Funções de agregação definidas pelo usuário em Python¶
Funções agregadas definidas pelo usuário (UDAFs) usam uma ou mais linhas como entrada e produzem uma única linha de saída. Elas operam em valores de várias linhas para realizar cálculos matemáticos como soma, média, contagem, valores mínimos/máximos, desvio padrão e estimativa, assim como algumas operações não matemáticas.
As UDAFs Python fornecem uma maneira para você escrever suas próprias funções de agregação de são semelhantes às funções de agregação SQL definidas pelo sistema Snowflake.
O aggregate_state tem um tamanho máximo de 64 MB em uma versão serializada, então tente controlar o tamanho do estado agregado.
Você não pode chamar uma UDAF como uma função de janela (em outras palavras, com uma cláusula OVER).
IMMUTABLE não é suportado em uma função agregada (quando você usa o parâmetro AGGREGATE). Portanto, todas as funções agregadas são VOLATILE por padrão.
Funções de agregação definidas pelo usuário não podem ser usadas em conjunto com a cláusula WITHIN GROUP. As consultas não serão executadas.
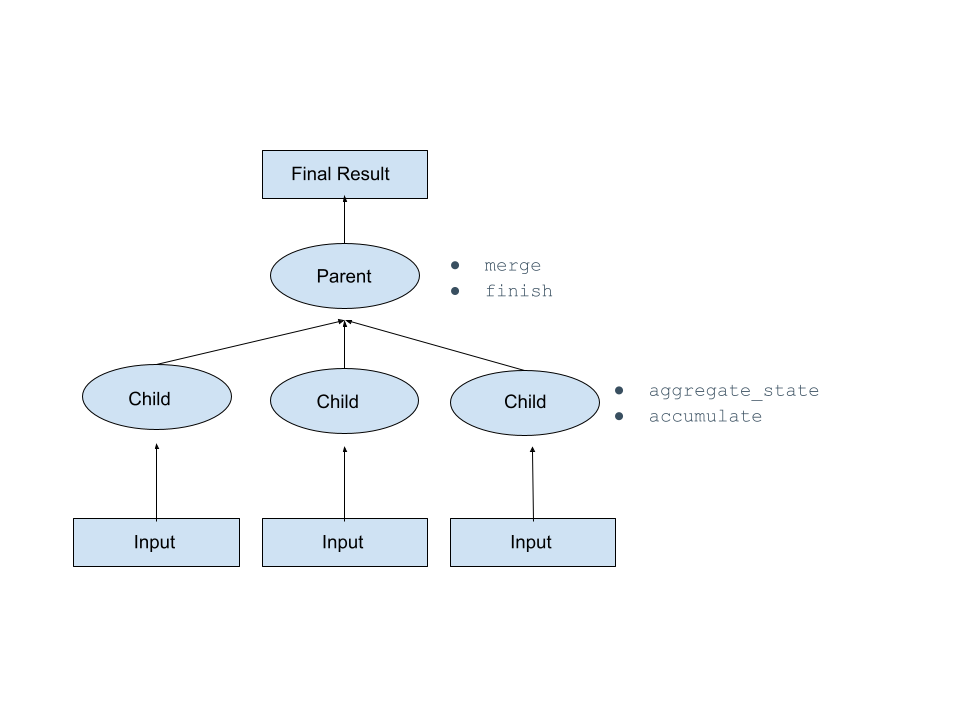
Uma função de agregação agrega estados em nós filhos e, então, eventualmente, esses estados agregados são serializados e enviados ao nó pai, onde são mesclados e o resultado final é calculado.
Para definir uma função de agregação, você deve definir uma classe Python (que é o manipulador da função) que inclua métodos que o Snowflake invoca em tempo de execução. Esses métodos são descritos na tabela abaixo. Veja exemplos em outras partes deste tópico.
O código no exemplo a seguir define uma função de agregação python_sum definida pelo usuário (UDAF) para retornar a soma dos valores numéricos.
Crie a UDAF.
