Snowpark Container Services: como trabalhar com serviços¶
O Snowpark Container Services permite implantar, gerenciar e dimensionar com mais facilidade aplicativos em contêineres. Depois de criar um aplicativo e carregar a imagem do aplicativo em um repositório na sua conta Snowflake, você pode executar os contêineres do aplicativo como um serviço.
Um serviço representa o Snowflake executando seu aplicativo em contêiner em um pool de computação, que é uma coleção de nós de máquinas virtuais (VM). Há dois tipos de serviços:
Serviços de longa duração. Um serviço de longa duração é como um serviço Web que não termina automaticamente. Depois de criar um serviço, o Snowflake gerencia o serviço em execução. Por exemplo, se um contêiner de serviço parar, por qualquer motivo, o Snowflake reinicia esse contêiner para que o serviço seja executado ininterruptamente.
Serviços de trabalho. Um serviço de trabalho é encerrado quando há a saída do código, de forma semelhante a um procedimento armazenado. Quando todos os contêineres saírem, o serviço de trabalho estará concluído.
O diagrama a seguir mostra a arquitetura de um serviço:
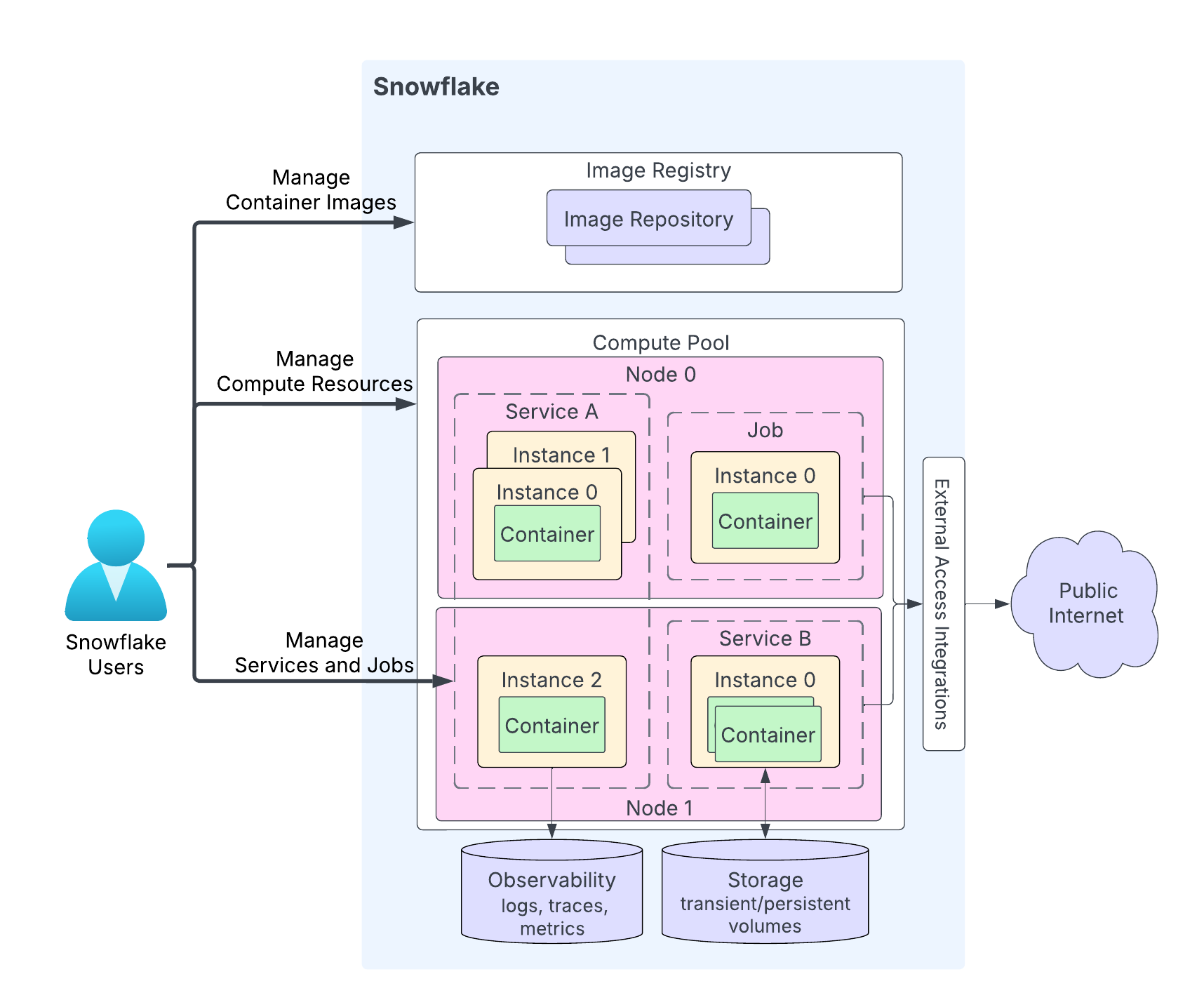
Os destaques do diagrama são os seguintes:
Os usuários fazem upload do código do aplicativo para um repositório na conta Snowflake. O serviço de registro de imagens atende a OCIv2 API para armazenar imagens em conformidade com OCI em um repositório. Por exemplo, você pode usar a Docker API para carregar imagens em um repositório. Ao criar um serviço, você especifica a imagem a ser usada.
Um pool de computação é onde o Snowflake executa os serviços. O diagrama mostra um pool de computação com dois nós de computação (Nó 0 e Nó 1). O Snowflake executa sua instância de serviço em um nó. Ao executar várias instâncias de serviço, dependendo dos requisitos de recursos, o Snowflake pode executá-las no mesmo nó ou distribuí-las entre vários nós. Por exemplo:
O Nó 0 está executando o serviço A (duas instâncias das três instâncias totais desse serviço) e um trabalho (com uma única instância).
O Nó 1 está executando a terceira instância do serviço A. Esse nó também está executando uma instância do serviço B.
Dependendo do código do seu aplicativo, uma instância de serviço pode consistir em vários contêineres. Embora o Snowflake possa distribuir instâncias de um serviço entre vários nós do pool de computação, todos os contêineres de uma única instância de serviço são sempre executados no mesmo nó do pool de computação.
Os serviços podem, opcionalmente, se comunicar com a Internet pública.
Um serviço pode usar o armazenamento, incluindo o armazenamento transitório (por exemplo, memória e disco local) e volumes persistentes (por exemplo, volumes de blocos).
O Snowflake pode registrar logs, rastreamentos e métricas dos seus serviços na tabela de eventos da sua conta Snowflake.
O Snowflake fornece APIs para que você crie e gerencie repositórios, pools de computação e serviços. Este tópico explica como trabalhar com serviços. APIs para gerenciar serviços incluem o seguinte:
Comandos SQL:
Criação de um serviço. CREATE SERVICE, EXECUTE JOB SERVICE.
Alteração de um serviço. ALTER SERVICE, DROP SERVICE.
Obtenção de informações sobre um serviço. SHOW SERVICES, DESCRIBE SERVICE e outros comandos.
Interfaces não SQL: Snowflake Python APIs, Snowflake REST APIs e Snowflake CLI.
