Amostra de serviço remoto assíncrono para AWS¶
Este tópico contém uma amostra assíncrona da Função AWS Lambda (serviço remoto). Você pode criar esta função de amostra seguindo as mesmas etapas descritas em Etapa 1: Como criar o serviço remoto (função lambda AWS) no Console de gerenciamento.
Visão geral do código¶
Esta seção da documentação fornece informações sobre a criação de uma função externa assíncrona na AWS. (Antes de implementar sua primeira função externa assíncrona, você pode ler a visão geral conceptual das funções externas assíncronas).
Na AWS, os serviços remotos assíncronos devem superar as seguintes restrições:
Como HTTP POST e GET são solicitações separadas, o serviço remoto deve manter informações sobre o fluxo de trabalho iniciado pela solicitação POST para que o estado possa ser consultado posteriormente pela solicitação GET.
Geralmente, cada HTTP POST e HTTP GET invoca uma instância separada da(s) função(ões) do manipulador em um processo ou thread separado. As instâncias separadas não compartilham memória. Para que o manipulador GET possa ler o status ou os dados processados, o manipulador GET deve acessar um recurso de armazenamento compartilhado que está disponível na AWS.
A única maneira do manipulador POST enviar o código de resposta HTTP 202 inicial é por meio de uma instrução
return(ou equivalente), que encerra a execução do manipulador. Portanto, antes de retornar HTTP 202, o manipulador de POST deve iniciar um processo (ou thread) independente para fazer o trabalho real de processamento de dados do serviço remoto. Este processo independente normalmente precisa de acesso ao armazenamento que é visível para o manipulador GET.
Uma maneira de um serviço remoto assíncrono superar essas restrições é usar 3 processos (ou threads) e armazenamento compartilhado:
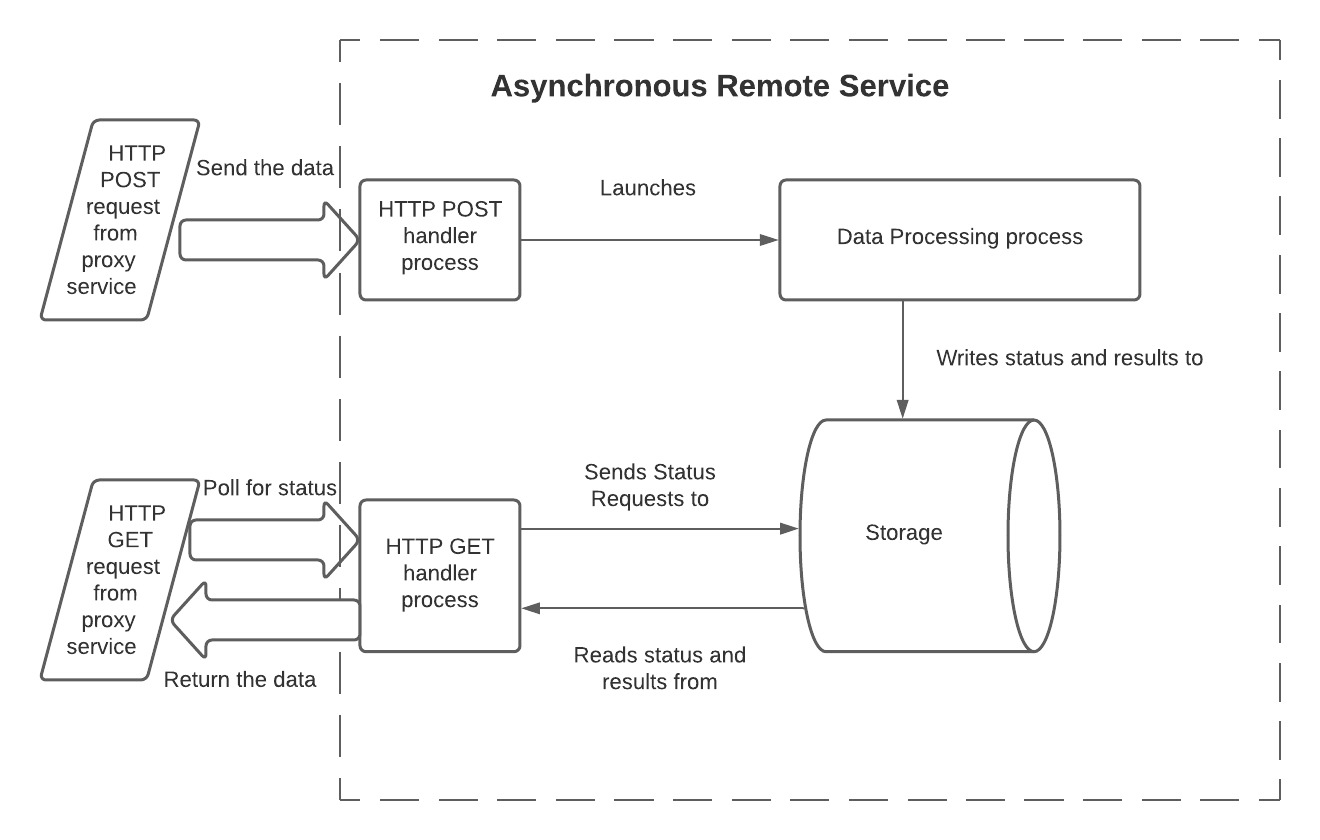
Nesse modelo, os processos têm as seguintes responsabilidades:
O manipulador HTTP POST:
Lê os dados de entrada. Em uma função Lambda, isto é lido a partir do corpo do parâmetro de entrada de
eventda função do manipulador.Lê a ID de lote. Em uma função Lambda, isto é lido a partir do cabeçalho do parâmetro de entrada de
event.Inicia o processo de processamento de dados, e passa os dados e a ID de lote. Os dados são geralmente passados durante a chamada, mas podem ser passados gravando-os para armazenamento externo.
