Snowpark Container Services: 서비스 사용하기¶
:doc:`Snowpark Container Services<overview>`를 사용하면 컨테이너화된 애플리케이션을 더 쉽게 배포하고, 관리하고, 확장할 수 있습니다. 애플리케이션을 만들고 Snowflake 계정의 리포지토리에 애플리케이션 이미지를 업로드하면 애플리케이션 컨테이너를 서비스로 실행할 수 있습니다.
서비스는 가상 머신(VM) 노드의 집합인 컴퓨팅 풀 에서 컨테이너화된 애플리케이션을 실행하는 Snowflake를 나타냅니다. 서비스에는 다음의 두 가지 유형이 있습니다.
장기 실행 서비스. 장기 실행 서비스는 자동으로 종료되지 않는 웹 서비스와 같습니다. 서비스를 생성하면 Snowflake가 실행 중인 서비스를 관리합니다. 예를 들어 서비스 컨테이너가 어떤 이유로든 중지되면 Snowflake는 해당 컨테이너를 다시 시작하여 서비스가 중단 없이 실행됩니다.
작업 서비스. 작업 서비스는 저장 프로시저와 마찬가지로 코드가 종료될 때 종료됩니다. 모든 컨테이너가 종료되면 작업 서비스가 완료됩니다.
다음 다이어그램은 서비스의 아키텍처를 보여줍니다.
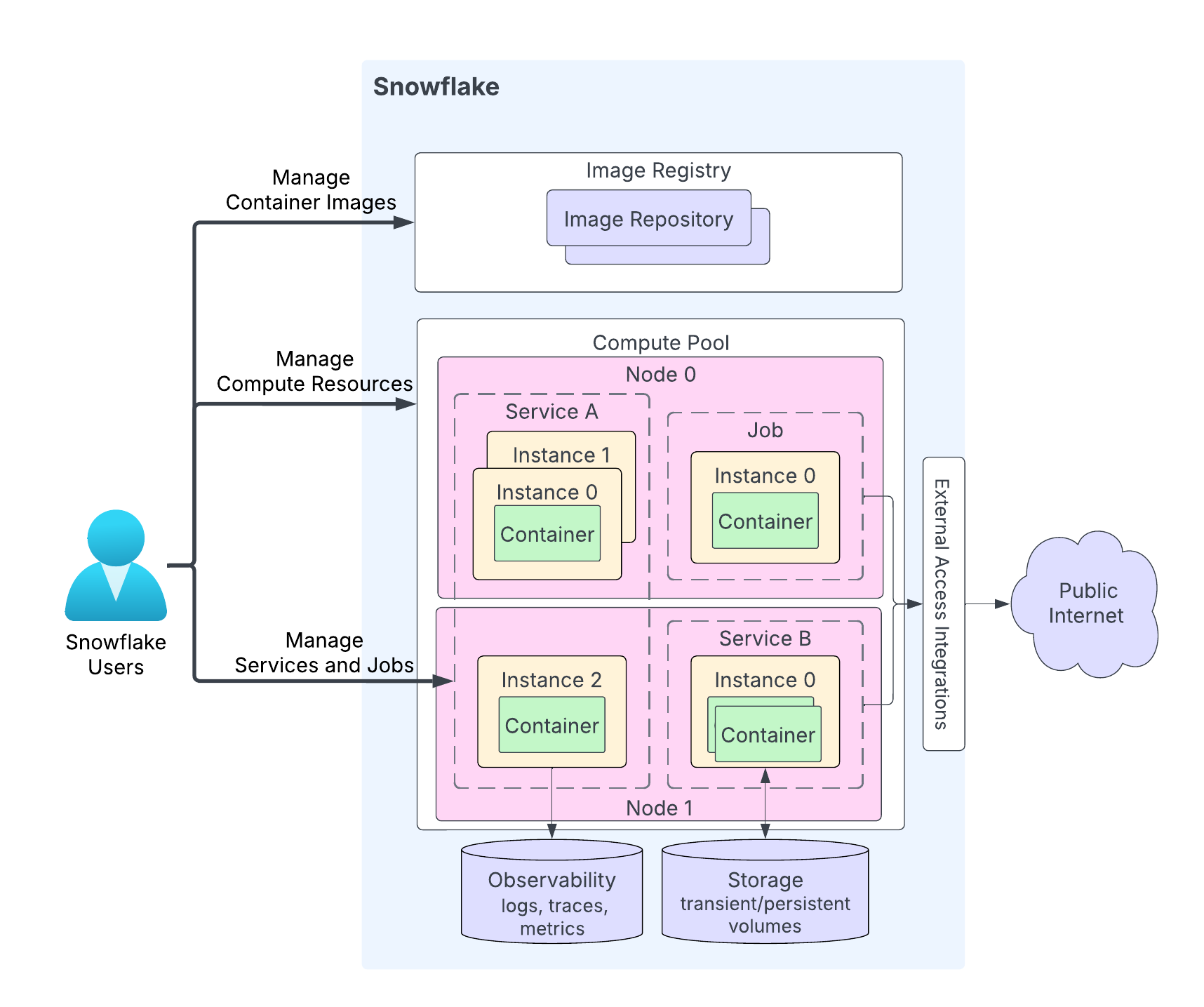
다이어그램의 주요 내용은 다음과 같습니다.
사용자는 애플리케이션 코드를 Snowflake 계정의 리포지토리에 업로드합니다. 이미지 레지스트리 서비스는 리포지토리에 OCI 호환 이미지를 저장하기 위해 OCIv2 API 를 제공합니다. 예를 들어 Docker API 를 사용하여 이미지를 리포지토리에 업로드할 수 있습니다. 서비스를 만들 때 사용할 이미지를 지정합니다.
컴퓨팅 풀은 Snowflake가 서비스를 실행하는 곳입니다. 이 다이어그램은 두 개의 컴퓨팅 노드(노드 0과 노드 1)가 있는 컴퓨팅 풀을 보여줍니다. Snowflake는 노드에서 서비스 인스턴스를 실행합니다. 여러 서비스 인스턴스를 실행하는 경우, 리소스 요구 사항에 따라 Snowflake는 동일한 노드에서 실행하거나 여러 노드에 분산하여 실행할 수 있습니다. 예:
노드 0은 서비스 A(해당 서비스의 총 인스턴스 3개 중 2개의 인스턴스)와 하나의 작업(단일 인스턴스)을 실행 중입니다.
노드 1은 서비스 A의 세 번째 인스턴스를 실행 중이며, 이 노드는 서비스 B의 인스턴스도 실행 중입니다.
애플리케이션 코드에 따라 서비스 인스턴스는 여러 개의 컨테이너로 구성될 수 있습니다. Snowflake는 서비스 인스턴스를 여러 컴퓨팅 풀 노드에 분산할 수 있지만, 단일 서비스 인스턴스 내의 모든 컨테이너는 항상 동일한 컴퓨팅 풀 노드에서 실행됩니다.
서비스는 선택적으로 공용 인터넷과 통신할 수 있습니다.
서비스는 일시적 저장소(예: 메모리 및 로컬 디스크)와 영구 볼륨(예: 블록 볼륨)을 포함한 저장소를 사용할 수 있습니다.
Snowflake는 서비스의 로그, 추적 및 메트릭을 Snowflake 계정의 이벤트 테이블에 기록할 수 있습니다.
Snowflake는 리포지토리, 컴퓨팅 풀, 서비스를 만들고 관리할 수 있는 API를 제공합니다. 이 항목에서는 서비스 작업에 대해 설명합니다. 서비스 관리를 위한 API에는 다음이 포함됩니다.
SQL 명령:
서비스 만들기. CREATE SERVICE, EXECUTE JOB SERVICE.
서비스 변경하기. ALTER SERVICE, DROP SERVICE.
서비스에 대한 정보 얻기. SHOW SERVICES, DESCRIBE SERVICE, 기타 명령.
SQL 이외의 인터페이스: Snowflake Python API, Snowflake REST API, Snowflake CLI.
서비스 시작하기¶
애플리케이션 코드를 리포지토리 에 업로드한 후 Snowflake 계정에서 서비스를 시작할 수 있습니다. 서비스를 시작하는 데 필요한 최소 정보에는 다음이 포함됩니다.
name: 서비스의 이름입니다.
서비스 사양: 이 사양 은 Snowflake에 서비스 실행에 필요한 정보를 제공합니다. 사양은 YAML 파일입니다.
