Snowpark Container Services: Verwenden von Diensten¶
Snowpark Container Services ermöglicht Ihnen die einfache Bereitstellung, Verwaltung und Skalierung von containerisierten Anwendungen. Nachdem Sie eine Anwendung erstellt und das Anwendungsimage in ein Repository Ihres Snowflake-Kontos hochgeladen haben, können Sie Ihre Anwendungscontainer als Dienst ausführen.
Ein Dienst repräsentiert Snowflake, das Ihre containerisierte Anwendung auf einem Computepool ausführt, der eine Sammlung virtueller Maschinenknoten (VM) ist. Es gibt zwei Typen von Diensten:
Langlaufende Dienste. Ein lang laufender Dienst ist wie ein Webservice, der nicht automatisch endet. Nachdem Sie einen Dienst erstellt haben, verwaltet Snowflake den aktiven Dienst. Wenn z. B. ein Dienstcontainer aus irgendeinem Grund anhält, startet Snowflake diesen Container neu, damit der Dienst ohne Unterbrechung ausgeführt wird.
Jobdienste. Ein Jobdienst wird beendet, wenn Ihr Code beendet wird, ähnlich wie eine gespeicherte Prozedur. Wenn alle Container beendet werden, ist auch der Jobdienst beendet.
Das folgende Diagramm zeigt die Architektur eines Dienstes:
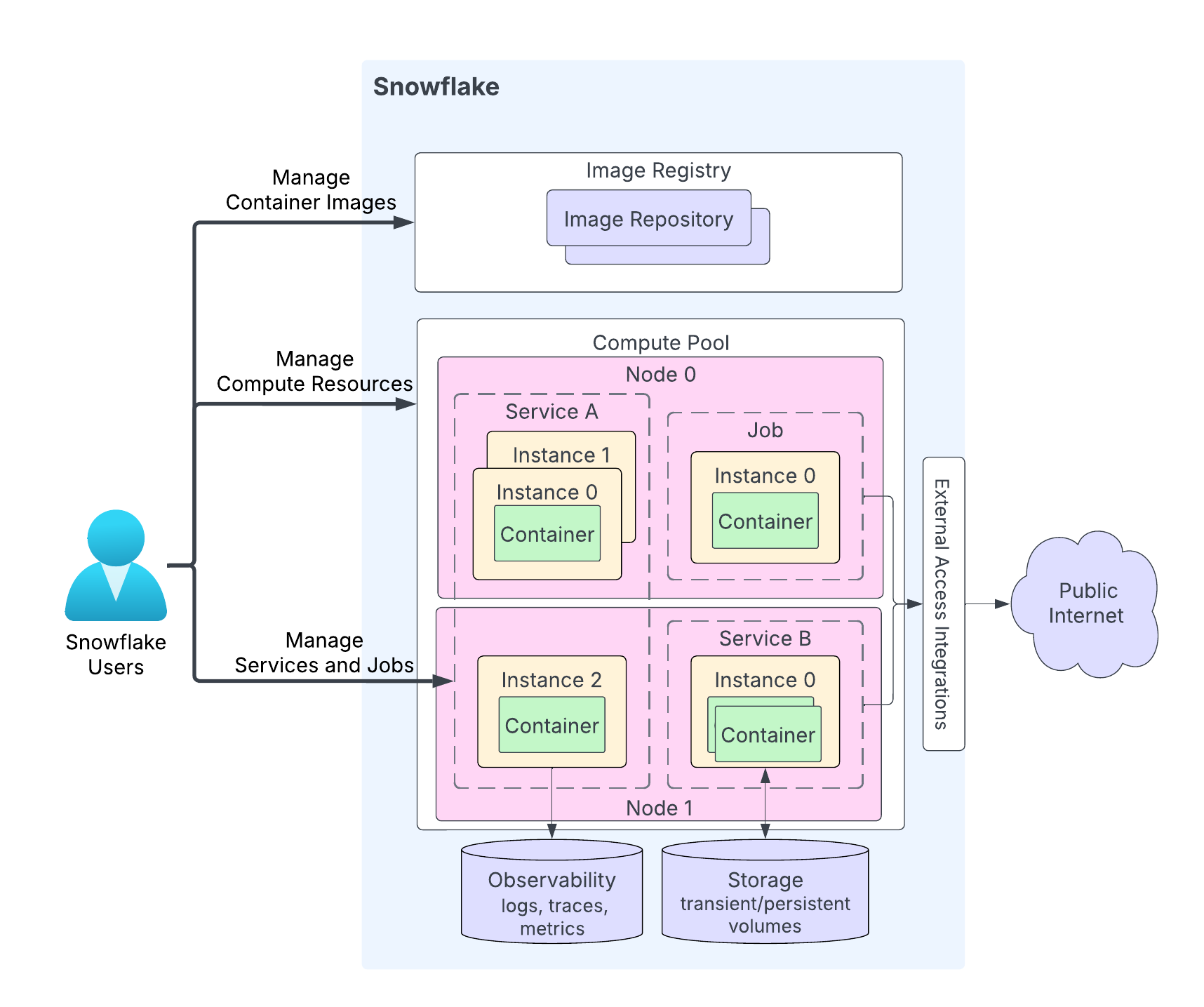
Die Höhepunkte des Diagramms sind die folgenden:
Benutzer laden ihren Anwendungscode in ein Repository in ihrem Snowflake-Konto hoch. Der Image Registry-Dienst dient der OCIv2-API zum Speichern von OCI-konformen Images in einem Repository. Sie können zum Beispiel Docker-API verwenden, um Images in ein Repository hochzuladen. Wenn Sie einen Dienst erstellen, geben Sie das zu verwendende Image an.
Ein Computepool ist der Ort, an dem Snowflake Ihre Dienste ausführt. Das Diagramm zeigt einen Computepool mit zwei Serverknoten (Knoten 0 und Knoten 1). Snowflake führt Ihre Dienstinstanz auf einem Knoten aus. Wenn Sie mehrere Dienstinstanzen ausführen, kann Snowflake diese je nach Ressourcenbedarf auf demselben Knoten ausführen oder sie auf mehrere Knoten verteilen. Beispiel:
Auf Knoten 0 laufen der Dienst A (zwei Instanzen der insgesamt drei Instanzen dieses Dienstes) und ein Job (mit einer einzigen Instanz).
Auf Knoten 1 läuft die dritte Instanz von Dienst A. Auf diesem Knoten läuft auch eine Instanz von Dienst B.
Abhängig von Ihrem Anwendungscode kann eine Dienstinstanz aus mehreren Containern bestehen. Während Snowflake die Instanzen eines Dienstes auf mehrere Computepool-Knoten verteilen kann, laufen alle Container innerhalb einer einzelnen Dienstinstanz immer auf demselben Computepool-Knoten.
Dienste können optional mit dem öffentlichen Internet kommunizieren.
Ein Dienst kann Speicher verwenden, einschließlich transientem Speicher (z. B. Arbeitsspeicher und lokale Festplatte) und persistenten Volumes (z. B. Blockspeicher-Volumes).
Snowflake kann Protokolle, Ablaufverfolgungen und Metriken von Ihren Diensten in der Ereignistabelle in Ihrem Snowflake-Konto aufzeichnen.
Snowflake bietet Ihnen APIs, um Repositories, Computepools und Dienste zu erstellen und zu verwalten. Unter diesem Thema wird die Verwendung von Diensten erläutert. APIs für die Verwaltung von Diensten umfassen die folgenden Punkte:
SQL-Befehle:
Erstellen eines Dienstes. CREATE SERVICE, EXECUTE JOB SERVICE.
Ändern eines Dienstes. ALTER SERVICE, DROP SERVICE.
Abrufen von Informationen über einen Dienst. SHOW SERVICES, DESCRIBE SERVICE, und andere Befehle.
Nicht-SQL-Weboberflächen: Snowflake Python-APIs, Snowflake-REST APIs, und Snowflake-CLI.
Starten von Diensten¶
Nachdem Sie Ihren Anwendungscode in ein Repository in Ihrem Snowflake-Konto hochgeladen haben, können Sie einen Dienst starten. Für das Starten eines Dienstes sind mindestens folgende Informationen erforderlich:
Ein Name: Name des Dienstes.
Eine Dienstspezifikation: Diese Spezifikation liefert Snowflake die Informationen, die zum Konfigurieren und Ausführen Ihres Dienstes erforderlich sind. Die Spezifikation ist eine YAML-Datei.
Ein Computepool: Snowflake führt Ihren Dienst in dem angegebenen Computepool aus.
Langlaufenden Dienst erstellen¶
Verwenden Sie CREATE SERVICE, um einen langlaufenden Dienst zu erstellen.