Como iniciar os serviços¶
Depois de carregar o código do aplicativo em um repositório na sua conta Snowflake, você pode iniciar um serviço. As informações mínimas necessárias para iniciar um serviço incluem:
Um nome: nome do serviço.
Uma especificação de serviço: esta especificação fornece ao Snowflake as informações necessárias para executar seu serviço. A especificação é um arquivo YAML.
Um pool de computação: o Snowflake executa seu serviço no pool de computação especificado.
Crie um serviço de longa duração¶
Use CREATE SERVICE para criar um serviço de longa duração.
Na maioria dos casos, você cria um serviço especificando uma especificação inline, como mostrado abaixo:
Crie um serviço fazendo referência a uma especificação de serviço armazenada em um estágio do Snowflake. Ao implantar o serviço em um ambiente de produção, você pode aplicar o princípio de design de separação de preocupações e carregar a especificação em um estágio, fornecendo informações sobre o estágio no comando CREATE SERVICE, conforme mostrado:
Execução de um serviço de trabalho¶
Use EXECUTE JOB SERVICE para criar um serviço de trabalho. Por padrão, esse comando é executado de forma síncrona e retorna uma resposta após a saída de todos os contêineres do serviço de trabalho. Opcionalmente, você pode especificar o parâmetro ASYNC para executar o serviço de trabalho de forma assíncrona.
Execute um serviço de trabalho usando uma especificação em linha. O comando aguarda até que o trabalho termine de ser executado:
Opcionalmente, você pode executar esse trabalho de forma assíncrona usando a propriedade
ASYNC.Ao executar um trabalho assíncrono, você pode usar esta função auxiliar <service_name>!SPCS_WAIT_FOR para aguardar a conclusão do trabalho.
Execute um serviço de trabalho usando informações de estágio:
Execução de várias réplicas de um serviço de trabalho (trabalhos em lote)¶
Por padrão, EXECUTE JOB SERVICE executa uma única instância de serviço de trabalho em um pool de computação para executar o trabalho. No entanto, você pode optar por executar várias réplicas de serviços de trabalho para distribuir a carga de trabalho entre os nós do pool de computação. Por exemplo, você pode usar 10 réplicas para processar um conjunto de dados de 10 milhões de linhas, com cada uma delas manipulando 1 milhão de linhas.
Os trabalhos em lote oferecem suporte a cenários em que o trabalho pode ser particionado em tarefas independentes, uma por instância de serviço de trabalho (também chamada de réplica), que podem ser potencialmente executadas simultaneamente. A capacidade do Snowflake de executar as instâncias simultaneamente depende do tamanho do pool de computação.
Para executar um trabalho em lote com várias instâncias, use o parâmetro REPLICAS opcional do EXECUTE JOB SERVICE como mostrado. O exemplo a seguir executa um serviço de trabalho com 10 instâncias:
Quando o parâmetro REPLICAS é especificado em EXECUTE JOB SERVICE, o Snowflake preenche as duas variáveis de ambiente a seguir no contêiner do trabalho:
SNOWFLAKE_JOBS_COUNT: O valor da propriedade REPLICAS especificada no EXECUTE JOB SERVICE.SNOWFLAKE_JOB_INDEX: O ID da instância do serviço de trabalho, começando em 0. Se você tiver três réplicas, os IDs de instância serão 0, 1 e 2.
Essas variáveis de ambiente são fornecidas para que um contêiner de trabalho possa usá-las para particionar a entrada e atribuir a cada instância uma partição específica para processar. Por exemplo, ao processar 10 milhões de linhas com 10 réplicas de trabalho, a instância com índice de trabalho 0 processaria as linhas de 1 a 1 milhão, a instância com índice de trabalho 1 processará linhas de 1 milhão a 2 milhões e assim por diante.
Use o comando SHOW SERVICE INSTANCES IN SERVICE para encontrar o status de cada instância do serviço de trabalho.
Use o comando DESCRIBE SERVICE para obter o status geral do serviço de trabalho. O Snowflake calcula o status geral do serviço de trabalho da seguinte forma:
Se alguma instância falhar, o status do trabalho será FAILED.
Se todas as instâncias forem concluídas com sucesso, o status do trabalho será DONE.
Se alguma instância estiver em execução, o status do trabalho será RUNNING.
Caso contrário, o status do serviço de trabalho será PENDING.
Uso de modelos de especificação¶
Às vezes, você pode querer criar vários serviços usando a mesma especificação, mas com configurações diferentes. Por exemplo, você supõe que define uma variável de ambiente em uma especificação de serviço e deseja criar vários serviços usando a mesma especificação, mas valores diferentes para a variável de ambiente.
Os modelos de especificação permitem que você defina variáveis para valores de campo na especificação. Ao criar um serviço, você fornece valores para essas variáveis.
Em um modelo de especificação, você especifica variáveis como valores para diversos campos de especificação. Use a sintaxe {{ variable_name }} para especificar essas variáveis. Em seguida, no comando CREATE SERVICE, especifique o parâmetro USING para definir valores para essas variáveis.
Por exemplo, o modelo de especificação inline no seguinte comando CREATE SERVICE usa uma variável chamada tag_name para o nome da tag da imagem. Você pode usar essa variável para especificar uma tag de imagem diferente para cada serviço. Nesse exemplo, o parâmetro USING define a variável tag_name como o valor latest.
Se você optar por salvar o modelo de especificação em um estágio do Snowflake na sua conta, você poderá apontar para o local do modelo no comando CREATE SERVICE:
Diretrizes para definir variáveis em uma especificação¶
Use a sintaxe
{{ variable_name }}para definir variáveis como valores de campo na especificação.Essas variáveis podem ter valores padrão. Para especificar o valor padrão, use a função
defaultna declaração da variável. Por exemplo, a especificação a seguir define duas variáveis (character_nameeendpoint_name) com valores padrão.Além disso, é possível especificar um parâmetro booliano opcional para a função
defaultpara indicar se deseja que o valor padrão seja usado quando um valor em branco for passado para a variável. Considere esta especificação:Na especificação:
Para a variável
character_name, o parâmetro booliano é definido comofalse. Portanto, se a variável for definida como um valor de cadeia de caracteres vazia (“”) para este parâmetro, o valor permanecerá em branco; o valor padrão («Bob») não será usado.Para a variável
echo_endpoint, o parâmetro booliano é definido comotrue. Portanto, se você passar um valor em branco para este parâmetro, o valor padrão (“ponto de extremidade-echo”) será usado.
Por padrão, o parâmetro booliano para a função
defaultéfalse.
Diretrizes para passagem de valores para variáveis de especificação¶
Especifique o parâmetro USING no comando CREATE SERVICE para fornecer valores para variáveis. A sintaxe geral para USING é:
onde
var_namediferencia maiúsculas de minúsculas e deve ser um identificador Snowflake válido (consulte Requisitos para identificadores).var_valuepode ser um valor alfanumérico ou um valor JSON válido.Exemplos:
O parâmetro USING em CREATE SERVICE deve fornecer valores para as variáveis de especificação (exceto as variáveis para as quais a especificação fornece valores padrão). Caso contrário, um erro é retornado.