컴퓨팅 풀: Snowflake는 지정된 컴퓨팅 풀 에서 서비스를 실행합니다.
장기 실행 서비스 만들기¶
장기 실행 서비스를 만들려면 CREATE SERVICE 를 사용합니다.
대부분의 경우 아래와 같이 인라인 사양을 지정하여 서비스를 생성합니다.
Snowflake 스테이지에 저장된 서비스 사양을 참조하여 서비스를 생성합니다. 프로덕션 환경에 서비스를 배포할 때는 다음과 같이 CREATE SERVICE 명령에서 관심사 분리 설계 원칙을 적용하여 스테이지에 사양을 업로드하고 스테이지 정보를 제공할 수 있습니다.
작업 서비스 실행하기¶
작업 서비스를 만들려면 EXECUTE JOB SERVICE 를 사용합니다. 기본적으로 이 명령은 동기적으로 실행되며, 작업 서비스의 모든 컨테이너가 종료된 후 응답을 반환합니다. 선택적으로 ASYNC 매개 변수를 지정하여 작업 서비스를 비동기적으로 실행할 수 있습니다.
인라인 사양을 사용하여 작업 서비스를 실행합니다. 이 명령은 작업의 실행이 완료될 때까지 기다립니다.
ASYNC속성을 사용하여 선택적으로 이 작업을 비동기적으로 실행할 수 있습니다.비동기 작업을 실행할 때 이 헬퍼 함수 :doc:`/sql-reference/functions/spcs_wait_for`를 사용하여 작업이 완료될 때까지 기다립니다.
스테이지 정보를 사용하여 작업 서비스 실행:
여러 작업 서비스 복제본 실행하기(일괄 작업)¶
기본적으로, :doc:`/sql-reference/sql/execute-job-service`는 컴퓨팅 풀에서 하나의 작업 서비스 인스턴스를 실행하여 작업을 실행합니다. 그러나 여러 작업 서비스 복제본을 실행하여 컴퓨팅 풀 노드에 워크로드를 분산하는 것을 선택할 수도 있습니다. 예를 들어, 1,000만 개의 행 데이터 세트를 처리하기 위해 10개의 복제본을 사용하고 각 복제본이 100만 개의 행을 처리하도록 할 수 있습니다.
일괄 작업은 작업을 동시에 실행할 수 있는 작업 서비스 인스턴스(복제본이라고도 함)당 하나씩 독립적인 작업으로 분할할 수 있는 시나리오를 지원합니다. 인스턴스를 동시에 실행하는 Snowflake의 권한은 컴퓨팅 풀의 크기에 따라 달라집니다.
여러 인스턴스로 일괄 작업을 실행하려면, 표시된 바와 같이 EXECUTE JOB SERVICE의 REPLICAS 매개 변수(선택 사항)를 사용하세요. 다음 예제에서는 인스턴스가 10개 있는 작업 서비스를 실행합니다.
REPLICAS 매개 변수가 EXECUTE JOB SERVICE에 지정되어 있으면 Snowflake는 작업 컨테이너에 다음의 두 환경 변수를 채웁니다.
SNOWFLAKE_JOBS_COUNT: EXECUTE JOB SERVICE에 지정된 REPLICAS 속성의 값입니다.SNOWFLAKE_JOB_INDEX: 0부터 시작하는 작업 서비스 인스턴스의 ID입니다. 복제본이 3개 있는 경우 인스턴스 IDs는 0, 1, 2가 됩니다.
이러한 환경 변수는 작업 컨테이너가 입력을 분할하고 각 인스턴스에 처리할 특정 파티션을 할당하는 데 사용할 수 있도록 제공됩니다. 예를 들어 작업 복제본 10개로 1,000만 개의 행을 처리하는 경우 작업 인덱스가 0인 인스턴스는 1~100만 개의 행을 처리하고, 작업 인덱스가 1인 인스턴스는 100만~200만 개의 행을 처리하는 식입니다.
SHOW SERVICE INSTANCES IN SERVICE 명령을 사용하여 각 작업 서비스 인스턴스의 상태를 찾습니다.
DESCRIBE SERVICE 명령을 사용하여 전체 작업 서비스 상태를 가져옵니다. Snowflake는 다음과 같이 전체 작업 서비스 상태를 계산합니다.
인스턴스가 실패하면 작업 상태는 FAILED입니다.
모든 인스턴스가 성공적으로 완료되면 작업 상태는 DONE입니다.
현재 실행 중인 인스턴스가 있는 경우 작업 상태는 RUNNING입니다.
그렇지 않으면 작업 서비스 상태는 PENDING입니다.
사양 템플릿 사용하기¶
사양은 동일하지만 구성이 다른 여러 서비스를 생성해야 할 때가 있습니다. 예를 들어, 서비스 사양에 환경 변수 를 정의하고 동일한 사양을 사용하지만 환경 변수의 값이 다른 여러 서비스를 생성한다고 가정해 보겠습니다.
사양 템플릿을 사용하면 사양에서 필드 값에 대한 변수를 정의할 수 있습니다. 사용자는 서비스를 생성할 때 이러한 변수에 대한 값을 제공합니다.
사양 템플릿에서는 다양한 사양 필드에 대한 값으로 변수를 지정합니다. 이러한 변수를 지정하려면 {{ variable_name }} 구문을 사용합니다. 그런 다음 CREATE SERVICE 명령에서 USING 매개 변수를 지정하여 이러한 변수에 대한 값을 설정합니다.
예를 들어 다음 CREATE SERVICE 명령의 인라인 사양 템플릿은 이미지 태그 이름에 tag_name 이라는 변수를 사용합니다. 이 변수를 사용하여 각 서비스에 대해 다른 이미지 태그를 지정할 수 있습니다. 이 예제에서 USING 매개 변수는 tag_name 변수를 변수 latest 로 설정합니다.
계정의 Snowflake 스테이지에 사양 템플릿을 저장하도록 선택한 경우 CREATE SERVICE 명령에서 템플릿의 위치를 가리킬 수 있습니다.
사양에서 변수를 정의하기 위한 지침¶
사양에서 변수를 필드 값으로 정의하려면
{{ variable_name }}구문을 사용합니다.이러한 변수에는 기본값이 있을 수 있습니다. 기본값을 지정하려면 변수 선언에
default함수를 사용합니다. 예를 들어, 다음 사양은 기본값이 있는 두 개의 변수(character_name및endpoint_name)를 정의합니다.또한,
default함수에 선택적 부울 매개 변수를 지정하여 변수에 빈 값을 전달할 때 기본값을 사용할지 여부를 나타낼 수 있습니다. 다음 사양을 고려하십시오.사양에서:
character_name변수의 경우 부울 매개 변수가false로 설정됩니다. 따라서 이 매개 변수에 변수를 빈 문자열 값(‘’)으로 설정하면 기본값(“Bob”)이 사용되지 않고 값이 공백으로 유지됩니다.echo_endpoint변수의 경우 부울 매개 변수가true로 설정됩니다. 따라서 이 매개 변수에 공백 값을 전달하면 기본값(“echo-endpoint”)이 사용됩니다.
기본적으로
default함수의 부울 매개 변수는false입니다.
사양 변수에 대한 값 전달 관련 지침¶
변수 값을 제공하려면 CREATE SERVICE 명령에 USING 매개 변수를 지정합니다. USING의 일반 구문은 다음과 같습니다.
여기서
var_name은 대/소문자를 구분하며 유효한 Snowflake 식별자이어야 합니다(식별자 요구 사항 참조).var_value는 영숫자 값 또는 유효한 JSON 값일 수 있습니다.예제:
CREATE SERVICE의 USING 매개 변수는 사양 변수에 대한 값을 제공해야 합니다(사양에서 기본값을 제공하는 변수 제외). 그렇지 않으면, 오류가 반환됩니다.
예¶
다음 예제에서는 사양 템플릿을 사용하여 서비스를 만드는 방법을 보여줍니다. 이 예제의 CREATE SERVICE 명령은 인라인 사양을 사용합니다.
예제 1: 간단한 값 제공¶
자습서 1 에서는 인라인 사양을 제공하여 서비스를 만듭니다. 다음 예제는 사양에서 두 개의 변수 image_url 및 SERVER_PORT 를 정의하는 동일한 예제를 수정한 것입니다. SERVER_PORT 변수는 세 위치에서 반복된다는 점에 유의하십시오. 이렇게 하면 동일한 값을 가질 것으로 예상되는 모든 필드가 동일한 값을 갖도록 하는 변수를 사용할 수 있다는 추가적인 이점이 있습니다.