In den meisten Fällen erstellen Sie einen Dienst, indem Sie eine Inline-Spezifikation angeben, wie unten gezeigt:
Erstellen Sie einen Dienst, indem Sie auf eine in einem Snowflake-Stagingbereich gespeicherte Dienstspezifikation verweisen. Wenn Sie den Dienst in einer Produktionsumgebung bereitstellen, können Sie das Prinzip der Funktionstrennung anwenden und die Spezifikation in einen Stagingbereich hochladen, indem Sie die Staging-Informationen im Befehl CREATE SERVICE angeben, wie gezeigt:
Jobdienst ausführen¶
Verwenden Sie EXECUTE JOB SERVICE, um einen Jobdienst zu erstellen. Standardmäßig wird dieser Befehl synchron ausgeführt und gibt eine Antwort zurück, nachdem alle Container des Jobdienstes beendet wurden. Sie können optional den Parameter ASYNC angeben, um den Jobdienst asynchron auszuführen.
Führen Sie einen Jobdienst mit einer Inline-Spezifikation aus. Der Befehl wartet, bis der Job die Ausführung abgeschlossen hat:
Sie können diesen Job optional asynchron ausführen, indem Sie die Eigenschaft
ASYNCverwenden.Wenn Sie einen asynchronen Job ausführen, verwenden Sie die Hilfsfunktion <service_name>!SPCS_WAIT_FOR, um auf den Abschluss des Jobs zu warten.
Führen Sie einen Jobdienst unter Verwendung von Stagingbereich-Informationen aus:
Mehrere Replikate eines Jobdiensts ausführen (Batchjobs)¶
Standardmäßig führt EXECUTE JOB SERVICE eine einzelne Jobdienstinstanz auf einem Computepool aus, um den Job auszuführen. Sie können jedoch mehrere Jobdienstreplikate ausführen, um die Workload auf die Computepool-Knoten zu verteilen. Sie könnten beispielsweise 10 Replikate verwenden, um ein Datenset mit 10 Millionen Zeilen zu verarbeiten, wobei jedes 1 Million Zeilen verarbeitet.
Batchjobs unterstützen Szenarien, in denen die Arbeit in unabhängige Aufgaben partitioniert werden kann – eine pro Jobdienstinstanz (auch als Replikat bezeichnet) –die potenziell gleichzeitig ausgeführt werden können. Die Fähigkeit von Snowflake, die Instanzen gleichzeitig auszuführen, hängt von der Größe des Computepools ab.
Um einen Batchjob mit mehreren Instanzen auszuführen, verwenden Sie den optionalen REPLICAS-Parameter von EXECUTE JOB SERVICE wie gezeigt. Das folgende Beispiel führt einen Jobdienst mit 10 Instanzen aus:
Wenn der REPLICAS-Parameter als EXECUTE JOB SERVICEangegeben ist, füllt Snowflake die folgenden beiden Umgebungsvariablen im Jobcontainer aus:
SNOWFLAKE_JOBS_COUNT: Der Wert der REPLICAS-Eigenschaft, die für den EXECUTE JOB SERVICE angegeben ist.SNOWFLAKE_JOB_INDEX: Die ID der Jobdienstinstanz, beginnend bei 0. Wenn Sie drei Replikate haben, werden die IDs der Instanz 0, 1 und 2 sein.
Diese Umgebungsvariablen werden bereitgestellt, sodass ein Jobcontainer sie verwenden kann, um die Eingabe zu partitionieren und jeder Instanz eine bestimmte Partition für die Verarbeitung zuzuweisen. Wenn Sie beispielsweise 10 Millionen Zeilen mit 10 Jobreplikaten verarbeiten, würde die Instanz mit dem Jobindex 0 Zeilen von 1 bis 1 Million verarbeiten, die Instanz mit Jobindex 1 würde Zeilen von 1 Million bis 2 Millionen verarbeiten und so weiter.
Verwenden Sie den Befehl SHOW SERVICE INSTANCES IN SERVICE, um den Status der einzelnen Jobdienstinstanzen zu ermitteln.
Verwenden Sie den Befehl DESCRIBE SERVICE, um den Gesamtstatus des Jobdienstes abzurufen. Snowflake berechnet den Gesamtstatus des Jobdienstes wie folgt:
Wenn eine Instanz fehlschlägt, lautet der Jobstatus FAILED.
Wenn alle Instanzen erfolgreich abgeschlossen wurden, lautet der Jobstatus DONE.
Wenn derzeit eine Instanz ausgeführt wird, lautet der Jobstatus RUNNING.
Andernfalls ist der Status des Jobdienstes PENDING.
Verwenden von Spezifikationsvorlagen¶
Es kann vorkommen, dass Sie mehrere Dienste mit der gleichen Spezifikation, aber mit unterschiedlichen Konfigurationen erstellen möchten. Nehmen Sie zum Beispiel an, dass Sie in einer Dienstspezifikation eine Umgebungsvariable definieren und Sie mehrere Services erstellen möchten, die dieselbe Spezifikation, aber unterschiedliche Werte für die Umgebungsvariable verwenden.
Spezifikationsvorlagen ermöglichen es Ihnen, Variablen für Feldwerte in der Spezifikation zu definieren. Wenn Sie einen Service erstellen, geben Sie Werte für diese Variablen an.
In einer Spezifikationsvorlage geben Sie Variablen als Werte für verschiedene Spezifikationsfelder an. Verwenden Sie die Syntax {{ variable_name }}, um diese Variablen anzugeben. Geben Sie dann im Befehl CREATE SERVICE den Parameter USING an, um Werte für diese Variablen festzulegen.
Die Inline-Spezifikationsvorlage im folgenden CREATE SERVICE-Befehl verwendet beispielsweise eine Variable namens tag_name für den Namen des Image-Tags. Sie können diese Variable verwenden, um für jeden Dienst ein anderes Image-Tag anzugeben. In diesem Beispiel setzt der Parameter USING die Variable tag_name auf den Wert latest.
Wenn Sie die Spezifikationsvorlage in einem Snowflake-Stagingbereich Ihres Kontos speichern möchten, können Sie im CREATE SERVICE-Befehl auf den Speicherort der Vorlage verweisen:
Richtlinien für das Definieren von Variablen in einer Spezifikation¶
Verwenden Sie die Syntax
{{ variable_name }}, um Variablen als Feldwerte in der Spezifikation zu definieren.Diese Variablen können Standardwerte haben. Um den Standardwert festzulegen, verwenden Sie die Funktion
defaultin der Variablendeklaration. Die folgende Spezifikation definiert zum Beispiel zwei Variablen (character_nameundendpoint_name) mit Standardwerten.Zusätzlich können Sie einen optionalen booleschen Parameter für die Funktion
defaultübergeben, um anzugeben, ob Sie den Standardwert verwenden möchten, wenn ein leerer Wert für die Variable übergeben wird. Betrachten Sie folgende Spezifikation:Erläuterungen zu dieser Spezifikation:
Für die Variable
character_namewird der boolesche Parameter auffalsegesetzt. Wenn die Variable also auf eine leere Zeichenfolge (‚‘) für diesen Parameter eingestellt wird, bleibt der Wert leer und der Standardwert („Bob“) wird nicht verwendet.Für die Variable
echo_endpointwird der boolesche Parameter auftruegesetzt. Wenn Sie diesem Parameter einen leeren Wert übergeben, wird daher der Standardwert („echo-endpoint“) verwendet.
Standardmäßig hat der boolesche Parameter für die Funktion
defaultden Wertfalse.
Richtlinien für die Übergabe von Werten für Spezifikationsvariablen¶
Geben Sie im Befehl CREATE SERVICE den Parameter USING an, um Werte für Variablen bereitzustellen. Die allgemeine Syntax für USING lautet:
Wobei:
var_nameunterscheidet zwischen Groß- und Kleinschreibung und sollte ein gültiger Snowflake-Bezeichner sein (siehe Anforderungen an Bezeichner).var_valuekann entweder ein alphanumerischer Wert oder ein gültiger JSON-Wert sein.Beispiele:
Der Parameter USING in CREATE SERVICE muss Werte für die Spezifikationsvariablen bereitstellen (mit Ausnahme der Variablen, für die die Spezifikation Standardwerte vorsieht). In folgenden Fällen wird ein Fehler zurückgegeben:
Beispiele¶
Diese Beispiele zeigen das Erstellen von Diensten mithilfe von Spezifikationsvorlagen. Die CREATE SERVICE-Befehle in diesen Beispielen verwenden Inline-Spezifikationen.
Beispiel 1: Einfache Werte bereitstellen¶
In Tutorial 1 erstellen Sie einen Dienst, indem Sie eine Inline-Spezifikation bereitstellen. Das folgende Beispiel ist eine modifizierte Version davon, in der die Spezifikation zwei Variablen definiert: image_url und SERVER_PORT. Beachten Sie, dass die Variable SERVER_PORT an drei Stellen wiederholt wird. Dies hat den zusätzlichen Vorteil der Verwendung von Variablen, die sicherstellen, dass alle Felder, die denselben Wert haben sollen, auch denselben Wert haben.
