>,
<extra_args>
)
)
Use o seguinte modelo SQL para obter a métrica estatística do seu monitor de modelos.
SELECT *
FROM TABLE(MODEL_MONITOR_STAT_METRIC (
<model_monitor_name>,
<metric_name>,
<granularity>,
<start_time>,
<end_time>,
<extra_args>
)
)
Consulta de métricas de segmentos específicos¶
Para consultar métricas de segmentos específicos, use o parâmetro <extra_args> parameter with a JSON format that specifies the segment column and value. The <extra_args> é opcional; se ele não tiver sido fornecido, a consulta retornará métricas para todos os dados (consulta não segmentada).
Nota
Atualmente, as consultas de segmento suportam apenas 1 par de coluna:valor por consulta. Não é possível consultar vários segmentos simultaneamente em uma única chamada de função.
Para consultas de segmento, use este formato para o parâmetro <extra_args>:
'{"SEGMENTS": [{"column": "<segment_column_name>", "value": "<segment_value>"}]}'
Por exemplo, para obter métricas de desvio apenas para clientes premium:
SELECT *
FROM TABLE(MODEL_MONITOR_DRIFT_METRIC (
'my_customer_monitor',
'PSI',
'FEATURE_1',
'DAY',
'2024-01-01'::TIMESTAMP_NTZ,
'2024-01-31'::TIMESTAMP_NTZ,
'{"SEGMENTS": [{"column": "CUSTOMER_TIER", "value": "PREMIUM"}]}'
)
)
As tabelas de resultados para consultas de segmentos incluem duas colunas adicionais:
SEGMENT_COLUMN: Nome da coluna do segmento para a qual a métrica é computada (ou NULL para consultas não segmentadas)SEGMENT_VALUE: Valor do segmento para o qual a métrica é computada (ou NULL para consultas não segmentadas)
Para mais informações sobre segmentos, consulte Adição de segmentos a um monitor de modelos.
Você pode configurar alertas e notificações para suas métricas de monitoramento. Para obter mais informações, consulte Alertas e notificações.
Limitações conhecidas¶
As seguintes limitações se aplicam aos monitores de modelo:
Os monitores devem residir no mesmo banco de dados e esquema que a versão do modelo.
Somente modelos de regressão de saída única e de classificação binária são aceitos.
É necessário ter pelo menos uma coluna de previsão (classe ou pontuação); as colunas reais são opcionais, mas necessárias para as métricas de precisão.
O cálculo do desvio requer dados de linha de base; sem eles, para adicionar dados de linha de base, você deve abandonar o monitor e criá-lo novamente.
Cada coluna só pode ser usada uma vez no monitor. Por exemplo, você não pode usar a mesma coluna como o ID de coluna e a coluna de previsão.
Os dados não podem conter valores inválidos (nulos, NaNs, +/-Inf, pontuações de probabilidade fora de 0-1, classes não binárias ou mais de duas classes em uma coluna PREDICTION_CLASS_COLUMNS ) para evitar falha e suspensão do monitor.
As colunas carimbo de data/hora devem ser do tipo
TIMESTAMP_NTZ; as colunas previsão e real devem serNUMBER.Você deve especificar as janelas de agregação em dias.
No máximo, 500 recursos podem ser monitorados.
Podem ser criados até 250 monitores.
As colunas de segmentos devem ser somente colunas categóricas de cadeia de caracteres.
Pode haver no máximo 5 colunas de segmento por monitor de modelos (limite rígido).
Cada coluna de segmentos deve ter menos de 25 valores exclusivos (limite recomendado).
Os valores dos segmentos diferenciam maiúsculas de minúsculas e as consultas não aceitam caracteres especiais.
Não é possível filtrar os segmentos por NULL.
Considerações sobre custo¶
Computação de warehouse virtual:
Os monitores de modelos usam um warehouse virtual, gerando custos durante a criação e em cada atualização.
O carregamento do painel do Snowsight também usa um warehouse virtual, o que acarreta custos adicionais.
Armazenamento:
Os monitores de modelos materializam os dados de origem em uma tabela armazenada em sua conta.
As colunas de segmento acrescentam a tabela materializada armazenada em sua conta.
Computação de serviços de nuvem:
Os monitores de modelos usam a computação dos serviços de nuvem para acionar atualizações quando um objeto de base subjacente foi alterado. O custo de computação dos serviços de nuvem só é cobrado se o custo diário dos serviços de nuvem for superior a 10% do custo diário do warehouse da conta.