이 CREATE SERVICE 명령에서 USING 매개 변수는 두 가지 사양 변수에 대한 값을 제공합니다. image_url 값에는 슬래시와 콜론이 포함됩니다. 이 값은 영숫자 문자가 아닙니다. 따라서 예제에서는 값을 큰따옴표로 묶어 유효한 JSON 문자열 값이 되도록 합니다. 템플릿 사양은 다음 사양을 확장합니다.
예 2: JSON 값 제공¶
자습서 1에서 사양은 다음과 같이 두 개의 환경 변수(SERVER_PORT 및 CHARACTER_NAME)를 정의합니다.
이 사양은 env 필드에 대한 변수를 사용하여 템플릿화할 수 있습니다. 이를 통해 환경 변수에 대해 서로 다른 값을 설정하여 여러 서비스를 생성할 수 있습니다. 다음 CREATE SERVICE 명령은 env 필드에 변수(env_values)를 사용합니다.
CREATE SERVICE의 USING 매개 변수는 env_values 변수에 대한 값을 제공합니다. 이 값은 두 환경 변수에 대한 값을 제공하는 JSON 맵입니다.
예제 3: 목록을 변수 값으로 제공¶
자습서 2 의 사양에는 두 개의 인자가 있는 args 필드가 포함되어 있습니다.
템플릿 버전의 명세서에서는 이러한 인자를 그림과 같이 JSON 목록으로 제공할 수 있습니다.
서비스 확장하기¶
기본적으로, Snowflake는 지정된 컴퓨팅 풀에서 서비스 인스턴스를 하나 실행합니다. 과도한 워크로드를 관리하려면 시작할 서비스의 최소 인스턴스 수와 필요할 때 Snowflake가 확장할 수 있는 최대 인스턴스 수를 지정하는 MIN_INSTANCES 및 MAX_INSTANCES 속성을 설정하여 여러 서비스 인스턴스를 실행할 수 있습니다.
예
여러 서비스 인스턴스가 실행 중인 경우 Snowflake는 수신 요청을 분산하기 위해 로드 밸런서를 자동으로 제공합니다.
Snowflake는 2개 이상의 인스턴스를 사용할 수 있는 상태가 되어야 해당 서비스를 READY 상태로 간주합니다. 서비스가 준비되지 않은 상태에서는 Snowflake가 서비스에 대한 액세스를 차단하는데, 이를 통해 준비 상태가 확인될 때까지 관련 서비스 기능이나 수신 요청이 거부됩니다.
어떤 경우에는 지정된 최소 인스턴스 수보다 적은 인스턴스가 사용 가능하더라도 Snowflake에서 서비스가 준비된 상태로 간주하여 수신 요청을 전달하도록 할 수 있습니다. MIN_READY_INSTANCES 속성을 설정하면 이를 달성할 수 있습니다.
이 시나리오를 생각해 보겠습니다. 유지 관리 또는 순차적인 서비스 업그레이드 중에 Snowflake가 하나 이상의 서비스 인스턴스를 종료할 수 있습니다. 이로 인해 지정된 MIN_INSTANCES 보다 사용 가능한 인스턴스가 적어져 서비스가 READY 상태로 전환되지 않을 수 있습니다. 이러한 경우, 서비스가 계속해서 요청을 수락할 수 있도록 MIN_READY_INSTANCES 를 MIN_INSTANCES 보다 작은 값으로 설정할 수 있습니다.
예
자세한 내용은 CREATE SERVICE 섹션을 참조하십시오.
자동 확장 사용하기¶
실행 중인 서비스 인스턴스 수를 자동으로 확장하도록 Snowflake를 구성하려면 CREATE SERVICE 명령에서 MIN_INSTANCES 및 MAX_INSTANCES 매개 변수를 설정합니다. ALTER SERVICE를 사용하여 이러한 값을 변경할 수도 있습니다. 지정된 MAX_INSTANCES가 MIN_INSTANCES보다 큰 경우 자동 크기 조정이 발생합니다.
Snowflake는 지정된 컴퓨팅 풀에 최소 개수의 서비스 인스턴스를 생성하는 것으로 시작합니다. 그런 다음 Snowflake는 80% CPU 리소스 요청을 기반으로 서비스 인스턴스 수를 확장하거나 축소합니다. Snowflake는 컴퓨팅 풀 내의 CPU 사용률을 지속적으로 모니터링하여 현재 실행 중인 모든 서비스 인스턴스의 사용량 데이터를 집계합니다.
(모든 서비스 인스턴스에서) 집계된 CPU 사용량이 80%를 초과하면 Snowflake는 컴퓨팅 풀 내에 추가 서비스 인스턴스를 배포합니다. 집계된 사용량이 80% 미만으로 떨어지면 Snowflake는 실행 중인 서비스 인스턴스를 제거하여 규모를 축소합니다. 집계된 CPU사용량이 80% 미만으로 떨어지는 경우 Snowflake는 실행 중인 서비스 인스턴스를 제거하여 규모를 축소합니다. Snowflake는 빈번한 크기 조정을 방지하기 위해 5분의 안정화 기간을 사용합니다. target_instances 서비스 속성은 Snowflake에서 확장하는 대상 서비스 인스턴스 수를 보고합니다.
다음 크기 조정 동작에 유의하십시오.
서비스 인스턴스의 확장은 서비스용으로 구성된 MIN_INSTANCES 및 MAX_INSTANCES 매개 변수로 제한됩니다.
확장이 필요하고 컴퓨팅 풀 노드에 다른 서비스 인스턴스를 시작하는 데 필요한 리소스 용량이 부족한 경우 컴퓨팅 풀 자동 크기 조정이 트리거될 수 있습니다. 자세한 내용은 컴퓨팅 풀 노드 자동 크기 조정 섹션을 참조하십시오.
서비스를 생성할 때 MAX_INSTANCES 및 MIN_INSTANCES 매개 변수를 지정하지만 서비스 사양 파일에서 서비스 인스턴스의 CPU 및 메모리 요구 사항을 지정하지 않으면 자동 크기 조정이 이루어지지 않습니다.Snowflake는 MIN_INSTANCES 매개 변수에 지정된 인스턴스 수로 시작하며 크기가 자동으로 조정되지 않습니다.
서비스 일시 중단하기¶
장기간 실행되는 서비스는 컴퓨팅 풀 리소스를 소모하여 비용이 발생하지만, 의미 있는 성능을 발휘하지 않을 때는 서비스를 일시 중단할 수 있습니다. 컴퓨팅 풀 노드에서 활동 중인 서비스나 작업이 없는 경우, Snowflake의 컴퓨팅 풀 자동 일시 중단 메커니즘이 풀을 일시 중단하여 비용을 절감합니다.
서비스를 일시 중단하려면 ALTER SERVICE … SUSPEND 를 명시적으로 호출하여 서비스를 일시 중단하거나 CREATE SERVICE 또는 ALTER SERVICE 를 사용하여 AUTO_SUSPEND_SECS 속성을 설정함으로써 Snowflake가 서비스를 자동으로 일시 중단하는 유휴 기간을 정의할 수 있습니다.
![]() 미리 보기 기능 — 공개
미리 보기 기능 — 공개
AUTO_SUSPEND_SECS 속성을 사용하여 Snowpark Container Services 서비스의 자동 일시 중단을 구성하는 것은 미리 보기 기능 입니다.
AUTO_SUSPEND_SECS 속성을 설정하면 아직 일시 중단되지 않은 서비스가 AUTO_SUSPEND_SECS 초 이상 유휴 상태인 경우 Snowflake가 자동으로 서비스를 일시 중단합니다. 다음 두 가지가 모두 해당하면 서비스는 유휴 상태입니다.
해당 서비스에 대한 서비스 함수 호출을 포함하는 쿼리가 현재 실행되고 있지 않습니다.
서비스 상태는 RUNNING 입니다.
조심
자동 일시 중단은 서비스 함수 호출에 의해 시작된 데이터 처리를 추적하지 않으며, 서비스 함수가 반환된 후에도 처리가 계속됩니다. 현재 구현에서 자동 일시 중단은 유입 및 서비스 간 통신도 추적하지 않습니다. 따라서 이러한 기능을 제공하는 서비스에 대해 자동 일시 중단을 활성화하면 잠재적으로 진행 중인 프로세스가 중단될 수 있으므로 사용하지 않아야 합니다.