In diesem CREATE SERVICE-Befehl liefert der Parameter USING Werte für die beiden Spezifikationsvariablen. Der Wert image_url enthält Schrägstriche und einen Doppelpunkt. Dies sind keine alphanumerischen Zeichen. Daher wird der Wert in dem Beispiel in doppelte Anführungszeichen gesetzt, um ihn zu einem gültigen JSON-Zeichenfolgewert zu machen. Die Spezifikation der Vorlage erweitert die folgende Spezifikation:
Beispiel 2: JSON-Wert bereitstellen¶
In Tutorial 1 definiert die Spezifikation zwei Umgebungsvariablen (SERVER_PORT und CHARACTER_NAME), wie gezeigt:
Sie können diese Angabe mit Hilfe einer Variable für das Feld env als Vorlage verwenden. So können Sie mehrere Dienste mit unterschiedlichen Werten für die Umgebungsvariablen erstellen. Der folgende CREATE SERVICE-Befehl verwendet eine Variable (env_values) für das Feld „env“.
Der Parameter USING in CREATE SERVICE liefert einen Wert für die Variable env_values. Der Wert ist eine JSON-Zuordnung, die Werte für die beiden Umgebungsvariablen bereitstellt.
Beispiel 3: Liste als Variablenwert bereitstellen¶
In Tutorial 2 enthält die Spezifikation das Feld args, das zwei Argumente enthält.
In einer Vorlagenversion der Spezifikation können Sie diese Argumente wie gezeigt als JSON-Liste angeben:
Skalieren von Diensten¶
Standardmäßig führt Snowflake eine Instanz des Dienstes in dem angegebenen Computepool aus. Um umfangreiche Workloads zu bewältigen, können Sie mehrere Dienstinstanzen ausführen, indem Sie die Eigenschaften MIN_INSTANCES und MAX_INSTANCES spezifizieren, die die Mindestanzahl der zu startenden Instanzen des Dienstes und die maximale Anzahl der Instanzen angeben, auf die Snowflake bei Bedarf skalieren kann.
Beispiel
Wenn mehrere Dienstinstanzen ausgeführt werden, stellt Snowflake automatisch einen Load Balancer zum Verteilen der eingehenden Anforderungen bereit.
Snowflake betrachtet den Dienst erst dann als READY, wenn mindestens zwei Instanzen verfügbar sind. Solange der Dienst nicht bereit ist, blockiert Snowflake den Zugriff darauf, d. h. die damit verbundenen Funktionen oder Anfragen werden verweigert, bis die Bereitschaft bestätigt ist.
In einigen Fällen möchten Sie vielleicht, dass Snowflake den Dienst auch dann als bereit betrachtet (und eingehende Anfragen weiterleitet), wenn weniger als die angegebenen Mindestinstanzen verfügbar sind. Sie können dies erreichen, indem Sie die Eigenschaft MIN_READY_INSTANCES festlegen.
Betrachten Sie folgendes Szenario: Während der Wartung oder eines fortlaufenden Dienst-Upgrades könnte Snowflake eine oder mehrere Dienstinstanzen beenden. Dies könnte dazu führen, dass weniger Instanzen als die angegebene MIN_INSTANCES verfügbar sind, was den Dienst daran hindert, in den Zustand READY zu gelangen. In diesen Fällen können Sie MIN_READY_INSTANCES auf einen kleineren Wert als MIN_INSTANCES setzen, um sicherzustellen, dass der Dienst weiterhin Anfragen annehmen kann.
Beispiel
Weitere Informationen dazu finden Sie unter CREATE SERVICE.
Aktivieren der automatischen Skalierung¶
Um Snowflake für die automatische Skalierung der Anzahl der ausgeführten Dienstinstanzen zu konfigurieren, legen Sie die Parameter MIN_INSTANCES und MAX_INSTANCES im Befehl CREATE SERVICE fest. Sie können auch ALTER SERVICE verwenden, um diese Werte zu ändern. Die Autoskalierung erfolgt, wenn die angegebene MAX_INSTANCES größer als MIN_INSTANCES ist.
Snowflake beginnt mit der Erstellung der Mindestanzahl von Dienstinstanzen auf dem angegebenen Computepool. Snowflake skaliert dann die Anzahl der Dienstinstanzen anhand von Ressourcenanforderungen von 80 % CPU hoch oder runter. Snowflake überwacht kontinuierlich die CPU-Auslastung innerhalb des Computepools und fasst die Nutzungsdaten aller derzeit laufenden Dienstinstanzen zusammen.
Wenn die aggregierte CPU-Nutzung (für alle Dienstinstanzen) 80 % übersteigt, stellt Snowflake eine zusätzliche Dienstinstanz im Computepool bereit. Wenn die aggregierte CPU-Nutzung unter 80 % fällt, skaliert Snowflake herunter, indem eine der aktiven Dienstinstanzen entfernt wird. Snowflake verwendet ein fünfminütiges Stabilisierungsfenster, um häufiges Skalieren zu verhindern. Die Diensteigenschaft target_instances gibt die Zielanzahl der Dienstinstanzen an, auf die Snowflake zugreift.
Beachten Sie das folgende Skalierungsverhalten:
Die Skalierung der Dienstinstanzen wird durch die für den Dienst konfigurierten Parameter MIN_INSTANCES und MAX_INSTANCES eingeschränkt.
Wenn ein Hochskalieren erforderlich ist und die Knoten des Computepools nicht über die erforderliche Ressourcenkapazität verfügen, um eine weitere Dienstinstanz zu starten, kann die automatische Skalierung des Computepools ausgelöst werden. Weitere Informationen dazu finden Sie unter Automatisches Skalieren von Computepool-Knoten.
Wenn Sie beim Erstellen eines Services die Parameter MAX_INSTANCES und MIN_INSTANCES angeben, aber in der Dienstspezifikationsdatei Ihrer Dienstinstanz keine CPU- und Arbeitsspeicheranforderungen spezifiziert sind, erfolgt keine automatische Skalierung. Snowflake beginnt dann mit der durch den Parameter MIN_INSTANCES angegebenen Anzahl von Instanzen und führt keine automatische Skalierung durch.
Einen Dienst aussetzen¶
Ein lang laufender Dienst verbraucht Ressourcen des Computepools und verursacht damit Kosten. Sie können den Dienst jedoch aussetzen, wenn er keine sinnvolle Arbeit leistet. Wenn auf einem Computepool-Knoten keine Dienste oder Aufträge aktiv sind, setzt der automatische Computepool-Aussetzungsmechanismus von Snowflake den Pool aus, um die Kosten zu senken.
Um einen Dienst auszusetzen, können Sie entweder explizit ALTER SERVICE. .. SUSPEND aufrufen, um einen Dienst auszusetzen, oder Sie setzen die Eigenschaft AUTO_SUSPEND_SECS mit CREATE SERVICE oder ALTER SERVICE, um die Leerlaufdauer festzulegen, nach der Snowflake den Dienst automatisch aussetzt.
![]() Vorschau-Feature – Offen
Vorschau-Feature – Offen
Die Konfiguration der automatischen Aussetzung eines Snowpark Container Services-Dienstes mit der Eigenschaft AUTO_SUSPEND_SECS ist ein Vorschau-Feature.
Wenn die Eigenschaft AUTO_SUSPEND_SECS gesetzt ist, setzt Snowflake einen Dienst automatisch aus, wenn er nicht bereits ausgesetzt wurde und mehr als AUTO_SUSPEND_SECS Sekunden lang inaktiv ist. Ein Dienst ist im Leerlauf, wenn beide folgenden Punkte zutreffen:
Es läuft derzeit keine Abfrage, die einen Dienstfunktion-Aufruf dieses Dienstes enthält.
Der Dienststatus lautet RUNNING.
Vorsicht
Die automatische Aussetzung verfolgt nicht die Datenverarbeitung, die durch den Aufruf einer Dienstfunktion eingeleitet wird, wenn die Verarbeitung nach der Rückkehr der Dienstfunktion fortgesetzt wird. In der aktuellen Implementierung verfolgt die automatische Aussetzung auch nicht die Eingangs- und Dienst-zu-Dienst-Kommunikation. Daher sollten Sie die automatische Aussetzung für Dienste, die solche Features anbieten, nicht aktivieren, da dies diese potenziell laufenden Prozesse stören könnte.
Wenn Snowflake einen Dienst aussetzt, werden alle Dienstinstanzen im Computepool heruntergefahren. Wenn keine anderen Dienste auf dem Computepool laufen und für den Computepool eine automatische Aussetzung konfiguriert ist, setzt Snowflake auch die Computepool-Knoten aus. So vermeiden Sie, dass Sie für einen inaktiven Computepool bezahlen müssen.