Exemplos¶
Esses exemplos mostram a criação de serviços usando modelos de especificação. Os comandos CREATE SERVICE nestes exemplos usam especificação inline.
Exemplo 1: forneça valores simples¶
Em Tutorial 1 você cria um serviço fornecendo uma especificação inline. O exemplo a seguir é uma versão modificada do mesmo, onde a especificação define duas variáveis: image_url e SERVER_PORT. Note que a variável SERVER_PORT é repetida em três lugares. Isso tem o benefício adicional de usar variáveis que garantem que todos esses campos que deveriam ter o mesmo valor tenham o mesmo valor.
Neste comando CREATE SERVICE, o parâmetro USING fornece valores para as duas variáveis de especificação. O valor image_url inclui barras e dois pontos. Estes não são caracteres alfanuméricos. Portanto, o exemplo envolve o valor entre aspas duplas para torná-lo um valor de cadeia de caracteres JSON válido. A especificação do modelo expande a seguinte especificação:
Exemplo 2: forneça um valor JSON¶
No Tutorial 1, a especificação define duas variáveis de ambiente (SERVER_PORT e CHARACTER_NAME), conforme mostrado:
É possível criar um modelo para essa especificação usando uma variável para o campo env. Isso permite que você crie vários serviços com valores diferentes para as variáveis de ambiente. O seguinte comando CREATE SERVICE usa uma variável (env_values) para o campo env.
O parâmetro USING em CREATE SERVICE fornece valor para a variável env_values. O valor é um mapa JSON que fornece valores para ambas as variáveis de ambiente.
Exemplo 3: fornecer lista como valor variável¶
Em Tutorial 2, a especificação inclui o campo args que inclui dois argumentos.
Em uma versão de modelo da especificação, você pode fornecer esses argumentos como uma lista JSON como mostrado:
Dimensionamento de serviços¶
Por padrão, o Snowflake executa uma instância do serviço no pool de computação especificado. Para gerenciar cargas de trabalho pesadas, você pode executar várias instâncias de serviço definindo as propriedades MIN_INSTANCES e MAX_INSTANCES, que especificam o número mínimo de instâncias do serviço para começar e o número máximo de instâncias para as quais o Snowflake pode escalar quando necessário.
Exemplo
Quando várias instâncias de serviço estão em execução, o Snowflake fornece automaticamente um balanceador de carga para distribuir as solicitações recebidas.
O Snowflake não considera o serviço como READY até que pelo menos duas instâncias estejam disponíveis. Enquanto o serviço não estiver pronto, o Snowflake bloqueia o acesso a ele, o que significa que as funções de serviço associadas ou solicitações de entrada serão negadas até que a prontidão seja confirmada.
Em alguns casos, você pode querer que o Snowflake considere o serviço pronto (e encaminhe solicitações recebidas), mesmo que haja menos instâncias disponíveis do que o mínimo especificado. É possível conseguir isso configurando a propriedade MIN_READY_INSTANCES.
Considere este cenário: durante a manutenção ou um upgrade de serviço contínuo, o Snowflake pode encerrar uma ou mais instâncias de serviço. Isso pode resultar em menos instâncias disponíveis do que o valor especificado de MIN_INSTANCES, o que impede que o serviço entre no estado READY. Nesses casos, você pode definir MIN_READY_INSTANCES como um valor menor que MIN_INSTANCES para garantir que o serviço possa continuar a aceitar solicitações.
Exemplo
Para obter mais informações, consulte CREATE SERVICE.
Ativação do dimensionamento automático¶
Para configurar o Snowflake para dimensionar automaticamente o número de instâncias de serviço em execução, defina os parâmetros MIN_INSTANCES e MAX_INSTANCES no comando CREATE SERVICE. Você também pode usar ALTER SERVICE para alterar esses valores. O dimensionamento automático ocorre quando o MAX_INSTANCES especificado é maior que o MIN_INSTANCES.
O Snowflake começa criando o número mínimo de instâncias de serviço no pool de computação especificado. Em seguida, o Snowflake aumenta ou diminui o número de instâncias de serviço com base em 80% das solicitações de recursos da CPU. O Snowflake monitora continuamente a utilização da CPU no pool de computação, agregando os dados de uso de todas as instâncias de serviço em execução no momento.
Quando o uso agregado da CPU (em todas as instâncias de serviço) ultrapassa 80%, o Snowflake implementa uma instância de serviço adicional no pool de computação. Se o uso agregado da CPU cair para menos de 80%, o Snowflake será reduzido com a remoção de uma instância de serviço em execução. Snowflake usa uma janela de estabilização de cinco minutos para evitar o dimensionamento frequente. A propriedade de serviço target_instances informa o número de destino de instâncias de serviço que o dimensionamento do Snowflake vai atingir.
Observe os seguintes comportamentos de dimensionamento:
O dimensionamento das instâncias de serviço é limitada pelos parâmetros MIN_INSTANCES e MAX_INSTANCES configurados para o serviço.
Se o dimensionamento for necessário e os nós do pool de computação não tiverem a capacidade de recursos necessária para iniciar outra instância de serviço, o escalonamento automático do pool de computação poderá ser acionado. Para obter mais informações, consulte Dimensionamento automático de nós do pool de computação.
Se você especificar os parâmetros MAX_INSTANCES e MIN_INSTANCES ao criar um serviço, mas não especificar os requisitos de CPU e memória para sua instância de serviço no arquivo de especificação de serviço, nenhum dimensionamento automático ocorrerá; o Snowflake inicia com o número de instâncias especificado pelo parâmetro MIN_INSTANCES e não realiza o dimensionamento automático.
Suspensão de um serviço¶
Um serviço de longa duração consome recursos do pool de computação, incorrendo em custos, mas você pode suspender o serviço quando ele não estiver realizando um trabalho significativo. Quando nenhum serviço ou trabalho está ativo em qualquer nó do pool de computação, o mecanismo de suspensão automática do pool de computação do Snowflake suspende o pool para reduzir os custos.
Para suspender um serviço, você pode chamar explicitamente ALTER SERVICE … SUSPEND para suspender um serviço, ou definir a propriedade AUTO_SUSPEND_SECS usando CREATE SERVICE ou ALTER SERVICE para definir a duração de inatividade após a qual o Snowflake suspende automaticamente o serviço.
![]() Recurso em versão preliminar — Aberto
Recurso em versão preliminar — Aberto
A configuração da suspensão automática de um serviço do Snowpark Container Services usando a propriedade AUTO_SUSPEND_SECS é um recurso em versão preliminar.
Quando a propriedade AUTO_SUSPEND_SECS é definida, o Snowflake suspende automaticamente um serviço se ele ainda não tiver sido suspenso e estiver ocioso por mais de AUTO_SUSPEND_SECS segundos. Um serviço está ocioso quando ambos os itens a seguir são verdadeiros:
Não há nenhuma consulta em execução no momento que inclua uma invocação de função de serviço nesse serviço.
O status do serviço é RUNNING.