Snowflake가 서비스를 일시 중단하면 컴퓨팅 풀의 모든 서비스 인스턴스를 종료합니다. 컴퓨팅 풀에서 실행 중인 다른 서비스가 없고 컴퓨팅 풀에 대해 자동 일시 중단이 구성된 경우, Snowflake는 컴퓨팅 풀 노드도 일시 중단합니다. 따라서 비활성 컴퓨팅 풀에 대한 비용을 지불하지 않아도 됩니다.
또한 다음 사항에 유의하십시오.
작업 서비스에는 자동 일시 중단 기능이 지원되지 않습니다.
자동 일시 중단은 현재 서비스 유휴 시점을 결정할 때 서비스 기능 트래픽만 추적하고 수신 트래픽은 추적하지 않기 때문에 공용 엔드포인트가 있는 서비스에서는 지원되지 않습니다.
서비스 수정 및 삭제하기¶
서비스 또는 작업 서비스를 만들고 나면 다음 작업을 수행할 수 있습니다.
DROP SERVICE 명령을 사용하여 스키마에서 서비스를 제거할 수 있습니다(Snowflake는 모든 서비스 컨테이너를 종료함).
<service_name>!SPCS_CANCEL_JOB 함수를 호출하여 작업 서비스를 취소할 수 있습니다. 작업을 취소하면 Snowflake가 작업 실행이 중지되고 작업 실행에 할당된 리소스를 제거합니다.
ALTER SERVICE 명령을 사용하여 서비스를 수정할 수 있습니다(예: 서비스 일시 중단 또는 재개, 실행 중인 인스턴스 개수 변경, 새 서비스 사양을 사용하여 서비스를 다시 배포하도록 Snowflake에 지시).
참고
작업 서비스는 변경할 수 없습니다.
서비스 종료하기¶
서비스를 일시 중단(ALTER SERVICE … SUSPEND)하거나 서비스를 삭제(DROP SERVICE)하면 Snowflake는 모든 서비스 인스턴스를 종료합니다. 마찬가지로 서비스 코드를 업그레이드(ALTER SERVICE … <fromSpecification>)하는 경우, Snowflake는 한 번에 1개의 서비스 인스턴스를 종료하고 다시 배포하는 방식으로 롤링 업그레이드 를 적용합니다.
서비스 인스턴스를 종료할 때, Snowflake는 먼저 각 서비스 컨테이너에 SIGTERM 신호를 보냅니다. 컨테이너에는 신호를 처리하고 30초의 유예 기간을 두고 종료하는 옵션이 있습니다. 그렇지 않으면, 유예 기간이 경과한 후 Snowflake는 컨테이너의 모든 프로세스를 종료합니다.
서비스 코드 업데이트하기 및 서비스 재배포하기¶
서비스가 생성된 후 ALTER SERVICE … <fromSpecification> 명령을 사용하여 서비스 코드를 업데이트하고 서비스를 재배포합니다.
먼저 수정한 애플리케이션 코드를 이미지 리포지토리에 업로드합니다. 그런 다음 ALTER SERVICE 명령을 실행하여 서비스 사양을 인라인으로 제공하거나 Snowflake 스테이지에서 사양 파일의 경로를 지정합니다. 예:
요청을 받으면 Snowflake는 새 코드를 사용하여 서비스를 다시 배포합니다.
참고
CREATE SERVICE … <fromSpecification> 명령을 실행하면 Snowflake가 제공된 이미지의 특정 버전을 기록합니다. 다음 시나리오에서 Snowflake는 리포지토리의 이미지가 업데이트된 경우에도 동일한 이미지 버전을 배포합니다.
일시 중단된 서비스가 재개되는 경우(ALTER SERVICE … RESUME 사용).
자동 크기 조정으로 서비스 인스턴스가 더 추가되는 경우.
클러스터 유지 관리 중에 서비스 인스턴스가 다시 시작되는 경우.
하지만 ALTER SERVICE … <fromSpecification>으로 호출하면 Snowflake가 해당 이미지의 리포지토리에 있는 최신 버전을 사용합니다.
서비스 소유자인 경우 DESCRIBE SERVICE 명령의 출력에는 아래와 같이 이미지 요약(사양에서 sha256 필드의 값)이 포함된 서비스 사양이 포함됩니다.
ALTER SERVICE는 서비스와의 통신에 영향을 미칠 수 있습니다(서비스 사용하기 참조).
ALTER SERVICE … <fromSpecification>을 통해 엔드포인트가 제거되거나 엔드포인트를 사용하기 위해 필요한 관련 권한이 제거되면(사양 참조의 serviceRoles 참조) 서비스에 대한 액세스가 실패합니다. 자세한 내용은 서비스 사용하기 섹션을 참조하십시오.
업그레이드가 진행되는 동안 새 연결이 새 버전으로 라우팅될 수 있습니다. 새 서비스 버전이 이전 버전과 호환되지 않으면 모든 활성 서비스의 사용이 중단됩니다. 예를 들어, 서비스 함수를 사용하는 진행 중인 쿼리가 실패할 수 있습니다.
참고
컨테이너로 네이티브 앱의 일부인 서비스 코드를 업데이트할 때 SYSTEM$WAIT_FOR_SERVICES 시스템 함수를 사용하여 네이티브 앱 설정 스크립트를 일시 중지하여 서비스가 완전히 업그레이드될 수 있도록 할 수 있습니다. 자세한 내용은 앱 업그레이드(레거시) 섹션을 참조하십시오.
롤링 업데이트 모니터링하기¶
여러 서비스 인스턴스가 실행 중인 경우, Snowflake는 서비스 인스턴스의 ID 를 기준으로 내림차순으로 롤링 업데이트를 수행합니다. 서비스 업데이트를 모니터링하려면 다음 명령을 사용합니다.
DESCRIBE SERVICE 및 SHOW SERVICES:
서비스가 업그레이드 중인 경우 출력의
is_upgrading열에 TRUE 가 표시됩니다.출력의
spec_digest열은 현재 서비스 사양의 사양 요약을 나타냅니다. 이 명령은 주기적으로 실행할 수 있으며,spec_digest값이 변경되면 서비스 업그레이드가 트리거되었음을 나타냅니다.spec_digest는is_upgrading이 FALSE 로 변경된 이후에만 사용되며, 그 외에는 아직 서비스 업그레이드가 진행 중입니다.아래에 설명된 대로 모든 인스턴스가 최신 버전으로 업데이트되었는지 확인하려면 SHOW SERVICE INSTANCES IN SERVICE 명령을 사용합니다.
SHOW SERVICE INSTANCES IN SERVICE:
출력의
status열은 롤링 업그레이드가 진행되는 동안 각 개별 서비스 인스턴스의 상태를 제공합니다. 업그레이드하는 동안 사용자는 TERMINATING에서 PENDING으로, PENDING에서 READY로 전환되는 등 각 서비스 인스턴스 전환 상태를 확인할 수 있습니다.서비스 업그레이드 중에는 이 명령의 출력에 있는
spec_digest열이 항상 최신 사양 다이제스트를 반환하는 SHOW SERVICES 와 다른 값으로 표시될 수 있습니다. 이 차이는 단순히 서비스 업그레이드가 진행 중이며 서비스 인스턴스가 여전히 이전 버전의 서비스를 실행하고 있음을 나타냅니다.
서비스에 대한 정보 가져오기¶
다음 명령을 사용할 수 있습니다.
서비스의 속성 및 상태를 검색하려면 DESCRIBE SERVICE 명령을 사용합니다. 출력은 모든 서비스 속성을 반환합니다.
권한이 있는 현재 서비스(작업 서비스 포함)를 목록으로 표시하려면 SHOW SERVICES 명령을 사용합니다. 출력은 이러한 서비스에 대한 속성 및 상태 중 일부를 제공합니다.
기본적으로 출력에는 현재 데이터베이스 및 스키마의 서비스가 목록으로 표시됩니다. 또는 다음 범위를 지정할 수 있습니다. 예:
계정, 특정 데이터베이스 또는 특정 스키마에 있는 서비스 나열: 예제: 서비스가 속한 데이터베이스 또는 스키마에 관계없이 IN ACCOUNT 필터를 사용하여 Snowflake 계정에 있는 서비스를 나열합니다. 이는 계정의 여러 데이터베이스와 스키마에서 생성된 Snowflake 서비스가 있는 경우 유용합니다. 다른 모든 명령과 마찬가지로 SHOW SERVICES IN ACCOUNTS는 권한으로 제어되며, 사용 중인 역할에 보기 권한이 있는 서비스만 반환합니다.