CREATEORREPLACEAGGREGATEFUNCTIONPYTHON_SUM(aINT)RETURNSINTLANGUAGEPYTHONRUNTIME_VERSION=3.12HANDLER='PythonSum'AS$$classPythonSum:def__init__(self):# This aggregate state is a primitive Python data type.self._partial_sum=0@propertydefaggregate_state(self):returnself._partial_sumdefaccumulate(self,input_value):self._partial_sum+=input_valuedefmerge(self,other_partial_sum):self._partial_sum+=other_partial_sumdeffinish(self):returnself._partial_sum$$;
O código no exemplo a seguir define uma função de agregação python_avg definida pelo usuário para retornar a média dos valores numéricos.
Crie a função.
CREATEORREPLACEAGGREGATEFUNCTIONpython_avg(aINT)RETURNSFLOATLANGUAGEPYTHONRUNTIME_VERSION=3.12HANDLER='PythonAvg'AS$$fromdataclassesimportdataclass@dataclassclassAvgAggState:count:intsum:intclassPythonAvg:def__init__(self):# This aggregate state is an object data type.self._agg_state=AvgAggState(0,0)@propertydefaggregate_state(self):returnself._agg_statedefaccumulate(self,input_value):sum=self._agg_state.sumcount=self._agg_state.countself._agg_state.sum=sum+input_valueself._agg_state.count=count+1defmerge(self,other_agg_state):sum=self._agg_state.sumcount=self._agg_state.countother_sum=other_agg_state.sumother_count=other_agg_state.countself._agg_state.sum=sum+other_sumself._agg_state.count=count+other_countdeffinish(self):sum=self._agg_state.sumcount=self._agg_state.countreturnsum/count$$;
O código no exemplo a seguir retorna uma lista dos maiores valores para k. O código acumula valores de entrada negados em um heap mínimo e, em seguida, retorna os primeiros valores maiores k.
CREATEORREPLACEAGGREGATEFUNCTIONpythonTopK(inputINT,kINT)RETURNSARRAYLANGUAGEPYTHONRUNTIME_VERSION=3.12HANDLER='PythonTopK'AS$$importheapqfromdataclassesimportdataclassimportitertoolsfromtypingimportList@dataclassclassAggState:minheap:List[int]k:intclassPythonTopK:def__init__(self):self._agg_state=AggState([],0)@propertydefaggregate_state(self):returnself._agg_state@staticmethoddefget_top_k_items(minheap,k):# Return k smallest elements if there are more than k elements on the min heap.if(len(minheap)>k):return[heapq.heappop(minheap)foriinrange(k)]returnminheapdefaccumulate(self,input,k):self._agg_state.k=k# Store the input as negative value, as heapq is a min heap.heapq.heappush(self._agg_state.minheap,-input)# Store only top k items on the min heap.self._agg_state.minheap=self.get_top_k_items(self._agg_state.minheap,k)defmerge(self,other_agg_state):k=self._agg_state.kifself._agg_state.k>0elseother_agg_state.k# Merge two min heaps by popping off elements from one and pushing them onto another.while(len(other_agg_state.minheap)>0):heapq.heappush(self._agg_state.minheap,heapq.heappop(other_agg_state.minheap))# Store only k elements on the min heap.self._agg_state.minheap=self.get_top_k_items(self._agg_state.minheap,k)deffinish(self):return[-xforxinself._agg_state.minheap]$$;
CREATEORREPLACETABLEnumbers_table(num_columnINT);INSERTINTOnumbers_tableSELECT5FROMTABLE(GENERATOR(ROWCOUNT=>10));INSERTINTOnumbers_tableSELECT1FROMTABLE(GENERATOR(ROWCOUNT=>10));INSERTINTOnumbers_tableSELECT9FROMTABLE(GENERATOR(ROWCOUNT=>10));INSERTINTOnumbers_tableSELECT7FROMTABLE(GENERATOR(ROWCOUNT=>10));INSERTINTOnumbers_tableSELECT10FROMTABLE(GENERATOR(ROWCOUNT=>10));INSERTINTOnumbers_tableSELECT3FROMTABLE(GENERATOR(ROWCOUNT=>10));-- Return top 15 largest values from numbers_table.SELECTpythonTopK(num_column,15)FROMnumbers_table;