Beachten Sie auch das Folgende:
Die automatische Aussetzung wird für Jobdienste nicht unterstützt.
Die automatische Aussetzung wird bei Diensten mit öffentlichen Endpunkten nicht unterstützt, da Snowflake bei der Entscheidung, wann ein Dienst inaktiv ist, derzeit nur den Datenverkehr der Dienstfunktionen und nicht den Datenverkehr am Eingang verfolgt.
Services ändern und löschen¶
Nachdem Sie einen Service oder einen Jobdienst erstellt haben, können Sie die folgenden Aktionen durchführen:
Verwenden Sie den Befehl DROP SERVICE, um einen Service aus einem Schema zu entfernen (Snowflake beendet alle Service-Container).
Rufen Sie die Funktion <service_name>!SPCS_CANCEL_JOB zum Abbrechen eines Jobdienstes auf. Wenn Sie einen Job abbrechen, stoppt Snowflake die Ausführung des Jobs und entfernt die für die Jobausführung zugewiesenen Ressourcen.
Verwenden Sie den Befehl ALTER SERVICE, um zum Beispiel den Service zu ändern, anzuhalten oder fortzusetzen, die Anzahl der aktiven Instanzen zu ändern und Snowflake anzuweisen, Ihren Service unter Verwendung einer neuen Service-Spezifikation neu bereitzustellen.
Bemerkung
Sie können einen Jobdienst nicht ändern.
Service beenden¶
Wenn Sie einen Service aussetzen (ALTER SERVICE … SUSPEND) oder einen Service beenden (DROP SERVICE), beendet Snowflake alle Dienstinstanzen. Ähnlich verhält es sich, wenn Sie den Dienstcode aktualisieren (ALTER SERVICE … <fromSpecification>), wendet Snowflake fortlaufende Upgrades an, indem es jeweils eine Dienstinstanz beendet und neu bereitstellt.
Wenn eine Dienstinstanz beendet wird, sendet Snowflake zunächst ein SIGTERM-Signal an jeden Dienstcontainer. Der Container hat die Möglichkeit, das Signal zu verarbeiten und mit einem 30-Sekunden-Fenster ordnungsgemäß herunterzufahren. Andernfalls beendet Snowflake nach Ablauf des Zeitraums alle Prozesse im Container.
Aktualisieren des Dienstcodes und erneutes Bereitstellen des Dienstes¶
Nachdem ein Dienst erstellt wurde, verwenden Sie den Befehl ALTER SERVICE … <fromSpecification>, um den Dienstcode zu aktualisieren und den Dienst erneut bereitzustellen.
Zunächst laden Sie den geänderten Anwendungscode in Ihr Image-Repository hoch. Anschließend führen Sie den Befehl ALTER SERVICE aus, wobei Sie entweder die Dienstspezifikation inline bereitstellen oder den Pfad zu einer Spezifikationsdatei im Stagingbereich von Snowflake angeben. Beispiel:
Nach Erhalt der Anforderung stellt Snowflake den Dienst mit dem neuen Code erneut bereit.
Bemerkung
Wenn Sie den Befehl CREATE SERVICE. .. <fromSpecification> ausführen, zeichnet Snowflake die spezifische Version des bereitgestellten Images auf. Snowflake setzt in den folgenden Szenarien dieselbe Image-Version ein, auch wenn das Image im Repository aktualisiert wurde:
Wenn ein angehaltener Dienst wieder fortgesetzt wird (mit ALTER SERVICE … RESUME).
Wenn Autoscaling weitere Dienstinstanzen hinzufügt.
Wenn Dienstinstanzen während der Cluster-Wartung neu gestartet werden.
Wenn Sie jedoch ALTER SERVICE. .. <fromSpecification> aufrufen, verwendet Snowflake die neueste Version im Repository für dieses Image
Wenn Sie der Eigentümer des Services sind, enthält die Ausgabe des Befehls DESCRIBE SERVICE die Dienstspezifikation, die den Image-Digest (den Wert des Feldes sha256 in der Spezifikation) enthält, wie unten gezeigt:
ALTER SERVICE kann die Kommunikation (siehe Verwenden eines Dienstes) mit dem Dienst beeinträchtigen.
Wenn ALTER SERVICE … <fromSpecification> einen Endpunkt entfernt oder relevante Berechtigungen entfernt, die für die Nutzung eines Endpunkts erforderlich sind (siehe serviceRoles in Spezifikationsreferenz), schlägt der Zugriff auf den Service fehl. Weitere Informationen finden Sie unter Verwendung eines Dienstes.
Während des Upgrades werden neue Verbindungen möglicherweise auf die neue Version geroutet. Wenn die neue Version des Dienstes nicht abwärtskompatibel ist, wird die aktive Nutzung des Dienstes unterbrochen. Zum Beispiel können laufende Abfragen mit einer Dienstfunktion fehlschlagen.
Bemerkung
Bei der Aktualisierung von Dienstcode, der Teil einer nativen App mit Containern ist, können Sie die SYSTEM$WAIT_FOR_SERVICES-Systemfunktion verwenden, um das Skript zur Einrichtung der nativen App anzuhalten, damit die Dienste vollständig aktualisiert werden können. Weitere Informationen dazu finden Sie unter Eine App aktualisieren (Legacy).
Überwachung rollierender Aktualisierungen¶
Wenn mehrere Dienstinstanzen laufen, führt Snowflake eine rollierende Aktualisierung in absteigender Reihenfolge auf der Grundlage der ID der Dienstinstanzen durch. Verwenden Sie die folgenden Befehle, um Dienstaktualisierungen zu überwachen:
DESCRIBE SERVICE und SHOW SERVICES:
Die Spalte
is_upgradingin der Ausgabe zeigt TRUE an, wenn der Dienst aktualisiert wird.Die Spalte
spec_digestin der Ausgabe stellt den Spec Digest der aktuellen Dienstspezifikation dar. Sie können diesen Befehl in regelmäßigen Abständen ausführen; eine Änderung desspec_digest-Wertes zeigt an, dass ein Dienst-Upgrade ausgelöst wurde.spec_digestwird erst verwendet, wenn ausis_upgradingFALSE geworden ist; andernfalls ist das Dienst-Upgrade noch im Gange.Verwenden Sie den Befehl SHOW SERVICE INSTANCES IN SERVICE, um zu überprüfen, ob alle Instanzen auf die neueste Version aktualisiert wurden (siehe unten).
SHOW SERVICE INSTANCES IN SERVICE:
Die
status-Spalte in der Ausgabe enthält den Status jeder einzelnen Dienstinstanz, während das fortlaufende Upgrade läuft. Während des Upgrades werden Sie den Status der einzelnen Dienstinstanzen beobachten, wie z. B. TERMINATING zu PENDING und PENDING zu READY.Während des Dienst-Upgrades kann die Spalte
spec_digestin der Ausgabe dieses Befehls einen anderen Wert anzeigen als SHOW SERVICES, der immer den neuesten Spec Digest zurückgibt. Dieser Unterschied zeigt lediglich an, dass die Aktualisierung des Dienstes im Gange ist und die Dienstinstanzen noch die alte Version des Dienstes ausführen.
Informationen zu Diensten abrufen¶
Sie können die folgenden Befehle verwenden:
Verwenden Sie den Befehl DESCRIBE SERVICE, um die Eigenschaften und den Status eines Dienstes abzurufen. Die Ausgabe liefert alle Eigenschaften des Dienstes.
Verwenden Sie den SHOW SERVICES Befehl, um die aktuellen Dienste (einschließlich Jobdienste) aufzulisten, für die Sie Berechtigungen haben. Die Ausgabe liefert einige der Eigenschaften und den Status dieser Dienste.
In der Standardeinstellung listet die Ausgabe die Dienste in der aktuellen Datenbank und im aktuellen Schema auf. Sie können alternativ einen der folgenden Bereiche angeben. Beispiel:
Listen Sie die Dienste im Konto, in einer bestimmten Datenbank oder in einem bestimmten Schema auf: Verwenden Sie zum Beispiel den Filter IN ACCOUNT, um die Dienste in Ihrem Snowflake-Konto aufzulisten, unabhängig davon, zu welcher Datenbank oder welchem Schema die Dienste gehören. Dies ist nützlich, wenn Sie Snowflake-Dienste in mehreren Datenbanken und Schemas Ihres Kontos erstellt haben. Wie alle anderen Befehle ist auch SHOW SERVICES IN ACCOUNTS von den Berechtigungen abhängig und gibt nur die Dienste zurück, für die die von Ihnen verwendete Rolle über Anzeigeberechtigungen verfügt.