IN DATABASE 또는 IN SCHEMA를 지정하여 현재(또는 지정된) 데이터베이스 또는 스키마에 있는 서비스를 나열할 수도 있습니다.
컴퓨팅 풀에서 실행 중인 서비스 나열: 예를 들어, IN COMPUTE POOL 필터를 사용하여 컴퓨팅 풀에서 실행 중인 서비스를 목록으로 표시합니다.
접두사로 시작하거나 패턴과 일치하는 서비스를 나열: LIKE 및 STARTS WITH 필터를 적용하여 이름별로 서비스를 필터링할 수 있습니다.
작업 서비스를 목록에 나열하거나 목록에서 작업 서비스 제외: SHOW JOB SERVICES 또는 SHOW SERVICES EXCLUDE JOBS를 사용하여 작업 서비스만 나열하거나 작업 서비스를 제외할 수 있습니다.
이러한 옵션을 조합하여 SHOW SERVICES 출력을 사용자 지정할 수도 있습니다.
서비스 인스턴스의 속성을 검색하려면 SHOW SERVICE INSTANCES IN SERVICE 명령을 사용합니다.
서비스 인스턴스의 속성 및 상태를 검색하려면 SHOW SERVICE CONTAINERS IN SERVICE 명령을 사용합니다.
지정된 시간 범위 내에서 실행된 작업의 작업 내역을 가져오려면 GET_JOB_HISTORY 함수를 호출합니다.
특정 시간 이후 서비스 상태(작업 서비스 상태 포함)를 대기하고 검색하려면 <service_name>!SPCS_WAIT_FOR 함수를 호출합니다.
서비스 모니터링하기¶
Snowpark Container Services는 계정의 컴퓨팅 풀과 해당 풀에서 실행 중인 서비스를 모니터링하는 도구를 제공합니다. 자세한 내용은 Snowpark Container Services: 모니터링 서비스 섹션을 참조하십시오.
서비스 사용하기¶
서비스를 만든 후에는 서비스를 만든 계정과 동일한 계정의 사용자가 서비스를 사용할 수 있습니다. 다이어그램에 표시된 대로 서비스를 사용하는 방법은 세 가지가 있습니다. 사용자는 필요한 권한을 가진 역할에 액세스할 수 있어야 합니다.
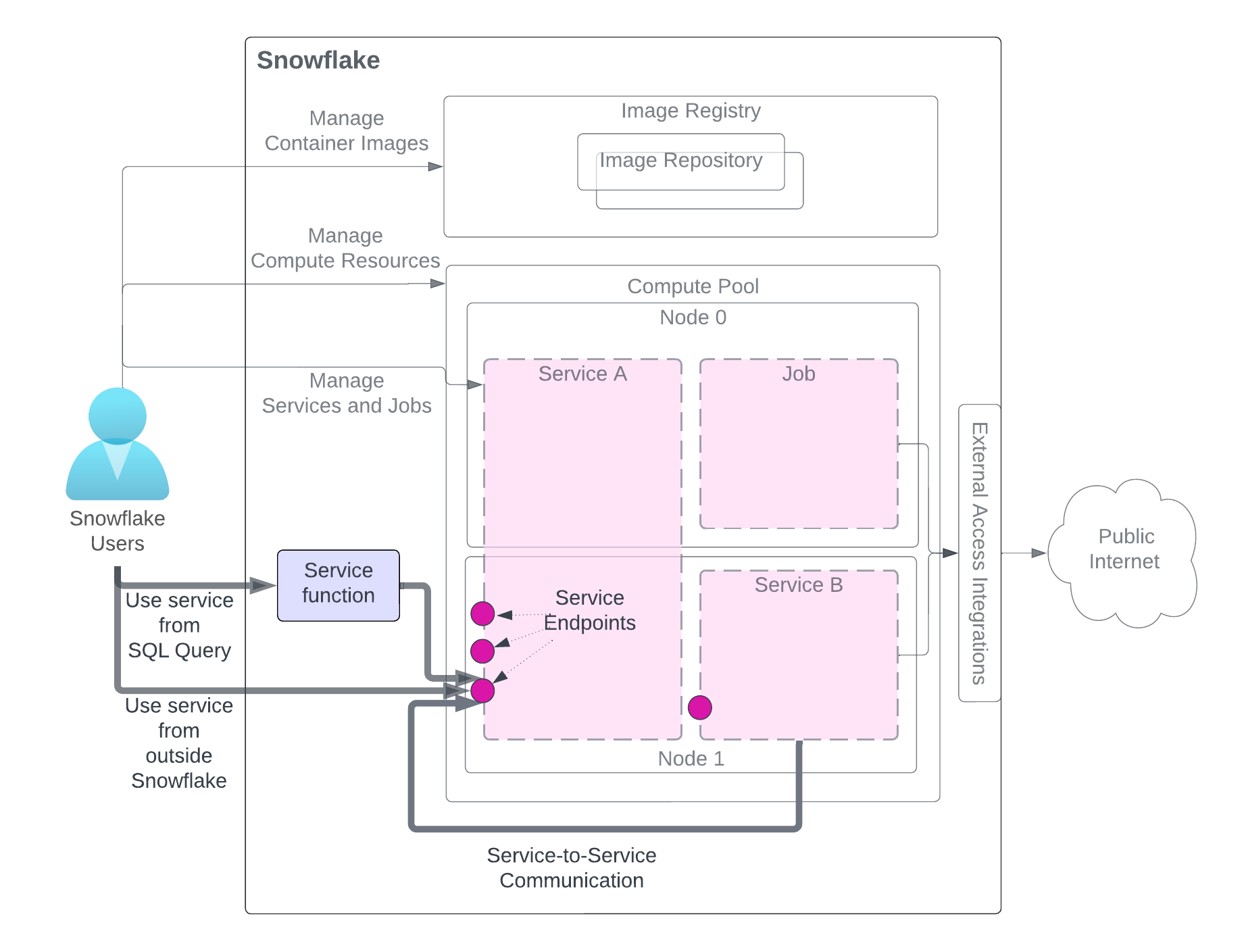
다이어그램에는 서비스 사용 방법이 강조되어 있으며, 그 외 서비스 관련 구성 요소는 명확성을 위해 회색으로 표시되어 있습니다. 서비스 구성 요소에 대한 자세한 설명은 이 페이지의 시작 부분에 있는 다이어그램 섹션을 참조하십시오.
SQL 쿼리에서 서비스(:ref:`Service 함수 <label-snowpark_containers_service_communicating_service_function>`) 사용: 서비스와 관련된 사용자 정의 함수(UDF)인 서비스 함수를 생성하여 SQL 쿼리에서 사용하고 서비스가 제공하는 사용자 지정 데이터 처리를 활용합니다. 예를 보려면 자습서 1 을 참조하십시오.
Snowflake 외부에서 서비스 사용 (수신): 하나 이상의 서비스 엔드포인트를 공개로 선언하여 서비스에 대한 네트워크 수신 액세스를 허용할 수 있습니다. 이는 웹 앱을 빌드하는 데 사용하거나 Snowflake 데이터를 통해 API를 노출하는 데 사용할 수 있습니다. 예를 보려면 자습서 1 을 참조하십시오.
**다른 서비스에서 서비스 사용**(서비스 간 통신): 서비스는 서비스 간 통신을 위해 Snowflake에서 할당된 서비스 DNS 이름을 사용하여 서로 통신할 수 있습니다. 예제는 :doc:`자습서 4<tutorials/advanced/tutorial-4>`를 참조하세요.
다이어그램에서 볼 수 있듯이 이러한 방법 중 하나를 사용하여 서비스와 통신할 때 서비스가 노출하는 엔드포인트에 요청을 보내고 결과를 얻습니다.
참고
서비스 함수는 작업 서비스와 통신하는 데 사용할 수 없습니다.
다음 섹션에서는 세부 정보를 제공합니다.