Cuidado
A suspensão automática não rastreia o processamento de dados iniciado por uma invocação de função de serviço, em que o processamento continua após o retorno da função de serviço. Na implementação atual, a suspensão automática também não rastreia as comunicações de entrada e comunicações de serviço para serviço. Portanto, você não deve ativar a suspensão automática para serviços que oferecem esses recursos, pois isso pode interromper esses processos potencialmente em andamento.
Quando o Snowflake suspende um serviço, ele desliga todas as instâncias de serviço no pool de computação. Se não houver outros serviços em execução no pool de computação e se a suspensão automática estiver configurada para o pool de computação, o Snowflake também suspenderá os nós do pool de computação. Assim, você evita pagar por um pool de computação inativo.
Além disso, observe o seguinte:
A suspensão automática não é compatível com os serviços de trabalho.
A suspensão automática não é compatível com serviços com pontos de extremidade públicos porque o Snowflake atualmente só rastreia o tráfego da função de serviço, e não o tráfego de entrada, para decidir quando um serviço está ocioso.
Modificação e descarte de serviços¶
Depois de criar um serviço ou serviço de trabalho, você poderá executar as seguintes ações:
Usar o comando DROP SERVICE para remover um serviço de um esquema (o Snowflake encerra todos os contêineres de serviço).
Chamar a função <service_name>!SPCS_CANCEL_JOB para cancelar um serviço de trabalho. Quando você cancela um trabalho, o Snowflake interrompe a execução do trabalho e remove os recursos alocados para tal.
Usar o comando ALTER SERVICE para modificar o serviço (por exemplo, suspender ou retomar o serviço, alterar o número de instâncias em execução e instruir o Snowflake a reimplantar seu serviço usando uma nova especificação de serviço).
Nota
Você não pode alterar um serviço de trabalho.
Encerramento do serviço¶
Quando você suspende um serviço (ALTER SERVICE … SUSPEND) ou descarta um serviço (DROP SERVICE), o Snowflake encerra todas as instâncias do serviço. Da mesma forma, quando você atualiza o código de serviço (ALTER SERVICE … <fromSpecification>), o Snowflake aplica atualizações contínuas encerrando e reimplementando uma instância de serviço por vez.
Ao encerrar uma instância de serviço, o Snowflake primeiro envia um sinal SIGTERM para cada contêiner de serviço. O contêiner tem a opção de processar o sinal e desligar normalmente em uma janela de 30 segundos. Caso contrário, após o período de carência, o Snowflake encerra todos os processos no contêiner.
Atualização do código de serviço e reimplementação do serviço¶
Após a criação de um serviço, use o comando ALTER SERVICE … <fromSpecification> para atualizar o código de serviço e reimplementar o serviço.
Primeiro, você faz o upload do código do aplicativo modificado para o repositório de imagens. Em seguida, você executa o comando ALTER SERVICE, fornecendo a especificação do serviço inline ou especificando o caminho para um arquivo de especificação no estágio do Snowflake. Por exemplo:
Ao receber a solicitação, o Snowflake reimplanta o serviço usando o novo código.
Nota
Quando você executa o comando CREATE SERVICE … <fromSpecification>, o Snowflake registra a versão específica da imagem fornecida. O Snowflake implementa a mesma versão de imagem nos seguintes cenários, mesmo que a imagem no repositório tenha sido atualizada:
Quando um serviço suspenso é retomado (usando ALTER SERVICE … RESUME).
Quando o dimensionamento automático adiciona mais instâncias de serviço.
Quando instâncias de serviço são reiniciadas durante a manutenção do cluster.
Mas quando você chama ALTER SERVICE … <fromSpecification>, o Snowflake usa a versão mais recente do repositório para essa imagem.
Se você for o proprietário do serviço, a saída do comando DESCRIBE SERVICE incluirá a especificação do serviço, que inclui o resumo da imagem (o valor do campo sha256 na especificação), conforme mostrado abaixo:
ALTER SERVICE pode afetar as comunicações (consulte Como usar um serviço) com o serviço.
Se ALTER SERVICE … <fromSpecification> remover um ponto de extremidade ou remover permissões relevantes necessárias para usar um ponto de extremidade (consulte serviceRoles na referência de especificação), o acesso ao serviço falhará. Para obter mais informações, consulte Como usar um serviço.
Enquanto a atualização estiver em andamento, novas conexões poderão ser roteadas para a nova versão. Se a nova versão do serviço não for compatível com versões anteriores, ela interromperá qualquer uso ativo do serviço. Por exemplo, consultas em andamento usando uma função de serviço podem falhar.
Nota
Ao atualizar o código de serviço que faz parte de um aplicativo nativo com contêineres, você pode usar a função do sistema SYSTEM$WAIT_FOR_SERVICES para pausar o script de configuração do aplicativo nativo para permitir que os serviços sejam atualizados completamente. Para obter mais informações, consulte Atualizar um app (legado).
Monitoramento de atualizações contínuas¶
Quando várias instâncias de serviço estão em execução, o Snowflake executa uma atualização contínua, em ordem decrescente, com base no ID das instâncias de serviço. Use os seguintes comandos para monitorar as atualizações de serviço:
DESCRIBE SERVICE e SHOW SERVICES:
A coluna
is_upgradingna saída mostra TRUE se o serviço estiver sendo atualizado.A coluna
spec_digestna saída representa o resumo da especificação do serviço atual. É possível executar este comando periodicamente; uma alteração no valorspec_digestindica que uma atualização de serviço foi acionada. Ospec_digestsó estará em uso depois queis_upgradingfor FALSE; caso contrário, a atualização do serviço ainda estará em andamento.Use o comando SHOW SERVICE INSTANCES IN SERVICE para verificar se todas as instâncias foram atualizadas para a versão mais recente, conforme explicado abaixo.
SHOW SERVICE INSTANCES IN SERVICE:
A coluna
statusna saída fornece o status de cada instância de serviço individual enquanto a atualização contínua está em andamento. Durante a atualização, você observará cada status de transição de instância de serviço, como TERMINATING para PENDING e PENDING para READY.Durante a atualização do serviço, a coluna
spec_digestna saída desse comando pode mostrar um valor diferente de SHOW SERVICES, que sempre retorna o resumo de especificações mais recente. Essa diferença indica simplesmente que a atualização do serviço está em andamento e que as instâncias de serviço ainda estão executando a versão antiga do serviço.
Obtenção de informações sobre serviços¶
É possível usar estes comandos:
Use o comando DESCRIBE SERVICE para recuperar as propriedades e o status de um serviço. A saída retorna todas as propriedades do serviço.
Use o comando SHOW SERVICES para listar os serviços atuais (incluindo serviços de trabalho) para os quais você tem permissões. A saída fornece algumas das propriedades e status desses serviços.
Por padrão, a saída lista os serviços no banco de dados e esquema atuais. Como alternativa, é possível especificar qualquer um dos seguintes escopos. Por exemplo:
Liste os serviços na conta, em um banco de dados específico ou em um esquema específico: Por exemplo, use o filtro IN ACCOUNT para listar serviços em sua conta Snowflake, independentemente do banco de dados ou esquema ao qual os serviços pertencem. Isso é útil se você tiver serviços Snowflake criados em vários bancos de dados e esquemas em sua conta. Como todos os outros comandos, SHOW SERVICES IN ACCOUNTS é controlado por privilégios, retornando apenas os serviços para os quais a função que você está usando tem permissões de exibição.