Sie können auch IN DATABASE oder IN SCHEMA angeben, um die Dienste in der aktuellen (oder angegebenen) Datenbank oder dem Schema aufzulisten.
Listen Sie die Dienste auf, die in einem Computepool ausgeführt werden: Verwenden Sie zum Beispiel den Filter IN COMPUTE POOL, um die Dienste aufzulisten, die in einem Computepool ausgeführt werden.
Auflistung der Dienste, die mit einem Präfix beginnen oder einem Muster entsprechen: Sie können die Filter LIKE und STARTS WITH anwenden, um die Dienste nach Namen zu filtern.
Auflistung von Diensten oder Ausschluss von Diensten aus der Liste: Sie können SHOW JOB SERVICES oder SHOW SERVICES EXCLUDE JOBS verwenden, um nur Dienste aufzulisten oder Dienste auszuschließen.
Sie können diese Optionen auch kombinieren, um die Ausgabe von SHOW SERVICES anzupassen.
Verwenden Sie den Befehl SHOW SERVICE INSTANCES IN SERVICE, um Eigenschaften der Dienstinstanzen abzurufen.
Verwenden Sie den SHOW SERVICE CONTAINERS IN SERVICE-Befehl, um die Eigenschaften und den Status der Dienstinstanzen abzurufen.
Rufen Sie die Funktion GET_JOB_HISTORY auf, um die Jobverläufe von Jobs abzurufen, die innerhalb eines bestimmten Zeitraums ausgeführt wurden.
Rufen Sie die Funktion <service_name>!SPCS_WAIT_FOR auf, um zu warten und den Service-Status – einschließlich des Status eines Jobdienstes – nach einer bestimmten Zeit abzurufen.
Überwachen von Diensten¶
Snowpark Container Services bietet Tools zur Überwachung der Computepools in Ihrem Konto und der darauf ausgeführten Services. Weitere Informationen dazu finden Sie unter Snowpark Container Services: Überwachen von Diensten.
Verwenden eines Dienstes¶
Nachdem Sie einen Dienst erstellt haben, können die Benutzer desselben Kontos (das den Dienst erstellt hat) ihn nutzen. Es gibt drei Methoden zur Nutzung eines Dienstes, wie in der Abbildung dargestellt. Der Benutzer benötigt Zugriff auf Rollen mit den erforderlichen Berechtigungen.
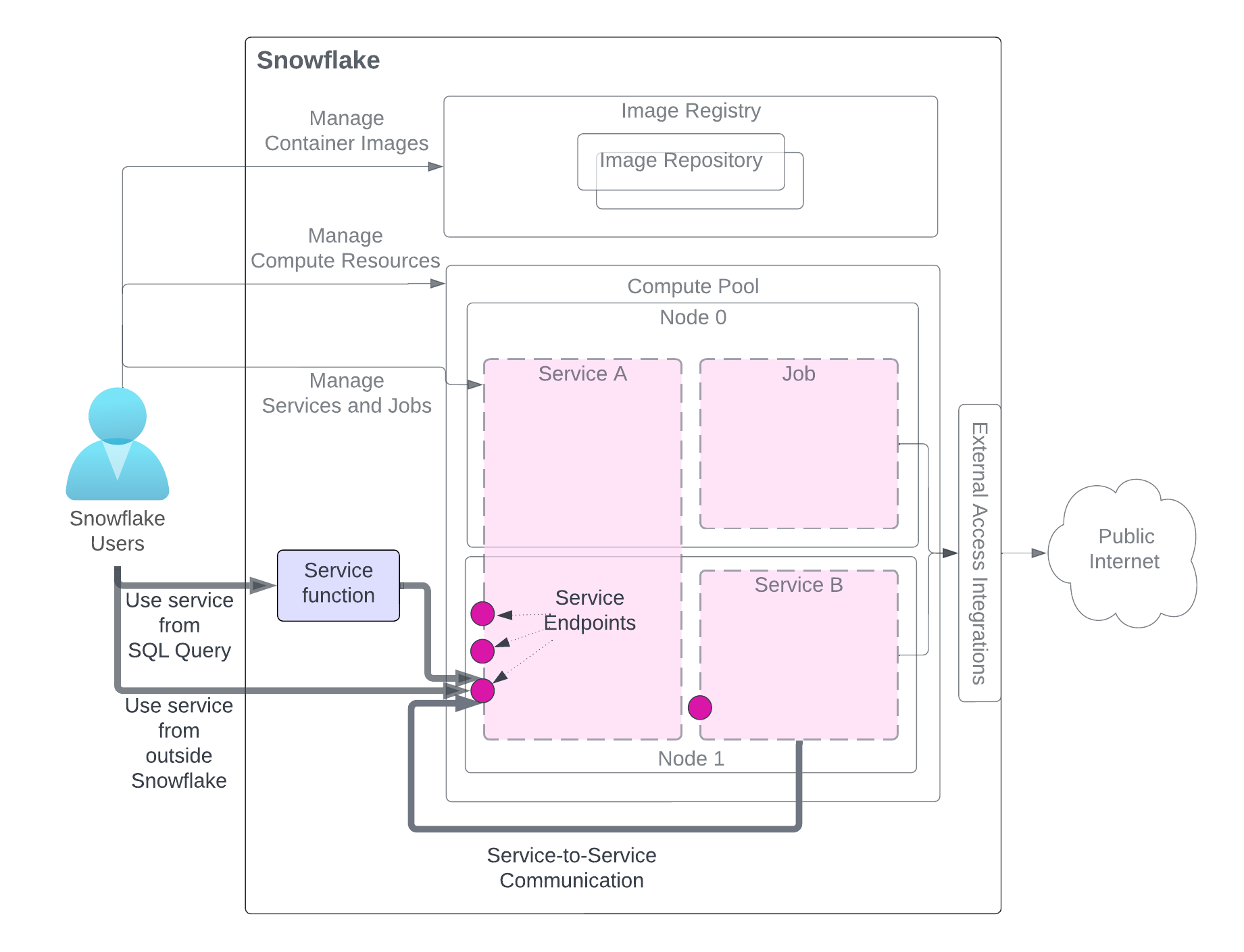
Das Diagramm hebt die Methoden zur Nutzung des Dienstes hervor, während andere dienstbezogene Komponenten zur besseren Übersichtlichkeit ausgegraut sind. Eine detaillierte Erklärung der Dienstkomponenten finden Sie in der Abbildung am Anfang dieser Seite.
Verwenden Sie den Dienst aus einer SQL-Abfrage (Dienstfunktion): Sie erstellen eine Dienstfunktion, eine benutzerdefinierte Funktion (UDF), die mit einem Dienst verknüpft ist, und verwenden sie in einer SQL-Abfrage und nutzen die benutzerdefinierte Datenverarbeitung, die Ihr Service bietet. Ein Beispiel dazu finden Sie unter Tutorial 1.
Verwenden Sie den Dienst von außerhalb von Snowflake (Eingang): Sie können einen oder mehrere Dienstendpunkte als öffentlich deklarieren, um den Zugriff auf den Dienst über Netzwerk-Eingang zu ermöglichen. Damit können Sie Webanwendungen erstellen oder APIs über Ihre Snowflake-Daten offenlegen. Ein Beispiel dazu finden Sie unter Tutorial 1.
Dienst eines anderen Dienstes verwenden (Dienst-zu-Dienst-Kommunikation): Dienste können miteinander kommunizieren, indem sie den von Snowflake zugewiesenen DNS-Dienstnamen für die Dienst-zu-Dienst-Kommunikation verwenden. Ein Beispiel finden Sie in Tutorial 4.
Wie das Diagramm veranschaulicht, senden Sie bei der Kommunikation mit einem Dienst über eine dieser Methoden Anfragen an Endpunkte, die der Dienst bereitstellt, und erhalten Ergebnisse.
Bemerkung
Dienstfunktionen können nicht zur Kommunikation mit einem Jobdienst verwendet werden.
Die folgenden Abschnitte enthalten weitere Details.
Dienstfunktionen: Verwenden eines Dienstes aus einer SQL-Abfrage¶
Eine Dienstfunktion ist eine benutzerdefinierte Funktion (UDF), die Sie mit CREATE FUNCTION (Snowpark Container Services) erstellen. Anstatt jedoch den Code von UDF direkt zu schreiben, verknüpfen Sie die UDF mit Ihrem Dienstendpunkt. Beachten Sie, dass Sie eine Dienstfunktion nur mit einem Dienstendpunkt verknüpfen können, der das Protokoll HTTP unterstützt (siehe Feld spec.endpoints (optional)).