Registra a ID de lote em um armazenamento compartilhado que o processo de processamento de dados e o processo do manipulador HTTP GET podem acessar.
Se necessário, registra que o processamento desse lote ainda não terminou.
Retorna HTTP 202 se nenhum erro for detectado.
O código de processamento de dados:
Lê os dados de entrada.
Processa os dados.
Torna o resultado disponível para o manipulador GET (gravando os dados do resultado para o armazenamento compartilhado, ou fornecendo uma API por meio da qual é possível consultar os resultados).
Normalmente, atualiza o status desse lote (por exemplo, de
IN_PROGRESSparaSUCCESS) para indicar que os resultados estão prontos para serem lidos.Sai. Opcionalmente, esse processo pode retornar um indicador de erro. O Snowflake não vê isso diretamente (o Snowflake vê apenas os códigos de retorno HTTP do manipulador POST e manipulador GET), mas retornar um indicador de erro do processo de processamento de dados pode ajudar durante a depuração.
O manipulador GET:
Lê a ID de lote. Em uma função Lambda, isto é lido a partir do cabeçalho do parâmetro de entrada de
event.Lê o armazenamento para obter o status atual desse lote (por exemplo,
IN_PROGRESSouSUCCESS).Se o processamento ainda estiver em andamento, retorna 202.
Se o processamento tiver terminado com sucesso, então:
Lê os resultados.
Limpa o armazenamento.
Retorna os resultados junto com o código HTTP 200.
Se o status armazenado indicar um erro, então:
Limpa o armazenamento.
Retorna um código de erro.
Observe que o manipulador GET pode ser chamado várias vezes para um lote se o processamento demorar o suficiente para que múltiplas solicitações HTTP GET sejam enviadas.
Há muitas variações possíveis nesse modelo. Por exemplo:
A ID de lote e o status podem ser gravados no início do processo de processamento de dados, e não no final do processo POST.
O processamento de dados pode ser feito em uma função separada (por exemplo, uma função Lambda separada) ou mesmo como um serviço completamente separado.
O código de processamento de dados não precisa necessariamente ser gravado para o armazenamento compartilhado. Em vez disso, os dados processados podem ser disponibilizados de outra forma. Por exemplo, uma API pode aceitar a ID de lote como um parâmetro e retornar os dados.
O código de implementação deve levar em conta a possibilidade de que o processamento demore muito tempo ou falhe e, portanto, qualquer resultado parcial deve ser limpo para evitar o desperdício de espaço de armazenamento.
O mecanismo de armazenamento deve ser compartilhável por meio de múltiplos processos (ou threads). Os possíveis mecanismos de armazenamento incluem:
Mecanismos de armazenamento fornecidos pela AWS, como:
Espaço em disco (por exemplo, Amazon Elastic File System (EFS) ).
Um servidor de banco de dados local disponível pela AWS (por exemplo, Amazon DynamoDB ).
Armazenamento que está fora da AWS, mas acessível a partir da AWS.
O código para cada um dos processos 3 acima pode ser gravado como 3 funções Lambda separadas (uma para o manipulador POST, uma para a função de processamento de dados e uma para o manipulador GET), ou como uma única função que pode ser invocada de diferentes maneiras.
A amostra de código Python abaixo é uma única função Lambda que pode ser chamada separadamente para processos POST, processamento de dados e processos GET.
Código da amostra¶
Este código mostra um exemplo de consulta com saída. O foco deste exemplo está nos três processos e como eles interagem, não no mecanismo de armazenamento compartilhado (DynamoDB) ou na transformação de dados (análise de sentimento). O código é estruturado para facilitar a substituição do mecanismo de armazenamento de exemplo e a transformação de dados em outros diferentes.
Para simplificar, este exemplo:
Codifica alguns valores importantes (por exemplo, a região AWS).
Considera a existência de alguns recursos (por exemplo, a tabela Jobs no Dynamo).
Amostra de chamada e saída¶
Aqui está uma chamada de amostra para a função externa assíncrona, juntamente com a saída de amostra, incluindo os resultados da análise de sentimento:
Notas sobre o código da amostra¶
A função de processamento de dados é invocada por chamada:
O InvocationType deve ser ‘Event’, como mostrado acima, porque o segundo processo (ou thread) deve ser assíncrono e
Eventé o único tipo de chamada sem bloqueio disponível pelo métodoinvoke().A função de processamento de dados retorna um código HTTP 200. Entretanto, esse código HTTP 200 não é retornado diretamente ao Snowflake. O Snowflake não vê HTTP 200 até que GET faça a sondagem do status e veja que a função de processamento de dados terminou o processamento desse lote com sucesso.