Você também pode especificar IN DATABASE ou IN SCHEMA para listar os serviços no banco de dados ou esquema atual (ou especificado).
Liste os serviços em execução em um pool de computação: Por exemplo, use o filtro IN COMPUTE POOL para listar os serviços em execução em um pool de computação.
Liste os serviços que começam com um prefixo ou que correspondam a um padrão: É possível aplicar os filtros LIKE e STARTS WITH para filtrar os serviços por nome.
Liste os serviços de trabalho ou exclua serviços de emprego da lista: É possível usar SHOW JOB SERVICES ou SHOW SERVICES EXCLUDE JOBS para listar apenas serviços de trabalho ou excluí-los.
Você também pode combinar essas opções para personalizar a saída de SHOW SERVICES.
Use o comando SHOW SERVICE INSTANCES IN SERVICE para recuperar propriedades das instâncias de serviço.
Use o comando SHOW SERVICE CONTAINERS IN SERVICE para recuperar as propriedades e o status das instâncias de serviço.
Chame a função GET_JOB_HISTORY para obter os históricos de trabalhos executados dentro de um intervalo de tempo especificado.
Chame a função <service_name>!SPCS_WAIT_FOR para esperar e recuperar o estado do serviço (incluindo o estado de um serviço de trabalho) após um horário específico.
Serviços de monitoramento¶
O Snowpark Container Services oferece ferramentas para monitorar pools de computação em sua conta e os serviços em execução neles. Para obter mais informações, consulte Snowpark Container Services: Serviços de monitoramento.
Como usar um serviço¶
Depois de criar um serviço, os usuários da mesma conta (que criou o serviço) podem usá-lo. Há três métodos para usar um serviço, conforme ilustrado no diagrama. O usuário precisa ter acesso a funções com os privilégios necessários.
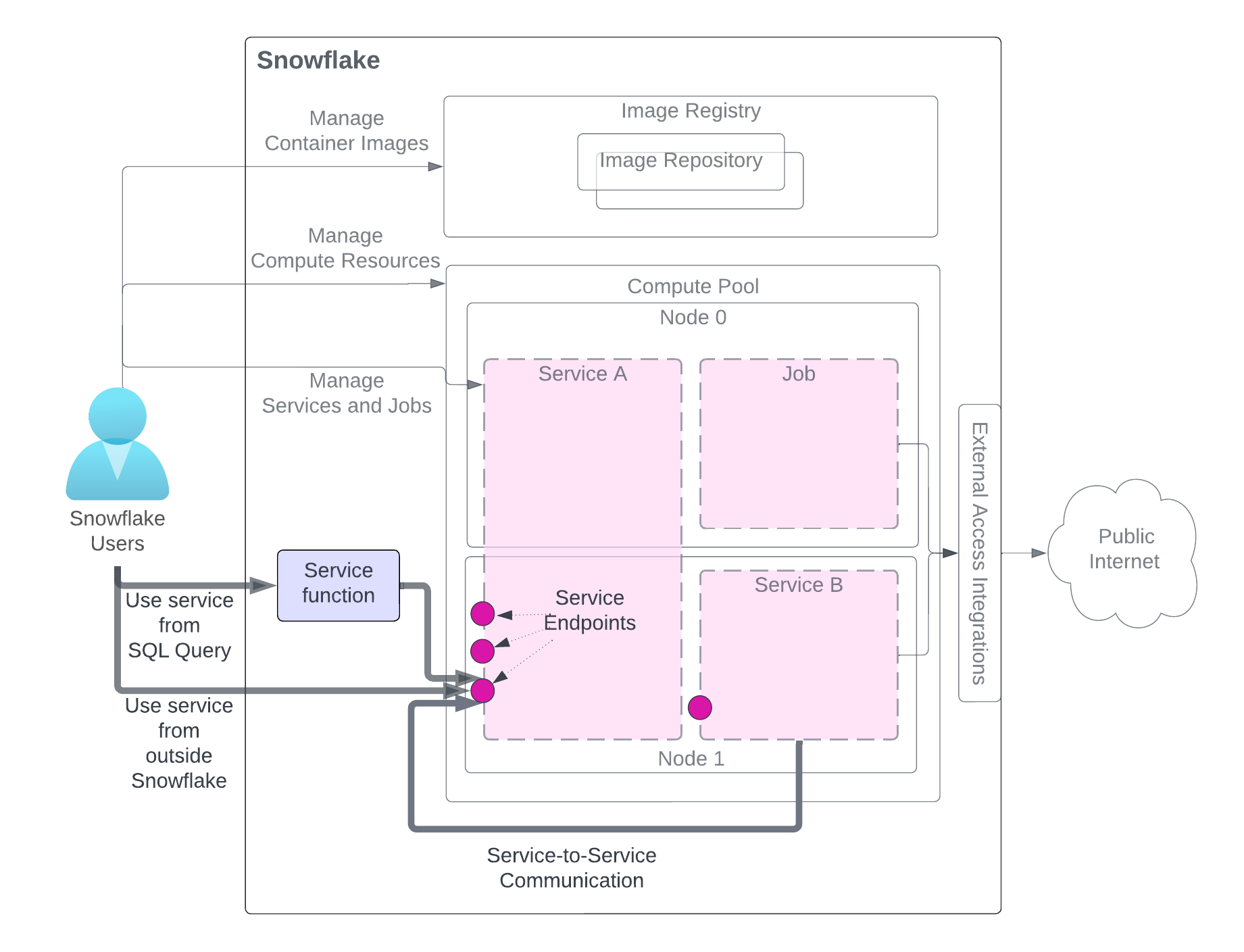
O diagrama destaca os métodos de uso do serviço, enquanto outros componentes relacionados ao serviço são esmaecidos para maior clareza. Para obter uma explicação detalhada dos componentes do serviço, consulte o diagrama no início desta página.
Usar o serviço de uma consulta SQL (Função de serviço): você cria uma função de serviço, uma função definida pelo usuário (UDF) associada a um serviço, e a utiliza em uma consulta SQL, aproveitando o processamento de dados personalizado que o serviço oferece. Para obter um exemplo, consulte Tutorial 1.
Usar o serviço de fora do Snowflake (Entrada): você pode declarar um ou mais pontos de extremidade de serviço como públicos para permitir o acesso de entrada de rede ao serviço. Isso pode ser usado para criar aplicativos Web ou APIs expostas em seus dados do Snowflake. Para obter um exemplo, consulte Tutorial 1.
Usar o serviço de outro serviço (Comunicações entre serviços): os serviços podem se comunicar entre si usando o nome DNS do serviço atribuído pelo Snowflake para comunicação entre serviços. Para consultar um exemplo, veja o Tutorial 4.
Conforme ilustrado no diagrama, ao se comunicar com um serviço usando qualquer um desses métodos, você envia solicitações a pontos de extremidade que o serviço expõe e obtém resultados.
Nota
As funções de serviço não podem ser usadas para comunicação com um serviço de trabalho.
As seções a seguir fornecem detalhes.