In Tutorial 1 erstellen Sie beispielsweise einen Dienst namens echo_service, der einen Endpunkt (echoendoint) gemäß der Definition in der Dienstspezifikation bereitstellt:
echoendpoint ist ein benutzerfreundlicher Endpunktname, der den entsprechenden Port (8080) darstellt. Um mit diesem Dienstendpunkt zu kommunizieren, erstellen Sie eine Dienstfunktion, indem Sie die Parameter SERVICE und ENDPOINT wie gezeigt angeben:
Der Parameter AS stellt den HTTP-Pfad zum Dienstcode bereit. Sie erhalten diesen Pfad-Wert aus dem Dienstcode. Die folgenden Zeilen stammen zum Beispiel aus service.py in Tutorial 1.
Sie rufen die Dienstfunktion in einer SELECT-Anweisung wie der folgenden auf:
Snowflake leitet die Anfrage an den zugehörigen Dienstendpunkt und Pfad weiter.
Bemerkung
Eine Dienstfunktion wird zur Kommunikation mit einem Dienst, aber nicht mit einem Job verwendet. Mit anderen Worten: Sie können nur einen Dienst (keinen Job) mit einer Dienstfunktion verknüpfen.
Datenaustauschformat¶
Für den Datenaustausch zwischen einer Dienstfunktion und einem Anwendungscontainer folgt Snowflake demselben Format, das auch externe Funktionen verwenden (siehe Datenformate). Angenommen, Sie haben Datenzeilen in einer Tabelle (input_table) gespeichert:
Um diese Daten an Ihren Dienst zu senden, rufen Sie die Dienstfunktion auf, indem Sie diese Zeilen als Parameter übergeben:
Snowflake sendet eine Reihe von Anforderung an den Container, wobei die Batches von Datenzeilen im Anforderungstext in diesem Format vorliegen:
Der Container gibt dann die Ausgabe in folgendem Format zurück:
Die gezeigte Beispielausgabe geht davon aus, dass das Ergebnis eine einspaltige Tabelle mit Zeilen („a“, „b“ …) ist.
Batchverarbeitung konfigurieren¶
Die Befehle CREATE FUNCTION und ALTER FUNCTION unterstützen Parameter, die konfigurieren, wie Snowflake Batches von Daten verarbeitet, die von Ihrem Dienst verarbeitet werden.
Batchgröße konfigurieren
Sie können den Parameter MAX_BATCH_ROWS verwenden, um die Batchgröße zu begrenzen, d. h. die maximale Anzahl von Zeilen, die Snowflake in einer einzigen Anfrage an Ihren Dienst sendet. Dies hilft, das Volumen der übertragenen Daten zu kontrollieren. Dies kann auch zu mehr, kleineren Batches führen, die parallel verarbeitet werden können, wenn Ihr Dienst mehrere Instanzen oder gleichzeitige Anfragen unterstützt.
Fehlerbehandlung
Sie können diese Parameter für die Batch-Fehlerbehandlung verwenden:
ON_BATCH_FAILURE,MAX_BATCH_RETRIES, undBATCH_TIMEOUT_SECS.
Der folgende ALTER FUNCTION-Befehl konfiguriert zum Beispiel die Parameter MAX_BATCH_ROWS und MAX_BATCH_RETRIES der Dienstfunktion my_echo_udf:
Erforderliche Berechtigungen zum Erstellen und Verwalten von Dienstfunktionen¶
Um Dienstfunktionen zu erstellen und zu verwalten, benötigt eine Rolle die folgenden Berechtigungen:
Die aktuelle Rolle muss die Dienstrolle haben, die für den Endpunkt gewährt wird, auf den im Befehl CREATE FUNCTION oder ALTER FUNCTION verwiesen wird.
Um eine Dienstfunktion in einer SQL-Abfrage zu verwenden, muss die aktuelle Sitzung über eine Rolle mit Nutzungsberechtigung für die Dienstfunktion verfügen und die Eigentümerrolle der Dienstfunktion muss die Dienstrolle für den zugehörigen Dienstendpunkt erhalten.
Das folgende Beispielskript zeigt, wie Sie Berechtigungen zum Erstellen und Verwenden einer Dienstfunktion erteilen können:
Dateneingang: Verwenden eines Dienstes von außerhalb von Snowflake¶
Sie können einen oder mehrere Endpunkte in der Dienstspezifikation als öffentlich deklarieren, damit Benutzer den Dienst von der Öffentlichkeit aus nutzen können. Beachten Sie, dass die Benutzer Snowflake-Benutzer in demselben Snowflake-Konto sein müssen, das den Dienst erstellt hat.
Beachten Sie, dass Eingang nur mit einem HTTP-Endpunkt erlaubt ist (siehe Feld spec.endpoints (optional)).
Eingang-Authentifizierung¶
Ein Benutzer kann auf einen öffentlichen Endpunkt zugreifen, wenn ihm eine Dienstrolle gewährt wird, die den Zugriff auf diesen Endpunkt erlaubt. (Siehe Erforderliche Berechtigungen für den Zugriff auf die Dienstendpunkte (Dienstrollen)).
Dann können Benutzer über einen Browser oder programmgesteuert auf den öffentlichen Endpunkt zugreifen.
Zugriff auf einen öffentlichen Endpunkt über einen Browser: Wenn der Benutzer einen Browser verwendet, um auf einen öffentlichen Endpunkt zuzugreifen, leitet Snowflake den Benutzenden automatisch auf eine Anmeldeseite weiter. Der Benutzende muss seine Snowflake-Anmeldeinformationen angeben, um sich anmelden zu können. Nach erfolgreicher Anmeldung hat der Benutzende Zugriff auf den Endpunkt. Im Hintergrund generiert die Benutzeranmeldung ein OAuth-Token von Snowflake. Das OAuth-Token wird dann verwendet, um eine Anforderung an den Dienstendpunkt zu senden.
Ein Beispiel dazu finden Sie unter Tutorial 1.
Programmgesteuerter Zugriff auf einen öffentlichen Endpunkt: Es gibt drei Möglichkeiten für programmgesteuerte Clients, auf Endpunkte zuzugreifen:
Verwendung eines programmgesteuerten Zugriffstokens (PAT): Ihre Anwendung übergibt das Token im
Authorization-Header von Anforderungen zur Angabe der Identität an den Endpunkt.Verwendung der Schlüsselpaar-Authentifizierung: Ihre Anwendung generiert ein JWT mithilfe eines Schlüsselpaars, tauscht das JWT mit Snowflake gegen ein OAuth-Token aus und übergibt dann das OAuth-Token im
Authorization-Header von Anforderungen zur Angabe der Identität an den Endpunkt.Verwendung des Python-Konnektors: Ihre Anwendung verwendet den Python-Konnektor, um ein Sitzungs-Token zu erzeugen, und übergibt dann das Sitzungs-Token im
Authorization-Header von Anforderungen zur Angabe der Identität an den Endpunkt.
Weitere Beispiele finden Sie in Tutorial 8.
Benutzerspezifische Header bei Dateneingangsanforderungen¶
Wenn eine Anfrage für einen öffentlichen Endpunkt eintrifft, übergibt Snowflake automatisch den folgenden Header zusammen mit der HTTP-Anfrage an den Container.
Der Containercode kann den Header optional lesen, weiß, wer der Aufrufer ist, und kann kontextspezifische Anpassungen für verschiedene Benutzer vornehmen. Darüber hinaus kann Snowflake optional den Header Sf-Context-Current-User-Email einschließen. Um diesen Header einzufügen, wenden Sie sich an den Snowflake-Support.
Dienst-zu-Dienst-Kommunikation¶
Dienstinstanzen können direkt über TCP (einschließlich HTTP) miteinander kommunizieren. Dies gilt sowohl für Instanzen, die zum selben Dienst gehören, als auch für Instanzen, die zu verschiedenen Diensten gehören.
Instanzen können nur Kommunikationen (Anfragen) über die in der Dienstspezifikation angegebenen Endpunkte empfangen. Der Client (der Dienst, der die Anfrage sendet) muss über die erforderlichen Rollen und Berechtigungen verfügen, um eine Verbindung zu diesem Endpunkt herzustellen (siehe Erforderliche Berechtigungen für den Zugriff auf die Dienstendpunkte (Dienstrollen)).
Standardmäßig kann sich eine Dienstinstanz mit anderen Instanzen desselben Dienstes an den angegebenen Endpunkten verbinden. Allgemeiner ausgedrückt, hat die Eigentümerrolle eines Dienstes die Berechtigung, sich mit Endpunkten von Diensten mit der gleichen Eigentümerrolle zu verbinden.
Damit ein Client-Dienst eine Verbindung zu einem Endpunkt eines Dienstes herstellen kann, der eine andere Eigentümerrolle hat, benötigt die Eigentümerrolle des Client-Dienstes die Dienstrolle, die den Zugriff auf den Endpunkt eines anderen Dienstes gewährt, um diesen Endpunkt aufzurufen. Weitere Informationen dazu finden Sie unter Erforderliche Berechtigungen für den Zugriff auf die Dienstendpunkte (Dienstrollen).