서비스 함수: SQL 쿼리에서 서비스 사용하기¶
서비스 함수는 CREATE FUNCTION(Snowpark Container Services) 를 사용하여 생성하는 사용자 정의 함수(UDF)입니다. 그러나 UDF 코드를 직접 작성하는 대신 UDF를 서비스 엔드포인트와 연결합니다. 서비스 함수는 HTTP 프로토콜(spec.endpoints 필드(선택 사항) 참조)을 지원하는 서비스 엔드포인트와만 연결할 수 있습니다.
예를 들어 자습서 1 에서는 서비스 사양에 정의된 대로 하나의 엔드포인트(echoendoint)를 노출하는 echo_service 라는 서비스를 만듭니다.
echoendpoint 는 해당 포트(8080)를 나타내는 사용자에게 친숙한 엔드포인트 이름입니다. 이 서비스 엔드포인트와 통신하려면 다음과 같이 SERVICE 및 ENDPOINT 매개 변수를 제공하여 서비스 함수를 만듭니다.
AS 매개 변수는 서비스 코드에 대한 HTTP 경로를 제공합니다. 이 경로 값은 서비스 코드에서 가져옵니다. 예를 들어, 다음 코드 라인은 자습서 1 의 service.py 에서 가져온 것입니다.
다음과 같은 SELECT 문에서 서비스 함수를 호출합니다.
Snowflake는 요청을 연결된 서비스 엔드포인트와 경로로 보냅니다.
참고
서비스 함수는 작업이 아닌 서비스와 통신하는 데 사용됩니다. 즉, (작업이 아니라) 서비스만 서비스 함수와 연결할 수 있습니다.
데이터 교환 형식¶
서비스 함수와 애플리케이션 컨테이너 간의 데이터 교환을 위해 Snowflake는 외부 함수가 사용하는 것과 동일한 형식을 따릅니다(데이터 형식 참조). 예를 들어 테이블(input_table)에 데이터 행이 저장되어 있다고 가정합니다.
이 데이터를 서비스로 보내려면 다음 행을 매개 변수로 전달하여 서비스 함수를 호출합니다.
Snowflake는 요청 본문에 다음 형식의 데이터 행 배치를 사용하여 일련의 요청을 컨테이너에 보냅니다.
그런 다음 컨테이너는 다음 형식으로 출력을 반환합니다.
표시된 출력 예에서는 결과가 행(“a”, “b”, …)이 있는 1열 테이블이라고 가정합니다.
일괄 처리 구성하기¶
CREATE FUNCTION 및 ALTER FUNCTION 명령은 서비스에서 처리하는 데이터 일괄 처리 방법을 구성하는 매개 변수를 지원합니다….
배치 크기 구성하기
MAX_BATCH_ROWS 매개 변수를 사용하여 배치 크기, 즉 한 번의 요청으로 Snowflake가 서비스에 보내는 최대 행 수를 제한할 수 있습니다. 이를 통해 전송되는 데이터의 양을 제어할 수 있습니다. 또한 서비스가 여러 인스턴스 또는 동시 요청을 지원하는 경우 병렬로 처리할 수 있는 더 작은 배치가 더 많이 발생할 수도 있습니다.
오류 처리
배치 오류 처리에
ON_BATCH_FAILURE,MAX_BATCH_RETRIES및BATCH_TIMEOUT_SECS매개 변수를 사용할 수 있습니다.
예를 들어 다음 ALTER FUNCTION 명령은 my_echo_udf 서비스 함수의 MAX_BATCH_ROWS 및 MAX_BATCH_RETRIES 매개 변수를 구성합니다.
서비스 함수를 생성하고 관리하는 데 필요한 권한¶
서비스 함수를 생성하고 관리하려면 역할에 다음 권한이 필요합니다.
현재 역할은 CREATE FUNCTION 또는 ALTER FUNCTION 명령에 참조된 엔드포인트에 대해 부여된 서비스 역할이 있어야 합니다.
SQL 쿼리에서 서비스 함수를 사용하려면 현재 세션에 서비스 함수에 대한 사용 권한이 있는 역할이 있어야 하며, 서비스 함수의 소유자 역할에 연결된 서비스 엔드포인트에 대한 서비스 역할이 부여되어야 합니다.
다음 예제 스크립트는 서비스 함수를 만들고 사용할 수 있는 권한을 부여하는 방법을 보여줍니다.
수신: Snowflake 외부에서 서비스 사용하기¶
서비스 사양에서 하나 이상의 엔드포인트를 공개로 선언하여 사용자가 공용 엔드포인트에서 서비스를 사용할 수 있도록 할 수 있습니다. 사용자는 서비스를 생성한 것과 동일한 Snowflake 계정의 Snowflake 사용자여야 합니다.
HTTP 엔드포인트를 통해서만 수신이 허용됩니다(spec.endpoints 필드(선택 사항) 참조).
수신 인증¶
사용자는 해당 엔드포인트에 액세스할 수 있는 서비스 역할이 부여된 경우에만 공용 엔드포인트에 액세스할 수 있습니다. (서비스 엔드포인트에 액세스하는 데 필요한 권한(서비스 역할) 참조).
그런 다음 사용자는 브라우저를 사용하거나 프로그래밍 방식으로 공용 엔드포인트에 액세스할 수 있습니다.
브라우저를 사용하여 공용 엔드포인트에 액세스하기: 사용자가 브라우저를 사용하여 공용 엔드포인트에 액세스하면 Snowflake는 자동으로 사용자를 로그인 페이지로 리디렉션합니다. 사용자는 로그인하려면 Snowflake 자격 증명을 제공해야 합니다. 로그인에 성공하면 사용자는 엔드포인트에 액세스할 수 있습니다. 백그라운드에서 사용자 로그인은 Snowflake에서 OAuth 토큰을 생성합니다. 그런 다음 OAuth 토큰은 서비스 엔드포인트에 요청을 보내는 데 사용됩니다.
예를 보려면 자습서 1 을 참조하십시오.
프로그래밍 방식으로 공용 엔드포인트에 액세스: 프로그래밍 방식 클라이언트가 엔드포인트에 액세스하는 방법은 다음 세 가지가 있습니다.
프로그래밍 방식 액세스 토큰(PAT) 사용: 애플리케이션이 해당 ID를 나타내기 위해 요청의
Authorization헤더에 있는 토큰을 엔드포인트에 전달합니다.키 페어 인증 사용: 애플리케이션이 키 페어를 사용하여 JWT를 교환하고, JWT를 Snowflake와 교환하여 OAuth 토큰을 얻은 후 해당 ID를 나타내기 위해 요청의
Authorization헤더에 있는 OAuth 토큰을 엔드포인트에 전달합니다.Python Connector 사용: 애플리케이션이 Python 커넥터를 사용하여 세션 토큰을 생성한 후 해당 ID를 나타내기 위해 요청의
Authorization헤더에 있는 세션 토큰을 엔드포인트에 전달합니다.
관련 예제는 :doc:`자습서 8<tutorials/advanced/tutorial-8-access-public-endpoint-programmatically>`을 참조하세요.
수신 요청의 사용자별 헤더¶
공용 엔드포인트에 대한 요청이 도착하면 Snowflake는 HTTP 요청과 함께 다음 헤더를 자동으로 컨테이너에 전달합니다.
컨테이너 코드는 선택적으로 헤더를 읽고, 호출자가 누구인지 파악하고, 다양한 사용자에 대한 컨텍스트별 사용자 지정을 적용할 수 있습니다. 또한 Snowflake는 선택적으로 Sf-Context-Current-User-Email 헤더를 포함할 수 있습니다. 이 헤더를 포함하려면 Snowflake 지원 에 문의하십시오.
서비스 간 통신¶
서비스 인스턴스는 TCP (HTTP 포함)를 통해 서로 직접 통신할 수 있습니다. 이는 동일한 서비스에 속하는 인스턴스와 다른 서비스에 속하는 인스턴스 모두에 해당됩니다.
인스턴스는 서비스 사양에 선언된 엔드포인트 에서만 통신(요청)을 수신할 수 있습니다. 클라이언트(요청을 보내는 서비스)는 해당 엔드포인트에 연결하기 위해 필요한 역할과 권한을 가지고 있어야 합니다(서비스 엔드포인트에 액세스하는 데 필요한 권한(서비스 역할) 참조).
기본적으로 서비스 인스턴스는 선언된 엔드포인트에서 동일한 서비스의 다른 인스턴스에 연결할 수 있습니다. 더 넓게 보면, 서비스의 소유자 역할 은 동일한 소유자 역할을 가진 서비스의 엔드포인트에 연결할 수 있는 권한을 가집니다.