Funções de serviço: como usar um serviço de uma consulta SQL¶
Uma função de serviço é uma função definida pelo usuário (UDF) que você cria usando CREATE FUNCTION (Snowpark Container Services). No entanto, em vez de escrever o código UDF diretamente, você associa a UDF ao seu ponto de extremidade do servidor. Observe que você pode associar uma função de serviço somente a um ponto de extremidade de serviço compatível com o protocolo HTTP (consulte Campo spec.endpoints (opcional)).
Por exemplo, no Tutorial 1, você cria um serviço chamado echo_service que expõe um ponto de extremidade (ponto de extremidade de eco) conforme definido na especificação do serviço:
echoendpoint é um nome de ponto de extremidade amigável que representa a porta correspondente (8080). Para se comunicar com esse ponto de extremidade de serviço, crie uma função de serviço fornecendo os parâmetros SERVICE e ENDPOINT conforme mostrado:
O parâmetro AS fornece o caminho HTTP para o código de serviço. Você obtém esse valor de caminho a partir do código de serviço. Por exemplo, as seguintes linhas de código são do service.py no Tutorial 1.
Você invoca a função de serviço em uma instrução SELECT, como a seguinte:
O Snowflake direciona a solicitação para o ponto de extremidade do serviço e o caminho associado.
Nota
Uma função de serviço é usada para se comunicar com um serviço e não com um trabalho. Em outras palavras, você só pode associar um serviço (não um trabalho) a uma função de serviço.
Formato de troca de dados¶
Para troca de dados entre uma função de serviço e um contêiner de aplicativo, o Snowflake segue o mesmo formato que as funções externas usam (consulte Formatos de dados). Por exemplo, suponha que você tenha linhas de dados armazenadas em uma tabela (input_table):
Para enviar esses dados ao seu serviço, você invoca a função de serviço passando estas linhas como parâmetros:
Snowflake envia uma série de solicitações ao contêiner, com lotes de linhas de dados no corpo da solicitação neste formato:
O contêiner então retorna a saída no seguinte formato:
O exemplo de saída mostrado assume que o resultado é uma tabela de uma coluna com linhas («a», «b»…).
Configuração do processamento em lote¶
Os comandos CREATE FUNCTION e ALTER FUNCTION aceitam parâmetros que configuram como o Snowflake lida com lotes de dados processados pelo seu serviço.
Configuração do tamanho do lote
Você pode usar o parâmetro MAX_BATCH_ROWS para limitar o tamanho do lote, ou seja, o número máximo de linhas que o Snowflake envia ao seu serviço em uma única solicitação. Isso ajuda a controlar o volume de dados transferidos. Isso também pode resultar em mais lotes menores que podem ser processados em paralelo se o seu serviço tiver suporte para várias instâncias ou solicitações simultâneas.
Tratamento de erros
Você pode usar estes parâmetros para o tratamento de erros em lote:
ON_BATCH_FAILURE,MAX_BATCH_RETRIESeBATCH_TIMEOUT_SECS.
Por exemplo, o seguinte comando ALTER FUNCTION configura os parâmetros MAX_BATCH_ROWS e MAX_BATCH_RETRIES da função de serviço my_echo_udf:
Privilégios necessários para criar e gerenciar funções de serviço¶
Para criar e gerenciar funções de serviço, uma função precisa dos seguintes privilégios:
A função atual deve ter a função de serviço concedida para o ponto de extremidade referenciado no comando CREATE FUNCTION ou ALTER FUNCTION.
Para usar uma função de serviço em uma consulta SQL, a sessão atual deve ter uma função com privilégio de uso na função de serviço, e a função de proprietário da função de serviço deve receber a função de serviço para o ponto de extremidade de serviço associado.
O script de exemplo a seguir mostra como você pode conceder permissões para criar e usar uma função de serviço:
Entrada: usando um serviço de fora do Snowflake¶
Você pode declarar um ou mais pontos de extremidade como públicos na especificação do serviço para permitir que os usuários usem o serviço a partir do público. Observe que os usuários devem ser usuários do Snowflake na mesma conta Snowflake que criou o serviço.
Observe que a entrada é permitida somente com um ponto de extremidade HTTP (consulte Campo spec.endpoints (opcional)).
Autenticação de entrada¶
Um usuário pode acessar um ponto de extremidade público quando lhe é concedida uma função de serviço que permite o acesso a esse ponto de extremidade (consulte Privilégios necessários para acessar os pontos de extremidade do serviço (funções de serviço)).
Em seguida, os usuários podem acessar o ponto de extremidade público usando um navegador ou de forma programática.
Acesso a um ponto de extremidade público usando um navegador: quando o usuário usa um navegador para acessar um ponto de extremidade público, o Snowflake redireciona automaticamente o usuário para uma página de login. O usuário deve inserir as credenciais do Snowflake para fazer login. Depois de fazer login com sucesso, o usuário terá acesso ao ponto de extremidade. Nos bastidores, o login do usuário gera um token OAuth do Snowflake. O token OAuth é então usado para enviar uma solicitação ao ponto de extremidade do serviço.
Para obter um exemplo, consulte Tutorial 1.
Acesso a um ponto de extremidade público programaticamente: os clientes programáticos podem acessar pontos de extremidade de três maneiras:
Usando um token de acesso programático (Programmatic Access Token, PAT): seu aplicativo passa o token no cabeçalho
Authorizationdas solicitações ao ponto de extremidade para representar sua identidade.Usando a autenticação de par de chaves: seu aplicativo gera um JWT usando um par de chaves, troca o JWT com o Snowflake por um token OAuth e passa o token OAuth no cabeçalho
Authorizationdas solicitações para o ponto de extremidade para representar sua identidade.Usando o conector Python: seu aplicativo usa o conector Python para gerar um token de sessão e, em seguida, passa esse token no cabeçalho
Authorizationdas solicitações ao ponto de extremidade para representar sua identidade.
Para exemplos relacionados, consulte o Tutorial 8.
Cabeçalhos específicos do usuário em solicitações de entrada¶
Quando chega uma solicitação para um ponto de extremidade público, o Snowflake passa automaticamente o seguinte cabeçalho junto com a solicitação HTTP para o contêiner.
Seu código de contêiner pode, opcionalmente, ler o cabeçalho, saber quem é o chamador e aplicar a personalização específica do contexto para diferentes usuários. Além disso, o Snowflake pode incluir opcionalmente o cabeçalho Sf-Context-Current-User-Email. Para incluir este cabeçalho, entre em contato com o suporte Snowflake.
Comunicações serviço a serviço¶
As instâncias de serviço podem se comunicar diretamente entre si por TCP (incluindo HTTP). Isso de aplica tanto para instâncias que pertencem ao mesmo serviço quanto para instâncias que pertencem a serviços diferentes.
As instâncias só podem receber comunicações (solicitações) nos pontos de extremidade declarados na especificação do serviço. O cliente (o serviço que envia a solicitação) deve ter as funções e concessões necessárias para se conectar a esse ponto de extremidade (consulte Privilégios necessários para acessar os pontos de extremidade do serviço (funções de serviço)).
Por padrão, uma instância de serviço pode se conectar a outras instâncias do mesmo serviço nos pontos de extremidade declarados. Em termos mais amplos, a função de proprietário de um serviço tem permissões para se conectar a pontos de extremidade de serviços com a mesma função de proprietário.