Wenn Sie verhindern möchten, dass Ihre Dienste miteinander kommunizieren (z. B. aus Sicherheitsgründen), verwenden Sie verschiedene Snowflake-Rollen, um diese Dienste zu erstellen.
Eine Dienstinstanz kann entweder über die IP-Adresse des Dienstes oder die IP-Adressen der Dienstinstanz erreicht werden.
Anfragen, die die Dienst-IP-Adresse verwenden, werden an einen Load-Balancer weitergeleitet, der wiederum Anfragen an eine zufällig ausgewählte Dienstinstanz weiterleitet.
Anfragen, die die IP-Adresse der Dienstinstanz verwenden, werden direkt an die entsprechende Dienstinstanz weitergeleitet. Sie müssen die Dienstinstanz-IP verwenden, wenn Sie sich mit einem Endpunkt verbinden, der über das Feld
portRangedefiniert ist (siehe Feld spec.endpoints (optional)).
Beide IP-Adressen sind über den DNS-Namen auffindbar, den Snowflake jedem Dienst automatisch zuweist. Beachten Sie, dass es nicht möglich ist, DNS zu verwenden, um eine Verbindung zu einer bestimmten Instanz herzustellen. So ist es beispielsweise nicht sinnvoll, eine URL unter Verwendung des Namens der Dienstinstanz DNS zu erstellen, da es keine Möglichkeit gibt, den Namen der Dienstinstanz DNS zu verwenden, um auf eine bestimmte Dienstinstanz zu verweisen.
Die IP-Adressen von Dienstinstanzen werden in der Ausgabe des Befehls SHOW SERVICE INSTANCES IN SERVICE angezeigt, wenn das Verhaltensänderungs-Bundle 2025_01 aktiviert ist.
Ein Beispiel für die Dienst-zu-Dienst-Kommunikation finden Sie in Tutorial 4.
Beachten Sie, dass, wenn ein Dienstendpunkt nur erstellt wird, um die Kommunikation zwischen Diensten zu ermöglichen, das TCP-Protokoll verwendet werden sollte (siehe Feld spec.endpoints (optional)).
Name des DNS-Dienstes¶
Das DNS-Namensformat ist:
Verwenden Sie SHOW SERVICES (oder DESCRIBE SERVICE), um den DNS-Namen eines Dienstes zu erhalten. Der vorangehende DNS-Name ist ein vollqualifizierter Name. Dienste, die im selben Schema erstellt wurden, können nur über den <service-name> kommunizieren. Anbieter, die sich in einem anderen Schema oder einer anderen Datenbank befinden, müssen den Hash angeben, z. B. <service-name>.<Hash> oder den vollqualifizierten Namen (<service-name>.<Hash>.svc.spcs.internal).
Verwenden Sie die Funktion SYSTEM$GET_SERVICE_DNS_DOMAIN, um die DNS-Domäne für ein bestimmtes Schema zu finden. Die DNS-Hashwert-Domäne ist spezifisch für die aktuelle Version des Schemas. Beachten Sie Folgendes:
Wenn dieses Schema oder die zugehörige Datenbank umbenannt wird, ändert sich der Hashwert nicht.
Wenn das Schema gelöscht und dann neu erstellt wird (z. B. mit CREATE OR REPLACE SCHEMA), erhält das neue Schema einen neuen Hashwert. Wenn Sie ein UNDROP-Schema verwenden, bleibt der Hashwert gleich.
DNS-Namen haben die folgenden Einschränkungen:
Ihr Dienstname muss ein gültiges DNS-Label sein. (Siehe auch https://www.ietf.org/rfc/rfc1035.html#section-2.3.1). Andernfalls wird das Erstellen eines Dienstes fehlschlagen.
Snowflake ersetzt einen Unterstrich (_) im Dienstnamen durch einen Bindestrich (-) im DNS-Namen.
Ein DNS-Name dient nur der internen Kommunikation innerhalb von Snowflake zwischen Diensten, die in demselben Konto ausgeführt werden. Er ist nicht über das Internet zugänglich.
DNS-Name der Dienstinstanzen¶
Das DNS-Namensformat der Dienstinstanz lautet wie folgt:
Sie wird in eine Liste von IP-Adressen aufgelöst, für jede Dienstinstanz. Beachten Sie, dass es keine garantierte Reihenfolge für die Liste der IP-Adressen gibt, die DNS zurückgibt. Dieser DNS-Name sollte nur mit DNS APIs verwendet werden, nicht als Hostname in einer URL. Die Erwartung ist, dass Ihre Anwendung diesen Hostnamen mit DNS APIs verwendet, um die Gruppe von Dienstinstanz-IPs zu sammeln und sich dann programmgesteuert direkt mit diesen Instanz-IPs zu verbinden.
Diese Liste von IP-Adressen ermöglicht die Erstellung eines Mesh-Netzwerks für die direkte Kommunikation zwischen bestimmten Dienstinstanzen.
Welchen DNS-Namen Sie wählen sollten¶
Die folgenden Überlegungen gelten für die Wahl des DNS-Namens, den Sie für die Verbindung zu einem Dienst bei der Kommunikation von Dienst zu Dienst verwenden.
Verwenden Sie den DNS-Dienstnamen, wenn einer der folgenden Punkte zutrifft:
Sie müssen auf einen bestimmten Port zugreifen, und zwar auf die einfachste Art und Weise.
Sie möchten, dass jede Anfrage an eine zufällig ausgewählte Dienstinstanz gesendet wird.
Sie wissen nicht, wie Ihr Anwendungsframework die DNS-Antworten ausführt und zwischenspeichert.
Verwenden Sie die den DNS-Namen der Dienstinstanz oder die IP der Dienstinstanz, wenn einer der folgenden Punkte zutrifft:
Sie möchten die IP-Adressen aller Dienstinstanzen ermitteln.
Sie möchten einen zwischengeschalteten Load Balancer auslassen.
Sie verwenden verteilte Frameworks oder Datenbanken wie Ray oder Cassandra, die IP-Adressen von Dienstinstanzen als Identitäten verwenden.
Verwalten der Typen von Services, die in Ihrem Konto zulässig sind¶
Snowflake unterstützt verschiedene Typen von Services (Workload-Typen), die Sie in Ihrem Konto erstellen können. Dazu gehören vom Benutzer bereitgestellte Workloads, wie z. B. Services und Jobs, sowie von Snowflake selbst verwaltete Workloads, wie z. B. Notebooks, Modellbereitstellung und ML-Jobs. Eine Liste der Workload-Typen finden Sie unter ALLOWED_SPCS_WORKLOAD_TYPES.
Wenn Sie Services in Ihrem Konto mit SHOW SERVICES auflisten, können Sie einen Filter einfügen, um nur bestimmte Workload-Typen aufzulisten. Zum Beispiel nur vom Benutzer bereitgestellte Services anzeigen:
Sie können die Typen von Workloads, die in Ihrem Snowflake-Konto zulässig sind, mithilfe der Parameter ALLOWED_SPCS_WORKLOAD_TYPES und DISALLOWED_SPCS_WORKLOAD_TYPES auf Kontoebene einschränken. Führen Sie zum Beispiel, um nur NOTEBOOK-Workloads zuzulassen, die folgende Anweisung aus:
Bemerkung
Workload-Typen, die in DISALLOWED_SPCS_WORKLOAD_TYPES angegeben sind, können nicht bereitgestellt werden. Wenn Sie sowohl ALLOWED_SPCS_WORKLOAD_TYPES als auch DISALLOWED_SPCS_WORKLOAD_TYPES konfigurieren, hat die Liste der nicht zulässigen Werte Vorrang. Wenn beispielsweise beide Parameter den Workload-Typ NOTEBOOK angeben, dürfen NOTEBOOK-Workloads nicht auf Snowpark Container Services ausgeführt werden.
Services, die erstellt werden, bevor Sie diese Parameter auf Kontoebene konfigurieren, werden weiterhin ausgeführt. Wenn Sie jedoch einen Service anhalten, dessen Workload-Typ nicht zulässig ist, können Sie ihn nicht neu starten.
Um alle zuvor erstellten Services mit unzulässigen Typen zu löschen, führen Sie den Befehl ALTER COMPUTE POOL … STOP ALL OF TYPE aus.
Übergabe von Anmeldeinformationen an einen Container mit Snowflake-Geheimnissen¶
Es gibt viele Gründe, warum Sie von Snowflake verwaltete Anmeldeinformationen an Ihren Container weitergeben möchten. Ihr Dienst könnte zum Beispiel mit externen Endpunkten (außerhalb von Snowflake) kommunizieren. In diesem Fall müssen Sie in Ihrem Container Anmeldeinformationen bereitstellen, die Ihr Anwendungscode verwenden kann.