클라이언트 서비스가 다른 소유자 역할을 가진 서비스의 엔드포인트에 연결하려면 클라이언트 서비스의 소유자 역할에 해당 엔드포인트를 호출하기 위해 다른 서비스의 엔드포인트에 대한 액세스 권한을 부여하는 서비스 역할 이 필요합니다. 자세한 내용은 서비스 엔드포인트에 액세스하는 데 필요한 권한(서비스 역할) 섹션을 참조하십시오.
(보안 등의 이유로) 서비스가 서로 통신하지 못하도록 하려면 다른 Snowflake 역할을 사용하여 해당 서비스를 생성하십시오.
서비스 인스턴스는 서비스 IP 주소 또는 서비스 인스턴스 IP 주소를 사용하여 연결할 수 있습니다.
IP 주소를 사용하는 요청은 로드 밸런서로 라우팅되며, 로드 밸런서는 무작위로 선택된 서비스 인스턴스로 요청을 라우팅합니다.
서비스 인스턴스 IP 주소를 사용하는 요청은 특정 서비스 인스턴스로 직접 라우팅됩니다.
portRange필드를 사용하여 정의된 엔드포인트에 연결할 때는 서비스 인스턴스 IP 를 사용해야 합니다(spec.endpoints 필드(선택 사항) 참조).
IP 주소는 모두 Snowflake가 각 서비스에 자동으로 할당하는 DNS 이름을 사용하여 검색할 수 있습니다. DNS 를 사용하여 특정 인스턴스에 연결할 수 없습니다. 예를 들어 서비스 인스턴스 DNS 이름을 사용하여 URL 을 구성하는 것은 의미가 없습니다. 서비스 인스턴스 DNS 이름을 사용하여 특정 서비스 인스턴스를 참조할 수 있는 방법이 없기 때문입니다.
2025_01 동작 변경 번들 이 활성화된 경우 SHOW SERVICE INSTANCES IN SERVICE 명령의 출력에 서비스 인스턴스 IP 주소가 표시됩니다.
서비스 간 통신 예제는 :doc:`자습서 4</developer-guide/snowpark-container-services/tutorials/advanced/tutorial-4>`를 참조하세요.
서비스 간 통신을 허용하기 위해서만 서비스 엔드포인트를 생성하는 경우에는 TCP 프로토콜을 사용해야 한다는 점에 유의하십시오(spec.endpoints 필드(선택 사항) 참조).
서비스 DNS 이름¶
DNS 이름 형식은 다음과 같습니다.
SHOW SERVICES (또는 DESCRIBE SERVICE)를 사용하여 서비스의 DNS 이름을 가져옵니다. 앞의 DNS 이름은 정규화된 이름입니다. 동일한 스키마에서 생성된 서비스는 <service-name> 만 사용하여 통신할 수 있습니다. 다른 스키마 또는 데이터베이스에 있는 서비스는 <service-name>.<hash> 또는 정규화된 이름(<service-name>.<hash>.svc.spcs.internal)과 같은 해시를 제공해야 합니다.
SYSTEM$GET_SERVICE_DNS_DOMAIN 함수를 사용하여 주어진 스키마에 대한 DNS 도메인을 찾습니다. DNS 해시 도메인은 현재 버전의 스키마에만 해당됩니다. 다음 사항을 참고하십시오.
해당 스키마 또는 해당 데이터베이스의 이름이 변경되더라도 해시는 변경되지 않습니다.
스키마를 삭제했다가 다시 만들면(예: CREATE OR REPLACE SCHEMA) 새 스키마는 새 해시를 갖게 됩니다. 스키마를 UNDROP 으로 변경하면 해시는 동일하게 유지됩니다.
DNS 이름에는 다음과 같은 제한 사항이 있습니다.
서비스 이름은 유효한 DNS 레이블이어야 합니다. (https://www.ietf.org/rfc/rfc1035.html#section-2.3.1 참조). 그렇지 않으면 서비스 생성이 실패합니다.
Snowflake는 서비스 이름의 밑줄(_)을 DNS 이름의 대시(-)로 바꿉니다.
DNS 이름은 동일한 계정에서 실행되는 서비스 사이에서 Snowflake 내의 내부 통신에만 사용됩니다. 인터넷에서는 액세스할 수 없습니다.
서비스 인스턴스 DNS 이름¶
서비스 인스턴스 DNS 이름 형식은 다음과 같습니다.
서비스의 각 인스턴스마다 하나씩 서비스 인스턴스 IP 주소 목록으로 확인합니다. DNS 가 반환하는 IP 주소 목록의 순서는 보장되지 않습니다. 이 DNS 이름은 DNS API에서만 사용해야 하며 URL 에서 호스트 이름으로 사용해서는 안 됩니다. 예상되는 것은 애플리케이션이 DNS API와 함께 이 호스트 이름을 사용하여 서비스 인스턴스 세트 IP를 수집한 다음 해당 인스턴스 IP에 프로그래밍 방식으로 직접 연결하는 것입니다.
이 IP 주소 목록을 사용하면 특정 서비스 인스턴스 간에 직접 통신할 수 있는 메시 네트워크를 만들 수 있습니다.
선택할 DNS 이름¶
서비스 간 통신에서 서비스에 연결할 때 사용할 DNS 이름을 선택할 때는 다음 사항을 고려해야 합니다.
다음 중 하나에 해당하는 경우 DNS 서비스 이름을 사용합니다.
가능한 가장 간단한 방법으로 특정 대상 포트에 액세스해야 합니다.
각 요청이 무작위로 선택된 서비스 인스턴스로 전송되기를 원합니다.
애플리케이션 프레임워크의 성능과 DNS 응답을 캐시하는 방법을 모릅니다.
다음 중 하나에 해당하는 경우 서비스 인스턴스 DNS 이름 또는 서비스 인스턴스 IP 를 사용합니다.
모든 서비스 인스턴스의 IP 주소를 검색하려고 합니다.
중간 로딩 밸런서를 건너뛰려고 합니다.
서비스 인스턴스 IP 주소를 ID로 사용하는 Ray 또는 Cassandra 등의 분산 프레임워크 또는 데이터베이스를 사용합니다.
계정에서 허용되는 서비스 유형 관리¶
Snowflake는 계정에서 생성할 수 있는 다양한 유형의 서비스(워크로드 유형)를 지원합니다. 이러한 유형에는 서비스, 작업과 같은 사용자 배포 워크로드 및 노트북, 모델 제공, ML 작업과 같이 Snowflake에서 관리하는 자사 워크로드가 포함됩니다. 워크로드 유형 목록은 ALLOWED_SPCS_WORKLOAD_TYPES 섹션을 참조하세요.
:doc:`/sql-reference/sql/show-services`를 사용하여 계정의 서비스를 나열할 때 필터를 포함하여 특정 워크로드 유형만 나열할 수 있습니다. 예를 들어, 사용자 배포 서비스만 표시합니다.
계정 수준 매개 변수 ALLOWED_SPCS_WORKLOAD_TYPES 및 DISALLOWED_SPCS_WORKLOAD_TYPES를 사용하여 Snowflake 계정에서 허용되는 워크로드 유형을 제한할 수 있습니다. 예를 들어, NOTEBOOK 워크로드만 허용하려면 다음 문을 실행합니다.
참고
DISALLOWED_SPCS_WORKLOAD_TYPES에 지정된 워크로드 유형은 배포할 수 없습니다. ALLOWED_SPCS_WORKLOAD_TYPES 및 DISALLOWED_SPCS_WORKLOAD_TYPES를 모두 구성하는 경우 허용되지 않는 목록이 우선 적용됩니다. 예를 들어, 두 매개 변수가 모두 NOTEBOOK 워크로드 유형인 경우, NOTEBOOK 워크로드는 Snowpark Container Services에서 실행할 수 없습니다.
이러한 계정 수준 매개 변수를 구성하기 전에 생성된 서비스는 계속 실행됩니다. 그러나 워크로드 유형이 허용되지 않는 서비스를 일시 중단하면 다시 시작할 수 없습니다.
이전에 생성된 허용되지 않는 유형의 서비스를 모두 삭제하려면 ALTER COMPUTE POOL … STOP ALL OF TYPE 명령을 실행합니다.