Para que um serviço cliente se conecte a um ponto de extremidade de um serviço que tenha uma função de proprietário diferente, a função de proprietário do serviço cliente precisa da função de serviço que concede acesso ao ponto de extremidade de outro serviço para chamar esse ponto de extremidade. Para obter mais informações, consulte Privilégios necessários para acessar os pontos de extremidade do serviço (funções de serviço).
Se você quiser evitar que seus serviços se comuniquem entre si (por motivos como segurança), use diferentes funções do Snowflake para criar esses serviços.
Uma instância de serviço pode ser acessada usando o endereço IP do serviço ou os endereços IP da instância de serviço.
As solicitações que usam o endereço IP do serviço são encaminhadas para um balanceador de carga que, por sua vez, encaminha as solicitações para uma instância de serviço selecionada aleatoriamente.
As solicitações que usam o endereço IP da instância de serviço são encaminhadas diretamente para a instância de serviço específica. Você deve usar o IP da instância de serviço ao se conectar a um ponto de extremidade definido usando o campo
portRange(consulte Campo spec.endpoints (opcional)).
Ambos os endereços IP podem ser descobertos usando o nome DNS que o Snowflake atribui automaticamente a cada serviço. Observe que não é possível usar DNS para se conectar a uma instância específica. Por exemplo, não faz sentido criar um URL usando o nome DNS da instância de serviço, pois não há como usar o nome DNS da instância de serviço para fazer referência a uma instância de serviço específica.
Os endereços IP da instância de serviço são mostrados na saída do comando SHOW SERVICE INSTANCES IN SERVICE quando o pacote de mudança de comportamento 2025_01 está ativado.
Para conferir um exemplo de comunicação entre serviços, consulte o Tutorial 4.
Observe que, se um ponto de extremidade de serviço for criado apenas para permitir comunicações de serviço a serviço, o protocolo TCP deverá ser usado (consulte Campo spec.endpoints (opcional)).
Nome DNS do serviço¶
O formato do nome DNS é:
Use SHOW SERVICES (ou DESCRIBE SERVICE) para obter o nome DNS de um serviço. O nome DNS anterior é um nome totalmente qualificado. Os serviços criados no mesmo esquema podem se comunicar usando apenas o <nome-do-serviço>. Os serviços que estão em um esquema ou banco de dados diferente devem fornecer o hash, como <service-name>.<hash> ou fornecer o nome totalmente qualificado (<service-name>.<hash>.svc.spcs.internal).
Use a função SYSTEM$GET_SERVICE_DNS_DOMAIN para encontrar o domínio DNS para um determinado esquema. O domínio do hash DNS é específico da versão atual do esquema. Observe o seguinte:
Se esse esquema ou seu banco de dados for renomeado, o hash não será alterado.
Se o esquema for descartado e depois recriado (por exemplo, usando CREATE OR REPLACE SCHEMA), o novo esquema terá um novo hash. Se você UNDROP um esquema, o hash permanecerá o mesmo.
Os nomes DNS têm as seguintes limitações:
Seus nomes de serviço devem ser uma etiqueta DNS válida. (consulte também https://www.ietf.org/rfc/rfc1035.html#section-2.3.1). Caso contrário, a criação de um serviço falhará.
O Snowflake substitui um sublinhado (_) no nome do serviço por um traço (-) no nome DNS.
Um nome DNS é apenas para comunicações internas no Snowflake entre serviços em execução na mesma conta. Não é acessível pela internet.
Nome DNS das instâncias de serviço¶
O formato do nome das instâncias de serviço DNS é o seguinte:
Ele resolve para uma lista de endereços IP da instância de serviço, um para cada instância do serviço. Observe que não há nenhuma ordem garantida para a lista de endereços IP que DNS retorna. Esse nome DNS só deve ser usado com DNS APIs, não como o nome do host em um URL. A expectativa é que seu aplicativo use esse nome de host com DNS APIs para coletar o conjunto de IPs de instâncias de serviço e, em seguida, conectar-se programaticamente a esses IPs de instâncias de forma direta.
Essa lista de endereços IP permite a criação de uma rede mesh para comunicação direta entre instâncias de serviço específicas.
Qual nome DNS escolher¶
As considerações a seguir se aplicam ao escolher o nome DNS a ser usado ao se conectar a um serviço na comunicação serviço a serviço.
Use o nome DNS do serviço quando qualquer uma das opções a seguir for verdadeira:
Você precisa acessar uma porta de destino específica da maneira mais simples possível.
Você deseja que cada solicitação seja enviada a uma instância de serviço selecionada aleatoriamente.
Você não sabe como a estrutura do seu aplicativo executa e armazena em cache as respostas do DNS.
Use o nome DNS da instância de serviço ou o IP da instância de serviço quando qualquer um dos itens a seguir for verdadeiro:
Você deseja descobrir os endereços IP de todas as instâncias de serviço.
Você deseja ignorar um balanceador de carga intermediário.
Você usa estruturas ou bancos de dados distribuídos, como Ray ou Cassandra, que usam endereços IP de instância de serviço como identidades.
Gerenciar os tipos de serviços permitidos em sua conta¶
O Snowflake oferece suporte a diferentes tipos de serviços (tipos de carga de trabalho) que você pode criar em sua conta. Os tipos incluem cargas de trabalho implantadas pelo usuário, como serviços e trabalhos, e cargas de trabalho próprias gerenciadas pelo Snowflake, como notebooks, serviços de modelos e trabalhos de ML. Para obter uma lista de tipos de carga de trabalho, consulte ALLOWED_SPCS_WORKLOAD_TYPES.
Quando você lista serviços em sua conta usando SHOW SERVICES, é possível incluir um filtro para listar apenas tipos de carga de trabalho específicos. Por exemplo, mostrar apenas os serviços implantados pelo usuário:
É possível restringir os tipos de cargas de trabalho permitidos na sua conta Snowflake usando os parâmetros no nível da conta ALLOWED_SPCS_WORKLOAD_TYPES e DISALLOWED_SPCS_WORKLOAD_TYPES. Por exemplo, para permitir somente cargas de trabalho de NOTEBOOK, execute a seguinte instrução:
Nota
Tipos de carga de trabalho especificados em DISALLOWED_SPCS_WORKLOAD_TYPES não podem ser implantados. Se você configurar ambos ALLOWED_SPCS_WORKLOAD_TYPES e DISALLOWED_SPCS_WORKLOAD_TYPES, a lista de não permitidos terá precedência. Por exemplo, se ambos os parâmetros especificarem o tipo de carga de trabalho NOTEBOOK, as cargas de trabalho de NOTEBOOK não poderão ser executadas no Snowpark Container Services.
Os serviços criados antes de você configurar esses parâmetros no nível da conta continuam em execução. No entanto, se você suspender um serviço que tem um tipo de carga de trabalho não permitido, não será possível reiniciá-lo.
Para excluir todos os serviços criados de tipos não permitidos, execute o comando ALTER COMPUTE POOL … STOP ALL OF TYPE.