Um Anmeldeinformationen bereitzustellen, speichern Sie diese zunächst in Snowflake-Geheimnis-Objekten. In der Service-Spezifikation geben Sie dann unter containers.secrets an, welche Geheimnisobjekte verwendet werden sollen und wo sie im Container platziert werden sollen. Sie können diese Anmeldeinformationen entweder an Umgebungsvariablen in den Containern übergeben oder sie in lokalen Dateien in den Containern verfügbar machen.
Snowflake-Geheimnisse angeben¶
Geben Sie ein Snowflake-Geheimnis durch Name oder Referenz an (die Referenz ist nur im Native Application-Szenario anwendbar):
Snowflake-Geheimnis per Name übergeben: Sie können einen Geheimnamen als
snowflakeSecret-Feldwert übergeben.Beachten Sie, dass Sie optional
<secret-name>direkt als WertsnowflakeSecretangeben können.Snowflake-Geheimnis per Referenz weitergeben: Wenn Sie Snowpark Container Services verwenden, um eine Native App (eine App mit Containern) zu erstellen, verwenden der App-Produzent und die Verbraucher unterschiedliche Snowflake-Konten. In bestimmten Kontexten muss eine installierte Snowflake Native App auf bestehende Geheimnisobjekte im Verbraucherkonto zugreifen, die außerhalb des APPLICATION-Objekts existieren. In diesem Fall können Entwickler die Syntax der Spezifikation „secrets by reference“ (Geheimnisse per Referenz) verwenden, um Anmeldeinformationen wie gezeigt zu behandeln:
Beachten Sie, dass die Spezifikation
objectReferenceanstelle vonobjectNameverwendet, um einen geheimen Referenznamen anzugeben.
Festlegen der Platzierung von Geheimnissen innerhalb des Containers¶
Sie können Snowflake anweisen, die Geheimnisse entweder als Umgebungsvariablen in den Containern zu platzieren oder sie in lokale Dateien der Container zu schreiben.
Übergeben Sie Geheimnisse als Variablen der Umgebung¶
Um Snowflake-Geheimnisse als Umgebungsvariablen an Container zu übergeben, fügen Sie envVarName in das containers.secrets-Feld ein.
Der secretKeyRef-Wert hängt von der Art des Snowflake-Geheimnisses ab. Mögliche Werte sind die folgenden:
usernameoderpassword, wenn das Snowflake-Geheimnis vom Typpasswordist.secret_string, wenn das Snowflake-Geheimnis vom Typgeneric_stringist.
Beachten Sie, dass Snowflake die als Umgebungsvariablen übergebenen Geheimnisse nicht aktualisiert, nachdem ein Dienst erstellt wurde.
Beispiel 1: Übergeben von Geheimnissen des Typs password als Umgebungsvariable¶
In diesem Beispiel erstellen Sie das folgende Snowflake-Geheimnisobjekt vom Typ password:
Um dieses Snowflake-Geheimnisobjekt den Umgebungsvariablen (z. B. LOGIN_USER und LOGIN_PASSWORD) in Ihrem Container zur Verfügung zu stellen, fügen Sie das folgende Feld containers.secrets in die Spezifikationsdatei ein:
In diesem Beispiel ist der Wert snowflakeSecret ein vollständig qualifizierter Objektname, da Geheimnisse in einem anderen Schema als der zu erstellende Dienst gespeichert sein können.
Das Feld containers.secrets in diesem Beispiel ist eine Liste mit zwei snowflakeSecret-Objekten:
Mit dem ersten Objekt wird
usernameim Snowflake-Geheimnisobjekt der UmgebungsvariablenLOGIN_USERin Ihrem Container zugeordnet.Mit dem zweiten Objekt wird
passwordim Snowflake-Geheimnisobjekt der UmgebungsvariablenLOGIN_PASSWORDin Ihrem Container zugeordnet.
Beispiel 2: Übergeben von Geheimnissen vom Typ generic_string als Umgebungsvariable¶
In diesem Beispiel erstellen Sie das folgende Snowflake-Geheimnisobjekt vom Typ generic_string:
Um dieses Snowflake-Geheimnisobjekt den Umgebungsvariablen (z. B. GENERIC_SECRET) in Ihrem Container zur Verfügung zu stellen, fügen Sie das folgende Feld containers.secrets in die Spezifikationsdatei ein:
Geheimnisse in lokale Containerdateien schreiben¶
Um Snowflake-Geheimnisse für Ihren Anwendungscontainer in lokalen Containerdateien verfügbar zu machen, fügen Sie ein containers.secrets-Feld ein: Um Snowflake-Geheimnisse für Ihren Anwendungscontainer in lokalen Containerdateien verfügbar zu machen, fügen Sie directoryPath in die Datei containers.secrets ein:
Snowflake füllt die notwendigen Dateien für das Geheimnis in diesem angegebenen directoryPath auf; die Angabe von secretKeyRef ist nicht erforderlich. Je nach Geheimnistyp erstellt Snowflake die folgenden Dateien im Container unter dem von Ihnen angegebenen Verzeichnispfad:
usernameundpassword, wenn das Snowflake-Geheimnis vom Typpasswordist.secret_string, wenn das Snowflake-Geheimnis vom Typgeneric_stringist.access_token, wenn das Snowflake-Geheimnis vom Typoauth2ist.
Bemerkung
Wenn nach dem Erstellen eines Dienstes das Snowflake-Geheimnisobjekt aktualisiert wird, aktualisiert Snowflake die entsprechenden Geheimnisdateien in den aktiven Containern.
Beispiel 1: Übergeben von Geheimnissen des Typs password mithilfe von lokalen Containerdateien¶
In diesem Beispiel erstellen Sie das folgende Snowflake-Geheimnisobjekt vom Typ password:
Um diese Anmeldeinformationen in lokalen Containerdateien zur Verfügung zu stellen, fügen Sie das folgende containers.secrets-Feld in die Spezifikationsdatei ein:
Wenn Sie Ihren Dienst starten, erstellt Snowflake zwei Dateien innerhalb des Containers: /usr/local/creds/username und /usr/local/creds/password. Ihr Anwendungscode kann dann diese Dateien lesen.
Beispiel 2: Übergabe von Geheimnissen vom Typ generic_string in lokalen Containerdateien¶
In diesem Beispiel erstellen Sie das folgende Snowflake-Geheimnisobjekt vom Typ generic_string:
Um dieses geheime Snowflake-Objekt in lokalen Containerdateien bereitzustellen, fügen Sie das folgende containers.secrets-Feld in die Datei mit den Spezifikationen ein:
Wenn Sie Ihren Dienst starten, erstellt Snowflake diese Datei in den Containern: /usr/local/creds/secret_string.
Beispiel 3: Übergeben von Geheimnissen des Typs oauth2 mithilfe von lokalen Containerdateien¶
In diesem Beispiel erstellen Sie das folgende Snowflake-Geheimnisobjekt vom Typ oauth2:
Um diese Anmeldeinformationen in lokalen Containerdateien zur Verfügung zu stellen, fügen Sie das folgende containers.secrets-Feld in die Spezifikationsdatei ein:
Snowflake ruft das Zugriffstoken aus dem OAuth-Geheimnisobjekt ab und erstellt /usr/local/creds/access_token in den Containern.
Wenn ein Dienst Geheimnisse des „oauth2“-Typs verwendet, wird erwartet, dass der Dienst dieses Geheimnis für den Zugriff auf ein Internetziel verwendet. Ein OAuth-Geheimnis muss von einer Integration für den externen Zugriff (EAI) erlaubt werden, da sonst CREATE SERVICE und EXECUTE JOB SERVICE fehlschlagen. Diese zusätzliche EAI-Anforderung gilt nur für Geheimnisse des „oauth2“-Typs und nicht für andere Typen von Geheimnissen.
Zusammenfassend sind folgende allgemeine Schritte zum Erstellen eines solchen Dienstes erforderlich:
Erstellen Sie ein Geheimnis vom Typ „oauth2“ (siehe oben).
Erstellen Sie eine EAI, um die Verwendung des Geheimnisses durch einen Dienst zu erlauben. Beispiel:
Erstellen Sie einen Dienst, der ein
containers.secrets-Feld in der Spezifikation enthält. Darin wird auch die optionale Eigenschaft EXTERNAL_ACCESS_INTEGRATIONS mit einer EAI angegeben, um die Verwendung des OAuth2-Geheimnisses zuzulassen.Beispiel für einen CREATE SERVICE-Befehl (mit Inline-Spezifikation):
Weitere Informationen zu ausgehendem Datenverkehr finden Sie unter Konfigurieren des ausgehenden Datenverkehrs des Dienstes.
Richtlinien und Einschränkungen¶
Weitere Informationen dazu finden Sie unter Snowpark Container Services: Richtlinien und Einschränkungen.