Snowflake 시크릿을 사용하여 컨테이너에 자격 증명 전달하기¶
Snowflake 관리 자격 증명을 컨테이너에 전달하려는 이유는 여러 가지가 있습니다. 예를 들어, 서비스가 외부 엔드포인트(Snowflake 외부)와 통신할 수 있으며, 이 경우 애플리케이션 코드가 사용할 자격 증명 정보를 컨테이너에 제공해야 합니다.
자격 증명을 제공하려면 먼저 Snowflake 시크릿 오브젝트에 자격 증명을 저장합니다. 그런 다음 서비스 사양에서 containers.secrets 를 사용하여 사용할 시크릿 오브젝트와 컨테이너 내부의 위치를 지정합니다. 이러한 자격 증명을 컨테이너의 환경 변수에 전달하거나 컨테이너의 로컬 파일에서 사용할 수 있도록 설정할 수 있습니다.
Snowflake 시크릿 지정하기¶
Snowflake 시크릿을 이름 또는 참조로 지정합니다(참조는 Native Application 시나리오에서만 적용 가능).
이름으로 Snowflake 시크릿 전달: 시크릿 이름을
snowflakeSecret필드 값으로 전달할 수 있습니다.선택 사항으로
<secret-name>을snowflakeSecret값으로 직접 지정할 수도 있습니다.참조로 Snowflake 시크릿 전달: Snowpark Container Services를 사용하여 Native App(컨테이너가 포함된 앱)을 생성할 때 앱 제작자와 컨슈머는 서로 다른 Snowflake 계정을 사용합니다. 경우에 따라 설치된 Snowflake Native App이 APPLICATION 오브젝트 외부에 있는 컨슈머 계정의 기존 시크릿 오브젝트에 액세스해야 하는 경우도 있습니다. 이 경우 개발자는 “참조에 의한 시크릿” 사양 구문을 사용하여 다음과 같이 자격 증명을 처리할 수 있습니다.
사양에서는 시크릿 참조 이름을 제공하기 위해
objectName대신 ``objectReference``를 사용합니다.
컨테이너 내부의 시크릿 배치 지정하기¶
Snowflake에 시크릿을 환경 변수로 컨테이너에 저장하거나 로컬 컨테이너 파일에 쓰도록 지시할 수 있습니다.
시크릿을 환경 변수로 전달하기¶
컨테이너에 Snowflake 시크릿을 환경 변수로 전달하려면 containers.secrets 필드에 envVarName 을 포함시킵니다.
secretKeyRef 값은 Snowflake 시크릿의 유형에 따라 달라집니다. 가능한 값은 다음과 같습니다.
Snowflake 시크릿이
password유형인 경우username또는password.Snowflake 시크릿이
generic_string유형인 경우secret_string.
Snowflake는 서비스가 생성된 후에 환경 변수로 전달된 시크릿을 업데이트하지 않습니다.
예 1: 비밀번호 유형의 시크릿을 환경 변수로 전달하기¶
이 예에서는 password 유형의 다음 Snowflake 시크릿 오브젝트를 생성합니다.
이 Snowflake 시크릿 오브젝트를 컨테이너의 환경 변수(예: LOGIN_USER 및 LOGIN_PASSWORD)에 제공하려면 사양 파일에 다음 containers.secrets 필드를 추가하십시오.
이 예제에서 snowflakeSecret 값은 생성 중인 서비스와 다른 스키마에 시크릿을 저장할 수 있으므로 정규화된 오브젝트 이름입니다.
이 예의 containers.secrets 필드는 두 snowflakeSecret 오브젝트의 목록입니다.
첫 번째 오브젝트는 Snowflake 시크릿 오브젝트의
username을 컨테이너의LOGIN_USER환경 변수에 매핑합니다.두 번째 오브젝트는 Snowflake 시크릿 오브젝트의
password를 컨테이너의LOGIN_PASSWORD환경 변수에 매핑합니다.
예 2: 일반_문자열 유형의 시크릿을 환경 변수로 전달하기¶
이 예에서는 generic_string 유형의 다음 Snowflake 시크릿 오브젝트를 생성합니다.
이 Snowflake 시크릿 오브젝트를 컨테이너의 환경 변수(예: GENERIC_SECRET)에 제공하려면 사양 파일에 다음 containers.secrets 필드를 추가하십시오.
로컬 컨테이너 파일에 시크릿 쓰기¶
로컬 컨테이너 파일에서 애플리케이션 컨테이너가 Snowflake 시크릿을 사용할 수 있도록 하려면 containers.secrets 필드를 포함시킵니다. 로컬 컨테이너 파일에서 애플리케이션 컨테이너가 Snowflake 시크릿을 사용할 수 있게 하려면, containers.secrets 에 directoryPath 를 포함시킵니다.
Snowflake는 지정된 이 directoryPath 에 시크릿에 필요한 파일을 채우며, secretKeyRef 를 지정할 필요는 없습니다. 시크릿 유형에 따라 Snowflake는 사용자가 제공한 디렉터리 경로 아래의 컨테이너에 다음 파일을 생성합니다.
Snowflake 시크릿이
password유형인 경우username및password.Snowflake 시크릿이
generic_string유형인 경우secret_string.Snowflake 시크릿이
oauth2유형인 경우access_token.
참고
서비스가 생성된 후 Snowflake 시크릿 오브젝트가 업데이트되면 Snowflake가 실행 중인 컨테이너에서 해당 시크릿 파일을 업데이트합니다.
예 1: 로컬 컨테이너 파일에 비밀번호 유형의 시크릿 전달하기¶
이 예에서는 password 유형의 다음 Snowflake 시크릿 오브젝트를 생성합니다.
이러한 자격 증명을 로컬 컨테이너 파일에서 사용할 수 있도록 하려면 사양 파일에 다음 containers.secrets 필드를 추가하십시오.
서비스를 시작하면 Snowflake가 컨테이너 내에 이름이 /usr/local/creds/username 및 /usr/local/creds/password 인 파일 두 개를 생성합니다. 그러면 애플리케이션 코드에서 이러한 파일을 읽을 수 있습니다.
예 2: 로컬 컨테이너 파일에 generic_string 유형의 시크릿 전달하기¶
이 예에서는 generic_string 유형의 다음 Snowflake 시크릿 오브젝트를 생성합니다.
로컬 컨테이너 파일에 이 Snowflake 시크릿 오브젝트를 제공하려면 사양 파일에 다음 containers.secrets 필드를 추가합니다.
서비스를 시작하면 Snowflake가 컨테이너 내에 이름이 /usr/local/creds/secret_string 인 파일을 생성합니다.
예 3: 로컬 컨테이너 파일에 oauth2 유형의 시크릿 전달하기¶
이 예에서는 oauth2 유형의 다음 Snowflake 시크릿 오브젝트를 생성합니다.
이러한 자격 증명을 로컬 컨테이너 파일에서 사용할 수 있도록 하려면 사양 파일에 다음 containers.secrets 필드를 추가하십시오.
Snowflake는 OAuth 시크릿 오브젝트에서 액세스 토큰을 가져오고 컨테이너에 /usr/local/creds/access_token 을 생성합니다.
서비스가 oauth2 유형의 시크릿을 사용하는 경우 해당 서비스는 해당 시크릿을 사용하여 인터넷 대상에 액세스해야 합니다. EAI(External Access Integration) 에서 Oauth 시크릿을 허용해야 하며, 그렇지 않으면 CREATE SERVICE 또는 EXECUTE JOB SERVICE가 실패합니다. 이 추가 EAI 요구 사항은 oauth2 유형의 시크릿에만 적용되며 다른 유형의 시크릿에는 적용되지 않습니다.
요컨대, 이러한 서비스를 생성하는 일반적인 단계는 다음과 같습니다.
(앞서 표시한 대로) oauth2 유형의 시크릿을 만듭니다.
서비스에서 시크릿을 사용할 수 있도록 EAI를 만듭니다. 예:
사양에
containers.secrets필드를 포함하는 서비스를 만듭니다. 또한 oauth2 시크릿 사용을 허용하기 위해 EAI를 포함하도록 선택적 EXTERNAL_ACCESS_INTEGRATIONS 속성을 지정합니다.예시 CREATE SERVICE(인라인 사양 포함) 명령:
송신에 대한 자세한 내용은 서비스 송신 구성 섹션을 참조하십시오.
지침 및 제한 사항¶
자세한 내용은 Snowpark Container Services: 지침 및 제한 사항 섹션을 참조하십시오.