Como passar credenciais para um contêiner usando segredos do Snowflake¶
Há muitos motivos pelos quais você pode querer passar credenciais Snowflake gerenciadas para seu contêiner. Por exemplo, seu serviço pode se comunicar com pontos de extremidade externos (fora do Snowflake), caso em que será necessário fornecer informações de credenciais em seu contêiner para que o código do aplicativo as utilize.
Para fornecer as credenciais, primeiro armazene-as em objetos secretos Snowflake. Em seguida, na especificação do serviço, use containers.secrets para definir quais objetos secretos usar e onde colocá-los dentro do contêiner. É possível passar essas credenciais para variáveis de ambiente nos contêineres ou disponibilizá-las em arquivos locais nos contêineres.
Especificando segredos Snowflake¶
Especifique um segredo Snowflake por nome ou referência (a referência é aplicável somente no cenário com Native Applications):
Passe o segredo Snowflake por nome: É possível passar um nome secreto como valor do campo
snowflakeSecret.Observe que você pode opcionalmente especificar
<secret-name>diretamente como o valorsnowflakeSecret.Passe o segredo Snowflake por referência: Ao usar o Snowpark Container Services para criar um Native App (um aplicativo com contêineres), o produtor e os consumidores do aplicativo usam contas Snowflake diferentes. Em alguns contextos, um Snowflake Native App instalado precisa acessar objetos secretos existentes na conta do consumidor que existem fora do objeto APPLICATION. Nesse caso, os desenvolvedores podem usar a sintaxe da especificação “segredos por referência” para manipular credenciais, conforme mostrado:
Observe que a especificação usa
objectReferenceem vez deobjectNamepara fornecer um nome de referência do segredo.
Especificação do posicionamento dos segredos dentro do contêiner¶
É possível dizer ao Snowflake para colocar os segredos nos contêineres como variáveis de ambiente ou gravá-los em arquivos de contêiner locais.
Como passar os segredos como variáveis de ambiente¶
Para passar segredos Snowflake para contêineres como variáveis de ambiente, inclua envVarName no campo containers.secrets.
O valor secretKeyRef depende do tipo de segredo Snowflake. Os valores possíveis são os seguintes:
usernameoupasswordse o segredo do Snowflake for do tipopassword.secret_stringse o segredo do Snowflake for do tipogeneric_string.
Observe que o Snowflake não atualiza segredos passados como variáveis de ambiente após a criação de um serviço.
Exemplo 1: como passar segredos do tipo senha como variáveis de ambiente¶
Neste exemplo, você cria o seguinte objeto de segredo do Snowflake do tipo password:
Para fornecer esse objeto de segredo do Snowflake às variáveis de ambiente (por exemplo, LOGIN_USER e LOGIN_PASSWORD) em seu contêiner, adicione o seguinte campo containers.secrets no arquivo de especificação:
Neste exemplo, o valor snowflakeSecret é um nome de objeto totalmente qualificado porque os segredos podem ser armazenados em um esquema diferente do serviço que está sendo criado.
O campo containers.secrets neste exemplo é uma lista de dois objetos snowflakeSecret:
O primeiro objeto mapeia
usernameno objeto do segredo do Snowflake para a variável de ambienteLOGIN_USERem seu contêiner.O segundo objeto mapeia
passwordno objeto do segredo do Snowflake para a variável de ambienteLOGIN_PASSWORDem seu contêiner.
Exemplo 2: como passar segredos do tipo cadeia_de_caracteres_genérica como variáveis de ambiente¶
Neste exemplo, você cria o seguinte objeto de segredo do Snowflake do tipo generic_string:
Para fornecer esse objeto do segredo do Snowflake para variáveis de ambiente (por exemplo, GENERIC_SECRET) em seu contêiner, adicione o seguinte campo containers.secrets no arquivo de especificação:
Gravação de segredos em arquivos de contêiner locais¶
Para disponibilizar segredos Snowflake para o contêiner do aplicativo em arquivos de contêiner locais, inclua um campo containers.secrets: Para disponibilizar os segredos Snowflake para o contêiner do aplicativo em arquivos de contêiner locais, inclua directoryPath em containers.secrets:
O Snowflake preenche os arquivos necessários para o segredo neste directoryPath especificado; não é necessário especificar secretKeyRef. Dependendo do tipo de segredo, o Snowflake cria os seguintes arquivos no contêiner no caminho de diretório fornecido:
usernameepassword, se o segredo Snowflake for do tipopassword.secret_stringse o segredo do Snowflake for do tipogeneric_string.access_tokense o segredo do Snowflake for do tipooauth2.
Nota
Após a criação de um serviço, se o objeto do segredo do Snowflake for atualizado, o Snowflake atualizará os arquivos do segredo correspondentes nos contêineres em execução.
Exemplo 1: como passar segredos do tipo senha em arquivos de contêiner locais¶
Neste exemplo, você cria o seguinte objeto de segredo do Snowflake do tipo password:
Para disponibilizar essas credenciais em arquivos de contêiner locais, adicione o seguinte campo containers.secrets no arquivo de especificação:
Quando você inicia o serviço, o Snowflake cria dois arquivos dentro do contêiner: /usr/local/creds/username e /usr/local/creds/password. O código do seu aplicativo pode então ler esses arquivos.
Exemplo 2: Como passar segredos do tipo generic_string em arquivos de contêiner locais¶
Neste exemplo, você cria o seguinte objeto de segredo do Snowflake do tipo generic_string:
Para fornecer este objeto secreto Snowflake em arquivos de contêiner locais, adicione o seguinte campo containers.secrets no arquivo de especificação:
Quando você inicia o serviço, o Snowflake cria este arquivo dentro dos contêineres: /usr/local/creds/secret_string.
Exemplo 3: Como passar segredos do tipo oauth2 em arquivos de contêiner locais¶
Neste exemplo, você cria o seguinte objeto de segredo do Snowflake do tipo oauth2:
Para disponibilizar essas credenciais em arquivos de contêiner locais, adicione o seguinte campo containers.secrets no arquivo de especificação:
Snowflake busca o token de acesso do objeto do segredo do OAuth e cria /usr/local/creds/access_token nos contêineres.
Quando um serviço usa segredos do tipo oauth2, espera-se que o serviço use esse segredo para acessar um destino da internet. Um segredo oauth deve ser permitido pela integração de acesso externo (EAI); caso contrário, CREATE SERVICE ou EXECUTE JOB SERVICE falharão. Este requisito de EAI extra se aplica apenas a segredos do tipo oauth2 e não a outros tipos de segredos.
Em resumo, as etapas típicas na criação de tal serviço são:
Crie um segredo do tipo oauth2 (mostrado anteriormente).
Crie uma EAI para permitir o uso do segredo por um serviço. Por exemplo:
Crie um serviço que inclua um campo
containers.secretsna especificação. Isso também especifica a propriedade opcional EXTERNAL_ACCESS_INTEGRATIONS para incluir uma EAI para permitir o uso do segredo oauth2.Um exemplo de comando CREATE SERVICE (com especificação inline):
Para obter mais informações sobre saída, consulte Configurar saída de serviço.
Diretrizes e limitações¶
Para obter mais informações, consulte Snowpark Container Services: Diretrizes e limitações.